Embed Size (px)
Citation preview

Frontera: open source, large scale web crawling framework
Alexander Sibiryakov, Scrapinghub Ltd. [email protected]

Здравствуйте участники!

Здравствуйте участники!• Software Engineer @
Scrapinghub

Здравствуйте участники!• Software Engineer @
Scrapinghub
• Born in Yekaterinburg, RU

Здравствуйте участники!• Software Engineer @
Scrapinghub
• Born in Yekaterinburg, RU
• 5 years at Yandex: social & QA search, snippets.

Здравствуйте участники!• Software Engineer @
Scrapinghub
• Born in Yekaterinburg, RU
• 5 years at Yandex: social & QA search, snippets.
• 2 years at Avast! antivirus: false positives, malicious downloads

We help turn web content into useful data {
"content": [ { "title": { "text": "'Extreme poverty' to fall below 10% of world population for first time", "href": "http://www.theguardian.com/society/2015/oct/05/world-bank-extreme-poverty-to-fall-below-10-of-world-population-for-first-time" }, "points": "9 points", "time_ago": { "text": "2 hours ago", "href": "https://news.ycombinator.com/item?id=10352189" }, "username": { "text": "hliyan", "href": "https://news.ycombinator.com/user?id=hliyan" } },

We help turn web content into useful data
• Over 2 billion requests per month (~800/sec.)
{ "content": [ { "title": { "text": "'Extreme poverty' to fall below 10% of world population for first time", "href": "http://www.theguardian.com/society/2015/oct/05/world-bank-extreme-poverty-to-fall-below-10-of-world-population-for-first-time" }, "points": "9 points", "time_ago": { "text": "2 hours ago", "href": "https://news.ycombinator.com/item?id=10352189" }, "username": { "text": "hliyan", "href": "https://news.ycombinator.com/user?id=hliyan" } },

We help turn web content into useful data
• Over 2 billion requests per month (~800/sec.)• Focused crawls & Broad crawls
{ "content": [ { "title": { "text": "'Extreme poverty' to fall below 10% of world population for first time", "href": "http://www.theguardian.com/society/2015/oct/05/world-bank-extreme-poverty-to-fall-below-10-of-world-population-for-first-time" }, "points": "9 points", "time_ago": { "text": "2 hours ago", "href": "https://news.ycombinator.com/item?id=10352189" }, "username": { "text": "hliyan", "href": "https://news.ycombinator.com/user?id=hliyan" } },

Broad crawl usages

Broad crawl usages• News analysis

Broad crawl usages• News analysis• Topical crawling

Broad crawl usages• News analysis• Topical crawling• Plagiarism detection

Broad crawl usages• News analysis• Topical crawling• Plagiarism detection• Sentiment analysis (popularity, likability)

Broad crawl usages• News analysis• Topical crawling• Plagiarism detection• Sentiment analysis (popularity, likability)• Due diligence (profile/business data)

Broad crawl usages• News analysis• Topical crawling• Plagiarism detection• Sentiment analysis (popularity, likability)• Due diligence (profile/business data)• Lead generation (extracting contact
information)

Broad crawl usages• News analysis• Topical crawling• Plagiarism detection• Sentiment analysis (popularity, likability)• Due diligence (profile/business data)• Lead generation (extracting contact
information)• Track criminal activity & find lost persons
(DARPA)

Saatchi Global Gallery Guide

Saatchi Global Gallery Guide• www.globalgalleryguide.com
• Discover 11K online galleries.

Saatchi Global Gallery Guide• www.globalgalleryguide.com
• Discover 11K online galleries.
• Extract general information, art samples, descriptions.

Saatchi Global Gallery Guide• www.globalgalleryguide.com
• Discover 11K online galleries.
• Extract general information, art samples, descriptions.
• NLP-based extraction.

Saatchi Global Gallery Guide• www.globalgalleryguide.com
• Discover 11K online galleries.
• Extract general information, art samples, descriptions.
• NLP-based extraction.
• Find more galleries on the web.

Task

Task• Spanish web: hosts and their sizes statistics.

Task• Spanish web: hosts and their sizes statistics.• Only .es ccTLD.

Task• Spanish web: hosts and their sizes statistics.• Only .es ccTLD.• Breadth-first strategy:

Task• Spanish web: hosts and their sizes statistics.• Only .es ccTLD.• Breadth-first strategy: • first 1-click environ,

Task• Spanish web: hosts and their sizes statistics.• Only .es ccTLD.• Breadth-first strategy: • first 1-click environ, • 2,

Task• Spanish web: hosts and their sizes statistics.• Only .es ccTLD.• Breadth-first strategy: • first 1-click environ, • 2,• 3,

Task• Spanish web: hosts and their sizes statistics.• Only .es ccTLD.• Breadth-first strategy: • first 1-click environ, • 2,• 3,• …

Task• Spanish web: hosts and their sizes statistics.• Only .es ccTLD.• Breadth-first strategy: • first 1-click environ, • 2,• 3,• …
• Finishing condition: 100 docs from host max., all hosts

Task• Spanish web: hosts and their sizes statistics.• Only .es ccTLD.• Breadth-first strategy: • first 1-click environ, • 2,• 3,• …
• Finishing condition: 100 docs from host max., all hosts
• Low costs.

