Embed Size (px)
Citation preview

Sistemas Distribuidos

“Valora las alternativas y ventajas para la implantación
de un sistema distribuido (Compartir Recursos) ”

Estructuras de Sistemas Distribuidos
Sistema de Archivos Distribuidos
Gestión Distribuida de procesos
Sistema de Ejecución Distribuida
Introducción2.0
2.1
2.2
2.3
2.4

Una definición de sistema distribuido
Conjunto de computadores interconectados igual que un sistema
en red que comparten un estado ofreciendo una visión de
sistema único (SSI) igual que un sistema centralizado
Tipos de sistemas (evolución histórica)
sistemas por lotes: proceso diferido, secuencial
Sistemas centralizados de tiempo compartido: terminal
Sistemas de teleproceso: red telefónica
Sistemas personales: estaciones de trabajo, PCs
Sistemas en red: cliente/servidor, protocolos (TCP/IP)
Sistemas distribuidos: transparencia (GUI)
“A distributed system is a collection of independent computers that appears to
its users as a single coherent system”

A distributed system organized as middleware. The middleware layer extends over
multiple machines, and offers each application the same interface.
Un sistema Distribuido es software Middleware

Ventajas del Sistema distribuido con respecto a:
• Sistema centralizado
• Bajo coste: puede estar compuesto de PCs estándar
• Escalabilidad: consecuencia de su modularidad
• Flexibilidad: reutilización de máquinas “viejas”
• Disponibilidad: mediante replicación de recursos
• Ofrecen la posibilidad de paralelismo
• Permiten acceder a recursos remotos
• Sistema en red
• Uso más eficiente de los recursos (migración)
• Acceso transparente a los recursos

Desventajas respecto a un sistema centralizado
• Un sistema centralizado del mismo coste es más eficiente que cada uno de los
componentes del sistema distribuido.
• Si la distribución de recursos es inadecuada algunos recursos pueden estar
desbordados mientras otros están libres
• Mantener la consistencia puede ser muy “costoso” en el sistema distribuido.
• La red de interconexión es una fuente de problemas
• La gestión de la seguridad es más compleja

2.1 Estructuras de Sistemas
Distribuidos

2.1.1 Sistemas operativos de red
2.1.2 Sistemas operativos distribuidos
2.1.3 Servicios Remotos
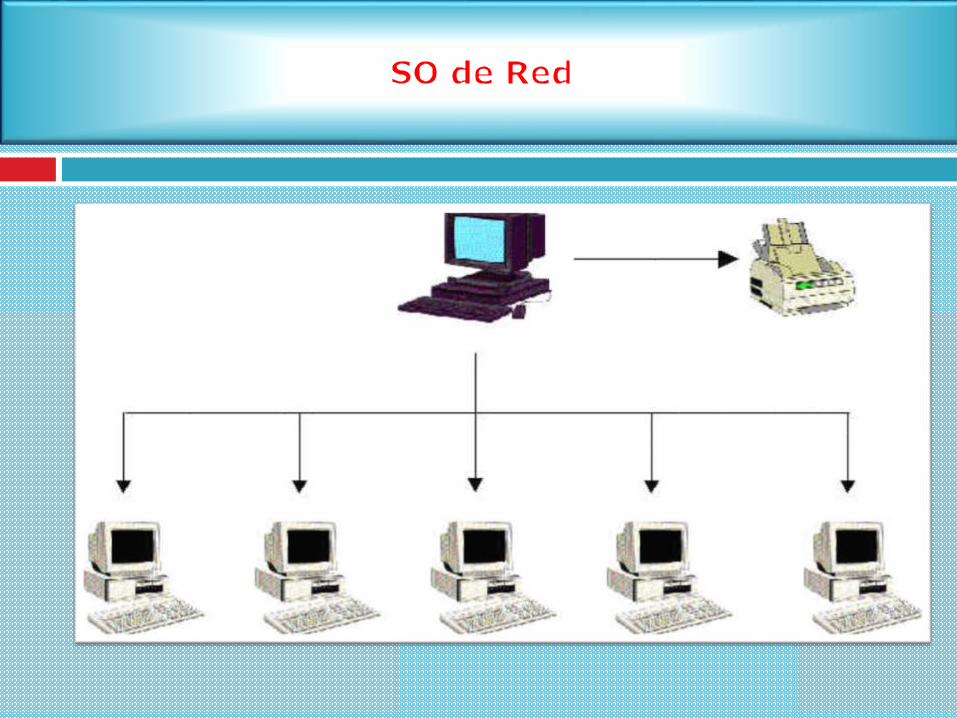
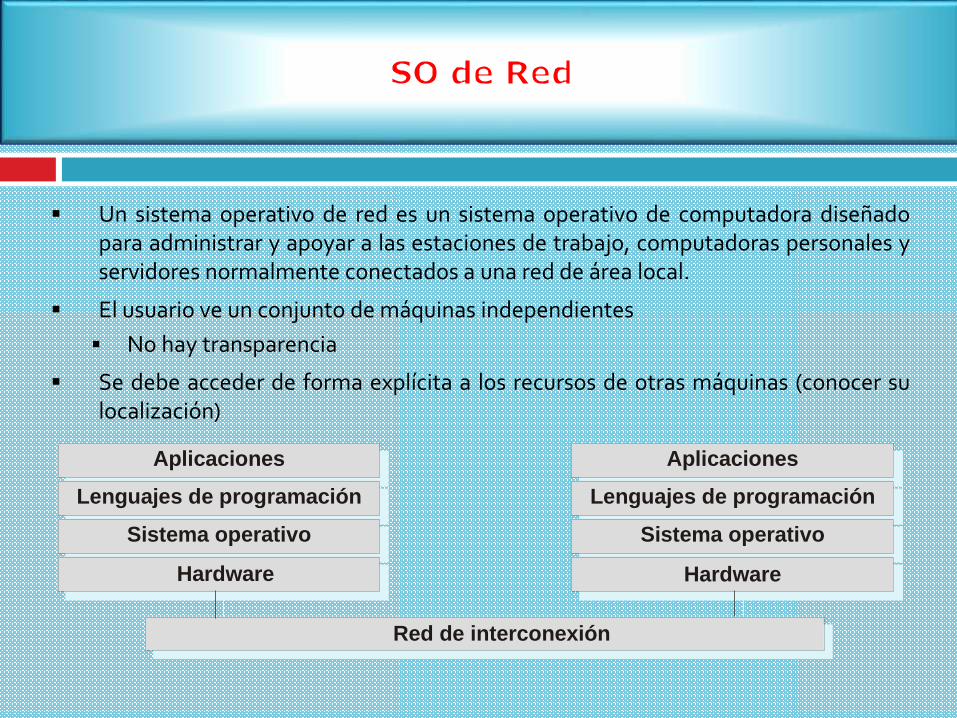
Un sistema operativo de red es un sistema operativo de computadora diseñadopara administrar y apoyar a las estaciones de trabajo, computadoras personales yservidores normalmente conectados a una red de área local.
El usuario ve un conjunto de máquinas independientes
No hay transparencia
Se debe acceder de forma explícita a los recursos de otras máquinas (conocer sulocalización)
Sistema operativo
Lenguajes de programación
Aplicaciones
Red de interconexión
Hardware
Sistema operativo
Lenguajes de programación
Aplicaciones
Hardware

Factores que empezaron con el desarrollo e implementación de los sistemas
operativos de red para:
Redes de área local. (LAN)
Redes de área amplia. (WAN)
Cada computadora tiene su sistema operativo privado.
La necesidad de compartir recursos.
Cada usuario normalmente trabaja en su propia computadora o en una
computadora designada; usando una computadora diferente invariablemente
requiere algún tipo de "login" remoto.
El deseo de mejorar el desempeño de las computadoras.

NetWare
Este sistema se diseñó con la finalidad de que lo usarán grandes compañías
que deseaban sustituir sus enormes máquinas conocidas como mainframe
por una red de PCs que resultara más económica y fácil de manejar.
UNIX
Los sistemas UNIX satisfacen necesidades de los programadores que crean
software y de los administradores que deben controlar las labores de
desarrollo de programas.
Windows NT
Las letras NT significan Nueva Tecnología. Fue diseñado para uso de
compañías grandes, por lo tanto realiza muy bien algunas tareas tales como
la potección por contraseñas.
IBM OS/2
LAN
SERVER
El Server de OS/2 opera a 32 bits y trabaja en conjunción con el Sistema
Operativo multitarea OS/2. El LAN Server se encuentra disponible en
versión para principiantes (Entry), es una solución de bajo costo y permite el
uso de un servidor no dedicado.
Linux
Linux es un sistema operativo para computadoras personales basadas en
Intel.

Los sistemas operativos realizan muchas funciones, como:
Planificar la distribución entre los usuarios.
Evitar que los usuarios se interfieran.
Proporcionar la interfaz con el usuario.
Permitir que los usuarios compartan entre sí el hardware - datos.
Administración de recursos compartidos
Facilitar la entrada y salida.
Recuperarse de los errores.
Organizar los datos para lograr un acceso rápido y seguro.

El sistema de archivos de un sistema operativo es el administrador
de ficheros.
Ofrece funciones para compartir información, mantenerla privada,
obtener acceso a ella, respaldarla, recuperarla, hacerla independiente
del dispositivo y cifrarla.
El acceso a los archivos se logra mediante funciones de los sistemas
operativos llamadas métodos de acceso.

Las estrategias de administración del almacenamiento buscan obtener el
mejor aprovechamiento y desempeño posibles del recurso de
almacenamiento principal.
Están dirigidas a la obtención del mejor uso posible del recurso del
almacenamiento principal .
Se dividen en las siguientes categorías:
Estrategias de: búsqueda por demanda o de búsqueda anticipada.
Estrategias de colocación.
Estrategias de reposición.

El administrador de dispositivos se encarga de las comunicaciones
entre las aplicaciones y los dispositivos.
Los dispositivos son componentes de hardware como unidades de
disco, impresoras y puertos de comunicación capaces de enviar
información al sistema operativo o recibir información de él. El
administrador de dispositivos se comunica con los manejadores de
dispositivos.

2.1.1 Sistemas operativos en Red
2.1.2 Sistemas operativos distribuidos
2.1.3 Servicios Remotos
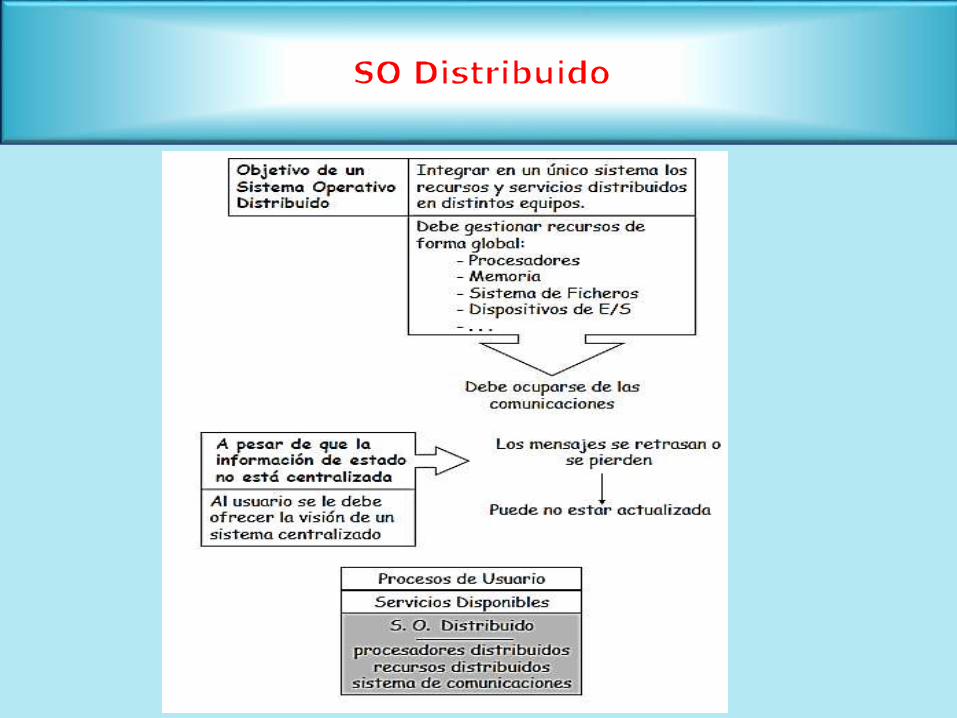


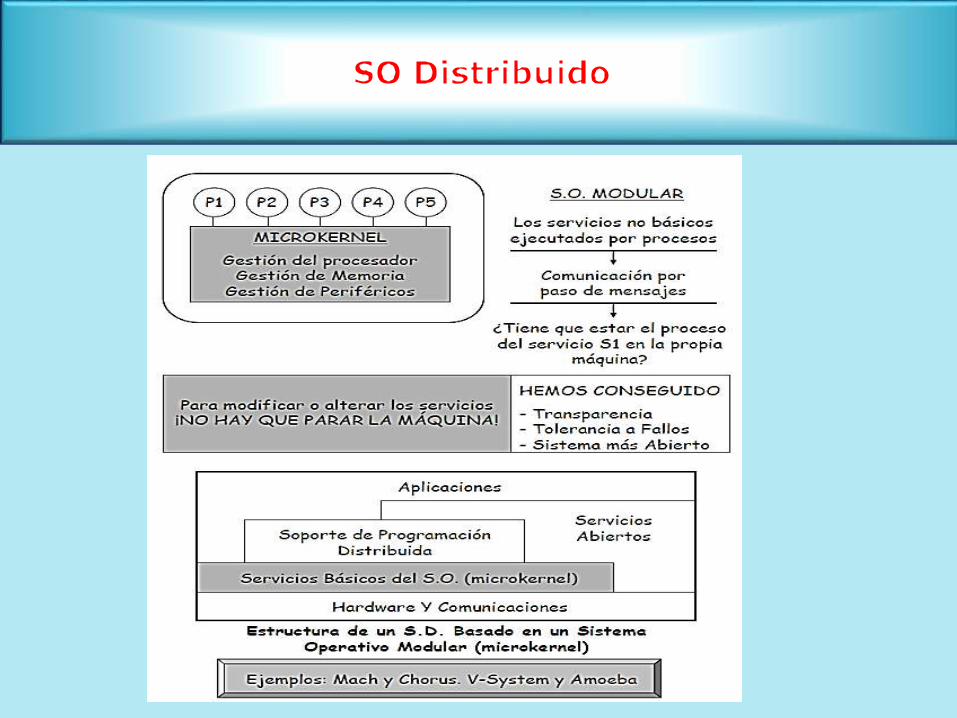
Visión de sistema único (Single System Image)
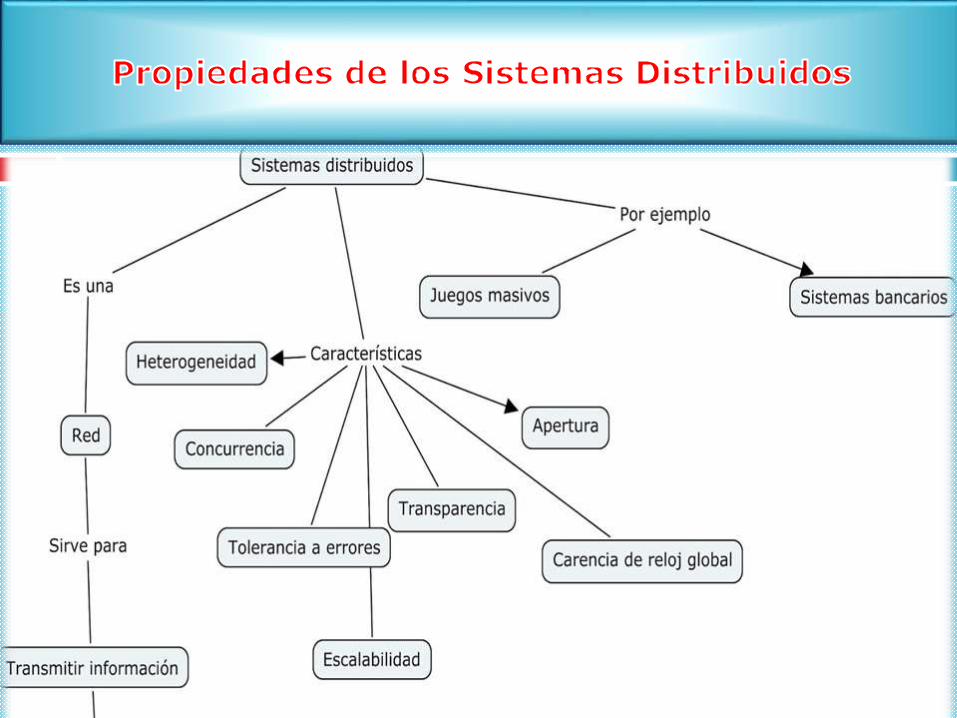
Propiedades deseables:
Transparencia
Fiabilidad y tolerancia a fallos
Escalabilidad
Consistencia

Consistencia
Problemas relacionados con la replicación
La red de interconexión es una nueva fuente de fallos
La seguridad del sistema es más vulnerable
Problemas para mantener la consistencia
Distribución física: varias copias, cada una con su estado
Errores y/o retardos en las comunicaciones
Ausencia de reloj global: ¿cómo ordenar eventos?
Para un rendimiento aceptable: relajar consistencia

Transparencia
Es la ocultación al usuario que los componentes de este sistema distribuido están separados.
El usuario percibirá que el sistema es un único sistema y no varios compones separados.
Existen ocho formas de transparencia, las que más consideración tienen en un sistema
distribuido son la transparencia a nivel de acceso y la transparencia a nivel de localización.
De acceso: no hay preocupación de la distribución de los archivos. Los programas deben
acceder de igual forma archivos locales y remotos.
De localización: Los archivos deben poder cambiarse sin que cambie el nombre.

