
© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Personalization: Techniques and applicationsKrishnan Ramanathan, Geetha Manjunath, Somnath BanerjeeHP Labs, Bangalore

2 22 January 2008
Topics• Overview of Personalization• User Profile creation • Personalizing Search• Document modeling• Recommender system• Semantics in Personalization

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Overview of PersonalizationKrishnan Ramanathan

4 22 January 2008
Why Personalization ?• Scale of the web is limiting its utility
•There is too much information•Consumer has to do all the work to use the web•Search engines and portals provide the same results for
different personalities, intentions and contexts
• Personalization can be the solution•Customize the web for individuals by
• Filtering out irrelevant information• Identifying relevant information

5 22 January 2008
Some quotes from NY bits• I am married with a house. Why do I see so many
ads for online dating sites and cheap mortgages?
Should I be happy that I see those ads? It means Internet advertisers still have no idea who I am.

6 22 January 2008
Personalization• Goal – Provide users what they need without requiring
them to ask for it explicitly• Steps
• Generate useful, actionable knowledge about users• Use this knowledge for personalizing an application
• User centric data model – Data must be attributable to specific user
• Two kinds• Business Centric : Amazon, Ebay• Consumer Centric
• Personalization requires User Profiling

7 22 January 2008
Applications of Personalization• Interface Personalization
•E.g. Go directly to the web page of interest instead of site home page
• Content personalization•Filtering (News, blog articles, videos etc)•Ratings based recommendations
• Amazon, Stumbleupon•Search
• Text, images, stories, research papers•Ads
• Service Personalization

8 22 January 2008
Why is personalization hard ?• Server side personalization – Sites do not see all
data•E.g. A user might visit Expedia and Orbitz, Expedia
doesn’t know what the user did on Orbitz
• Difficult to get user context •User needs to agree to cookies or login
• Site profiles are not portable•Some standards are emerging (Attention profile markup
language)
• Privacy

9 22 January 2008
Personalization example 1 (Routing queries)Google alerts Google news page
routing queries

10 22 January 2008
Personalization example 2 - Amazon

11 22 January 2008
Personalization Example 3 – Google news

12 22 January 2008
Personalization Example 4 – Yahoo MyWeb

13 22 January 2008
The future …

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
User Profile CreationKrishnan Ramanathan

15 22 January 2008
Outline• User Profile creation• Profile Privacy• Evaluating and managing user profiles• Personalizing search

16 22 January 2008
User profile information• Two kinds of information
•Factual (Explicit)•Behavioral (Implicit)
• Factual – Geographic, Demographic, Psychographic information•Eg. Age is 25 years, searched for Lexus, lives in
Bangalore
• Behavioral – Describes behavioral activities (visits finance sites, buys gadgets)

17 22 January 2008
Client side versus Server side profilesClient side
No access to clickstreams of multiple users
See all user data
Possible for user to aggregate and reuse their attentionalinformation
Strong privacy model
Can access the full compute power at the client
Server side
Have queries, clickstreams from multiple users
Don’t see all the user data
No way for users to aggregate and reuse the profiles different websites (Google, Yahoo, ..) build using their data
Privacy is a big problem
Server cycles have to be shared, however some computations can be done once and reused

18 22 January 2008
Desired profile characteristics• Represent multiple interests• Adapt to changing user interests• Incorporate contextual information

19 22 January 2008
Using User profiles to personalize services
Data Collection
User
Profile Constructor
Profile to Content Matching
Personalized services
User
Profile
Explicit and Implicit info
ContentSearch query, news, video,
…
Diagram adapted from Gauch et.al, Chapter 2, The Adaptive Web, Springer LNCS 4321

20 22 January 2008
User Profiling approaches• Broadly two approaches• IR approach
•User interests derived from text (documents/search queries)
• Machine learning approach•Model user based on positive and negative examples of
his interests•Problems
• Getting labeled samples• High dimensional feature space

21 22 January 2008
Profile building Steps• Authenticate the user• Select information to build profile from and archive
the information if necessary (eg. Web pages might get flushed from IE cache)
• Build/Refresh/Expand/Prune the profile • Use it in an application• Evaluate the profile

22 22 January 2008
Authenticating the user• Users need to be authenticated in order to attribute
data to a particular user for profile creation• Identifying single user
•Login•Cookies • IP address (when it is static)
• Identifying different users on same machine •Login•Biometrics

23 22 January 2008
Explicit user information collection• Ask the user for
• static information• Name, age, residence location, hobbies, interests etc• Google personalization – found explicit information to be noisy
• People specified literature as one of their interests but did not make a single related search
• Matchmine – presents examples (movies, TV shows, music, blog topics) and asks the users to explicity rate them
• Ratings• Netflix, Stumbleupon (thumbs up/down)
• In general, people do not like to give explicit information frequently
• Recent research (Jian Hu WWW 2007) showed good results for gender and age prediction based on users browsing behavior

24 22 January 2008
Explicit information collection: Matchmine interface

25 22 January 2008
Implicit user information collection• Data sources
•Web pages, documents, search queries, location• Information from applications (Media players, Games)
• Data collection techniques•Desktop based
• Browser cache• Proxy servers• Browser plugins
•Server side• Web logs• Search logs

26 22 January 2008
How much implicit info to use ?• Teevan (SIGIR 2005) constructed two profiles
•One with only search queries•Other using all information on desktop
• Findings•More richer information => better profile•All docs better than only recent docs better than only
web pages better than only search queries better than no personalization
• Drawback with implicit info – cannot collect info about user dislikes

27 22 January 2008
Stereotypes • Generalizations from communities of users
•Characteristics of group of users
• Stereotypes alleviate the bootstrap problem• Construction of stereotypes
•Manual – e.g. Bangalore user will be interested in IT•Automatic method
• Clustering – Similar profiles are clustered and common characteristics extracted

28 22 January 2008
How Acxiom delivers personalized ads (source - WSJ)• Acxiom has accumulated a database of about 133 million households and
divided it into 70 demographic and lifestyle clusters based on information available from public sources.
• A person gives one of Acxiom’s Web partners his address by buying something, filling out a survey or completing a contest form on one of the sites.
• Acxiom checks the address against its database and places a “cookie,” or small piece of tracking software, embedded with a code for that person’s demographic and behavioral cluster on his computer hard drive.
• When the person visits an Acxiom partner site in the future, Acxiom can use that code to determine which ads to show
• Through another cookie, Acxiom tracks what consumers do on partner Web sites

29 22 January 2008
Profile representation• Bag of words (BOW)
• Use words in user documents to represent user interests• Issues
• Words appear independent of page content (“Home”, “page”)• Polysemy (word has multiple meanings e.g. bank)• Synonymy (multiple words have same meanings e.g. joy, happiness)• Large profile sizes
• Concepts (e.g. DMOZ)• Use existing ontology maintained for free• Issues
• Too large (about 6 lakh DMOZ nodes), ontology has to be drastically pruned for use
• Need to build classifiers for each DMOZ node

30 22 January 2008
Word based term vector profiles• Profile represented as sets of words tf*idf weighted• Could use one long profile vector or different
vectors for different topics (sports, health, finance)• Documents converted to same representation,
matched with keyword vectors using cosine similarity
• Should take structure of the document into account (ignore html tags, email header vs body)

31 22 January 2008
Word based hierarchical profiles
User Profile:10
Sports:3.5
Soccer:2 Others:1.5
Research:5
IR:3 DB:2
Search:2
Sex:1.5
...
Support decreases from high to low level, and from left to right
Support of Interest
We are thankful to Yabo Arber-Xu from Simon Fraser University for kindly allowing us to use slides numbered 31,37,38,39 from his WWW 07 presentation.

