
Designing Scalable HPC, Deep Learning, Big Data, and Cloud Middleware for Exascale Systems
Dhabaleswar K. (DK) Panda
The Ohio State University
E-mail: [email protected]
http://www.cse.ohio-state.edu/~panda
Talk at SCEC ’18 Workshop
by
SCEC (Dec ‘18) 2Network Based Computing Laboratory
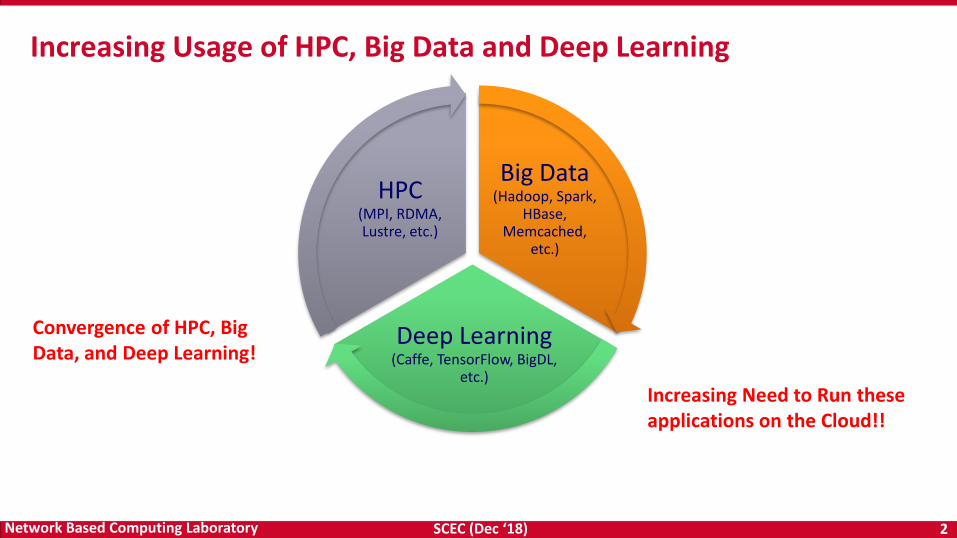
Big Data (Hadoop, Spark,
HBase, Memcached,
etc.)
Deep Learning(Caffe, TensorFlow, BigDL,
etc.)
HPC (MPI, RDMA, Lustre, etc.)
Increasing Usage of HPC, Big Data and Deep Learning
Convergence of HPC, Big Data, and Deep Learning!
Increasing Need to Run these applications on the Cloud!!

SCEC (Dec ‘18) 3Network Based Computing Laboratory
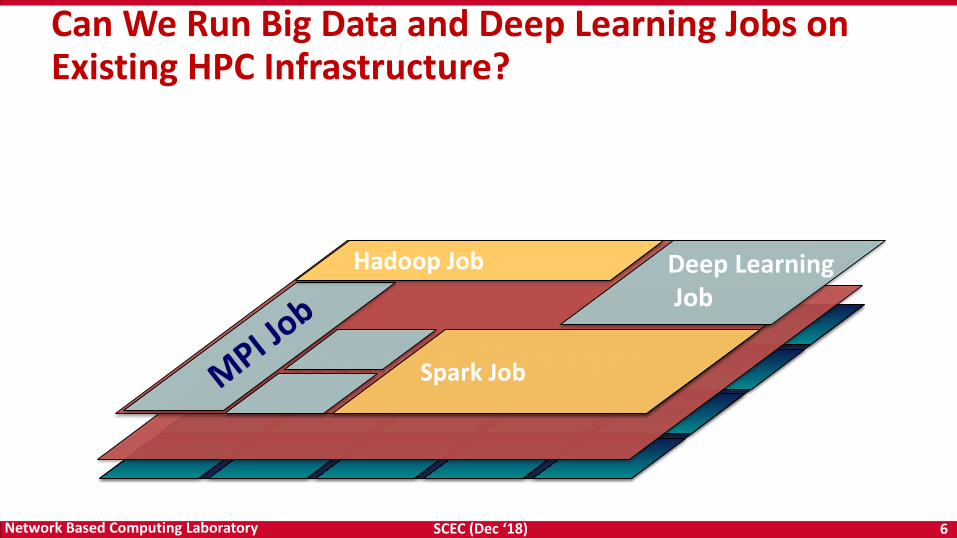
Can We Run Big Data and Deep Learning Jobs on Existing HPC Infrastructure?
Physical Compute

SCEC (Dec ‘18) 4Network Based Computing Laboratory
Can We Run Big Data and Deep Learning Jobs on Existing HPC Infrastructure?

SCEC (Dec ‘18) 5Network Based Computing Laboratory
Can We Run Big Data and Deep Learning Jobs on Existing HPC Infrastructure?
SCEC (Dec ‘18) 6Network Based Computing Laboratory
Can We Run Big Data and Deep Learning Jobs on Existing HPC Infrastructure?
Spark Job
Hadoop Job Deep LearningJob

SCEC (Dec ‘18) 7Network Based Computing Laboratory
• Traditional HPC
– Message Passing Interface (MPI), including MPI + OpenMP
– Exploiting Accelerators
• Deep Learning
– Caffe, CNTK, TensorFlow, and many more
• Big Data/Enterprise/Commercial Computing
– Spark and Hadoop (HDFS, HBase, MapReduce)
– Deep Learning over Big Data (DLoBD)
• Cloud for HPC and BigData
– Virtualization with SR-IOV and Containers
HPC, Big Data, Deep Learning, and Cloud
SCEC (Dec ‘18) 8Network Based Computing Laboratory
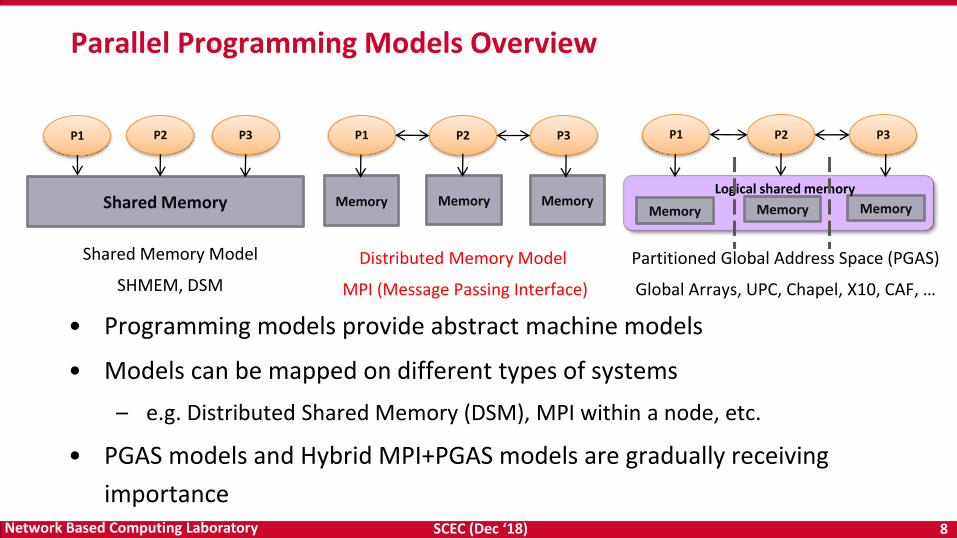
Parallel Programming Models Overview
P1 P2 P3
Shared Memory
P1 P2 P3
Memory Memory Memory
P1 P2 P3
Memory Memory Memory
Logical shared memory
Shared Memory Model
SHMEM, DSM
Distributed Memory Model
MPI (Message Passing Interface)
Partitioned Global Address Space (PGAS)
Global Arrays, UPC, Chapel, X10, CAF, …
• Programming models provide abstract machine models
• Models can be mapped on different types of systems
– e.g. Distributed Shared Memory (DSM), MPI within a node, etc.
• PGAS models and Hybrid MPI+PGAS models are gradually receiving
importance
SCEC (Dec ‘18) 9Network Based Computing Laboratory
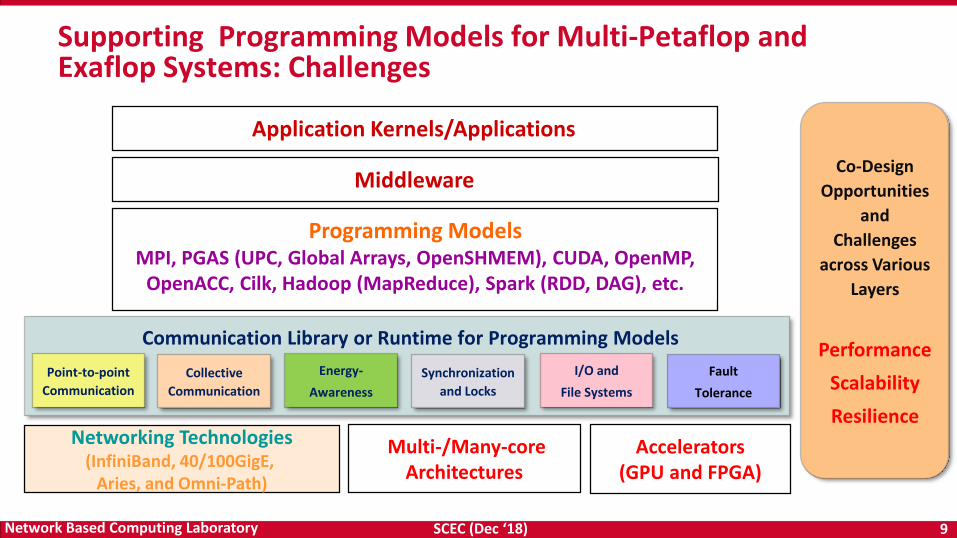
Supporting Programming Models for Multi-Petaflop and Exaflop Systems: Challenges
Programming ModelsMPI, PGAS (UPC, Global Arrays, OpenSHMEM), CUDA, OpenMP,
OpenACC, Cilk, Hadoop (MapReduce), Spark (RDD, DAG), etc.
Application Kernels/Applications
Networking Technologies(InfiniBand, 40/100GigE,
Aries, and Omni-Path)
Multi-/Many-coreArchitectures
Accelerators(GPU and FPGA)
MiddlewareCo-Design
Opportunities
and
Challenges
across Various
Layers
Performance
Scalability
Resilience
Communication Library or Runtime for Programming Models
Point-to-point
Communication
Collective
Communication
Energy-
Awareness
Synchronization
and Locks
I/O and
File Systems
Fault
Tolerance