Fiabilidad
Capacidad para realizar correctamente y en todo momento las funciones
para las que se ha diseñado
Disponibilidad
• Fracción de tiempo que el sistema está operativo (%)
Parámetros: MTBF (Mean Time Between Failures).
Tolerancia a fallos
• Capacidad para seguir operando correctamente ante el fallo de alguno de
sus componentes.
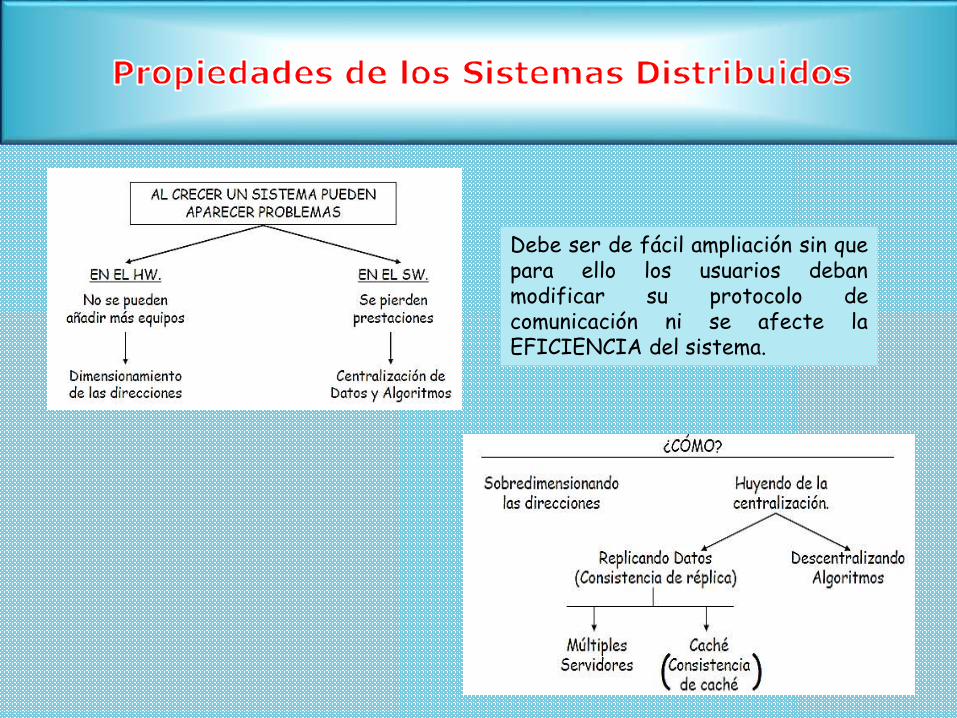
Debe ser de fácil ampliación sin quepara ello los usuarios debanmodificar su protocolo decomunicación ni se afecte laEFICIENCIA del sistema.
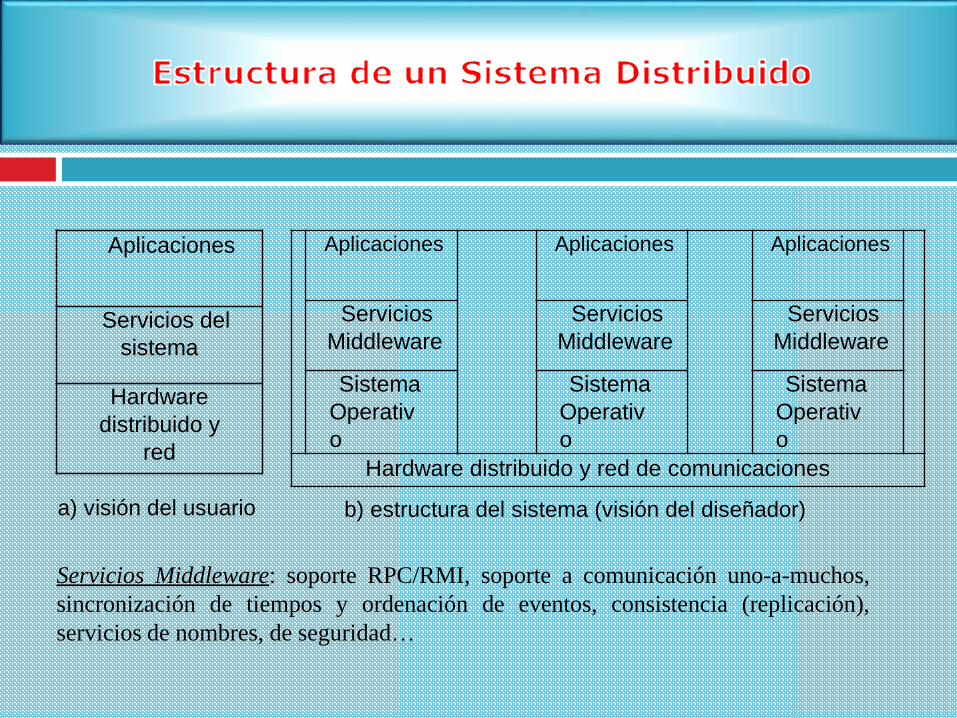
a) visión del usuario b) estructura del sistema (visión del diseñador)
Aplicaciones Aplicaciones Aplicaciones
Servicios
Middleware
Servicios
Middleware
Servicios
Middleware
Sistema
Operativ
o
Sistema
Operativ
o
Sistema
Operativ
o
Hardware distribuido y red de comunicaciones
Aplicaciones
Servicios del
sistema
Hardware
distribuido y
red
Servicios Middleware: soporte RPC/RMI, soporte a comunicación uno-a-muchos,
sincronización de tiempos y ordenación de eventos, consistencia (replicación),
servicios de nombres, de seguridad…

Se comporta como un SO único (visión única)
Distribución con transparencia
Se construyen normalmente como micro núcleos que ofrecen servicios básicos de
comunicación
Todos los computadores deben ejecutar el mismo Sistema Operativo Distribuido
Ejemplos : Cluster, Grid, etc.
Sistema operativo distribuido
Lenguajes de programación
Aplicaciones
Red de interconexión
Hardware Hardware

2.1.1 Sistemas operativos en Red
2.1.2 Sistemas operativos Distribuidos
2.1.3 Servicios Remotos

Un acceso remoto es poder acceder desde una computadora a un recurso
ubicado físicamente en otra computadora que se encuentra geográficamente
en otro lugar, a través de una red local o externa (como Internet).
En caso de que un usuario solicita el acceso a un archivo remoto:
Se localiza mediante un esquema de nominación apropiada el servidor
que contiene el archivo
Se debe efectuar la transferencia de datos para satisfacer la solicitud de
acceso remoto del usuario.
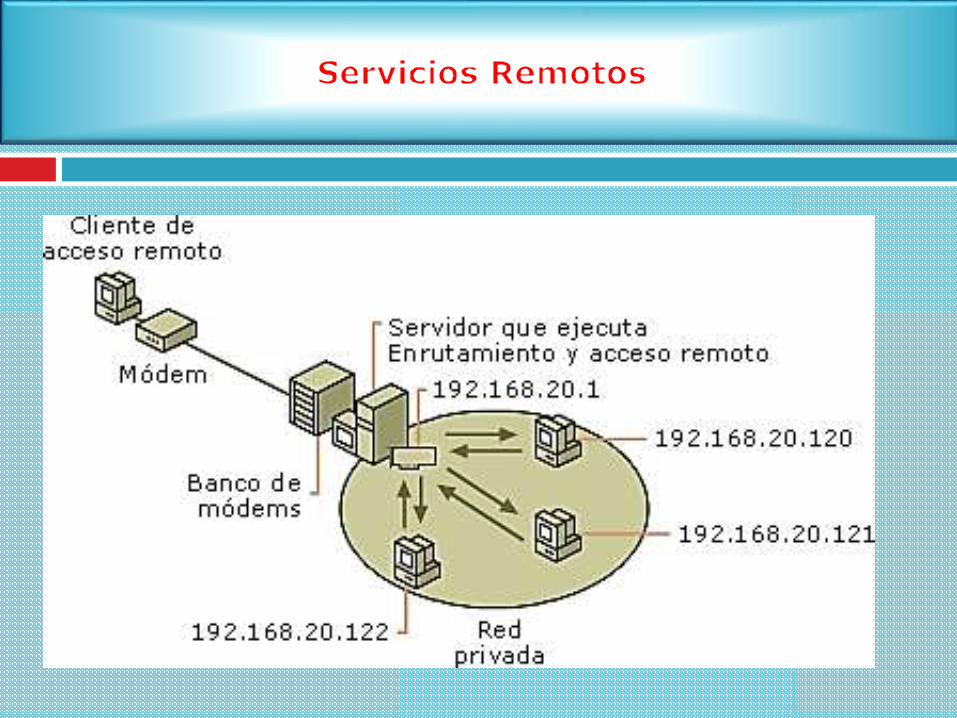
Una de las formas más comunes de servicio remoto RPC, fue diseñado como una
forma de abstraer el mecanismo de llamadas a procedimientos para usarse entre
sistemas con conexiones de red.
Llamada a procedimiento remoto es un protocolo que un programa puede utilizar para
solicitar un servicio de un programa ubicado en otro ordenador en una red sin tener
que comprender detalles de la red. RPC utiliza el modelo cliente / servidor.
El programa solicitante es un cliente y el programa de prestación de servicios es el
servidor. Al igual que una llamada a procedimiento ordinario o local, un RPC es una
operación que requiere el programa síncrono solicitando ser suspendido hasta que se
devuelven los resultados del procedimiento remoto. Sin embargo, el uso de procesos
ligeros o de hilos que comparten el mismo espacio de direcciones permite a varios PCs
que se ejecutan simultáneamente.

2.2 Sistema de Archivos Distribuido
servicio de
archivos
servicio
de
directorio
s
Un sistema de archivos distribuidos, (DFS), es una implementación distribuida del
clásico modelo de tiempo compartido de un sistema de archivos, donde varios
usuarios comparten archivos y almacenan recursos.
Sistema Distribuido: colección de máquinas interconectadaspor una red de comunicación.
Recursos locales: recursos con los que cuenta la máquina
Recursos remotos: el resto de las máquina y sus recursos
Máquina: puede ser una estación o un mainframe
Servicio: software ejecutándose en una o más máquinas queproporcionan un tipo particular de función
Servidor: software de servicio en una sola máquina Unservidor es un proceso que implementa servicios
Cliente: proceso que puede invocar un servicio a través deun conjunto de operaciones que forman su interfaz de cliente
PUNTOS
CLAVES

Las maquinas clientes no tiene en general acceso a los bloques de almacenamiento de forma
directa si no que pueden acceder a los datos a través de la red por medio de algún protocolo
de red.
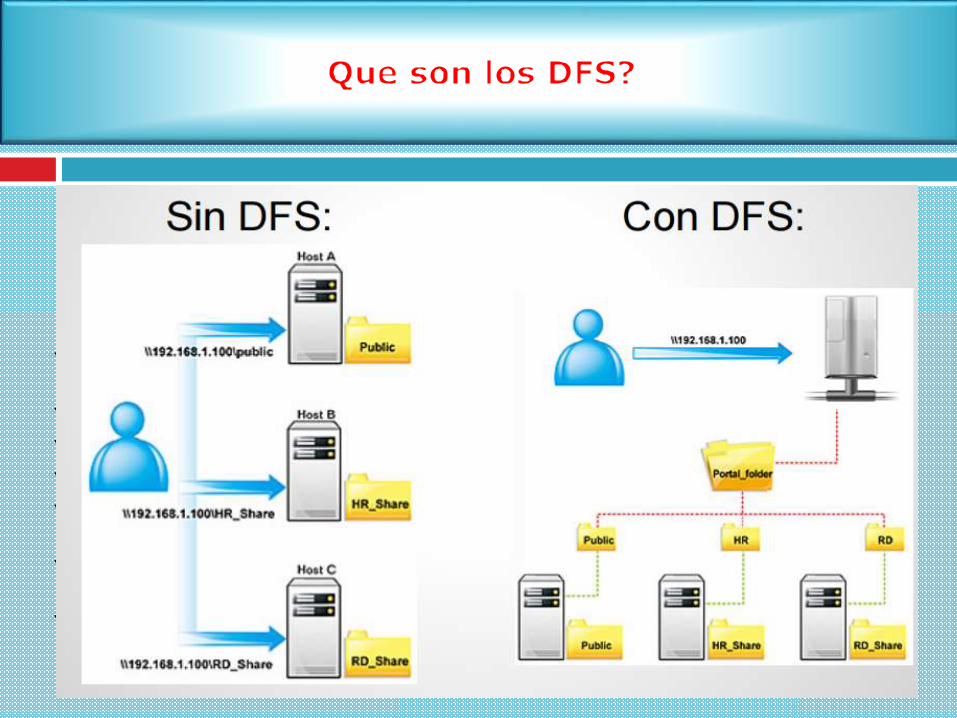
Los sistemas de archivos distribuidos almacena archivos en una o más maquinas
denominadas servidores y los hace accesibles a otros maquinas denominadas clientes, donde
se manipulan como si fueran locales.
Es soportar la misma clase de comportamiento cuando los archivos están dispersos
físicamente entre los diversos sitios de un sistema distribuido
Se caracterizan por:
La utilización efectiva de la memoria caché en el cliente para conseguir iguales prestacioneso mejores que las de los sistemas de archivos locales
El mantenimiento de la consistencia entre múltiples copias de archivos en las cachés de losclientes cuando son actualizadas, la recuperación después de un fallo en el servidor o en elcliente,
Un alto rendimiento en la lectura y escritura de archivos de todos los tamaños.
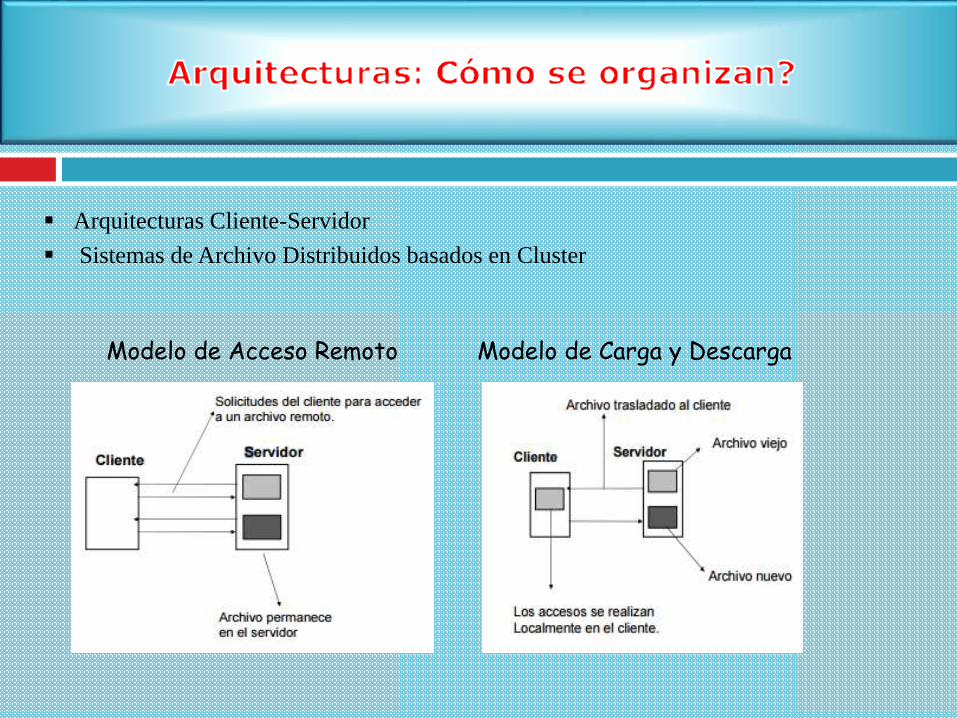
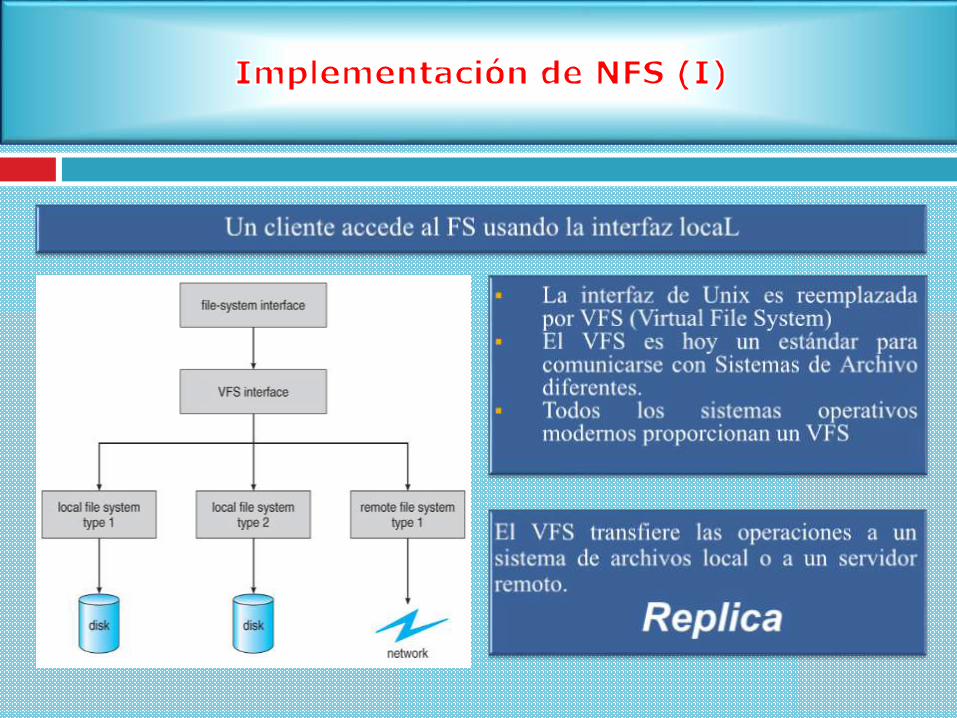
Arquitecturas Cliente-Servidor
Sistemas de Archivo Distribuidos basados en Cluster
Modelo de Acceso Remoto Modelo de Carga y Descarga
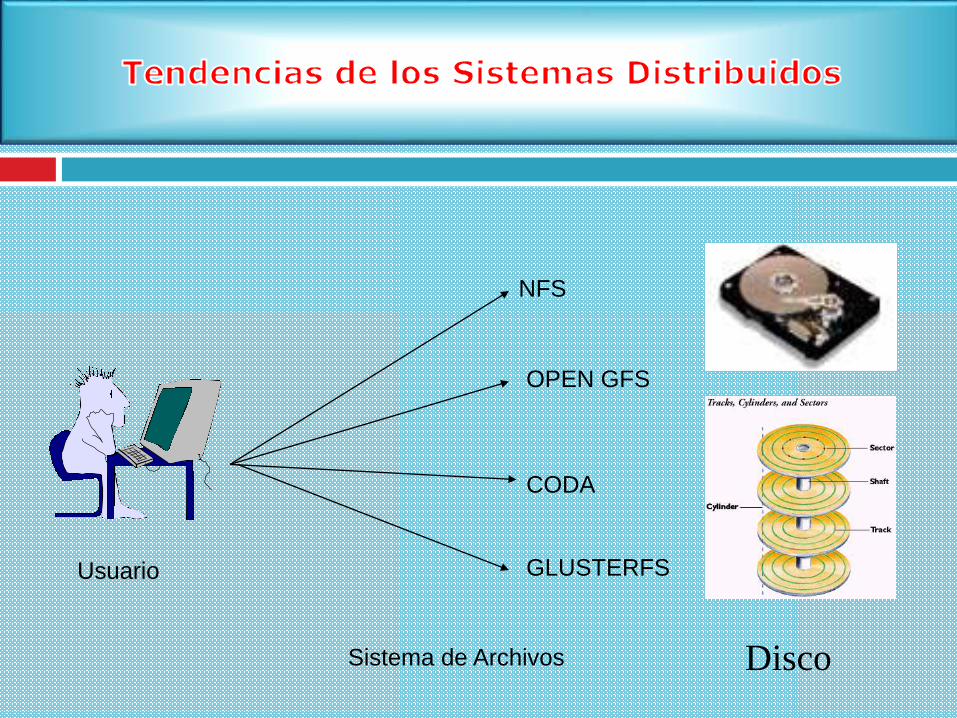
Usuario
Sistema de Archivos
NFS
CODA
OPEN GFS
GLUSTERFS
Disco