32 22 January 2008
Building word based hierarchical profiles• Build a (word, document) map for each word
occurring in the corpus• Order words by amount of support
•Support of a word = number of documents in which word appears
• For each word•Decide whether to merge with another word (using some
measure of similarity)•Decide whether to make one word the child of other

33 22 January 2008

34 22 January 2008
Term similarity and Parent-child terms• Words that cover the same document sets are similar• Jacquard measure
• Parent child terms• A specific term is a child of a more general term if it frequently occurs
with a general term (but the reverse is not true)• Word w2 is taken as child of term w1 if P(w1|w2) > some_threshold• e.g. Terms “Soccer” and “Badminton” might co-occur with the term
“Sport” but not the other way around
|)()(|/|)()(|)2,1( 2121 wDwDwDwDwwSim UI=

35 22 January 2008
Personalization and Privacy• Studies have shown that
•People are comfortable sharing preferences (favourite TV show, snack etc.), demographic and lifestyle information
•People not comfortable sharing financial and purchase related information• Facebook fiasco because of reporting “Your friends bought …”
• Financial rewards (even small amounts) encourage disclosure•People parted with valuable information for Singapore
$15

36 22 January 2008
Privacy related attitudes (Teltzrow/Kobsa 2003)

37 22 January 2008
Manual Option – Absolute privacy guarantee, but requires a lot of user intervention
What and How much to Reveal? - 1
More specific
MoreSensitiveUser Profile:10
Sports:3.5
Soccer:2 Others:1.5
Research:5
IR:3 DB:2
Search:2
Sex:1.5
...

38 22 January 2008
User Profile U à indicator of a user’s possible interestsTerm t à indicator of a possible interest,
P(t)=Sup(t)/|D|
The amount of information for an interest tI(t) = log(1/P(t))= log(|D|/ Sup(t)).
àindication of the specificity and sensitivity of an interest
H(U) – the amount of information carried by UH(U)=∑tP(t)×I(t)
What and How much to Reveal? - 2
Two Privacy Parameters:
MinDetail - Protect t with P(t)<MinDetailExpRatio – H(U[exp] )/H(U)
The more detail we expose, the higher expRatio.

39 22 January 2008
The mindetail and expRation parameters allow a balance between privacy and personalization.
What and How much to Reveal? - 3
User Profile:10
Sports:3.5
Soccer:2 Others:1.5
Research:5
IR:3 DB:2
Search:2
Sex:1.5
...
minDetail=0.5expRatio=44%
minDetail=0.3expRatio=69%

40 22 January 2008
Profile portability• Move the profile to a central server
•Claria PersonalWeb, Google-Yahoo-Microsoft•Provision to delete search queries, visited pages•No control over which part of the profile can be used
• Have a client side component that reconstructs the profile on the client using server side info (Matchmine)
• Attention Profile markup language•Allows explicit and implicit information to be stored (as
XML) and provided to web services

41 22 January 2008
Attention Profile Markup (http://www.apml.org)

42 22 January 2008
Application-independent evaluation of the profile• Stability
• Number of profile elements that do not change over the evaluation cycle
• Precision• How many items in the profile does the user agree with as
representative of his interests ?• Does the user agree with the strength of the interest ?• Do interests at deeper levels of the hierarchy have less precision
compared to interests at higher levels ?
• Which data sources (bookmarks, search keywords, web pages) is better ?• Bookmarks were not very representative of user interests in our study

43 22 January 2008
Profile evaluation
0
0.10.20.30.40.50.6
0.70.8
0 200 400 600
Number of web pages in cache
Stab
ility Stability_alpha
Stability_date
0.7
0.75
0.8
0.85
0.9
0.95
1
Support > 5 3 < Support < 5 Support < 3
Prec
ision
0
0.2
0.4
0.6
0.8
1
1.2
Level 1 Level 2 Level 3 Level 4 Level 5 Level 6
Perc
ent (
%)
Percentage in profile
Precis ion
Figure 1
Figure 2 Figure 3
Sample Evaluation of one profiling algorithm
•Profiles are stable (fig 1)
•Profile elements with high support have high precision (fig 2)
•Profile elements at all levels of the hierarchy have similar precision (fig 3)

44 22 January 2008
Managing the profile• Profiles may need to be expanded (bootstrapped) or
pruned• Allowing users to manually edit their profiles to add/delete
topics of interest was found to make performance worse (Jae-wook Ahn, WWW 2007)• Adding and deleting topics to profile harmed system performance• Deleting topics harmed performance four times more compared to
adding topics
• Some agents learn short term and long term profiles separately using different techniques (K-NN for short term interests, Naïve Bayes for long term interests)

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Personalizing SearchKrishnan Ramanathan

46 22 January 2008
Personalized search• Search can be personalized based on
•User profile•Current working context•Past search queries•Server side clickstreams•Personalized Pagerank
• Determining user intent is hard (e.g query Visa)

47 22 January 2008
A generic personalized search algorithmusing a user profile
• Inputs - User profile, Search query• Output – A results vector reordered by the user’s
preference• Steps
•Send the query to a search engine• Results[] = A vector of the search engine’s results•For each item i in Results[] calculate the preference
Pref [i] = α *Similarity(Results[i] , User Profile)
+ (1- α)*SearchEngineRank
•Sort Results[] using Pref [i] as the comparator

48 22 January 2008
Current working context – JIT retrieval• Context includes time, location, applications
currently running, documents currently opened, IM status
• Use profile and current context to provide relevant (and just-in-time) information•Blinkx toolbar – provides relevant news, video and
Wikipedia articles within different applications (MicrsoftWord, IE browser)
• Intersect interests from the overall profile with current context to get the contextual profile
• Context can also be used in query expansion

49 22 January 2008
Personalization based on Search history• Use query-to-query similarity to suggest results that
satisfied past queries• Create user profiles from past queries/snippets from
search results clicked• Misearch (Gauch et.al 2004) creates weighted concept
hierarchies based on ODP as the reference concept hierarchy• Compute degree of similarity between search engine result
snippets (title and text summaries) and user profile as
jdocument in k concept ofweight iprofilein k concept ofweight
*),(1
==
= ∑=
jk
ik
n
kjkikji
wdwp
wdwpdocusersim

