
Two-dimensional pattern matchingM.G.W.H. van de Rijdt
23 August 2005

Introduction•Problem description
•Naive algorithm
•Filter-based algorithms
– A simple filter function
– Takaoka-Zhu
– Baker-Bird
•Baeza-Yates & Régnier
•Polcar
•Conclusions
•Future work
•Questions

Problem description•One-dimensional pattern matching: finding all
occurrences of a pattern string in a text string
•Two-dimensional pattern matching: finding all
occurrences of a 2D pattern matrix in a 2D text matrix
•Applications: image processing, ...

Naive algorithm•Simply check for each position in the text whether
there is a match there
•Most straightforward, but inefficient, solution
•Better algorithms
– use gathered information to disregard a larger
area of the text at onces
and/or
– precompute information to determine more
quickly whether a match exists on a position in
the text

Filter-based algorithms (0)
•Define a “filter function”, which transforms each
row of the pattern matrix to a single value
•Using this function, reduce the pattern matrix to a
single (column) vector

Filter-based algorithms (1)•Apply the filter function to partial rows of the text
matrix
•There can only be an occurrence where the
pattern’s column vector occurs in the reduced text
•Use 1D pattern matching to find those occurrences
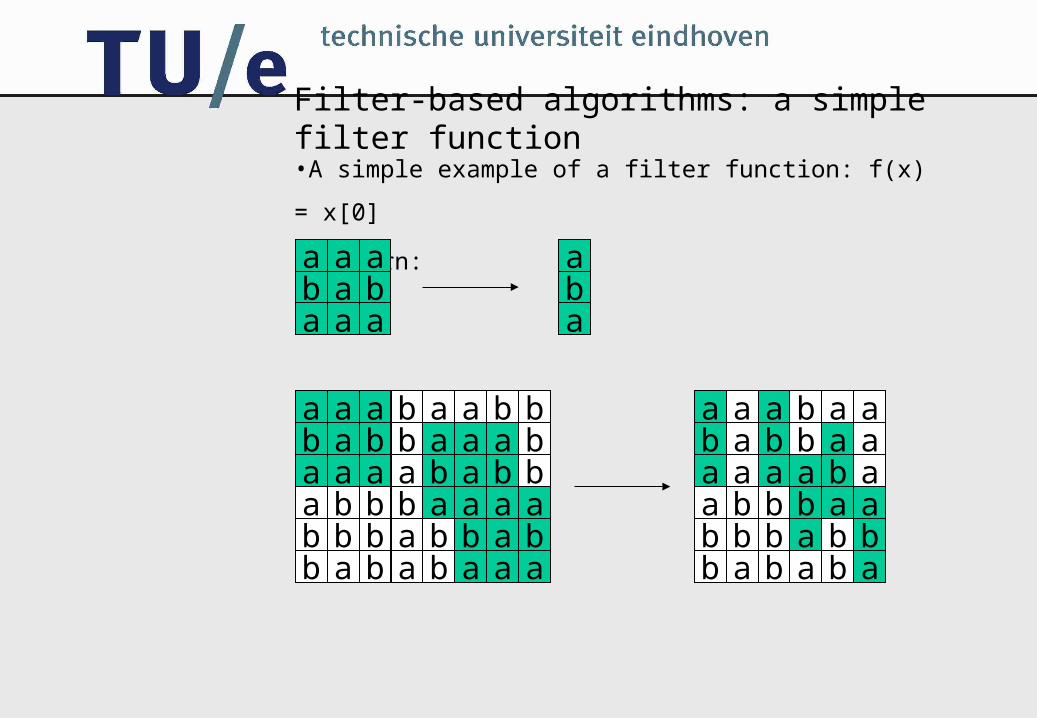
Filter-based algorithms: a simple filter function•A simple example of a filter function: f(x) = x[0]
•Pattern:
•Text:
a a ab a ba a a
aba
a a ab a ba a a
b a ab a aa b a
a b bb b bb a b
b ba bb b
b a aa b ba b a
a aa ba a
a a ab a ba a a
b a ab a aa b a
a b bb b bb a b
b a aa b ba b a