Spanish, Russian and world Web, 2012
Sources: OECD Communications Outlook 2013, statdom.ru * - current period (October 2015)
Domains Web servers Hosts DMOZ*
Spanish (.es) 1,5M 280K 4,2M 122K
Russian (.ru, .рф, .su) 4,8M 2,6M ? 105K
World 233M 62M 890M 1,7

Solution

Solution• Scrapy (based on Twisted) - async
network operations.

Solution• Scrapy (based on Twisted) - async
network operations.
• Apache Kafka - data bus (offsets, partitioning).

Solution• Scrapy (based on Twisted) - async
network operations.
• Apache Kafka - data bus (offsets, partitioning).
• Apache HBase - storage (random access, linear scanning, scalability).

Solution• Scrapy (based on Twisted) - async
network operations.
• Apache Kafka - data bus (offsets, partitioning).
• Apache HBase - storage (random access, linear scanning, scalability).
• Snappy - efficient compression algorithm for IO-bounded applications.

Architecture
Kafka topic
SW Crawling strategy workers
Storage workersDB

1. Big and small hosts problem

1. Big and small hosts problem
• Queue is flooded with URLs from the same host.

1. Big and small hosts problem
• Queue is flooded with URLs from the same host.
• → underuse of spider resources.

1. Big and small hosts problem
• Queue is flooded with URLs from the same host.
• → underuse of spider resources.
• additional per-host (per-IP) queue and metering algorithm.

1. Big and small hosts problem
• Queue is flooded with URLs from the same host.
• → underuse of spider resources.
• additional per-host (per-IP) queue and metering algorithm.
• URLs from big hosts are cached in memory.

2. DDoS DNS service Amazon AWS

2. DDoS DNS service Amazon AWS
Breadth-first strategy →

2. DDoS DNS service Amazon AWS
Breadth-first strategy → first visiting of unknown hosts →

2. DDoS DNS service Amazon AWS
Breadth-first strategy → first visiting of unknown hosts → generating huge amount of DNS reqs.

2. DDoS DNS service Amazon AWS
Breadth-first strategy → first visiting of unknown hosts → generating huge amount of DNS reqs.

2. DDoS DNS service Amazon AWS
Breadth-first strategy → first visiting of unknown hosts → generating huge amount of DNS reqs.

2. DDoS DNS service Amazon AWS
Breadth-first strategy → first visiting of unknown hosts → generating huge amount of DNS reqs.
Recursive DNS server

2. DDoS DNS service Amazon AWS
Breadth-first strategy → first visiting of unknown hosts → generating huge amount of DNS reqs.
Recursive DNS server • on every spider node,

2. DDoS DNS service Amazon AWS
Breadth-first strategy → first visiting of unknown hosts → generating huge amount of DNS reqs.
Recursive DNS server • on every spider node,• upstream to Verizon &
OpenDNS.

2. DDoS DNS service Amazon AWS
Breadth-first strategy → first visiting of unknown hosts → generating huge amount of DNS reqs.
Recursive DNS server • on every spider node,• upstream to Verizon &
OpenDNS.We used dnsmasq.

3. Tuning Scrapy thread pool for efficient DNS resolution

3. Tuning Scrapy thread pool for efficient DNS resolution• OS DNS resolver,

3. Tuning Scrapy thread pool for efficient DNS resolution• OS DNS resolver,• blocking calls,

3. Tuning Scrapy thread pool for efficient DNS resolution• OS DNS resolver,• blocking calls,• thread pool to
resolve DNS name to IP.

3. Tuning Scrapy thread pool for efficient DNS resolution• OS DNS resolver,• blocking calls,• thread pool to
resolve DNS name to IP.

3. Tuning Scrapy thread pool for efficient DNS resolution• OS DNS resolver,• blocking calls,• thread pool to
resolve DNS name to IP.
• numerous errors and timeouts 🆘

3. Tuning Scrapy thread pool for efficient DNS resolution• OS DNS resolver,• blocking calls,• thread pool to
resolve DNS name to IP.
• numerous errors and timeouts 🆘
• A patch for thread pool size and timeout adjustment.

