Embed Size (px)
Citation preview

Content Mining: Technology and Policy Developments
@jenny_molloy World Health Organisation – 9 April 2015

What is content?

What is mining?
1982“Automatically generating logical representations of text passages... by means of an analysis of the coherence structure of the passages.”Jerry R. Hobbs, Donald E. Walker, and Robert A. Amsler. 1982. Natural language access to structured text. In Proceedings of the 9th conference on Computational linguistics - Volume 1(COLING '82), Ján Horecký (Ed.), Vol. 1. Academia Praha, , Czechoslovakia, 127-132. DOI=10.3115/991813.991833 http://dx.doi.org/10.3115/991813.991833
2008“The use of automated methods for exploiting
the enormous amount of knowledge available in the biomedical literature.”
Cohen, K. Bretonnel; Hunter, Lawrence (2008). "Getting Started in Text Mining". PLoS Computational Biology 4 (1): e20. doi:10.1371/journal.pcbi.0040020. PMC 2217579.PMID 18225946.

Legal Considerations
Copyright
Databaserights
ContractLaw

2011
2014
From 2014
UK Law
Workshops, hackdays, presentations, collaborations, discussions with librarians and publishers.Putting new rights into action.

In Europe2013
Shortly after
20132015
Research commisioned through H2020...any EU Directive >5 years away.Ireland already considering following UK - plus other member states?.

OUR MISSION
“make 100,000,000 facts from the scholarly literature
open, accessible and reusable”

SOFTWARE OVERVIEWquickscrape & thresher
norma AMI fact extraction

THE SCALE OF THE TASK• ~ 27,000 peer reviewed journals* • > 5,000 publishers • ~ 3,000 new papers per day
*Ulrich’s database: http://ulrichsweb.serialssolutions.com/login

STRUCTURED INFORMATION
• chemical names and structures • species • metabolism • phylogenetic trees

SOFTWARE PIPELINE
PRODUCT:
PROCESS:
journals (ISSNs)
fulltext URLs
metadata + content +
filesfacts
crawl scrape extract

CRAWLING
The latest journal tables of contents at Journal TOCs
http://www.journaltocs.hw.ac.uk/

SCRAPERS• all have the same plumbing • scraping software (thresher) handles the plumbing • scraperJSON is a config file
• supports large collections of scrapers • no programming required • not limited to one piece of software

BASIC SCRAPER JSONname of the scraper:
the URL(s) it applies to: the elements to capture:
element name: where to find it:
{ !
"name": "PLOS", !
"url": "plos\\w*.org", !
"elements": { !
"title": { !
"selector": “//h1[@property=‘dc:title’]”, !
} !
} !
} !
http://github.com/ContentMine/scraperJSON