50 22 January 2008
Personalization by clickthrough data analysis – CubeSVD (Jian-Tao Sun, WWW 2005)• Search engine has tuples of the form (User, Query, Visited
page)• Multiple tuples constitute a tensor (generalization of matrix
to higher dimensions)• Higher order SVD (HOSVD) performs SVD on tensor• The reconstructed tensor is a tuple of the form (User,
Query, web page, p)• Where p is the probability that the user posing the query will visit
the web page• Recommend pages with highest value of p• Computationally intensive but HOSVD can be done offline
• Need to recompute to account for new clickthrough data

51 22 January 2008
Topic sensitive pagerank (Haveliwala2002)• For top 16 ODP categories, create a pagerank vector
•Each web page/document d has multiple ranks depending on what the topic of interest j is
• For a query compute, P(Cj|q) = P(Cj)*P(q,Cj)• Intuition: If a topic is more probable given a query, the
topic specific rank should have more say in the final rank
• Compute query sensitive rank as
jdj rankqCP *)|(∑

52 22 January 2008
Topics ••• Overview of PersonalizationOverview of PersonalizationOverview of Personalization••• User Profile creationUser Profile creationUser Profile creation••• PersonalizingPersonalizingPersonalizing SearchSearchSearch• Document modeling• Recommender System••• Semantics in PersonalizationSemantics in PersonalizationSemantics in Personalization

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Document modelingSomnath Banerjee

54 22 January 2008
Under this topic• Document representation
• Document analysis using •Latent Semantic Analysis (LSA)•Probabilistic Latent Semantic Analysis (PLSA)
• Document Classification•Support Vector Machine (SVM): A machine learning
algorithm

55 22 January 2008
Document representation• Term vector
• Document is represented as vector of terms• Each dimension corresponds to a separate term
• Several methods of computing the weights of the terms• Binary weighting: 1 if the word appear in the document
• Most well known is TF*IDF
{ }ijiji
jiji
kjk
jiji
idftftfidf
dtd
Didf
n
ntf
×=
∈=
=∑
,,
,
,,
:log

56 22 January 2008
Computing similarity
BABA
BAD
BABA
BAJ
BA
BA
BA
BAineBAsimii
ii
+==
==
×=
×
•==
∑∑∑
I
U
I
2),(t coefficiensDice'
),(t coefficienJaccard
)(cos),(22
22
θ

57 22 January 2008
Example• g1: Google Gets Green Light from FTC for DoubleClick Acquisition• g2: Google Closes In on DoubleClick Acquisition• g3: FTC clears Google DoubleClick deal• g4: US regulator clears DoubleClick deal• g5: DoubleClick deal brings greater focus on privacy
• e1: EU Agrees to Reduce Aviation Emissions• e2: Aviation to be included in EU emissions trading• e3: EU wants tougher green aviation laws
• Underlined words appeared in more than one documents

58 22 January 2008
Term Document Matrix (X)
01100000emmision
11100000aviation
11100000eu
00011100deal
00001100clear
00000011acquisition
00011111doubleclick
00000101ftc
10000001green
00000111google
e3e2e1g5g4g3g2g1

59 22 January 2008
Retrieval example• Query (or Profile) q = “Google Acquisition”
• Query vector q = [1 0 0 0 1 0 0 0 0 0]'
• Cosine similarity of the query to the documents
S =
• What about the documents g4 and g5?• Problem of data sparsity
000000.4470.8160.634
e3e2e1g5g4g3g2g1

60 22 January 2008
Under this topic••• Document representationDocument representationDocument representation
• Document analysis using •Latent Semantic Analysis (LSA)•Probabilistic Latent Semantic Analysis (PLSA)
••• Document ClassificationDocument ClassificationDocument Classification••• Support Vector Machine (SVM) ): A machine learning Support Vector Machine (SVM) ): A machine learning Support Vector Machine (SVM) ): A machine learning
algorithmalgorithmalgorithm

61 22 January 2008
Latent Semantic Analysis (LSA)• You searching for “Tata Nano” are not the documents
containing “People’s Car” also relevant?
• How a machine can understand that?• Analyze the collection of documents
• Documents that contain “Tata Nano” generally contain “People’s Car” as well• Covariance of these two dimensions are high
• LSA finds such correlation using a technique from linear algebra

62 22 January 2008
LSA• Transforms the term document matrix into a relation
between the • terms and some concepts, • relation between those concepts and the documents
• Concepts are the dimensions of maximum variance
• Removes the dimensions with low variance• Reduction in feature space• Term document matrix becomes denser

63 22 January 2008
Singular Value Decomposition
terms X T
•1•2
•3…
•m
D'=
documents
t x d t x m
m x m m x d
S
•1• •2 • … • •m>0
m is the rank of the matrix X
T and D are orthonormal matrix
S is a diagonal matrix of singular values

64 22 January 2008
Reduced SVD
Xk Tk
•1•2
•3…
•k
Dk'=
documents
t x d t x k
m x k m x k
Skterms
-Choose largest k singular values (•1… •k)
-Choose k columns of T and D
-Then construct Xk
-Xk is the best k rank approximation of X in terms of Frobenius norm

65 22 January 2008
Example• g1: Google Gets Green Light from FTC for DoubleClick Acquisition• g2: Google Closes In on DoubleClick Acquisition• g3: FTC clears Google DoubleClick deal• g4: US regulator clears DoubleClick deal• g5: DoubleClick deal brings greater focus on privacy
• e1: EU Agrees to Reduce Aviation Emissions• e2: Aviation to be included in EU emissions trading• e3: EU wants tougher green aviation laws
• Query (or Profile) q = “Google Acquisition”

66 22 January 2008
Term Document Matrix (X)
01100000emmision
11100000aviation
11100000eu
00011100deal
00001100clear
00000011acquisition
00011111doubleclick
00000101ftc
10000001green
00000111google
e3e2e1g5g4g3g2g1

67 22 January 2008
LSA Example
T(10x7) =
S(7x7) =
D‘(7x8) =

68 22 January 2008
LSA Example• Rank 2 approximation of X
terms
documents

69 22 January 2008
LSA Example• Query (or Profile) q = “Google Acquisition”• Query vector q = [1 0 0 0 1 0 0 0 0 0]'
• Representation of the queryDq = q'T2S2
-1 = [-0.204 0.005 ]
• Query to document similaritySim = Dq S2
2 D2'