4. Overloaded HBase region servers during state check
3Tb of metadata. URLs, timestamps,… 275 b/doc

4. Overloaded HBase region servers during state check• 10^3 links per doc,
3Tb of metadata. URLs, timestamps,… 275 b/doc
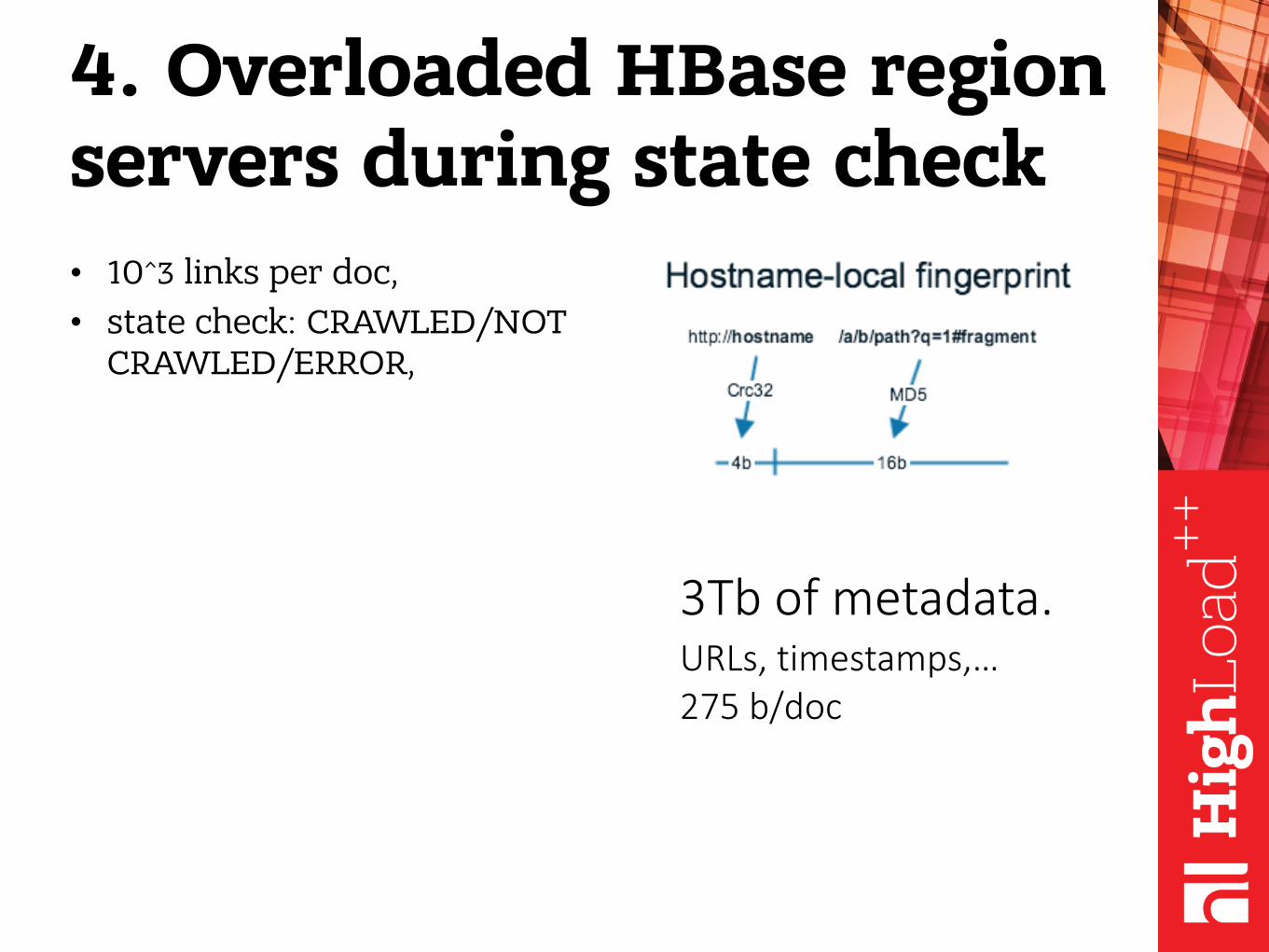
4. Overloaded HBase region servers during state check• 10^3 links per doc,• state check: CRAWLED/NOT
CRAWLED/ERROR,
3Tb of metadata. URLs, timestamps,… 275 b/doc

4. Overloaded HBase region servers during state check• 10^3 links per doc,• state check: CRAWLED/NOT
CRAWLED/ERROR,• HDDs.
3Tb of metadata. URLs, timestamps,… 275 b/doc

4. Overloaded HBase region servers during state check• 10^3 links per doc,• state check: CRAWLED/NOT
CRAWLED/ERROR,• HDDs.
• Small volume 🆗
3Tb of metadata. URLs, timestamps,… 275 b/doc

4. Overloaded HBase region servers during state check• 10^3 links per doc,• state check: CRAWLED/NOT
CRAWLED/ERROR,• HDDs.
• Small volume 🆗
• With ⬆table size, response times ⬆🆘 3Tb of metadata.
URLs, timestamps,… 275 b/doc

4. Overloaded HBase region servers during state check• 10^3 links per doc,• state check: CRAWLED/NOT
CRAWLED/ERROR,• HDDs.
• Small volume 🆗
• With ⬆table size, response times ⬆🆘
• Disk queue ⬆3Tb of metadata. URLs, timestamps,… 275 b/doc

4. Overloaded HBase region servers during state check• 10^3 links per doc,• state check: CRAWLED/NOT
CRAWLED/ERROR,• HDDs.
• Small volume 🆗
• With ⬆table size, response times ⬆🆘
• Disk queue ⬆• Host-local fingerprint
function for keys in HBase.
3Tb of metadata. URLs, timestamps,… 275 b/doc