Uno de los sistemas de archivos más populares que trabaja con la
arquitectura de acceso remoto es NFS (Network File System).
„La idea básica de NFS es que cada servidor de archivos proporcione
una visión estandarizada (interfaz) de su sistema de archivos local,
independientemente de la implementación de este último.
El NFS cuenta con un protocolo de comunicación que permite a los
clientes acceder a los archivos guardados en el servidor. Luego, es
posible que un conjunto heterogéneo de procesos (quizás
ejecutándose en máquinas diferentes con SO diferentes) compartan
archivos.
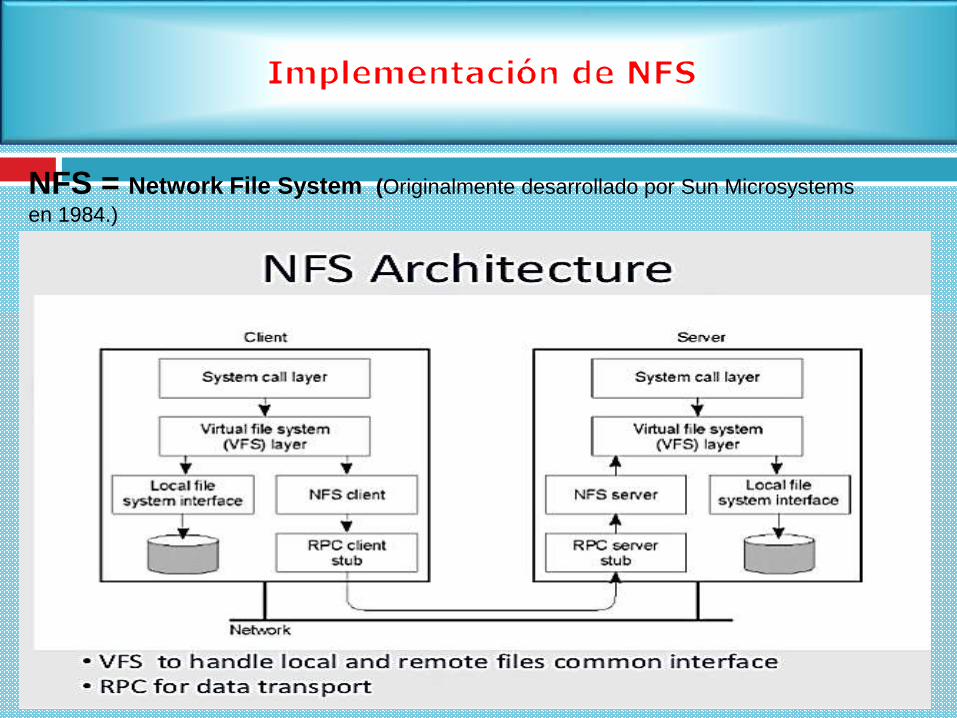
NFS = Network File System (Originalmente desarrollado por Sun Microsystems
en 1984.)
Permite compartir datos entre varios ordenadores de una forma sencilla.
Es un sistema de archivos distribuido para un entorno de red de área local.
Posibilita que distintos sistemas conectados a una misma red accedan a
ficheros remotos ficheros remotos como si se tratara de locales.
Soportar un sistema heterogéneo en donde los clientes y servidores podrían
ejecutar distintos S. O. en hardware diverso, por ello es esencial que la interfaz
entre los clientes y los servidores esté bien definida.
NFS logra este objetivo definiendo dos “protocolos cliente - servidor”.
Por ejemplo: Un usuario validado en una red no necesitará hacer login a un ordenador
específico: vía NFS, accederá a su directorio personal (que llamaremos exportado) en la
máquina en la que esté trabajando.
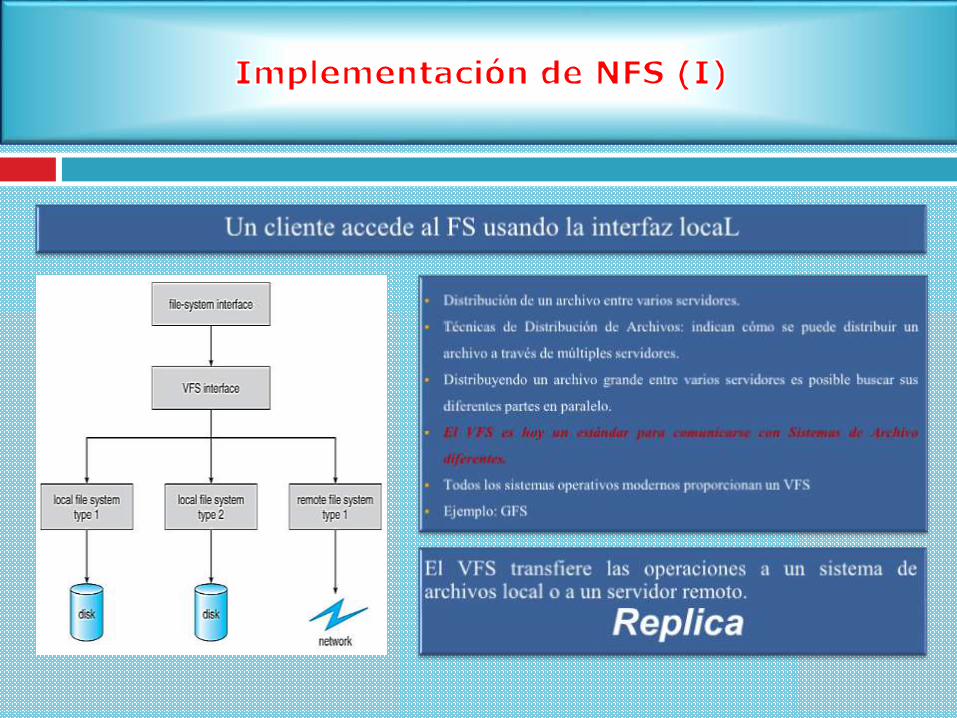

Network File System (Licencia abierta (GPL) Desarrollado en 1987.)
Cuenta con bastantes características muy deseables para un sistema
distribuido (especialmente para un cluster)
El cliente es capaz de funcionar sin problemas desconectado del
servidor, ya sea porque estamos trabajando en un portátil que
desconectamos de la red, por un fallo en la comunicación, o por una
caída del servidor.
Replicación automática de servidores. Coda proporciona los
mecanismos necesarios para realizar réplicas automáticas entre
servidores, y para que los clientes puedan acceder a uno u otro de forma
transparente para el usuario si alguno cae.
Modelo de seguridad propio e independiente del sistema operativo para
la identificación de usuarios.
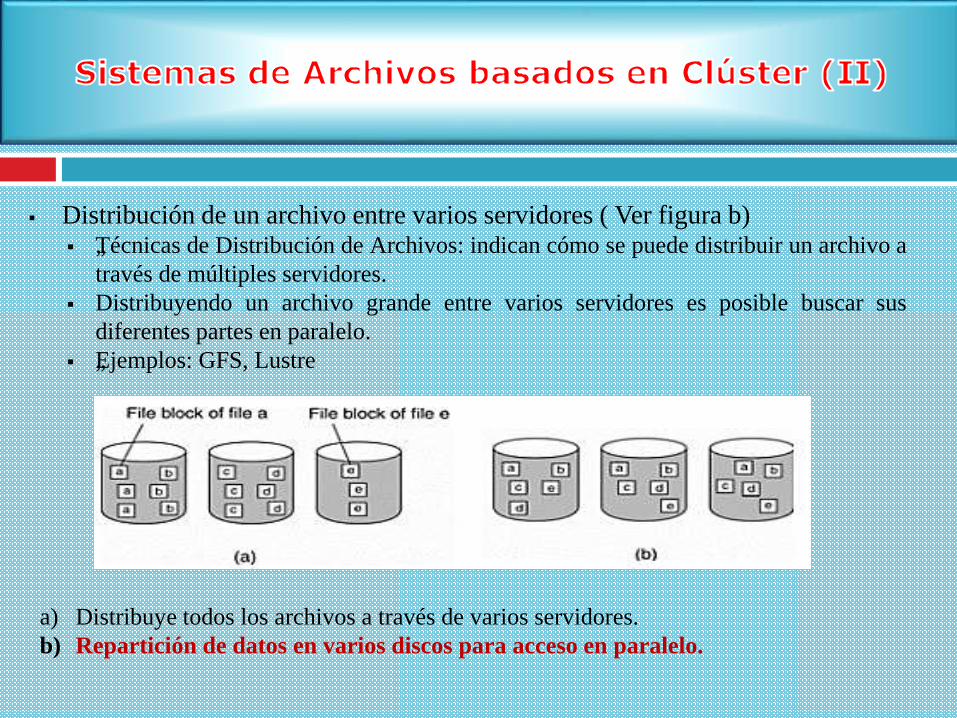
Distribución de un archivo entre varios servidores ( Ver figura b) „Técnicas de Distribución de Archivos: indican cómo se puede distribuir un archivo a
través de múltiples servidores.
Distribuyendo un archivo grande entre varios servidores es posible buscar sus
diferentes partes en paralelo.
„Ejemplos: GFS, Lustre
a) Distribuye todos los archivos a través de varios servidores.
b) Repartición de datos en varios discos para acceso en paralelo.
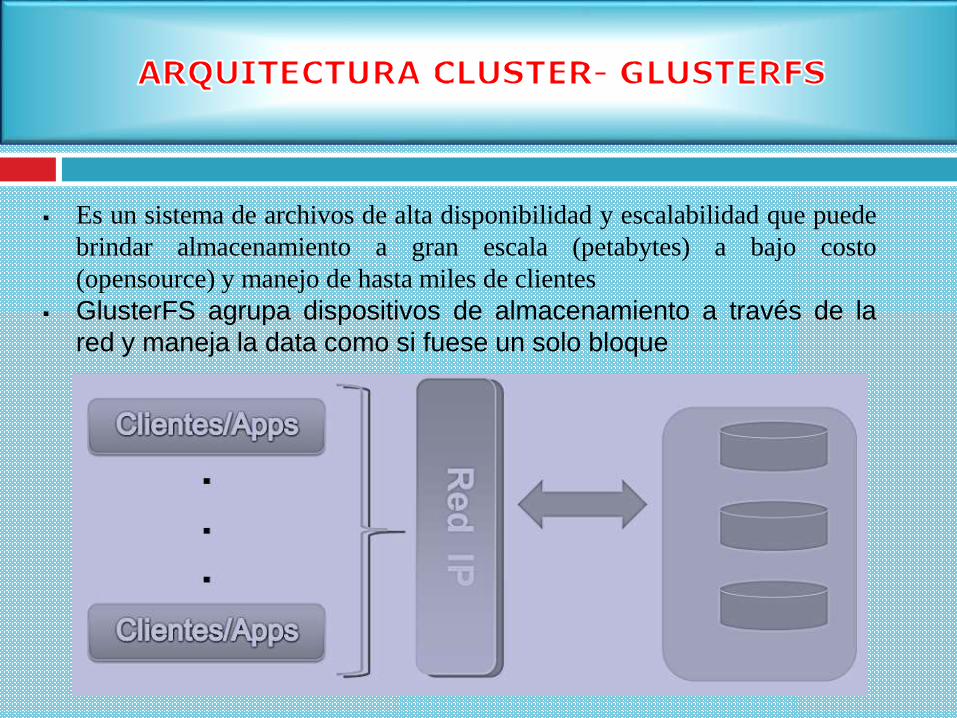
Es un sistema de archivos de alta disponibilidad y escalabilidad que puede
brindar almacenamiento a gran escala (petabytes) a bajo costo
(opensource) y manejo de hasta miles de clientes
GlusterFS agrupa dispositivos de almacenamiento a través de la
red y maneja la data como si fuese un solo bloque

Método de acceso a la data Los volúmenes de Clúster se pueden acceder de diversas maneras, se
puede utilizar NFS para exportar o también el protocolo nativo de
Clúster que es el más recomendado. Este protocolo esta basado en
FUSE (Fileystem user space) por lo cual hay que asegurarse que este
modulo este cargado en el kernel. FUSE permite levantar el sistema de
archivo de Gluster en el user space (espacio de memoria donde trabajan
las aplicaciones del usuario)
Algunas aplicaciones comerciales
Gluster Virtual Appliance for Amazon Web Services: Permite el desarrollo de un
servidor de almacenamiento basado en Gluster en la nube de Amazon

2.2.1 Nombres y Transparencia
2.2.2 Acceso a Archivos Remotos
2.2.3 Servicios con y sin estado
2.2.4 Replicación de archivos

Servicio uniforme de nombres para todos los objetos: Nombres orientados al usuario
Asociación entre nombre y posición dinámica
Propiedad más exigente que la transparencia
Transparencia de la posición:
El nombre del objeto no permite obtener directamente el lugar donde está almacenado
Independencia de la posición:
El nombre no necesita ser cambiado cuando el objeto cambia de lugar.
Diferentes esquemas para diferentes archivos. (Varios servidores)
Escalabilidad: Facilidad de crecimiento
Replicación

2.2.1 Nombres y Transparencia
2.2.2 Acceso a Archivos Remotos
2.2.3 Servicios con y sin estado
2.2.4 Replicación de archivos

La coutilización
La semántica de coutilización es un conjunto de criterios que se toman en
cuenta al momento que un archivo es solicitado por varios usuarios y se desea
mostrar las actualizaciones hechas a este archivo.
Semántica UNIX
Las modificaciones a un archivo abierto son visibles de inmediato por los
demás usuarios.
El archivo tiene una sola imagen que intercala todos los accesos, sea cual sea
su origen.
Semántica de Sesión
Las modificaciones a un archivo abierto no son visibles de inmediato por los demás
usuarios.
Las modificaciones que sufre un archivo son visibles solo después de que se cierra un
archivo.