70 22 January 2008
LSA Example
X
Dq
D2'
Sim =
X
S22

71 22 January 2008
Example• g1: Google Gets Green Light from FTC for DoubleClick Acquisition• g2: Google Closes In on DoubleClick Acquisition [0.936]• g3: FTC clears Google DoubleClick deal [1.426]• g4: US regulator clears DoubleClick deal [0.891]• g5: DoubleClick deal brings greater focus on privacy [0.697]
• e1: EU Agrees to Reduce Aviation Emissions [0.035]• e2: Aviation to be included in EU emissions trading [0.035]• e3: EU wants tougher green aviation laws [0.152]
• Underlined words appeared in more than one documents
[1.284]

72 22 January 2008
Under this topic••• Document representationDocument representationDocument representation
• Document analysis using ••• Latent Semantic Analysis (LSA)Latent Semantic Analysis (LSA)Latent Semantic Analysis (LSA)•Probabilistic Latent Semantic Analysis (PLSA)
••• Document ClassificationDocument ClassificationDocument Classification••• Support Vector Machine (SVM) ): A machine learning Support Vector Machine (SVM) ): A machine learning Support Vector Machine (SVM) ): A machine learning
algorithmalgorithmalgorithm

73 22 January 2008
Probabilistic Latent Semantic Analysis (PLSA)• If we know the document collection contains two
topics can we do better?•Can we estimate
• Probability( topic | document) ?• Probability( word | topic) ?
• If we can also estimate Probability( topic | query) then we can compute the document to query similarity
• PLSA is a statistical technique to estimate those probability from a collection of documents

74 22 January 2008
Probabilistic Latent Semantic Analysis (PLSA)• Dyadic data: Two (abstract) sets of objects, X ={x1,
..,xm} and Y ={y1, … ,yn} in which observations are made of dyads(x,y)•Simplest case: observation of co-occurrence of x and y•Other cases may involve scalar weight for each
observation
• Examples:• X = Documents, Y =Words• X = Users, Y =Purchased Items• X = Pixels, Y =Values

75 22 January 2008
PLSA• Document consists of topics and words in the document are generated
based on those topics
• Generative model (asymmetric): (di, wj) is generated as follow• pick a document with probability P(di),• pick a topic zk with probability P(zk | di),• generate a word wj with probability P(wj | zk)
( ) ( ) ( )
( ) ( ) ( )∑=
=
=K
kikkjij
ijiji
dzPzwPdwP
dwPdPwdP
1
|||
|,
D Z WP(di) P(wj |zk)P(zk |di)

76 22 January 2008
PLSA• Parameters P(di), P(zk | di), P(wj | zk)
• P(di) is proportional to number of times the document is observed and be computed independently
• P(zk | di), P(wj | zk) can be estimated using Expectation Maximization (EM) algorithm
( )
( ) ( )
ordsdistinct wofNumber Ndocuments;ofNumber M
1 1
1 1
),(
,ln,
,),(
==
= =
= =
∑∑
∏∏
=
=
M
i
N
jjiji
N
i
M
j
wdnji
wdPwdnL
wdPWDP ji

77 22 January 2008
PLSA: EM steps• E-Step:
• M-Step:
( ) ( ) ( )
( ) ( )∑=
= K
lillj
ikkjjik
dzPzwP
dzPzwPwdzP
1
||
||,|
( )( ) ( )
( ) ( )
( )( ) ( )
)(
,|,
|
,|,
,|,|
1
1 1
1
i
M
jjikji
ik
M
m
N
imikmi
N
ijikji
kj
dn
wdzPwdn
dzP
wdzPwdn
wdzPwdnzwP
∑
∑∑
∑
=
= =
=
=
=

78 22 January 2008
PLSA Exampleg1 googleg1 greeng1 ftcg1 doubleclickg1 acquisitiong2 googleg2 doubleclickg2 acquisitiong3 ftcg3 clearg3 googleg3 doubleclickg3 dealg4 clearg4 doubleclickg4 dealg5 doubleclickg5 deal
e1 eue1 aviatione1 emissione2 aviatione2 eue2 emissione3 eue3 greene3 aviation
•Dyadic data in our example

79 22 January 2008
PLSA Example• After 20 iterations of EM algorithm
P(zk |di)
P(wj |zk)

80 22 January 2008
PLSA Example• Query q = “Google Acquisition”• Steps
• Keep P(wj |zk) fixed. • Estimate P(zk |q) using EM steps • Then compute cosine similarity of the vector P(Z|q) to the
P(Z|d)
01qZ2Z1
P(zk |q)

81 22 January 2008
Example• g1: Google Gets Green Light from FTC for DoubleClick Acquisition• g2: Google Closes In on DoubleClick Acquisition [1.0]• g3: FTC clears Google DoubleClick deal [1.0]• g4: US regulator clears DoubleClick deal [1.0]• g5: DoubleClick deal brings greater focus on privacy [1.0]
• e1: EU Agrees to Reduce Aviation Emissions [0.0]• e2: Aviation to be included in EU emissions trading [0.0]• e3: EU wants tougher green aviation laws [0.0]
• Underlined words appeared in more than one documents
[1.0]

82 22 January 2008
Under this topic••• Document representationDocument representationDocument representation
••• Document analysis using Document analysis using Document analysis using ••• Latent Semantic Analysis (LSA)Latent Semantic Analysis (LSA)Latent Semantic Analysis (LSA)••• Probabilistic Latent Semantic Analysis (PLSA)Probabilistic Latent Semantic Analysis (PLSA)Probabilistic Latent Semantic Analysis (PLSA)
• Document Classification•Support Vector Machine (SVM) ): A machine learning
algorithm

83 22 January 2008
Document Classification

84 22 January 2008
Document classification with SVM• We will concentrate on binary classification
• {sports, not sports}, {interesting, not interesting} etc• In general {+1,-1} also called {positive, negative}
• SVM is a supervised machine learning technique. It learns the pattern from a training set
• Training set• A set of documents with labels belonging to {+1, -1}
• SVM tries to draw a hyperplane that best separates the positive and negative data in the training set

85 22 January 2008
Support Vector Machine (SVM)• A Machine learning algorithm
• SVM was introduced in COLT-92 by Boser, Guyon and Vapnik.
• Initially popularized in the NIPS community, now an important and active field of all Machine Learning Research
• Successful applications in many fields (text, bioinformatics, handwriting, image recognition etc.)

