Embed Size (px)
Citation preview

A Little Competition Never Hurt Anyone’s
Relevance AssessmentsYuan Jin1, Mark Carman1 and Lexing Xie2
1) Monash University 2) Australian National University
Image source: https://pixabay.com/en/competition-race-sport-run-1019774/

Motivation
• Everybody thinks that competition should help, but does it really?
• We performed a controlled study to determine the extent to which realtime feedback and competition improve the accuracy of crowdworkers performing relevance assessment.

research questions1. Does providing real-time feedback affect crowd
worker performance?
2. Does competition result from providing a leaderboard and improve performance?
3. Are financial rewards for good performance needed?
4. Are test questions needed and does competition still affect performance in that case??

A/B/n Testingstandard setup for online experiments • randomly assign users to treatment groups
System A
System B
A/B/n Testing

Integrating with CrowdFlower
Users choose job on crowdsourcing platform • Client side script calls A/B/n testing
server Worker free to drop out at any time
• Results in unequal assignment of users to groups

Experimental SettingsTask:
• assign judgments {not-relevant, relevant, highly-relevant}
• queries selected randomly from TREC 2011 crowdsourcing track “balanced dataset”
• workers shown 1 query & 5 docs per page • all workers see same query-doc pairs,
disjoint sets across experiments • workers paid 1c per judgment • up to 100 judgements (20 pages) collected
from each worker
image source: https://www.iconfinder.com/icons/269930/chemistry_config_configuration_design_experiment_formule_gear_graphic_lab_laboratory_science_system_tool_wrench_icon

Experimental Settings IIFeedback:
• accuracy values estimated from ground truth, (smoothed with Dirichlet prior)
• A/B/n server updates statistics shown to user with each page refresh
Analysis: • accuracy aggregated at the worker level • low volume workers (<50 responses) removed • pairwise (unequal variance) t-test with
Bonferroni correction
image source: https://www.iconfinder.com/icons/269930/chemistry_config_configuration_design_experiment_formule_gear_graphic_lab_laboratory_science_system_tool_wrench_icon

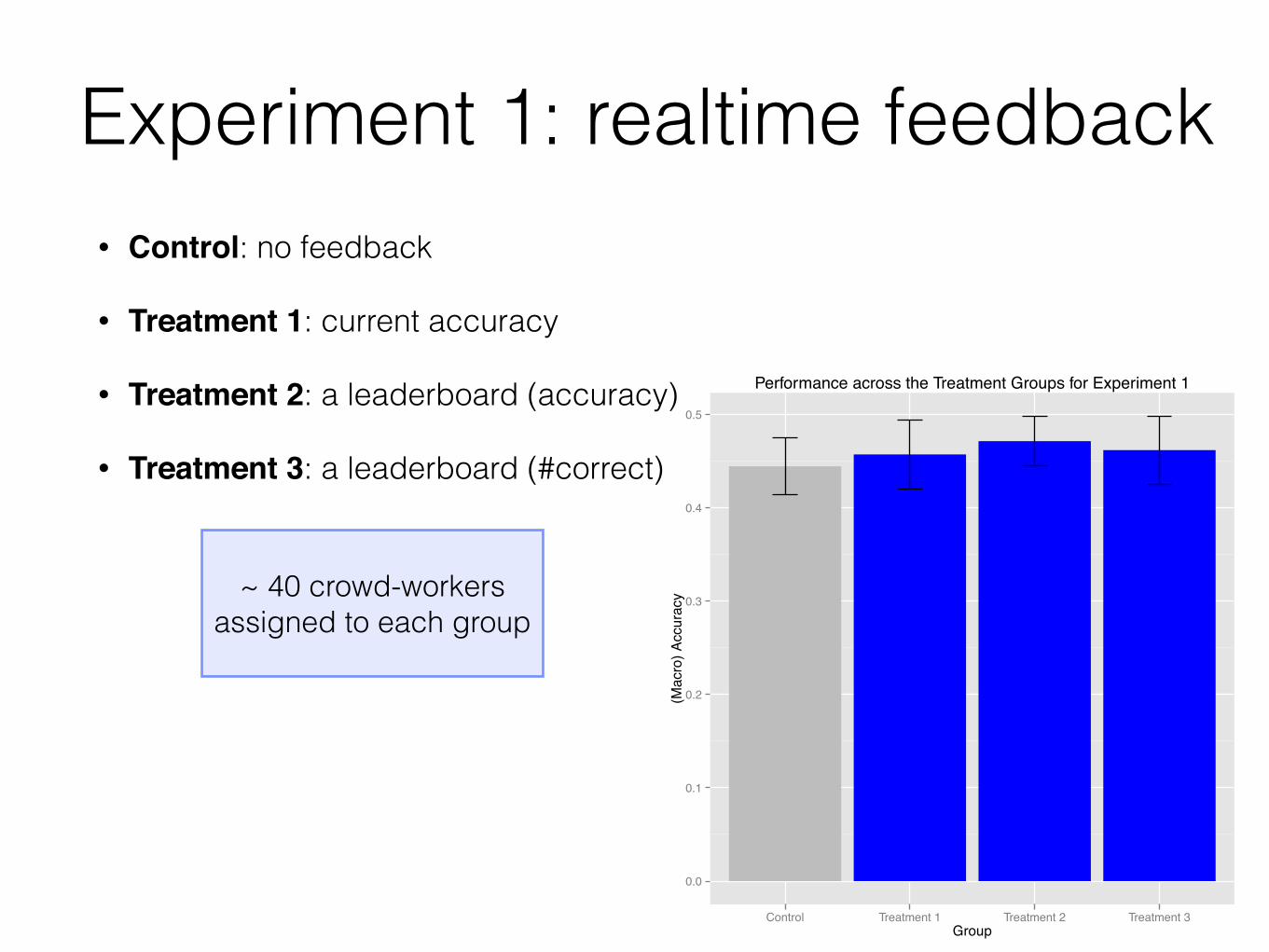
Experiment 1: realtime feedback• Control: no feedback
• Treatment 1: current accuracy
• Treatment 2: a leaderboard (based on accuracy)
• Treatment 3: a leaderboard (based on #correct responses)