Métodos de Acceso a Archivos
Modelo carga/descarga
Transferencias completas del archivo
Localmente se almacenan en memoria o discos locales
Normalmente utilizan semántica de sesión
Eficiencia en las transferencias
Llamada open con mucha latencia
Múltiples copias de un archivo
Modelo de servicios remotos
El servidor debe proporcionar todas las operaciones sobre el archivo.
Acceso por bloques
Modelo cliente/servidor
Empleo de caché en el cliente
Combina los dos modelos anteriores.

2.2.1 Nombres y Transparencia
2.2.2 Acceso a Archivos Remotos
2.2.3 Servicios con y sin estado
2.2.4 Replicación de archivos

Servidores con estado
Cuando se abre un archivo, el servidor almacena información y da
al cliente un identificador único a utilizar en las posteriores
llamadas
Por Ejemplo: La tabla que asocia los descriptores de archivos con los
archivos propiamente dichos.
Pueden conocer qué datos están en el cache del cliente (permiten
al cliente mantener copias locales de datos compartidos).
Cuando se cierra un archivo se libera la información

Servidores sin estado (stateless)
Cuando un cliente envía una solicitud a un servidor, éste la lleva a cabo,
envía la respuesta y elimina de sus tablas internas toda la información
relativa a dicha solicitud.
Por ejemplo, no registra si un archivo ha sido abierto previamente.
No guarda información del cliente entre solicitudes. No mantiene un
registro de las operaciones que van dejando los clientes
Cada solicitud debe ser auto contenida. Operaciones idempotentes

Ventajas de los servidores con estado
Mensajes de petición más cortos
Mejor rendimiento (se mantiene información en memoria)
Facilita la lectura adelantada. El servidor puede analizar el patrón de accesos
que realiza cada cliente
Es necesario en invalidaciones iniciadas por el servidor
Ventajas de los servidores sin estado
Más tolerante a fallos
No son necesarios open y close. Se reduce el nº de mensajes
No se gasta memoria en el servidor para almacenar el estado

2.2.1 Nombres y Transparencia
2.2.2 Acceso a Archivos Remotos
2.2.3 Servicios con y sin estado
2.2.4 Replicación de archivos

Caché de Bloques
El empleo de cache de bloques permite mejorar el rendimiento
Explota el principio de proximidad de referencias:
Proximidad temporal
Proximidad espacial
Lecturas adelantadas: Mejora el rendimiento de las operaciones de lectura, sobre todo
si son secuenciales
Escrituras diferidas : Mejora el rendimiento de las escrituras
Otros tipos de caché
Caché de nombres
Caché de metadatos del sistema de archivos

Localización de las Caché en un Sistema Archivos Distribuido
Caché en los servidores
Reducen los accesos a disco
Caché en los clientes
Reducen el tráfico por la red
Reducen la carga en los servidores
Mejora la capacidad de crecimiento
Dos posibles localizaciones
En discos locales: Más capacidad, más lento, no volátil, facilita la
recuperación
En memoria principal: Menor capacidad, más rápido, memoria volátil
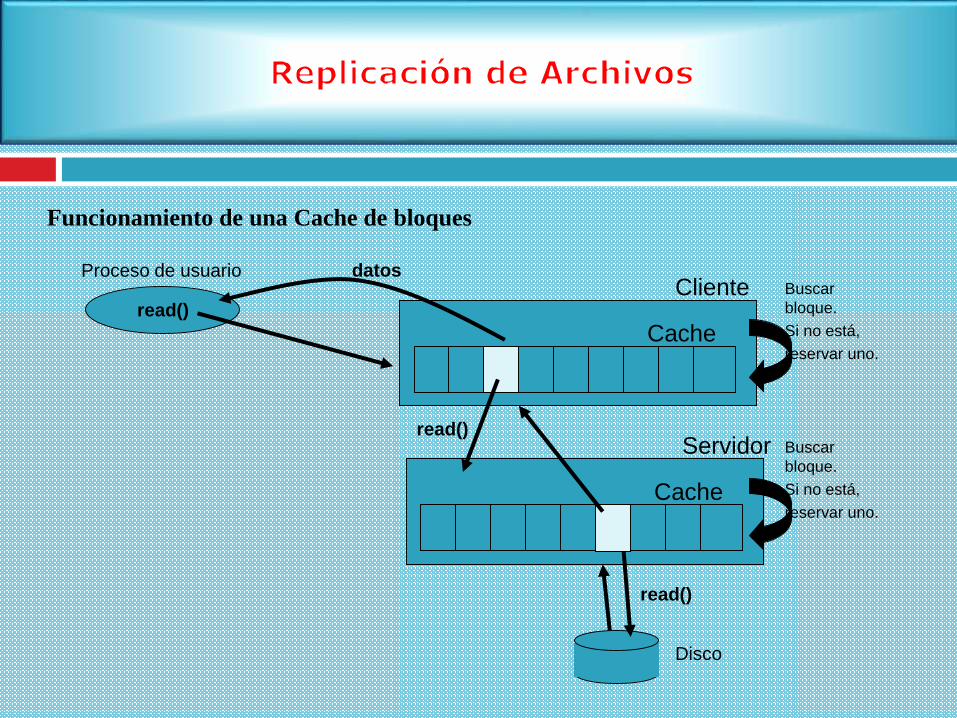
Funcionamiento de una Cache de bloques
Cache
Cliente
Cache
Servidor
Disco
Proceso de usuario
read()
Buscar
bloque.
Si no está,
reservar uno.
read()Buscar
bloque.
Si no está,
reservar uno.
read()
datos

Tamaño de la memoria cache
Mayor tamaño puede incrementar la tasa de aciertos y mejorar la utilización de la red pero
Aumentan los problemas de coherencia
Depende de las características de las aplicaciones
En memoria caché grandes
Es beneficioso emplear bloques grandes (8 KB y más)
En memorias pequeñas
El uso de bloques grandes es menos adecuado

Políticas de Actualización
Escritura inmediata (write-through)
Buena fiabilidad
En escrituras se obtiene el mismo rendimiento que en el modelo de accesos remotos
Las escrituras son más lentas
Escritura diferida (write-back)
Escrituras más rápidas. Se reduce el tráfico en la red
Los datos pueden borrarse antes de ser enviados al servidor
Alternativas
Volcado (flush) periódico (Sprite)
Write-on-close

El problema de la Coherencia
El uso de caché en los clientes de un sistema de archivos introduce el problema
de la coherencia de caché:
Múltiples copias.
El problema surge cuando se coutiliza un archivo en escritura:
Coutilización en escritura secuencial
Típico en entornos y aplicaciones distribuidas.
Coutilización en escritura concurrente
Típico en aplicaciones paralelas.

Solución al problema de la Coherencia
No emplear caché en los clientes.
Solución trivial que no permite explotar las ventajas del uso de caché en los
clientes (reutilización, lectura adelantada y escritura diferida)
No utilizar caché en los clientes para datos compartidos en escritura (Sprite).
Accesos remotos sobre una única copia asegura semántica UNIX
Empleo de protocolos de coherencia de caché

2.3 Gestion Distribuida de Procesos
• Aplicaciones paralelas Muchas tareas a la vez
• Objetivo principal: disminuir el tiempo de ejecución
• Aplicaciones distribuidas (motivaciones):
• Alto rendimiento: cluster computing
• Tolerancia a fallos: replicación, transacciones
• Sistemas informáticos bancarios
• La gestión de la consistencia es crítica
• Alta disponibilidad: caching, mirroring
• Bajo tiempo de respuesta: WWW, sistemas de ficheros.
• La consistencia es importante, pero no crítica
• Movilidad, ubicuidad: aplicaciones AmI

Es un aplicación con distintos componentes que seejecutan en entornos separados, normalmente endiferentes plataformas conectadas a través de la red.
La distribución se refiere a la construcción desoftware por partes, a cada parte se le asignauna serie de responsabilidades entero de unsistema.
La distribución habla de que las partes ocomponentes se ejecutan en diferentesmáquinas (física) Separación en Niveles
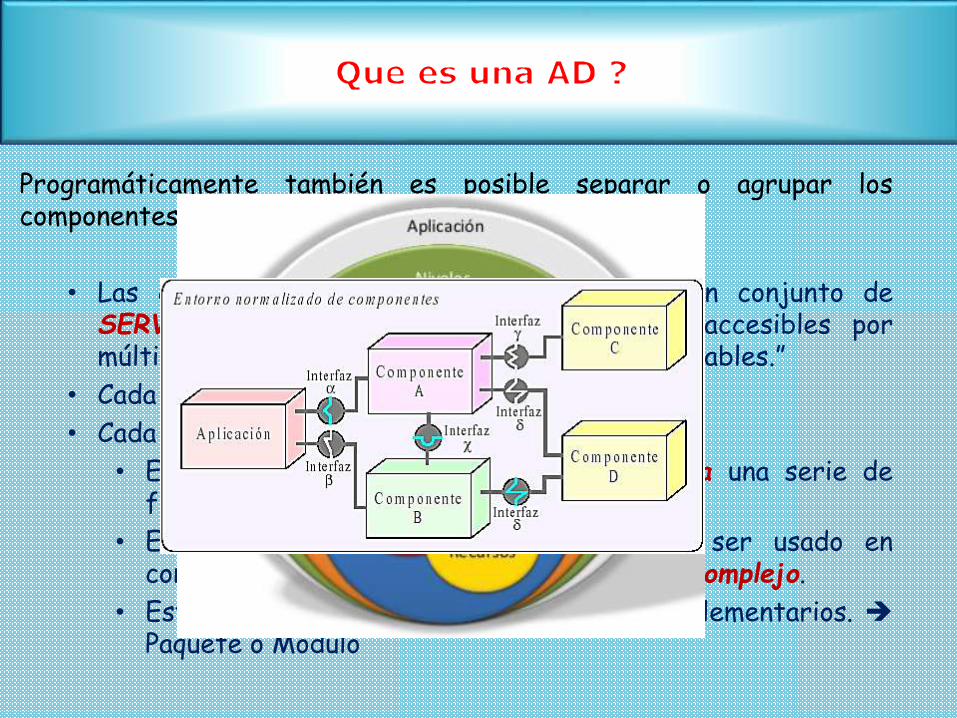
Programáticamente también es posible separar o agrupar loscomponentes (lógica). Separación en CAPAS:
• Las capas dentro de una arquitectura son un conjunto deSERVICIOS especializados que pueden ser accesibles pormúltiples clientes y deben ser fácilmente reutilizables.”
• Cada capa tiene N componentes
• Cada componente :
• Es un elemento de software que encapsula una serie defuncionalidades
• Es una unidad independiente que puede ser usado enconjunto otras para formar un sistema mas complejo.
• Esta compuesto por clases o recursos complementarios. Paquete o Modulo
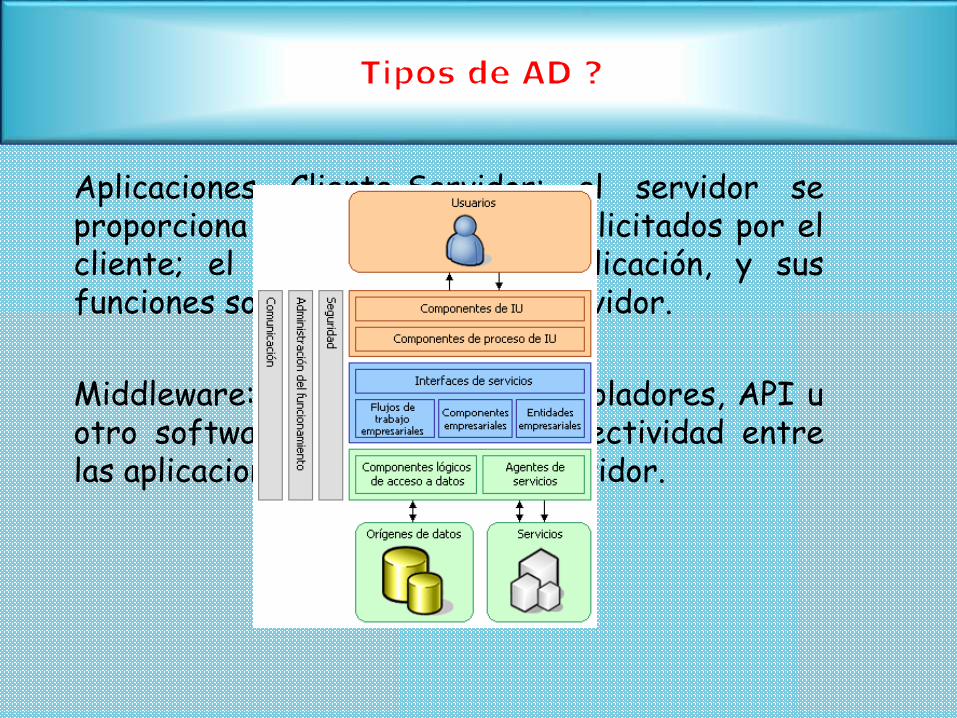
Aplicaciones Cliente-Servidor: el servidor seproporciona y procesa los datos solicitados por elcliente; el cliente maneja la aplicación, y susfunciones son solicitar datos al servidor.
Middleware: Un conjunto de controladores, API uotro software que mejora la conectividad entrelas aplicaciones de cliente y un servidor.

