
1 © 2014 SAP AG or an SAP affiliate company. All rights reserved.
SAP HANA SPS 09 – What’s New? Text Analysis
SAP HANA Product Management November, 2014
(Delta from SPS 08 to SPS 09)

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 2 Public
Agenda (1/2)
New or Improved Text Analysis Features
Custom extraction rules
Document filters
Voice of Customer
TA_PARENT
Language identification
Word segmentation
New or Improved Language Coverage
Indonesian support
Part-of-Speech & Noun Groups for Hebrew, Thai,
Turkish
Cyrillic Script for Serbian
Core extraction for Traditional Chinese
Voice of Customer for Italian, Portuguese, Russian,
Traditional Chinese
Emoticon & Profanity extraction for Dutch
Public Sector fact extraction for English
Enterprise fact extraction for English

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 3 Public
Agenda (2/2)
New Text Mining Features
Intro
Top-ranked functions
Characteristics
Sample
Queries
Demo

New or Improved Text Analysis
Features

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 5 Public
New Support of Custom Extraction Rules (1/2)
Rule patterns enable you to identify more complex entity types
than text analysis dictionaries can
Dictionaries are ideal for specifying named entities, whereas
Custom Grouper User Language (CGUL) rules enable you to
identify events, relationships, etc.
CGUL rules can leverage linguistic markup, core entities and
custom dictionaries
Several CGUL rules are included in a rule set which is stored
as a file in the SAP HANA repository
#group BuyingEvent: { [SN] <>*?
[TE PERSON] <>+ [/TE] <>*?
<STEM:buy> <>*?
[NP] <>+ [/NP] <>*?
[TE DATE] <>+ [/TE]
<>* [/SN] }

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 6 Public
New Support of Custom Extraction Rules (2/2)
Allow users to create CGUL rule sets and store them in the repository
A single custom rule set may support all supported languages or a single language
Custom rule sets reside in the SAP HANA repository and benefit from its life cycle management
Custom rules sets are interchangeable with Text Data Processing on SAP Data Services
Steps
1. Choose the project to contain the new rule set in the Development perspective of SAP HANA Studio.
2. Enter or select a parent folder and enter the rule set file name in the Wizard. The file extension must
be .hdbtextrule. Your rule set file is created locally and opens as an empty file in the text editor.
3. Enter your text analysis rule set specification into the new file and save it locally.
4. Commit your new rule set. The rule set is now synchronized to the repository as a design time object and the icon shows the
rule set is committed.
5. Activate once you have finished editing your rule set. The rule set is created in the repository as a runtime object and the
icon shows the rule set is activated. This allows you and others to use the rule set. If you haven’t done so previously, you will
need to create a custom text analysis configuration as well.

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 7 Public
Improved Document Filters
Document filters in the NLP engine automatically detect
and extract text content and metadata from almost
any type of binary file format from PPT to XLS to PDF,
etc.
• Additional format support – new and enhanced file types
• Performance and viewing fidelity improvements:
• Major enhancements to speed, memory usage, and viewing
fidelity of MS Excel
• Improved consistency of output across all formats
• Bug fixes

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 8 Public
Challenge: Make Existing Sentiment Analysis Easier to Use (1/6)
Redesign the Voice of Customer (VOC) language module for domain
customization via simple positive/negative dictionaries instead of complex
rule modifications
This will result in:
easier customizability
improved runtime performance
reliably extended extraction coverage
Simplify Voice of
Customer module for
domain customization
by non-experts

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 9 Public
Improved Voice of Customer (2/6)
Sentiment analysis modules for previously available English,
French, German, Spanish and Simplified Chinese have been
redesigned.
New languages adhere to the redesign: Italian, Portuguese,
Russian and Traditional Chinese
Keyword and profanity dictionaries identify and classify
sentiments and are easily customizable, if needed. These
dictionaries use the EXTRACTION_CORE_VOICEOFCUSTOMER
configuration.
Dictionaries are located in the sap.hana.ta.voc package of the
SAP HANA repository.
Language EXTRACTION_CORE_VOICEOFCUSTOMER Chinese (Simplified) IMPROVED Chinese (Traditional) NEW Dutch NEW (Emoticons & Profanity only) English IMPROVED French IMPROVED German IMPROVED Italian NEW Portuguese NEW Russian NEW Spanish IMPROVED