4. Overloaded HBase region servers during state check• 10^3 links per doc,• state check: CRAWLED/NOT
CRAWLED/ERROR,• HDDs.
• Small volume 🆗
• With ⬆table size, response times ⬆🆘
• Disk queue ⬆• Host-local fingerprint
function for keys in HBase.• Tuning HBase block cache
to fit average host states into one block.
3Tb of metadata. URLs, timestamps,… 275 b/doc

5. Intensive network traffic from workers to services

5. Intensive network traffic from workers to services• Throughput
between workers and Kafka/HBase ~ 1Gbit/s.

5. Intensive network traffic from workers to services• Throughput
between workers and Kafka/HBase ~ 1Gbit/s.
• Thrift compact protocol for HBase

5. Intensive network traffic from workers to services• Throughput
between workers and Kafka/HBase ~ 1Gbit/s.
• Thrift compact protocol for HBase
• Message compression in Kafka with Snappy

6. Further query and traffic optimizations to HBase

6. Further query and traffic optimizations to HBase• State check: lots of
reqs and network

6. Further query and traffic optimizations to HBase• State check: lots of
reqs and network• Consistency

6. Further query and traffic optimizations to HBase• State check: lots of
reqs and network• Consistency• Local state cache
in strategy worker.

6. Further query and traffic optimizations to HBase• State check: lots of
reqs and network• Consistency• Local state cache
in strategy worker.• For consistency,
spider log was partitioned by host.

State cache

State cache• All ops are batched:

State cache• All ops are batched:
– If no key in cache→ read HBase

State cache• All ops are batched:
– If no key in cache→ read HBase
– every ~4K docs → flush

State cache• All ops are batched:
– If no key in cache→ read HBase
– every ~4K docs → flush
• Close to 3M (~1Gb) elms → flush & cleanup

State cache• All ops are batched:
– If no key in cache→ read HBase
– every ~4K docs → flush
• Close to 3M (~1Gb) elms → flush & cleanup
• Least-Recently-Used (LRU) 👍

Spider priority queue (slot)
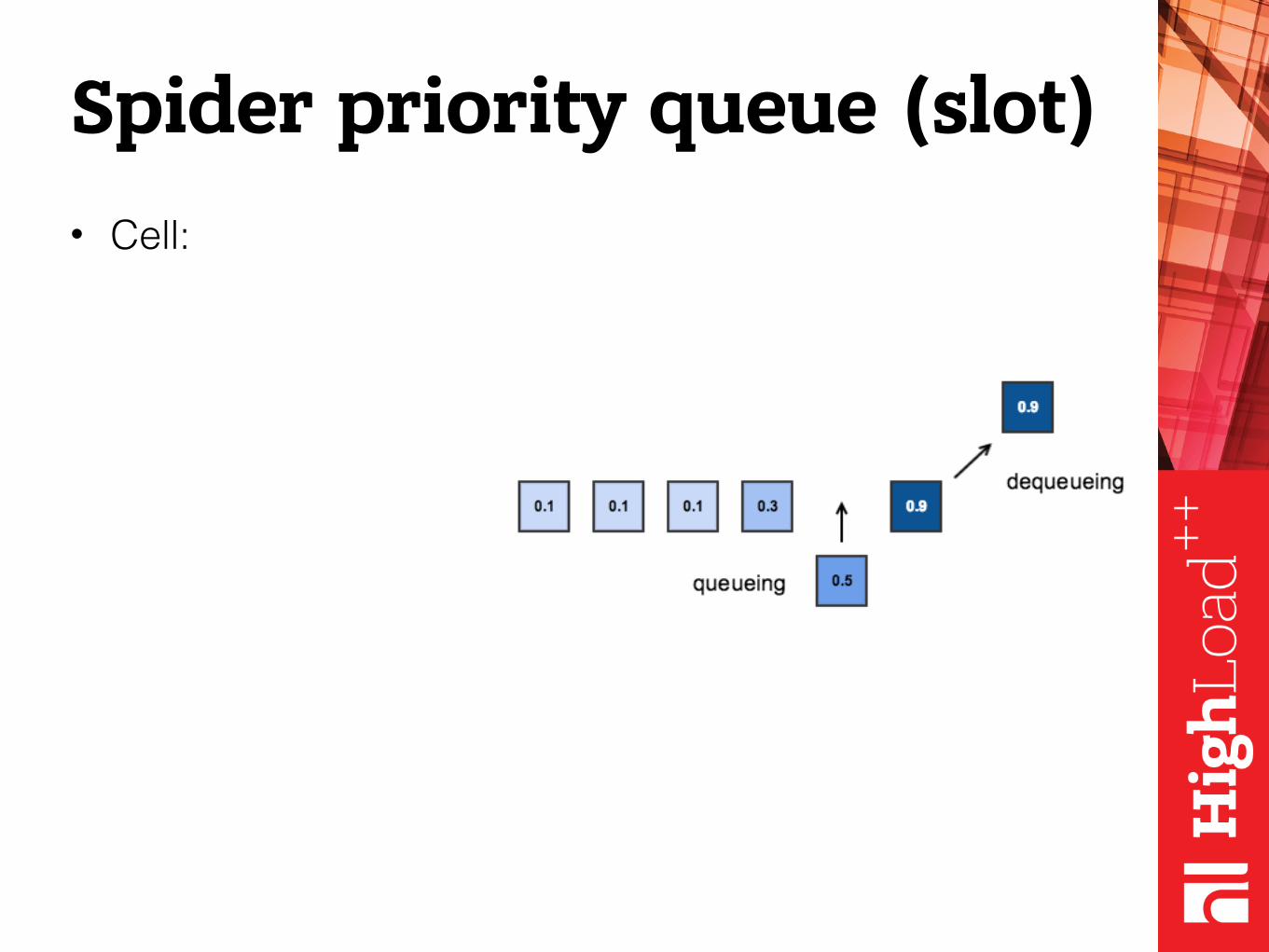
Spider priority queue (slot)• Cell:

