
Méthodes d’apprentissage
statistique (« Machine Learning »)
Journées d’Etudes IARD
Niort, 21 Mars 2014
Fabrice TAILLIEU
Sébastien DELUCINGE
Rémi BELLINA
© 2014 Milliman. All rights reserved

2
Sommaire
Introduction
Les méthodes d’apprentissage statistique
Illustration

3
Le marché de l’assurance non-vie est extrêmement compétitif
en France, ce qui fait peser une incertitude importante sur les
marges des compagnies.
Plusieurs facteurs accentuent ce phénomène, notamment :
– L’aggravation des charges sinistres sur certaines branches (accidents corporels
lourds, assurance santé, événements climatiques, …)
– L’environnement économique et financier
– Les changements législatifs (réforme FGAO, fin de la différenciation liée au critère
de genre, loi Hamon, entrée en vigueur de Solvabilité II, …)
– L’incertitude liée à de nouveaux risques (risques technologiques, risques
climatiques, …)
Introduction L’environnement du marché de l’assurance

4
Introduction L’environnement du marché de l’assurance
0
1
2
3
4
5
6
7
0
10
20
30
40
50
60
70
2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012
Cotisations acquises (Mds €)
Résultat technique (Mds €)
Résultat net comptable (Mds €)
Source : Rapport annuel FFSA 2012, Sociétés dommages
Les résultats des compagnies s’en ressortent fortement :

5
Dans ce contexte, il est primordial pour toute compagnie :
– D’identifier les segments de clientèle fragilisant ses résultats, ou à l’inverse ceux
qui peuvent êtres créateurs de richesse
– De suivre les résultats des affaires en portefeuille de manière objective,
indépendamment de la structure tarifaire utilisée lors de la souscription de ces
affaires
– D’être capable d’identifier les actions à mettre en œuvre, et dans la mesure du
possible avant ses concurrents
– De mettre en œuvre les actions nécessaires pendant les périodes de
renouvellement (résiliations, augmentations/baisses tarifaires) et tout au long de
l’année (suivi de la performance d’un réseau de distribution, actions marketing vis-à-
vis des clients à conserver en portefeuille, efforts commerciaux sur les affaires
nouvelles, etc)
Dans la plupart des compagnies d’assurance, ces travaux sont
aujourd’hui menés en utilisant des techniques et des
indicateurs relativement standardisés.
Introduction Les enjeux pour une compagnie d’assurance

6
De nouvelles dimensions à prendre en compte :
Choix du type de modélisation
(GLM, Apprentissage statistique, Mix des 2, etc)
Temps nécessaire à l’implémentation des modèles
Les contraintes des Systèmes d’Informations existants
Le diagnostic recherché par le modèle (tarif, revue, scoring, valeur client, …)
Les variables candidates à la modélisation (leur nombre et leur connaissance par l’actuaire) et leurs interactions
La distribution des données
Pour un grand nombre de ces dimensions, le choix des
méthodes d’apprentissage statistique sera le plus à même de
répondre aux besoins croissants en termes de modélisations.
Introduction Les dimensions de modélisation

7
Pour répondre aux
problématiques nouvelles
soulevées par le management,
les actuaires ont besoin d’outils
adaptés au nouvel
environnement dans lequel leur
compagnie exerce.
Quelles solutions apportent les
méthodes d’apprentissage
statistique pour effectuer les
bons diagnostics ?
Est-ce pour autant la fin des GLM
en tarification ?
Introduction Les enjeux pour une compagnie d’assurance

8
Sommaire
Introduction
Les méthodes d’apprentissage statistique
Illustration

9
Définition : on parle de machine
learning ou d’apprentissage
lorsqu’un algorithme est mis en
œuvre pour apprendre et extraire des
informations d’une base de données.
Une fois la phase d’apprentissage
terminée, on peut utiliser les résultats
pour réaliser des prédictions.
Cela couvre un domaine très vaste,
tant par les méthodes (réseaux de
neurones, arbres, méthodes
ensemblistes, etc.) que par les
applications (filtre anti-spam,
marketing, etc.).
Nous nous concentrons sur
l’algorithme CART (Classification
And Regression Tree) et ses
méthodes d’agrégation.
Les méthodes d’apprentissage statistique Machine learning
Source : Michie D., Spiegelhalter D.J., Taylor
C.C. (1984) Machine Learning, Neural and
Statistical Classification

10
Les méthodes d’apprentissage statistique Base de données pour illustration
BASE DE DONNÉES
𝑋1 𝑋2 𝑋3 𝑋4 𝑋5 𝑌
LUXE CITADINE CYLINDRE USAGE AGE_COND NOMBRE_SIN
1 N N 4 PRIVE 50 0
2 N N 6 PRIVE 60 0
3 N Y 4 COMMERCIAL 40 1
4 N Y 4 PRIVE 30 0
5 N N 4 PRIVE 70 0
6 Y Y 4 COMMERCIAL 23 0
7 N N 4 BUSINESS 40 0
8 N N 6 PRIVE 40 1
9 Y Y 4 PRIVE 60 0
10 N N 6 PRIVE 50 0
11 N N 8 PRIVE 30 1
12 N Y 4 BUSINESS 30 0
13 Y N 6 PRIVE 40 0
14 N N 6 PRIVE 30 0
⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
998 N N 4 BUSINESS 60 0
999 N Y 4 PRIVE 60 2
1000 N N 4 COMMERCIAL 40 1
Apprentissage Validation Test
70% 20% 10%

