
CHRONIX SPARKTIME SERIES PROCESSING WITH SPARK
Dr. Josef Adersberger ( @adersberger)

2
TIME SERIES 101

TIME SERIES 101
WE`RE SURROUNDED BY TIME SERIES▸ Operational data: Monitoring data, performance metrics, log events, …
▸ Data Warehouse: Dimension time
▸ Measured Me: Activity tracking, ECG, …
▸ Sensor telemetry: Sensor data, …
▸ Financial data: Stock charts, …
▸ Climate data: Temperature, …
▸ Web tracking: Clickstreams, …
TIME SERIES 101
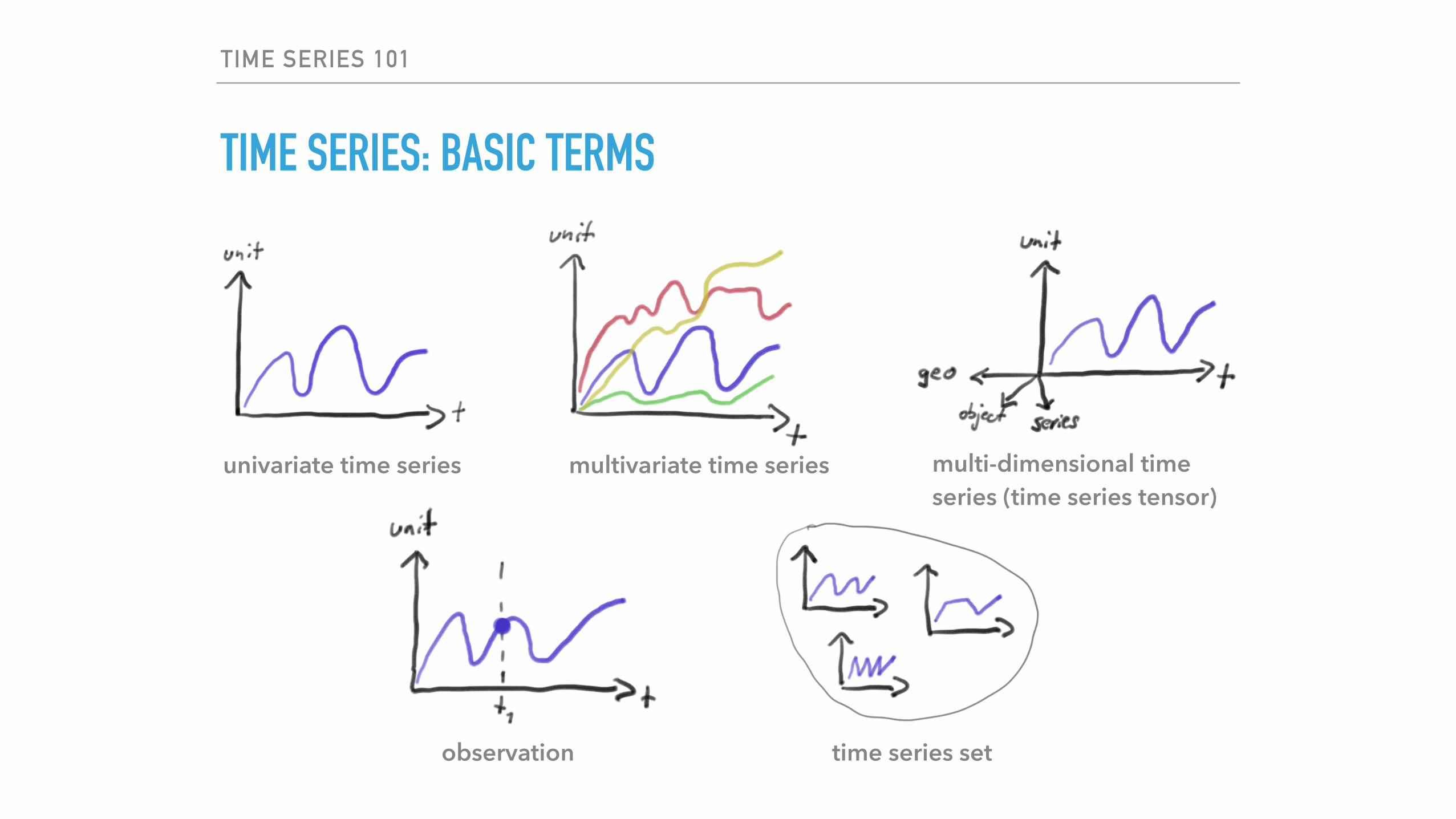
TIME SERIES: BASIC TERMS
univariate time series multivariate time series multi-dimensional time series (time series tensor)
time series setobservation

TIME SERIES 101
OPERATIONS ON TIME SERIES (EXAMPLES)
align
Time series Time series
Time series Scalar
diff downsampling outlier
min/max avg/med slope std-dev

6
OUR USE CASE
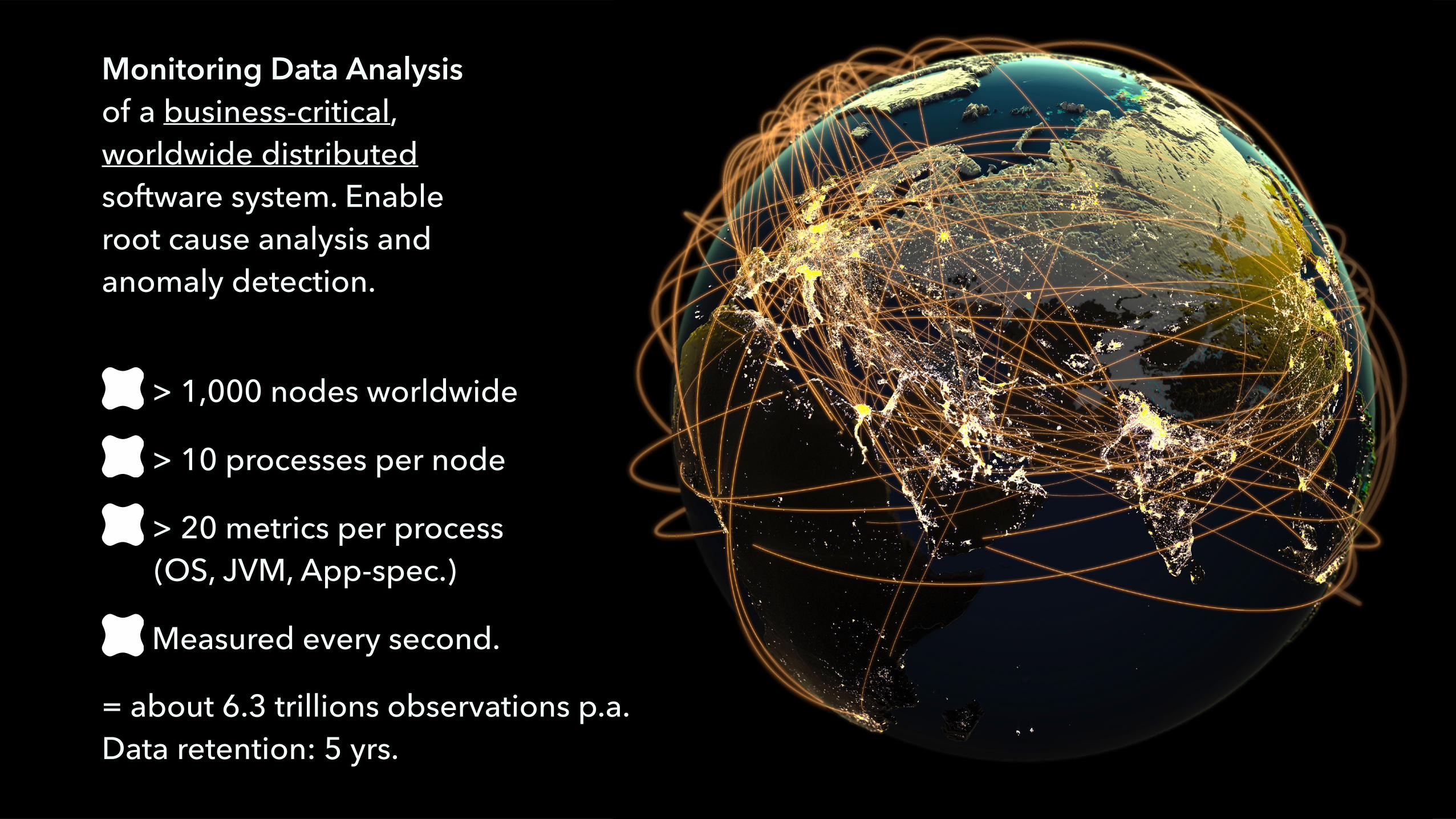
Monitoring Data Analysis of a business-critical,worldwide distributed software system. Enableroot cause analysis and anomaly detection.
> 1,000 nodes worldwide
> 10 processes per node
> 20 metrics per process (OS, JVM, App-spec.)
Measured every second.
= about 6.3 trillions observations p.a.Data retention: 5 yrs.


