
PDQCollections: A Data-Parallel Programming Model andLibrary for Associative Containers
Maneesh Varshney Vishwa Goudar
Technical Report #130004Computer Science Department
University of California, Los AngelesApril, 2013
ABSTRACTAssociative containers are content-addressable data struc-tures, such as maps, ordered maps, multimaps, sets etc.,that are wide employed in a variety of computational prob-lems. In this paper, we explore a parallel programmingparadigm for data-centric computations involving associa-tive data. We present PDQCollections - a novel set of datastructures, coupled with a computation model (which werefer to as the Split-Replicate-Merge model) - that can effi-ciently exploit parallelism in multi-core as well distributedenvironments, for in-memory as well as large datasets. Thedistinguishing characteristics of our programming model arethe design of data structure that inherently encapsulate par-allelism and the computation model that transforms theproblem of parallelization to that of defining addition oper-ator for value data types. The PDQ design offers fundamen-tal benefits over traditional data structures: with memory-bound workloads, PDQ avoids locks and other forms of syn-chronization, and is able to significantly outperform lock-based data structures; with larger disk-bound workloads,PDQ does not use caches and avoids random disk access,and thus significantly outperform traditional disk-backedstructures; and with distributed workloads, PDQ accessesremote data resources sequentially and only once, and is ableto significantly outperform distributed data structures. Wehighlighted the distinguishing capabilities of PDQ librarywith several applications drawn from a variety of fields inComputer Science, including machine learning, data mining,graph processing, relational processing of structured dataand incremental processing of log data.
1. INTRODUCTIONAssociative containers, also commonly referred to as hashes,
hash tables, dictionaries or maps, are a cornerstone of pro-gramming template libraries. They provide standardized,robust and easy-to-use mechanisms to efficiently store andaccess key-value mappings. In this paper, we explore data-centric programming problems where either the input orthe output or both are associative containers. Such com-putations are commonly employed in the fields of docu-ment processing, data mining, data analytics and machinelearning, statistical analysis, log analysis, natural languageprocessing, indexing and so on. In particular, we seek adata-parallel programming framework for associative data,where the parallelism can scale from multi-core to distributedenvironments, the data can scale from in-memory to disk-backed to distributed storage and the programming paradigm
is as close as possible to the natural sequential programmingpatterns.
The problems of data parallelism with associative contain-ers are unlike from the index-based data structures such asthe arrays and matrices. The most familiar parallel pro-gramming paradigm for the latter is the parallel for loop,as exemplified in OpenMP, Intel’s Thread Building Blocks(TBB) and Microsoft’s .NET Task Parallel Library (TPL).In this model, the index range of the for loop is partitionedand each partition of the range is assigned to a separatethread. However, this paradigm requires that the inputto the computation (that has to be partitioned for paral-lelization) must be index-addressable. Secondly, as the out-puts generated by each thread must be protected againstconcurrent modifications, each thread must write data innon-overlapping memory regions or use critical sections orconcurrent-safe containers. Maps are content-addressable,and consequently, can neither serve as input or output in aparallel for computation. Furthermore, in the data-parallelprogramming context, the synchronization locks are con-tested often leading to a significant locking overhead, whichwe confirmed in our benchmarks. Finally, these libraries,are typically meant for shared-memory and memory boundworkloads and offer little support or perform poorly withdistributed systems and persistent data stores.
In our study of data-parallel programming paradigms, wedid not discover any library or framework that can: (a) oper-ate on associative containers, (b) execute in shared memorymulti-threaded as well as distributed contexts, (c) supportdata size that scales from in-memory to disk-backed, and (d)have parallelization constructs that are as close as possibleto the natural sequential and object-oriented style of pro-gramming. Towards this last point, we note that the widelyacclaimed Map-Reduce model, owing to the functional na-ture of the programming framework, does not provide to theprogrammers the familiar Abstract Data Type of associativecontainers.
In this paper, we present PDQCollections 1 − a novel setof data structures, coupled with a computation model, forexploiting data parallelism in associative data sets. PDQ-Collections is a comprehensive library of collection classesthat implement the native associative container interfaces:map, multimap, ordered map, ordered multimap, set, sortedset and others. We have also proposed a computation model,which we refer to as the Split-Replicate-Merge (SRM) model,that transparently and efficiently supports and exploits par-
1PDQ could stand for Processes Data Quickly

allelism in multi-core as well as distributed environments,over the data scales that range from memory-bound to disk-backed. We have shown an equivalence between the SRMand the map-reduce (MR) model by mutual reducibility,that is, any problem that can be solved by one model canbe solved by another.