SCEC (Dec ‘18) 10Network Based Computing Laboratory
• Scalability for million to billion processors– Support for highly-efficient inter-node and intra-node communication (both two-sided and one-sided)
– Scalable job start-up
– Low memory footprint
• Scalable Collective communication– Offload
– Non-blocking
– Topology-aware
• Balancing intra-node and inter-node communication for next generation nodes (128-1024 cores)– Multiple end-points per node
• Support for efficient multi-threading
• Integrated Support for Accelerators (GPGPUs and FPGAs)
• Fault-tolerance/resiliency
• QoS support for communication and I/O
• Support for Hybrid MPI+PGAS programming (MPI + OpenMP, MPI + UPC, MPI + OpenSHMEM, MPI+UPC++, CAF, …)
• Virtualization
• Energy-Awareness
Broad Challenges in Designing Runtimes for (MPI+X) at Exascale

SCEC (Dec ‘18) 11Network Based Computing Laboratory
Overview of the MVAPICH2 Project• High Performance open-source MPI Library for InfiniBand, Omni-Path, Ethernet/iWARP, and RDMA over Converged Ethernet (RoCE)
– MVAPICH (MPI-1), MVAPICH2 (MPI-2.2 and MPI-3.1), Started in 2001, First version available in 2002
– MVAPICH2-X (MPI + PGAS), Available since 2011
– Support for GPGPUs (MVAPICH2-GDR) and MIC (MVAPICH2-MIC), Available since 2014
– Support for Virtualization (MVAPICH2-Virt), Available since 2015
– Support for Energy-Awareness (MVAPICH2-EA), Available since 2015
– Support for InfiniBand Network Analysis and Monitoring (OSU INAM) since 2015
– Used by more than 2,950 organizations in 86 countries
– More than 511,000 (> 0.5 million) downloads from the OSU site directly
– Empowering many TOP500 clusters (Nov ‘18 ranking)
• 3rd ranked 10,649,640-core cluster (Sunway TaihuLight) at NSC, Wuxi, China
• 14th, 556,104 cores (Oakforest-PACS) in Japan
• 17th, 367,024 cores (Stampede2) at TACC
• 27th, 241,108-core (Pleiades) at NASA and many others
– Available with software stacks of many vendors and Linux Distros (RedHat, SuSE, and OpenHPC)
– http://mvapich.cse.ohio-state.edu
• Empowering Top500 systems for over a decade
Partner in the upcoming TACC Frontera System

SCEC (Dec ‘18) 12Network Based Computing Laboratory
0
100000
200000
300000
400000
500000
600000
Sep
-04
Feb
-05
Jul-
05
Dec
-05
May
-06
Oct
-06
Mar
-07
Au
g-0
7
Jan
-08
Jun
-08
No
v-0
8
Ap
r-0
9
Sep
-09
Feb
-10
Jul-
10
Dec
-10
May
-11
Oct
-11
Mar
-12
Au
g-1
2
Jan
-13
Jun
-13
No
v-1
3
Ap
r-1
4
Sep
-14
Feb
-15
Jul-
15
Dec
-15
May
-16
Oct
-16
Mar
-17
Au
g-1
7
Jan
-18
Jun
-18
No
v-1
8
Nu
mb
er o
f D
ow
nlo
ads
Timeline
MV
0.9
.4
MV
2 0
.9.0
MV
2 0
.9.8
MV
21
.0
MV
1.0
MV
21
.0.3
MV
1.1
MV
21
.4
MV
21
.5
MV
21
.6
MV
21
.7
MV
21
.8
MV
21
.9
MV
2-G
DR
2.0
b
MV
2-M
IC 2
.0
MV
2 2
.3M
V2
-X2
.3rc
1
MV
2V
irt
2.2
MV
2-G
DR
2.3
OSU
INA
M 0
.9.4
MVAPICH2 Release Timeline and Downloads

SCEC (Dec ‘18) 13Network Based Computing Laboratory
Architecture of MVAPICH2 Software Family
High Performance Parallel Programming Models
Message Passing Interface(MPI)
PGAS(UPC, OpenSHMEM, CAF, UPC++)
Hybrid --- MPI + X(MPI + PGAS + OpenMP/Cilk)
High Performance and Scalable Communication RuntimeDiverse APIs and Mechanisms
Point-to-
point
Primitives
Collectives
Algorithms
Energy-
Awareness
Remote
Memory
Access
I/O and
File Systems
Fault
ToleranceVirtualization
Active
MessagesJob Startup
Introspection
& Analysis
Support for Modern Networking Technology(InfiniBand, iWARP, RoCE, Omni-Path)
Support for Modern Multi-/Many-core Architectures(Intel-Xeon, OpenPower, Xeon-Phi, ARM, NVIDIA GPGPU)
Transport Protocols Modern Features
RC XRC UD DC UMR ODPSR-
IOV
Multi
Rail
Transport Mechanisms
Shared
MemoryCMA IVSHMEM
Modern Features
MCDRAM* NVLink* CAPI*
* Upcoming
XPMEM

SCEC (Dec ‘18) 14Network Based Computing Laboratory
MVAPICH2 Software Family
Requirements Library
MPI with IB, iWARP, Omni-Path, and RoCE MVAPICH2
Advanced MPI Features/Support, OSU INAM, PGAS and MPI+PGAS with IB, Omni-Path, and RoCE
MVAPICH2-X
MPI with IB, RoCE & GPU and Support for Deep Learning MVAPICH2-GDR
HPC Cloud with MPI & IB MVAPICH2-Virt
Energy-aware MPI with IB, iWARP and RoCE MVAPICH2-EA
MPI Energy Monitoring Tool OEMT
InfiniBand Network Analysis and Monitoring OSU INAM
Microbenchmarks for Measuring MPI and PGAS Performance OMB

SCEC (Dec ‘18) 15Network Based Computing Laboratory
• Scalability for million to billion processors– Support for highly-efficient inter-node and intra-node communication
– Scalable Start-up
– Optimized Collectives using SHArP and Multi-Leaders
– Optimized CMA-based and XPMEM-based Collectives
– Asynchronous Progress
• Exploiting Accelerators (NVIDIA GPGPUs)
• Optimized MVAPICH2 for OpenPower (with/ NVLink) and ARM
• Application Scalability and Best Practices
Overview of A Few Challenges being Addressed by the MVAPICH2 Project for Exascale
SCEC (Dec ‘18) 16Network Based Computing Laboratory
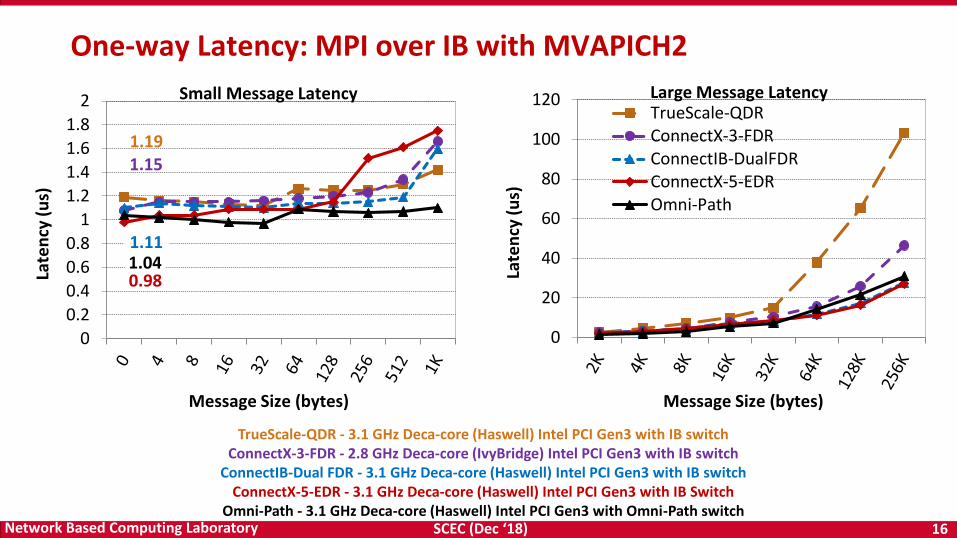
One-way Latency: MPI over IB with MVAPICH2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2 Small Message Latency
Message Size (bytes)
Late
ncy
(u
s)
1.11
1.19
0.98
1.15
1.04
TrueScale-QDR - 3.1 GHz Deca-core (Haswell) Intel PCI Gen3 with IB switchConnectX-3-FDR - 2.8 GHz Deca-core (IvyBridge) Intel PCI Gen3 with IB switch
ConnectIB-Dual FDR - 3.1 GHz Deca-core (Haswell) Intel PCI Gen3 with IB switchConnectX-5-EDR - 3.1 GHz Deca-core (Haswell) Intel PCI Gen3 with IB Switch
Omni-Path - 3.1 GHz Deca-core (Haswell) Intel PCI Gen3 with Omni-Path switch
0
20
40
60
80
100
120TrueScale-QDRConnectX-3-FDRConnectIB-DualFDRConnectX-5-EDROmni-Path
Large Message Latency
Message Size (bytes)
Late
ncy
(u
s)

