
PlaySta'on and Lucene
Indexing 1M documents per second

Who is talking Alexander Filipchik (PSN: LaserToy) Principal So>ware Engineer
at Sony Interac've Entertainment

Me

Agenda • Quick PSN overview • Search at PlayStaEon • First system: 200k docs/second for PS Store • Friends Finder and the Epic Journey • And finally 1M docs/second

The Rise of PlayStaEon4 PlayStaEon Network is big and growing. – Over 65 million monthly acEve users. – Hundreds of millions of users. – More than 40M devices – A Lot of Services.

Some Search Examples


What is it? • It is an online store for PlayStaEon • To give you an idea: – Revenue went from 800M per year several years ago to almost 5B last year
– It is making more than all of Nintendo • And it is not just eCommerce, it is connected to a whole set of services – Video Streaming, Game Streaming, Social, etc

Search use cases • Simple game or video search – Nothing exciEng here: just Solr – But you said something is indexing 200k doc/sec and I don’t believe there are so many games and videos out there!
-‐ User game/videos library, which is powered by Lucene and Cassandra

Challenges that led to the design • We are not Amazon, so content should be delivered right away
• What you bought is not just a transac'onal record which user checks once in a while. MulEple services need instant access to this informaEon in real 'me
• Which means it should be – highly available – fast – easy to scale – launch and forget

The Problem • Legacy System uses well known RelaEonal DB to handle our transacEons.
• It is state of the art so>ware that doesn’t scale well in our circumstances.
• We wanted to allow client to run any queries without consulEng with DBAs first.
• Sharding sounded like a pain. • Mul'ple regions should be easy.

SoluEon, as easy as
NoSQL

But hold on Axiom It is Not Easy to Replace a RelaEonal Database with NoSQL for user facing traffic. -‐ It is not easy in general

Simple Digital Store Model
Anothe
r hun
dred
tables

Taming the beast

Hypothesizes • For us most load will come from user-‐centric acEviEes
• So, we will mostly query within a user’s dataset
• Which means we will not need to join across users o>en

So we can denormalize
Purchased

So, we came up with The Schema Account1 Json 1 Json 2 …. Json n
Now it horizontally scales as long as NoSQL scales We can even have some rudimentary transac'ons Read is very fast – no joins
Now we need to propagate user purchases And updates to any shared data (names, descripEon) from RelaEonal DB and other sources to C* And figure out how to support flexible queries

Going deeper • What client wants: – Search, sort, filter
• What can we do: – Use some kind of NoSql secondary Index (Cassandra, Couchbase, …) powered by magic
– Fetch everything in memory and process L – How about…

Solr? • Can we use it to support our flexible user level query requirement?
• Not really: – Data has both high and low cardinality properEes – We will need to somehow index relaEons between products, enEtlements and users. And it is not obvious.
– And it will not be very fast because Solr is opEmized for a completely different use case
– It will be another set of systems to support and scale

What can We Do? • We can index ourselves, and wri'ng indexer sounds like a lot of fun
• Wait, someone already had the fun and made:

Account1 Json 1 Json 2 …. Json n
Schema v2 Account1 Json 1 Json n Version
Now We can Search on anything inside the row that represents the user Index is small and it is fast to pull it from NoSql
But we will be pulling all this bytes (indexes) all the 'me (stateless design) And what if 2 servers write to the same row?

Distributed Cache? • It is nice to keep things as close to our Microservice as
possible • In something that can do fast reads • And we have a lot of RAM these days • So we can have a beefy Memcached/Redis/Aerospike/[Put
your preferred Cache] deployment • And SEll pay Network penalty and think about scaling them • What if

So> State Paiern • Cache lives inside the MicroService, so no network penalty • There are very good libraries for ojeap caching (We use Ehcache) out
there, so no GC • Requests for the same user are processed on the same instance, so we
can save network roundtrip and also have some op'miza'ons done (read/write lock, etc)
• Changes to State also are replicated to the storage (C*) and are idenEfied with some version number
• We will need to check index version before doing search • If instance goes down, user session is moved to another instance
automa'cally • It is much easier to scale up Microservices than DB
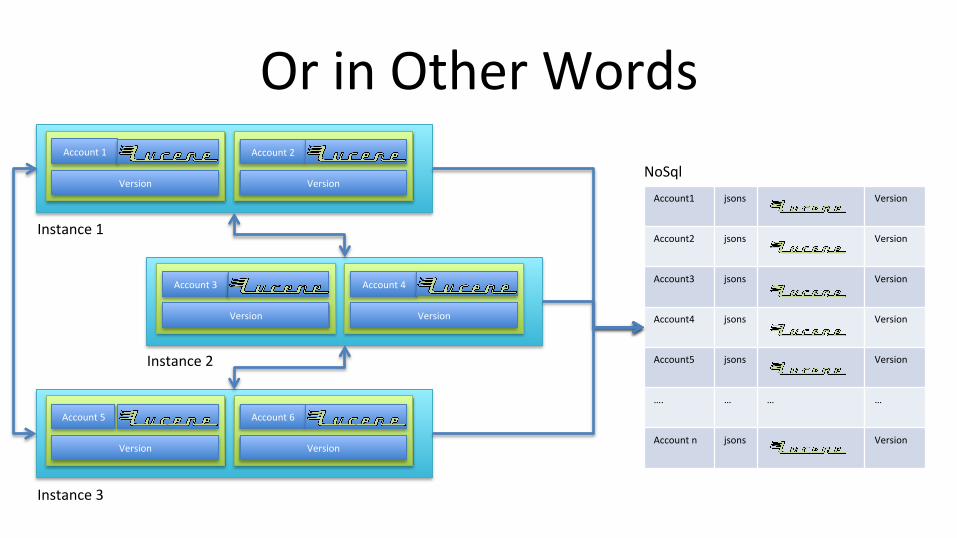
Or in Other Words Account 1
Version
Account 2
Version
Account 3
Version
Account 4
Version
Account 5
Version
Account 6
Version
Account1 jsons Version
Account2 jsons
Version
Account3 jsons
Version
Account4 jsons
Version
Account5 jsons
Version
…. … … …
Account n jsons
Version
Instance 1
Instance 2
Instance 3
NoSql