Experiment 1: realtime feedback• Control: no feedback
• Treatment 1: current accuracy
• Treatment 2: a leaderboard (based on accuracy)
• Treatment 3: a leaderboard (based on #correct responses)
leaderboard • preserves worker anonymity • highlights change

0.0
0.1
0.2
0.3
0.4
0.5
Control Treatment 1 Treatment 2 Treatment 3Group
(Mac
ro) A
ccur
acy
Performance across the Treatment Groups for Experiment 1
Experiment 1: realtime feedback• Control: no feedback
• Treatment 1: current accuracy
• Treatment 2: a leaderboard (accuracy)
• Treatment 3: a leaderboard (#correct)
0.0
0.1
0.2
0.3
0.4
0.5
Control Treatment 1 Treatment 2 Treatment 3Group
(Mac
ro) A
ccur
acy
Performance across the Treatment Groups for Experiment 1
Experiment 1: realtime feedback• Control: no feedback
• Treatment 1: current accuracy
• Treatment 2: a leaderboard (accuracy)
• Treatment 3: a leaderboard (#correct)
~ 40 crowd-workers assigned to each group
0.0
0.1
0.2
0.3
0.4
0.5
Control Treatment 1 Treatment 2 Treatment 3Group
(Mac
ro) A
ccur
acy
Performance across the Treatment Groups for Experiment 1
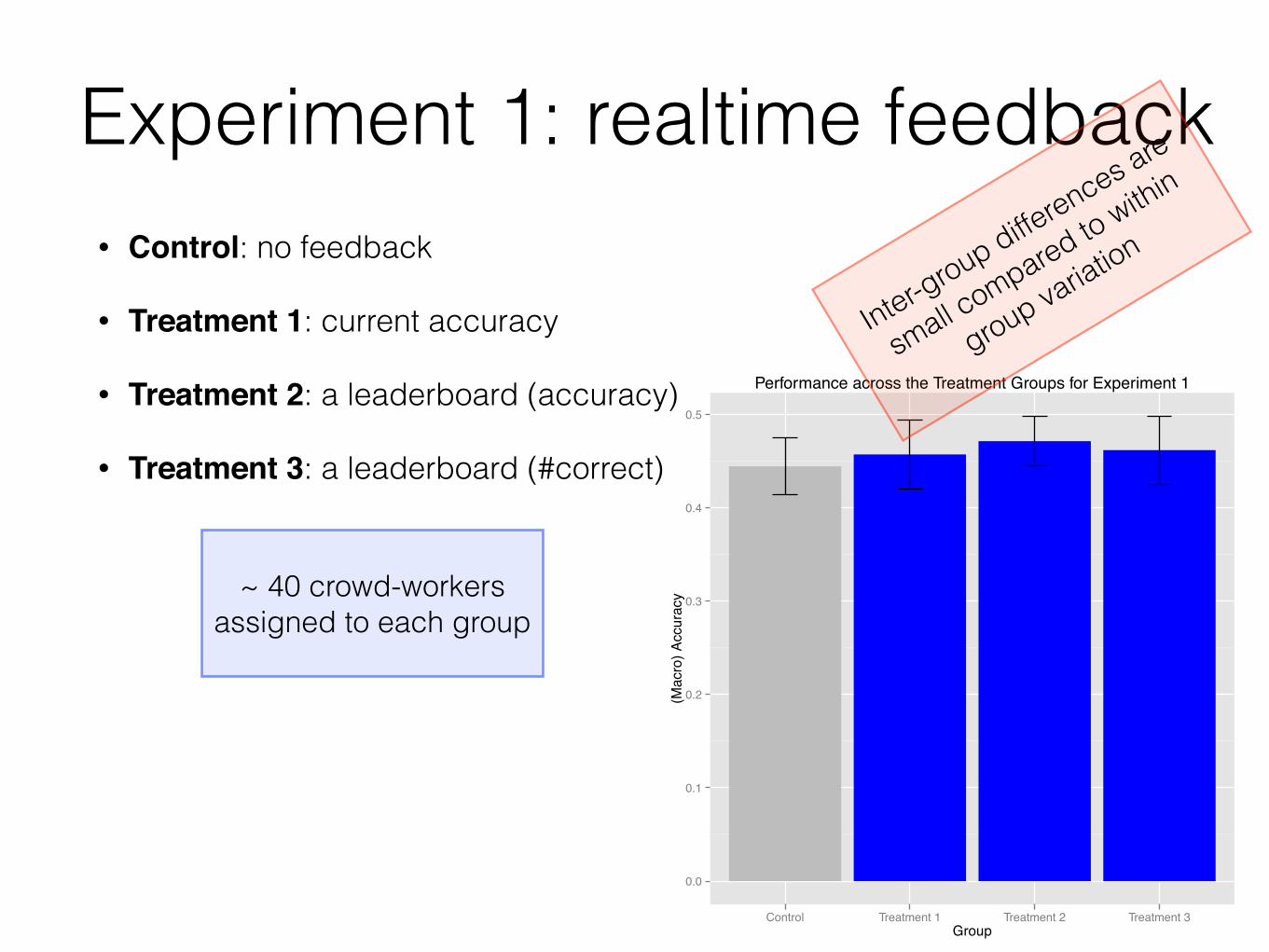
Experiment 1: realtime feedback• Control: no feedback
• Treatment 1: current accuracy
• Treatment 2: a leaderboard (accuracy)
• Treatment 3: a leaderboard (#correct)
Inter-group differences are
small compared to within
group variation
~ 40 crowd-workers assigned to each group

Experiment 2: adding a bonus
• Control 1: no feedback & no bonus
• Control 2: no feedback & bonus
• Treatment 1: leaderboard (accuracy) & bonus
• Treatment 2: leaderboard (#correct) & bonus
image source: https://pixabay.com/en/money-bag-brown-rope-sack-308815/

Experiment 2: adding a bonus
• Control 1: no feedback & no bonus
• Control 2: no feedback & bonus
• Treatment 1: leaderboard (accuracy) & bonus
• Treatment 2: leaderboard (#correct) & bonus
image source: https://pixabay.com/en/money-bag-brown-rope-sack-308815/
top 10 workers from each group paid bonus of $1 at
completion of task