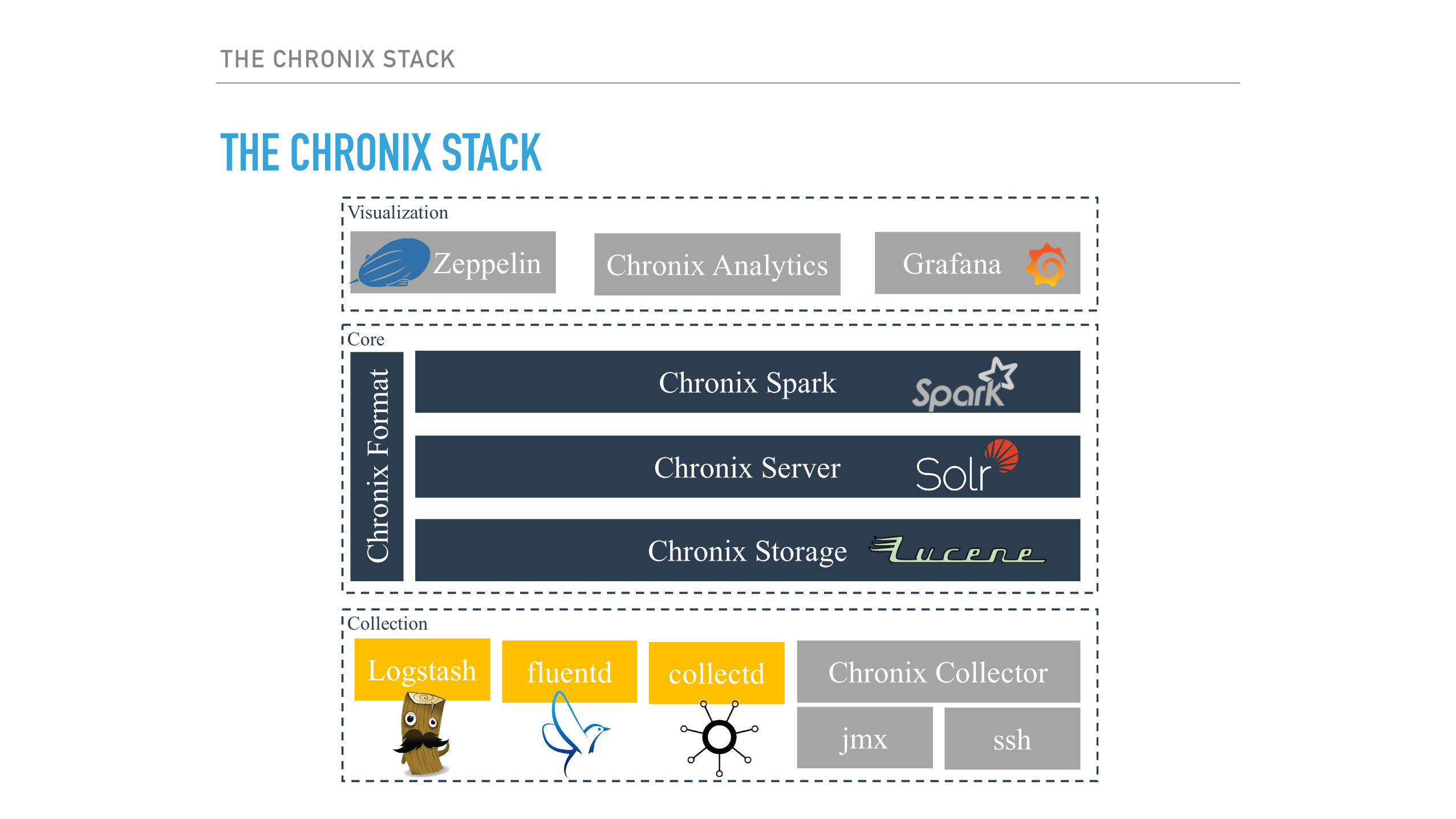
THE CHRONIX STACK
THE CHRONIX STACK
Core
Chronix Storage
Chronix Server
Chronix SparkC
hron
ix F
orm
at
GrafanaChronix Analytics
Collection
Visualization
Chronix CollectorLogstash fluentd
jmx
collectd
ssh
Zeppelin