Spider priority queue (slot)• Cell:
Array of: - fingerprint, - Crc32(hostname), - URL, - score
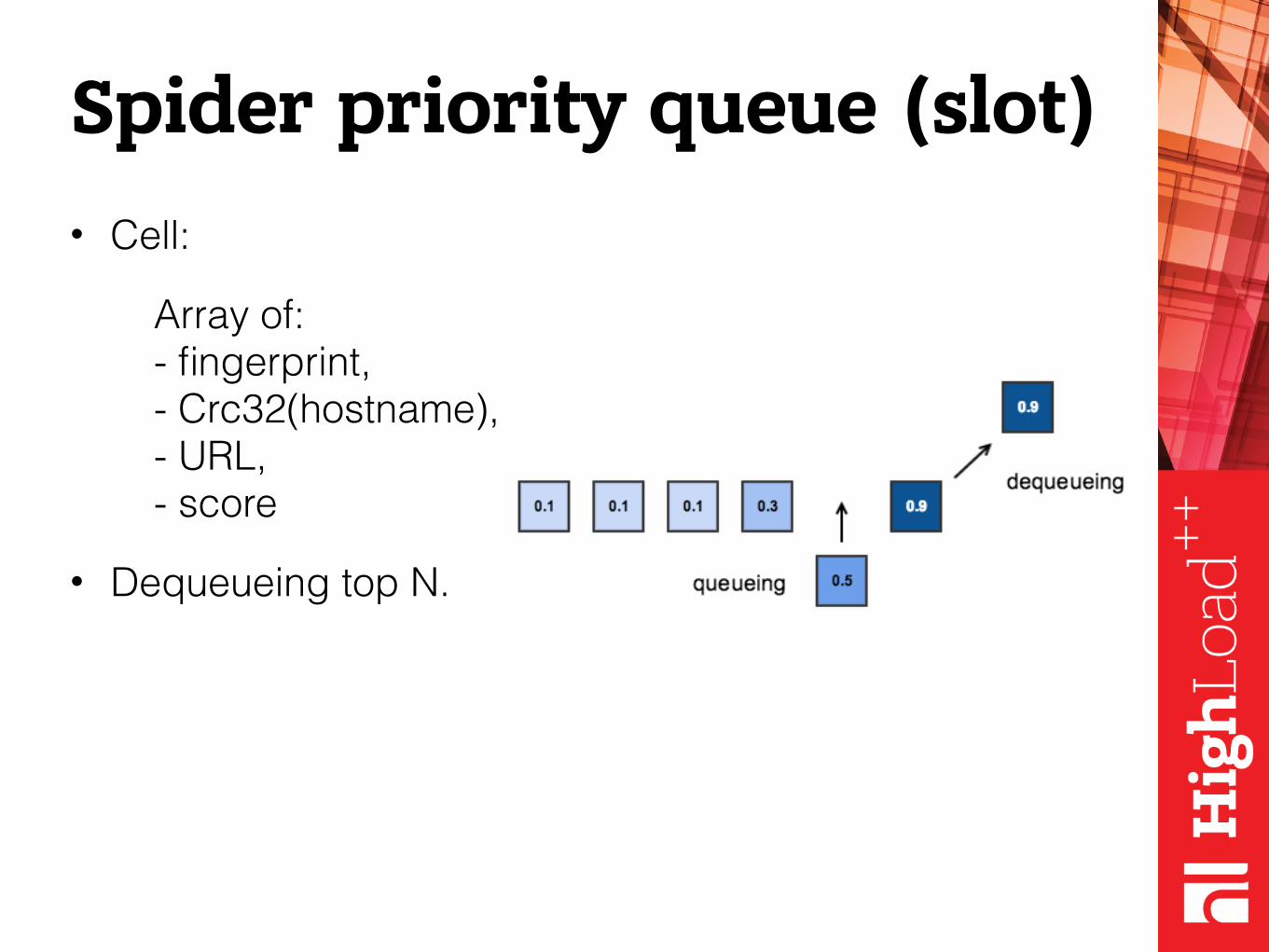
Spider priority queue (slot)• Cell:
Array of: - fingerprint, - Crc32(hostname), - URL, - score
• Dequeueing top N.

