Embed Size (px)
Citation preview

Cloud Native Data Pipelines
Sid Anand QCon Shanghai & Tokyo 2016
1

About Me
2
Work [ed | s] @
Committer & PPMC on
Father of 2
Co-Chair for
Apache Airflow

3
ライブ中継

Agari
4
What We Do!

Agari : What We Do
5

6
Agari : What We Do

7
Agari : What We Do

8
Agari : What We Do

9
Agari : What We Do

10
Enterprise Customers
email metadata
apply trust
models
email md + trust score
Agari’s Previous EP Version
Agari : What We Do
Batch

11
email metadata
apply trust
modelsemail md + trust score
Agari’s Current EP VersionEnterprise Customers
Agari : What We Do
Near-real time
Quarantine

Data PipelinesBI vs Predictive
12

Data Pipelines (BI)
13
WebServers
OLTPDB
DataWarehouse
Repor6ngTools
QueryBrowsers
ETL(batch)MySQL,Oracle,Cassandra
Terradata,RedShi;BigQuery

Data Pipelines (Predictive)
14
OLTPDBorcache
ETL(batchorstreaming)
MySQL,Oracle,Cassandra,Redis
Spark,Flink,Beam,Storm
WebServers
DataProductsRanking(Search,NewsFeed),RecommenderProducts,FraudDetecGon/PrevenGon
DataSource

Data Products
15

BI Predictive
Common Focus of this talk
Data Pipelines
16
WebServers
OLTPDB
DataWarehouse
Repor6ngTools
QueryBrowsers
ETL(batch)MySQL,Oracle,Cassandra
Terradata,RedShi;BigQuery
OLTPDBorcache
ETL(batchorstreaming)
MySQL,Oracle,Cassandra,Redis
Spark,Flink,Beam,Storm
WebServers
Ranking(Search,NewsFeed),RecommenderProducts,FraudDetecGon/PrevenGon
DataSource

MotivationCloud Native Data Pipelines
17

Cloud Native Data Pipelines
18
Big Data Companies like LinkedIn, Facebook, Twitter, & Google build custom, large scale data pipelines that run in their own Data Centers

Cloud Native Data Pipelines
19
Big Data Companies like LinkedIn, Facebook, Twitter, & Google build custom, large scale data pipelines that run in their own Data Centers
Most start-ups run in the public cloud. Can they leverage aspects of the public cloud to build comparable pipelines?

Cloud Native Data Pipelines
20
Cloud Native Techniques
Open Source Technogies
Custom Data Pipeline Stacks seen in Big Data companies
~

Design GoalsDesirable Qualities of a Resilient Data Pipeline
21

22
Desirable Qualities of a Resilient Data Pipeline
OperabilityCorrectness
Timeliness Cost

23
Desirable Qualities of a Resilient Data Pipeline
OperabilityCorrectness
Timeliness Cost
• Data Integrity (no loss, etc…) • Expected data distributions
• All output within time-bound SLAs
• Fine-grained Monitoring & Alerting of Correctness & Timeliness SLAs
• Quick Recoverability
• Pay-as-you-go

Quickly Recoverable
24
• Bugs happen!
• Bugs in Predictive Data Pipelines have a large blast radius
• Optimize for MTTR

Predictive Analytics @ AgariUse Cases
25

Use Cases
26
Apply trust models (message scoring)
batch + near real time
Build trust models
batch
(Enterprise Protect)

Use-Case : Message Scoring (batch)Batch Pipeline Architecture
27

Use-Case : Message Scoring
28
enterprise Aenterprise Benterprise C
S3
S3 uploads an Avro file every 15 minutes

Use-Case : Message Scoring
29
enterprise Aenterprise Benterprise C
S3
Airflow kicks of a Spark message scoring job
every hour (EMR)

Use-Case : Message Scoring
30
enterprise Aenterprise Benterprise C
S3
Spark job writes scored messages and stats to
another S3 bucket
S3

Use-Case : Message Scoring
31
enterprise Aenterprise Benterprise C
S3
This triggers SNS/SQS messages events
S3
SNS
SQS

Use-Case : Message Scoring
32
enterprise Aenterprise Benterprise C
S3
An Autoscale Group (ASG) of Importers spins up when it detects SQS
messages
S3
SNS
SQS
Importers
ASG

33
enterprise Aenterprise Benterprise C
S3
The importers rapidly ingest scored messages and aggregate statistics into
the DB
S3
SNS
SQS
Importers
ASGDB
Use-Case : Message Scoring