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 10 Public
Previous Voice of Customer Rule Behavior (3/6)
Rule patterns tried to extract all the following pieces within one pass:
Positive or negative keyword
Possible topic
Possible presence of an intensifier that modifies the positive/negative keyword
Possible presence of a negation
I am [happy]. Weak Positive
I am [not happy]. Weak Negative
I am [tremendously happy]. Strong Positive
I am [not tremendously happy]. Weak Negative
I am [happy with my purchase]. Weak Positive
I am [not happy with my purchase]. Weak Negative
I am [tremendously happy with my purchase]. Strong Positive
I am [not tremendously happy with my purchase]. Weak Negative
Rules became very complex: need to account for all combinations of these 4 pieces of information and
output the right sentiment value.
Not easily customizable: list of positive/negative keywords lived in the CGUL rules.
Resulting in very large finite state networks which impacted runtime performance.

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 11 Public
Rule Behavior with Improved Voice of Customer (4/6)
Now there are 2 sets of VOC rules that require a post-processing filtering mechanism (embedded in
the NLP engine):
1) One set of rules identifies positive/negative keywords with topics
2) The other set of rules identifies positive/negative keywords along with their modifiers (negation and
intensifier)
3) The filtering mechanism sorts through the rule results and outputs one final value for each
Keyword/Topic/Modifier combination
Two Rule Sets Output
I am <not [happy> with my purchase]. “happy” + “my purchase” WeakNegative
“happy” + “not”
I am <tremendously [happy> with my purchase]. “happy” + “my purchase” StrongPositive
“happy” + “tremendously”
I am <not tremendously [happy> with my purchase]. “happy” + “my purchase” WeakNegative
“happy” + “tremendously” + “not”

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 12 Public
Benefits of Improved Voice of Customer (5/6)
Rules are easily customizable via a dictionary:
• Positive/negative keywords are now maintained via a customizable dictionary.
• Entries in the dictionary get called by the CGUL rules No need to go through and modify the CGUL code.
• Users can add or remove entries as well as change the positive/negative categorization of entries to better
match their vertical domain.
Better runtime performance:
• Best case example: German module is 71% faster
Extension of extraction coverage to subordinate clauses, such as “I don’t think your product is good”
which did not reliably extract before because of the many possible intervening tokens between the
negation “don’t” and the keyword “good”.
• Before: I don’t think [Topic]your product[/Topic] is [WeakPositive]good[/WeakPositive].
• After: I don’t think [Topic]your product[/Topic] is [WeakNegative]good[/WeakNegative].

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 13 Public
What Differentiates Voice of Customer (6/6)
SAP solution … Other offerings …
7 sentiment levels (strong positive, weak positive,
neutral, weak negative, strong negative, major
problem, minor problem)
Usually limited to 3 (positive, neutral, negative)
Identification of topic for each sentiment Topics not necessarily linked to sentiments
One sentiment per clause Often only one sentiment/document
Identification of requests N/a
Broad domain coverage – from automotive to
electronics
Usually limited to a particular domain – e.g.,
hospitality
Wide input coverage (customer reviews, CRM
messages, social media, surveys, etc.)
Usually limited to social media
Consistent across languages Vary widely across languages

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 14 Public
New TA_PARENT
A new column has been added to the $TA output table.
The TA_PARENT column stores the TA_COUNTER value of the parent token, or NULL if the token
has no parent. This field is used to indicate that there is a semantic relationship between two
tokens.
For example, it is used by the EXTRACTION_CORE_VOICEOFCUSTOMER rules to relate topics to
their enclosing sentiments.

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 15 Public
Improved Language Identification
Text analysis automatically detects the language of the
input text in order to apply the appropriate linguistic rules.
Language identification for Farsi, Polish, Thai and Turkish
has higher precision.

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 16 Public
Improved Word Segmentation for Chinese
More granular Chinese tokenization improves recall in
searches.

New or Improved Language
Coverage

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 18 Public
Available Text Analysis Configuration Options
Language LINGANALYSIS_BASIC LINGANALYSIS_STEMS
LINGANALYSIS_FULL EXTRACTION_CORE EXTRACTION_CORE_VOICEOFCUSTOMER EXTRACTION_CORE_PUBLIC_SECTOR EXTRACTION_CORE_ENTERPRISE
Arabic
Catalan
Chinese (Simplified) IMPROVED
Chinese (Traditional) NEW NEW
Croatian
Czech
Danish
Dutch NEW (Emoticons & Profanity only)
English IMPROVED NEW NEW
Farsi
French IMPROVED
German IMPROVED
Greek
Hebrew NEW
Hungarian
Indonesian NEW NEW
Italian NEW
Japanese
Korean
Norwegian (Bokmal)
Norwegian (Nynorsk)
Polish
Portuguese NEW
Romanian
Russian NEW
Serbian NEW (Cyrillic support)
Slovak
Slovenian
Spanish IMPROVED
Swedish
Thai NEW
Turkish NEW