Spider priority queue (slot)• Cell:
Array of: - fingerprint, - Crc32(hostname), - URL, - score
• Dequeueing top N.
• Prone to huge hosts

Spider priority queue (slot)• Cell:
Array of: - fingerprint, - Crc32(hostname), - URL, - score
• Dequeueing top N.
• Prone to huge hosts
• Scoring model: document count per host.

7. Problem of big and small hosts (strikes back!)

7. Problem of big and small hosts (strikes back!)• Discovered few very
huge hosts (>20M docs)

7. Problem of big and small hosts (strikes back!)• Discovered few very
huge hosts (>20M docs)
• All queue partitions were flooded with huge hosts,

7. Problem of big and small hosts (strikes back!)• Discovered few very
huge hosts (>20M docs)
• All queue partitions were flooded with huge hosts,
• Two MapReduce jobs:

7. Problem of big and small hosts (strikes back!)• Discovered few very
huge hosts (>20M docs)
• All queue partitions were flooded with huge hosts,
• Two MapReduce jobs:– queue shuffling,

7. Problem of big and small hosts (strikes back!)• Discovered few very
huge hosts (>20M docs)
• All queue partitions were flooded with huge hosts,
• Two MapReduce jobs:– queue shuffling,– limit all hosts to
100 docs MAX.

Hardware requirements

Hardware requirements• Single-thread Scrapy spider →
1200 pages/min. from ~100 websites in parallel.

Hardware requirements• Single-thread Scrapy spider →
1200 pages/min. from ~100 websites in parallel.
• Spiders to workers ratio is 4:1 (without content)

Hardware requirements• Single-thread Scrapy spider →
1200 pages/min. from ~100 websites in parallel.
• Spiders to workers ratio is 4:1 (without content)
• 1 Gb of RAM for every SW (state cache, tunable).

Hardware requirements• Single-thread Scrapy spider →
1200 pages/min. from ~100 websites in parallel.
• Spiders to workers ratio is 4:1 (without content)
• 1 Gb of RAM for every SW (state cache, tunable).
• Example:

Hardware requirements• Single-thread Scrapy spider →
1200 pages/min. from ~100 websites in parallel.
• Spiders to workers ratio is 4:1 (without content)
• 1 Gb of RAM for every SW (state cache, tunable).
• Example:
– 12 spiders ~ 14.4K pages/min.,

Hardware requirements• Single-thread Scrapy spider →
1200 pages/min. from ~100 websites in parallel.
• Spiders to workers ratio is 4:1 (without content)
• 1 Gb of RAM for every SW (state cache, tunable).
• Example:
– 12 spiders ~ 14.4K pages/min.,
– 3 SW and 3 DB workers,

Hardware requirements• Single-thread Scrapy spider →
1200 pages/min. from ~100 websites in parallel.
• Spiders to workers ratio is 4:1 (without content)
• 1 Gb of RAM for every SW (state cache, tunable).
• Example:
– 12 spiders ~ 14.4K pages/min.,
– 3 SW and 3 DB workers,
– Total 18 cores.

Software requirements
CDH (100% Open source Hadoop package)

Software requirements
• Apache HBase,
CDH (100% Open source Hadoop package)

Software requirements
• Apache HBase,
• Apache Kafka,CDH (100% Open source Hadoop package)

Software requirements
• Apache HBase,
• Apache Kafka,
• Python 2.7+,CDH (100% Open source Hadoop package)

Software requirements
• Apache HBase,
• Apache Kafka,
• Python 2.7+,
• Scrapy 0.24+,
CDH (100% Open source Hadoop package)

Software requirements
• Apache HBase,
• Apache Kafka,
• Python 2.7+,
• Scrapy 0.24+,
• DNS Service.
CDH (100% Open source Hadoop package)

Maintaining Cloudera Hadoop on Amazon EC2

Maintaining Cloudera Hadoop on Amazon EC2• CDH is very sensitive to free space on root
partition, parcels, and storage of Cloudera Manager.

Maintaining Cloudera Hadoop on Amazon EC2• CDH is very sensitive to free space on root
partition, parcels, and storage of Cloudera Manager.
• We’ve moved it using symbolic links to separate EBS partition.

Maintaining Cloudera Hadoop on Amazon EC2• CDH is very sensitive to free space on root
partition, parcels, and storage of Cloudera Manager.
• We’ve moved it using symbolic links to separate EBS partition.
• EBS should be at least 30Gb, base IOPS should be enough.

Maintaining Cloudera Hadoop on Amazon EC2• CDH is very sensitive to free space on root
partition, parcels, and storage of Cloudera Manager.
• We’ve moved it using symbolic links to separate EBS partition.
• EBS should be at least 30Gb, base IOPS should be enough.
• Initial hardware was 3 x m3.xlarge (4 CPU, 15Gb, 2x40 SSD).