34
enterprise Aenterprise Benterprise C
S3
Users receive alerts of untrusted emails & can review them in
the web app
S3
SNS
SQS
Importers
ASGDB
Use-Case : Message Scoring

35
enterprise Aenterprise Benterprise C
S3 S3
SNS
SQS
Importers
ASGDB
Airflow manages the entire process
Use-Case : Message Scoring

Tackling Cost & TimelinessLeveraging the AWS Cloud
36

Tackling Cost
37
Between Daily Runs During Daily Runs
When running daily, for 23 hours of a day, we didn’t pay for instances in the ASG or EMR
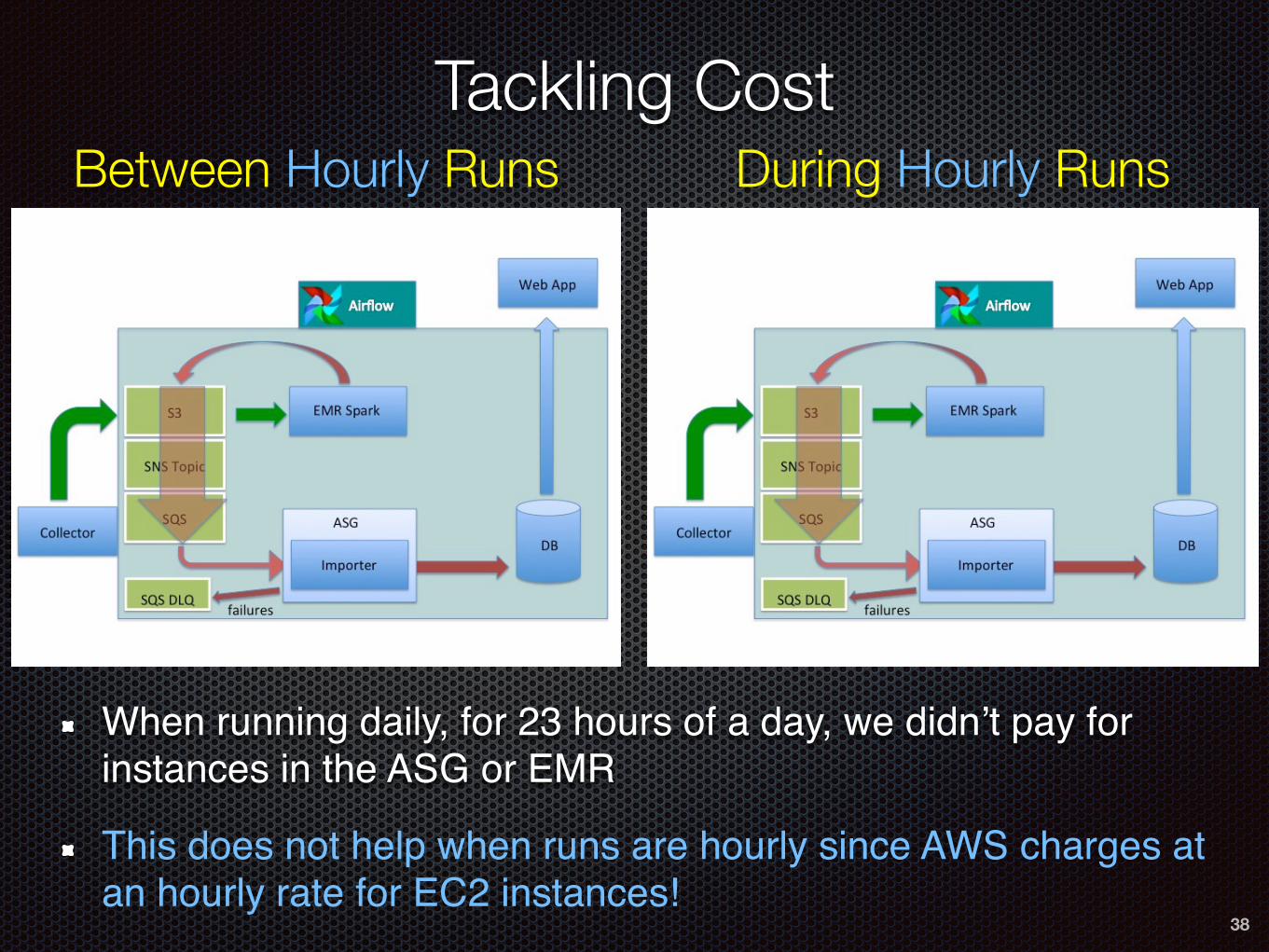
Tackling Cost
38
Between Hourly Runs During Hourly Runs
When running daily, for 23 hours of a day, we didn’t pay for instances in the ASG or EMR
This does not help when runs are hourly since AWS charges at an hourly rate for EC2 instances!