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 19 Public
New Indonesian Language Support
Bahasa Indonesia is the official language of Indonesia.
Indonesia is the 4th most populous nation in the world. The
majority speak Indonesian, making it one of the most widely
spoken languages in the world.
The type of language support:
• Language identification – apply the appropriate grammatical
rules and dictionaries
• Tokenization – decompose word sequences, e.g. “the quick
brown fox” > “the” “quick” “brown” “fox”
• Stemming – reduce to linguistic base form, e.g. “ran” > “run”
• Part-of-Speech – tag word categories, e.g. “houses”: Nn-Pl
• Noun Groups – identify concepts, e.g. “global piracy”

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 20 Public
Improved Language Support for Hebrew, Thai, Turkish
Full linguistic analysis support by adding Part-of-Speech (POS)
tagging and Noun Group (concepts) extraction for the following
languages:
• Hebrew
• Thai
• Turkish

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 21 Public
New Cyrillic Script Support for Serbian
The Cyrillic script is an alphabetic writing system employed
across Eastern Europe, North and Central Asian countries.
Added Cyrillic script support to the previous Serbian Latin
script coverage.
© 2014 SAP SE or an SAP affiliate company. All rights reserved. 22 Public
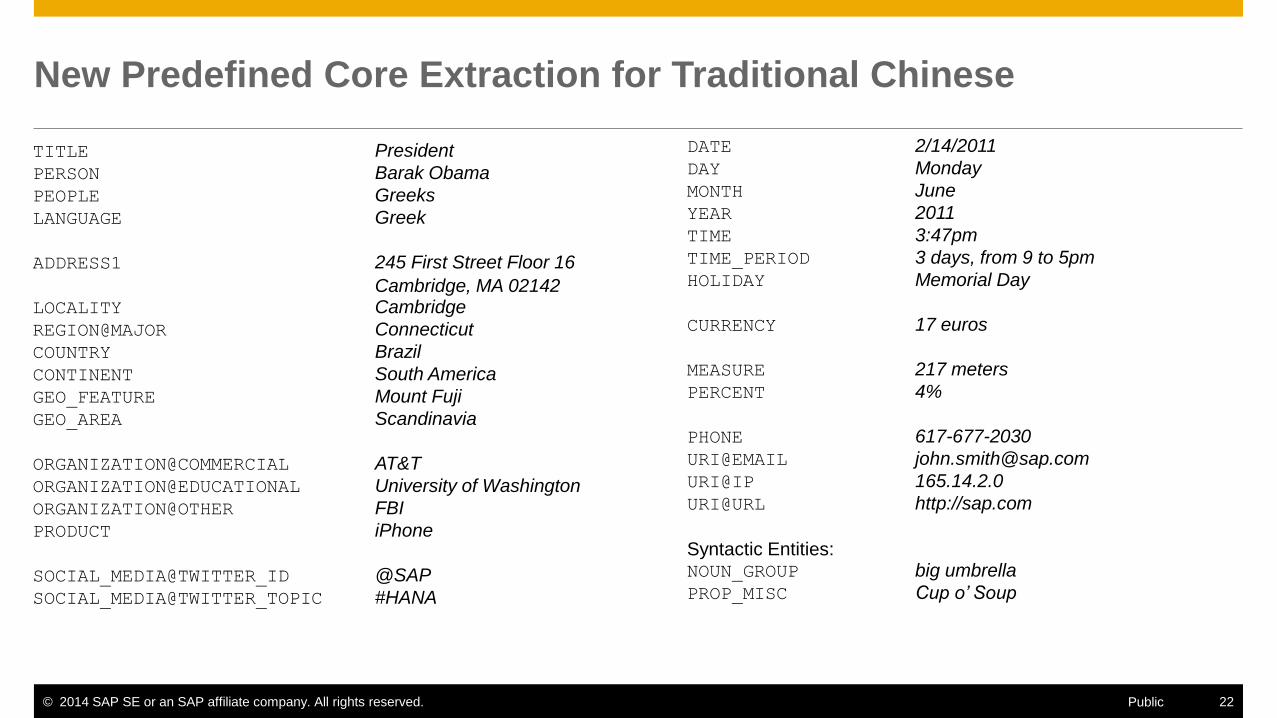
New Predefined Core Extraction for Traditional Chinese
TITLE President
PERSON Barak Obama
PEOPLE Greeks
LANGUAGE Greek
ADDRESS1 245 First Street Floor 16
Cambridge, MA 02142 LOCALITY Cambridge
REGION@MAJOR Connecticut
COUNTRY Brazil
CONTINENT South America
GEO_FEATURE Mount Fuji
GEO_AREA Scandinavia
ORGANIZATION@COMMERCIAL AT&T
ORGANIZATION@EDUCATIONAL University of Washington
ORGANIZATION@OTHER FBI
PRODUCT iPhone
SOCIAL_MEDIA@TWITTER_ID @SAP
SOCIAL_MEDIA@TWITTER_TOPIC #HANA
DATE 2/14/2011
DAY Monday
MONTH June
YEAR 2011
TIME 3:47pm
TIME_PERIOD 3 days, from 9 to 5pm
HOLIDAY Memorial Day
CURRENCY 17 euros
MEASURE 217 meters
PERCENT 4%
PHONE 617-677-2030
URI@EMAIL [email protected]
URI@IP 165.14.2.0
URI@URL http://sap.com
Syntactic Entities: NOUN_GROUP big umbrella
PROP_MISC Cup o’ Soup