Maintaining Cloudera Hadoop on Amazon EC2• CDH is very sensitive to free space on root
partition, parcels, and storage of Cloudera Manager.
• We’ve moved it using symbolic links to separate EBS partition.
• EBS should be at least 30Gb, base IOPS should be enough.
• Initial hardware was 3 x m3.xlarge (4 CPU, 15Gb, 2x40 SSD).
• After one week of crawling, we ran out of space, and started to move DataNodes to d2.xlarge (4 CPU, 30.5Gb, 3x2Tb HDD).

Spanish (.es) internet crawl results

Spanish (.es) internet crawl results• fnac.es, rakuten.es, adidas.es,
equiposdefutbol2014.es, druni.es, docentesconeducacion.es - are the biggest websites

Spanish (.es) internet crawl results• fnac.es, rakuten.es, adidas.es,
equiposdefutbol2014.es, druni.es, docentesconeducacion.es - are the biggest websites
• 68.7K domains found (~600K expected),

Spanish (.es) internet crawl results• fnac.es, rakuten.es, adidas.es,
equiposdefutbol2014.es, druni.es, docentesconeducacion.es - are the biggest websites
• 68.7K domains found (~600K expected),
• 46.5M crawled pages overall,

Spanish (.es) internet crawl results• fnac.es, rakuten.es, adidas.es,
equiposdefutbol2014.es, druni.es, docentesconeducacion.es - are the biggest websites
• 68.7K domains found (~600K expected),
• 46.5M crawled pages overall,
• 1.5 months,

Spanish (.es) internet crawl results• fnac.es, rakuten.es, adidas.es,
equiposdefutbol2014.es, druni.es, docentesconeducacion.es - are the biggest websites
• 68.7K domains found (~600K expected),
• 46.5M crawled pages overall,
• 1.5 months,
• 22 websites with more than 50M pages

where are the rest of web servers?!

Bow-tie modelA. Broder et al. / Computer Networks 33 (2000) 309-320

Y. Hirate, S. Kato, and H. Yamana, Web Structure in 2005
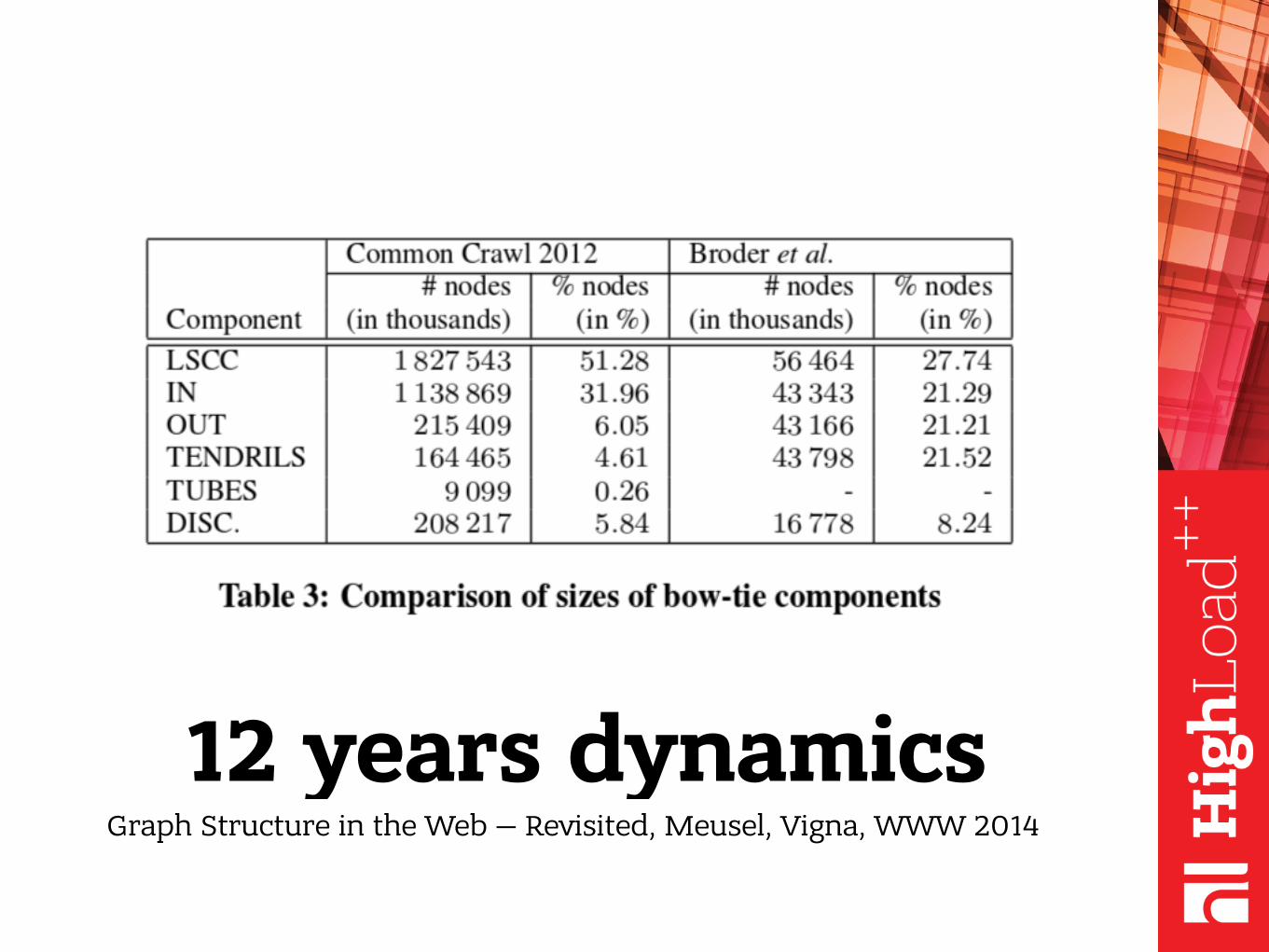
12 years dynamicsGraph Structure in the Web — Revisited, Meusel, Vigna, WWW 2014