THE CHRONIX STACK
node
Distributed Data &Data Retrieval
Distributed Processing
Result Processing data flow
icon credits to Nimal Raj (database), Arthur Shlain (console) and alvarobueno (takslist)
}
}
Chro
nix
Spar
kCh
roni
x Se
rver
USE CASE
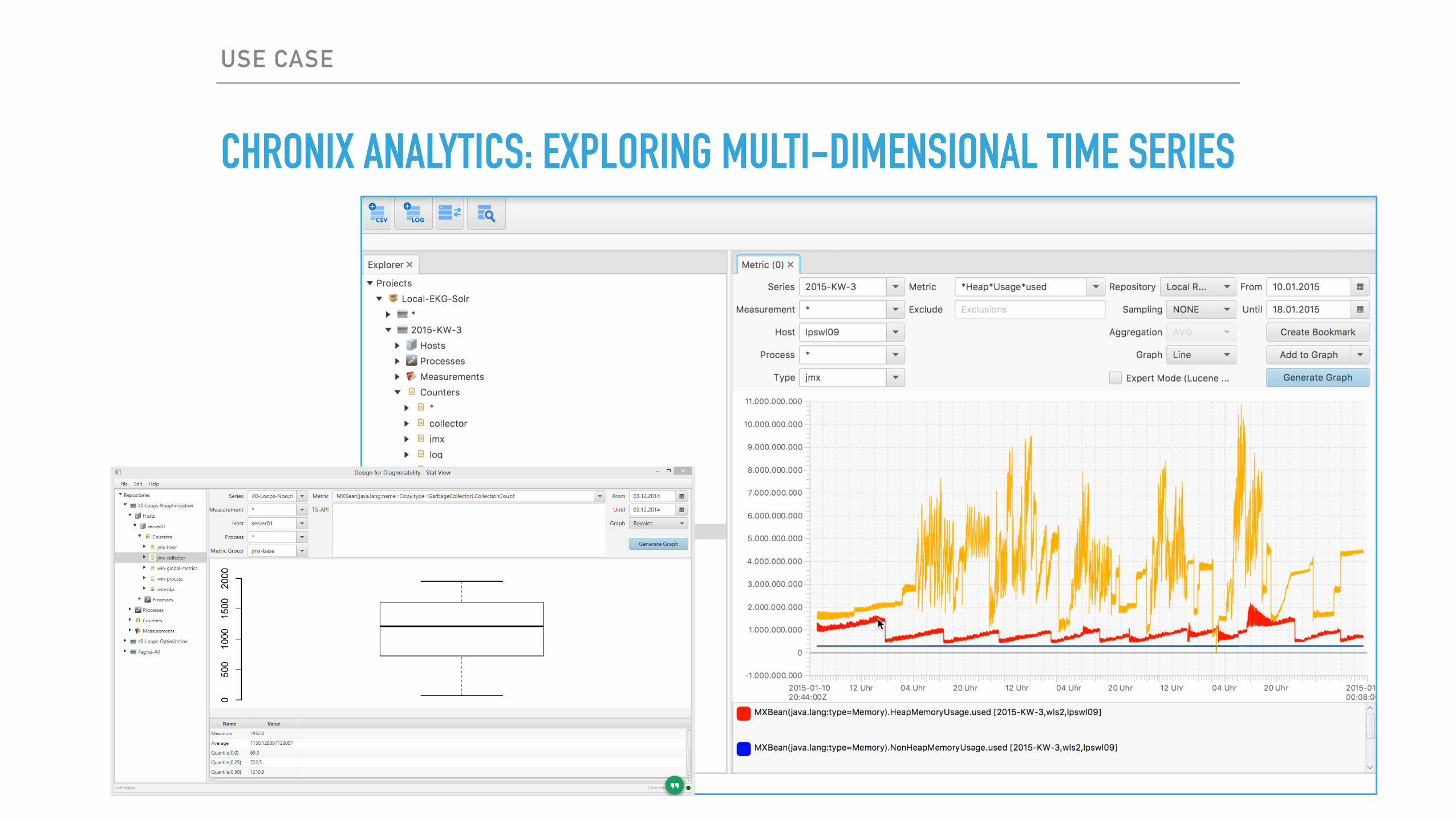
CHRONIX ANALYTICS: EXPLORING MULTI-DIMENSIONAL TIME SERIES
USE CASE
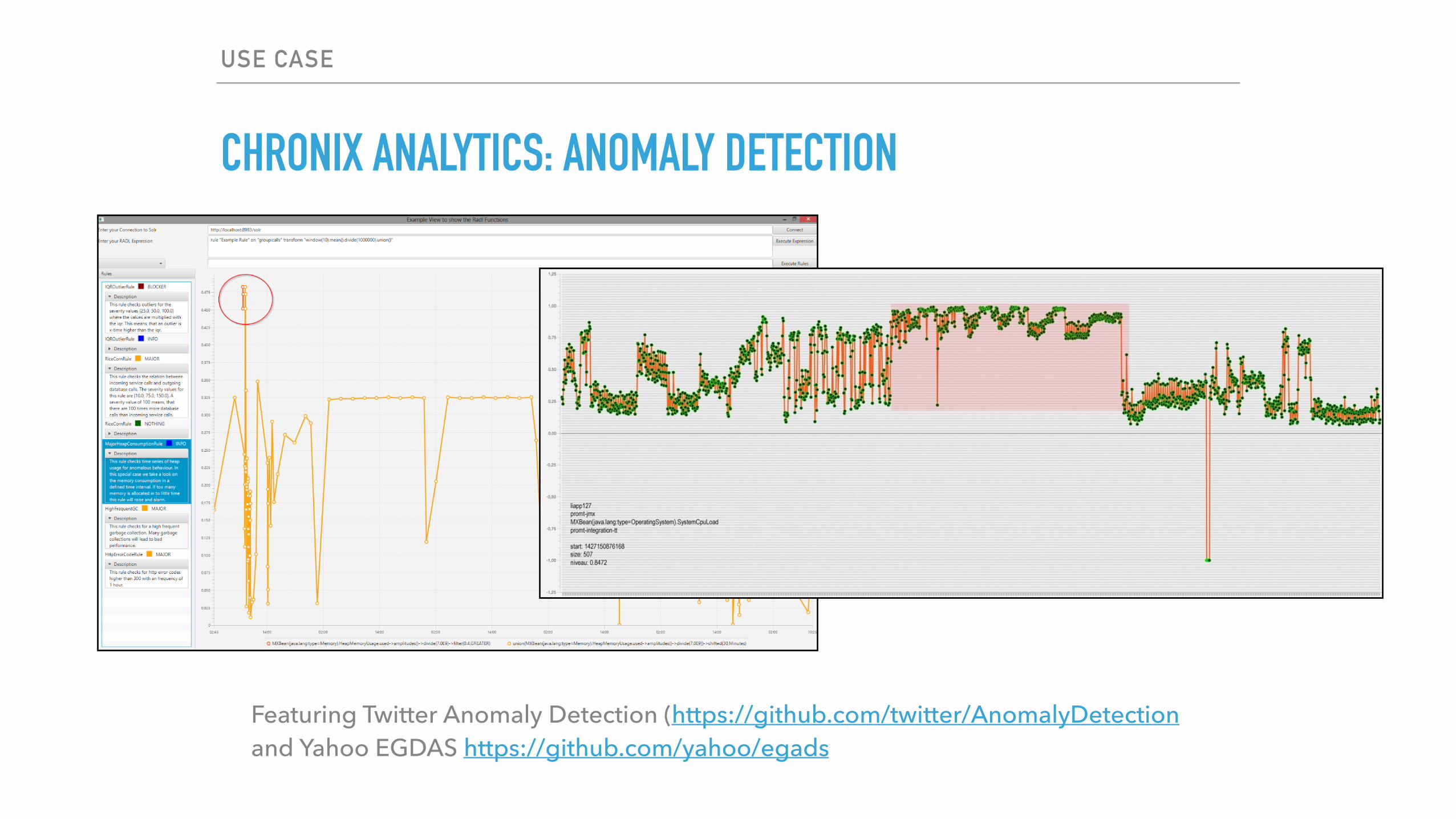
CHRONIX ANALYTICS: ANOMALY DETECTION
Featuring Twitter Anomaly Detection (https://github.com/twitter/AnomalyDetectionand Yahoo EGDAS https://github.com/yahoo/egads
USE CASE
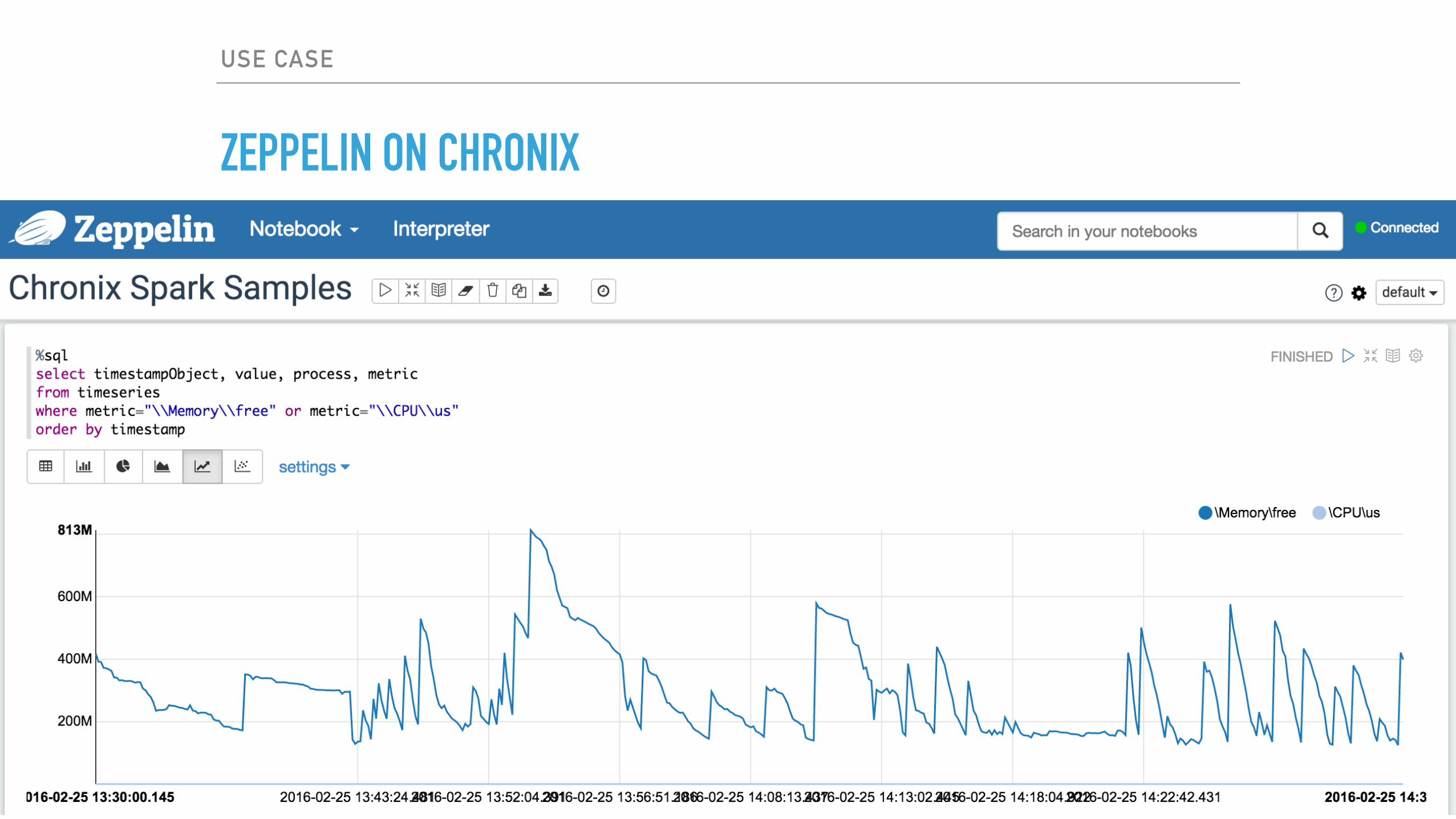
ZEPPELIN ON CHRONIX