Tackling TimelinessAuto Scaling Group (ASG)
39

ASG - Overview
40
What is it?
A means to automatically scale out/in clusters to handle variable load/traffic
A means to keep a cluster/service of a fixed size always up

ASG - Data Pipeline
41
importer
importer
importer
importer
Importer ASG
scale out / inSQS
DB

42
Sent
CPU
ACKd/Recvd
CPU-based auto-scaling is good at scaling in/out to keep the average CPU constant
ASG : CPU-based

ASG : CPU-based
43
Sent
CPU
Recv
Premature Scale-in
Premature Scale-in:
• The CPU drops to noise-levels before all messages are consumed
• This causes scale in to occur while the last few messages are still being committed

44
Scale-out: When Visible Messages > 0 (a.k.a. when queue depth > 0)
Scale-in: When Invisible Messages = 0 (a.k.a. when the last in-flight message is ACK’d)
This causes the ASG to grow
This causes the ASG to shrink
ASG : Queue-based

45
ASG : Queue-based
Shoyu Koto Da!!!!しょうゆうことだ!!

46
Desirable Qualities of a Resilient Data Pipeline
OperabilityCorrectness
Timeliness Cost• ASG • EMR Spark
Daily • ASG • EMR Spark Hourly ASG • No Cost Savings

Tackling Operability & CorrectnessLeveraging Tooling
47

48
A simple way to author and manage workflows
Provides visual insight into the state & performance of workflow runs
Integrates with our alerting and monitoring tools
Tackling Operability : Requirements

Apache AirflowWorkflow Automation & Scheduling
49

50
Airflow: Author DAGs in Python! No need to bundle many config files!
Apache Airflow - Authoring DAGs

51
Airflow: Visualizing a DAG
Apache Airflow - Authoring DAGs

52
Airflow: It’s easy to manage multiple DAGs
Apache Airflow - Managing DAGs

Apache Airflow - Perf. Insights
53
Airflow: Gantt chart view reveals the slowest tasks for a run!

54
Apache Airflow - Perf. InsightsAirflow: Task Duration chart view show task completion time trends!

55
Airflow: …And easy to integrate with Ops tools!Apache Airflow - Alerting

56
Apache Airflow - Correctness

57
Desirable Qualities of a Resilient Data Pipeline
OperabilityCorrectness
Timeliness Cost

Use-Case : Message Scoring (near-real time)NRT Pipeline Architecture
58

Use-Case : Message Scoring
59
enterprise Aenterprise Benterprise C
Kinesis batch put every second
K

Use-Case : Message Scoring
60
enterprise Aenterprise Benterprise C
K
As ASG of scorers is scaled up to one process per core per kinesis shard
Scorers
ASG

Use-Case : Message Scoring
61
enterprise Aenterprise Benterprise C
KScorers
ASG
KinesisScorers apply the trust model and send scored messages downstream

Use-Case : Message Scoring
62
enterprise Aenterprise Benterprise C
KScorers
ASG
Kinesis
Importers
ASG
As ASG of importers is scaled up to rapidly import messages
DB

Use-Case : Message Scoring
63
enterprise Aenterprise Benterprise C
KScorers
ASG
Kinesis
Importers
ASG
Imported messages are also consumed by the
alerter
DB
K
Alerters
ASG

Use-Case : Message Scoring
64
enterprise Aenterprise Benterprise C
KScorers
ASG
Kinesis
Importers
ASG
Imported messages are also consumed by the
alerter
DB
K
Alerters
ASG
Quarantine Email

InnovationsNRT Pipeline Architecture
65

Apache AvroWhat is Avro?
66

67
What is Avro?
Avro is a self-describing serialization format that supports
primitive data types : int, long, boolean, float, string, bytes, etc…
complex data types : records, arrays, unions, maps, enums, etc…
many language bindings : Java, Scala, Python, Ruby, etc…

68
What is Avro?
Avro is a self-describing serialization format that supports
primitive data types : int, long, boolean, float, string, bytes, etc…
complex data types : records, arrays, unions, maps, enums, etc…
many language bindings : Java, Scala, Python, Ruby, etc…
The most common format for storing structured Big Data at rest in HDFS, S3, Google Cloud Storage, etc…
Supports Schema Evolution!