The distinguishing characteristic of our programming modelis encapsulating the parallelism within the data struc-ture implementations (the PDQ Collections classes) ratherthan the program code. Object oriented programming en-courages encapsulating the distinguishing characteristics withinthe implementation of the objects, while providing famil-iar interfaces to the programmer. For example, BerkeleyDB’s StoredMap abstracts the knowledge that the data isbacked on disk, while providing the familiar Map interface;GUI libraries hide the platform specific characteristics be-hind the implementation, while providing the same widgetinterface; and the Remote Method Invocations hide the factthat the objects are remotely located. However, traditionalapproaches for data parallel programming have instead re-lied on modifying the computation code, either by extendingthe grammar of a language (e.g. the parallel for loop), orenforcing alternate paradigms (e.g. functional programmingin Map Reduce).
By encapsulating parallelism within the data structures,the programming model is able to cleanly separate out thecode for actual computation and the code for paralleliza-tion. Consider the analogy of Semaphores vs. Monitors:semaphores require introducing the logic of concurrency withinthe code, as opposed to monitors where all logic is capturedseparately within the monitor object. Similarly, with ourprogramming model, the logic of parallelism is not inter-spersed within the code, rather it is expressed separately.As a concrete example, we shall discuss the Frequent Pat-tern (FP) growth algorithm [1] in Section 5.2, where theinput data is processed to generate a FP tree data struc-ture. The traditional methods of parallelism would requiremodifying this tree-generation code by embedding parallelconstructs within the code. With our model, the program-mer only needs to separately define how to “add” two trees.We believe, our design choice lead to a cleaner separationof functionality, resulting in a flexible and robust systemarchitecture.
The SRM computation model employs the divide-and-conquer strategy for parallelization. We have proposed anovel shared-nothing strategy for merging associative con-tainers, which obviates the need for any explicit or underly-ing synchronization, concurrent access or transactional pro-cessing. By avoiding locking overheads, PDQ containerssignificantly outperform the locking-based data structures,such as ConcurrentMaps. The same strategy, when appliedto disk-bound workloads, is a cache-free design and ensuresthat data is always read and written to disk sequentially. Byavoiding cache-miss penalties and random disk seek over-heads, PDQ containers significantly outperform the tradi-tional disk-backed data structures, such as BerkeleyDB.
The PDQ collection classes are versatile in managing dataover a wide range of scale. Initially, the data is stored in-memory, but as the size of the container grows, the datais transparently and automatically spilled over to the disk,where it is stored in a format most efficient for further pro-cessing. The disk-backed form of the container objects havethe capability to store data on multiple disks, if present, to
improve the disk I/O speeds. They have a distributed im-plementation as well, where the data can be flexibly storedat common location (e.g. SAN, NFS) or in a distributedstorage.
The rest of the paper is organized as follows: in Section 2we provide a formal description of programming model andin Section 3 we discuss our implementation. We conduct acomparative design performance analysis study in Section 4with concurrent data structures (for memory bound compu-
tation), BerkeleyDBaAZs StoredMap (for disk-backed com-putation) and Hazelcast (for distributed computation) tohighlight the salient characteristics of our programming modelthat explains how PDQ significantly outperforms these tra-ditional data structures. We illustrate several applicationsof our PDQ in different fields of Computer Science in Section5 and conclude in Section 6.
2. DESIGNIn this section, we provide a formal description of pro-
gramming model, including the data model, which formal-izes the problems that can be parallelized with our model,the Split-Replicate-Merge computation model, which describesthe strategy for parallelism, and the programming APIs. Wealso show an equivalence with the Map Reduce programmingmodel.
2.1 Data Model: Mergeable MapsThis section formalizes the data-centric problems that can
be parallelized using our model. We begin by defining anassociative container as a mapping function from key spaceK to value space V:
A : K→ V
Different variants of associative containers can be inter-preted by adapting the semantics of the mapping function.For example, the container is a multimap if the value spaceV is a set of collection of values, or a set if a Boolean space.Similarly, the container is an array if the key space K isa range of natural numbers, or a matrix if a set of tuples.Other complex containers, such as graphs, can similarly beinterpreted.