EASY-TO-USE BIG TIME SERIES DATA STORAGE & PROCESSING ON SPARK
MISSION

MISSION
(as well as for data scientists)

CHRONIX SPARK
TIME SERIES MODEL
Set of univariate multi-dimensional numeric time series
▸ set … because it’s more flexible and better to parallelise if operations can input and output multiple time series.
▸ univariate … because multivariate will introduce too much complexity (and we have our set to bundle multiple time series).
▸ multi-dimensional … because the ability to slice & dice in the set of time series is very convenient for a lot of use cases.
▸ numeric … because it’s the most common use case.
A single time series is identified by a combination of its non-temporal dimensional values (e.g. unit “mem usage” + host “aws42” + process “tomcat”)

CHRONIX SPARK
CHRONIX SPARK
ChronixRDD
ChronixSparkContext
‣ Represents a set of time series ‣Distributed operations on sets of time series
‣Creates ChronixRDDs ‣ Speaks with the Chronix Server (Solr)

CHRONIX SPARK
ChronixRDD
transform to a Dataset
extends
transform to a DataFrame (SQL!)
the set characteristic: a JavaRDD of MetricTimeSeries
CHRONIX SPARK
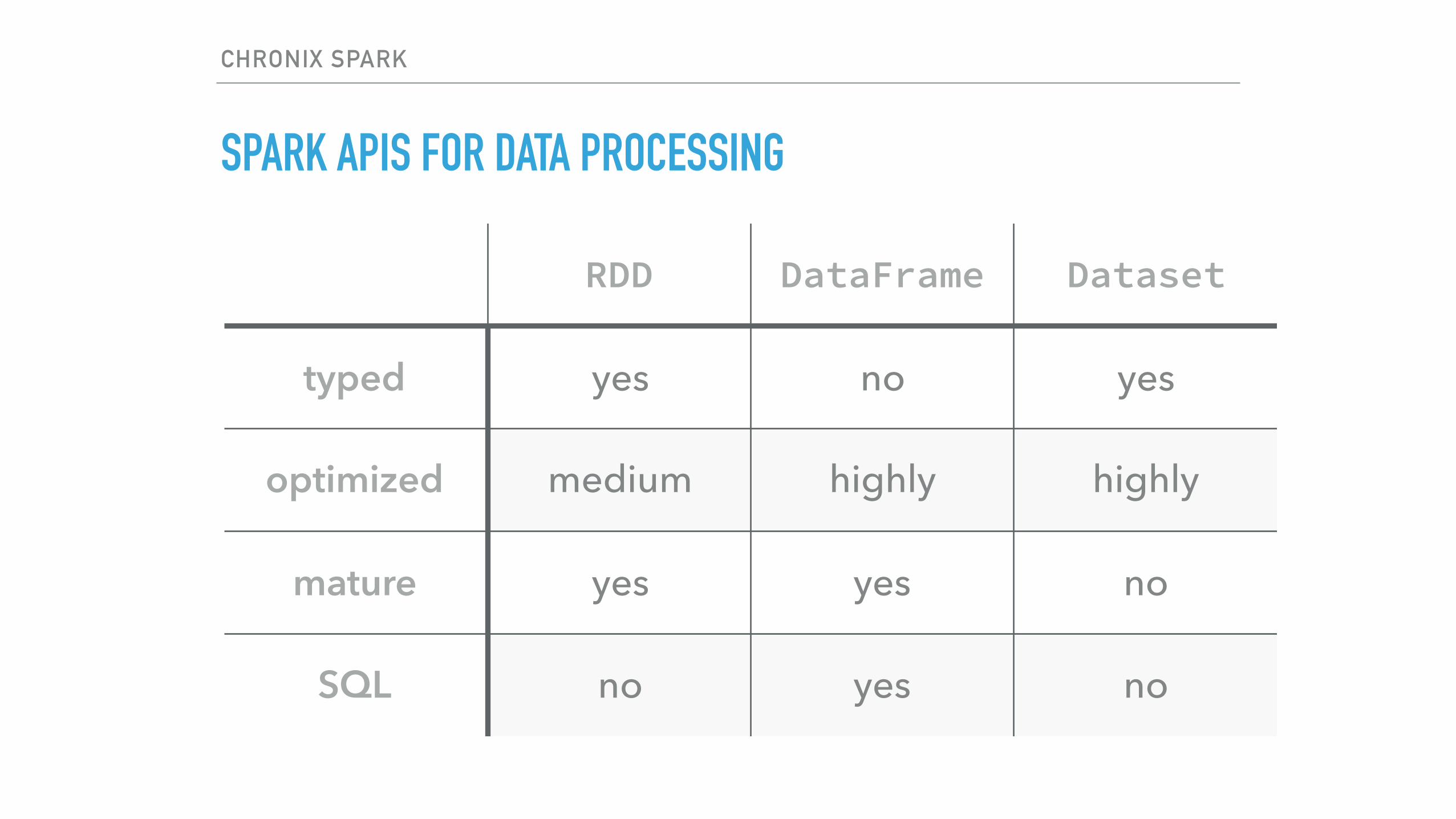
SPARK APIS FOR DATA PROCESSING
RDD DataFrame Dataset
typed yes no yes
optimized medium highly highly
mature yes yes no
SQL no yes no

CHRONIX SPARK
THE MetricTimeSeries DATA TYPEaccess all timestamps
access all observations as stream
the multi-dimensionality:get/set dimensions(attributes)
access all numeric values(univariate)

CHRONIX SPARK
THE OVERALL DATA MODEL
ChronixRDD
MetricTimeSeries
MetricObservation Dataset<MetricObservation>
Dataset<MetricTimeSeries>
DataFrame
toDataFrame()
toDataset()
toObservationsDataset()

