Embed Size (px)
Citation preview

Tartalomgazdagítás
szövegbányászattal
Linked Open Data felhasználása
ajánlórendszerekben
Dr. Tikk Domonkos, CEO
@domonkostikk

Vázlat
• Ajánlórendszerek és motiváció
• Tartalomgazdagítás szükségessége
• Szemantikus háló alapú technológia
• Hol van szükség szövegbányászatra
Tartalomgazdagítás szövegbányászattal

Tartalomgazdagítás szövegbányászattal
Ajánlórendszerek és
motiváció

Ajánlórendszerek
• Kollaboratív filtering
felhasználók tartalmakkal való
interakciói alapján működik
o interakciók hasonlóság
o látens modellek közelsége
• Tartalom alapú szűrés
tartalmak leírói alapján
működik
o tartalmak hasonlósága
o felhasználó történetére vetítve
Tartalomgazdagítás szövegbányászattal

Kollaboratív filtering vs. tartalom alapú szűrés
+ pontosabb
+ doménfüggetlen
– indulásnál nem működik
– nehezen magyarázható
+ kevés adat esetén is működik
+ jól magyarázható
– doménfüggő
– pontatlanabb
– bezártság
Tartalomgazdagítás szövegbányászattal

Motiváció
• Hagyományos tartalom keresési és felfedezési módszerek nem
kielégítőek a mai tartalomrengetegben
Tartalomgazdagítás szövegbányászattal

Cél
• Műsorinformáció + videotéka információ és felhasználói viselkedés
alapján releváns tartalmak ajánlása
Tartalomgazdagítás szövegbányászattal

Tartalomgazdagítás szövegbányászattal
Tartalomgazdagítás
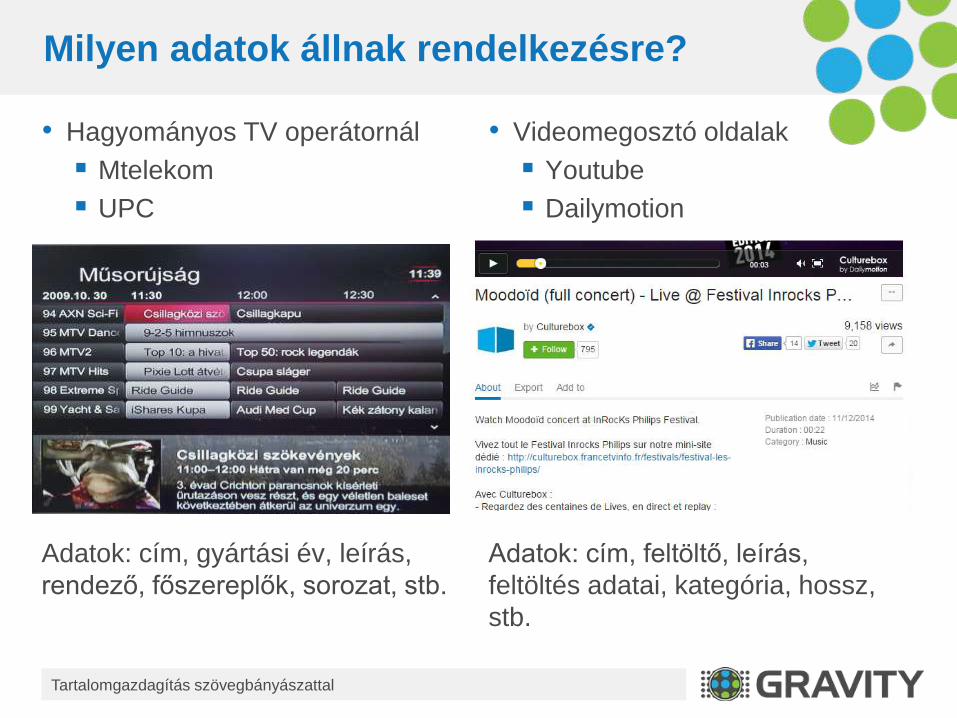
Milyen adatok állnak rendelkezésre?
• Hagyományos TV operátornál
Mtelekom
UPC
Adatok: cím, gyártási év, leírás,
rendező, főszereplők, sorozat, stb.
• Videomegosztó oldalak
Youtube
Dailymotion
Adatok: cím, feltöltő, leírás,
feltöltés adatai, kategória, hossz,
stb.
Tartalomgazdagítás szövegbányászattal