SCEC (Dec ‘18) 17Network Based Computing Laboratory
TrueScale-QDR - 3.1 GHz Deca-core (Haswell) Intel PCI Gen3 with IB switchConnectX-3-FDR - 2.8 GHz Deca-core (IvyBridge) Intel PCI Gen3 with IB switch
ConnectIB-Dual FDR - 3.1 GHz Deca-core (Haswell) Intel PCI Gen3 with IB switchConnectX-5-EDR - 3.1 GHz Deca-core (Haswell) Intel PCI Gen3 IB switch
Omni-Path - 3.1 GHz Deca-core (Haswell) Intel PCI Gen3 with Omni-Path switch
Bandwidth: MPI over IB with MVAPICH2
0
5000
10000
15000
20000
25000TrueScale-QDR
ConnectX-3-FDR
ConnectIB-DualFDR
ConnectX-5-EDR
Omni-Path
Bidirectional Bandwidth
Ban
dw
idth
(M
Byt
es/
sec)
Message Size (bytes)
22,564
12,161
21,983
6,228
24,136
0
2000
4000
6000
8000
10000
12000
14000 Unidirectional Bandwidth
Ban
dw
idth
(M
Byt
es/
sec)
Message Size (bytes)
12,590
3,373
6,356
12,35812,366

SCEC (Dec ‘18) 18Network Based Computing Laboratory
0
20
40
60
80
64
12
82
56
51
2
1K
2K
4K
8K
16
K
32
K6
4K
12
8K
18
0K
23
0K
Tim
e (s
eco
nd
s)
Number of Processes
TACC Stampede2
MPI_Init Hello World
Startup Performance on KNL + Omni-Path
0
5
10
15
20
25
64
12
8
25
6
51
2
1K
2K
4K
8K
16
K
32
K
64
K
Tim
e (s
eco
nd
s)
Number of Processes
Oakforest-PACS
MPI_Init Hello World
22s
5.8s
21s
57s
• MPI_Init takes 22 seconds on 231,936 processes on 3,624 KNL nodes (Stampede2 – Full scale)• At 64K processes, MPI_Init and Hello World takes 5.8s and 21s respectively (Oakforest-PACS)• All numbers reported with 64 processes per node, MVAPICH2-2.3a• Designs integrated with mpirun_rsh, available for srun (SLURM launcher) as well

SCEC (Dec ‘18) 19Network Based Computing Laboratory
0
0.1
0.2
0.3
0.4
(4,28) (8,28) (16,28)La
ten
cy (
seco
nd
s)
(Number of Nodes, PPN)
MVAPICH2
Benefits of SHARP Allreduce at Application Level
12%
Avg DDOT Allreduce time of HPCG
SHARP support available since MVAPICH2 2.3a
Parameter Description Default
MV2_ENABLE_SHARP=1 Enables SHARP-based collectives Disabled
--enable-sharp Configure flag to enable SHARP Disabled
• Refer to Running Collectives with Hardware based SHARP support section of MVAPICH2 user guide for more information
• http://mvapich.cse.ohio-state.edu/static/media/mvapich/mvapich2-2.3-userguide.html#x1-990006.26
SCEC (Dec ‘18) 20Network Based Computing Laboratory
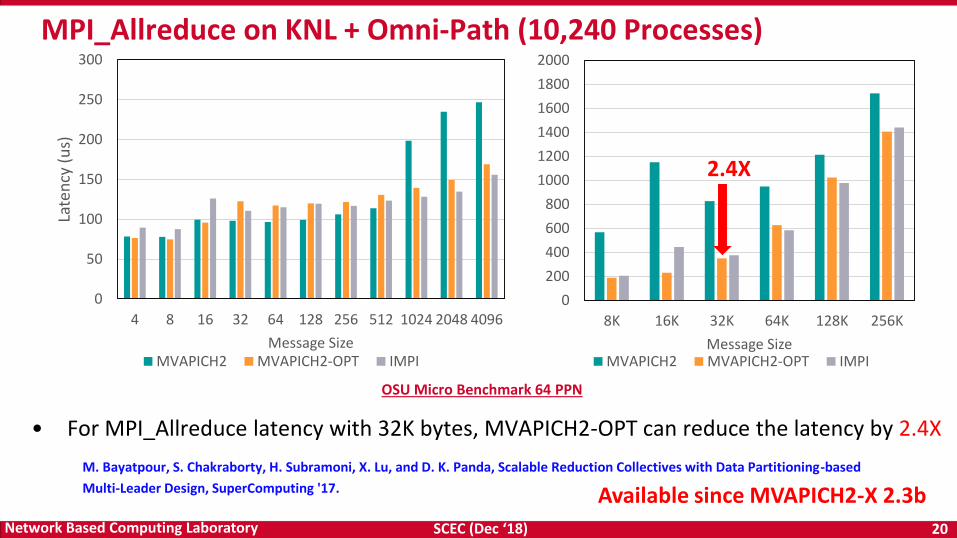
MPI_Allreduce on KNL + Omni-Path (10,240 Processes)
0
50
100
150
200
250
300
4 8 16 32 64 128 256 512 1024 2048 4096
Late
ncy
(u
s)
Message SizeMVAPICH2 MVAPICH2-OPT IMPI
0
200
400
600
800
1000
1200
1400
1600
1800
2000
8K 16K 32K 64K 128K 256K
Message SizeMVAPICH2 MVAPICH2-OPT IMPI
OSU Micro Benchmark 64 PPN
2.4X
• For MPI_Allreduce latency with 32K bytes, MVAPICH2-OPT can reduce the latency by 2.4X
M. Bayatpour, S. Chakraborty, H. Subramoni, X. Lu, and D. K. Panda, Scalable Reduction Collectives with Data Partitioning-based
Multi-Leader Design, SuperComputing '17. Available since MVAPICH2-X 2.3b

SCEC (Dec ‘18) 21Network Based Computing Laboratory
Optimized CMA-based Collectives for Large Messages
1
10
100
1000
10000
100000
10000001K 2K 4K 8K
16K
32K
64K
128K
256K
512K 1M 2M 4M
Message Size
KNL (2 Nodes, 128 Procs)
MVAPICH2-2.3a
Intel MPI 2017
OpenMPI 2.1.0
Tuned CMA
Late
ncy
(u
s)
1
10
100
1000
10000
100000
1000000
1K 2K 4K 8K
16K
32K
64K
128K
256K
512K 1M 2M
Message Size
KNL (4 Nodes, 256 Procs)
MVAPICH2-2.3a
Intel MPI 2017
OpenMPI 2.1.0
Tuned CMA1
10
100
1000
10000
100000
1000000
1K 2K 4K 8K
16K
32K
64K
128K
256
K
512K 1M
Message Size
KNL (8 Nodes, 512 Procs)
MVAPICH2-2.3a
Intel MPI 2017
OpenMPI 2.1.0
Tuned CMA
• Significant improvement over existing implementation for Scatter/Gather with 1MB messages (up to 4x on KNL, 2x on Broadwell, 14x on OpenPower)
• New two-level algorithms for better scalability• Improved performance for other collectives (Bcast, Allgather, and Alltoall)
~ 2.5xBetter
~ 3.2xBetter
~ 4xBetter
~ 17xBetter
S. Chakraborty, H. Subramoni, and D. K. Panda, Contention Aware Kernel-Assisted MPI
Collectives for Multi/Many-core Systems, IEEE Cluster ’17, BEST Paper Finalist
Performance of MPI_Gather on KNL nodes (64PPN)
Available since MVAPICH2-X 2.3b
SCEC (Dec ‘18) 22Network Based Computing Laboratory
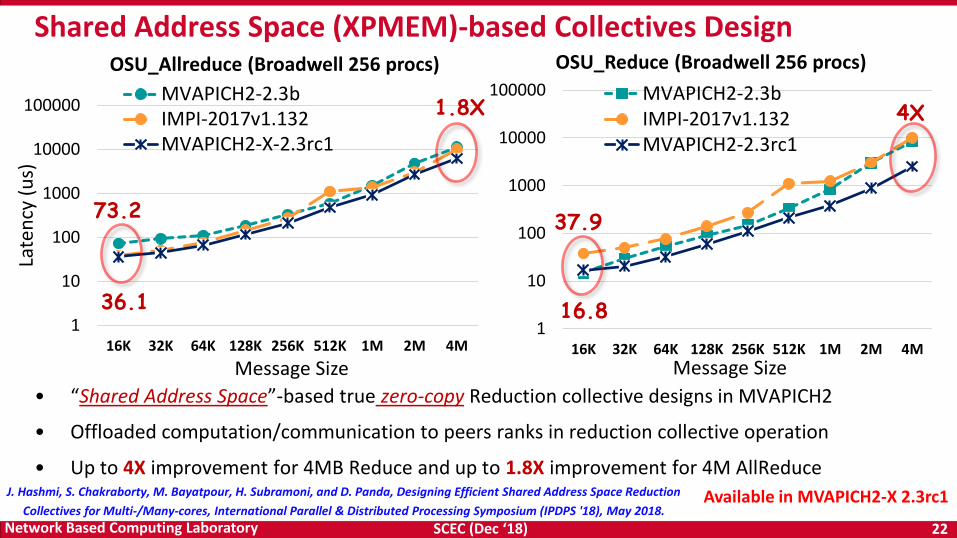
Shared Address Space (XPMEM)-based Collectives Design
1
10
100
1000
10000
100000
16K 32K 64K 128K 256K 512K 1M 2M 4M
Late
ncy
(u
s)
Message Size
MVAPICH2-2.3bIMPI-2017v1.132MVAPICH2-X-2.3rc1
OSU_Allreduce (Broadwell 256 procs)
• “Shared Address Space”-based true zero-copy Reduction collective designs in MVAPICH2
• Offloaded computation/communication to peers ranks in reduction collective operation
• Up to 4X improvement for 4MB Reduce and up to 1.8X improvement for 4M AllReduce
73.2
1.8X
1
10
100
1000
10000
100000
16K 32K 64K 128K 256K 512K 1M 2M 4M
Message Size
MVAPICH2-2.3bIMPI-2017v1.132MVAPICH2-2.3rc1
OSU_Reduce (Broadwell 256 procs)
4X
36.1
37.9
16.8
J. Hashmi, S. Chakraborty, M. Bayatpour, H. Subramoni, and D. Panda, Designing Efficient Shared Address Space Reduction
Collectives for Multi-/Many-cores, International Parallel & Distributed Processing Symposium (IPDPS '18), May 2018.Available in MVAPICH2-X 2.3rc1