86 22 January 2008
SVM – Maximum margin separation
SVM illustration by Bülent Üstün
Radboud Universiteit

87 22 January 2008
Mapping to higher dimension for non-separable data
P1 • (0,0) x {+1}
P2 • (0,1) x {-1}
P3 • (1,1) x {+1}
P4 • (1,0) x {-1}
P1
P3
P4
P2
( )
→→
21
22
21
xxxx
xx φ
P1 • (0,0,0) x {+1}
P2 • (0,1,0) x {-1}
P3 • (1,1,1) x {+1}
P4 • (1,0,0) x {-1}

88 22 January 2008
The XOR example
SVM uses kernel trick to map data to higher dimensional feature space without incurring much computational overhead

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Recommender SystemSelect top N items for a user-Somnath Banerjee

90 22 January 2008
Example

91 22 January 2008
Example

92 22 January 2008
Classification• Broadly three approaches
•Content Based Recommendation•Collaborative Filtering•Hybrid approach

93 22 January 2008
Content based recommendation• Utility of an item for a user is determined based on
the items preferred by the user in the past
• Applies similar techniques as introduced in the document modeling part

94 22 January 2008
Basic Approach• Create and represent the user profile from the items rated by the user in
the past• A popular choice of profile representation is vector of terms weighted
based on TF*IDF
• Represent the item in the same format• A news item can be represented using (TF*IDF) term vector• For movies, books one needs to get sufficient metadata to represent the
item in vector format
• Define a similarity measure to compute the similarity between the profile and the item• Popular choice is cosine similarity• Advance machine learning techniques can also be applied to do the
matching
• Recommend most similar items

95 22 January 2008
Problems with content based recommendation• Knowledge engineering problem
•How do you describe multimedia, graphics, movies, songs
• Recommendation shows limited diversity
• New user problem• It requires large number of ratings from the user to generate
quality recommendation

96 22 January 2008
Collaborative filtering• Recommends items that are liked in the past by other users
with similar tastes
• Quite popular in e-commerce sites, like Amazon, eBay
• Can recommend various media types, text, video, audio, Ads, products

97 22 January 2008

98 22 January 2008
Advantages• Does not have the knowledge engineering
problem•Both user and items can be represented using just ids
• Often recommendation shows good amount of diversity

99 22 January 2008
Lets learn C.F. with an example
What rating Jane will possibly give to MI – II?
154?
MI -II
133Cathy
522Tom
32Bill
255Jane
Air Force One
Tomb RaiderBen Hur
CasablancaRan
100 22 January 2008
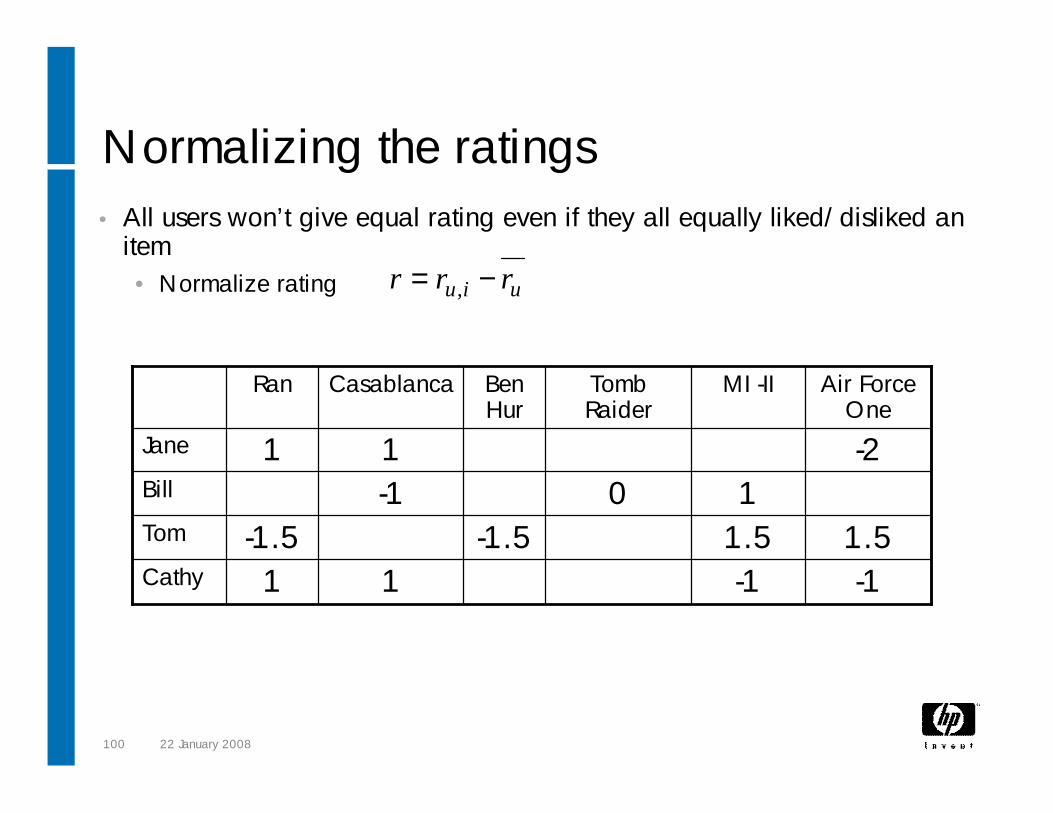
Normalizing the ratings• All users won’t give equal rating even if they all equally liked/disliked an
item• Normalize rating uiu rrr −= ,
-11.51
MI -II
-111Cathy1.5-1.5-1.5Tom
0-1Bill-211Jane
Air Force One
Tomb Raider
Ben Hur
CasablancaRan

101 22 January 2008
Similarity between users• Who are the other users with similar taste like Jane
• Each row of the matrix is a vector representing the user• Compute cosine similarity between the users
-0.612Tom
0.816-0.289JaneCathyBill

102 22 January 2008
Compute probable rating• Possible rating is the rating given by the other users weighted by the
similarity• Sometimes only top N similar users are taken
• Jane will rate MI-II as
( ) ( )( )∑
∑
∈
∈
−∗
+=
Vv
Vvviv
uiu vusim
rrvusimrr
,
, ,
,
82.2816.0612.0289.0
)1816.0()5.1612.0()1289.0(4
≈++
−×+×−+×−+=

103 22 January 2008
Remarks• There is another popular version of the above technique
where instead of user to user similarity item to item similarity is computed• Rating prediction is based on the similarity to the items rated by the
user
• The above mentioned methods are known as memory based techniques• It has the disadvantage that it require more online
computations

104 22 January 2008
Model based technique• A model is learnt using the collection of ratings as training
set
• Prediction is done using the model
• More offline computing and less online computing

105 22 January 2008
Model based technique• A simple model
( ) ( )∑∈
′ ∈′=×==Rr
usuiuiuiu IsrrrrrEr ,|Pr ,,,,

106 22 January 2008
Model based technique• Recent research tries to model the recommendation process
with more complex probabilistic models
• Parameters P(r|z,i) and P(z|u) can be estimated using EM algorithm
( ) ( ) ( )∑ ×=z
uzPizrPiurP |,|,|
u
i r
z

107 22 January 2008
Problems of C.F.• New user problem
• New Item problem
• Sparsity problem•A user rates only a few items
• Unusual user•User whose tastes are unusual compared to the rest of
the population