Next we define a computation as a function with inputin the domain I (which may be an associative container) toproduce as output an associative container A:
Cseq : I → A
We have explicitly formulated the computation to be asequential function. For the sake of simplicity, we have alsoassumed only one input and one output for this computa-tion. The extension to the general case is trivial, and willbe discussed later.
Our objective is to develop a data-parallel programmingparadigm for this computation that simultaneously satisfiesthe following requirements:
1. the computation can be parallelized and scaled acrossmultiple cores and processors, in shared-memory con-current as well as distributed processing contexts.
2. the parallel computation can handle input and outputdata that scales from memory-bound to disk-backed todistributed storage.

3. both forms of scaling (processing and data) can beachieved by using the unmodified sequential form ofthe computation.
We claim that the above requirements can be satisfied forthe class of computation problems with inherent parallelismthat can be formulated as follows:
If I1 ⊂ I, and I2 ⊂ I, such that I1 ∩ I2 = φ, and C(I1)→A1, C(I2)→ A2. Then the following must be equivalent:
C(I1 ∪ I2)⇐⇒ A1 ]merge A2
Where the merge operator ]merge is defined as:
(A1 ]merge A2)(k) =
A1(k) if k ∈ A1, k /∈ A2
A2(k) if k /∈ A1, k ∈ A2
A1(k)⊕A2(k) otherwise
Here, ⊕ is some user-defined operator. It is required, how-ever, that this “add” operator is both commutative and as-sociative.
Intuitively, the above formulation specifies that the inher-ent parallelism in the computation is such that if partialresults were obtained by processing partial inputs, then theresult of the combined inputs can be produced by mergingthe partial outputs.
We shall later prove that this formulation of parallelism isequivalent to the map-reduce programming model, that is,any problem that can be solved by map-reduce can be for-mulated in this manner. Let us now review some examplesto illustrate this model of parallelism in action.
Word Count : Given a document, find the number of timeseach word appeared in the document. The input is a listof words, and the output is a simple map of string to inte-gers. This problem can be parallelized since we can partitionthe input list into sublists, execute the word count programseparately on each sublist, and merge the generated outputmaps by defining ⊕ as integer addition operator.
Inverted Index : Given a map of keys to a list of words (theinput), generate a map of words to the list of keys that theybelonged (the output). Although we have not yet discussedhow the maps are partitioned, for now we imagine that thekey space is partitioned and the sub-maps are created withkey-value mappings for each partition, and the program toinvert indices is executed separately on each sub-map. Ifwe define ⊕ as the list concatenation operator, the mergedoutput will indeed be the inverted index of the original map.
Finding Average: Find the average from the list of num-bers. Since the average of averages is not the average, weneed to define a custom data type with two fields, sum andcount. We also define the ⊕ operator for this data typethat adds the two fields. The output of the computationis a “singleton” container, which contains only one element.The computation, then, takes as input a sublist of numbersand computes the result into this data type. These partialresults are ‘added’ together to produce the final result.
2.2 Computation Model: Split, Replicate,Merge
In this section we describe our parallel computation model,called the Split-Replicate-Merge model, to exploit paral-lelism for the class of problems identified in the previoussection. As previously, for the sake of simplicity we assumethe computation with single input and single output. Themodel executes as follows: the input is first splitted into M
partitions. The number of splits is atleast equal to the num-ber of processing units available, although it can be greaterif it is desired that each partition should be of some manage-able size (for example, if each partition has to be processedentirely within memory). Next, the output data structureis replicated M times. Each replication is an initially emptydata structure of same type as the output data containertype. These splits and replicas are paired together, and Minstances of computation are executed (one for each pair)concurrently. Finally, the replicas, which now contain theresults of the computation from the respective splits, aremerged to produce the final output. The following psuedocode outlines this process:
PDQRun(Cseq , input , output ) {SPLIT( input ) → {spi , 1 ≤ i ≤M }REPLICATE( output ) → {rpi , 1 ≤ i ≤M }paral le l for ( i : 1 to M ) do
Cseq (spi , rpi )end
output ←⊎M
i=1 rpi // Merge}
Listing 1: The Split-Replicate-Merge ComputationModel
Note that there is a single synchronization point in theentire model, which is the implied barrier at the end of theparallel for loop.
This model is easily extended to support multiple inputand output parameters, as well as“shared”parameters. Withmultiple inputs, the implementation must ensure that eachinput generates equal number of splits, and the respectivesplit from each input share the same keyspace. The multi-ple outputs are replicated, and later merged, independent ofeach other. The shared arguments are neither splitted norreplicated; the same copy of the object is provided to all thecomputation instances.
