Embed Size (px)
Citation preview

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 11
Genomics & Proteomics Based Genomics & Proteomics Based Drug DISCOVERYDrug DISCOVERY
Dr. Basavaraj K. Nanjwade Dr. Basavaraj K. Nanjwade M.Pharm., Ph. DM.Pharm., Ph. D
Associate ProfessorAssociate ProfessorDepartment of PharmaceuticsDepartment of Pharmaceutics
KLE UniversityKLE UniversityBELGAUM – 590010BELGAUM – 590010

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 22
GenomicsGenomics
Genetic scientist isolate individual Genetic scientist isolate individual genes and determine their chemical genes and determine their chemical composition, and ultimately to sequence composition, and ultimately to sequence entire genomes.entire genomes.
The sequencing of the human The sequencing of the human genome with the human genome projectgenome with the human genome project

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 33
Genome SequencingGenome Sequencing Gene number, exact locations, and functions Gene number, exact locations, and functions
Gene regulation Gene regulation
DNA sequence organization DNA sequence organization
Chromosomal structure and organization Chromosomal structure and organization
Noncoding DNA types, amount, distribution, information content, Noncoding DNA types, amount, distribution, information content, and functions and functions
Coordination of gene expression, protein synthesis, and post-Coordination of gene expression, protein synthesis, and post-translational events translational events
Interaction of proteins in complex molecular machines Interaction of proteins in complex molecular machines
Predicted vs experimentally determined gene function Predicted vs experimentally determined gene function

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 44
Genome SequencingGenome Sequencing Evolutionary conservation among organisms Evolutionary conservation among organisms
Protein conservation (structure and function) Protein conservation (structure and function)
Proteomes (total protein content and function) in organisms Proteomes (total protein content and function) in organisms
Correlation of SNPs (Single nucleotide polymorphisms ) with health and Correlation of SNPs (Single nucleotide polymorphisms ) with health and disease disease
Disease-susceptibility prediction based on gene sequence variation Disease-susceptibility prediction based on gene sequence variation
Genes involved in complex traits and multigene diseases Genes involved in complex traits and multigene diseases
Complex systems biology including microbial consortia useful for Complex systems biology including microbial consortia useful for environmental restoration environmental restoration
Developmental genetics, genomicsDevelopmental genetics, genomics

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 55
Genome SequencingGenome Sequencing
C = Cytosine, G = Guanine, A = Adenine and T = Thymine

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 66
SBI* can be used to examine:SBI* can be used to examine:• drug drug targetstargets (usually proteins) (usually proteins)• binding of binding of ligandsligands
↓ ↓
“ “rational” drug designrational” drug design
(benefits = saved time and (benefits = saved time and RsRsRsRsRsRs))
Drug DiscoveryDrug Discovery
* SBI-Structural Bioinformatics

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 77
What’s different?What’s different?
Drug discovery process begins Drug discovery process begins
with a with a diseasedisease (rather than a treatment) (rather than a treatment)
Use disease model to pinpoint relevant Use disease model to pinpoint relevant genetic/biological components (i.e. genetic/biological components (i.e. possible drug targets)possible drug targets)
ModernModern Drug Discovery Drug Discovery

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 88
Modern Drug DiscoveryModern Drug Discovery
diseasedisease →→ genetic/biological target genetic/biological target
↓ ↓
discovery of a “lead” moleculediscovery of a “lead” molecule- design assay to measure - design assay to measure
function of function of target target
- use assay to look for - use assay to look for modulators of modulators of target’s function target’s function
↓ ↓
high throughput screen (HTS)high throughput screen (HTS) - to identify “hits”- to identify “hits”

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 99
Modern Drug DiscoveryModern Drug Discovery
small molecule hitssmall molecule hits↓↓
manipulate structure to increase potency manipulate structure to increase potency ↓↓
*optimization of lead molecule into *optimization of lead molecule into candidate drug*candidate drug*
fulfillment of required pharmacological properties:fulfillment of required pharmacological properties:potency, absorption, bioavailability, metabolism, safetypotency, absorption, bioavailability, metabolism, safety
↓↓clinical trialsclinical trials

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 1010
Interesting facts...Interesting facts...
Over 90% of drugs Over 90% of drugs entering clinical entering clinical trials fail to make trials fail to make it to marketit to market
The average cost The average cost to bring a new to bring a new drug to market is drug to market is estimated at estimated at $770 $770 millionmillion