11
Variables explicatives : 𝑋1, … , 𝑋𝑝.
Variable à expliquer : 𝑌.
On cherche parmi un ensemble de fonctions admissibles ℱ :
𝜙 ∶ ℝ𝑝 → ℝ, 𝑥 = 𝑥1, … , 𝑥𝑝 ↦ 𝜙 𝑥 = 𝑦
Comment trouver une « bonne » fonction 𝜙 ?
Selon un critère quadratique et sans restriction sur ℱ, la meilleure fonction 𝜙 est l’espérance
conditionnelle :
𝜙∗ = argmin𝜙∈ℱ 𝑌 − 𝜙 𝑋 2 = arg min
𝑊∈𝐿2 𝜎 𝑋𝑌 −𝑊 2 = 𝑬 𝒀|𝑿
La meilleure représentation 𝜙∗ 𝑋 de 𝑌 sachant que l’on dispose de l’échantillon 𝑋 est 𝐸 𝑌|𝑋 .
On souhaite obtenir un bon estimateur de l’espérance conditionnelle.
L’erreur d’un modèle sur une base est donnée par 𝑅base 𝜙 = 𝑦𝑖 − 𝜙 𝑥𝑖2
base .
Les méthodes d’apprentissage statistique Cadre mathématique (1/4)
12
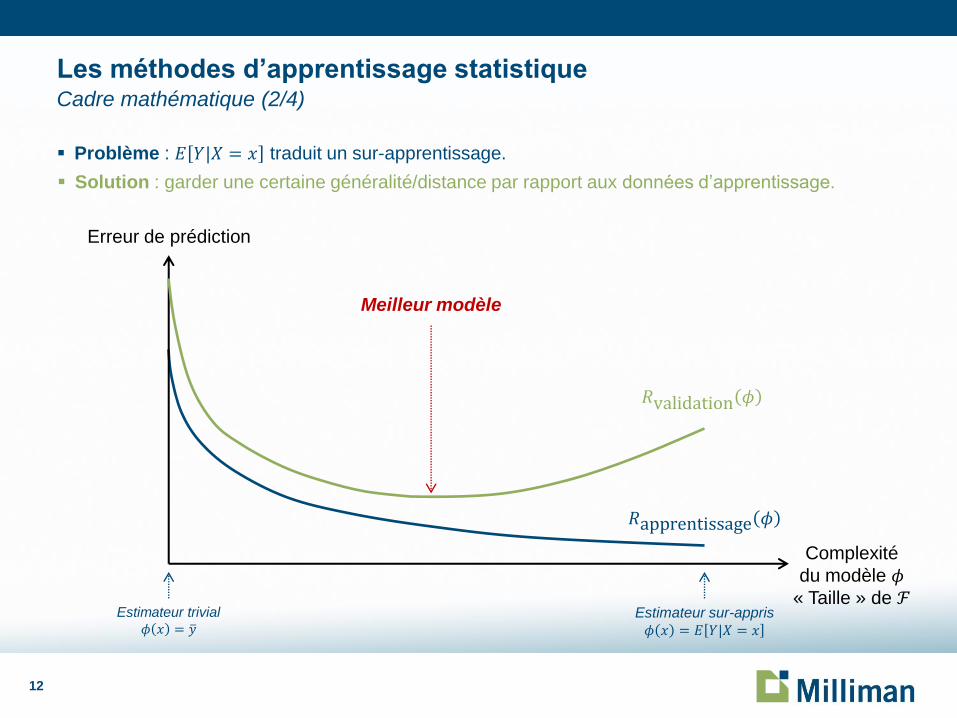
Problème : 𝐸 𝑌|𝑋 = 𝑥 traduit un sur-apprentissage.
Les méthodes d’apprentissage statistique Cadre mathématique (2/4)
Meilleur modèle
𝑅apprentissage 𝜙
Erreur de prédiction
Complexité
du modèle 𝜙 « Taille » de ℱ
Estimateur trivial
𝜙 𝑥 = 𝑦 Estimateur sur-appris
𝜙 𝑥 = 𝐸 𝑌|𝑋 = 𝑥
𝑅validation 𝜙
Solution : garder une certaine généralité/distance par rapport aux données d’apprentissage.