¿Qué se entiende por computador?
Datos
Instrucciones
Un dato a la vez Muchos datos a la
vez
Una
instrucción a la
vez
SISDarquitecturas Von Neumann
clásicas
SIMDprocesadores
vectoriales
Muchas
instrucciones
a la vez
MISDno se ha implementado
MIMDmultiprocesadores,
multicomputadores, redes

Procesadores con base en buses
Constan de cierto número de cpu conectadas a un bus
común, junto con un módulo de memoria.
Todos los elementos precedentes operan en paralelo.
Solo existe una memoria, la cual presenta la
propiedad de la coherencia:
Las modificaciones hechas por una cpu se reflejan de
inmediato en las subsiguientes lecturas de la misma o
de otra cpu.
El problema de este esquema es que el bus tiende a
sobrecargarse y el rendimiento a disminuir
drásticamente; la solución es añadir una memoria
caché de alta velocidad entre la cpu y el bus:
El caché guarda las palabras de acceso reciente.
Todas las solicitudes de la memoria pasan a través del
caché.
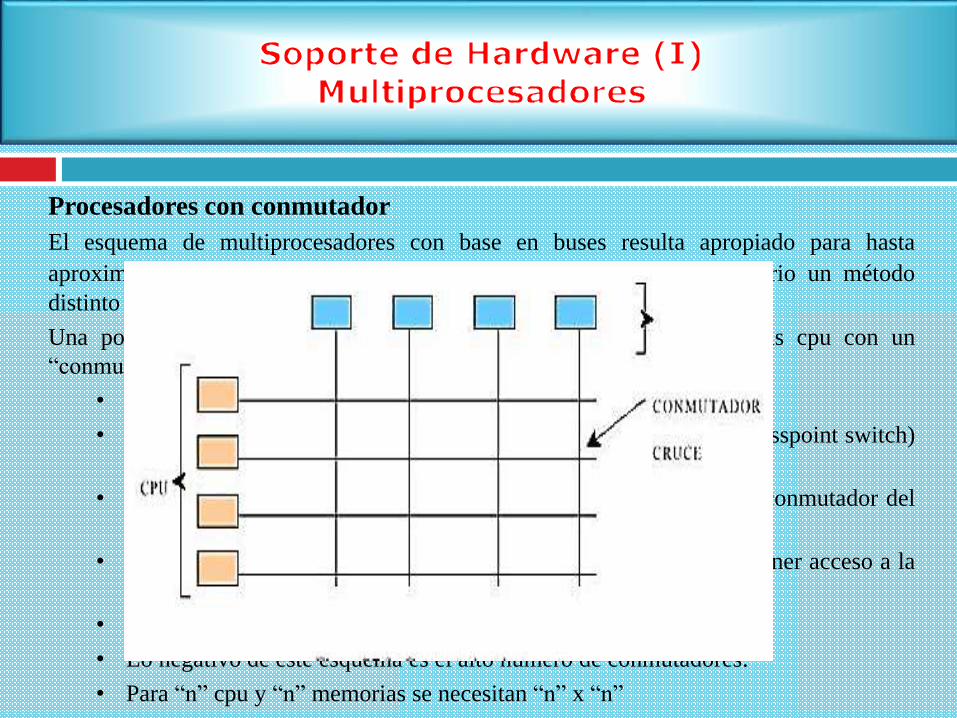
Procesadores con conmutador
El esquema de multiprocesadores con base en buses resulta apropiado para hasta
aproximadamente 64 procesadores. Para superar esta cifra es necesario un método
distinto de conexión entre procesadores (cpu) y memoria.
Una posibilidad es dividir la memoria en módulos y conectarlos a las cpu con un
“conmutador de cruceta” (cross-bar switch):
• Cada cpu y cada memoria tiene una conexión que sale de él.
• En cada intersección está un “conmutador del punto de cruce” (crosspoint switch)
electrónico que el hardware puede abrir y cerrar:
• Cuando una cpu desea tener acceso a una memoria particular, el conmutador del
punto de cruce que los conecta se cierra momentáneamente.
• La virtud del conmutador de cruceta es que muchas cpu pueden tener acceso a la
memoria al mismo tiempo:
• Aunque no a la misma memoria simultáneamente.
• Lo negativo de este esquema es el alto número de conmutadores:
• Para “n” cpu y “n” memorias se necesitan “n” x “n”
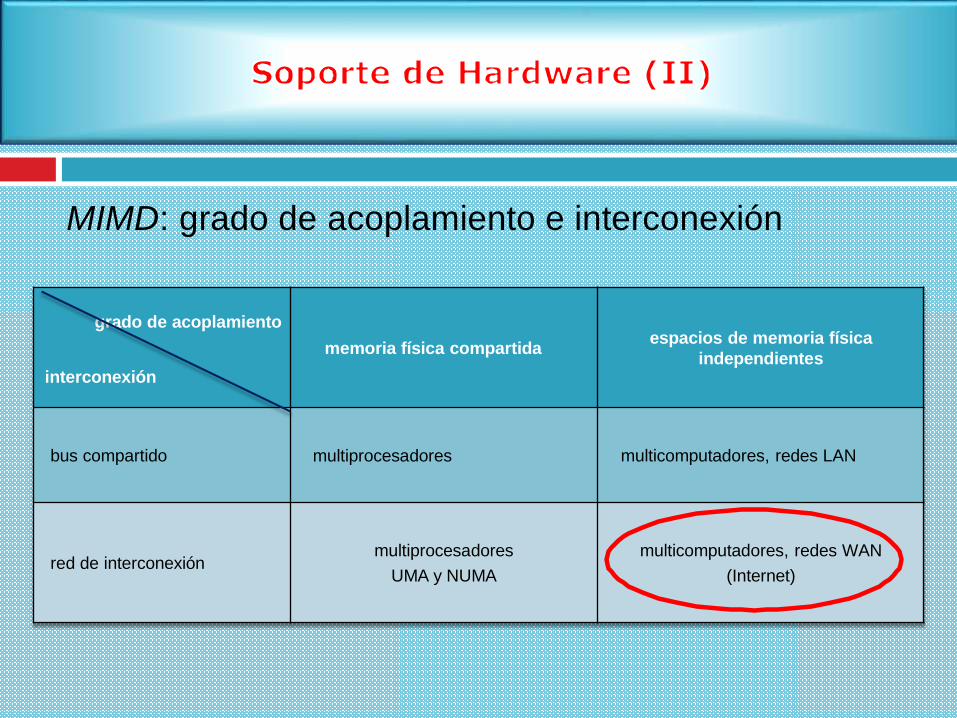
MIMD: grado de acoplamiento e interconexión
grado de acoplamiento
interconexión
memoria física compartidaespacios de memoria física
independientes
bus compartido multiprocesadores multicomputadores, redes LAN
red de interconexiónmultiprocesadores
UMA y NUMA
multicomputadores, redes WAN
(Internet)
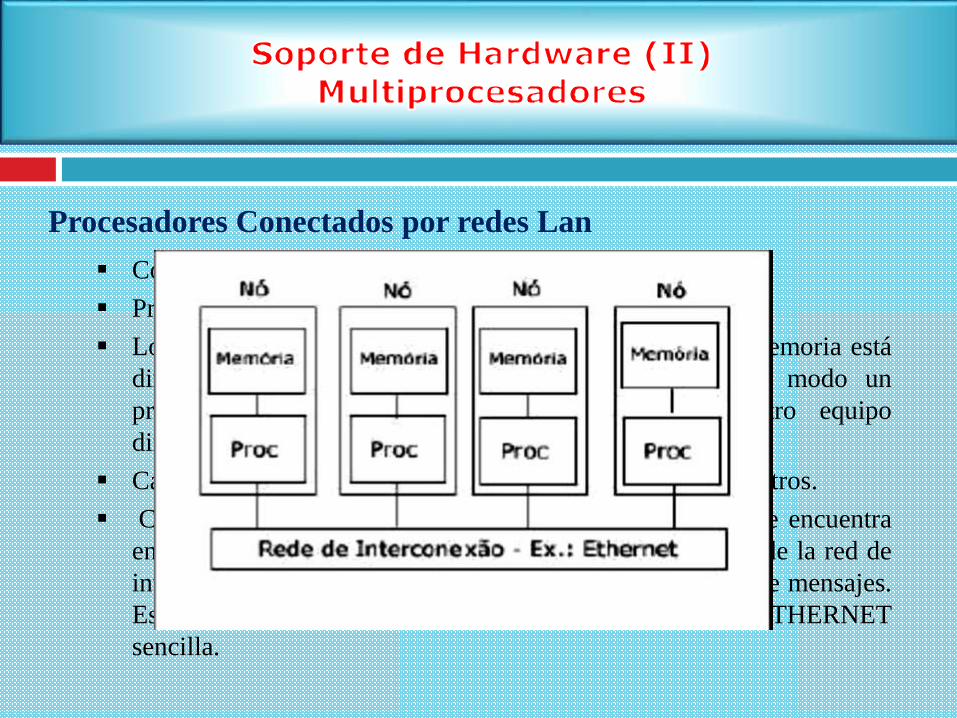
Procesadores Conectados por redes Lan
Computadores de memória distribuídas son muy utilizadas.
Presisan de red de interconexion entre los processos.
Los procesadores tienen su propia memoria local y esta memoria está
dirigida únicamente por el procesador local, de deste modo un
procesador no puede acceder a la memoria de otro equipo
directamente.
Cada procesador funciona de manera independiente de los otros.
Cuando un procesador necesita acceder a los datos que se encuentra
en la memoria de otro procesador, este acceso es a través de la red de
interconexión de estas máquinas mediante el intercambio de mensajes.
Esta red puede ser una red dedicada, o incluso una red ETHERNET
sencilla.

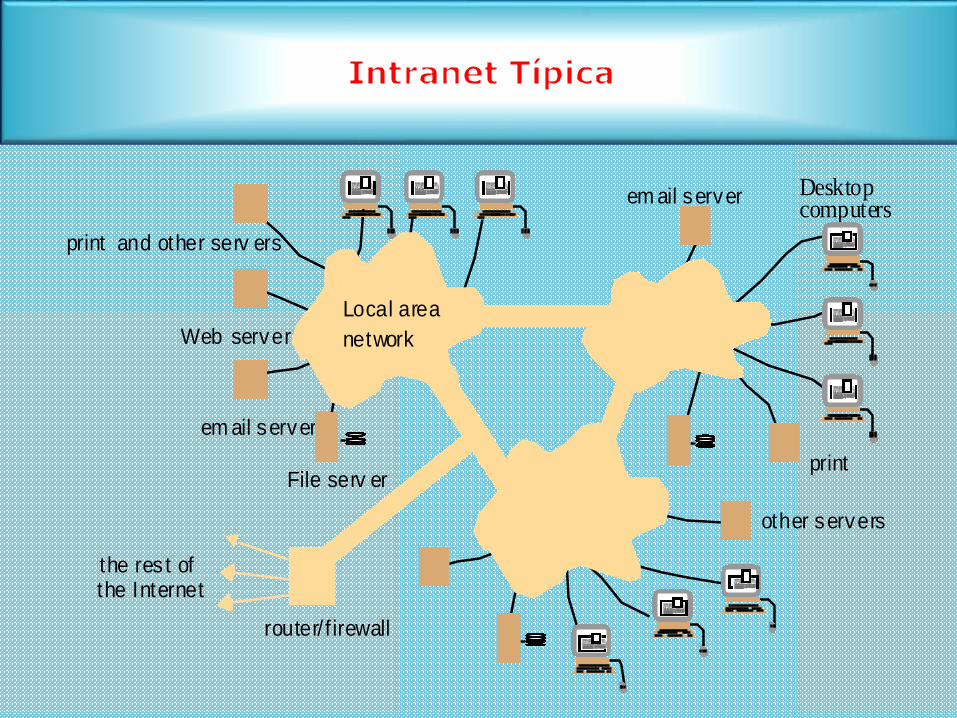
the res t of
em ail server
Web server
Desktopcomputers
File serv er
router/ f irewall
print and other serv ers
other servers
Local area
network
em ail server
the Internet
Red RedIRIS

2.3.1 Migración de procesos
2.3.2 Estados globales distribuidos
2.3.3 Gestión distribuida de procesos – exclusión Mutua
2.3.4 Interbloqueo distribuido
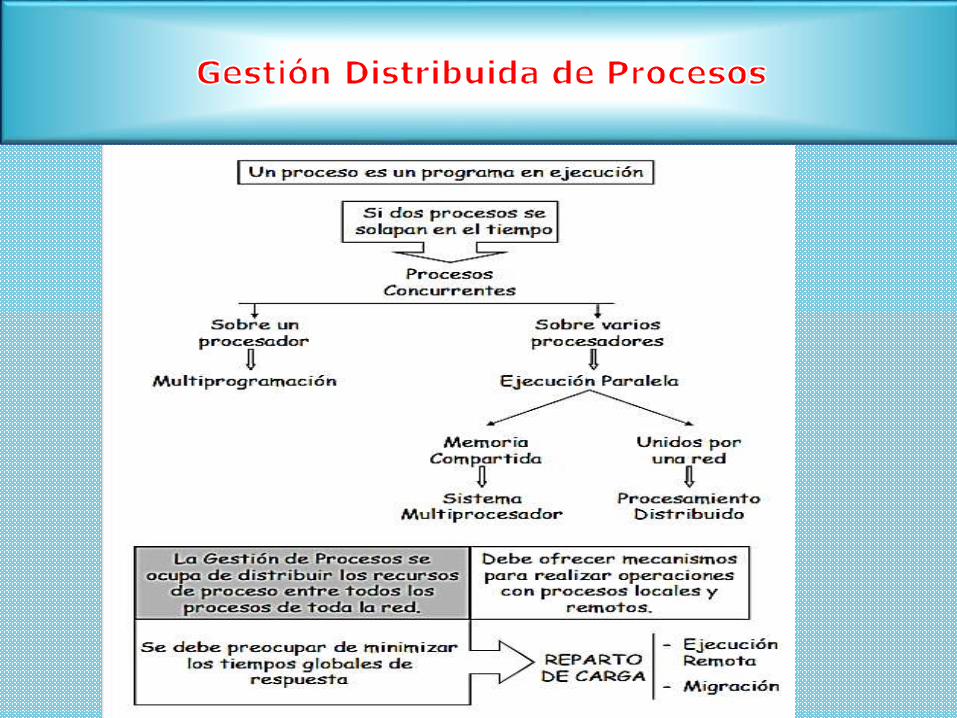
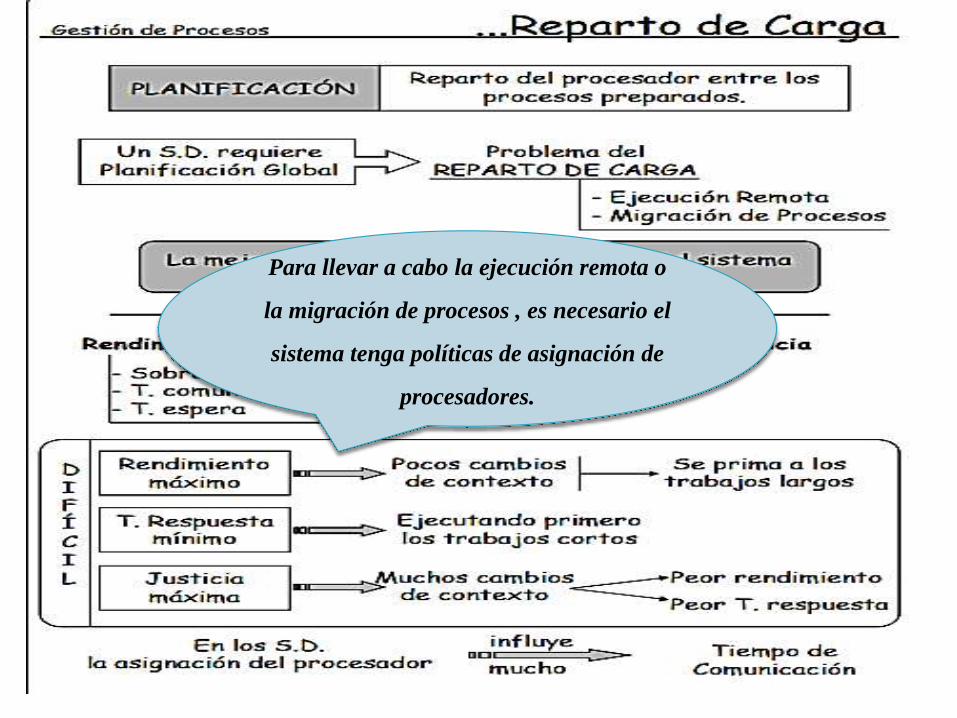
Para llevar a cabo la ejecución remota o
la migración de procesos , es necesario el
sistema tenga políticas de asignación de
procesadores.