SCEC (Dec ‘18) 23Network Based Computing Laboratory
Application-Level Benefits of XPMEM-Based Collectives
MiniAMR (Broadwell, ppn=16)
• Up to 20% benefits over IMPI for CNTK DNN training using AllReduce
• Up to 27% benefits over IMPI and up to 15% improvement over MVAPICH2 for MiniAMR application kernel
0
200
400
600
800
28 56 112 224
Exec
uti
on
Tim
e (s
)
No. of Processes
Intel MPIMVAPICH2MVAPICH2-XPMEM
CNTK AlexNet Training (Broadwell, B.S=default, iteration=50, ppn=28)
0
20
40
60
80
16 32 64 128 256
Exec
uti
on
Tim
e (s
)
No. of Processes
Intel MPI
MVAPICH2
MVAPICH2-XPMEM20%
9%
27%
15%
SCEC (Dec ‘18) 24Network Based Computing Laboratory
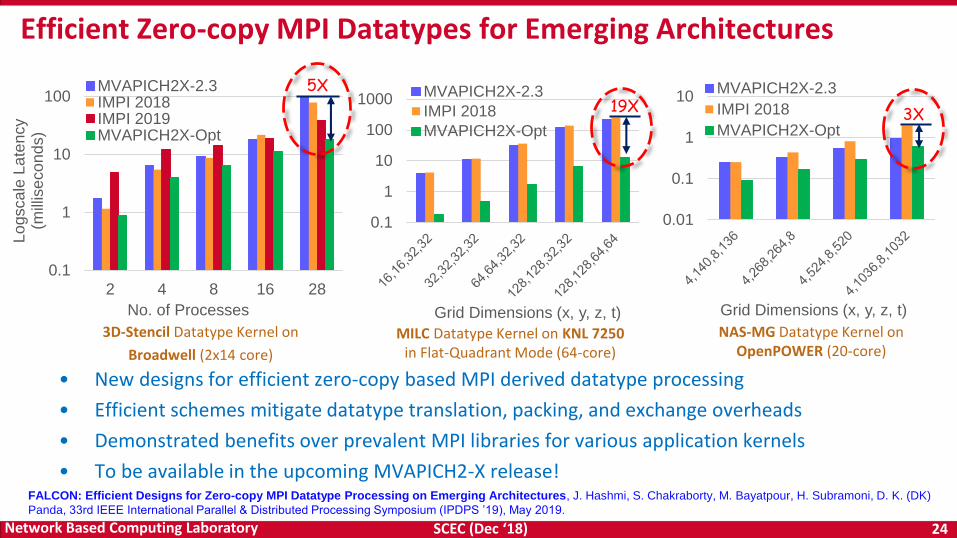
Efficient Zero-copy MPI Datatypes for Emerging Architectures
• New designs for efficient zero-copy based MPI derived datatype processing
• Efficient schemes mitigate datatype translation, packing, and exchange overheads
• Demonstrated benefits over prevalent MPI libraries for various application kernels
• To be available in the upcoming MVAPICH2-X release!
0.1
1
10
100
2 4 8 16 28
Lo
gsca
le L
ate
ncy
(mill
ise
co
nd
s)
No. of Processes
MVAPICH2X-2.3IMPI 2018IMPI 2019MVAPICH2X-Opt
5X
0.1
1
10
100
1000
Grid Dimensions (x, y, z, t)
MVAPICH2X-2.3
IMPI 2018
MVAPICH2X-Opt
19X
0.01
0.1
1
10
Grid Dimensions (x, y, z, t)
MVAPICH2X-2.3
IMPI 2018
MVAPICH2X-Opt3X
3D-Stencil Datatype Kernel on
Broadwell (2x14 core)
MILC Datatype Kernel on KNL 7250 in Flat-Quadrant Mode (64-core)
NAS-MG Datatype Kernel on OpenPOWER (20-core)
FALCON: Efficient Designs for Zero-copy MPI Datatype Processing on Emerging Architectures, J. Hashmi, S. Chakraborty, M. Bayatpour, H. Subramoni, D. K. (DK)
Panda, 33rd IEEE International Parallel & Distributed Processing Symposium (IPDPS ’19), May 2019.

SCEC (Dec ‘18) 25Network Based Computing Laboratory
Benefits of the New Asynchronous Progress Design: Broadwell + InfiniBand
Up to 44% performance improvement in P3DFFT application with 448 processesUp to 19% and 9% performance improvement in HPL application with 448 and 896 processes
0
50
100
150
56 112 224 448
Tim
e p
er lo
op
in s
eco
nd
s
Number of processes
MVAPICH2-X Async MVAPICH2-X Default
Intel MPI 18.1.163
( 28 PPN )
106
119
109
100 100 100
80
100
120
140
224 448 896
No
rmal
ized
Per
form
ance
in
GFL
OP
S
Number of ProcessesMVAPICH2-X Async MVAPICH2-X Default
Memory Consumption = 69%
PPN=28
P3DFFT High Performance Linpack (HPL)
44%
33%
Lower is better Higher is better
A. Ruhela, H. Subramoni, S. Chakraborty, M. Bayatpour, P. Kousha, and D.K. Panda, Efficient Asynchronous Communication Progress for MPI without Dedicated Resources, EuroMPI 2018 Available in MVAPICH2-X 2.3rc1

SCEC (Dec ‘18) 26Network Based Computing Laboratory
• Scalability for million to billion processors
• Exploiting Accelerators (NVIDIA GPGPUs)
• Optimized MVAPICH2 for OpenPower (with/ NVLink) and ARM
• Application Scalability and Best Practices
Overview of A Few Challenges being Addressed by the MVAPICH2 Project for Exascale

SCEC (Dec ‘18) 27Network Based Computing Laboratory
At Sender:
At Receiver:
MPI_Recv(r_devbuf, size, …);
inside
MVAPICH2
• Standard MPI interfaces used for unified data movement
• Takes advantage of Unified Virtual Addressing (>= CUDA 4.0)
• Overlaps data movement from GPU with RDMA transfers
High Performance and High Productivity
MPI_Send(s_devbuf, size, …);
GPU-Aware (CUDA-Aware) MPI Library: MVAPICH2-GPU

SCEC (Dec ‘18) 28Network Based Computing Laboratory
CUDA-Aware MPI: MVAPICH2-GDR 1.8-2.3 Releases
• Support for MPI communication from NVIDIA GPU device memory
• High performance RDMA-based inter-node point-to-point communication (GPU-GPU, GPU-Host and Host-GPU)
• High performance intra-node point-to-point communication for multi-GPU adapters/node (GPU-GPU, GPU-Host and Host-GPU)
• Taking advantage of CUDA IPC (available since CUDA 4.1) in intra-node communication for multiple GPU adapters/node
• Optimized and tuned collectives for GPU device buffers
• MPI datatype support for point-to-point and collective communication from GPU device buffers
• Unified memory

SCEC (Dec ‘18) 29Network Based Computing Laboratory
0
2000
4000
6000
1 2 4 8
16
32
64
12
8
25
6
51
2
1K
2K
4K
Ban
dw
idth
(M
B/s
)
Message Size (Bytes)
GPU-GPU Inter-node Bi-Bandwidth
MV2-(NO-GDR) MV2-GDR-2.3
0
1000
2000
3000
4000
1 2 4 8
16
32
64
12
8
25
6
51
2
1K
2K
4K
Ban
dw
idth
(M
B/s
)
Message Size (Bytes)
GPU-GPU Inter-node Bandwidth
MV2-(NO-GDR) MV2-GDR-2.3
0
10
20
300 1 2 4 8
16
32
64
12
8
25
6
51
2
1K
2K
4K
8K
Late
ncy
(u
s)
Message Size (Bytes)
GPU-GPU Inter-node Latency
MV2-(NO-GDR) MV2-GDR 2.3
MVAPICH2-GDR-2.3Intel Haswell (E5-2687W @ 3.10 GHz) node - 20 cores
NVIDIA Volta V100 GPUMellanox Connect-X4 EDR HCA
CUDA 9.0Mellanox OFED 4.0 with GPU-Direct-RDMA
10x
9x
Optimized MVAPICH2-GDR Design
1.85us11X

SCEC (Dec ‘18) 30Network Based Computing Laboratory
• Platform: Wilkes (Intel Ivy Bridge + NVIDIA Tesla K20c + Mellanox Connect-IB)
• HoomdBlue Version 1.0.5
• GDRCOPY enabled: MV2_USE_CUDA=1 MV2_IBA_HCA=mlx5_0 MV2_IBA_EAGER_THRESHOLD=32768
MV2_VBUF_TOTAL_SIZE=32768 MV2_USE_GPUDIRECT_LOOPBACK_LIMIT=32768
MV2_USE_GPUDIRECT_GDRCOPY=1 MV2_USE_GPUDIRECT_GDRCOPY_LIMIT=16384
Application-Level Evaluation (HOOMD-blue)
0
500
1000
1500
2000
2500
4 8 16 32
Ave
rage
Tim
e St
eps
per
se
con
d (
TPS)
Number of Processes
MV2 MV2+GDR
0
500
1000
1500
2000
2500
3000
3500
4 8 16 32Ave
rage
Tim
e St
eps
pe
r se
con
d (
TPS)
Number of Processes
64K Particles 256K Particles
2X2X

SCEC (Dec ‘18) 31Network Based Computing Laboratory
Application-Level Evaluation (Cosmo) and Weather Forecasting in Switzerland
0
0.2
0.4
0.6
0.8
1
1.2
16 32 64 96No
rmal
ized
Exe
cuti
on
Tim
e
Number of GPUs
CSCS GPU cluster
Default Callback-based Event-based
0
0.2
0.4
0.6
0.8
1
1.2
4 8 16 32
No
rmal
ized
Exe
cuti
on
Tim
e
Number of GPUs
Wilkes GPU Cluster
Default Callback-based Event-based
• 2X improvement on 32 GPUs nodes• 30% improvement on 96 GPU nodes (8 GPUs/node)
C. Chu, K. Hamidouche, A. Venkatesh, D. Banerjee , H. Subramoni, and D. K. Panda, Exploiting Maximal Overlap for Non-Contiguous Data
Movement Processing on Modern GPU-enabled Systems, IPDPS’16
On-going collaboration with CSCS and MeteoSwiss (Switzerland) in co-designing MV2-GDR and Cosmo Application
Cosmo model: http://www2.cosmo-model.org/content
/tasks/operational/meteoSwiss/