13
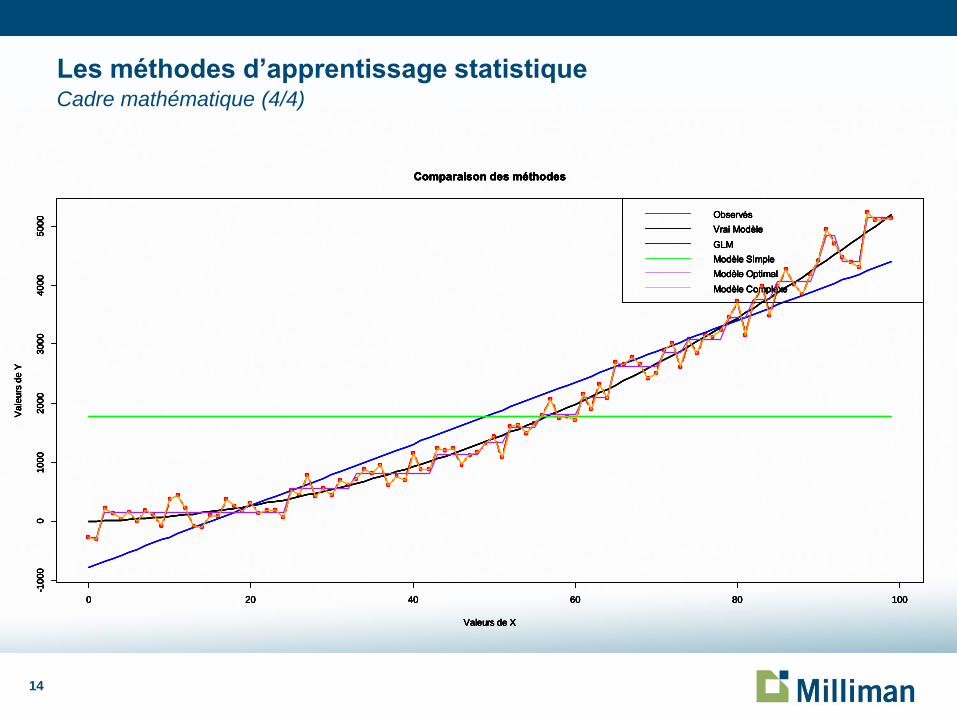
Plus formellement, écrivons :
𝑌 = 𝜙 𝑋 + 𝜖 – 𝐸 𝜖 = 0 et 𝑉 𝜖 = 𝜎2
– 𝜙 𝑋 est une fonction déterministe certaine mais inconnue
Dans l’absolu, on souhaite estimer 𝜙 mais on ne dispose que des observations bruitées 𝑌.
Le sur-apprentissage consiste à apprendre 𝑌 (et 𝜖) en s’éloignant de 𝜙.
Les méthodes d’apprentissage permettent d’obtenir un modèle estimé 𝜙 𝑋 . On peut montrer :
𝑌 − 𝜙 2
2
à minimiser
= 𝐸 𝑌 − 𝜙 2= 𝜎2 + 𝐸 𝜙 − 𝜙
biais
2+ 𝑉 𝜙 variance
Le meilleur modèle traduit un compromis entre le biais et la variance.
Les méthodes d’apprentissage statistique Cadre mathématique (3/4)
14
0 20 40 60 80 100
-10
00
01
00
02
00
03
00
04
00
05
00
0
Comparaison des méthodes
Valeurs de X
Va
leu
rs d
e Y
Observés
Vrai Modèle
GLM
Modèle Simple
Modèle Optimal
Modèle Complexe
0 20 40 60 80 100
-10
00
01
00
02
00
03
00
04
00
05
00
0
Comparaison des méthodes
Valeurs de X
Va
leu
rs d
e Y
Observés
Vrai Modèle
GLM
Modèle Simple
Modèle Optimal
Modèle Complexe
0 20 40 60 80 100
-10
00
01
00
02
00
03
00
04
00
05
00
0
Comparaison des méthodes
Valeurs de X
Va
leu
rs d
e Y
Observés
Vrai Modèle
GLM
Modèle Simple
Modèle Optimal
Modèle Complexe
0 20 40 60 80 100
-10
00
01
00
02
00
03
00
04
00
05
00
0
Comparaison des méthodes
Valeurs de X
Va
leu
rs d
e Y
Observés
Vrai Modèle
GLM
Modèle Simple
Modèle Optimal
Modèle Complexe
0 20 40 60 80 100
-10
00
01
00
02
00
03
00
04
00
05
00
0
Comparaison des méthodes
Valeurs de X
Va
leu
rs d
e Y
Observés
Vrai Modèle
GLM
Modèle Simple
Modèle Optimal
Modèle Complexe
Les méthodes d’apprentissage statistique Cadre mathématique (4/4)
15
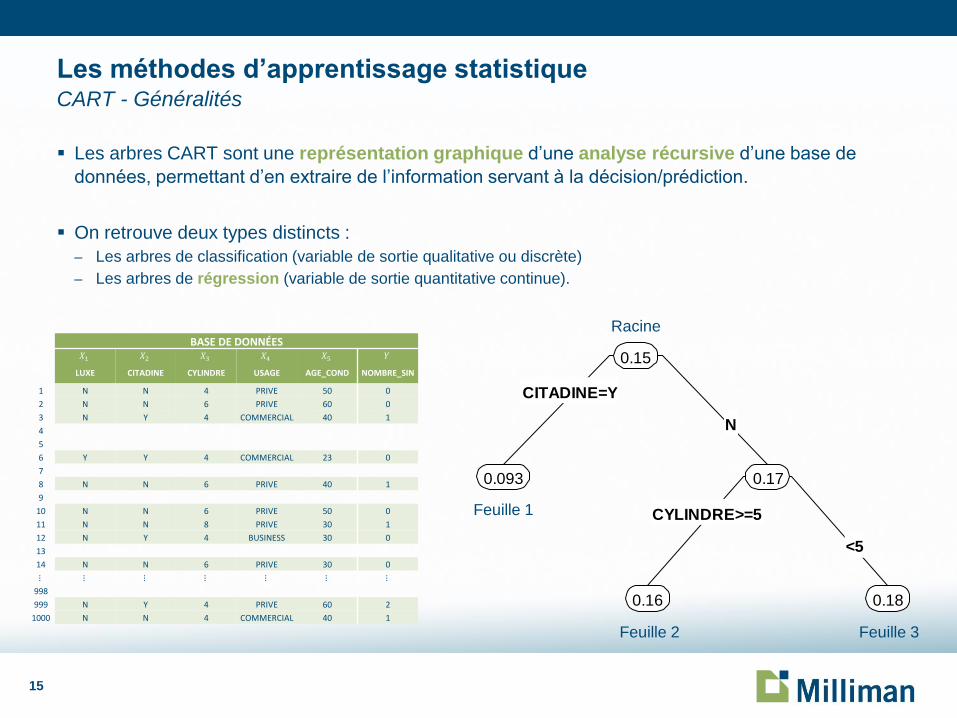
Les arbres CART sont une représentation graphique d’une analyse récursive d’une base de
données, permettant d’en extraire de l’information servant à la décision/prédiction.
On retrouve deux types distincts :
– Les arbres de classification (variable de sortie qualitative ou discrète)
– Les arbres de régression (variable de sortie quantitative continue).
Les méthodes d’apprentissage statistique CART - Généralités
Racine
Feuille 1
Feuille 2 Feuille 3
BASE DE DONNÉES 𝑋1 𝑋2 𝑋3 𝑋4 𝑋5 𝑌
LUXE CITADINE CYLINDRE USAGE AGE_COND NOMBRE_SIN
1 N N 4 PRIVE 50 0
2 N N 6 PRIVE 60 0
3 N Y 4 COMMERCIAL 40 1
4
5
6 Y Y 4 COMMERCIAL 23 0
7
8 N N 6 PRIVE 40 1
9
10 N N 6 PRIVE 50 0
11 N N 8 PRIVE 30 1
12 N Y 4 BUSINESS 30 0
13
14 N N 6 PRIVE 30 0
⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