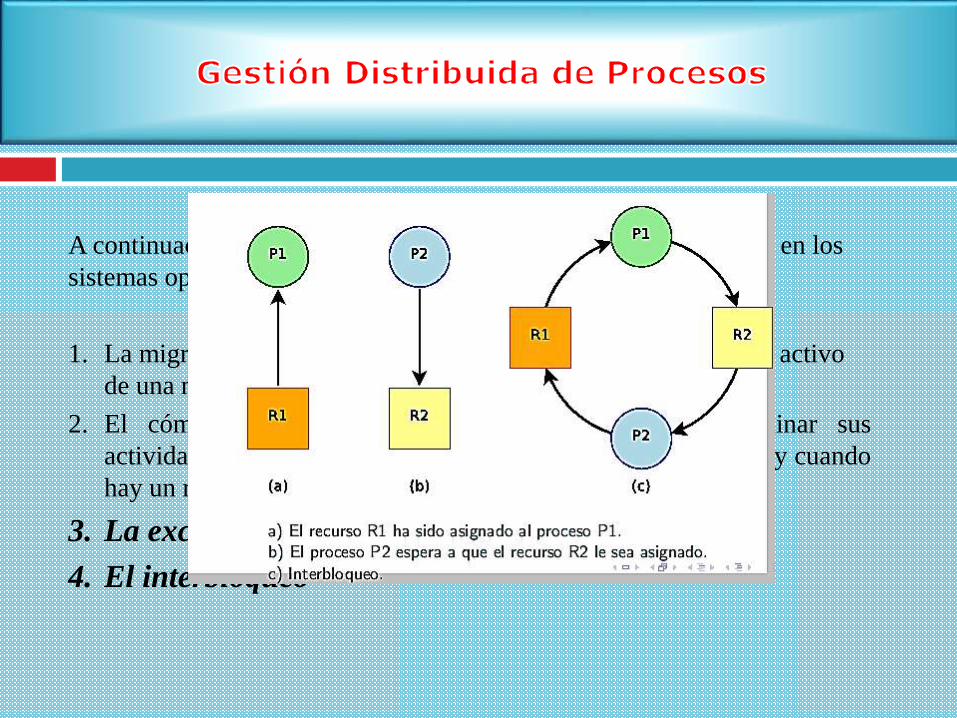
A continuación se analizaran algunos mecanismos clave utilizados en los
sistemas operativos distribuidos:
1. La migración de procesos, que es el movimiento de un proceso activo
de una máquina a otra.
2. El cómo procesos en diferentes sistemas pueden coordinar sus
actividades cuando cada uno está gobernado por un reloj local y cuando
hay un retardo en el intercambio de información.
3. La exclusión mutua
4. El interbloqueo
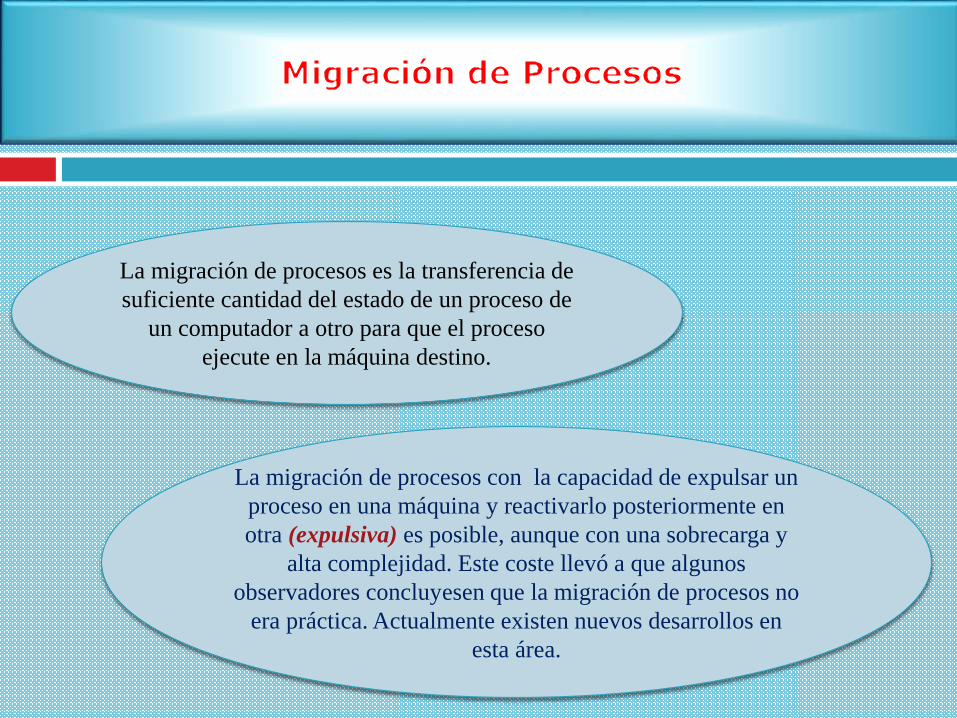
La migración de procesos es la transferencia de
suficiente cantidad del estado de un proceso de
un computador a otro para que el proceso
ejecute en la máquina destino.
La migración de procesos con la capacidad de expulsar un
proceso en una máquina y reactivarlo posteriormente en
otra (expulsiva) es posible, aunque con una sobrecarga y
alta complejidad. Este coste llevó a que algunos
observadores concluyesen que la migración de procesos no
era práctica. Actualmente existen nuevos desarrollos en
esta área.

La migración de procesos es deseable en sistemas distribuidos por:
• Compartición de carga. Moviendo procesos de un sistema muy cargado a otro poco
cargado, la carga puede equilibrarse para mejorar el rendimiento global. Datos empíricos
sugieren que son posibles mejoras del rendimiento.
• Disponibilidad. Se puede necesitar que los procesos de larga duración se muevan para
sobrevivir en el caso de fallos que puedan ser conocidos anticipadamente o anticipándose a
paradas del sistema planificadas. Si el sistema operativo proporciona la información, un
proceso que desea continuar puede bien migrar a otro sistema o asegurarse que podrá re
arrancarse en el sistema actual en algún momento posterior.
• Rendimiento de las comunicaciones. Los procesos que interaccionan intensivamente
pueden llevarse al mismo nodo para reducir el coste de las comunicaciones mientras dure
su interacción.

Mecanismos de la migración:
• ¿Quién inicia la migración?
• ¿Qué parte del proceso se migra?
• ¿Qué sucede con los mensajes y señales pendientes?
• Depende del objetivo del servicio de la migración.
• Este modulo es el responsable de expulsar o indicar el proceso que vaemigrar.
• Si el objetivo es llegar a un recurso en especifico, el procesos puedemigrar por si mismo según la necesidad
Al ser este un movimiento se lo destruye en el sistema origen y locrea en el destino. Se mueve la imagen del proceso mismo juntocon su bloque de control.
Cuando el proceso migra por si solo selecciona la maquina destino yle envía un mensaje de tarea remota. El mensaje lleva la imagen delproceso y la información de archivos abiertos.

2.3.1 Migración de procesos
2.3.2 Estados globales distribuidos
2.3.3 Gestión distribuida de procesos – exclusión Mutua
2.3.4 Interbloqueo distribuido
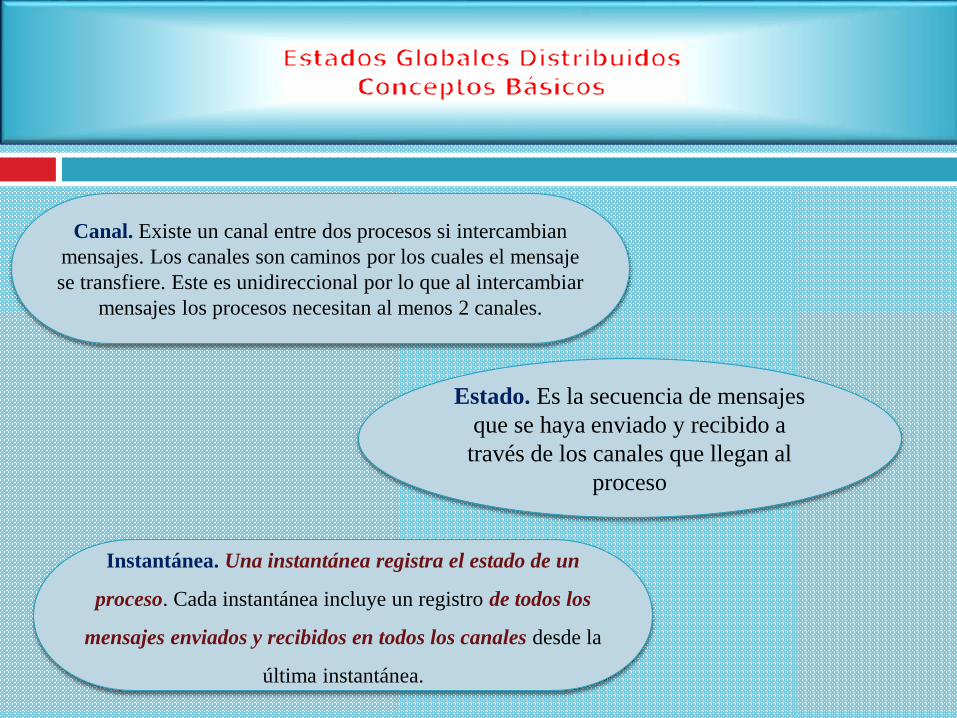
Canal. Existe un canal entre dos procesos si intercambian
mensajes. Los canales son caminos por los cuales el mensaje
se transfiere. Este es unidireccional por lo que al intercambiar
mensajes los procesos necesitan al menos 2 canales.
Estado. Es la secuencia de mensajes
que se haya enviado y recibido a
través de los canales que llegan al
proceso
Instantánea. Una instantánea registra el estado de un
proceso. Cada instantánea incluye un registro de todos los
mensajes enviados y recibidos en todos los canales desde la
última instantánea.
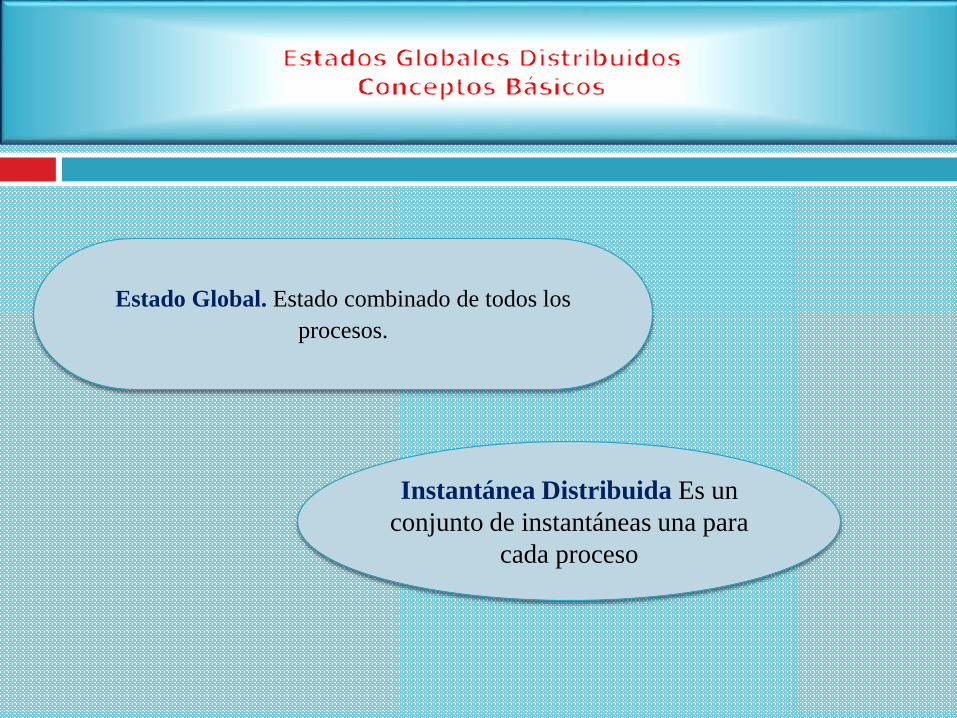
Estado Global. Estado combinado de todos los
procesos.
Instantánea Distribuida Es un
conjunto de instantáneas una para
cada proceso

Las estrategias de diseño en estas áreas se complican por el hecho de que no existe
un estado global del sistema. Esto es, no es posible para el sistema operativo ni
para ningún proceso, conocer el estado actual de todos los procesos en un sistema
distribuido.
Un proceso tan sólo puede conocer el estado actual de todos los procesos en el
sistema local, accediendo a los bloques de control de proceso en memoria.
Para los procesos remotos, un proceso tan sólo puede conocer información de
estado que se reciba vía mensajes, lo que representa el estado del proceso remoto
en algún momento del pasado.
El problema es que el estado global real no puede determinarse debido al lapso de
tiempo asociado con la transferencia de los mensajes.
Se puede intentar definir un estado global
recolectando instantáneas de todos los procesos. una
instantánea distribuida puede indicar que un mensaje
se ha recibido pero todavía no se ha enviado.

El Algoritmo de Instantánea Distribuida
Un algoritmo de instantánea distribuida registra un estado global consistente. El algoritmo
asume que los mensajes se entregan en el orden en que se envían y que no se pierden
mensajes. Un protocolo de transporte fiable (ej., TCP) satisface estos requisitos. El
algoritmo hace uso de un mensaje de control especial denominado marcador. El algoritmo
termina para un proceso una vez que ha recibido el marcador de cada canal entrante:
G =(S,L)
S ={ S1 ,S2 ,S3 .. Sm Estado interno de M procesadores
L ={ L i,j | | i,j E 1 .. M Estado de los canales unidirecc. C i,j entre procesadores.
El estado del canal son los mensajes en el encolados

2.3.1 Migración de procesos
2.3.2 Estados globales distribuidos
2.3.3 Gestión distribuida de procesos – exclusión Mutua
2.3.4 Interbloqueo distribuido
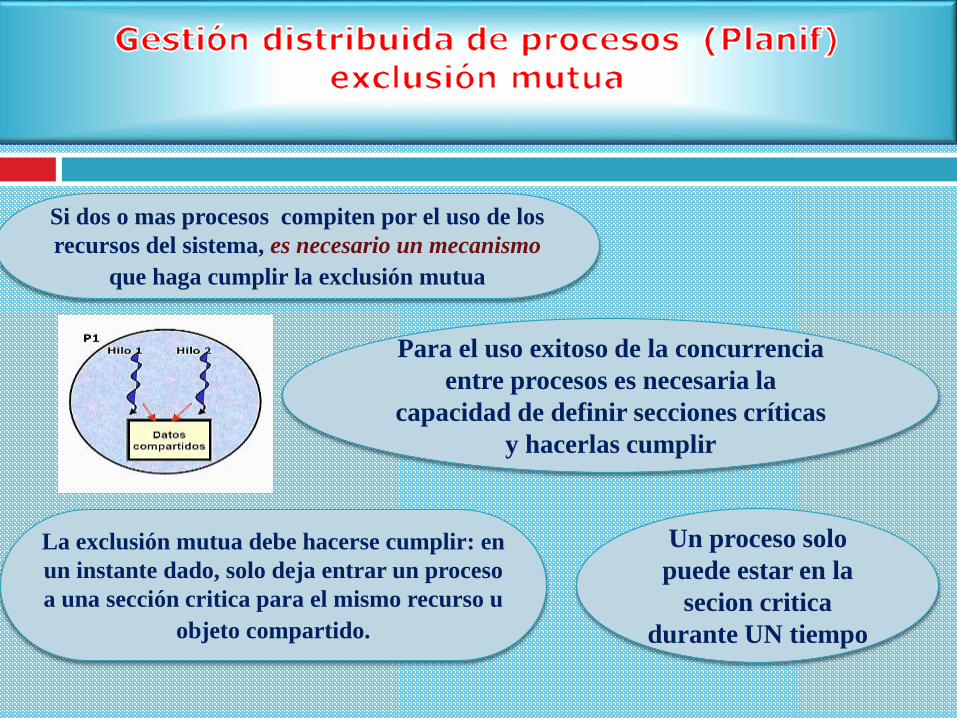
Si dos o mas procesos compiten por el uso de los
recursos del sistema, es necesario un mecanismo
que haga cumplir la exclusión mutua
Para el uso exitoso de la concurrencia
entre procesos es necesaria la
capacidad de definir secciones críticas
y hacerlas cumplir
La exclusión mutua debe hacerse cumplir: en
un instante dado, solo deja entrar un proceso
a una sección critica para el mismo recurso u
objeto compartido.
Un proceso solo
puede estar en la
secion critica
durante UN tiempo

Los sistemas de exclusión mutua pueden ser centralizados o distribuidos.
1. Centralizado (sencillo)
El nodo de control es el que aprueba una petición de un recurso hasta
que sea liberado
Problema: Si falla no funcionan las asignaciones,
puede llegar a ser como cuello de botella.
2. Distribuido:
• Todos los nodos disponen de una cantidad igual de información, por termino medio.
• Cada nodo tiene una representación parcial del sistema total, esto para tomar decisiones
• Todos los nodos tienen igual responsabilidad en la decisión final.
Problema: No existe un reloj común para regular los
sucesos y hacen mas difícil idear ALGORTMOS
DISTRIBUIDOS de exclusión mutua e Interbloqueo

2.3.1 Migración de procesos
2.3.2 Estados globales distribuidos
2.3.3 Gestión distribuida de procesos – exclusión Mutua
2.3.4 Interbloqueo distribuido

El manejo del interbloqueo se complica en un sistema distribuido porque ningún nodo
tiene conocimiento preciso del estado actual del sistema global y porque la
transferencia de cada mensaje entre procesos involucra un retardo impredecible.
La literatura ha prestado atención a dos tipos de interbloqueo distribuido: aquellos
que surgen en la ubicación de recursos, y aquellos que surgen con la comunicación
de mensajes.
En los interbloqueos por recursos, los procesos intentan acceder a recursos,
tales como objetos en una base de datos o recursos de E/S en un servidor; el
interbloqueo sucede si cada proceso de un conjunto de procesos solicita un
recurso que tiene otro proceso del conjunto.
En los interbloqueos en comunicaciones, los mensajes son los recursos por
los cuales esperan los procesos; el interbloqueo sucede si cada proceso de un
conjunto está esperando un mensaje de otro proceso en el conjunto y ningún
proceso en el conjunto envía nunca un mensaje.

Este fenómeno se produce debido a:
1. Exclusion mututa: Solo 1 procesos puede usar 1 recurso en 1 instante.
2. Retencion y espera: Un proceso puede usar los recursos asignados
mientras espera se le asigne otros.
3. No expulsión: No se puede quitar un recurso a un proceso q lo esta
utilizando.
4. Circulo visioso de espera: Existe una cadena cerrada de procesos, tal que
cada procesos retiene al menos un proceso que necesita el siguiente proceso
de la cadena.
El manejo del interbloqueo es complicado pero se puede:
1. Prevenir
2. Predecir
3. Detectar

• Debido a la falta de un reloj común o sincronizador se
propuso el método : Registro de tiempo o Marca de Tiempo.
• El esquema de marca de tiempo busca ordenar los sucesos
(mensajes de envió no recepción).
• Para logar la gestión se ha de utilizar algoritmos tales como:
Cola Distribuida y el Paso de Testigo.