CHRONIX SPARK
ChronixSparkContext
RDD on all time series matched by a SolrQuery:
/** * @param query Solr query * @param zkHost Zookeeper host * @param collection the Solr collection of chronix time series data * @param chronixStorage a ChronixSolrCloudStorage instance * @return ChronixRDD of time series */public ChronixRDD query( final SolrQuery query, final String zkHost, final String collection, final ChronixSolrCloudStorage chronixStorage) {
CHRONIX SPARK
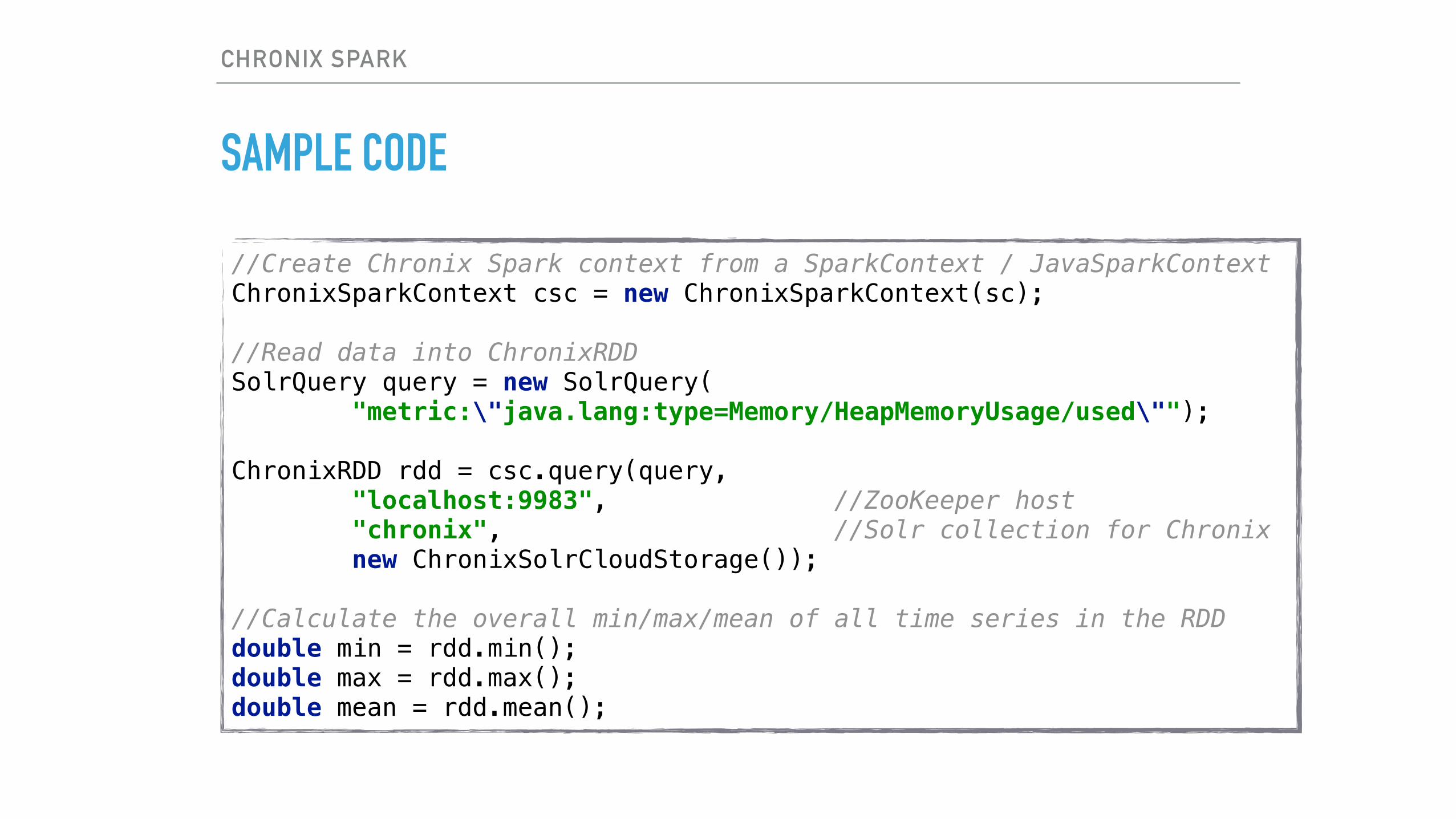
SAMPLE CODE
//Create Chronix Spark context from a SparkContext / JavaSparkContextChronixSparkContext csc = new ChronixSparkContext(sc);//Read data into ChronixRDDSolrQuery query = new SolrQuery( "metric:\"java.lang:type=Memory/HeapMemoryUsage/used\"");ChronixRDD rdd = csc.query(query, "localhost:9983", //ZooKeeper host "chronix", //Solr collection for Chronix new ChronixSolrCloudStorage());//Calculate the overall min/max/mean of all time series in the RDDdouble min = rdd.min();double max = rdd.max();double mean = rdd.mean();

DEMO TIME
‣ 8,707 time series with 76,983,735 observations ‣ one MacBook with 4 cores
https://github.com/ChronixDB/chronix.spark/tree/master/chronix-infrastructure-local

28
A TRIP TOCHRONIX SPARK WONDERLAND

CHRONIX SPARK WONDERLAND
‣ Data sharding ‣ Fast index-based queries and
aggregations ‣ Efficient storage format
‣ Heavy lifting distributed processing
‣ Catalyst processing optimizer
‣ Post-processing on a smaller set of time series (e.g. complex analysis algorithms)

CHRONIX SPARK WONDERLAND
}
}
Chro
nix
Spar
kCh
roni
x Se
rver

… with a few custom extensions.
▸ Index machine.
▸ Powerful query language based on Lucene. Powerful aggregation features (facets). E.g. groups way better than Spark.

CHRONIX SPARK WONDERLAND
ARCHITECTURE
Shard2
Solr Server
Zookeeper
Solr ServerSolr Server
Shard1
Zookeeper Zookeeper Zookeeper Cluster
Solr Cloud
Leader
Scale Out
Shard3
Replica8 Replica9
Shard5Shard4 Shard6 Shard8Shard7 Shard9
Replica2 Replica3 Replica5
Shards
Replicas
Collection
Replica4 Replica7 Replica1 Shard6

CHRONIX SPARK WONDERLAND
STORAGE FORMAT
TIME SERIES ‣ start: TimeStamp ‣ end: TimeStamp ‣ unit: String ‣ dimensions: Map<String, String> ‣ values: byte[]
TIME SERIES ‣ start: TimeStamp ‣ end: TimeStamp ‣ unit: String ‣ dimensions: Map<String, String> ‣ values: byte[]
TIME SERIES ‣ start: TimeStamp ‣ end: TimeStamp ‣ unit: String ‣ dimensions: Map<String, String> ‣ values: byte[]
▸ Chunking:1 logical time series = n physical time series all with the same identity containing a fixed amount of observations. 1 chunk = 1 solr document.
▸ Binary encoding of alltimestamp/value pairs. Delta-encoded and bitwise compressed.
Logical
Physical

CHRONIX SPARK WONDERLAND
CHRONIX FORMAT: OPTIMAL CHUNK SIZE AND COMPRESSION CODEC
GZIP + 128
kBytes
Florian Lautenschlager, Michael Philippsen, Andreas Kumlehn, Josef AdersbergerChronix: Efficient Storage and Query of Operational Time Series International Conference on Software Maintenance and Evolution 2016 (submitted)

