Embed Size (px)
Citation preview

Presented by-
Sujit Kumar Das
M.Tech 3rd sem,IT
Roll-021413 No-363202205
1
Token Classification In Bengali
Language By Using Bangla
TokenizerUnder the Supervision Of
Mr. Sourish Dhar
Asst. Professor,Dept of IT
Assam University

Contents…
2
Introduction
Literature Survey
Our Proposal
Future Works To Be Done
Conclusions
References

Introduction:
3
What is Token Classification?
Tokens classification means identification of each
tokens(words/terms) in a document and classify them
into some predefined categories.
Theses predefined categories can be name of a
person, symbols, punctuations, Abbreviations,
numbers, date etc.

Steps in Tokens Classification:
4
Tokenize the given input text.
Assign to each token the class (or tag) that it
belongs to.
For Example,Token Class
মাইকেল Name
৪৫ Number
খবর Word

Introduction:What Is Tokenization?
5
Tokenization is the process of breaking a stream of
text up into words, phrases, symbols and other
meaningful elements called tokens.
Token: It’s a sequence of character that can be treated as
a single
logical entity.
Typically Tokens are-Natural Languages Programming Languages
Words Identifiers
Numbers Keywords
Abbreviations Operators
Symbols Special symbols
Constants

Cont…What Is Tokenizer?
6
The job of a Tokenizer is to break up a stream of textinto tokens.
Why Tokenizer?
It does very crucial task in pre-processing anynatural language.
To handle semantic issues in the subsequent stagesin machine translation.
Produces a structural description on an inputsentence.
For language modeling, the distribution of input textinto tokens is compulsory[9].

Literature Survey:
7
A Tokenizer is a component of parser . Parsing
natural language text is more difficult than the
computer languages such as compiler and word
processor because the grammars for natural
languages are complex, ambiguous and infinity
number of vocabulary[8].
Natural language applications namely Information
Extraction, Machine Translation, and Speech
Recognition, need to have an accurate parser[8].
A tokenizer plays its significant part in a parser, by
identifying the group or collection of words, existing
as a single and complex word in a sentence. Later
on, it breaks up the complex word into its
constituents in their appropriate forms[2].

Cont…Related Works:
8
Some Existing standard tokenizers-
Standford Tokenizer for English Language[10].
Shallow Tokenizer for Bengali Language.
Vaakkriti Tokenizer for Sanskrit Language[2].
These Tokenizers was developed for some
particular languages only i.e., all Tokenizers doesn’t
work for all languages.

Cont…Standford Tokenizer:
9
Developed mainly for English Language and later
on for Arabic,Chinese and spanish languages also.
Java language was used for developing.
Online Interface:

Cont…Results after parsing:
10

Cont…Shallow Bangla Tokenizer:
11
The shallow parser gives the analysis of a sentence in
terms of-
Morphological Analysis.
POS Tagging.
Chunking.
Apart from the final output, intermediate output of
individual modules is also available.

Cont…
12
Online Interface:

Cont…
13
Result after submitting:

Cont…
14
Bengali Stemmers:
A Rule-Based Stemmer for Bengali Language by
Sandipan Sarkar,IBM and Sivaji
Bandhopadhay,Jadavpur University[12].
A light weight stemmer for Bengali and which was
use in spelling checker by Md. Zahurul Islam, Md.
Nizam Uddin and Mumit Khan,CRBLP,BRAC
University,Dhaka in 2007[13].
Yet Another Suffix Stripper, which uses a clustering
based approach based on string distance
measures and requires no linguistic knowledge by
P.Majumdar, Gobinda Kole,ISI Pabitra Mitra,IIT and
Kalyankumar Dutta,Jadavpur University in
2007[14].
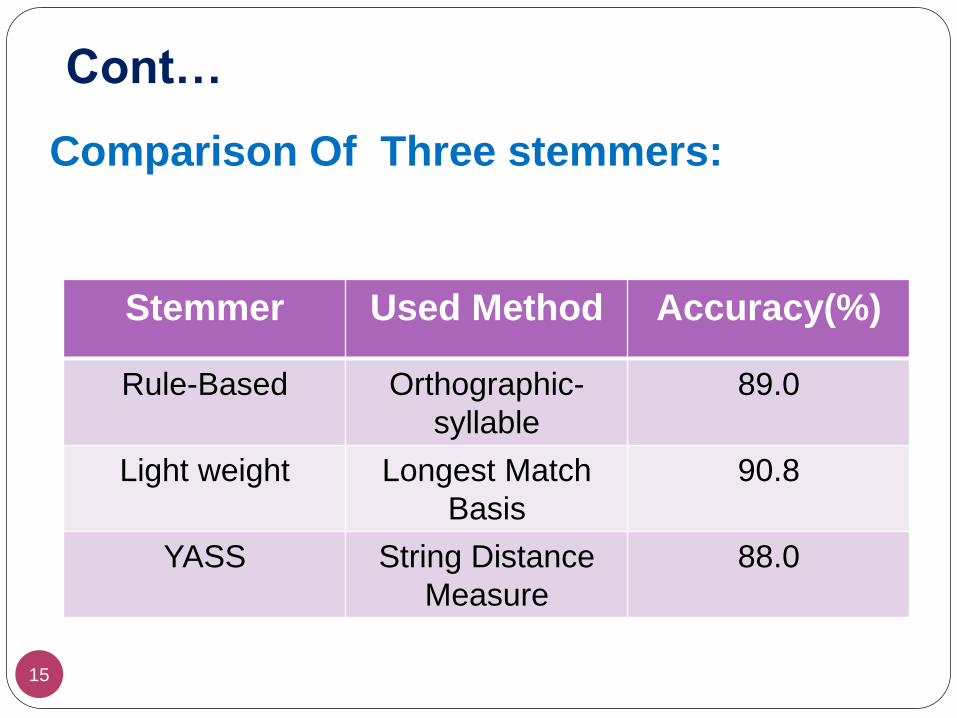
Cont…
15
Comparison Of Three stemmers:
Stemmer Used Method Accuracy(%)
Rule-Based Orthographic-
syllable
89.0
Light weight Longest Match
Basis
90.8
YASS String Distance
Measure
88.0