SCRAPERS
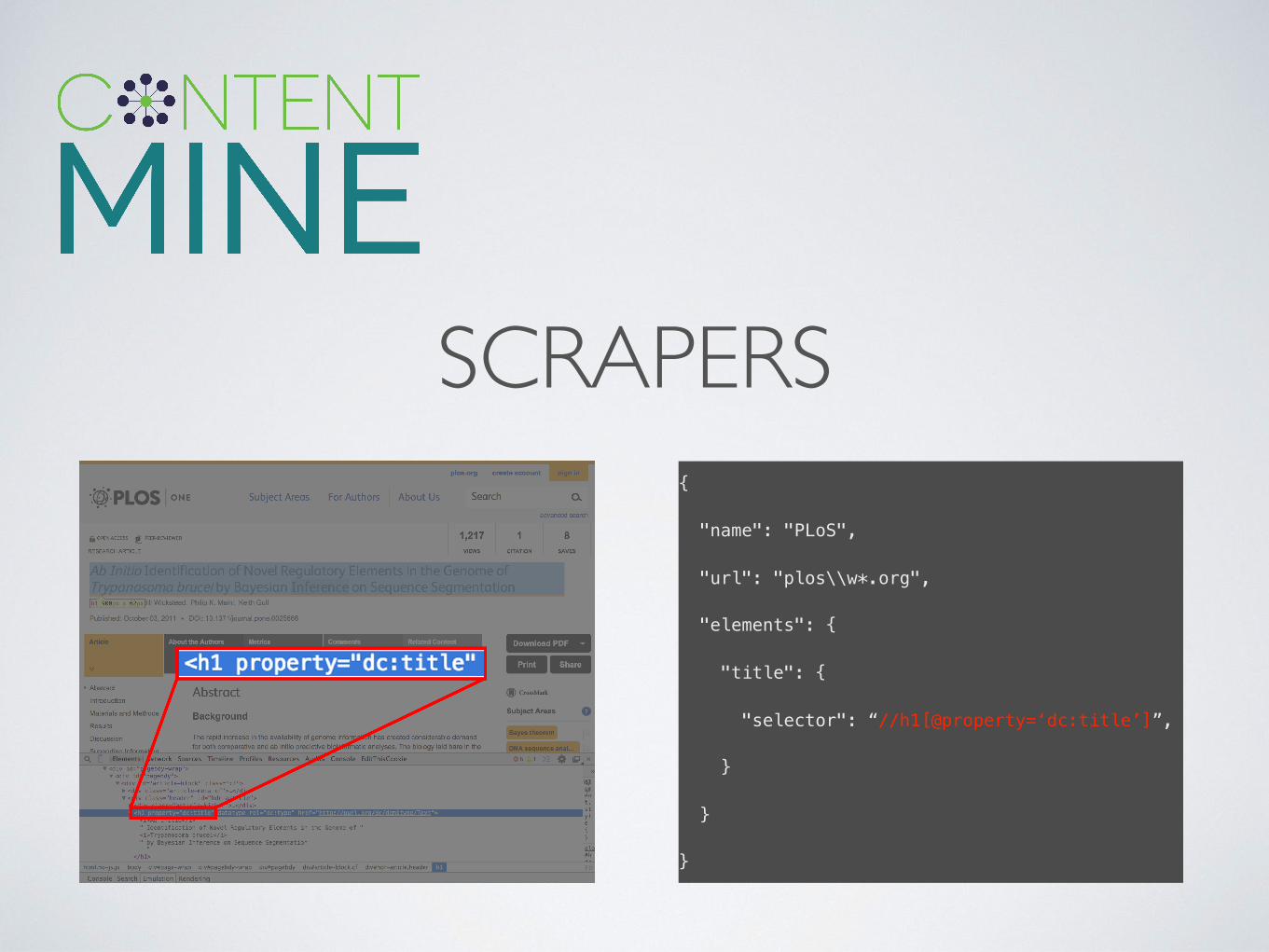
SCRAPERS{ !
"name": "PLoS", !
"url": "plos\\w*.org", !
"elements": { !
"title": { !
"selector": “//h1[@property=‘dc:title’]”, !
} !
} !
} !

SCRAPERS
{ !
"title": "Ab Initio Identification of Novel Regulatory Elements in the Genome of Trypanosoma brucei by Bayesian Inference on Sequence Segmentation" !
} !
bibJSON output

THRESHER & QUICKSCRAPE• reference implementation of scraperJSON • thresher is the scraping library
• http://github.com/ContentMine/thresher
• quickscrape is the command-line tool • http://github.com/ContentMine/quickscrape
• Node.js, MIT licensed

JOURNAL SCRAPERShttp://github.com/ContentMine/journal-scrapers
a self-testing collection of scraperJSON scrapers for academic journals
PLOS MDPI
PeerJ Wiley
ScienceDirect Taylor & Francis
NPG, AAAS, RSC, ACS Springer

NORMALISATIONquickscrape HTML
PDFXMLDOCCSV
Norma sHTMLAMI fact
extraction

NORMALISATIONbefore after
• un-navigable • non-unicode • pixel glyphs • no structure
• processable • sectioned • tagged • structured

NORMALISATIONmending on a journal-by-journal basis
invalid XHTML from PLOS ONE
invalid XHTML from BMC

NORMALISATIONdocument structure
before: un-sectioned HTML from Hindawi
after: sectioned and tagged HTML

FACT EXTRACTIONwe can’t turn a hamburger into a cow
but we can turn PDFs into science

FACT EXTRACTIONAMI software: https://bitbucket.org/petermr/ami-core
pixel path shape char word… !! para document SCIENCE

FACT EXTRACTION• titles • scale • units • ticks • quantity • + data
DATA!!%2000+%points%
VECTOR%%PDF%