A metaadatok függenek az entitás típusától
• A TV programokban különböző entitások vannak jelen:
Film (The Shining)
Sorozat (Six Feet Under)
Rendező (Stanley Kubrick)
Foci csapat (Manchester United F.C.)
Különböző sportemberek (Federer – Djokovic)
Talk-show házigazda (Steven Colbert)
• Doménfüggő a fenti entitásokhoz tartozó metaadatok típusa:
film: kiadási év, cím, rendező(k), színész(ek) stb.
színész: név, születési hely és idő, stb.
TV sorozat: évad, epizód
Foci csapat: játékosok, székhely stb.
Tartalomgazdagítás szövegbányászattal

„One size fits all”?
Tartalomgazdagítás szövegbányászattal

„One size fits all” – miért nem működik
• A metaadatüzlet is 20/80-as elv szerint működik
Tartalom 20%-a „gazdag” metaadatban (TOP csatornák), 80% csak
a költségeket fedezik
Ajánlásnak 100%-nak kell lennie a teljes spektrumon!!!
• EPG és videotéka katalógusok más forrásból jönnek, de egységesen
kell kezelni őket
• Más megoldások kellenek a különböző szolgáltatástípusok esetén
IPTV és OTT megoldások
Videomegosztó oldalak (felhasználói tartalom)
Tartalomgazdagítás szövegbányászattal

Hol találhatók a metaadatok?
• A metaadatok különböző ún. Linked Open Data (LOD) adatbázisokban
vannak:
Filmek: Freebase, IMDB, LinkedMDB, TheTVDB
Sport: Freebase, DBPedia
Személyek: DBpedia, Freebase
Zene: Magnatune, Musicbrainz
Termékek: POD (Product Open Data)
Tartalomgazdagítás szövegbányászattal

Tartalomgazdagítás szövegbányászattal
Szemantikus háló alapú
technológia

Gravity Metaadat architektúra
• Fő tulajdonságok
TV-s és videotéka tartalmak egységek kezelése és összekapcsolása
Többnyelvű tartalomfeldolgozás
o Nyelvfüggő (cím, leírás)
o Nyelvfüggetlen (szereplő, műfaj, epizódszám)
Több adatbázis együttes kezelése
Skálázódás
Tartalomgazdagítás szövegbányászattal

Szemantikus háló
• Hogyan tárolhatóak illetve modellezhetők egységesen egy adott
entitáshoz tartozó tulajdonságok:
Resource Description Framework (RDF) az adatmodellezésre lett
kitalálva
Az RDF alany – állítás – tárgy hármasokban írja le a világot
subject: <http://rdf.freebase.com/ns/m.02vyptn>
predicate: <http://rdf.freebase.com/ns/film.film.written_by>
object: <http://rdf.freebase.com/ns/m.016hvl>
Tartalomgazdagítás szövegbányászattal

Apache Stanbol
• hagyományos CMS adatbázisok kiegészítése szemantikus
szolgáltatásokkal
Tartalomgazdagítás szövegbányászattal

LOD integrálása: EntityHub modullal
• Entityhub (/entityhub): entitások lokális kezelését teszi lehetővé,
amelyeket külső site-okról (LOD) is lehetnek importálva.
• Site Manager (/entityhub/sites): A SiteManager egységesített
csatlakozási felületet kínál a kezelt LOD-okhoz. Egy adott lekérdezés
az összes megkapcsolt LOD végponthoz továbbítja a kérést.
• Sites (/entityhub/site/{siteId}): egy konkrét LOD-hoz
(entitásszolgáltatóhoz) való integráció
ReferencedSite: Külső szolgáltató. Lokális caching és indexelést is
támogat, ezért nem kell mindig kapcsolódni a külső LOD-hoz, csak
ha az cache-ben nincs meg az adat.
ManagedSite: saját entitás menedzselés
Tartalomgazdagítás szövegbányászattal

EntityHub
Tartalomgazdagítás szövegbányászattal

Gravity Metaadat motor
• LOD integrálása: RDF mapping definiálása, ha nem létezik
• ReferencedSite definiálása minden integrálandó LOD-hoz
lokál cache létrehozása, ha a LOD támogatja ezt (teljes adatbázis
dump)
ahol nincs támogatva (csak egyedi lekérések), ott a ReferencedSite
cache-ét használjuk
• Névelemek azonosítására Stanbol Enhancer használata
Tartalomgazdagítás szövegbányászattal

Stanbol Enhancer
Tartalomgazdagítás szövegbányászattal

Enhancer használata
Tartalomgazdagítás szövegbányászattal

Adattárolás
• Nagy méretű adatbázisok (Freebase: 400M triplet)
• Skálázható háttéradatbázisként: Titan DB
Elosztott gráf adatbázis, ami RDF adatbázisként is használható a
GraphSail interfészen keresztül
HBase és Cassandra backendet támogat
• Jelenleg 2 csomópontból álló Hadoop klasztert használunk HBase-zel
• 50 konkurens folyamat kiszolgálására bőven elég
• Faunus gráfelemző motort használunk az adatok betöltésére
100M adat betöltése csak 3 óra
Tartalomgazdagítás szövegbányászattal

Tartalomgazdagítás szövegbányászattal
Hol használunk
szövegbányászatot?