Cont…
16
POS Tagger:
Supervised POS Tagging: Has pre-tagged
Corpora used for training to learn information
about the tagset, word-tag frequencies, rule sets
etc[11].
e.g., N-Gram,Maximum Entropy Model(ME),Hidden
Markov Model(HMM) etc.
Unsupervised POS Tagging: Do not require a
pre-tagged corpora. they use advanced
computational methods to automatically induce
tagsets.
e.g.,Brill, Baum-Welch algorithm etc[11].

Cont…
17
Supervised POS Taggers Comparison:
Tagger Applied Method
Uni-Gram(N=1) Most likely approach
HMM One sentence at a
time. Formula-
P (word | tag) * P (tag | previous n
tags)
Bi-Gram(N=2) Same as Unigram but consider just
previous word tag

Cont…
18
UNI-GRAM BI-GRAM HMM
Sentences
Tokens Accuracy(%) Accuracy(%) Accuracy(%)
87 1002 28.6 28.6 39.3
304 4003 42.4 41.9 49.7
532 8026 48.1 47.9 53.6
677 10001 49.8 49.5 54.3
Bangla - SPSAL Corpus and Tagset with Test data: 400
sentences, 5225 tokens from the SPSAL test corpus[11].

Cont…Problem Domain:
19
Bangla is very rich in inflections, vibhakties (suffix)
and karakas, and often they are ambiguous also.
It is not easy to provide necessary semantic and
world knowledge that we humans often use while
we parse and understand various Bangla
sentences.
So, mainly due to grammatical vastness design of
bangla Toeknizer is not an easy task.

Cont…Bengali Grammar: POS
20

Cont…Bengali Grammar: Genders
21
There are four genders in Bengali grammar -
1.Pung lingo(masculine)
2.Stree lingo(feminine)
3.Ubha lingo(common)
4.Klib lingo(material)

Cont…Bengali Grammar: Numbers
22
Like English language Bengali has also two
numbers-
Singular: When we define a single object or
person its singular.
eg. a man, a girl etc.
When we consider more than one objects or
persons its plural numbers.
eg. Two man, mangoes etc.

Our Proposal:
23
We are going to develop such a system which canbe use for tokenize Bengali Text as well as thesystem will be able to solve the problem of TokensClassification.
Used Resources:Platform:
Windows 7
Front End:
ASP.Net 4.0
Back End:
Microsoft Excel Stylsheet
Language:
C#(C-sharp)
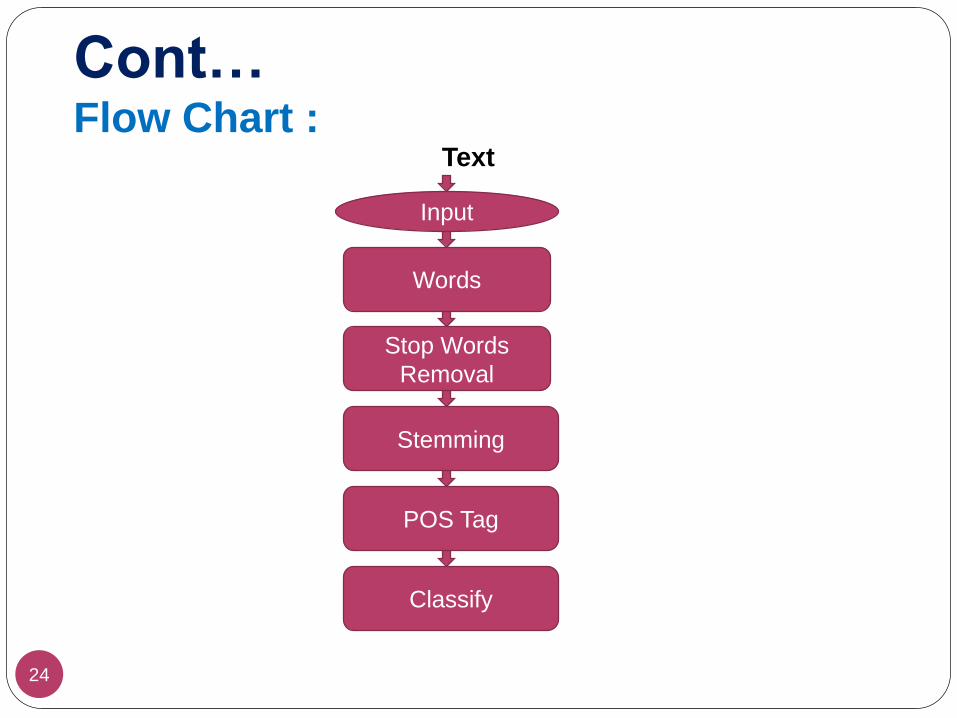
Cont…Flow Chart :
24
Input
Words
Stop Words
Removal
POS Tag
Classify
Text
Stemming