998
999 N Y 4 PRIVE 60 2
1000 N N 4 COMMERCIAL 40 1
CITADINE=Y
CYLINDRE>=5
N
<5
0.15
0.093 0.17
0.16 0.18
16
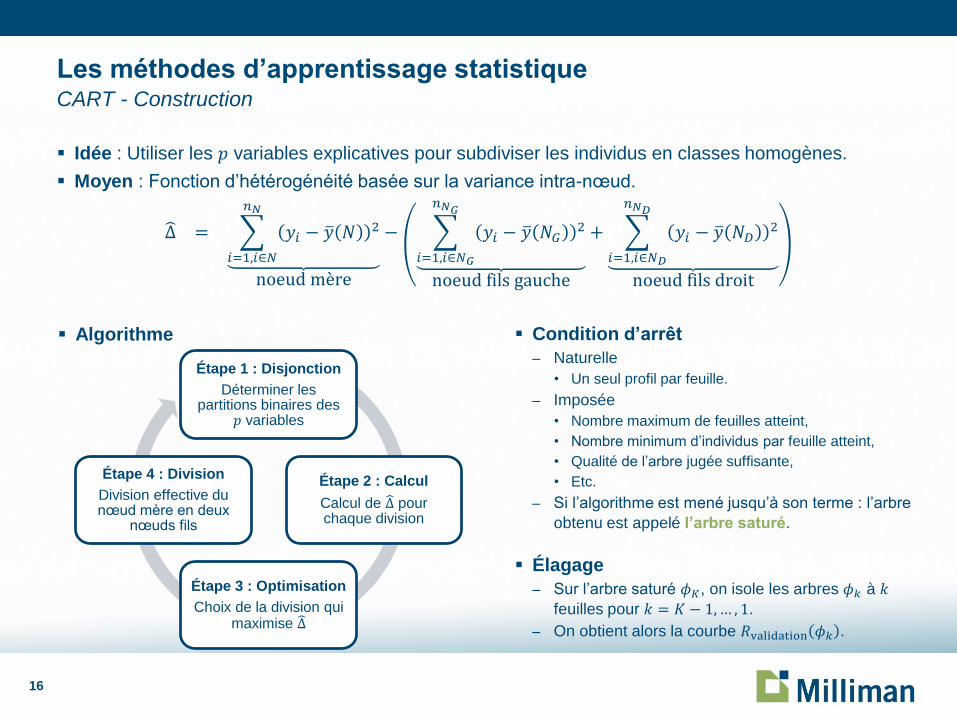
Idée : Utiliser les 𝑝 variables explicatives pour subdiviser les individus en classes homogènes.
Moyen : Fonction d’hétérogénéité basée sur la variance intra-nœud.
Δ = 𝑦𝑖 − 𝑦 𝑁2
𝑛𝑁
𝑖=1,𝑖∈𝑁
noeud mère
− 𝑦𝑖 − 𝑦 𝑁𝐺2
𝑛𝑁𝐺
𝑖=1,𝑖∈𝑁𝐺
noeud fils gauche
+ 𝑦𝑖 − 𝑦 𝑁𝐷2
𝑛𝑁𝐷
𝑖=1,𝑖∈𝑁𝐷
noeud fils droit
Étape 1 : Disjonction
Déterminer les partitions binaires des 𝑝 variables
Étape 2 : Calcul
Calcul de Δ pour chaque division
Étape 3 : Optimisation
Choix de la division qui maximise Δ
Étape 4 : Division
Division effective du nœud mère en deux
nœuds fils
Condition d’arrêt
– Naturelle
• Un seul profil par feuille.
– Imposée
• Nombre maximum de feuilles atteint,
• Nombre minimum d’individus par feuille atteint,
• Qualité de l’arbre jugée suffisante,
• Etc.
– Si l’algorithme est mené jusqu’à son terme : l’arbre
obtenu est appelé l’arbre saturé.
Élagage
– Sur l’arbre saturé 𝜙𝐾, on isole les arbres 𝜙𝑘 à 𝑘
feuilles pour 𝑘 = 𝐾 − 1,… , 1.
– On obtient alors la courbe 𝑅validation 𝜙𝑘 .
Algorithme
Les méthodes d’apprentissage statistique CART - Construction
17
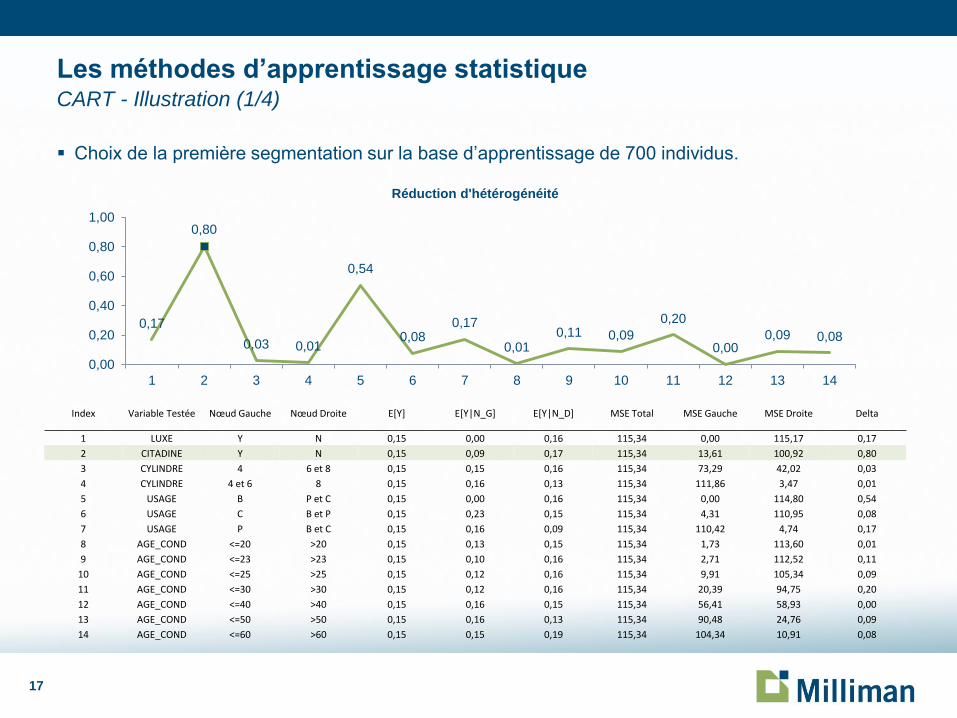
Choix de la première segmentation sur la base d’apprentissage de 700 individus.
0,17
0,80
0,03 0,01
0,54
0,08 0,17
0,01 0,11 0,09
0,20
0,00 0,09 0,08
0,00
0,20
0,40
0,60
0,80
1,00
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Réduction d'hétérogénéité
Index Variable Testée Nœud Gauche Nœud Droite E[Y] E[Y|N_G] E[Y|N_D] MSE Total MSE Gauche MSE Droite Delta
1 LUXE Y N 0,15 0,00 0,16 115,34 0,00 115,17 0,17
2 CITADINE Y N 0,15 0,09 0,17 115,34 13,61 100,92 0,80
3 CYLINDRE 4 6 et 8 0,15 0,15 0,16 115,34 73,29 42,02 0,03
4 CYLINDRE 4 et 6 8 0,15 0,16 0,13 115,34 111,86 3,47 0,01
5 USAGE B P et C 0,15 0,00 0,16 115,34 0,00 114,80 0,54
6 USAGE C B et P 0,15 0,23 0,15 115,34 4,31 110,95 0,08
7 USAGE P B et C 0,15 0,16 0,09 115,34 110,42 4,74 0,17
8 AGE_COND <=20 >20 0,15 0,13 0,15 115,34 1,73 113,60 0,01
9 AGE_COND <=23 >23 0,15 0,10 0,16 115,34 2,71 112,52 0,11
10 AGE_COND <=25 >25 0,15 0,12 0,16 115,34 9,91 105,34 0,09
11 AGE_COND <=30 >30 0,15 0,12 0,16 115,34 20,39 94,75 0,20
12 AGE_COND <=40 >40 0,15 0,16 0,15 115,34 56,41 58,93 0,00
13 AGE_COND <=50 >50 0,15 0,16 0,13 115,34 90,48 24,76 0,09
14 AGE_COND <=60 >60 0,15 0,15 0,19 115,34 104,34 10,91 0,08