0.0
0.1
0.2
0.3
0.4
0.5
Control 1 Control 2 Treatment 1 Treatment 2Group
(Mac
ro) A
ccur
acy
Performance across the Treatment Groups for Experiment 2
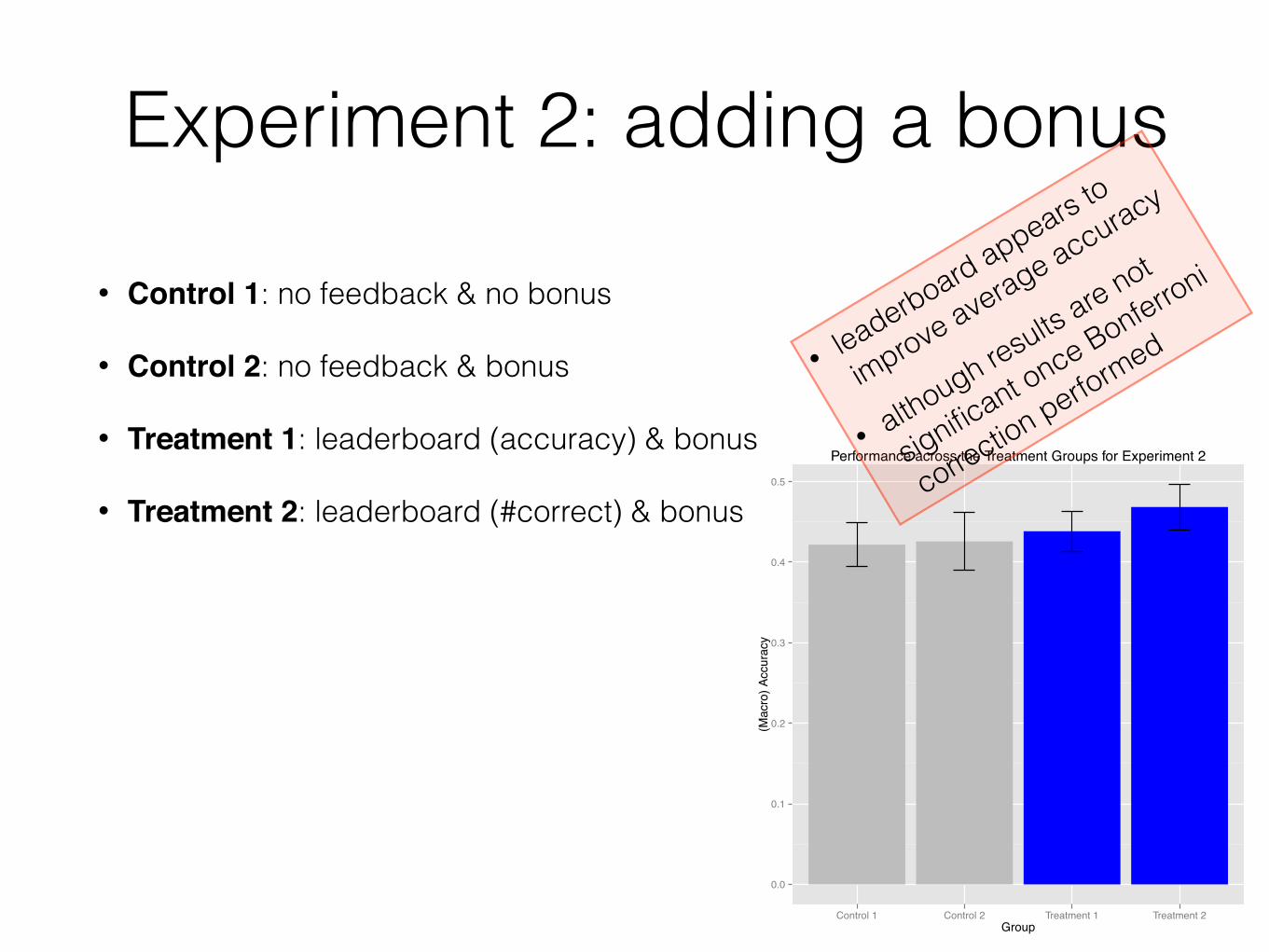
Experiment 2: adding a bonus
• Control 1: no feedback & no bonus
• Control 2: no feedback & bonus
• Treatment 1: leaderboard (accuracy) & bonus
• Treatment 2: leaderboard (#correct) & bonus
0.0
0.1
0.2
0.3
0.4
0.5
Control 1 Control 2 Treatment 1 Treatment 2Group
(Mac
ro) A
ccur
acy
Performance across the Treatment Groups for Experiment 2
Experiment 2: adding a bonus
• Control 1: no feedback & no bonus
• Control 2: no feedback & bonus
• Treatment 1: leaderboard (accuracy) & bonus
• Treatment 2: leaderboard (#correct) & bonus
• leaderboard appears to
improve average accuracy
• although results are not
significant once Bonferroni
correction performed