SCEC (Dec ‘18) 32Network Based Computing Laboratory
• Scalability for million to billion processors
• Exploiting Accelerators (NVIDIA GPGPUs)
• Optimized MVAPICH2 for OpenPower (with/ NVLink) and ARM
• Application Scalability and Best Practices
Overview of A Few Challenges being Addressed by the MVAPICH2 Project for Exascale

SCEC (Dec ‘18) 33Network Based Computing Laboratory
0
0.5
1
1.5
0 1 2 4 8 16 32 64 128 256 512 1K 2K
Late
ncy
(u
s)
MVAPICH2-2.3
SpectrumMPI-10.1.0.2
OpenMPI-3.0.0
Intra-node Point-to-Point Performance on OpenPower
Platform: Two nodes of OpenPOWER (Power8-ppc64le) CPU using Mellanox EDR (MT4115) HCA
Intra-Socket Small Message Latency Intra-Socket Large Message Latency
Intra-Socket Bi-directional BandwidthIntra-Socket Bandwidth
0.30us0
20
40
60
80
4K 8K 16K 32K 64K 128K 256K 512K 1M 2M
Late
ncy
(u
s)
MVAPICH2-2.3
SpectrumMPI-10.1.0.2
OpenMPI-3.0.0
0
10000
20000
30000
40000
1 8 64 512 4K 32K 256K 2M
Ban
dw
idth
(M
B/s
)
MVAPICH2-2.3
SpectrumMPI-10.1.0.2
OpenMPI-3.0.0
0
20000
40000
60000
80000
1 8 64 512 4K 32K 256K 2M
Ban
dw
idth
(M
B/s
)
MVAPICH2-2.3
SpectrumMPI-10.1.0.2
OpenMPI-3.0.0

SCEC (Dec ‘18) 34Network Based Computing Laboratory
0
5
10
15
20
1 2 4 8
16
32
64
12
8
25
6
51
2
1K
2K
4K
8K
Late
ncy
(u
s)
Message Size (Bytes)
INTRA-NODE LATENCY (SMALL)
INTRA-SOCKET(NVLINK) INTER-SOCKET
MVAPICH2-GDR: Performance on OpenPOWER (NVLink + Pascal)
010203040
1 4
16
64
25
6
1K
4K
16
K
64
K
25
6K
1M
4M
Ban
dw
idth
(G
B/s
ec)
Message Size (Bytes)
INTRA-NODE BANDWIDTH
INTRA-SOCKET(NVLINK) INTER-SOCKET
0
2
4
6
8
1 4
16
64
25
6
1K
4K
16
K
64
K
25
6K
1M
4MB
and
wid
th (
GB
/sec
)
Message Size (Bytes)
INTER-NODE BANDWIDTH
Platform: OpenPOWER (ppc64le) nodes equipped with a dual-socket CPU, 4 Pascal P100-SXM GPUs, and 4X-FDR InfiniBand Inter-connect
0
200
400
16K 32K 64K 128K256K512K 1M 2M 4M
Late
ncy
(u
s)
Message Size (Bytes)
INTRA-NODE LATENCY (LARGE)
INTRA-SOCKET(NVLINK) INTER-SOCKET
0
10
20
30
1 2 4 8
16
32
64
12
8
25
6
51
2
1K
2K
4K
8K
Late
ncy
(u
s)
Message Size (Bytes)
INTER-NODE LATENCY (SMALL)
0
200
400
600
800
1000
Late
ncy
(u
s)
Message Size (Bytes)
INTER-NODE LATENCY (LARGE)
Intra-node Bandwidth: 33.2 GB/sec (NVLINK)Intra-node Latency: 13.8 us (without GPUDirectRDMA)
Inter-node Latency: 23 us (without GPUDirectRDMA) Inter-node Bandwidth: 6 GB/sec (FDR)Available since MVAPICH2-GDR 2.3a

SCEC (Dec ‘18) 35Network Based Computing Laboratory
0
1000
2000
16K 32K 64K 128K 256K 512K 1M 2M
Late
ncy
(u
s)
MVAPICH2-GDR-Next
SpectrumMPI-10.1.0
OpenMPI-3.0.0
3X0
2000
4000
16K 32K 64K 128K 256K 512K 1M 2M
Late
ncy
(u
s)
Message Size
MVAPICH2-GDR-Next
SpectrumMPI-10.1.0
OpenMPI-3.0.0
34%
0
1000
2000
3000
4000
16K 32K 64K 128K 256K 512K 1M 2M
Late
ncy
(u
s)
Message Size
MVAPICH2-GDR-Next
SpectrumMPI-10.1.0
OpenMPI-3.0.0
0
1000
2000
16K 32K 64K 128K 256K 512K 1M 2M
Late
ncy
(u
s)MVAPICH2-GDR-Next
SpectrumMPI-10.1.0
OpenMPI-3.0.0
Optimized All-Reduce with XPMEM on OpenPOWER(N
od
es=1
, PP
N=2
0)
Optimized Runtime Parameters: MV2_CPU_BINDING_POLICY=hybrid MV2_HYBRID_BINDING_POLICY=bunch
• Optimized MPI All-Reduce Design in MVAPICH2– Up to 2X performance improvement over Spectrum MPI and 4X over OpenMPI for intra-node
2X
(No
des
=2, P
PN
=20
)
4X48%
3.3X
2X
2X

SCEC (Dec ‘18) 36Network Based Computing Laboratory
0
0.5
1
1.5
0 1 2 4 8 16 32 64 128256512 1K 2K 4K
Late
ncy
(u
s)
MVAPICH2-2.3
Intra-node Point-to-point Performance on ARM Cortex-A72
0
2000
4000
6000
8000
10000
Ban
dw
idth
(M
B/s
)
MVAPICH2-2.3
0
5000
10000
15000
20000
Bid
irec
tio
nal
Ban
dw
idth MVAPICH2-2.3
Platform: ARM Cortex A72 (aarch64) processor with 64 cores dual-socket CPU. Each socket contains 32 cores.
Small Message Latency Large Message Latency
Bi-directional BandwidthBandwidth
0.27 micro-second
(1 bytes)
0
200
400
600
800
8K 16K 32K 64K 128K 256K 512K 1M 2M 4M
Late
ncy
(u
s)
MVAPICH2-2.3

SCEC (Dec ‘18) 37Network Based Computing Laboratory
• Scalability for million to billion processors
• Exploiting Accelerators (NVIDIA GPGPUs)
• Optimized MVAPICH2 for OpenPower (with/ NVLink) and ARM
• Application Scalability and Best Practices
Overview of A Few Challenges being Addressed by the MVAPICH2 Project for Exascale

SCEC (Dec ‘18) 38Network Based Computing Laboratory
0
20
40
60
80
100
120
140
160
MILC Leslie3D POP2 LAMMPS WRF2 LU
Exe
cuti
on
Tim
e in
(s)
Intel MPI 18.1.163
MVAPICH2-X-2.3rc1
31%
SPEC MPI 2007 Benchmarks: Broadwell + InfiniBand
MVAPICH2-X outperforms Intel MPI by up to 31%
Configuration: 448 processes on 16 Intel E5-2680v4 (Broadwell) nodes having 28 PPN and interconnected
with 100Gbps Mellanox MT4115 EDR ConnectX-4 HCA
29% 5%
-12%1%
11%

SCEC (Dec ‘18) 39Network Based Computing Laboratory
Application Scalability on Skylake and KNL (Stamepede2)
MiniFE (1300x1300x1300 ~ 910 GB)
Runtime parameters: MV2_SMPI_LENGTH_QUEUE=524288 PSM2_MQ_RNDV_SHM_THRESH=128K PSM2_MQ_RNDV_HFI_THRESH=128K
0
50
100
150
2048 4096 8192
Exec
uti
on
Tim
e (s
)
No. of Processes (KNL: 64ppn)
MVAPICH2
0
20
40
60
2048 4096 8192
Exec
uti
on
Tim
e (s
)
No. of Processes (Skylake: 48ppn)
MVAPICH2
0
500
1000
1500
48 96 192 384 768No. of Processes (Skylake: 48ppn)
MVAPICH2
NEURON (YuEtAl2012)
Courtesy: Mahidhar Tatineni @SDSC, Dong Ju (DJ) Choi@SDSC, and Samuel Khuvis@OSC ---- Testbed: TACC Stampede2 using MVAPICH2-2.3b
0
1000
2000
3000
4000
64 128 256 512 1024 2048 4096
No. of Processes (KNL: 64ppn)
MVAPICH2
0
500
1000
1500
68 136 272 544 1088 2176 4352
No. of Processes (KNL: 68ppn)
MVAPICH2
0
500
1000
1500
2000
48 96 192 384 768 1536 3072No. of Processes (Skylake: 48ppn)
MVAPICH2
Cloverleaf (bm64) MPI+OpenMP, NUM_OMP_THREADS = 2

SCEC (Dec ‘18) 40Network Based Computing Laboratory
• MPI runtime has many parameters
• Tuning a set of parameters can help you to extract higher performance
• Compiled a list of such contributions through the MVAPICH Website– http://mvapich.cse.ohio-state.edu/best_practices/
• Initial list of applications– Amber
– HoomDBlue
– HPCG
– Lulesh
– MILC
– Neuron
– SMG2000
– Cloverleaf
– SPEC (LAMMPS, POP2, TERA_TF, WRF2)
• Soliciting additional contributions, send your results to mvapich-help at cse.ohio-state.edu.
• We will link these results with credits to you.
Applications-Level Tuning: Compilation of Best Practices