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 23 Public
New VOC for Italian, Portuguese, Russian, Traditional Chinese
The following major fact types are classified:
Sentiments: expression of a customer’s feelings about something
Problems: a statement about something which impedes a customer’s work
Requests: expression of a customer’s desire for an enhancement/change
Profanity: defines a set of pejorative vocabulary
Emoticons: expression of someone's feelings about the whole sentence or situation

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 24 Public
New Profanity & Emoticon Extraction for Dutch
The following major fact types are classified:
Sentiments: expression of a customer’s feelings about something
Problems: a statement about something which impedes a customer’s work
Requests: expression of a customer’s desire for an enhancement/change
Profanity: defines a set of pejorative vocabulary
Emoticons: expression of someone's feelings about the whole sentence or situation
Note: Dutch does not support the above ‘faint’ sentiment analysis

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 25 Public
New Public Sector Extraction for English (1/2)
Augments predefined entity types for core extraction with a number of entity, event, and relation
types targeting public sector’s needs.
The following major fact types are classified:
Action: information about action and travel events
Military Units: information about teams, wings, and squadrons
Organizational Information: information about organizations
Person-Alias: information about a person’s possible aliases
Person-Appearance: information about a person’s appearance
Person-Attributes: information about a person’s non-appearance attributes
Person-Relationships: information about a person’s relationships
Spatial References: distances, cardinal directions, or locations

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 26 Public
New Public Sector Extraction for English (2/2)
The following 15+ types of named entities specific to public sector are extracted:
VEHICLE/AIR, VEHICLE/LAND, VEHICLE/WATER, VEHICLE/VIN, VEHICLE/LICENCE
PRECURSOR/CHEMICAL, PRECURSOR/NUCLEAR
WEAPON/BIOLOGICAL, WEAPON/CHEMICAL, WEAPON/EXPLODING, WEAPON/NUCLEAR,
WEAPON/PROJECTILE, WEAPON/SHOOTING
GEOCOORD and MGRS (Military Grid Reference System)
The following 40+ types of common entities specific to public sector are extracted:
COMMON_COUNTRY (beloved country)
COMMON_FACILITY (commercial airport)
COMMON_PERSON (math teacher)
Etc.

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 27 Public
New Enterprise Extraction for English
Rules for the extraction of entities and facts of particular interest to the enterprise domain.
The following major fact types are classified: Membership Information: information about a person’s affiliations
Management Changes: information about management changes
Product Releases: information about product releases
Mergers & Acquisitions: information about mergers and acquisitions
Organizational Information: founder, location or contact information

New Text Mining Features

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 29 Public
New Text Mining
Text mining works at the document level – making semantic
determinations about the overall content of documents relative to other
documents. Whereas text analysis does linguistic analysis and extracts
information embedded within each document.
Functions based on Vector Space Model
Identify similar documents
Identify key terms of a document
Identify related terms
Categorize new documents based on a training corpus
Scenarios
Highlight the key terms when viewing a patent document
Identify similar incidents for faster problem solving
Categorize new scientific papers along a hierarchy of topics
t1
tn
d1
d2