CHRONIX SPARK WONDERLAND
BENCHMARK: STORAGE DEMAND
Florian Lautenschlager, Michael Philippsen, Andreas Kumlehn, Josef AdersbergerChronix: Efficient Storage and Query of Operational Time SeriesInternational Conference on Software Maintenance and Evolution 2016 (submitted)
CHRONIX SPARK WONDERLAND
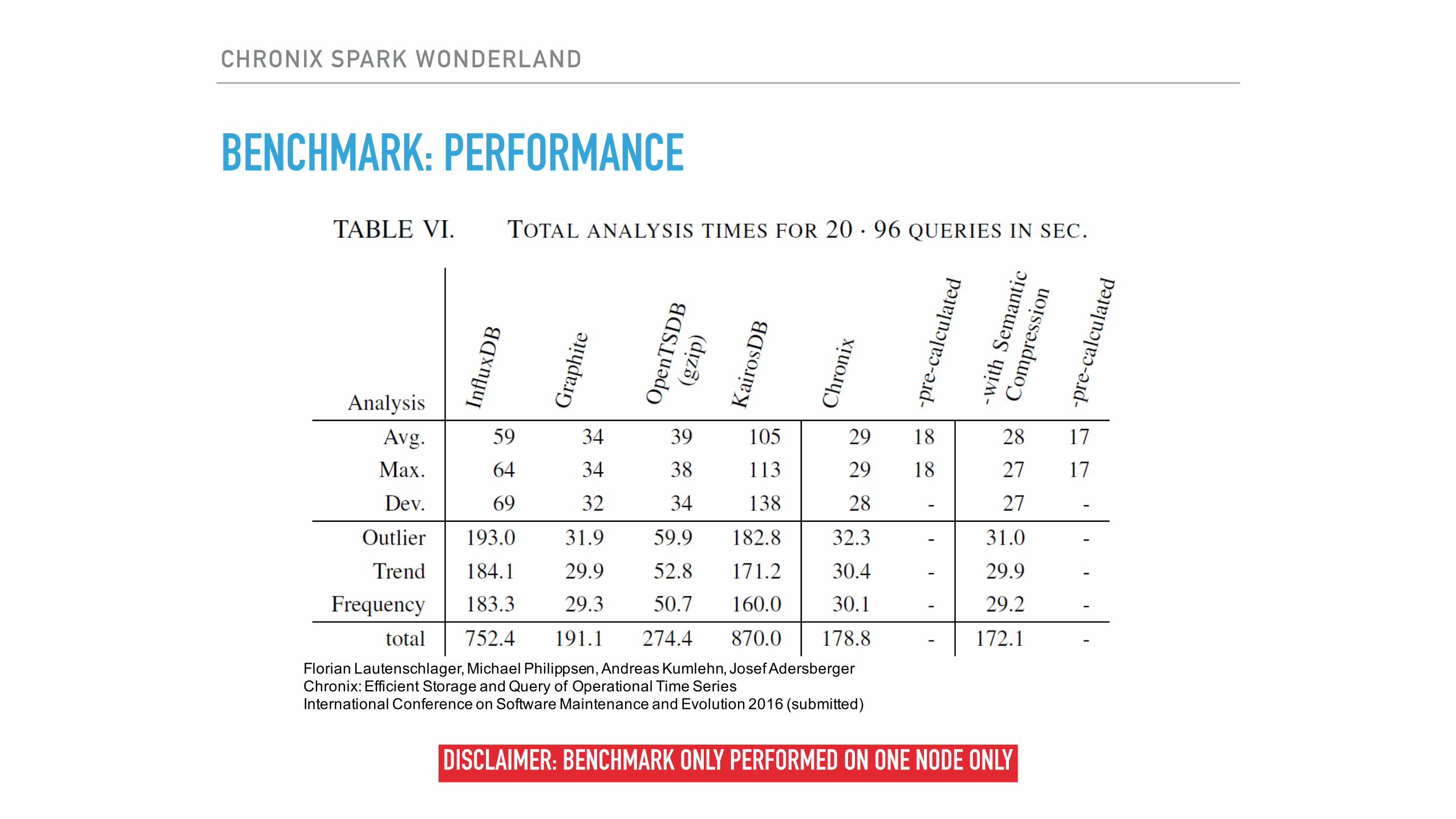
BENCHMARK: PERFORMANCE
Florian Lautenschlager, Michael Philippsen, Andreas Kumlehn, Josef AdersbergerChronix: Efficient Storage and Query of Operational Time SeriesInternational Conference on Software Maintenance and Evolution 2016 (submitted)
DISCLAIMER: BENCHMARK ONLY PERFORMED ON ONE NODE ONLY
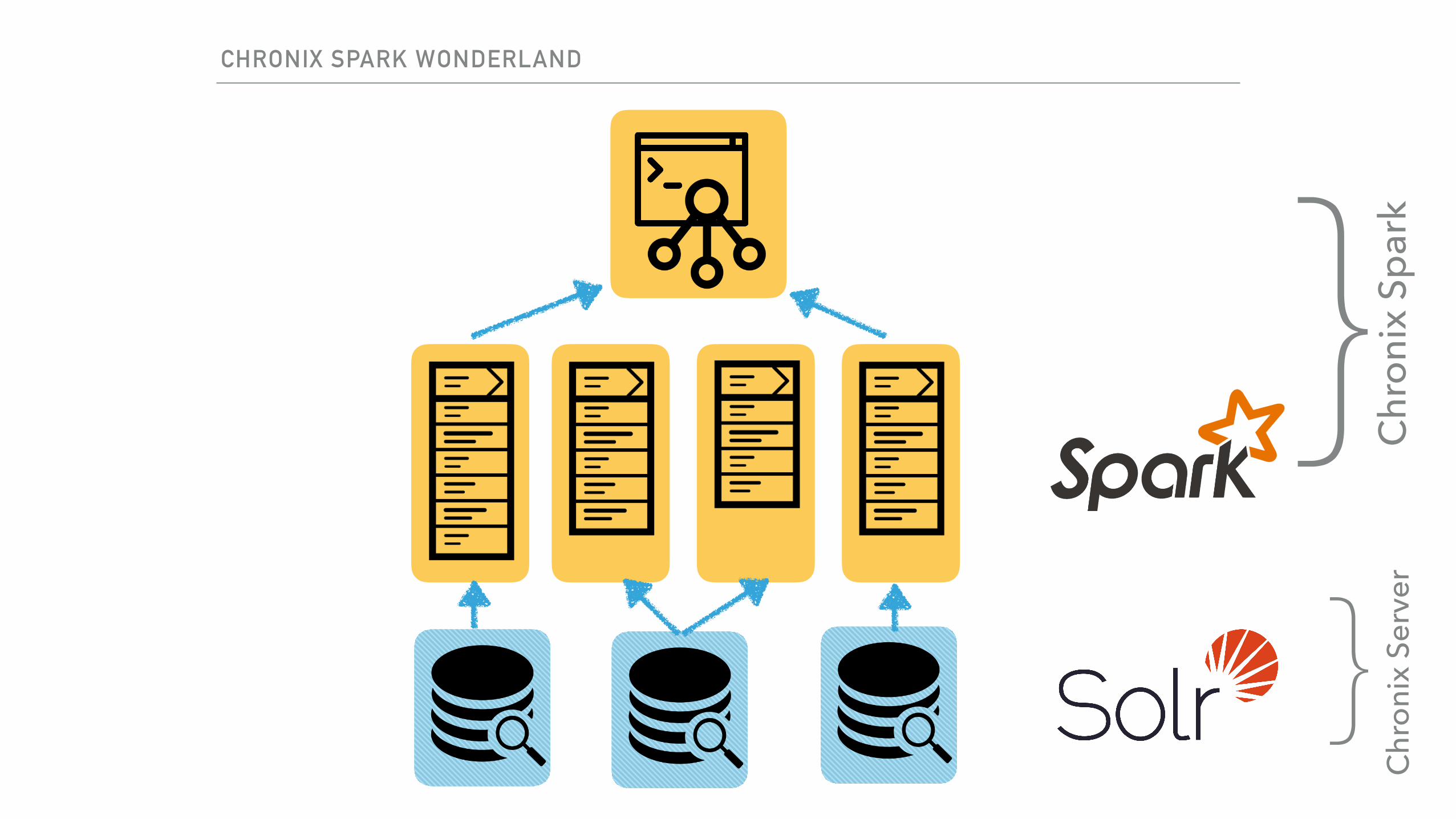
CHRONIX SPARK WONDERLAND
}
}
Chro
nix
Spar
kCh
roni
x Se
rver