In section 3, we shall discuss efficient implementations forsplitting and merging. We show that associative containerscan be splitted in O(1) time, and the replicas can be mergedin parallel as well. We shall also see how this computationmodel can be easily adapted to handle volumes of data andto operate in distribute execution mode.
2.3 Programming ModelWhereas the computation model described previously is
meant to be transparent to the programmers, it is the pro-gramming model, described herein, that is visible to the pro-grammers. This model describes how the computation mustbe coded for parallelization.
We describe the programming model by means of theWord Count program, outlined in Listing 2. Although theexample shown is coded in Java SE 6, the model can beapplied to any programming language that supports Ob-ject Polymorphism and function references, either as clo-sures, function pointers or functors, and, of course, a multi-threaded environment.
1 @Para l l e l (name=”wordcount ”)2 public void wordcount (3 @ArgIn java . i o . Fi leReader input ,4 @ArgOut java . u t i l .Map<Str ing , Integer> output ) {5 BufferedReader reader = new BufferedReader ( input ) ;6 St r ing l i n e ;7 for ( ( l i n e = reader . readLine ( ) ) != null ) {

8 for ( S t r ing word : l i n e . s p l i t ( ” ” ) )9 i f ( ! output . containsKey (word ) )
10 output . put (word , 1 ) ;11 else12 output . put (word , output . get (word ) + 1 ) ;13 }14 }1516 public stat ic void main ( St r ing [ ] args ) {17 PDQ. se tCon f i g ( args ) ;18 Fi leReader input = new PDQFileReader ( f i l ename ) ;19 Map<Str ing , Integer> output =20 new PDQMap<Str ing , Integer >( IntegerAdder ) ;2122 PDQ. run ( this , ”wordcount ” , input , output ) ;23 }
Listing 2: Word count using PDQCollections
The first segment of the code (lines 1 through 14) is theactual computation. Notice that the method arguments arethe native data types, and the method body is entirely se-quential. The @ArgIn and @ArgOut Java annotations indi-cate that the arguments are split of the input and replicationof output, respectively. The @Parallel annotation merelyserves as a naming marker for the method, which we utilizeto extract the method reference (java.lang.reflect.Method)using the Java reflection APIs. This is only a user-friendlyway to name a method, other techniques such as functionobjects would have sufficed as well.
Next, we instantiate the objects for the computation - aFileReader as input, and a Map of String to Integer as out-put. Here, instead of using the Java native classes, we createthe input/output objects from the counterpart classes pro-vided by the PDQCollections library. The library includesthe typical container data types: PDQMap, PDQMultimap,PDQSortedMap, PDQSortedMultimap, PDQSet, PDQSort-edSet, PDQList etc that implement the respective Java in-terfaces; as well as File I/O classes, including PDQFileReaderand PDQFileInputStream that subclass the respective Javaclasses. The input object is instantiated at line 18, while theoutput object in lines 19-20. The PDQMap is also providedwith the ⊕ operator, in this case an Integer adder.
Observe this salient feature of our programming model: toparallelize a sequential program, the programmer only needsto replace the programming language’s native input/outputcontainer, or File I/O, classes with the counterpart classesfrom the PDQ library; while the actual computation codeitself remains unmodified.
The parallel execution is invoked in line 22 where the ref-erence to the computation method and the input/outputobjects are passed to the PDQ library. This library callexecutes the Split-Replicate-Merge computation on the pro-vided arguments. The behavior of the computation modelexecution can be controlled by the configuration parameters,shown in line 17.
2.4 Equivalence with the Map Reduce ModelMap-Reduce is a widely acclaimed programming model for
processing large data sets. This is a functional-style modelthat processes data in two stages of map and reduce phases.We show this model is equivalent to the SRM model byproving that the two models are reducible to each other.
Consider an arbitrary problem that can be parallelizedwith the map-reduce model. There exists, then, a map func-tion that transforms the key-value mappings of the input
into an intermediate list of mappings in a different domain:
MAP : (k1, v1)→ list(k2, v2)
This intermediate output is processed to collect all valuesfor a given key together, and the key space is sorted. Thisserves as the input to the reduce function, which generatesthe final result:
REDUCE : (k2, list(v2))→ list(k3, v3)
This problem can be formulated by the Split-Replicate-Merge model in two execution steps, as shown in Listing3. In the first step, the input map is processed to producea SortedMultimap of intermediate values, which is furtherprocessed in the second step to generate the output result.
