
Quem está aí?
● Devs● DBAs● Téc. de infra● Estudantes● Entusiastas do
ramo● Curiosos

Short bio
● Professor de desenvolvimento Web e coordenador de EaD no IFMS campus Aquidauana
● Bacharel em Ciência da Computação (UEMS)
● Mestre em Ciência da Computação (UNICAMP)
● Especialista em docência (IFMS)● Desenvolvedor há 10 anos (UEMS,
Pinuts, DigithoBrasil, CASSEMS e IFMS)

Roteiro
● A Web como fonte de dados e informações● Falando a linguagem das páginas Web● O que é um Web Scraper?● Aplicações nos negócios● Aplicações na ciência● Questões legais e conclusões

A Web como fonte de dados e informações

…mas, o que é a Web?

O que é a Web?

O que é a Web?
O que é a Web?

O que é a Web?

A Web mudou o comportamento da humanidade

… quer um exemplo?

Vou pedir dinheiro pra mãe para pegar o ônibus pro centro
para ir na biblioteca fazer aquele trabalho de história...

Não esquece de pedir dinheiro para comprar folhas de almaço para
você poder copiar os textos.

Pfff... tá tirando? Vou xerocar!

Ah, muleque!

Hoje em dia...

Puts... onde eu vou achar conteúdo pro trabalho de filosofia?

Deixa de vacilo, garoto! Procura no Google!

#partiuGoogle

Falando a linguagem das páginas Web

Boa notícia: páginas Web são ricas!

Problema: páginas Web são ricas!

Extraindo trechos de páginas Web
● Páginas Web são baseadas em HTML● HTML → conjuntos de tags aninhadas● Estrutura parecida com uma árvore● XPath → linguagem de consulta a documentos
estruturados com linguagens baseadas em XML● Permite a navegação estratégica na árvore

//*[contains(@class, 'destaque')]//a/text()
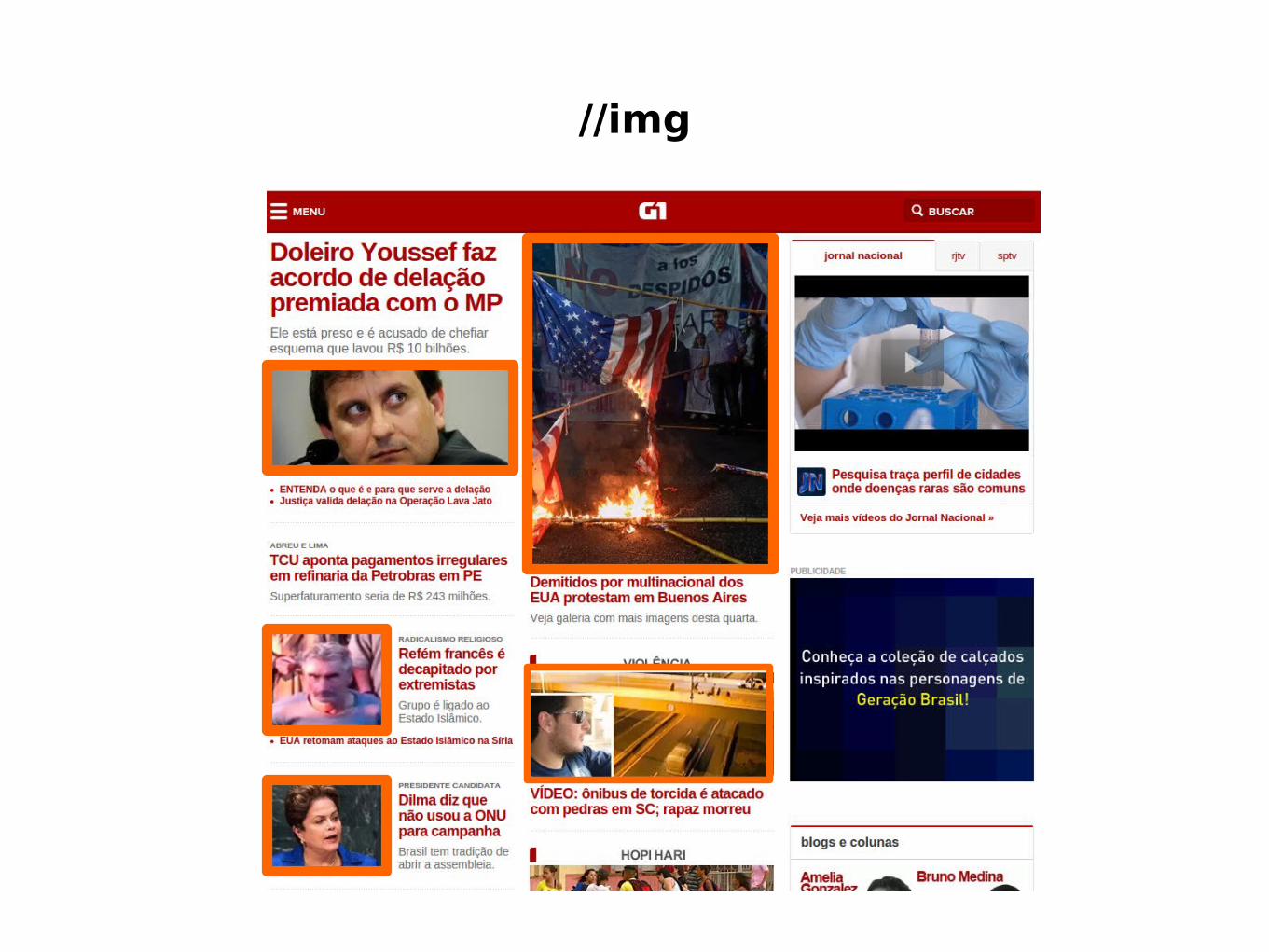
//img

O que é um Web Scraper?