Filter-based algorithms: Takaoka-Zhu
•Filter function: hash function from the (1D) Karp-
Rabin algorithm
a a ab a ba a a
b a ab a aa b a
a b bb b bb a b
b ba bb b
b a aa b ba b a
a aa ba a
qjxrowPcoljjxf jPcol mod||])[(:)(0: 1)(

Filter-based algorithms: Baker-Bird (0)
•Based on Aho-Corasick automaton
– Aho-Corasick is an algorithm for (1D)
multipattern matching
– It uses a special automaton, based on the
pattern strings
•Filter function for Baker-Bird: state in the Aho-
Corasick automaton, based on the pattern’s rows
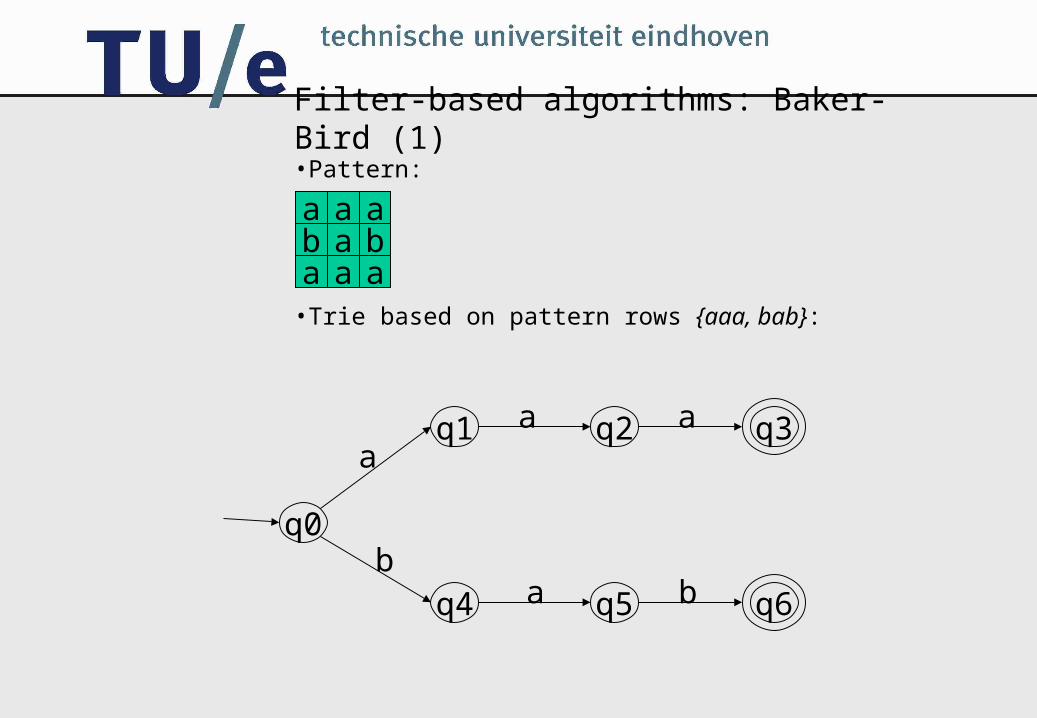
Filter-based algorithms: Baker-Bird (1)
•Pattern:
•Trie based on pattern rows {aaa, bab}:
q0
q1 q2 q3
q4 q5 q6
aa a
ab
b
a a ab a ba a a