CHRONIX SPARK WONDERLAND
SolrDocumentSolr Shard
SolrDocument SolrDocument SolrDocumentSolr Shard
SolrDocument
TimeSeries TimeSeries TimeSeries TimeSeries TimeSeries
Partition Partition
ChronixRDD
Binary protocol
1 SolrDocument = 1 Chunk
1 Spark Partition = 1 Solr Shard

CHRONIX SPARK WONDERLAND
ChronixRDD CREATION: GET THE CHUNKS
public ChronixRDD queryChronixChunks( final SolrQuery query, final String zkHost, final String collection, final ChronixSolrCloudStorage<MetricTimeSeries> chronixStorage) throws SolrServerException, IOException { // first get a list of replicas to query for this collection List<String> shards = chronixStorage.getShardList(zkHost, collection); // parallelize the requests to the shards JavaRDD<MetricTimeSeries> docs = jsc.parallelize(shards, shards.size()).flatMap( (FlatMapFunction<String, MetricTimeSeries>) shardUrl -> chronixStorage.streamFromSingleNode( new KassiopeiaSimpleConverter(), shardUrl, query)::iterator); return new ChronixRDD(docs);}
Figure out all Solr shards
Query each shard in parallel and convert SolrDocuments to MetricTimeSeries

CHRONIX SPARK WONDERLAND
ChronixRDD CREATION: JOIN THEM TOGETHER TO A LOGICAL TIME SERIESpublic ChronixRDD joinChunks() { JavaPairRDD<MetricTimeSeriesKey, Iterable<MetricTimeSeries>> groupRdd = this.groupBy(MetricTimeSeriesKey::new); JavaPairRDD<MetricTimeSeriesKey, MetricTimeSeries> joinedRdd = groupRdd.mapValues((Function<Iterable<MetricTimeSeries>, MetricTimeSeries>) mtsIt -> { MetricTimeSeriesOrdering ordering = new MetricTimeSeriesOrdering(); List<MetricTimeSeries> orderedChunks = ordering.immutableSortedCopy(mtsIt); MetricTimeSeries result = null; for (MetricTimeSeries mts : orderedChunks) { if (result == null) { result = new MetricTimeSeries .Builder(mts.getMetric()) .attributes(mts.attributes()).build(); } result.addAll(mts.getTimestampsAsArray(), mts.getValuesAsArray()); } return result; }); JavaRDD<MetricTimeSeries> resultJavaRdd = joinedRdd.map((Tuple2<MetricTimeSeriesKey, MetricTimeSeries> mtTuple) -> mtTuple._2); return new ChronixRDD(resultJavaRdd); }
group chunks according identity
join chunks tological time series

PERFORMANCE
PERFORMANCE
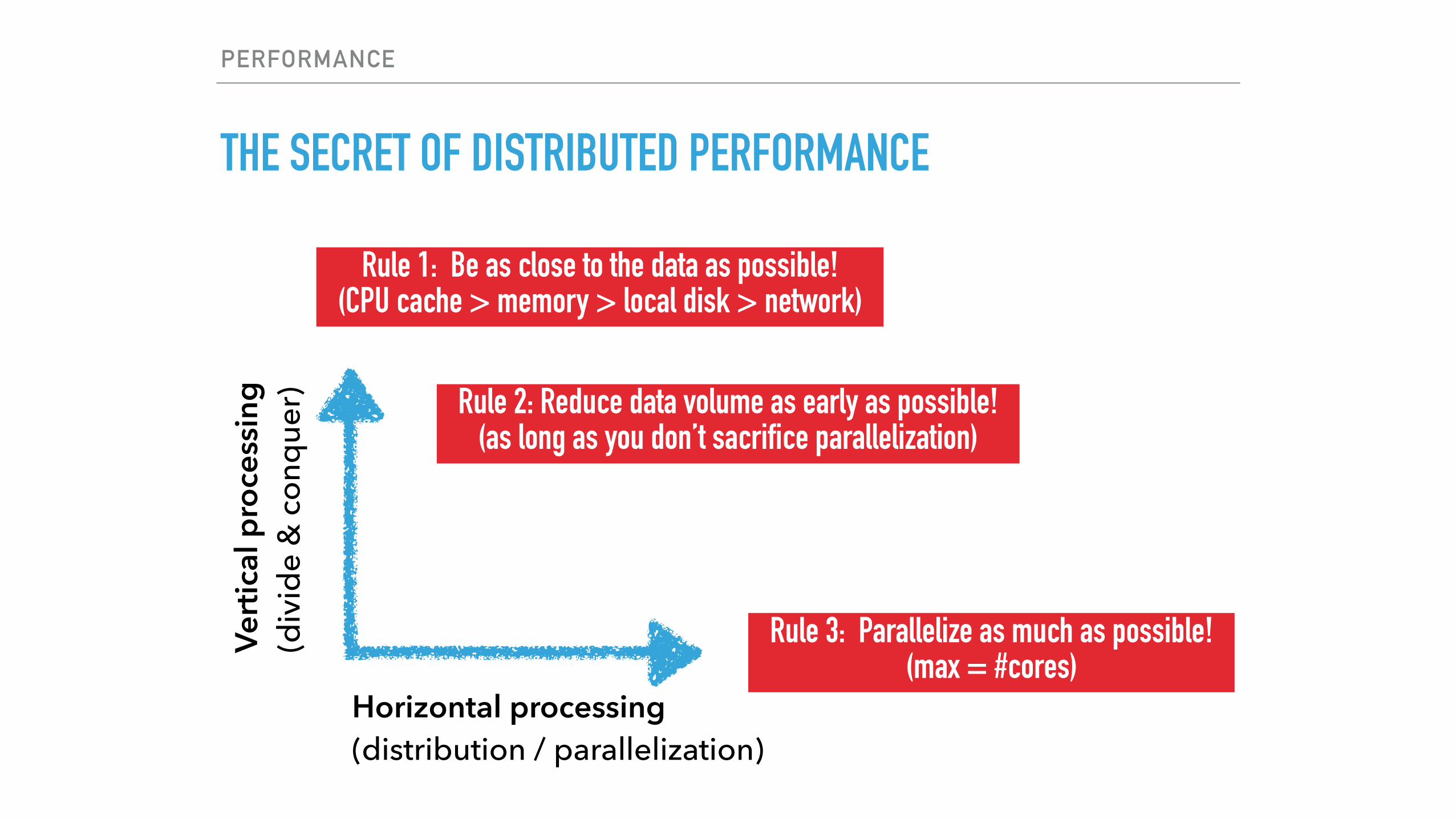
THE SECRET OF DISTRIBUTED PERFORMANCE
Rule 1: Be as close to the data as possible!(CPU cache > memory > local disk > network)
Horizontal processing (distribution / parallelization)
Verti
cal p
roce
ssin
g
(div
ide
& c
onqu
er) Rule 2: Reduce data volume as early as possible!
(as long as you don’t sacrifice parallelization)
Rule 3: Parallelize as much as possible! (max = #cores)

PERFORMANCE
THE RULES APPLIED
‣ Rule 1: Be as close to the data as possible! 1. Solr caching2. Spark in-memory processing with activated RDD compression3. Binary protocol between Solr and Spark
‣ Rule 2: Reduce data volume as early as possible! ‣ Efficient storage format (Chronix Format)‣ Predicate pushdown to Solr (query)‣ Group-by & aggregation pushdown to Solr (faceting within a query)
‣ Rule 3: Parallelize as much as possible! ‣ Scale-out on data-level with SolrCloud‣ Scale-out on processing-level with Spark