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 30 Public
Text Mining – Top-Ranked Functions
Input / Output Terms Documents
Terms related terms,
suggested terms relevant documents
Documents relevant terms related documents,
categorize

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 31 Public
Text Mining Index – Characteristics
The text mining index is an optional
data structure that is built from the
results of linguistic analysis. It is
bound to the full-text indexing and
text analysis process.
Full Text
Indexing
Fu
ll Te
xt In
de
x
Text
Analysis
Results
Table
Full Text
Indexing
with TA
and TM
Text Mining
Index
TM
config.
insert
ID TITLE

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 32 Public
New Text Mining – Basic Sample
Prerequisite
data is stored in a SAP HANA table
Goal
build a text mining index in order to use the text mining functions
CREATE FULLTEXT INDEX myIndexName ON myTable(myColumn) TEXT MINING ON;

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 33 Public
New Text Mining – Queries
SAP HANA provides a server-side
JavaScript interface for the Text
Mining engine
getRelatedTerms
getRelatdDocuments
and more
SAP HANA
Indexserver
Tables
Engine
HANA App
Preprocessor
Linguistic
Processing
Entity, Fact
Extraction
Extended Application Services (XS)
TM API
Views
Text Mining

Demo
Text Mining in SAP HANA SPS09

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 35 Public
Disclaimer
This presentation outlines our general product direction and should not be relied on in making
a purchase decision. This presentation is not subject to your license agreement or any other
agreement with SAP.
SAP has no obligation to pursue any course of business outlined in this presentation or to
develop or release any functionality mentioned in this presentation. This presentation and
SAP’s strategy and possible future developments are subject to change and may be changed
by SAP at any time for any reason without notice.
This document is provided without a warranty of any kind, either express or implied, including
but not limited to, the implied warranties of merchantability, fitness for a particular purpose, or
non-infringement. SAP assumes no responsibility for errors or omissions in this document,
except if such damages were caused by SAP intentionally or grossly negligent.

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 36 Public
How to find SAP HANA documentation on this topic?
SAP HANA Platform SPS 09
What’s New – Release Notes
Development
– SAP HANA Developer Guide
– SAP HANA Text Analysis Developer Guide
– SAP HANA Text Mining Developer Guide
References
– SAP HANA Text Analysis Extraction Customization Guide
– SAP HANA Text Analysis Language Reference Guide
• In addition to this learning material, you find SAP HANA documentation on
SAP Help Portal knowledge center at http://help.sap.com/hana_platform.
• The knowledge center is structured according to the product lifecycle: installation, security, administration,
development.

© 2014 SAP SE or an SAP affiliate company. All rights reserved.
Thank you
Anthony Waite
SAP HANA Product Management

© 2014 SAP SE or an SAP affiliate company. All rights reserved. 38 Public
© 2014 SAP SE or an SAP affiliate company. All rights reserved.
No part of this publication may be reproduced or transmitted in any form or for any purpose without the express permission of SAP SE or an SAP affiliate company.
SAP and other SAP products and services mentioned herein as well as their respective logos are trademarks or registered trademarks of SAP SE (or an SAP affiliate
company) in Germany and other countries. Please see http://global12.sap.com/corporate-en/legal/copyright/index.epx for additional trademark information and notices.
Some software products marketed by SAP SE and its distributors contain proprietary software components of other software vendors.
National product specifications may vary.
These materials are provided by SAP SE or an SAP affiliate company for informational purposes only, without representation or warranty of any kind, and SAP SE or its
affiliated companies shall not be liable for errors or omissions with respect to the materials. The only warranties for SAP SE or SAP affiliate company products and services
are those that are set forth in the express warranty statements accompanying such products and services, if any. Nothing herein should be construed as constituting an
additional warranty.
In particular, SAP SE or its affiliated companies have no obligation to pursue any course of business outlined in this document or any related presentation, or to develop or
release any functionality mentioned therein. This document, or any related presentation, and SAP SE’s or its affiliated companies’ strategy and possible future
developments, products, and/or platform directions and functionality are all subject to change and may be changed by SAP SE or its affiliated companies at any time for
any reason without notice. The information in this document is not a commitment, promise, or legal obligation to deliver any material, code, or functionality. All forward-
looking statements are subject to various risks and uncertainties that could cause actual results to differ materially from expectations. Readers are cautioned not to place
undue reliance on these forward-looking statements, which speak only as of their dates, and they should not be relied upon in making purchasing decisions.
Recommended

