Szövegbányászati feladatok
• Névelemek felismerése
• Névelemek egyértelműsítése
• Névelemek tulajdonságainak meghatározása
• Inkonzisztens adatok egyértelműsítése
Tartalomgazdagítás szövegbányászattal

Névelemek felismerése
• Szabad szövegben meghatározni, hogy melyek azok az entitások,
amelyek érdekesek lehetnek számunkra
Szótár alapú megközelítés
o Függ az adat minőségétől
oMelyik adatforrásokat akarjuk felhasználni?
Szekvenciatanulás alapú megközelítés
o HMM, CRF
oMennyire érzékeny a rendszer a hibára?
• Stanbol Enhancer
Tartalomgazdagítás szövegbányászattal

Névelemek egyértelműsítése
• Adott egy entitás, melyik LOD-entitásra lehet leképezni
• Melyik LOD-adatbázisban kell keresni?
Szolgáltató függő adatséma
nem egységes lekérdezés
o Apache Marmotta: Linked Data Client
o Standard RDF formátumra alakítja a LOD-ok egyedi válaszformátumát
o Ezután a Marmotta LOD cache-ét lehet használni
• Szükség van az adat szemantikájára
rendező, filmszínész, stb. – különben nagyon zajos lesz a
lekérdezés eredménye
Tartalomgazdagítás szövegbányászattal

Hasonlóság
• Mely tulajdonságok határoznak meg egyértelműen adott filmet?
Cím:
o Revolver (2005) vs Revolver (1991)
o The Bourne Identity (2002) vs The Bourne Identity (1988)
Cím + Kiadás Éve:
o The Bourne Identity (2002) vs A Bourne-rejtély (2002)
o Terminator (1984) vs Terminátor - A halálosztó (1984)
Kiadás Éve + Rendező:
o Elég jó, de még mindig nem feltétlenül egyértelmű
− Elírási hibák: Jonnie vs Johnny
− Különböző kiadási év:
− tényleges kiadási év (2007) vs vetítési év az adott országban (2008)
Tartalomgazdagítás szövegbányászattal

Hasonlóság
• Létrehozunk egy vektort: v = [kiadási év, rendező, vetítési idő]
v1 = [1999, ['Steven', 'Allan', 'Spielberg''], 120]
v2 = [1999, ['Stanley', 'Kubrick'], 118]
v3 = [1999, ['Steven', 'Spielberg'], 115]
• Két vektor tavolsága:
|| v_src – v_target ||_2
• A különbség két név között:
['Steven', 'Allan', 'Spielberg''] - ['Steven', 'Spielberg']
Egyszerű megoldás: | halmaz(A) \ halmaz(B) |
Komplexebb megoldás: ∑ min(Levenshtein távolság(a_i,b))
Tartalomgazdagítás szövegbányászattal

Névelemek tulajdonságainak meghatározása
• Ha már adott a LOD adatbázis és a lekérdezés, akkor SPARQL
lekérdezéssel megkaphatók az entitás tulajdonságai
• Simple Protocol and RDF Query Language (SPARQL)
• SQL-szerű RDF lekérdező nyelv
• A SPARQL lekérdezések triple mintákból, konjunkciókból,
diszjunkciókból és opcionális mintákból állnak
• A lekérdezés szétosztható több SPARQL végponthoz (szolgáltatások,
melyek fogadják SPARQL lekérdezéseket és eredményt adnak vissza),
kiszámolja, és összegyűjti az eredményt
Tartalomgazdagítás szövegbányászattal

SPARQL – 1. példa
• Woody Allennel egy filmben szereplő színészek:
Tartalomgazdagítás szövegbányászattal

SPARQL – 2. példa
• Olyan színészek, akik Stanley Kubrick és Steven Spielberg filmben is
szerepeltek
Tartalomgazdagítás szövegbányászattal

Köszönöm!
www.gravityrd.com
Legfrissebb hírek:
www.facebook.com/gravityrd
Dr. Tikk Domonkos
CEO
Tel: +36 30 5470780