SCEC (Dec ‘18) 41Network Based Computing Laboratory
• Traditional HPC
– Message Passing Interface (MPI), including MPI + OpenMP
– Exploiting Accelerators
• Deep Learning
– Caffe, CNTK, TensorFlow, and many more
• Big Data/Enterprise/Commercial Computing
– Spark and Hadoop (HDFS, HBase, MapReduce)
– Deep Learning over Big Data (DLoBD)
• Cloud for HPC and BigData
– Virtualization with SR-IOV and Containers
HPC, Big Data, Deep Learning, and Cloud

SCEC (Dec ‘18) 42Network Based Computing Laboratory
• Deep Learning frameworks are a different game
altogether
– Unusually large message sizes (order of megabytes)
– Most communication based on GPU buffers
• Existing State-of-the-art
– cuDNN, cuBLAS, NCCL --> scale-up performance
– NCCL2, CUDA-Aware MPI --> scale-out performance
• For small and medium message sizes only!
• Proposed: Can we co-design the MPI runtime (MVAPICH2-
GDR) and the DL framework (Caffe) to achieve both?
– Efficient Overlap of Computation and Communication
– Efficient Large-Message Communication (Reductions)
– What application co-designs are needed to exploit
communication-runtime co-designs?
Deep Learning: New Challenges for MPI Runtimes
Scal
e-u
p P
erf
orm
ance
Scale-out PerformanceA. A. Awan, K. Hamidouche, J. M. Hashmi, and D. K. Panda, S-Caffe: Co-designing MPI Runtimes and Caffe for Scalable Deep Learning on Modern GPU Clusters. In Proceedings of the 22nd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP '17)
cuDNN
gRPC
Hadoop
MPIMKL-DNN
DesiredNCCL1NCCL2

SCEC (Dec ‘18) 43Network Based Computing Laboratory
• MVAPICH2-GDR offers
excellent performance via
advanced designs for
MPI_Allreduce.
• Up to 11% better
performance on the RI2
cluster (16 GPUs)
• Near-ideal – 98% scaling
efficiency
Exploiting CUDA-Aware MPI for TensorFlow (Horovod)
0
100
200
300
400
500
600
700
800
900
1000
1 2 4 8 16
Imag
es/s
eco
nd
(H
igh
er is
bet
ter)
No. of GPUs
Horovod-MPI Horovod-NCCL2 Horovod-MPI-Opt (Proposed) Ideal
MVAPICH2-GDR 2.3 (MPI-Opt) is up to 11% faster than MVAPICH2
2.3 (Basic CUDA support)
A. A. Awan et al., “Scalable Distributed DNN Training using TensorFlow and CUDA-Aware MPI: Characterization, Designs, and Performance Evaluation”, Under Review, https://arxiv.org/abs/1810.11112

SCEC (Dec ‘18) 44Network Based Computing Laboratory
0
10000
20000
30000
40000
50000
512K 1M 2M 4M
Late
ncy
(u
s)
Message Size (Bytes)
MVAPICH2 BAIDU OPENMPI
0
1000000
2000000
3000000
4000000
5000000
6000000
83
88
608
16
77
721
6
33
55
443
2
67
10
886
4
13
42
177
28
26
84
354
56
53
68
709
12
Late
ncy
(u
s)
Message Size (Bytes)
MVAPICH2 BAIDU OPENMPI
1
10
100
1000
10000
100000
4
16
64
25
6
10
24
40
96
16
38
4
65
53
6
26
21
44
Late
ncy
(u
s)
Message Size (Bytes)
MVAPICH2 BAIDU OPENMPI
• 16 GPUs (4 nodes) MVAPICH2-GDR vs. Baidu-Allreduce and OpenMPI 3.0
MVAPICH2-GDR: Allreduce Comparison with Baidu and OpenMPI
*Available since MVAPICH2-GDR 2.3a
~30X betterMV2 is ~2X better
than Baidu
~10X better OpenMPI is ~5X slower
than Baidu
~4X better

SCEC (Dec ‘18) 45Network Based Computing Laboratory
MVAPICH2-GDR vs. NCCL2 – Allreduce Operation
• Optimized designs in MVAPICH2-GDR 2.3 offer better/comparable performance for most cases
• MPI_Allreduce (MVAPICH2-GDR) vs. ncclAllreduce (NCCL2) on 16 GPUs
1
10
100
1000
10000
100000
Late
ncy
(u
s)
Message Size (Bytes)
MVAPICH2-GDR NCCL2
~1.2X better
Platform: Intel Xeon (Broadwell) nodes equipped with a dual-socket CPU, 1 K-80 GPUs, and EDR InfiniBand Inter-connect
1
10
100
1000
4 8
16
32
64
12
8
25
6
51
2
1K
2K
4K
8K
16
K
32
K
64
K
Late
ncy
(u
s)
Message Size (Bytes)
MVAPICH2-GDR NCCL2
~3X better
SCEC (Dec ‘18) 46Network Based Computing Laboratory
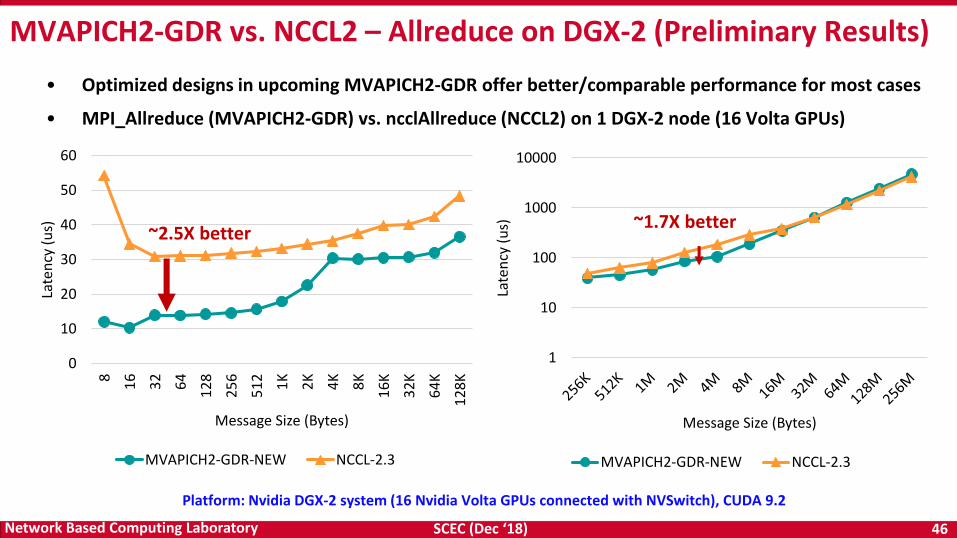
MVAPICH2-GDR vs. NCCL2 – Allreduce on DGX-2 (Preliminary Results)
• Optimized designs in upcoming MVAPICH2-GDR offer better/comparable performance for most cases
• MPI_Allreduce (MVAPICH2-GDR) vs. ncclAllreduce (NCCL2) on 1 DGX-2 node (16 Volta GPUs)
1
10
100
1000
10000
Late
ncy
(u
s)
Message Size (Bytes)
MVAPICH2-GDR-NEW NCCL-2.3
~1.7X better
Platform: Nvidia DGX-2 system (16 Nvidia Volta GPUs connected with NVSwitch), CUDA 9.2
0
10
20
30
40
50
60
8
16
32
64
12
8
25
6
51
2
1K
2K
4K
8K
16
K
32
K
64
K
12
8K
Late
ncy
(u
s)
Message Size (Bytes)
MVAPICH2-GDR-NEW NCCL-2.3
~2.5X better
SCEC (Dec ‘18) 47Network Based Computing Laboratory
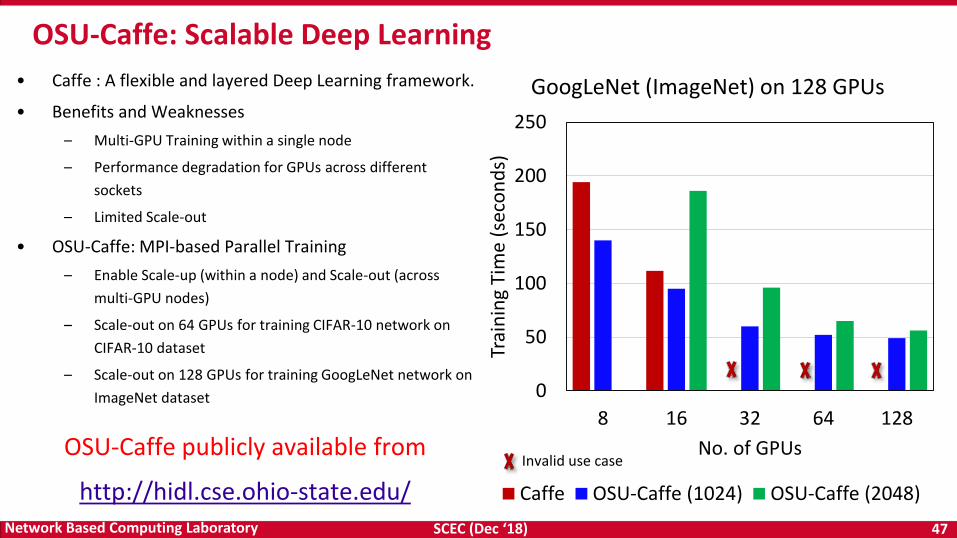
• Caffe : A flexible and layered Deep Learning framework.
• Benefits and Weaknesses
– Multi-GPU Training within a single node
– Performance degradation for GPUs across different
sockets
– Limited Scale-out
• OSU-Caffe: MPI-based Parallel Training
– Enable Scale-up (within a node) and Scale-out (across
multi-GPU nodes)
– Scale-out on 64 GPUs for training CIFAR-10 network on
CIFAR-10 dataset
– Scale-out on 128 GPUs for training GoogLeNet network on
ImageNet dataset
OSU-Caffe: Scalable Deep Learning
0
50
100
150
200
250
8 16 32 64 128
Trai
nin
g Ti
me
(sec
on
ds)
No. of GPUs
GoogLeNet (ImageNet) on 128 GPUs
Caffe OSU-Caffe (1024) OSU-Caffe (2048)
Invalid use caseOSU-Caffe publicly available from
http://hidl.cse.ohio-state.edu/