108 22 January 2008
Hybrid approaches- Combining Collaborative and Content based methods
• Combining predictions of Content based method and C.F.• Implement separate content based and collaborative
filtering method
•Combine their predictions using• Linear combination• Voting schemes
•Alternatively select a prediction method based on some confidence measure on the recommendation

109 22 January 2008
Hybrid Approaches• Adding content based characteristics into a C.F.
based method•Maintain a content based profile for each user•Use these content based profiles (not the commonly
rated items) to compute the similarity between users•Then do C.F.•Helps to overcome sparsity related problems as
generally not many items are commonly rated two users

110 22 January 2008
Hybrid approaches• Adding C.F. characteristics into a content based
method•Most popular techniques in this category is
dimensionality reduction on a group of content based profiles
•Dimensionality reduction technique like LSA can improve prediction quality by having compact representation of profile

111 22 January 2008
Future directions of research (Adomavicious et al)
• Incorporating richer user and item profile in a unified framework of different methods
• Using contextual information in recommendation• Example: Recommending a vacation package the system should
consider• User• Time of the year• With whom the user plans to travel• Traveling conditions and restrictions at the time
• Multi-Criteria ratings• E.g. three criteria restaurant ratings food, décor and service

112 22 January 2008
Future directions of research• Non-intrusiveness
• Flexibility•Enabling end-users to customize recommendation
• Evaluation•Empirical evaluation on test data that users choose to
rate• Items that users choose to rate are likely to be biased
•Economics-oriented measures

113 22 January 2008
References (Recommender System)• Adomavicius, G., and Tuzhilin, A., “Toward the Next
Generation of Recommender Systems: A Survey of the State-of-the-Art and possible Extensions”, IEEE Transaction on Knowledge and Data Engineering, 2005

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Semantics in Personalization
Geetha ManjunathHewlett Packard Labs India

115 22 January 2008
Topic Outline• Why use semantic information?• Introduction to Ontology• Formal Specification of an Ontology
•A Quick Overview of Semantic Web• Techniques and Approaches
•Word Sense Disambiguation•Semantic Profiles•Constrained Spreading Activation•Semantic Similarity
• Looking Ahead

116 22 January 2008
News Example Revisited• g1: Google Gets Green Light from FTC for DoubleClick Acquisition• g2: Google Closes In on DoubleClick Acquisition• g3: FTC clears Google DoubleClick deal• g4: US regulator clears DoubleClick deal• g5: DoubleClick deal brings greater focus on privacy
• e1: EU Agrees to Reduce Aviation Emissions• e2: Aviation to be included in EU emissions trading• e3: EU wants tougher green aviation laws
•

117 22 January 2008
News Example Modified• g1: Apple Gets Green Light from FTC for TripleClick Acquisition• g2: Apple Closes In on TripleClick Acquisition• g3: FTC clears Apple TripleClick deal• g4: US regulator clears TripleClick deal• g5: TripleClick deal brings greater focus on privacy
• e1: EU Agrees to Reduce Aviation Emissions• e2: Aviation to be included in EU emissions trading• e3: EU wants tougher green aviation laws
• f1: Apple prices soaring high.• f2: Increased apple rates causes concern to doctors.• f3: Cost of 10 kg of apple to become Rs 1000 from 1 Feb.
IT company Acquisition
Google Acquisition

118 22 January 2008
Semantics for Personalization
Data Collection
User Documents
Profile Constructor
Profile to Content Matching
Personalized services
User
Profile
Explicit and Implicit info
ContentSearch query, news, video,
…
ImplicitInfo based on domain knowledge
Represent Profiles as meaningful
concepts
Profile Representation using domain
concepts
Semantics based
Matching Function
Expand the generated
profile using domain info
Cluster documents based on
better User groups

119 22 January 2008
Techniques and Approaches1. Implicit Information based on domain knowledge
• Word Sense Disambiguation2. Represent Profiles as meaningful concepts
• Semantic Profiles3. Semantics based Matching Function
• Semantic Distance4. Expand the generated profile using domain info
• Constrained Spreading Activation5. Cluster documents based on better User groups
• Social Semantic Networks

120 22 January 2008
Jaguar
Word Sense disambiguation
Panther
Big cat
Feline
Carnivore
Mammal
Animal
tailfurnail
Hyp
onym
s
Meronyms
Synonyms
same as
contains
type of
Using Wordnet
Jaguar
Car
Automobile
Motor Vehicle
Vehicle
Transport
AcceleratorDoorBumper
Wheel

121 22 January 2008
Word Sense disambiguation
Apple
food
solid
substance
entity
Apple
company
institution
organization
group
Abstractentity
employeeAdvisory boardstocks
skinseedpulp
plant
eat
ripetree
animalplant
fruit
KEY: Additional domain information
RevenueAcquisitionSales tax
…..
Business

122 22 January 2008
Three level Conceptual Network
• Hyperlinks• Order of access• Browsed together• …
• Co-occurrence• synonyms• hyponyms• ..
• Domain Ontology

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Introduction to Ontologies

124 22 January 2008
Views on Ontologies
Front-End
Back-End
TopicMaps
Extended ER-Models
Thesauri
Predicate Logic
Semantic Networks
Taxonomies
Ontologies
Navigation
Queries
Sharing of Knowledge
Information Retrieval
Query Expansion
Mediation Reasoning
Consistency CheckingEAI

125 22 January 2008
Structure of an OntologyOntologies typically have two components:• Names for important concepts in the domain
•Elephant is a concept whose members are a kind of animal
•Herbivore is a concept whose members are exactly those animals who eat only plants or parts of plants
• Background knowledge/constraints on the domain•No individual can be both a Herbivore and a
Carnivore

126 22 January 2008
A Simple Ontology
Person Topic Document
Student Researcher Semantics Ontology
PhD Student
ObjectIs a
Is a
Is a
Described inknows
writes
similar
Is a
Topic Document Document TopicDescribed in Is about
Person Document Person TopicTopicwrites Is about knows

127 22 January 2008
Defining Ontology[Gruber, 1993]An Ontology is aformal specificationof a sharedconceptualizationof a domain of interest.
Ø ExecutableØ Group of personsØ About conceptsØ Application & “unique truth”
•Formal description of concepts and their relationships•Strong Basis in the family of First Order Logics (DL)•Deductive Inference based on ground truth of the domain.