@Para l l e l (name=”step1 ”)void step1 (Map<K1 , V1> input ,
SortedMultimap<K2 , V2> i n t e rmed ia te ) {for (k1 , v1 in input )
List<K2 , V2> l i s t = MAP(k1 , v1 ) ;for (k2 , v2 in l i s t )
in t e rmed ia te . add (k2 , v2 ) ;}
@Para l l e l (name=”step2 ”)void step2 ( SortedMultimap<K2 , V2> intermediate ,
SortedMultimap<K3 , V3> output ) {for (k2 , l i s t v2 in i n t e rmed ia te )
List<K3 , V3> l i s t = REDUCE(k2 , l i s t v2 ) ;for (k3 , v3 in l i s t )
output . add (k3 , v3 ) ;}
void main (Map<K1 , V1> o r i g i n a l I npu t ) {Map<K1 , V1> input =
new PDQMap<K1 , V1>( o r i g i n a l I npu t ) ;SortedMultimap<K2 , V2> i n t e rmed ia te =
new PDQSortedMultimap<K2 , V2 >();SortedMultimap<K3 , V3> output =
new PDQSortedMultimap<K3 , V3 >();
PDQ. run ( this , ”step1 ” , input , in t e rmed ia te ) ;PDQ. run ( this , ”step2 ” , intermediate , output ) ;
}
Listing 3: Reducing SRM model to Map-Reduce
Conversely, consider an arbitrary problem that can for-mulated with our data and computation model, that is, thefollowing method is defined:
SRM(Cseq fn , Map<K1 , V1> input , Map<K2 , V2> output )
This problem can be reduced to the map-reduce model asfollows:
class Mapper {Map<K1 , V1> input ;void map(K1 k , V1 v ) {
input . put (k , v ) ;}
void f i n a l i z e ( ) {Map<K2 , V2> part ia lOutput = REPLICATE( output ) ;fn ( input , part ia lOutput ) ;for (k2 , v2 in part ia lOutput ) EMIT(k2 , v2 )
}}
class Reducer {void reduce (K2 k2 , L i s t<V2> l i s t v2 ) {
V2 sum = fo l d (⊕ , l i s t v2 ) ;EMIT(k2 , sum ) ;
}}
Listing 4: Reducing Map-Reduce model to SRM

In the mapper class, the key-values mappings are first col-lected into a Map. The output object is replicated, and thecomputation is invoked on these two objects. The mappingsfrom the replica (which served as the output container forthe chunk of input provided to this Mapper) are emittedto the reducer. At the reducer, the list of values for a keyare aggregated together using the ⊕ operator, which is thenemitted for the given key.
We have thus shown that that two programming mod-els can be emulated with each other and, consequently, areequivalent.
2.5 Related WorkPiccolo [2] is a data-centric programming model with a
similar objective of parallel and distributed computing usingassociative containers. The system ensures execution local-ity by partitioning the input across machines with a user-specified partitioning function. While each process process-ing its partition locally to produce the corresponding output,it also has access to global state. In other words, it can at-tain a globally consistent view of the value corresponding toan output key. Piccolo achieves this by introducing a user-specified accumulation function akin to our add operator.When called by the user, this operator can “accumulate” thevalues for a specific key across all processes. This differen-tiates the PDQ programming model from Piccolo’s. WhilePiccolo offers fine-grained access to global state, it requiresuser control over the merge procedure. On the other hand,PDQ executes the merge operation transparent to the user.PDQ also reduces the merge overhead partitioning the out-put across a SuperMap. Finally, in contrast to Piccolo thatonly supports, memory-constrained outputs, PDQ transpar-ently allows in-memory, out-of-core and distributed process-ing and output data structures.
3. IMPLEMENTATIONOur primary goal for implementation is efficient process-
ing of data by maximizing the CPU utilization as well asby maximizing the disk I/O. Our implementation targetsdata sizes up to few terabytes, and optimized for multi-coresystems and small to medium sized clusters. Concerns suchas large scale cluster management, fault tolerance are notaddressed. Our secondary goal is transparent parallelism,that is, the computation can be coded using programminglanguage’s native data type and sequential style of program-ming, and does not require any modifications to languagegrammar. In the following, we describe our data structuresthat can transparently switch from memory bound, to disk-backed and distributed operational behavior. We have im-plemented our programming model as a library in Java SE6.