Les méthodes d’apprentissage statistique CART - Illustration (1/4)
18
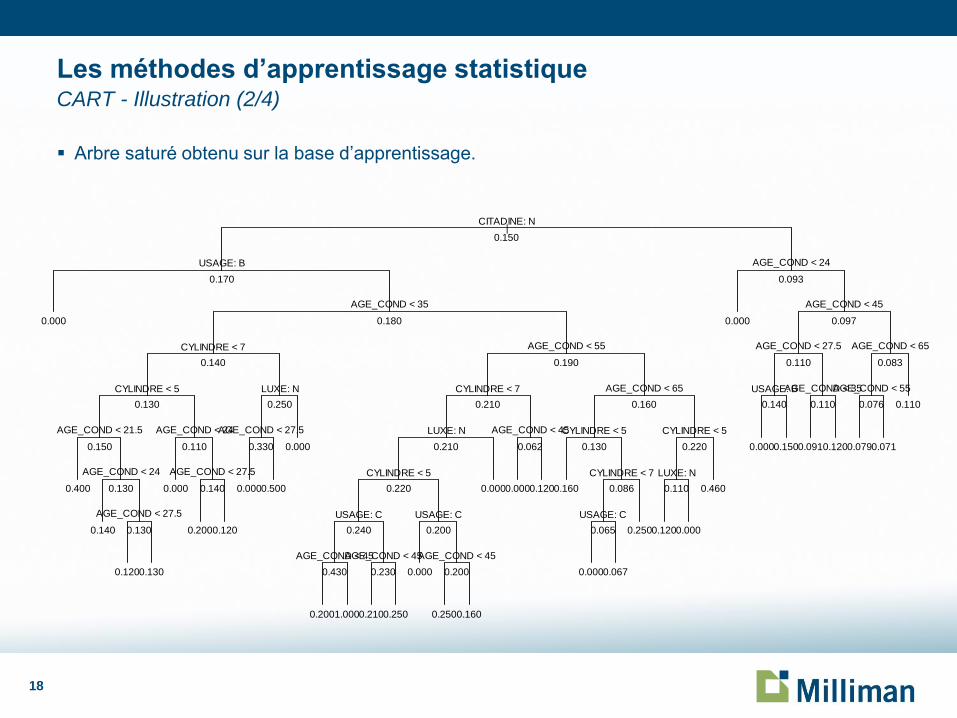
Arbre saturé obtenu sur la base d’apprentissage.
|CITADINE: N
USAGE: B
AGE_COND < 35
CYLINDRE < 7
CYLINDRE < 5
AGE_COND < 21.5
AGE_COND < 24
AGE_COND < 27.5
AGE_COND < 24
AGE_COND < 27.5
LUXE: N
AGE_COND < 27.5
AGE_COND < 55
CYLINDRE < 7
LUXE: N
CYLINDRE < 5
USAGE: C
AGE_COND < 45AGE_COND < 45
USAGE: C
AGE_COND < 45
AGE_COND < 45
AGE_COND < 65
CYLINDRE < 5
CYLINDRE < 7
USAGE: C
CYLINDRE < 5
LUXE: N
AGE_COND < 24
AGE_COND < 45
AGE_COND < 27.5
USAGE: BAGE_COND < 35
AGE_COND < 65
AGE_COND < 55
0.150
0.170
0.000 0.180
0.140
0.130
0.150
0.400 0.130
0.140 0.130
0.1200.130
0.110
0.000 0.140
0.2000.120
0.250
0.330
0.0000.500
0.000
0.190
0.210
0.210
0.220
0.240
0.430
0.2001.000
0.230
0.2100.250
0.200
0.000 0.200
0.2500.160
0.000
0.062
0.0000.120
0.160
0.130
0.160 0.086
0.065
0.0000.067
0.250
0.220
0.110
0.1200.000
0.460
0.093
0.000 0.097
0.110
0.140
0.0000.150
0.110
0.0910.120
0.083
0.076
0.0790.071
0.110
Les méthodes d’apprentissage statistique CART - Illustration (2/4)
19
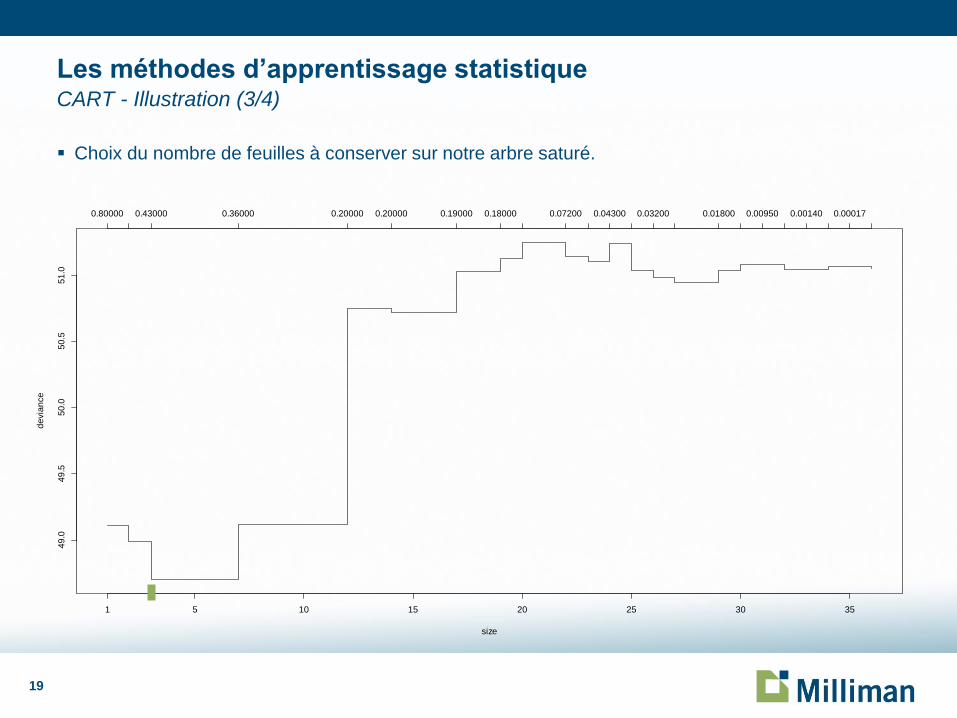
Choix du nombre de feuilles à conserver sur notre arbre saturé.
size
de
via
nce
49
.04
9.5
50
.05
0.5
51
.0
1 5 10 15 20 25 30 35
0.80000 0.43000 0.36000 0.20000 0.20000 0.19000 0.18000 0.07200 0.04300 0.03200 0.01800 0.00950 0.00140 0.00017
Les méthodes d’apprentissage statistique CART - Illustration (3/4)
20
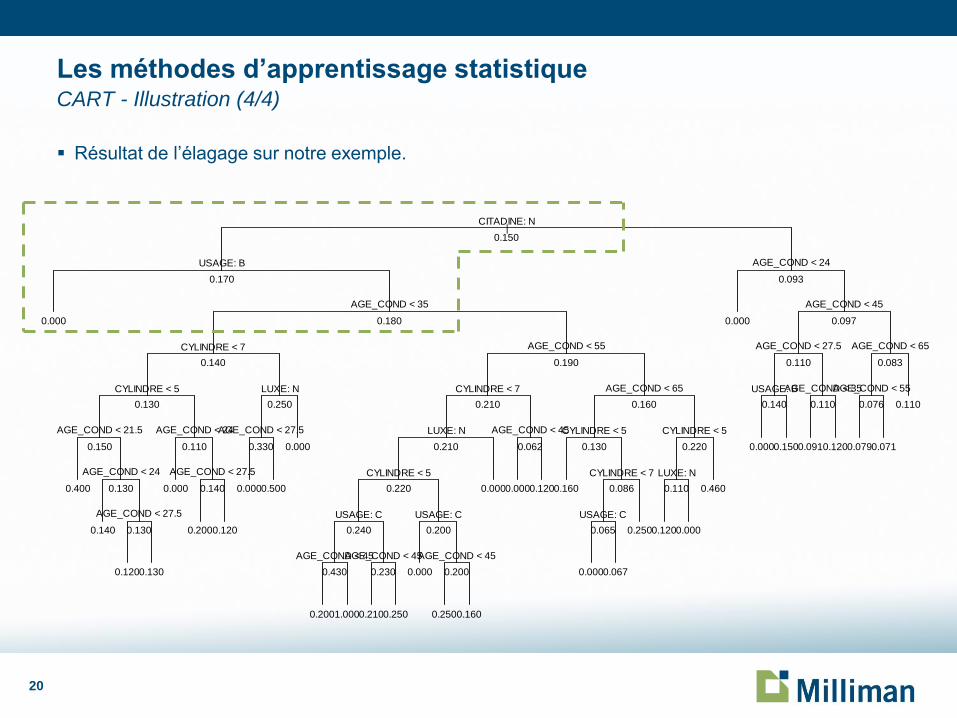
Résultat de l’élagage sur notre exemple.
|CITADINE: N
USAGE: B
AGE_COND < 35
CYLINDRE < 7
CYLINDRE < 5
AGE_COND < 21.5
AGE_COND < 24
AGE_COND < 27.5
AGE_COND < 24
AGE_COND < 27.5
LUXE: N
AGE_COND < 27.5
AGE_COND < 55
CYLINDRE < 7
LUXE: N
CYLINDRE < 5
USAGE: C
AGE_COND < 45AGE_COND < 45
USAGE: C
AGE_COND < 45
AGE_COND < 45
AGE_COND < 65
CYLINDRE < 5
CYLINDRE < 7
USAGE: C
CYLINDRE < 5
LUXE: N
AGE_COND < 24
AGE_COND < 45
AGE_COND < 27.5
USAGE: BAGE_COND < 35
AGE_COND < 65
AGE_COND < 55
0.150
0.170
0.000 0.180
0.140
0.130
0.150
0.400 0.130
0.140 0.130
0.1200.130
0.110
0.000 0.140
0.2000.120
0.250
0.330
0.0000.500
0.000
0.190
0.210
0.210
0.220
0.240
0.430
0.2001.000
0.230
0.2100.250
0.200
0.000 0.200
0.2500.160
0.000
0.062
0.0000.120
0.160
0.130
0.160 0.086
0.065
0.0000.067
0.250
0.220
0.110
0.1200.000
0.460
0.093
0.000 0.097
0.110
0.140
0.0000.150
0.110
0.0910.120
0.083
0.076
0.0790.071
0.110
Les méthodes d’apprentissage statistique CART - Illustration (4/4)