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 1111
Relating druggable targets Relating druggable targets to disease...to disease...
GPCR
STY kinases
Zinc peptidases
Serine proteases
PDE
Other 110 families
Cys proteases
Gated ion-channel Ion channels
Nuclear receptor
P450 enzymes
Analysis of Pharm Analysis of Pharm industry reveals:industry reveals:
• Over 400 proteins used Over 400 proteins used as drug targetsas drug targets
• Sequence analysis of Sequence analysis of these proteins shows these proteins shows that most targets fall that most targets fall within a few major gene within a few major gene families (GPCRs, families (GPCRs, kinases, proteases and kinases, proteases and peptidases) peptidases)

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 1212
Assessing Target DruggabilityAssessing Target Druggability
Once a target is defined for your Once a target is defined for your disease of interest, SBI can help disease of interest, SBI can help answer the question: answer the question:
Is this a “druggable” target?Is this a “druggable” target?
• Does it have sequence/domains similar to Does it have sequence/domains similar to known targets?known targets?
• Does the target have a site where a drug Does the target have a site where a drug can bind, and with appropriate affinity?can bind, and with appropriate affinity?

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 1313
Genome Annotation and AnalysisGenome Annotation and Analysis

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 1414
Impact of Structural BioinformaticsImpact of Structural Bioinformatics on Drug Discovery on Drug Discovery
. Speeds up key steps in . Speeds up key steps in DD process by combining DD process by combining aspects of bioinformatics, aspects of bioinformatics, structural biology, and structural biology, and structure-based drug structure-based drug designdesign Bio-
informatics
Structure-based Drug Design
Structural Biology

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 1515
human genome
polysaccharides
lipids nucleic acids proteins
Problems with toxicity, specificity, and difficulty in creating potent inhibitors eliminate the first 3 categories...

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 1616
human genome
polysaccharides
lipids nucleic acids proteins
proteins with binding site
““druggable genome”druggable genome” = subset of genes which = subset of genes which express proteins capable of binding small drug-like express proteins capable of binding small drug-like moleculesmolecules

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 1717
ProteomicsProteomics Proteomics studies networks of proteins by measuring, Proteomics studies networks of proteins by measuring,
among other things, protein expression. among other things, protein expression.
Protein activity is regulated by post-translational Protein activity is regulated by post-translational modification and degradation; these cannot yet be modification and degradation; these cannot yet be predicted from DNA sequence.predicted from DNA sequence.
Proteomics measures protein expression directly, not via Proteomics measures protein expression directly, not via gene expression, thus achieving better accuracy. gene expression, thus achieving better accuracy. Current work uses 2-dimensional polyacrylamide gel Current work uses 2-dimensional polyacrylamide gel electrophoresis (2D-PAGE) and mass spectrometry. electrophoresis (2D-PAGE) and mass spectrometry.
New separation and characterization technologies, such New separation and characterization technologies, such as protein microarrays and high-throughput as protein microarrays and high-throughput chromatography, are being developedchromatography, are being developed

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 1818
ProteomicsProteomics

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 1919
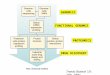
Process Flow Chart of ProteomicsProcess Flow Chart of Proteomics
(Image) analysis(Data massage, Evaluation)
Spot identification(Mass spectrometry)
Biomarkers(Principal compound analysis)
Two dimensional – gel electrophoresis

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 2020
Proteomics in Drug DiscoveryProteomics in Drug Discovery
As we have seen genomics has dramatically altered the As we have seen genomics has dramatically altered the way drug discovery is now being viewed. way drug discovery is now being viewed.
However, there may not be a good correlation between However, there may not be a good correlation between gene expression and protein expression as most disease gene expression and protein expression as most disease processes and treatments are manifest at the protein processes and treatments are manifest at the protein level. level.
It is believed that gene-based expression analysis alone It is believed that gene-based expression analysis alone will be totally inadequate for drug discovery.will be totally inadequate for drug discovery.

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 2121
Proteomics is Drug DiscoveryProteomics is Drug Discovery
Proteomics has unique and significant Proteomics has unique and significant advantages as an important complement advantages as an important complement to a genomics approach.to a genomics approach.
1.1. Target/marker identificationTarget/marker identification
2.2. Target validation/toxicologyTarget validation/toxicology

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 2222
Target/marker identificationTarget/marker identification
This application of proteomics provides a This application of proteomics provides a protein profile of a cell, tissue and/or bodily protein profile of a cell, tissue and/or bodily fluids that can be used to compare a fluids that can be used to compare a healthy with a diseased state for protein healthy with a diseased state for protein differences in the search for drugs or drug differences in the search for drugs or drug targets.targets.