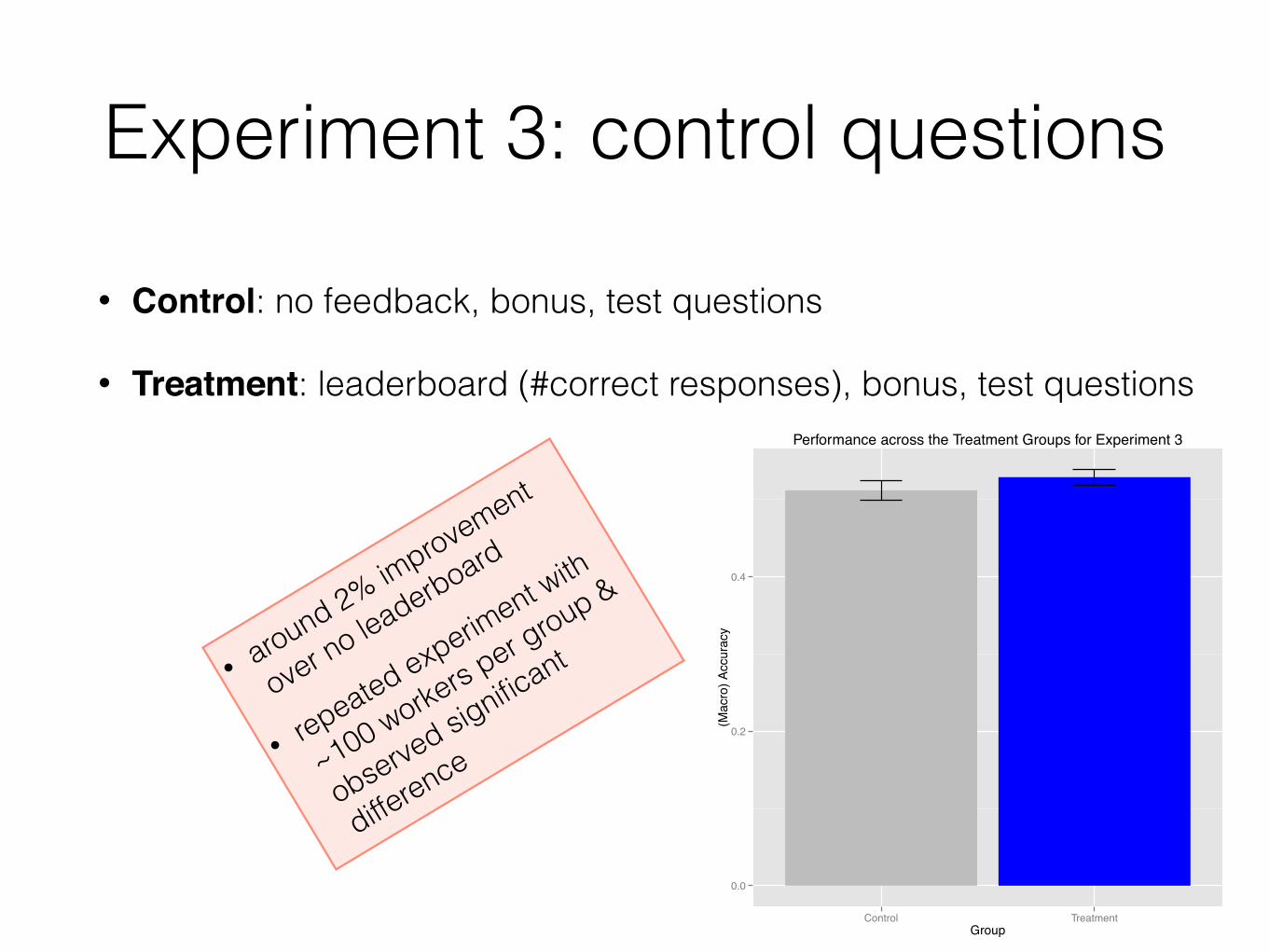
Experiment 3: control questions
• Control: no feedback, bonus, test questions
• Treatment: leaderboard (#correct responses), bonus, test questions
image source: http://gvarc.org/2014/03/09/gvarc-qtr2-VEsession.html