Supuestos Cumple con
Se tienen N nodos numerados
en forma única
Exclusión mutua: Las solicitudes de entrada en la
sección crítica se manejan de acuerdo al orden de los
mensajes impuesto por el mecanismo de marcas de
tiempo
Los mensajes de un proceso a
otro se reciben en el mismo
orden en que fueron enviados
Equidad: Al estar ordenados por marcas de tiempo,
todos tienen igual oportunidad.
Cada mensaje es entregado en
un tiempo finito.
No hay Interbloqueo: Debido a que las marcas de
tiempo son de forma consistente no puede ocurrir un
interbloqueo.
Los mensajes son enviados en
forma directa sin proceso
intermedios.
No hay Inanicion: Una vez se hubiera terminado una
sección critica el proceso emitirá el mensaje de
Liberaciòn..
Algoritmo de Cola Distribuida

2.4 Sistema de Ejecución Distribuida
2.4.1 Soporte de software distribuido con Middleware
2.4.2 Programas de aplicación distribuidos clásicos
2.4.3 Soporte middleware => programación distribuida clásica
2.4.4 Programación distribuida en el WEB

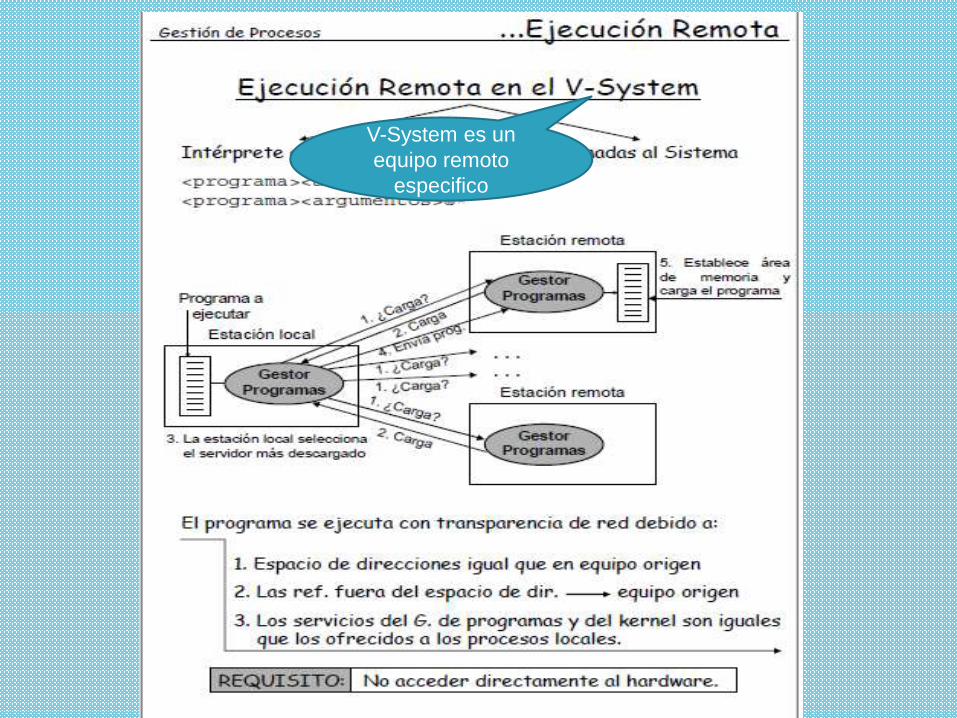
V-System es un
equipo remoto
especifico

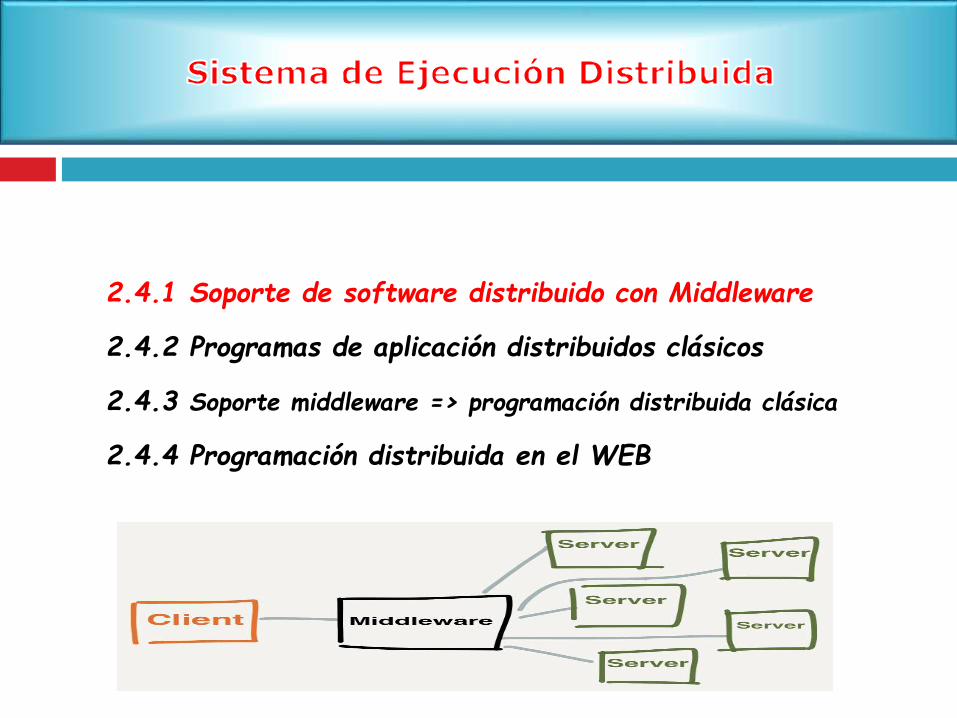
El software distribuido requerido para facilitar las interacciones cliente-
servidor se denomina middleware.
El acceso transparente a servicios y recursos no locales distribuidos a través
de una red se provee a través del middleware, que sirve como marco para la
comunicaciones entre las porciones cliente y servidor de un sistema.
El middleware define: el API que usan los clientes para pedir un servicio
a un servidor, la transmisión física de la petición vía red, y la devolución
de resultados desde el servidor al cliente.
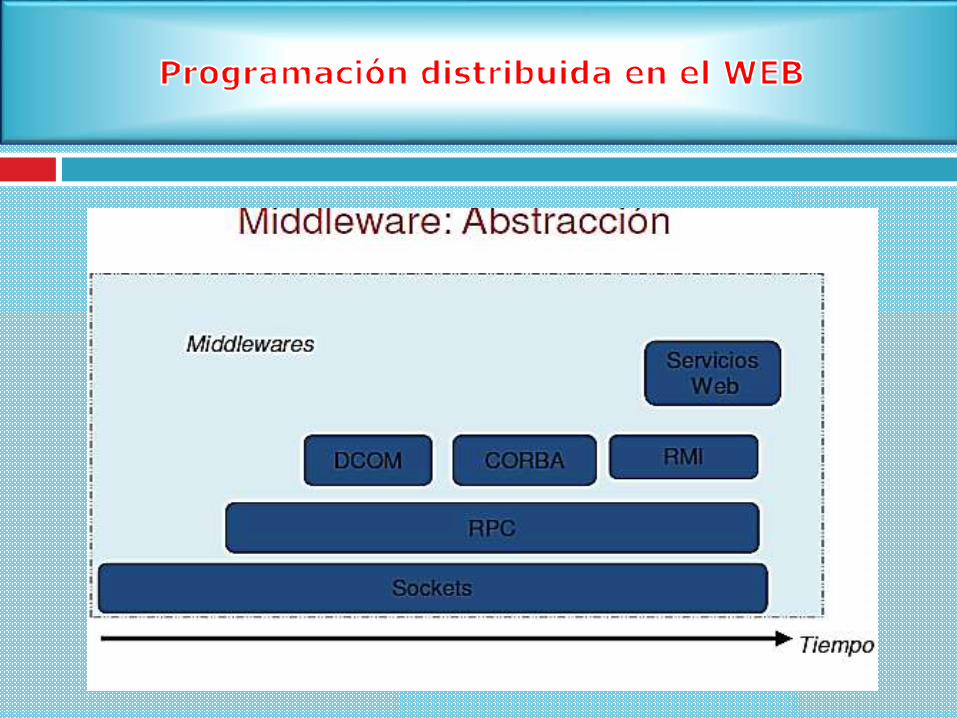
Ejemplos de middleware estándar para dominios específicos incluyen:
ODBC, para bases de datos, Lotus para groupware, HTTP y SSL para
Internet y CORBA, DCOM y JAVA RMI para objetos distribuidos.
El middleware fundamental o genérico es la base de los sistemas cliente-
servidor.
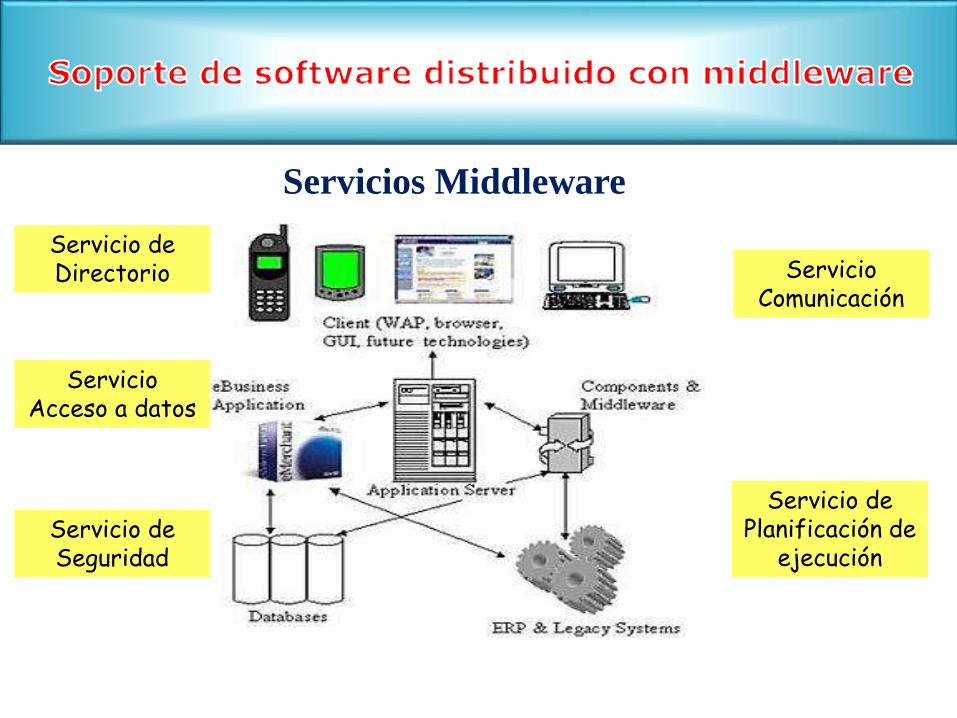
Servicio Comunicación
Servicio Acceso a datos
Servicio de Planificación de
ejecuciónServicio de Seguridad
Servicio de Directorio
Servicios Middleware
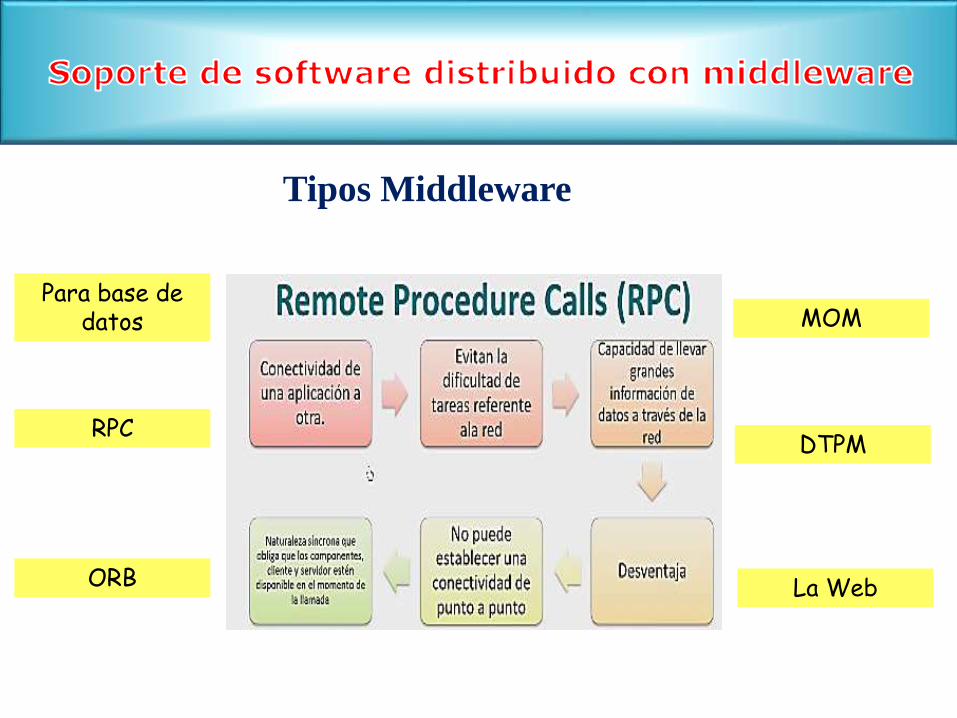
MOM
RPCDTPM
ORB
Para base de datos
Tipos Middleware
La Web

Si dos aplicaciones se quieren comunicar, hay que resolver la
comunicación entre los procesos.
Si las aplicaciones se conectan directamente a software de red,
entonces no se necesita Middleware.
Este enfoque dificulta el desarrollo de las aplicaciones: Puesto que
se deben programar módulos de bajo nivel y esto se hace
repetitivo para cada aplicación a conectar.
El software de Middleware permite realizar esta conexión a través de
interfaces de alto nivel
A manera de ejemplo la invocación remota de un procedimiento,
puede realizarse como si fuera local.

2.4.1 Soporte de software distribuido con Middleware
2.4.2 Programas de aplicación distribuidos clásicos
2.4.3 Soporte middleware => programación distribuida clásica
2.4.4 Programación distribuida en el WEB