FACT EXTRACTION
raw mobile photo shadows, contrast,
noise, skew
binarization: pixels = 0, 1
clipping
AMI-chem for extracting chemical formulae
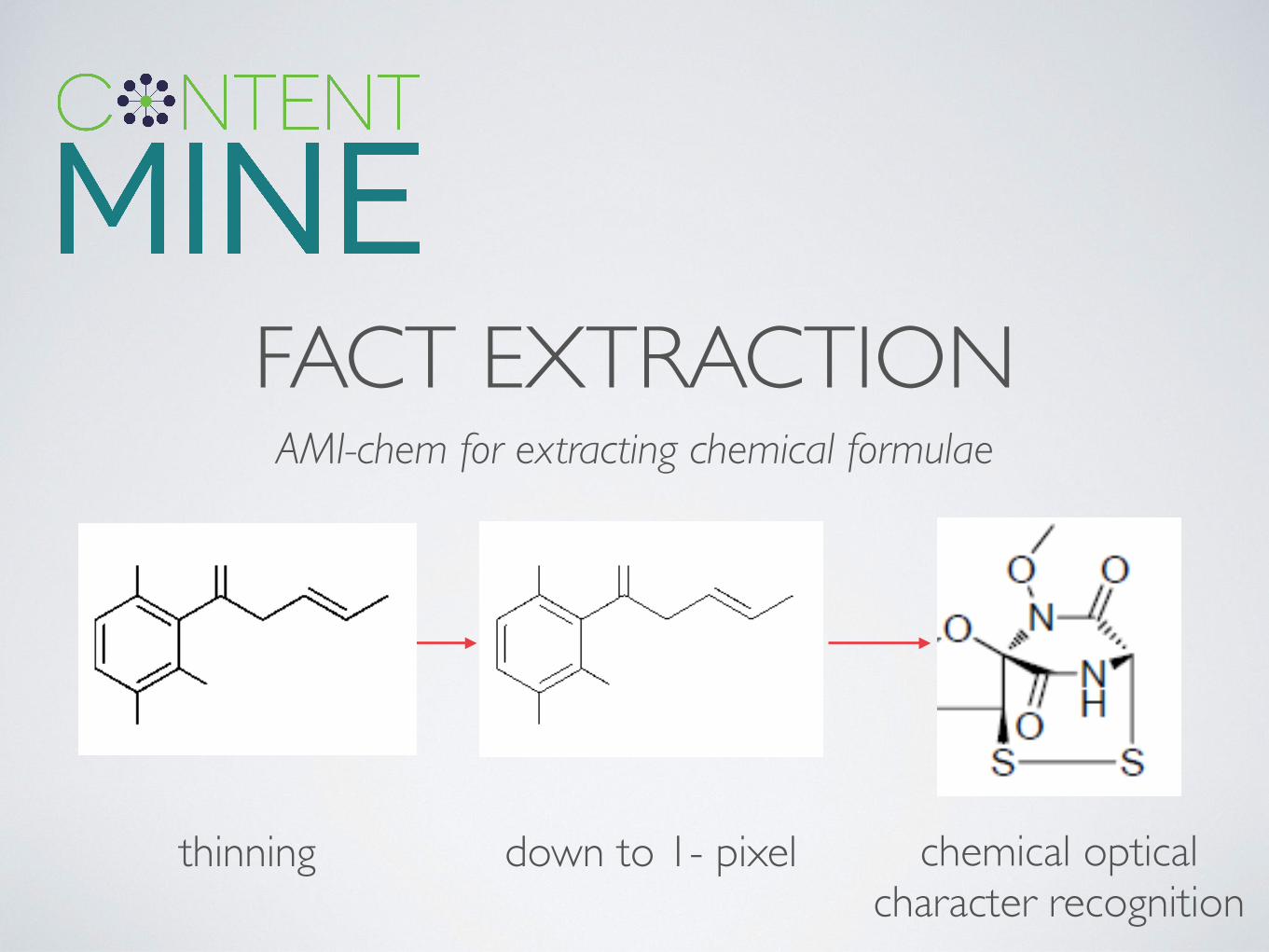
FACT EXTRACTION
thinning chemical optical character recognition
down to 1- pixel
AMI-chem for extracting chemical formulae