21
Arbre saturé 𝜙280 1000 obs. par feuille
Arbre élagué 𝜙5 5 feuilles
Arbre élagué 𝜙20 20 feuilles
Arbre tronc 𝜙1 1 feuille
Arbre optimal 𝝓𝟏𝟐𝟐 122 feuilles
size
de
via
nce
16
45
01
65
00
16
55
01
66
00
1 50 100 150 200 250
1.4e+02 6.5e+00 3.6e+00 2.1e+00 1.6e+00 1.3e+00 1.1e+00 8.2e-01 7.1e-01 6.5e-01 5.7e-01 5.3e-01 4.6e-01 4.1e-01 3.1e-01 2.6e-01 2.0e-01 1.4e-01 6.8e-02 -Inf
𝑅validation 𝜙𝑘
Les méthodes d’apprentissage statistique CART - Illustration sur la base complète
22
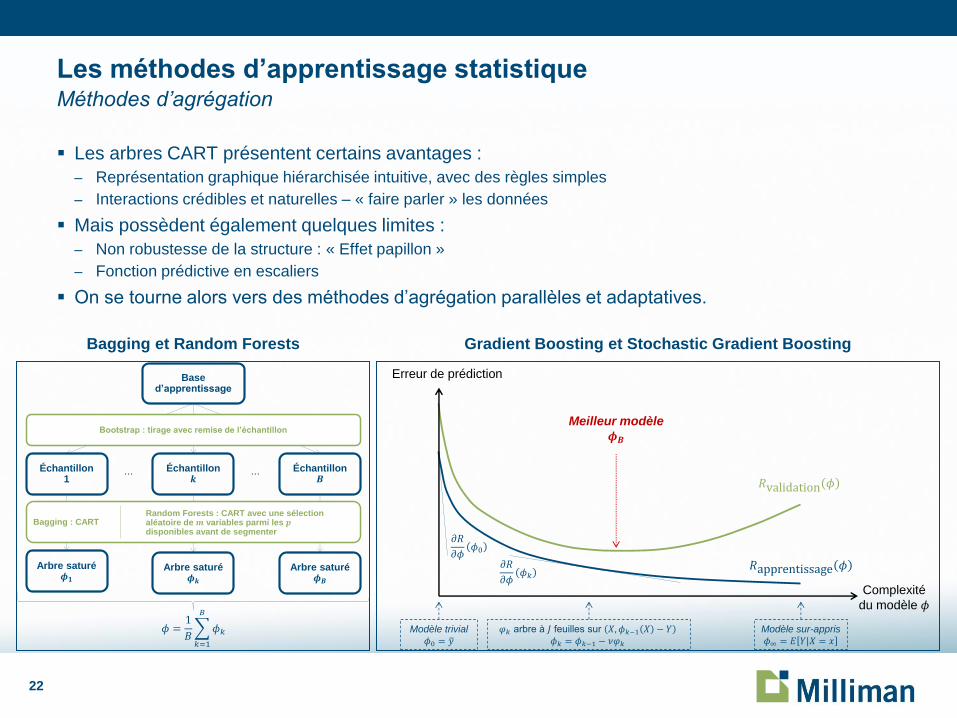
Les arbres CART présentent certains avantages :
– Représentation graphique hiérarchisée intuitive, avec des règles simples
– Interactions crédibles et naturelles – « faire parler » les données
Mais possèdent également quelques limites :
– Non robustesse de la structure : « Effet papillon »
– Fonction prédictive en escaliers
On se tourne alors vers des méthodes d’agrégation parallèles et adaptatives.
Les méthodes d’apprentissage statistique Méthodes d’agrégation
Base d’apprentissage
Bootstrap : tirage avec remise de l’échantillon
Échantillon1
Échantillon Échantillon
Bagging : CART
Arbre saturé Arbre saturéArbre saturé
Random Forests : CART avec une sélection aléatoire de variables parmi les disponibles avant de segmenter
Complexité
du modèle
Modèle sur-appris
Meilleur modèle
Erreur de prédiction
Modèle trivial
Bagging et Random Forests Gradient Boosting et Stochastic Gradient Boosting