At first simple changes to Lucene
RAMFile RAMDirectory
implements Serializable
WritableRAMFile WritableRAMDirectory WritableRAMInputStream WritableRAMOutputStream

How can you do rouEng? • We are on AWS so we just used ELB s'ckiness with a twist
• It works only with cookies so, you will need to somehow store them
• Client library is smart and writes accountId-‐>AWSSEckyCookie to a shared cache
• Before sending request through ELB we pull s'cky cookie from the shared cache and a^ach it to the request

But what if cross user data changes?
• Product was renamed • Game image just got updated • And so on…

RelaEvity to the rescue

Cross User Data sync • So, as simply as: – Reverse lookup table to find all affected users – When something changes find all the affected users
– And lazily reindex

How About Stats? • Tens of billions of documents • Average API latency is below 10ms • Actual search latency is in microseconds • Hundreds thousands of documents are indexed per second
• And most importantly: – No major incidents in producEon.

Let’s talk about 1M doc/sec Friend Finder

New Feature/new Journey • We want users to be able to find other users on the plarorm • We should respect privacy sesngs • We want to recommend new friends to users (You May Know) • When user searches we want to display result in the following
order: – Direct friends – Friends of Friends 0_o – Everyone else
• Do it fast with a small team of ninjas (small means 2 engs)

So, we figured out • We can use Solr to index everyone, so we can do pla`orm wide
search • And decided to reuse same idea we did for Store with personal
indexes, so we can: – Sort by distance (direct, friend of a friend) – Sort by other user related fields (who do I play with o>en, Facebook
friends, and so on) – You may know is another search: Give me 10 friend of friends sorted
by number of common friends • It required some kind of no'fica'ons system in place so
personalized indexes can be rebuilt when something related to a parEcular user changes

Let’s put some boxes
Solr Cloud
Social Network
Friends Finder
Cassandra
Queue
Personalized Search
Microservice
Indexer Change Change
New user Privacy update etc
Friendship changed Name change etc

How did it do? • Solr was fine • Personalized part not so fine • Each change in friendship required reindexing of a lot of
users • Same goes for privacy changes • NoSQL we use (Cassandra) uses SSTables, so space it not
released right a>er an update • Data size was growing much faster than we expected • So, we had to take ac'on

Here we again Taming another beast

Some insights • You May Know was producing a significant load
• Both on update indexing and lazy indexing (only when user goes to search or checks You May Know) didn’t help
• Users don’t search frequently, but when they do they spend some 'me doing it

AcEons • Cache You May Know • Learn that it doesn’t help • Back to the drawing board

Crazy idea • What if we do ephemeral indexes? • They can live in memory for the dura'on of user’s search session and then get discarded
• We can use the same code, we just need to slightly change it

More boxes
Solr Cloud
Social Network
Friends Finder
Queue
Personalized Search
Microservice
Indexer Change
New user Privacy update etc Get Friends Friendship
Change, etc

Is it fixed yet? • Not really • Now we need to make indexing really fast • And significant 'me and resources are spent on pulling user related data from Social network
• Wait, we’ve just talked about Sod State. What if?

Let’s do math • Number of users: hundreds of millions, but number of ac've is less
• Each user has some searchable metadata; let’s say it is 200 bytes
• How much memory will we need to cache all the acEve ones?
• 100000000 * 200/ (1024 * 1024* 1024) = 18Gb • Well, it looks like it is doable

We can organize it like App Memory
Java Heap (8Gb)
Off Heap Ehcache (40 Gb)
Accounts info (20Gb) Lucene indexes (20Gb)
SSD if we need to spill over

Will it work? • On AWS we can have up to 256Gb of ram (r3.8xlarge) and instances have SSDs which usually do nothing
• Actually, with new X1 family we can have up to 1.9 TB • The only catch, now we need to propagate changes that go to Solr to Search microservice so we don’t use stale metadata
• So, it sounds like it can work

Yes

Learnings • You can do wonders when you are desperate • Worked before doesn't mean that it is going to work now
• Lucene is extremely fast when index is small • And can be applied to use cases that don’t look like search
• You can’t beat RAM

PlaySta'on is hiring in SF:
Find me at hackitects.com
Recommended

