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Formal Specification of OntologiesSemantic Web: A quick introduction

129 22 January 2008
The Semantic Web VisionSemantic web aims to transform WWW into a global database
“The semantic web is a web for computers”

130 22 January 2008
Semantic web
• Extend existing rendering markup with semantic markup• Metadata annotations that describe content/funtion of web
accessible resources
• Use Ontologies to provide vocabulary for annotations• “Formal specification” is accessible to machines
• A prerequisite is a standard web ontology language• Need to agree common syntax before we can share semantics• Syntactic web based on standards such as HTTP and HTML
Make web resources more accessible to automated processes

131 22 January 2008
Semantic Web Layers
Globally Unambiguous
IdentifiersUser definable, domain specific
markup
Context for vocabulary

132 22 January 2008
What is RDF ?
• RDF – resource description framework• RDF is a data model• Statement-based approach
•Subject/predicate/object triples – simple powerful unit•All resources identified by URIs•Triples create a directed labelled graph of
• object/attribute/value • (semantic) relationships between objects
• RDF model is an abstract layer independent of XML•XML serialization is supported

133 22 January 2008
RDF Example
Enables easy merge of information
• Indirect metadata (anyone can say anything about anything)
• Extensibility (open world assumption, compositional)
../presentation.ppt
mailto:[email protected]
Some starter slides…
2005-09-23
dc:date
dc:creator
org:email
dc:description
people.com/../dave_reynolds
resource valueproperty
<rdf:Description rdf:about=“allppt.com/presentation.ppt"><dc:creator resource=“people.com/person/dave_reynolds"/></rdf:Description>
<rdf:Description rdf:ID=“people.com/person/dave_reynolds"><org:email resource= “mailto:[email protected]” /></rdf:Description>

134 22 January 2008
RDF Schema • Defines small vocabulary for RDF:
•Class, subClassOf, type•Property, subPropertyOf•domain, range
• Vocabulary can be used to define other vocabularies for your application domain
rdfs:Resource
Veh: Van
Veh: PassengerVehicle
Veh: Truck
Veh: MiniVan
Veh: MotorVehicle
rdfs:subClassOf
rdfs:subClassOf
rdfs:subClassOf

135 22 January 2008
OWL – Web Ontology Language• A language to express an ontology• An OWL ontology is an RDF graph
• A set of RDF triples • Vocabulary Extension
• Structure• Ontology headers• Class Axioms
• Class Descriptions, Enumeration, Membership Restrictions• Property Axioms
• Property Descriptions, Property Restrictions, Functional Spec• Facts about individuals
Important Concepts of the Domain
Domain Restrictions/Truth

136 22 January 2008
OWL Class Constructors

137 22 January 2008
The Syntax
<owl:Class rdf:ID=“Parent”><owl:intersectionOf >
<owl:Class rdf:about="#Person"/><owl:Restriction>
<owl:onProperty rdf:resource="#hasChild"/><owl:minCardinality>1</owl:minCardinality>
</owl:Restriction></owl:intersectionOf>
</owl:Class>
Parent = Person with at least one child

138 22 January 2008
OWL Axioms

139 22 January 2008
SPARQL
• RDF Query Language• Triples with unbound variables
• Protocol• HTTP binding• SOAP binding
• XML Results Format• Easy to transform (XSLT, XQuery)

140 22 January 2008
Why Ontologies?• Enable formalisation of user preferences
• Common underlying, interoperable representation• Public vocabulary agreed & shared between different systems • Better content matching & sharing across applications
• User interests can be matched to content meaning • Using conceptual reasoning
• Richer, more precise, less ambiguous than keyword-based• Provides adequate grounding for hierarchical representation
• coarse to fine-grained user interests
• Formal, computer processable meaning on the concepts

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Semantic User Profiles
142 22 January 2008
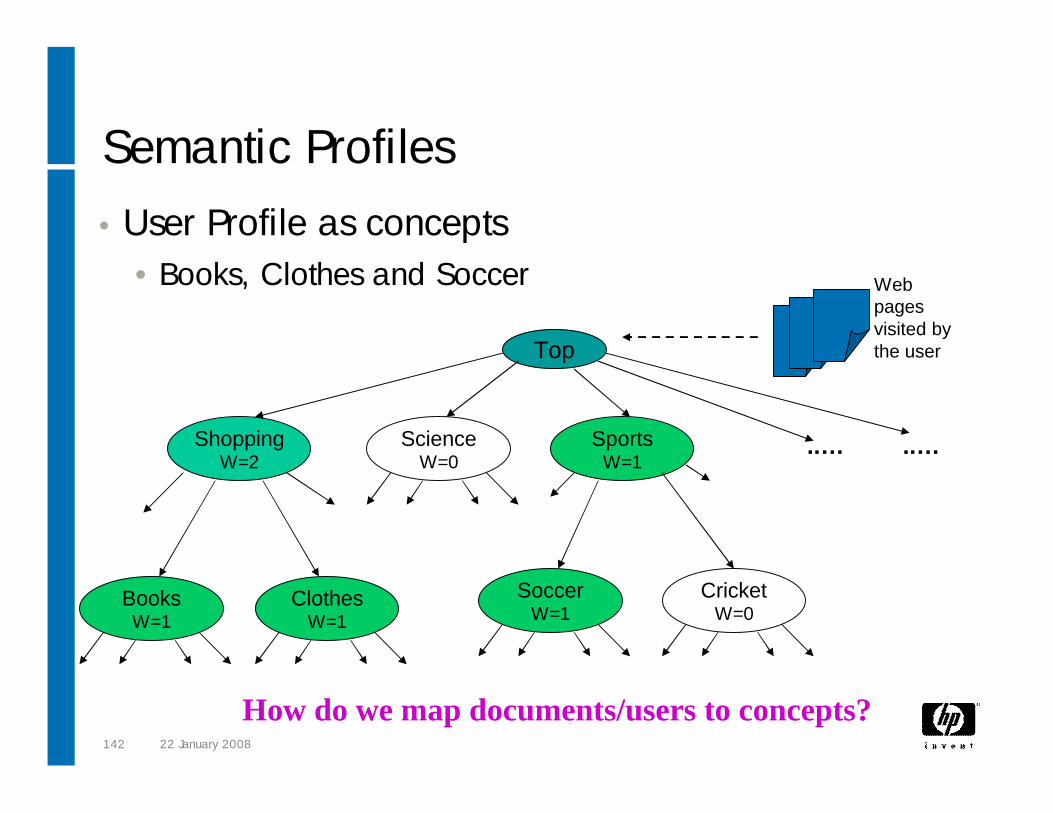
Semantic Profiles• User Profile as concepts
•Books, Clothes and Soccer
Top
..… ..…ShoppingW=2
SportsW=1
ScienceW=0
Web pages visited by the user
BooksW=1
ClothesW=1
SoccerW=1
CricketW=0
How do we map documents/users to concepts?