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 2323
Target validation/toxicologyTarget validation/toxicology
Proteomics can be applied as an assay procedure for Proteomics can be applied as an assay procedure for the potential utility of drug candidates. the potential utility of drug candidates.
This can be achieved by a comparative analysis of This can be achieved by a comparative analysis of reference protein profiles from normal or diseased states reference protein profiles from normal or diseased states with profiles after drug treatment (Wang 1999). with profiles after drug treatment (Wang 1999).
Proteomics technology can also be integrated with Proteomics technology can also be integrated with combinatorial chemistry to evaluate comparative combinatorial chemistry to evaluate comparative structure-activity relationships of drug analogs.structure-activity relationships of drug analogs.

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 2424
Protein-Ligand DockingProtein-Ligand Docking
Starting orientation of the program with 2 water molecules as the “Protein” and “Ligand” (a useful setup for testing the application). The energy of the system is in J/mol.

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 2525
Protein-Ligand DockingProtein-Ligand Docking
Independent control of both molecules is allowed. The leftmost molecule is rotated using a trackball style rotation, while the second molecule remains fixed.

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 2626
Protein-Ligand DockingProtein-Ligand Docking
From the previous figure, the second molecule has been independently translated up and away from the first molecule. Molecules can be arbitrarily positioned and oriented in 3D

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 2727
Protein-Ligand DockingProtein-Ligand Docking
This is the same setup as the previous figure, except the viewpoint has been rotated, translated and zoomed to a different location. The energy of the system remains the same as the molecules are physically unmoved relative to each other

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 2828
Protein-Ligand DockingProtein-Ligand Docking
The two oxygen atoms are just overlapping and consequently the energy of the system takes on a large negative value indicating a VERY high energy (the energy well is reversed for the purpose of the program, so large positive values indicate a favourable conformation, and large negative values indicate unfavourable conformations

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 2929
Protein-Ligand DockingProtein-Ligand Docking
Here the atoms are at an optimum distance for the van der Waals Forces to hit the minimum of the well potential. However, the atoms are not aligned for any dipole-dipole interaction or hydrogen bonding

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 3030
Protein-Ligand DockingProtein-Ligand Docking
The energy of the system attains a maximum with the following orientation. This is the orientation that occurs between water molecules when ice forms. This puts the hydrogen bond in its optimum orientation, and this changes makes another order of magnitude difference in the energy of the system

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 3131
Structure being the key to function, determining a Structure being the key to function, determining a protein’s structure is a key step toward elucidating its protein’s structure is a key step toward elucidating its role.role.
The subfield of protein-ligand docking is useful in rational The subfield of protein-ligand docking is useful in rational drug design.drug design.
Laboratory prediction is time consuming and expensive, Laboratory prediction is time consuming and expensive, so researchers have been working on computerized so researchers have been working on computerized prediction for several decades.prediction for several decades.
Exact computational prediction is difficult but Exact computational prediction is difficult but sophisticated algorithms to find approximate solutions sophisticated algorithms to find approximate solutions continue to be developed.continue to be developed.
Protein-Ligand DockingProtein-Ligand Docking

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 3232
Critical Assessment of Methods of Protein Critical Assessment of Methods of Protein Structure PredictionStructure Prediction
Computational groups predict structures of Computational groups predict structures of proteins whose structures have been found in the proteins whose structures have been found in the laboratory before the latter results are released.laboratory before the latter results are released.
Tools are ClassifiedTools are Classified
1.1. Comparative modeling looks for amino acid similarity to Comparative modeling looks for amino acid similarity to proteins of known structure.proteins of known structure.
2.2. Fold recognition predicts folds in regions that do not Fold recognition predicts folds in regions that do not share amino acid similarity with known structuresshare amino acid similarity with known structures

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 3333
AdvantagesAdvantages More Powerful MedicinesMore Powerful Medicines
Better, Safer Drugs the First TimeBetter, Safer Drugs the First Time
More Accurate Methods of Determining Appropriate Drug More Accurate Methods of Determining Appropriate Drug DosagesDosages
Advanced Screening for DiseaseAdvanced Screening for Disease
Better VaccinesBetter Vaccines
Improvements in the Drug Discovery and Approval ProcessImprovements in the Drug Discovery and Approval Process
Decrease in the Overall Cost of Health CareDecrease in the Overall Cost of Health Care

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 3434
Disadvantages Disadvantages
Complexity of finding gene variations that Complexity of finding gene variations that affect drug responseaffect drug response
Limited drug alternativesLimited drug alternatives
Disincentives for drug companies to make Disincentives for drug companies to make multiple pharmacogenomic productsmultiple pharmacogenomic products
Educating healthcare providersEducating healthcare providers

20/03/200820/03/2008 Dept.of PharmaceuticsDept.of Pharmaceutics 3535
THANK YOUTHANK YOUE-mail: [email protected]: [email protected]