FACT EXTRACTION
thinning topology
AMI-phylo for extracting phylogenetic trees

FACT EXTRACTION
Newick format can be viewed at: http://www.unc.edu/~bdmorris/treelib-js/demo.html
AMI-phylo for extracting phylogenetic trees
serialization
((n122,((n121,n205),((n39,(n84,((((n35,n98),n191),n22),n17))),((n10,n182),((((n232,n76),n68),(n109,n30)),(n73,(n106,n58))))))),((((((n103,n86),(n218,(n215,n157))),((n164,n143),((n190,((n108,n177),(n192,n220))),((n233,n187),n41)))),((((n59,n184),((n134,n200),(n137,(n212,((n92,n209),n29))))),(n88,(n102,n161))),((((n70,n140),(n18,n188)),(n49,((n123,n132),(n219,n198)))),(((n37,(n65,n46)),(n135,(n11,(n113,n142)))),(n210,((n69,(n216,n36)),(n231,n160))))))),(((n107,n43),((n149,n199),n74)),(((n101,(n19,n54)),n96),(n7,((n139,n5),((n170,(n25,n75)),(n146,(n154,(n194,(((n14,n116),n112),(n126,n222))))))))))),(((((n165,(n168,n128)),n129),((n114,n181),(n48,n118))),((n158,(n91,(n33,n213))),(n87,n235))),((n197,(n175,n117)),(n196,((n171,(n163,n227)),((n53,n131),n159)))))));

Mining Examples
Building bacterial supertrees
Mining chemical reactions
Better genome annotation

Chemistry
AMI reads and recognises chemicals structures. Can even create reaction animation.
Natural language processing can be used to analyse chemical methods. These are FACTS but the paper itself may be copyrighted.

Clinical Trials
Clinical trials offer clear use cases for content mining.
Data extraction from graphs could be very useful for meta-analyses where raw data is unavailable.
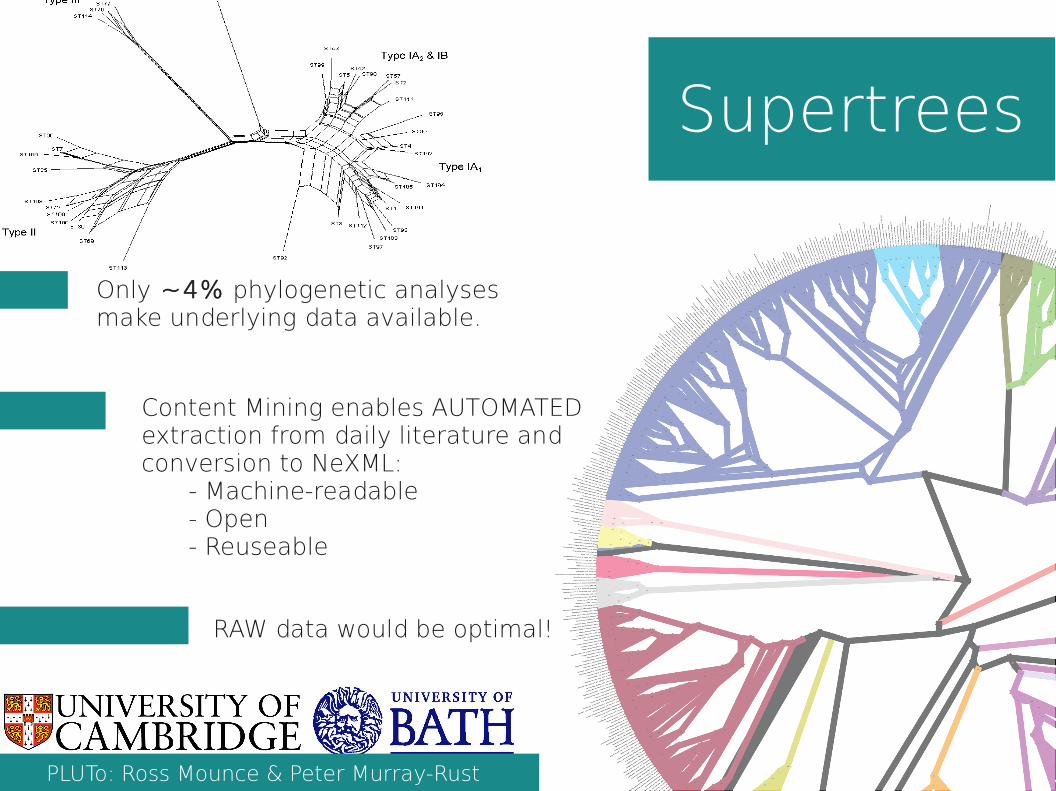
Only ~4% phylogenetic analyses make underlying data available.
Supertrees
Content Mining enables AUTOMATED extraction from daily literature and conversion to NeXML:
- Machine-readable- Open- Reuseable
RAW data would be optimal!
PLUTo: Ross Mounce & Peter Murray-Rust

Annotation
Many applications:
- Find primers- Enhance positive controls- Find novel sequence information- More detailed and accurate annotation
Potential to improve quality and efficiency
of genomic research.