Main features

Main features• Online operation: scheduling of new batch,
updating of DB state.

Main features• Online operation: scheduling of new batch,
updating of DB state.
• Storage abstraction: write your own backend (sqlalchemy, HBase is included).

Main features• Online operation: scheduling of new batch,
updating of DB state.
• Storage abstraction: write your own backend (sqlalchemy, HBase is included).
• Canonical URLs resolution abstraction: each document has many URLs, which to use?

Main features• Online operation: scheduling of new batch,
updating of DB state.
• Storage abstraction: write your own backend (sqlalchemy, HBase is included).
• Canonical URLs resolution abstraction: each document has many URLs, which to use?
• Scrapy ecosystem: good documentation, big community, ease of customization.

Distributed Frontera features

Distributed Frontera features• Communication layer is Apache Kafka: topic
partitioning, offsets mechanism.

Distributed Frontera features• Communication layer is Apache Kafka: topic
partitioning, offsets mechanism.
• Crawling strategy abstraction: crawling goal, url ordering, scoring model is coded in separate module.

Distributed Frontera features• Communication layer is Apache Kafka: topic
partitioning, offsets mechanism.
• Crawling strategy abstraction: crawling goal, url ordering, scoring model is coded in separate module.
• Polite by design: each website is downloaded by at most one spider.

Distributed Frontera features• Communication layer is Apache Kafka: topic
partitioning, offsets mechanism.
• Crawling strategy abstraction: crawling goal, url ordering, scoring model is coded in separate module.
• Polite by design: each website is downloaded by at most one spider.
• Python: workers, spiders.

References• Frontera. https://github.com/scrapinghub/frontera
• Distributed extension. https://github.com/scrapinghub/distributed-frontera
• Documentation:
– http://frontera.readthedocs.org/
– http://distributed-frontera.readthedocs.org/
• Google groups: Frontera (https://goo.gl/ak9546)

Future plans

Future plans• Lighter version, without HBase and Kafka.
Communicating using sockets.

Future plans• Lighter version, without HBase and Kafka.
Communicating using sockets.
• Revisiting strategy out-of-box.

Future plans• Lighter version, without HBase and Kafka.
Communicating using sockets.
• Revisiting strategy out-of-box.
• Watchdog solution: tracking website content changes.

Future plans• Lighter version, without HBase and Kafka.
Communicating using sockets.
• Revisiting strategy out-of-box.
• Watchdog solution: tracking website content changes.
• PageRank or HITS strategy.

Future plans• Lighter version, without HBase and Kafka.
Communicating using sockets.
• Revisiting strategy out-of-box.
• Watchdog solution: tracking website content changes.
• PageRank or HITS strategy.
• Own HTML and URL parsers.

Future plans• Lighter version, without HBase and Kafka.
Communicating using sockets.
• Revisiting strategy out-of-box.
• Watchdog solution: tracking website content changes.
• PageRank or HITS strategy.
• Own HTML and URL parsers.
• Integration into Scrapinghub services.

Future plans• Lighter version, without HBase and Kafka.
Communicating using sockets.
• Revisiting strategy out-of-box.
• Watchdog solution: tracking website content changes.
• PageRank or HITS strategy.
• Own HTML and URL parsers.
• Integration into Scrapinghub services.
• Testing on larger volumes.

Run your business using Frontera

Run your business using Frontera
SCALABLE

Run your business using Frontera
SCALABLE
OPEN

Run your business using Frontera
SCALABLE
OPEN CUSTOMIZABLE

Run your business using Frontera
Made in Scrapinghub (authors of Scrapy)
SCALABLE
OPEN CUSTOMIZABLE

Здесь может быть ВАШ код!

Здесь может быть ВАШ код!
• Web scale crawler,

Здесь может быть ВАШ код!
• Web scale crawler,
• Historically first attempt in Python,

Здесь может быть ВАШ код!
• Web scale crawler,
• Historically first attempt in Python,
• Truly resource-intensive task: CPU, network, disks.

