23
-100%
-24%
-18%
0%
6% 6%
15% 13%
-100%
-80%
-60%
-40%
-20%
0%
20%
85,9
86,0
86,1
86,2
86,3
86,4
86,5
86,6
86,7
Arbre tronc Arbre saturé(1000 obs)
Arbre optimal(122 feuilles)
GLMsélectionné
Bagging(B=55)
RandomForest (B=17)
GradientBoosting(B=515)
Sto. GradientBoosting(B=585)
Erreur de prédiction sur la base de test en fonction du modèle
Gain d'écart relatif au modèle trivial par rapport au GLM
Les méthodes d’apprentissage statistique Comparaison des méthodes sur la base complète

24
Sommaire
Introduction
Les méthodes d’apprentissage statistique
Illustration

25
Une compagnie d’assurance dommages
souhaite faire un état des lieux de son tarif
auto existant (GLM).
L’état des lieux peut consister à répondre
aux diagnostics suivants :
– 1. Est-ce que la structure actuelle du GLM est toujours
pertinente ?
– 2. Est-ce que des variables (auto) qui étaient
candidates à la modélisation (et donc non-retenues)
lors de la création du tarif pourraient aujourd’hui
améliorer la structure tarifaire ?
– 3. Est-ce que les variables (auto) nouvellement
disponibles (externe ou nouveau champ) depuis la
création du tarif pourraient améliorer la structure
tarifaire ?
– 4. Est-ce que les variables des clients sur les autres
branches pourraient permettre d’identifier de nouveaux
segments de clientèle créateurs de richesse (lien avec
la valeur client) pour la compagnie ?
Illustration Présentation de l’illustration
Diagnostic 1 = OUI
Test de validité du GLM existant au sein de la compagnie :
Application des paramètres du GLM sur une nouvelle base
(test) : par exemple un sondage sur les 12 derniers mois de
production
Présentation du diagnostic sous l’angle de vue du GLM : la
population est répartie en 30 paquets triés par fréquence
prédite du GLM dans la base de test
Nous proposons une démarche possible pour mettre en œuvre les diagnostics 2 et
3 à l’aide des méthodes d’apprentissage