Filter-based algorithms: Baker-Bird (2)
•Pattern:
•Aho-Corasick automaton based on pattern rows
{aaa, bab}:
q0
q1 q2 q3
q4 q5 q6
aa a
ab
b
b
b b
b
a
b
a
a
a a ab a ba a a
q3q6q3
b
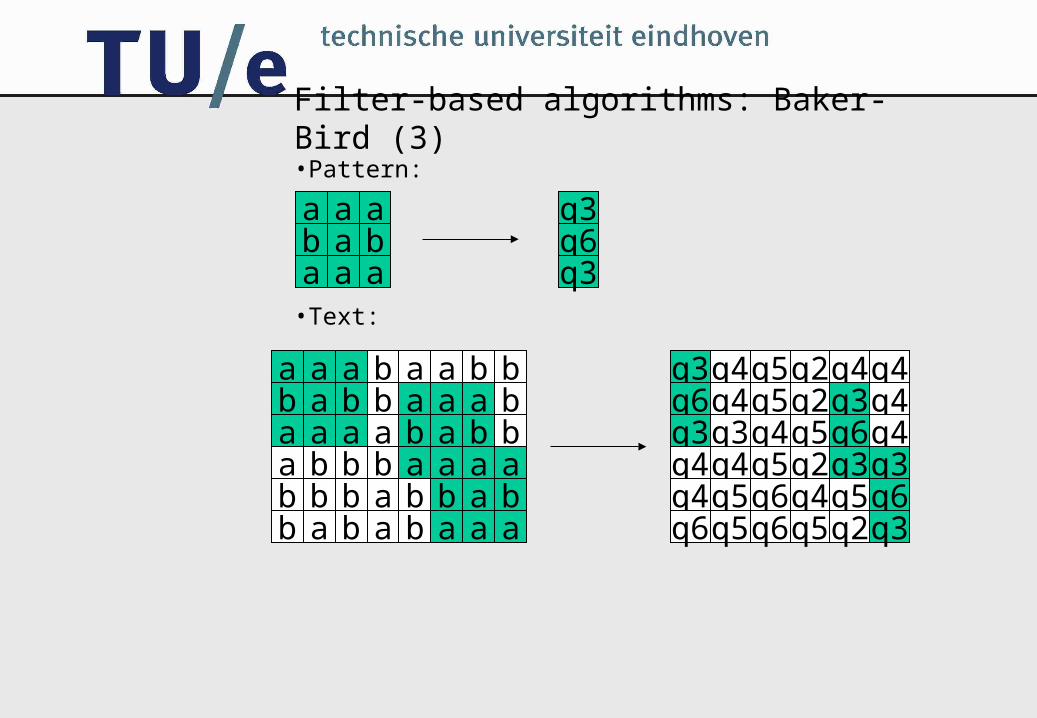
Filter-based algorithms: Baker-Bird (3)
•Pattern:
•Text:
a a ab a ba a a
q3q6q3
a a ab a ba a a
b a ab a aa b a
a b bb b bb a b
b ba bb b
b a aa b ba b a
a aa ba a
q3 q4 q5q6 q4 q5q3 q3 q4
q2 q4 q4q2 q3 q4q5 q6 q4
q4 q4 q5q4 q5 q6q6 q5 q6
q2 q3 q3q4 q5 q6q5 q2 q3