Experiment 3: control questions
• Control: no feedback, bonus, test questions
• Treatment: leaderboard (#correct responses), bonus, test questions
image source: http://gvarc.org/2014/03/09/gvarc-qtr2-VEsession.html
qualification quiz: • 5 test questions
task: • 20 pages • 1 test question & 4 non-test
questions randomly ordered
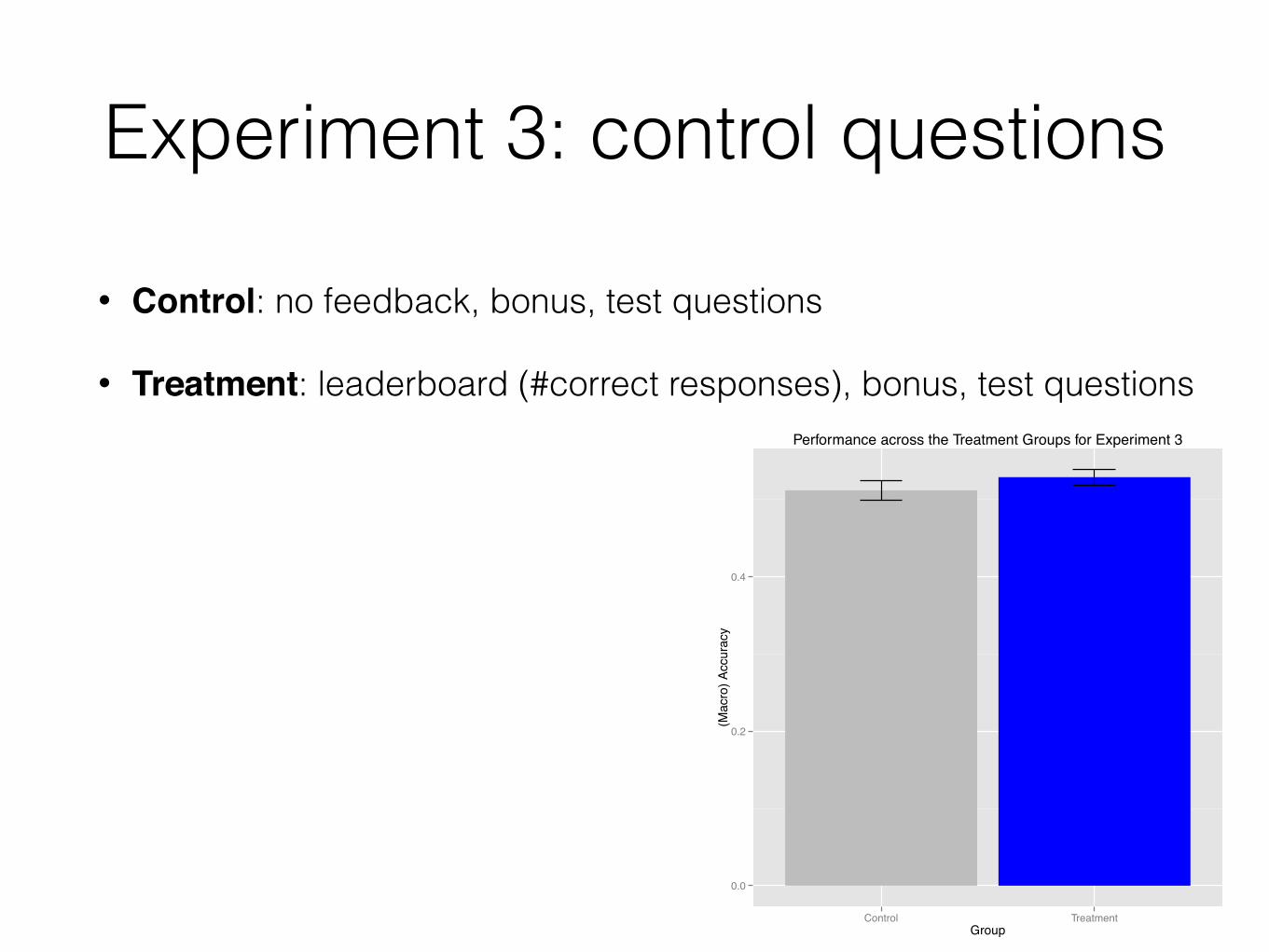
Experiment 3: control questions
• Control: no feedback, bonus, test questions
• Treatment: leaderboard (#correct responses), bonus, test questions
0.0
0.2
0.4
Control TreatmentGroup
(Mac
ro) A
ccur
acy
Performance across the Treatment Groups for Experiment 3
Experiment 3: control questions
• Control: no feedback, bonus, test questions
• Treatment: leaderboard (#correct responses), bonus, test questions
0.0
0.2
0.4
Control TreatmentGroup
(Mac
ro) A
ccur
acy
Performance across the Treatment Groups for Experiment 3
• around 2% improvement
over no leaderboard
• repeated experiment with
~100 workers per group &
observed significant
difference

Conclusions1. competition doesn’t hurt and can help a little:
• providing a bonus to motivate users probably necessary
• around 2% improvement in judging accuracy after test questions are included
2. providing realtime feedback requires additional programming effort
• whether it is economically worthwhile depends on the amount of judging required
3. positive unsolicited qualitative feedback
• one crowd-worker loved it





![[ 3 : ] hurt skirt](https://img.dokumen.tips/doc/110x75/56812eda550346895d9479e7/-3-hurt-skirt.jpg)