69
Avro Schema Example
{"namespace": "agari", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }

70
{"namespace": "agari", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }
complex type (record)
Avro Schema Example

71
{"namespace": "agari", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }
complex type (record)Schema name : User
Avro Schema Example

72
{"namespace": "agari", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }
complex type (record)Schema name : User
3 fields in the record: 1 required, 2 optional
Avro Schema Example

73
{"namespace": "agari", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }
Data
x 1,000,000,000
Avro Schema Data File Example
Schema
Data
0.0001 %
99.999 %
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data

74
{"namespace": "agari", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }
Binary Data block
Avro Schema Streaming Example
Schema
Data
99 %
1 %
Data

75
{"namespace": "agari", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }
Binary Data block
Avro Schema Streaming Example
Schema
Data
99 %
1 %
Data
OVERHEAD!!

76
Schema Registry
(Lambda)
Innovation 1 : Avro Schema Registry
{"namespace": "agari", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }
register_schema
Message Producer (P)

77
Schema Registry
(Lambda)
Innovation 1 : Avro Schema Registry
register_schema returns a UUID
Message Producer (P)

78
Schema Registry
(Lambda)
Innovation 1 : Avro Schema Registry
Message Producer sends UUID +
Message Producer (P)
Data
Message Consumer (C)

79
Schema Registry
(Lambda)
Innovation 1 : Avro Schema Registry
Message Producer (P)
Data
Message Consumer (C)
getSchemaById (UUID)

80
Schema Registry
(Lambda)
Innovation 1 : Avro Schema Registry
Message Producer (P)
Data
Message Consumer (C)
getSchemaById (UUID){"namespace": "agari", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }

81
Schema Registry
(Lambda)
Innovation 1 : Avro Schema Registry
Message Producer (P)
Message Consumer (C)
getSchemaById (UUID){"namespace": "agari", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }
Message Consumers • download & cache the schema
• then decode the data

82
enterprise Aenterprise Benterprise C
KScorers
ASG
Kinesis
Importers
ASG
Imported messages are also consumed by the
alerter
DB
K
Alerters
ASG
SR
SR
SR
Innovation 1 : Avro Schema Registry

83
The Architecture is composed of repeated patterns of :
ASG-based compute consumer
Kinesis transport streams (i.e. AWS’ managed “Kafka”)
A Lambda-based Avro Schema Registry
Innovation 2 : Repeatable Units
ComputeiKinesisi
ASGi
SR

84
You can chain these repeatable units together to make arbitrary DAGs (Directed Acyclic Graphs)
User Hashicorp’s Terraform to compose your DAG through automation
The example above is a simple Linear DAG with 3 units
Innovation 2 : Repeatable Units
ComputeiKinesisi
ASGi
SR
ComputeiKinesisi
ASGi
SR
ComputeiKinesisi
ASGi
SR

Airflow Job Reactively Scales
Innovation 3 : Reactive-Scaling (WIP)
85
enterprise Aenterprise Benterprise C
KScorers
ASG
Kinesis
Importers
ASGDB
K
Alerters
ASG
SR
SR
SR

86
If the ADR is triggered and a model build or code push was recently done to Compute 1, ADR will revert the last code or model push to ASG Compute 1
Innovation 4 : Anomaly-based Rollback (WIP)
ASG
Compute1 Compute2Kinesis
ASG
SR
Anomaly-detector&Reverter

Open Source Plans
87
Follow us to be notified when the following is open-sourced
• Avro Schema Registry
• Agari (Kinesis+ASG) scaling tool (Airflow Job)
• Anomaly-detector & Reverter
To be notified, follow @AgariEng & @r39132

Acknowledgments
88
• Vidur Apparao • Stephen Cattaneo • Jon Chase • Andrew Flury • William Forrester • Chris Haag • Mike Jones
• Scot Kennedy • Thede Loder • Paul Lorence • Kevin Mandich • Gabriel Ortiz • Jacob Rideout • Josh Yang • Julian Mehnle
None of this work would be possible without the contributions of the strong team below

Questions? (@r39132)
89
![Resilient Predictive Data Pipelines v4 - QCon London 2020 · Resilient Predictive Data Pipelines Sid Anand (@r39132) QCon London 2016 1. About Me 2 Work [ed | s] @ Maintainer on Report](https://img.dokumen.tips/doc/110x75/5ecd50d8d9022a55521a322e/resilient-predictive-data-pipelines-v4-qcon-london-2020-resilient-predictive-data.jpg)



