Baeza-Yates & Régnier (0)
•Say our pattern has m rows
•In the text, each occurrence of the pattern
intersects with exactly one row of the form i * m – 1
0
m-1
2*m-1
3*m-1
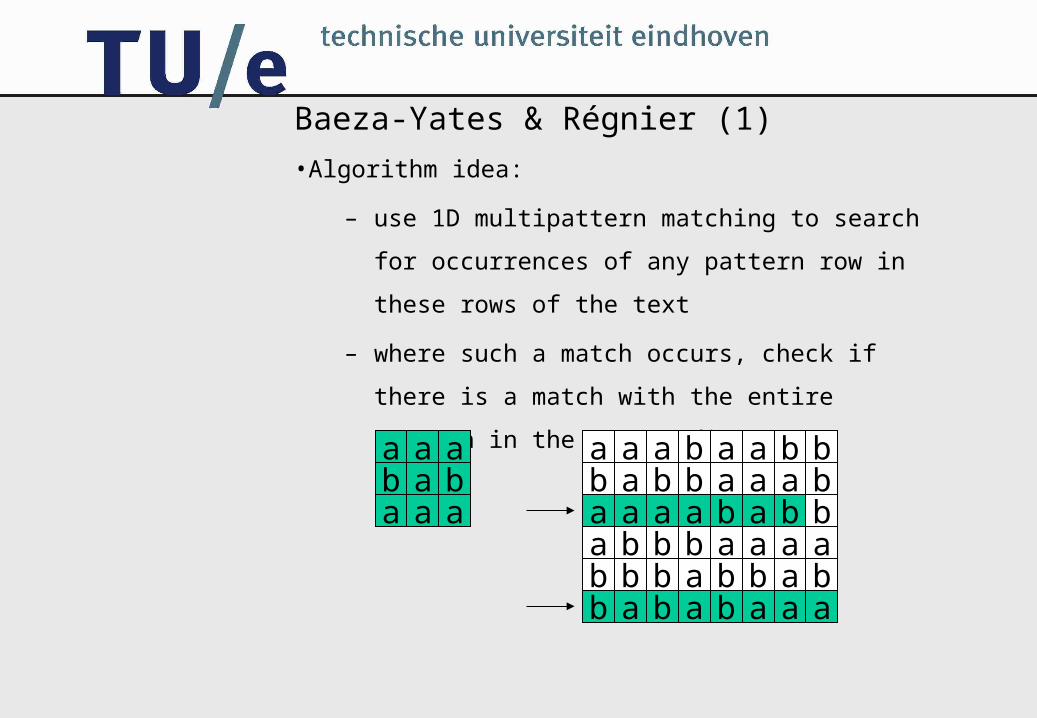
Baeza-Yates & Régnier (1)
•Algorithm idea:
– use 1D multipattern matching to search for
occurrences of any pattern row in these rows
of the text
– where such a match occurs, check if there is
a match with the entire pattern in the
surrounding areaa a ab a ba a a
a a ab a ba a a
b a ab a aa b a
a b bb b bb a b
b ba bb b
b a aa b ba b a
a aa ba a

Polcar (0)
•In some 1D pattern matching algorithms, we view
an occurrence of the pattern as a suffix of a prefix
of the text
•For Polcar, we do the same in two dimensions

Polcar (1)
•For each prefix of the text A, we compute the set of
suffixes of A that are also a prefix of the pattern:)()( PprefAsuff

Polcar (1)
•For each prefix of the text A, we compute the set of
suffixes of A that are also a prefix of the pattern:)()( PprefAsuff

Polcar (1)
•For each prefix of the text A, we compute the set of
suffixes of A that are also a prefix of the pattern:)()( PprefAsuff

Polcar (1)
•For each prefix of the text A, we compute the set of
suffixes of A that are also a prefix of the pattern:)()( PprefAsuff

Polcar (2)•In derivations of the corresponding 1D pattern
matching algorithms, sets of prefixes of the pattern
are represented by their element of maximum length
•In 2D there is not always one unique maximum
•But these sets of matrices can be represented by
their maximal elements

Conclusions•Presentation of several 2D pattern matching
algorithms
•All of them have been formally derived
– derivation is a formal proof
– derivations show the major design decisions
•Similarities between the filter-based algorithms
•Several improvements to existing algorithms
– most notably: in Polcar’s algorithm, sets of
matrices can be represented by their maximal
elements

Future work•Derive other existing algorithms
•Construct a taxonomy
•Find new algorithms
•Expand existing pattern matching toolkits (SPARE Time / SPARE
Parts) or create a new 2D pattern matching toolkit
•Thorough performance analysis
•Further generalisations of the 2D pattern matching problem
– Multipattern matching
– More than two dimensions
– Approximate 2D pattern matching
– Patterns of non-rectangular shapes
– ...

Questions

Recommended

