WHO
Thank you very much for your attention!Any questions?
Peter Murray-RustRoss Mounce
Richard Smith-UnnaSteph UnnaJenny Molloy
Mark MacGillivrayGraham Steel
With thanks to:Charles Oppenheim
Michelle Brook
Follow @TheContentMine
contentmine.org
Find the code ongithub.com/Content
Mine
Funded by:
Why might ContentMine be of interest?
Training for pubic health data researchers.
'Science on a Stick' standardised scholarly HTML corpus for mining.
Potential to mine other standardised PDF documents such as reports.
Open source, academic-led, easy to use and customise.

All images are licensed under CC-BY unless otherwise stated
What is Content?Phylogenetic Tree from Figure 1 in Evolution and Taxonomic Classification of Human Papillomavirus 16 (HPV16)-Related Variant Genomes: HPV31, HPV33, HPV35, HPV52, HPV58 and HPV67. Chen Z, Schiffman M, Herrero R, DeSalle R, Anastos K, et al. (2011) Evolution and Taxonomic Classification of Human Papillomavirus 16 (HPV16)-Related Variant Genomes: HPV31, HPV33, HPV35, HPV52, HPV58 and HPV67. PLoS ONE 6(5): e20183. doi: 10.1371/journal.pone.0020183
Graph from He F, Fromion V, Westerhoff HV. (Im)Perfect robustness and adaptation of metabolic networks subject to metabolic and gene-expression regulation: marrying control engineering with metabolic control analysis. BMC Syst Biol. 2013;7 131. doi:10.1186/1752-0509-7-131. PubMed PMID: 24261908; PubMed Central PMCID: PMC4222491.
Table from Table 1 Young GR, Mavrommatis B, Kassiotis G. Microarray analysis reveals global modulation of endogenous retroelement transcription by microbes. Retrovirology. 2014;11 59. doi:10.1186/1742-4690-11-59. PubMed PMID: 25063042; PubMed Central PMCID: PMC4222864.
Text from Laidlaw CT, Condon JM, Belk MC. Viability Costs of Reproduction and Behavioral Compensation in Western Mosquitofish (Gambusia affinis). PLoS One. 2014;9(11) e110524. doi:10.1371/journal.pone.0110524. PubMed PMID: 25365426; PubMed Central PMCID: PMC4217728.
Cell microscopy image from Pettinato G, Vanden Berg-Foels WS, Zhang N, Wen X. ROCK Inhibitor Is Not Required for Embryoid Body Formation from Singularized Human Embryonic Stem Cells. PLoS One. 2014;9(11) e100742. doi:10.1371/journal.pone.0100742. PubMed PMID: 25365581; PubMed Central PMCID: PMC4217711.
Supertrees:Lang JM, Darling AE, Eisen JA. Phylogeny of bacterial and archaeal genomes using conserved genes: supertrees and supermatrices. PLoS One. 2013;8(4) e62510. doi:10.1371/journal.pone.0062510. PubMed PMID: 23638103; PubMed Central PMCID: PMC3636077.
McDowell A, Nagy I, Magyari M, Barnard E, Patrick S. The opportunistic pathogen Propionibacterium acnes: insights into typing, human disease, clonal diversification and CAMP factor evolution. PLoS One. 2013;8(9) e70897. doi:10.1371/journal.pone.0070897. PubMed PMID: 24058439; PubMed Central PMCID: PMC3772855.
Chemistry:Diagram from Klejnstrup ML, Frandsen RJ, Holm DK, Nielsen MT, Mortensen UH, Larsen TO, Nielsen JB. Genetics of Polyketide Metabolism in Aspergillus nidulans. Metabolites. 2012;2(1) 100-133. doi:10.3390/metabo2010100. PubMed PMID: 24957370; PubMed Central PMCID: PMC3901194.
Methods text from Greshock, T. J., Grubbs, A. W., Jiao, P., Wicklow, D. T., Gloer, J. B., & Williams, R. M. (2008). Isolation, Structure Elucidation, and Biomimetic Total Synthesis of Versicolamide B, and the Isolation of Antipodal (−) Stephacidin A and (+) Notoamide B from Aspergillus versicolor NRRL ‐ ‐35600. Angewandte Chemie m frokInternational Edition, 47(19), 3573-3577.
Annotation:Stubben, C. J., & Challacombe, J. F. (2014). Mining locus tags in PubMed Central to improve microbial gene annotation. BMC bioinformatics, 15(1), 43.
Figure from Haeussler, M., Gerner, M., & Bergman, C. M. (2011). Annotating genes and genomes with DNA sequences extracted from biomedical articles. Bioinformatics, 27(7), 980-986.





