143 22 January 2008
Building concept profiles based on ODP
ODP categories + documents
Training ODP classifier
User web pages
ODP classifier
ODP concepts
Add to profile
Step 1: Build ODP classifier for selected ODP categories
Step 2: Use user data and ODP classifier to build the user profile
The Machine Learning Approach

144 22 January 2008
Topic Hierarchy from ODP / DMOZ

145 22 January 2008
Item: “Sony to slash PlayStation3 price”Term vector Representation: <sony:1>,<slash:1>, <playstation3:1>,<price:1>
Item: “Jittery Sony Knocks $100 Off PS3 Price Tag”Term vector Representation: <jittery:1>, <sony:1>, <knocks:1> <ps3:1>,<price:1>, <tag:1>
Index of Wikipedia dump
query
Sony to slash PlayStation3 price
Additional features: titles of the retrieved articles
1. PlayStation Network Platform2. PlayStation 23. Ducks demo4. PlayStation 35. PlayStation6. Ken Kutaragi7. PlayStation Portable8. Console manufacturer9. Sony Group10. Crystal Dynamics11. PlayStation 3 accessories12. …13. …
Using Wikipedia to map documents to concepts
A Search Approach

146 22 January 2008
Profile: Words Vs Concepts
Text Retrieval ConferenceHTML elementBank of AmericaGoogle searchICICI BankIDBI BankBank fraudArtificial neural networkWeb crawlerWeb designDebit cardExtensible Markup LanguageHewlett-PackardMicrosoftXHTMLDemand account
SearchHomeHelpNewsPrivacyGoogleTermsNewPageUseWebViewResultsInformationAccount
Wikipedia Based user profileTF * IDF based user profile

147 22 January 2008
Semantic Profiles• Vector of weights – representing the intensity of user
interest for each concept (-1 to 1)• Content also described by a set of weighted concepts
(0 to 1)
• Concept Profiles: Can express fine grained interests • Interest in atheletes who have won a gold medal• Interest in IT companies which have acquired atleast 3
companies in the last one year•Only movies with either Amitabh or Sharukh

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Ontology-based Profile Spreading

149 22 January 2008
Profile Expansion• Use inference mechanism to enhance personalisation
•Synonym expansion• Interest in multiple subclasses implies broader interest•Transitive closure (locatedIn, subtopic)• Interest in superclass leads to potential interest in subclass•Guess changing interest over time

150 22 January 2008
Constrained Spreading
Machine Learning
NeuralNetworks
Artificial Intelligence

151 22 January 2008
Constrained Spreading Activation
• Cannot take ‘all’ related data• Commonly used SA models
•Distance Constraint•Fan-out Constraint•Path Constraints
• App dependent inference rules• Type of relationship• Preferential paths
•Activation Constraint • Threshold function at each single node level

152 22 January 2008
Learning preferences using semantic links
Two main ways of updating Concept History Stack1. Interest Assumption Completion
• Add more potential user interests • Based on Hierarchical relationships
• Threshold on value of pseudo-occurrence for insertion• Nocc (C supertype) = γ * Nocc (C subtype)
where γ < 1 is determined empherically
• Based on Semantic relationships• All related concepts such that ∃ prop p, p (C, C related)• Pseudo-occurrence Nocc (Crelated) = αi* Nocc (C)

153 22 January 2008
Learning preferences using semantic links (contd)
2. Preference update by expansion• Re-weighting over time
• Wnew (Crelated) = Wold (Crelated) + βi * Wnew(C)• βI – Semantic Factor that depends on the level of semantic proximity
• Directly part of definition (Tbox)• Related through inferred transitive relation (# such links matter)
• Notion of Semantic distance

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Semantic Similarity

155 22 January 2008
Similarity/Matching•Cosine similarity
•U represents user preference•D represents content object •Dimension: #concepts in the ontology
DU
DU
DU
DUDUsimilarityii
ii ×=
×
•==
∑∑∑
cos),(22
22
(U ,D)

156 22 January 2008
Semantic distance d(x,y,c)• Semantic distance between 2 nodes x and y is defined
with respect to a concept, c• Example: a black cat and an orange cat
• very similar as instances of the category Animal, since their common catlike properties would be the most significant for distinguishing them from other kinds of animals.
• But in the category Cat, they would share their catlike properties with all the other kinds of cats, and the difference in color would be more significant.
• In the category BlackEntity, color would be the most relevant property, and the black cat would be closer to a crow or a lump of coal than to the orange cat.

157 22 January 2008
Semantic Similarity
Mtrl: MaterialAccm: Accompaniment

158 22 January 2008
Using Wordnet (hypernyms)

159 22 January 2008
Match all nodes

160 22 January 2008
Similarity Formula

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Looking Ahead

162 22 January 2008
Contextual Personalisation• Finer, qualitative, context sensitive activation of
user pref• Notion of a Semantic Runtime Context
•Representation: Vector of concept weights
• Fuzzy semantic intersection between user preferences and runtime context•Using Constrained spreading activation

163 22 January 2008
Semantic Social Networking• Identify hidden links between users
•Similarity between user preferences
• Collaborative Recommender systems•Use of Global Preferences not correct•Partial & Strong Similarities are very useful•Eg: Coinciding interest in cinema but drastically different
in sports

164 22 January 2008
Semantic Social Networks

165 22 January 2008
Microformats
http://microformats.org
• Microformats are small bits of HTML that represent things like people, events, tags, etc. in web pages. • Building blocks that enable users to own, control, move, and share their data on the Web. • Microformats enable
• publishing of higher fidelity information on the Web,• the fastest and simplest way to support feeds and APIs for your website.
GeohResumeadr
MetadataSocial linksOutlineLicensingtags

166 22 January 2008

167 22 January 2008
eRDF• A subset of RDF embedded into XHTML or HTML by using
common idioms and attributes. • No new elements or attributes have been invented and the
usages of the HTML attributes are within normal bounds. • This scheme is designed to work with CSS and other HTML
support technologies. • HTML Embeddable RDF. • all HTML Embeddable RDF is valid RDF, not all RDF is
Embeddable RDF

168 22 January 2008
GRDDL• Gleaning Resource Descriptions from Dialects of
Languages• Obtaining RDF data from XHTML pages• Explicitly associated transformation algorithms
(XSLT)

169 22 January 2008
Acknowledgements• Self-tuning Personalized Information Retrieval in an
Ontology-Based Framework, Pablo Castells, Miriam Fernández, David Vallet, et al, OTM Workshop 2005
• An Approach for Semantic Search by Matching RDF Graphs, Haiping Zhu, Jiwei Zhong, Jianming Li and Yong Yu
• Semantic Web Tutorials

170 22 January 2008
Concluding Remarks• Personalization: An upcoming area of technology• Personalization aims at faster access to information to improve
user productivity• Server-side Vs Client-side personalization• Technologies
• Machine Learning techniques• Semantic Web• New Markup Languages
• Challenges• Understanding the user behaviour, intentions, likes, …• Relating human edited content to the profile

© 2006 Hewlett-Packard Development Company, L.P.The information contained herein is subject to change without notice
Thank youQuestions?
Recommended
















![[ACM-ICPC] 0 - ACM-ICPC](https://img.dokumen.tips/doc/110x75/555603ead8b42a3f168b4838/acm-icpc-0-acm-icpc.jpg)