RULE 4: PREMATURE OPTIMIZATION IS NOT EVIL IF YOU HANDLE BIG DATA
Josef Adersberger
PERFORMANCE
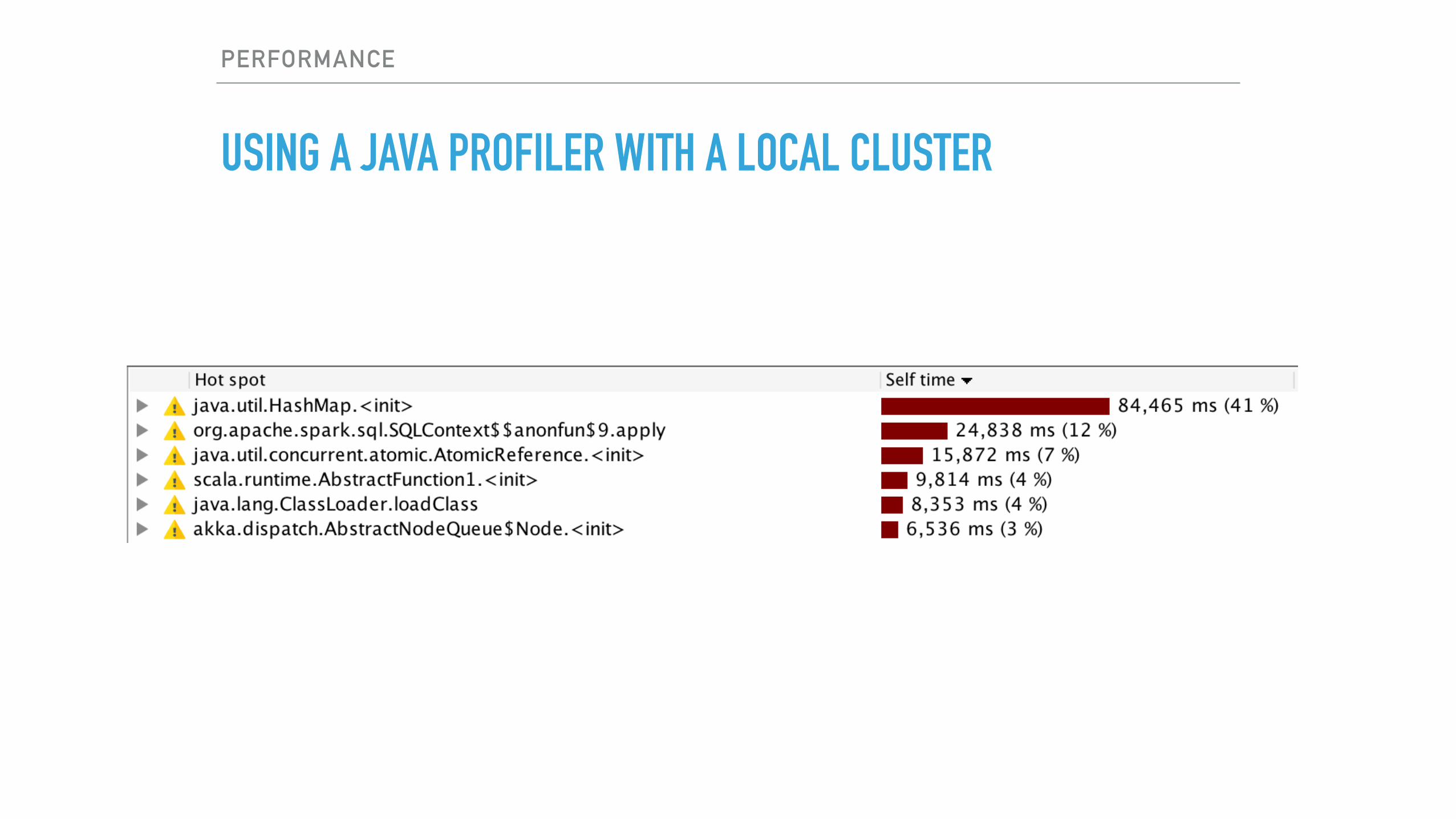
USING A JAVA PROFILER WITH A LOCAL CLUSTER

PERFORMANCE
HIGH-PERFORMANCE, LOW-OVERHEAD COLLECTIONS

PERFORMANCE
830 MB -> 360 MB(- 57%)
unveiled wrong Jackson handling inside of SolrClient

PERFORMANCE
PROFILING ChronixRDD WITH PLAIN VANILLA SPARK
Watch out for branches!
Watch out for shuffling!

ROADMAP

ROADMAP
THINGS TO COME
see https://github.com/ChronixDB/chronix.spark/issues
v0.4(06/16)
v0.5(08/16)
v0.6(10/16)
v1.0(12/16)
More actions and transformations
Bulk transfer Solr request handler Streaming access R wrapper
Reduce memory overhead
Data locality (co-location) SparkML support Custom Dataset
encoder
SolrRDD adapter Incorporate alien technology

JohannesJosef
LukasClaudio
Johannes
Flaute
Cloud
THE CONTRIBUTORS
YOU!

TWITTER.COM/QAWARE - SLIDESHARE.NET/QAWARE
Thank you! Questions?
[email protected] @adersberger https://github.com/ChronixDB/chronix.spark

BONUS SLIDES

55
THE COMPETITORS

THE COMPETITORS / ALTERNATIVES
THE COMPETITORS / ALTERNATIVES
▸ Small Time Series Data
▸ Matlab (Econometrics toolbox)
▸ Python (Pandas)
▸ R (zoo, xts)
▸ SAS (ETS)
▸ …
▸ Big Time Series Data
▸ influxDB
▸ Graphite
▸ OpenTSDB
▸ KairosDB
▸ Prometheus
▸ …

THE COMPETITORS / ALTERNATIVES
BIG DATA LANDSCAPE
https://github.com/qaware/big-data-landscape

THE COMPETITORS / ALTERNATIVES
CHRONIX RDD VS. SPARK-TS
▸ Spark-TS provides no specific time series storage it uses the Spark persistence mechanisms instead. This leads to a less efficient storage usage and less possibilities to perform performance optimizations via predicate pushdown.
▸ In contrast to Spark-TS Chronix does not align all time series values on one vector of timestamps. This leads to greater flexibility in time series aggregation
▸ Chronix provides multi-dimensional time series as this is very useful for data warehousing and APM.
▸ Chronix has support for Datasets as this will be an important Spark API in the near future. But Chronix currently doesn’t support an IndexedRowMatrix for SparkML.
▸ Chronix is purely written in Java. There is no explicit support for Python and Scala yet.
▸ Chronix doesn not support a ZonedTime as this makes it way more complicated.

59
APACHE SPARK 101

CHRONIX SPARK WONDERLAND
ARCHITECTURE

APACHE SPARK
SPARK TERMINOLOGY (1/2)
▸ RDD: Has transformations and actions. Hides data partitioning & distributed computation. References a set of partitions (“output partitions”) - materialized or not - and has dependencies to another RDD (“input partitions”). RDD operations are evaluated as late as possible (when an action is called). As long as not being the root RDD the partitions of an RDD are in memory but they can be persisted by request.
▸ Partitions: (Logical) chunks of data. Default unit and level of parallelism - inside of a partition everything is a sequential operation on records. Has to fit into memory. Can have different representations (in-memory, on disk, off heap, …)

APACHE SPARK
SPARK TERMINOLOGY (2/2)
▸ Job: A computation job which is launched when an action is called on a RDD.
▸ Task: The atomic unit of work (function). Bound to exactly one partition.
▸ Stage: Set of Task pipelines which can be executed in parallel on one executor.
▸ Shuffling: If partitions need to be transferred between executors. Shuffle write = outbound partition transfer. Shuffle read = inbound partition transfer.
▸ DAG Scheduler: Computes DAG of stages from RDD DAG. Determines the preferred location for each task.
Recommended




