Cont…
25
Input:
Input will be a Bengali Text.
Words:(Done)
Text will be split into words after removing all non-
character and white spaces and then store them into
excel file.
Stop Words Removal(Done):
Stop words are the frequently occurring set of
words which do not aggregate relevant information to
the text classification task.
Root words:
After pulling out prefixes and suffixes from any
word thus the origin form of a word is known as root
word. This is also known as stemming.

Cont…
26
POS Tagging:
After finding the root word(stemming) eachelements will push into some particular classeswhich is previously generated. Thus, Parts-Of-Speech(POS) will be tagged with each wordhere.
Tokens Classification:
Tokens classification means after findingtokens from above tasks categories them intosome pre-defined classes.
Our consideration of classes will be mainlyTitle,Surname,Collocation,punctuation,Abbreviation,Number,
Date, Unknown and foreign word.

Current Status Of Our Work:
27 Snapshot1: system Interface

Cont…
28
Snapshot 2: After Loading Using Load
Button

Cont…
29 Snapshot 3: After getting tokens from
Text

Cont…
30Snapshot4: Tokens after removing Stop-
words

Cont…
31Snapshot3: After execution words are split and stored in excel file.

Future Works To Be Done:
32
Stemming i.e., Finding Root Words.
POS Tagging.
Classification

Conclusions:
33
Although in Language processing tokenizing is
a Fundamental task, But due to richness of Bengali
grammar and structure of Bengali text it is not an
easy task in case of Bengali Language. Again
Stemming is also a difficult task to do. To make an
effective bangla Tokenizer one must have a vast
knowledge on Bengali Grammar. So, We hope that
we will able to develop such a system which will
overcome difficulties and the limitations of existing
bangla Tokenizer and give efficient Tokens and
finally we will able to classify the tokens.

References:
34
[1] Wikipedia
[2] Aasish Pappu and Ratna Sanyal “Vaakkriti:
Sanskrit Tokenizer”Indian Institute of Information
Technology, Allahabad (U.P.), India.
[3] Firoj Alam, S. M. Murtoza Habib, Mumit Khan
“Text Normalization system for Bangla” Center for
research on Bangla Language Processing,
Department of Computer Science and Engineering,
BRAC University, Bangladesh.
[4] Goutam Kumar Saha, “Parsing Bengali Text - an
Intelligent Approach” Scientist-F, Centre for
Development of Advanced Computing, (CDAC),
Kolkata.

Cont…
35
[5] “Magic of ASP.Net with C#” by Kumar Sanjeeb and
Shibi Panikkar.
[6] www.C-sharpcorner.com
[7] “Overview of Stemming Algorithms” Ilia Smirnov
http://the-smirnovs.org/info/stemming.pdf.
[8] “Recognizing Bangla grammar using predictive
parser”, by K. M. Azharul Hasan, Al-Mahmud, Amit
Mondal, Amit Saha. Department of Computer Science
and Engineering (CSE) Khulna University of
Engineering and Technology (KUET) Khulna-9203,
Bangladesh.
[9] “Model for Sindhi Text Segmentation into Word
Tokens” J. A. MAHAR, H. SHAIKH*, G. Q. MEMON
Faculty of Engineering, Science and Technology,
Hamdard University, Karachi.

Cont…
36
[11] “COMPARISON OF DIFFERENT POS TAGGINGTECHNIQUES FOR SOME SOUTH ASIANLANGUAGES” by Fahim Muhammad Hasan, BRACUniversity,Dhaka,Bangladesh.
[12] “Design of a Rule-based Stemmer for NaturalLanguage Text in Bengali”by Sandipan Sarkar IBMIndia and Sivaji Bandyopadhyay Computer Scienceand Engineering Department Jadavpur University,Kolkata.
[13] “A Light Weight Stemmer for Bengali and Its Use inSpelling Checker” by Md. Zahurul Islam, Md. NizamUddin and Mumit Khan, Center for Research onBangla Language Processing, BRAC University,Dhaka, Bangladesh.
[14] “Yet Another Suffix Stripper” by PRASENJITMAJUMDER, MANDAR MITRA, SWAPAN K. PARUI,and GOBINDA KOLE Indian Statistical Institute.

37
Thank
You





