Una aplicación distribuida que sigue el modelo cliente-servidor tiene:
• Lado servidor: Programa que se ejecuta en un computador que está conectado
a una red. Esta a la escucha en un puerto, esperando las peticiones de los
clientes; por ejemplo, un servidor Web escucha en el puerto 80.
• Lado cliente: Programa que ejecuta el usuario de la aplicación. El cliente hace
sus peticiones al servidor a través de la red. Por ejemplo, un navegador Web.
Protocolo de aplicación propicia la comunicación entre el cliente y el servidor.
El protocolo define el tipo de mensajes intercambiados:
Por ejemplo, el protocolo de la capa de aplicación de la Web, HTTP, define el
formato y la secuencia de los mensajes transmitidos entre el navegador y el
servidor Web.
Algunas de las aplicaciones distribuidas más conocidas son:
Remote login
Correo electrónico
Navegación Web.
2.4.1 Soporte de software distribuido con Middleware
2.4.2 Programas de aplicación distribuidos clásicos
2.4.3 Programación distribuida clásica
2.4.4 Programación distribuida en el WEB
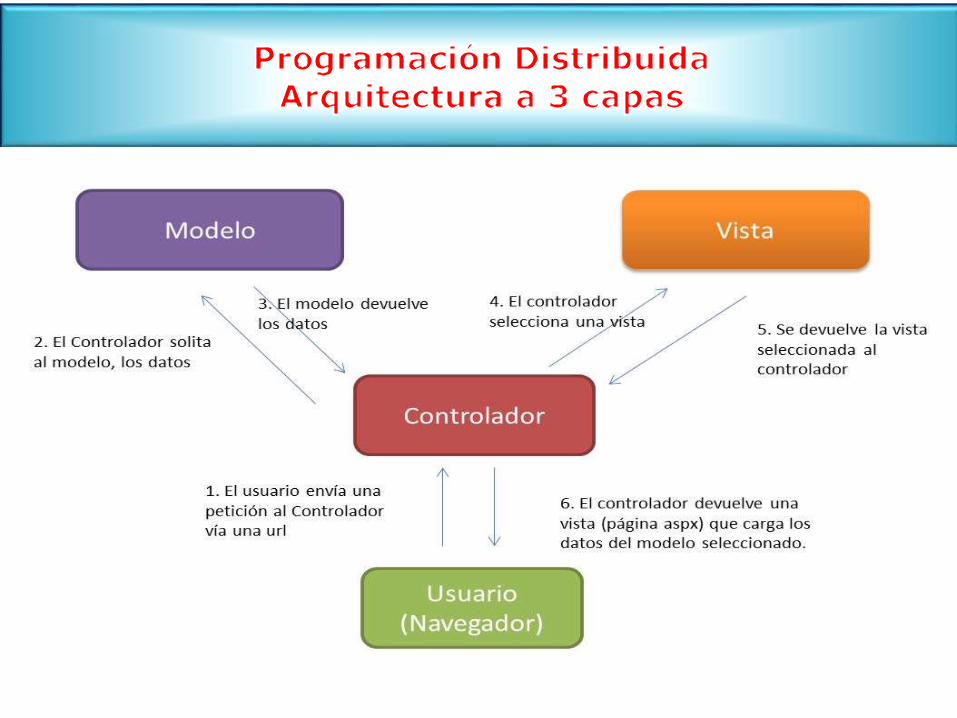
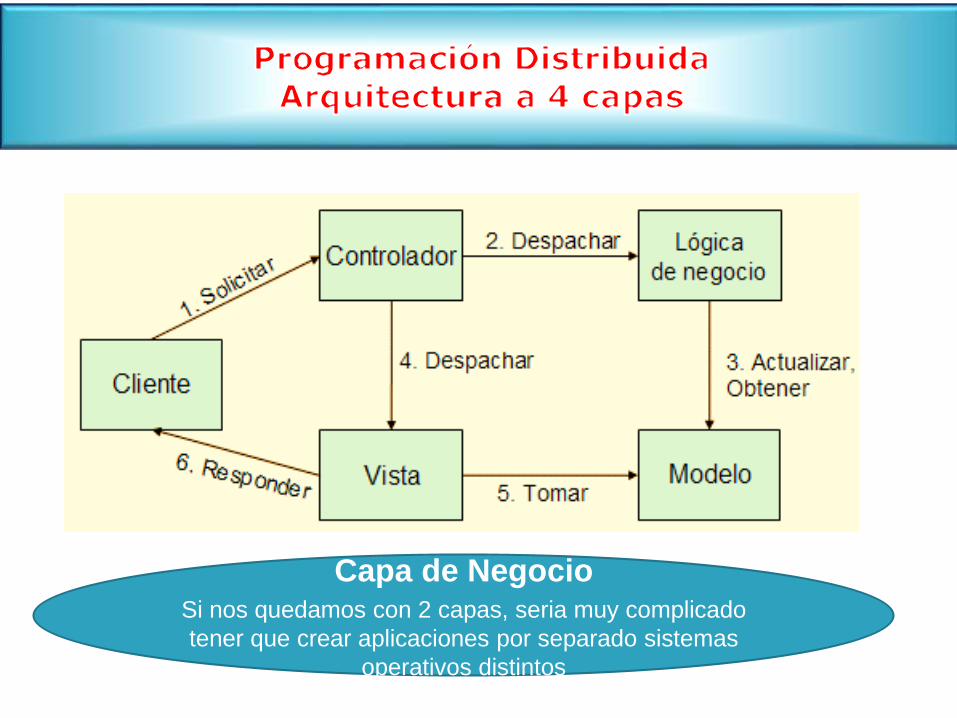
Capa de NegocioSi nos quedamos con 2 capas, seria muy complicado
tener que crear aplicaciones por separado sistemas
operativos distintos
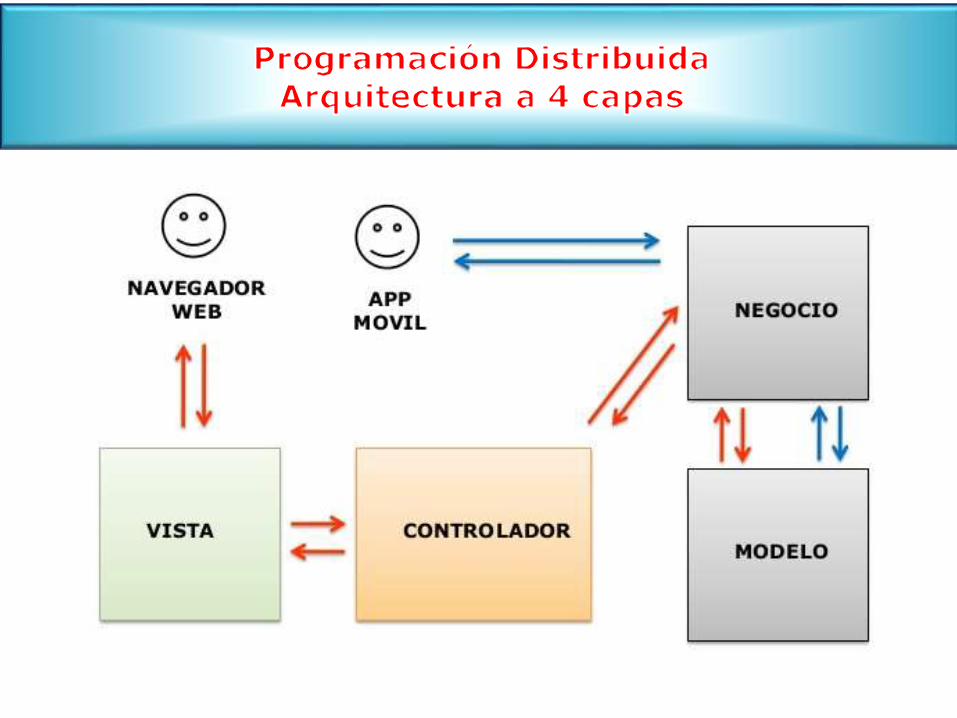
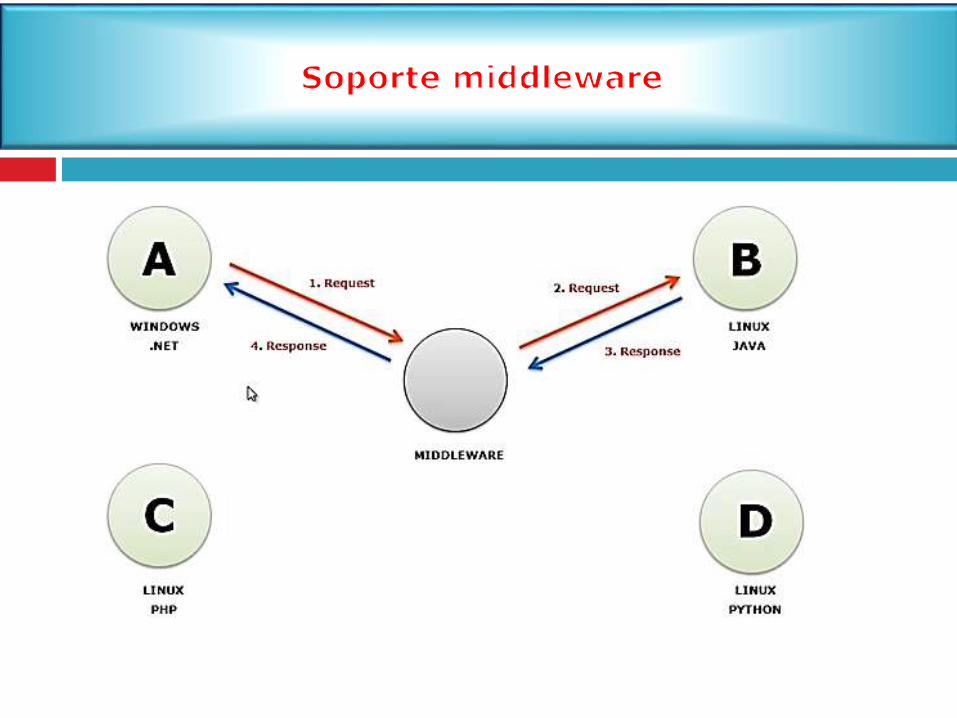
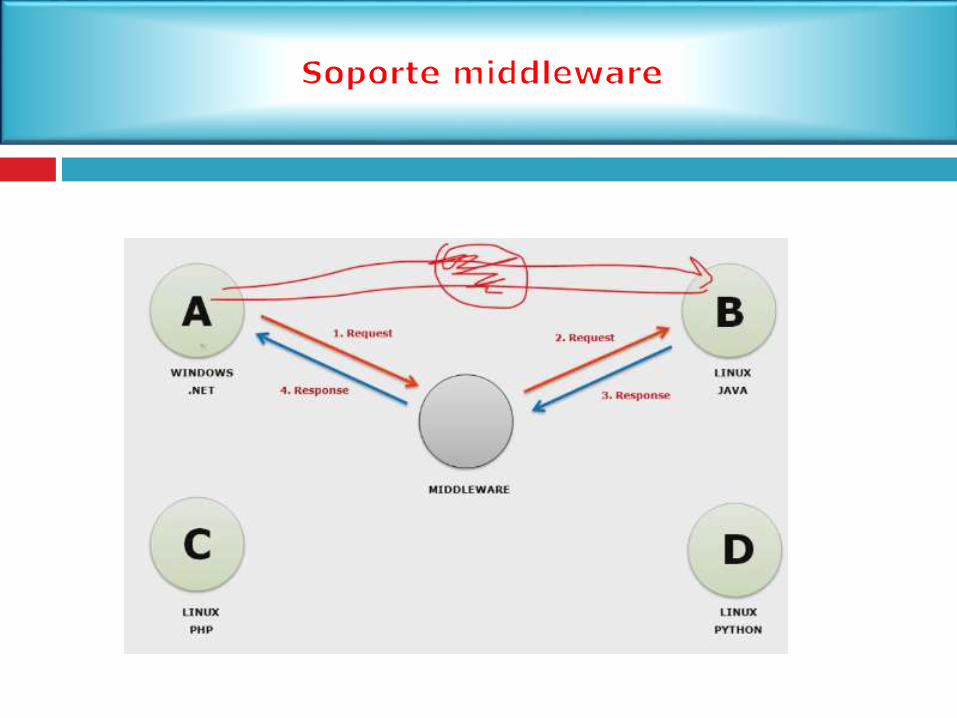
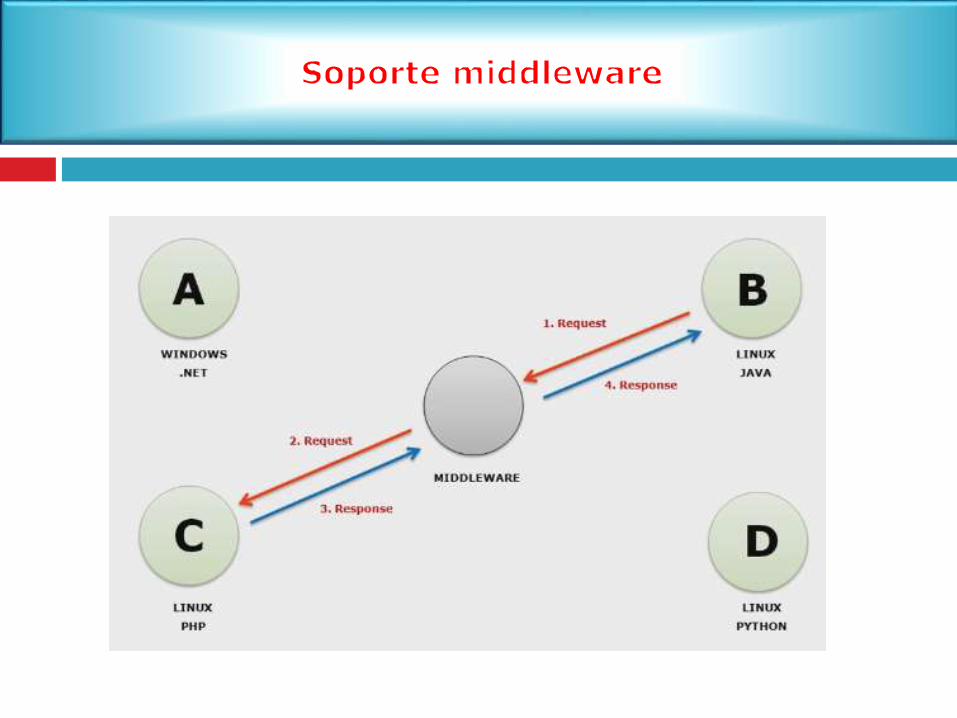
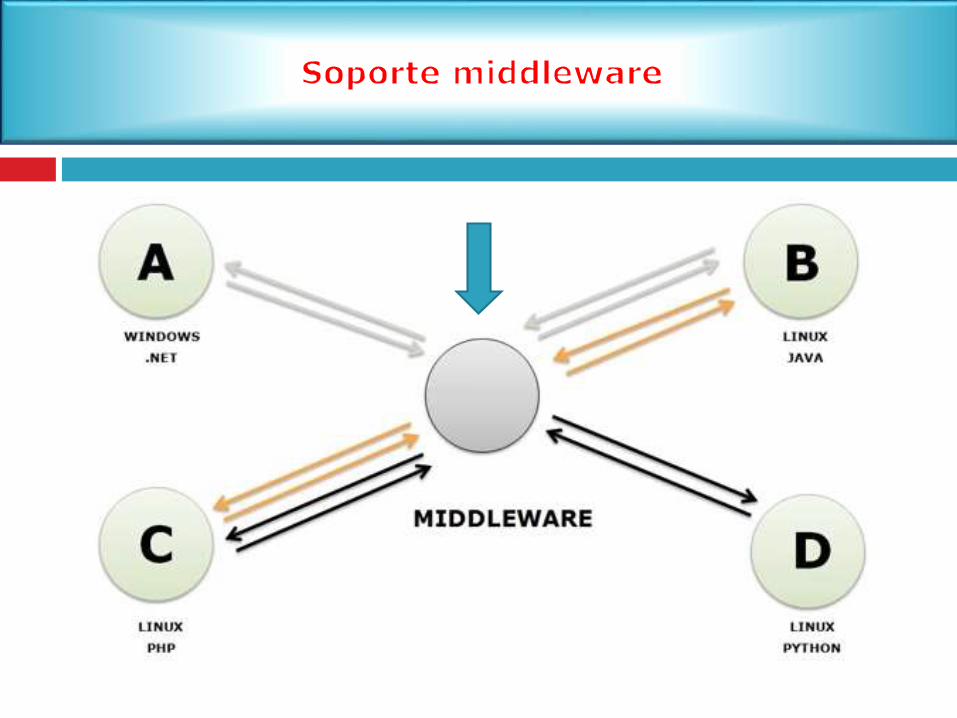

2.4.1 Soporte de software distribuido con Middleware
2.4.2 Programas de aplicación distribuidos clásicos
2.4.3 Programación distribuida clásica
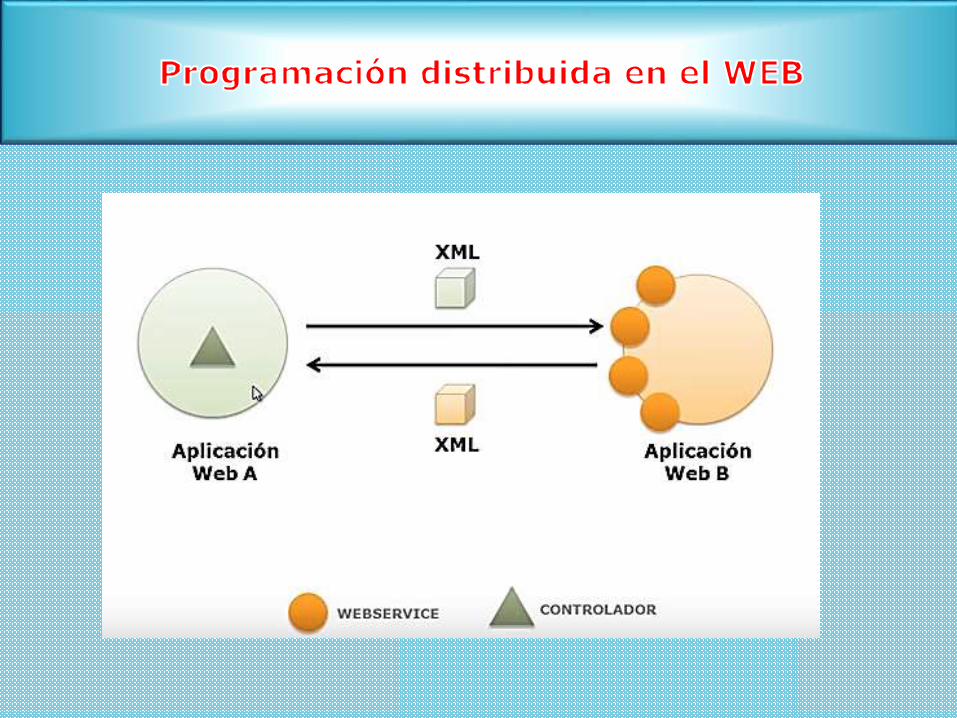
2.4.4 Programación distribuida en el WEB

Sistemas Operativos. Willian Stallings. 5ta Ed.
http://www.dia.eui.upm.es/Asignatu/Sis_dis/Paco/SOD.pdf





