26
Illustration Présentation du modèle
Un exemple d’une variable candidate :
Fréquence
Observée
Fréquence
Résiduelle
Un exemple d’une variable non-candidate :
Fréquence
Observée
Fréquence
Résiduelle
Pour répondre aux diagnostics 2 et 3, l’algorithme d’apprentissage statistique que nous
avons mis en œuvre a pour fonction objectif la fréquence résiduelle de sinistre sachant la
fréquence prédite par le GLM existant :
𝑦 = 𝑁𝑜𝑚𝑏𝑟𝑒 𝑑𝑒 𝑠𝑖𝑛𝑖𝑠𝑡𝑟𝑒𝑠 𝑜𝑏𝑠𝑒𝑟𝑣é𝑠
𝐸𝑥𝑝𝑜𝑠𝑖𝑡𝑖𝑜𝑛 × 𝑓𝑟é𝑞𝑢𝑒𝑛𝑐𝑒 𝑝𝑟é𝑑𝑖𝑡𝑒 𝑑𝑢 𝐺𝐿𝑀
Les variables candidates :
– Ne sont pas les variables explicatives déjà retenues par le GLM
– Et sont donc toutes les autres variables explicatives disponibles pour prédire la fréquence
27
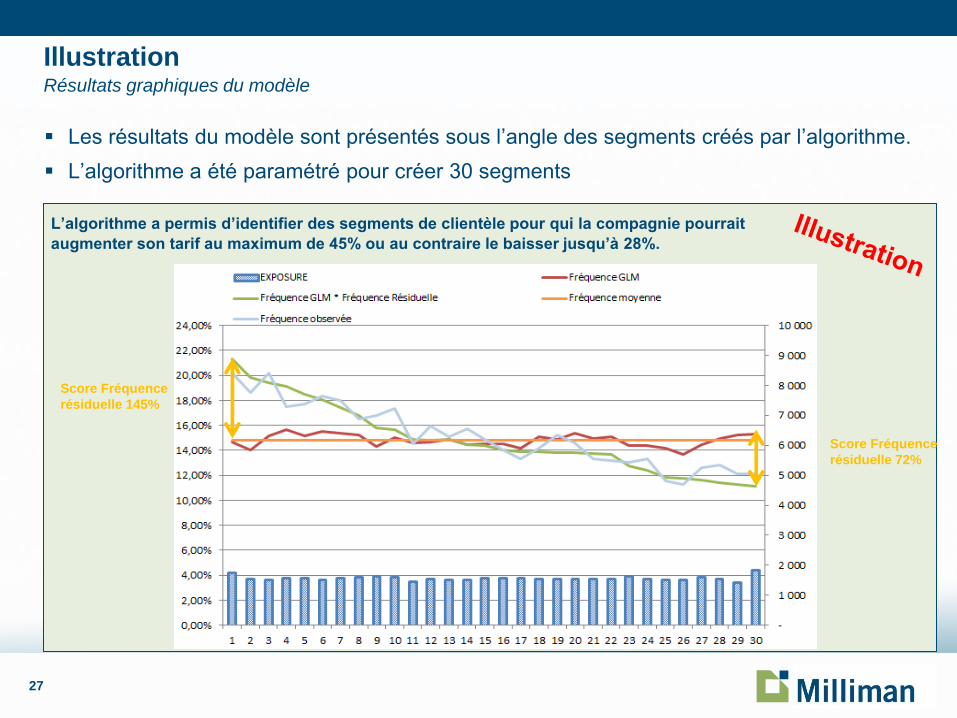
Les résultats du modèle sont présentés sous l’angle des segments créés par l’algorithme.
L’algorithme a été paramétré pour créer 30 segments
Illustration Résultats graphiques du modèle
L’algorithme a permis d’identifier des segments de clientèle pour qui la compagnie pourrait
augmenter son tarif au maximum de 45% ou au contraire le baisser jusqu’à 28%.
Score Fréquence
résiduelle 145%
Score Fréquence
résiduelle 72%

28
La compagnie souhaite intégrer les résultats de l’algorithme dans sa structure tarifaire GLM
existante
Illustration Intégration des résultats dans la structure GLM existante
Apprentissage statistique (30 segments)
PARAMETRES
𝒚
Fréquence résiduelle
1 145%
2 135%
3 125%
…
29 78%
30 72%
DEFINITION DES SEGMENTS
Variable 1 Variable 2 Variable 3 Variable N
1 N D 3 … 50
2 C … 60
3 N B 4 … 40
… … … … … …
29 N A 6 …
30 N 8 … 30
Contrairement à une structure GLM, il se peut que
certains segments soient définis sans utiliser
l’ensemble des variables de l’algorithme.
TABLE FACTEURS GLM
VARIABLE MODALITE FACTEUR
INTERCEPT - 2
AGE_COND 40 0
AGE_COND 23 0,8
AGE_COND 60 0,1
CYLINDRE 6 0
USAGE PRIVE 0
Structure GLM existante
TABLE FACTEURS GLM
VARIABLE MODALITE FACTEUR
INTERCEPT - 2
AGE_COND 40 0
AGE_COND 23 0,8
AGE_COND 60 0,1
CYLINDRE 6 0
USAGE PRIVE 0
SCORE 1 1,45
SCORE 2 1,35
SCORE 3 1,25
SCORE …
SCORE 30 0,72
Nouvelle structure GLM
Il est nécessaire que chaque variable
retenue par le score soit lisible dans le
système d’informations pour être
intégrée dans la structure GLM de la
compagnie

29
L’illustration a permis de montrer que l’utilisation des méthodes d’apprentissage
statistique pouvait être un complément pertinent à l’utilisation des GLM dans un cadre
tarifaire. En effet, l’application de ces méthodes permet :
– De pallier certaines limites des GLM
– D’optimiser le temps d’implémentation pour mettre en œuvre un modèle
– De traiter un grand nombre de variables tarifaires
Plus généralement, ces méthodes permettent également d’ouvrir un horizon de
modélisation plus large que la tarification. En effet, les méthodes d’apprentissage
statistique permettent par exemple :
– De répondre à un besoin de suivi des actions du management en « temps réel »
– D’être une réponse pertinente à la mise en place d’un concept de valeur client au sein d’une
compagnie
– D’être la réponse de modélisation pour les données de masse dont les assureurs vont pouvoir ou
peuvent déjà disposer.
Conclusion

30
Contacts
Fabrice TAILLIEU Principal [email protected]
+ 33 6 87 30 69 92
Sébastien DELUCINGE Senior Consultant [email protected]
+ 33 6 38 74 52 15
Rémi BELLINA Consultant [email protected]
+ 33 6 08 23 39 95
Recommended

