SCEC (Dec ‘18) 48Network Based Computing Laboratory
• High-Performance Design of TensorFlow over RDMA-enabled Interconnects
– High performance RDMA-enhanced design with native InfiniBand support at the verbs-level for gRPC and TensorFlow
– RDMA-based data communication
– Adaptive communication protocols
– Dynamic message chunking and accumulation
– Support for RDMA device selection
– Easily configurable for different protocols (native InfiniBand and IPoIB)
• Current release: 0.9.1
– Based on Google TensorFlow 1.3.0
– Tested with
• Mellanox InfiniBand adapters (e.g., EDR)
• NVIDIA GPGPU K80
• Tested with CUDA 8.0 and CUDNN 5.0
– http://hidl.cse.ohio-state.edu
RDMA-TensorFlow Distribution

SCEC (Dec ‘18) 49Network Based Computing Laboratory
0
50
100
150
200
16 32 64
Imag
es /
Sec
on
d
Batch Size
gRPPC (IPoIB-100Gbps)
Verbs (RDMA-100Gbps)
MPI (RDMA-100Gbps)
AR-gRPC (RDMA-100Gbps)
Performance Benefit for RDMA-TensorFlow (Inception3)
• TensorFlow Inception3 performance evaluation on an IB EDR cluster
– Up to 20% performance speedup over Default gRPC (IPoIB) for 8 GPUs
– Up to 34% performance speedup over Default gRPC (IPoIB) for 16 GPUs
– Up to 37% performance speedup over Default gRPC (IPoIB) for 24 GPUs
4 Nodes (8 GPUS) 8 Nodes (16 GPUS) 12 Nodes (24 GPUS)
0
200
400
600
16 32 64
Imag
es /
Sec
on
d
Batch Size
gRPPC (IPoIB-100Gbps)Verbs (RDMA-100Gbps)MPI (RDMA-100Gbps)AR-gRPC (RDMA-100Gbps)
0
100
200
300
400
16 32 64Im
ages
/ S
eco
nd
Batch Size
gRPPC (IPoIB-100Gbps)
Verbs (RDMA-100Gbps)
MPI (RDMA-100Gbps)
AR-gRPC (RDMA-100Gbps)

SCEC (Dec ‘18) 50Network Based Computing Laboratory
• Traditional HPC
– Message Passing Interface (MPI), including MPI + OpenMP
– Exploiting Accelerators
• Deep Learning
– Caffe, CNTK, TensorFlow, and many more
• Big Data/Enterprise/Commercial Computing
– Spark and Hadoop (HDFS, HBase, MapReduce)
– Deep Learning over Big Data (DLoBD)
• Cloud for HPC and BigData
– Virtualization with SR-IOV and Containers
HPC, Big Data, Deep Learning, and Cloud

SCEC (Dec ‘18) 51Network Based Computing Laboratory
Designing Communication and I/O Libraries for Big Data Systems: Challenges
Big Data Middleware(HDFS, MapReduce, HBase, Spark and Memcached)
Networking Technologies
(InfiniBand, 1/10/40/100 GigE and Intelligent NICs)
Storage Technologies(HDD, SSD, NVM, and NVMe-
SSD)
Programming Models(Sockets)
Applications
Commodity Computing System Architectures
(Multi- and Many-core architectures and accelerators)
RDMA?
Communication and I/O Library
Point-to-PointCommunication
QoS & Fault Tolerance
Threaded Modelsand Synchronization
Performance TuningI/O and File Systems
Virtualization (SR-IOV)
Benchmarks
Upper level
Changes?

SCEC (Dec ‘18) 52Network Based Computing Laboratory
• RDMA for Apache Spark
• RDMA for Apache Hadoop 2.x (RDMA-Hadoop-2.x)
– Plugins for Apache, Hortonworks (HDP) and Cloudera (CDH) Hadoop distributions
• RDMA for Apache HBase
• RDMA for Memcached (RDMA-Memcached)
• RDMA for Apache Hadoop 1.x (RDMA-Hadoop)
• OSU HiBD-Benchmarks (OHB)
– HDFS, Memcached, HBase, and Spark Micro-benchmarks
• http://hibd.cse.ohio-state.edu
• Users Base: 290 organizations from 34 countries
• More than 28,500 downloads from the project site
The High-Performance Big Data (HiBD) Project
Available for InfiniBand and RoCE
Also run on Ethernet
Available for x86 and OpenPOWER
Support for Singularity and Docker

SCEC (Dec ‘18) 53Network Based Computing Laboratory
0
50
100
150
200
250
300
350
400
80 120 160
Exec
uti
on
Tim
e (s
)
Data Size (GB)
IPoIB (EDR)OSU-IB (EDR)
0
100
200
300
400
500
600
700
800
80 160 240
Exec
uti
on
Tim
e (s
)
Data Size (GB)
IPoIB (EDR)OSU-IB (EDR)
Performance Numbers of RDMA for Apache Hadoop 2.x –RandomWriter & TeraGen in OSU-RI2 (EDR)
Cluster with 8 Nodes with a total of 64 maps
• RandomWriter
– 3x improvement over IPoIB
for 80-160 GB file size
• TeraGen
– 4x improvement over IPoIB for
80-240 GB file size
RandomWriter TeraGen
Reduced by 3x Reduced by 4x

SCEC (Dec ‘18) 54Network Based Computing Laboratory
• InfiniBand FDR, SSD, 32/64 Worker Nodes, 768/1536 Cores, (768/1536M 768/1536R)
• RDMA vs. IPoIB with 768/1536 concurrent tasks, single SSD per node.
– 32 nodes/768 cores: Total time reduced by 37% over IPoIB (56Gbps)
– 64 nodes/1536 cores: Total time reduced by 43% over IPoIB (56Gbps)
Performance Evaluation of RDMA-Spark on SDSC Comet – HiBench PageRank
32 Worker Nodes, 768 cores, PageRank Total Time 64 Worker Nodes, 1536 cores, PageRank Total Time
0
50
100
150
200
250
300
350
400
450
Huge BigData Gigantic
Tim
e (s
ec)
Data Size (GB)
IPoIB
RDMA
0
100
200
300
400
500
600
700
800
Huge BigData Gigantic
Tim
e (s
ec)
Data Size (GB)
IPoIB
RDMA
43%37%

SCEC (Dec ‘18) 55Network Based Computing Laboratory
Using HiBD Packages on Existing HPC Infrastructure

SCEC (Dec ‘18) 56Network Based Computing Laboratory
Using HiBD Packages on Existing HPC Infrastructure
SCEC (Dec ‘18) 57Network Based Computing Laboratory
(1) Prepare Datasets @Scale
(2) Deep Learning @Scale
(3) Non-deep learning
analytics @Scale
(4) Apply ML model @Scale
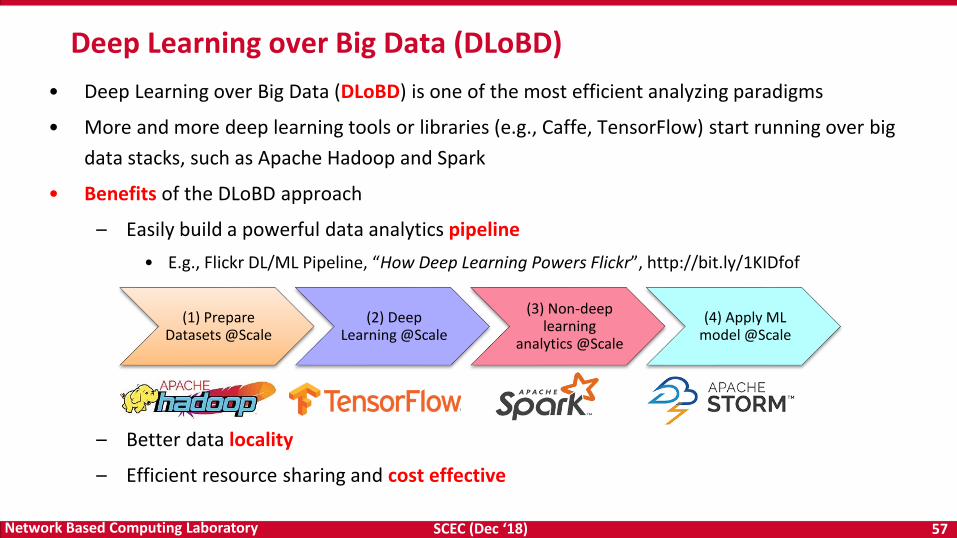
• Deep Learning over Big Data (DLoBD) is one of the most efficient analyzing paradigms
• More and more deep learning tools or libraries (e.g., Caffe, TensorFlow) start running over big
data stacks, such as Apache Hadoop and Spark
• Benefits of the DLoBD approach
– Easily build a powerful data analytics pipeline
• E.g., Flickr DL/ML Pipeline, “How Deep Learning Powers Flickr”, http://bit.ly/1KIDfof
– Better data locality
– Efficient resource sharing and cost effective
Deep Learning over Big Data (DLoBD)

SCEC (Dec ‘18) 58Network Based Computing Laboratory
X. Lu, H. Shi, M. H. Javed, R. Biswas, and D. K. Panda, Characterizing Deep Learning over Big Data (DLoBD) Stacks on RDMA-capable Networks, HotI 2017.
High-Performance Deep Learning over Big Data (DLoBD) Stacks
• Benefits of Deep Learning over Big Data (DLoBD)▪ Easily integrate deep learning components into Big Data
processing workflow▪ Easily access the stored data in Big Data systems▪ No need to set up new dedicated deep learning clusters;
Reuse existing big data analytics clusters
• Challenges▪ Can RDMA-based designs in DLoBD stacks improve
performance, scalability, and resource utilization on high-performance interconnects, GPUs, and multi-core CPUs?
▪ What are the performance characteristics of representative DLoBD stacks on RDMA networks?
• Characterization on DLoBD Stacks▪ CaffeOnSpark, TensorFlowOnSpark, and BigDL▪ IPoIB vs. RDMA; In-band communication vs. Out-of-band
communication; CPU vs. GPU; etc.▪ Performance, accuracy, scalability, and resource utilization ▪ RDMA-based DLoBD stacks (e.g., BigDL over RDMA-Spark)
can achieve 2.6x speedup compared to the IPoIB based scheme, while maintain similar accuracy
0
20
40
60
10
1010
2010
3010
4010
5010
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Acc
ura
cy (
%)
Ep
och
s T
ime
(sec
s)
Epoch Number
IPoIB-TimeRDMA-TimeIPoIB-AccuracyRDMA-Accuracy
2.6X