Definição
Web Scraper → programa que realiza Web Scraping


Segundo a Wikipedia...
“Web scraping (web harvesting or web data extraction) is a computer software technique of extracting information from websites. Usually,
such software programs simulate human exploration of the World Wide Web by either implementing lowlevel Hypertext Transfer
Protocol (HTTP), or embedding a fullyfledged web browser, such as Internet Explorer or
Mozilla Firefox.”

Web Scraping via browser
● Uso de plugins/addons para consultar páginas com Xpath → Ex: XPath Helper, para o Chrome
● Uso de plugins/addons para planejar/criar esquemas de extração de conteúdo em páginas → Web Scraper, para o Chrome

Web Scraping via programação
● Uso de APIs para realizar conexões HTTP e aplicar consultas XPath em páginas →Ex: HTTPClient, HTMLCleaner, urllib3, lxml
● Uso de APIs para realizar Web Scraping em alto nível →Ex: Scrapy

Web Scraping com Java
String urlPagina = "http://g1.globo.com/index.html";
String xPathListaManchetes = "//*[contains(@class, 'destaque')]//a/text()";
ExemploWebCrawler crawler = new ExemploWebCrawler();
CloseableHttpClient clienteHTTP = crawler.criaClienteHTTP();
Object[] listaManchetes = crawler.pegaLista(clienteHTTP, urlPagina, xPathListaManchetes);
if (listaManchetes != null && listaManchetes.length > 1) {
for (Object manchete : listaManchetes) {
String textoManchete = String.valueOf(manchete).toUpperCase();
// faça alguma coisa...
}
}

Web Scraping com Java: Classe ExemploWebCrawler
public CloseableHttpClient criaClienteHTTP() {
return HttpClientBuilder.create().build();
}
public Object[] pegaLista(CloseableHttpClient cliente, String url, String xpath) {
Object[] resultados = new Object[0];
try {
HttpGet httpGet = new HttpGet(url);
HttpResponse response = cliente.execute(httpGet);
HttpEntity entidade = response.getEntity();
if (entidade != null) {
HtmlCleaner cleaner = new HtmlCleaner();
CleanerProperties propriedades = cleaner.getProperties();
propriedades.setAllowHtmlInsideAttributes(true);
propriedades.setAllowMultiWordAttributes(true);
propriedades.setRecognizeUnicodeChars(true);
propriedades.setOmitComments(true);
TagNode no = cleaner.clean(new InputStreamReader(entidade.getContent()));

Web Scraping com Java: Classe ExemploWebCrawler
try {
resultados = no.evaluateXPath(xpath);
} catch (org.htmlcleaner.XPatherException e) {
try {
Document documento = new DomSerializer(
new CleanerProperties()).createDOM(no);
XPath consulta = XPathFactory.newInstance().newXPath();
NodeList nosResultado = (NodeList) consulta.evaluate(
xpath, documento, XPathConstants.NODESET);
if (nosResultado != null) {
resultados = new Object[nosResultado.getLength()];
for (int i = 0; i < nosResultado.getLength(); i++) {
resultados[i] = nosResultado.item(i).getTextContent().trim();
StringWriter writer = new StringWriter();
StringEscapeUtils.unescapeHtml(writer,resultados[i].toString());

Web Scraping com Java: Classe ExemploWebCrawler
resultados[i] = writer.toString().replace("\n","");
}
}
} catch (Exception e1) {
e1.printStackTrace();
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
return resultados;
}

Web Scraping com Python
import urllib3
import lxml.html
import re
consulta_xpath = "//*[contains(@class, 'destaque')]//a/text()"
url = "http://g1.globo.com/index.html"
http = urllib3.PoolManager()
resposta = http.request('GET', url)
documento = lxml.html.document_fromstring(resposta.data)
resultados = documento.xpath(consulta_xpath)
for resultado in resultados:
print(resultado.strip())

Aplicações nos negócios
Bite Hunter

DATA.GOV.UK

lyst

Mapado

Elabora

Aplicações na ciência

SciencesPo

Scrappy

Projetos de pesquisa no IFMS

Questões legais e conclusões

Questões legais
● Não existe uma legislação específica para o uso de Web Scraping
● Porém, há precedentes de penalização ao uso:
– Curriculum Tecnologia Ltda. x Catho Online S/C Ltda. (2002)
– American Airlines x FareChase (2003)– eBay x Bidder's Edge (2000)
● Cuidados a serem tomados:
– Sazonalidade de extração– Publicação dos dados extraídos

Conclusões
● Web Scraping é ideal para agregação de dados e geração de informação
● Mais importante que o Web Scraping é o uso dos dados extraídos
– Visão computacional– Mineração de dados– BI

Recommended


