SCEC (Dec ‘18) 59Network Based Computing Laboratory
• Traditional HPC
– Message Passing Interface (MPI), including MPI + OpenMP
– Exploiting Accelerators
• Deep Learning
– Caffe, CNTK, TensorFlow, and many more
• Big Data/Enterprise/Commercial Computing
– Spark and Hadoop (HDFS, HBase, MapReduce)
– Deep Learning over Big Data (DLoBD)
• Cloud for HPC and BigData
– Virtualization with SR-IOV and Containers
HPC, Big Data, Deep Learning, and Cloud

SCEC (Dec ‘18) 60Network Based Computing Laboratory
• Virtualization has many benefits– Fault-tolerance
– Job migration
– Compaction
• Have not been very popular in HPC due to overhead associated with Virtualization
• New SR-IOV (Single Root – IO Virtualization) support available with Mellanox InfiniBand adapters changes the field
• Enhanced MVAPICH2 support for SR-IOV
• MVAPICH2-Virt 2.2 supports:– OpenStack, Docker, and singularity
Can HPC and Virtualization be Combined?
J. Zhang, X. Lu, J. Jose, R. Shi and D. K. Panda, Can Inter-VM Shmem Benefit MPI Applications on SR-IOV based
Virtualized InfiniBand Clusters? EuroPar'14
J. Zhang, X. Lu, J. Jose, M. Li, R. Shi and D.K. Panda, High Performance MPI Library over SR-IOV enabled InfiniBand
Clusters, HiPC’14 J. Zhang, X .Lu, M. Arnold and D. K. Panda, MVAPICH2 Over OpenStack with SR-IOV: an Efficient Approach to build
HPC Clouds, CCGrid’15

SCEC (Dec ‘18) 61Network Based Computing Laboratory
0
50
100
150
200
250
300
350
400
milc leslie3d pop2 GAPgeofem zeusmp2 lu
Exe
cuti
on
Tim
e (
s)
MV2-SR-IOV-Def
MV2-SR-IOV-Opt
MV2-Native
1%9.5%
0
1000
2000
3000
4000
5000
6000
22,20 24,10 24,16 24,20 26,10 26,16
Exe
cuti
on
Tim
e (
ms)
Problem Size (Scale, Edgefactor)
MV2-SR-IOV-Def
MV2-SR-IOV-Opt
MV2-Native2%
• 32 VMs, 6 Core/VM
• Compared to Native, 2-5% overhead for Graph500 with 128 Procs
• Compared to Native, 1-9.5% overhead for SPEC MPI2007 with 128 Procs
Application-Level Performance on Chameleon
SPEC MPI2007Graph500
5%
A Release for Azure Coming Soon

SCEC (Dec ‘18) 62Network Based Computing Laboratory
0
500
1000
1500
2000
2500
3000
22,16 22,20 24,16 24,20 26,16 26,20
BFS
Exe
cuti
on
Tim
e (
ms)
Problem Size (Scale, Edgefactor)
Graph500
Singularity
Native
0
50
100
150
200
250
300
CG EP FT IS LU MG
Exec
uti
on
Tim
e (
s)
NPB Class D
Singularity
Native
• 512 Processes across 32 nodes
• Less than 7% and 6% overhead for NPB and Graph500, respectively
Application-Level Performance on Singularity with MVAPICH2
7%
6%
J. Zhang, X .Lu and D. K. Panda, Is Singularity-based Container Technology Ready for Running MPI Applications on HPC Clouds?,
UCC ’17, Best Student Paper Award

SCEC (Dec ‘18) 63Network Based Computing Laboratory
0
5000
10000
15000
20000
Ban
dw
idth
(M
B/s
)
Message Size (Bytes)
GPU-GPU Inter-node Bi-Bandwidth
Docker Native
02000400060008000
1000012000
Ban
dw
idth
(M
B/s
)
Message Size (Bytes)
GPU-GPU Inter-node Bandwidth
Docker Native
1
10
100
1000
1 4 16 64 256 1K 4K 16K 64K 256K 1M 4M
Late
ncy
(u
s)
Message Size (Bytes)
GPU-GPU Inter-node Latency
Docker Native
MVAPICH2-GDR-2.3aIntel Haswell (E5-2687W @ 3.10 GHz) node - 20 cores
NVIDIA Volta V100 GPUMellanox Connect-X4 EDR HCA
CUDA 9.0Mellanox OFED 4.0 with GPU-Direct-RDMA
MVAPICH2-GDR on Container with Negligible Overhead
Works with NVIDIA HPC Container Makerhttps://github.com/NVIDIA/hpc-container-maker/blob/master/recipes/hpcbase-pgi-mvapich2.py

SCEC (Dec ‘18) 64Network Based Computing Laboratory
• Supported through X-ScaleSolutions (http://x-scalesolutions.com)
• Benefits:
– Help and guidance with installation of the library
– Platform-specific optimizations and tuning
– Timely support for operational issues encountered with the library
– Web portal interface to submit issues and tracking their progress
– Advanced debugging techniques
– Application-specific optimizations and tuning
– Obtaining guidelines on best practices
– Periodic information on major fixes and updates
– Information on major releases
– Help with upgrading to the latest release
– Flexible Service Level Agreements
• Support provided to Lawrence Livermore National Laboratory (LLNL) this year
Commercial Support for MVAPICH2, HiBD, and HiDL Libraries

SCEC (Dec ‘18) 65Network Based Computing Laboratory
• Looking for Bright and Enthusiastic Personnel to join as
– Post-Doctoral Researchers
– PhD Students
– MPI Programmer/Software Engineer
– Deep Learning/Big Data Programmer/Software Engineer
• If interested, please contact me at this conference and/or send an e-mail
Multiple Positions Available in My Group

SCEC (Dec ‘18) 66Network Based Computing Laboratory
Funding Acknowledgments
Funding Support by
Equipment Support by

SCEC (Dec ‘18) 67Network Based Computing Laboratory
Personnel AcknowledgmentsCurrent Students (Graduate)
– A. Awan (Ph.D.)
– M. Bayatpour (Ph.D.)
– S. Chakraborthy (Ph.D.)
– C.-H. Chu (Ph.D.)
– S. Guganani (Ph.D.)
Past Students
– A. Augustine (M.S.)
– P. Balaji (Ph.D.)
– R. Biswas (M.S.)
– S. Bhagvat (M.S.)
– A. Bhat (M.S.)
– D. Buntinas (Ph.D.)
– L. Chai (Ph.D.)
– B. Chandrasekharan (M.S.)
– N. Dandapanthula (M.S.)
– V. Dhanraj (M.S.)
– T. Gangadharappa (M.S.)
– K. Gopalakrishnan (M.S.)
– R. Rajachandrasekar (Ph.D.)
– G. Santhanaraman (Ph.D.)
– A. Singh (Ph.D.)
– J. Sridhar (M.S.)
– S. Sur (Ph.D.)
– H. Subramoni (Ph.D.)
– K. Vaidyanathan (Ph.D.)
– A. Vishnu (Ph.D.)
– J. Wu (Ph.D.)
– W. Yu (Ph.D.)
– J. Zhang (Ph.D.)
Past Research Scientist
– K. Hamidouche
– S. Sur
Past Post-Docs
– D. Banerjee
– X. Besseron
– H.-W. Jin
– W. Huang (Ph.D.)
– W. Jiang (M.S.)
– J. Jose (Ph.D.)
– S. Kini (M.S.)
– M. Koop (Ph.D.)
– K. Kulkarni (M.S.)
– R. Kumar (M.S.)
– S. Krishnamoorthy (M.S.)
– K. Kandalla (Ph.D.)
– M. Li (Ph.D.)
– P. Lai (M.S.)
– J. Liu (Ph.D.)
– M. Luo (Ph.D.)
– A. Mamidala (Ph.D.)
– G. Marsh (M.S.)
– V. Meshram (M.S.)
– A. Moody (M.S.)
– S. Naravula (Ph.D.)
– R. Noronha (Ph.D.)
– X. Ouyang (Ph.D.)
– S. Pai (M.S.)
– S. Potluri (Ph.D.)
– J. Hashmi (Ph.D.)
– H. Javed (Ph.D.)
– P. Kousha (Ph.D.)
– D. Shankar (Ph.D.)
– H. Shi (Ph.D.)
– J. Lin
– M. Luo
– E. Mancini
Current Research Scientists
– X. Lu
– H. Subramoni
Past Programmers
– D. Bureddy
– J. Perkins
Current Research Specialist
– J. Smith
– S. Marcarelli
– J. Vienne
– H. Wang
Current Post-doc
– A. Ruhela
– K. Manian
Current Students (Undergraduate)
– V. Gangal (B.S.)
– M. Haupt (B.S.)
– N. Sarkauskas (B.S.)
– A. Yeretzian (B.S.)
Past Research Specialist
– M. Arnold

SCEC (Dec ‘18) 68Network Based Computing Laboratory
Thank You!
Network-Based Computing Laboratoryhttp://nowlab.cse.ohio-state.edu/
The High-Performance MPI/PGAS Projecthttp://mvapich.cse.ohio-state.edu/
The High-Performance Deep Learning Projecthttp://hidl.cse.ohio-state.edu/
The High-Performance Big Data Projecthttp://hibd.cse.ohio-state.edu/
Recommended

