3.1 Data StructuresThe PDQCollections library provides a suite of data struc-
ture implementations that are meant to be drop-in replace-ment for their counterpart native implementations. Theseinclude the typical container data types that implement theMap, Multimap, SortedMap, SortedMultimap, Set, Sorted-Set, List and other interfaces, as well as File I/O classes,that inherit the FileReader and FileInputStream classes.
Recall the computation model outlined in Listing 1, wherewe discussed that the input containers are partitioned intosplits, and that the output containers are first replicated,
and later these replicas are merged back. This behavioris enforced by requiring the input and output containersto implement the Splittable and Mergeable interfaces, re-spectively. The signatures of these two interfaces are shownbelow:
interface Sp l i t t a b l e {I t e r a t o r<Object> s p l i t ( ) ;
}
interface Mergeable {Object r e p l i c a t e ( ) ;void merge ( Object [ ] p a r t i a l s ) ;
}
The splits of an input container and the replicas of an out-put container are objects of the same abstract data type asthe respective input and output containers. In addition, thereplicated objects are in-memory data structures. The col-lections classes support both interfaces, while the file readerclasses only implement the Splittable interface.
3.1.1 PDQ Collections ClassesRecall that an associative container can be viewed as a
mapping from key space to value space: A : K → V. If theexecution environment has N threads, then the key spaceis exhaustively divided into N non-overlapping subspacesand a delegate associative container is created for each ofthese key subspaces. In other words, the PDQ container isa wrapper around N associative containers, each managinga portion of the keyspace, as defined below:
APDQ : fpdq(k) =
f1assoc(k) if k ∈ K1
f2assoc(k) if k ∈ K2
..
fNassoc(k) if k ∈ KN
where K1, K2 ... KN are the N divisions of the key space,and f1
assoc, f2assoc, ... fN
assoc are the N delegates. As anexample, in an execution environment with four threads, aPDQMap wraps four java.util.HashMap delegates. For anoperation for a key k (for example, get(), put(), contains(),etc), the key subspace Ki is identified that contains thiskey, and the operation is applied to the associated delegatef iassoc.One simple strategy for partitioning the key space is by
partitioning the hash code range of the keys, that is, a keyk will belong to subspace hash(k) modulo N . Although,it must be ensured that this hashing function is differentfrom functions that may be used internally by the associativecontainer (for example, HashMap).
There are several benefits to this wrapped delegates de-sign. First, the Splittable interface is trivially implemented:each delegates is a split! Notice that our approach is not tosplit the container after it is populated, rather to create thesplits beforehand and populate them incrementally. This isan easier as well as an essentially zero-cost operation.
Secondly, this design allows for merging of the partialresults in parallel. Each PDQ Collection implements theMergeable interface, where the replicas themselves are wrappedcollections of delegates. That is, for an execution environ-ment with N threads, the PDQ collection wraps N dele-gates, as shown below:
APDQ := {D1, D2, ..., DN}
where Di is the ith delegate of the PDQ collection. This

collection object will generate N replications, which them-selves wraps N containers, as shown below:
R1 := {DR11 , DR1
2 , . . . DR1N }
R2 := {DR21 , DR2
2 , . . . DR2N }
. . .
RN := {DRN1 , DRN
2 , . . . DRNN }
where Ri is the ith replication, and DRij is its jth delegate.
Now the merge operation can be applied in parallel by shuf-fling the replication delegates and grouping them accordingto the key subspace they manage. That is:
MERGE (APDQ , [R1 , R2 . . . RN ] ) :p a r a l l e l f o r ( i : 1 to N) :
Di ← DR1i ] DR2
i . . . ] DRNi
Similar parallelization benefits are achieved when the con-tainer data is stored on disk, as we shall see in Section 3.3. Inthis case, the various activities such as sorting, serializationand writing to disk can be applied in parallel.
3.1.2 PDQ File I/O ClassesThe PDQ library provides replacements for the java.io file
I/O classes. In particular, the PDQFileReader and PDQ-FileInputStream classes support reading characters and bytes,respectively, from files. Both implement the Splittable inter-face, and, therefore, can act as inputs to the computation.Similarly, the PDQFileWriter and PDQFileOutputStreamclasses support writing characters and bytes, respectively,and implement the Mergeable interface.
The primary consideration in reading files is blocksize −the size of the chunk of input that is processed by a sin-gle thread. The input file is partitioned into chunks of sizeblocksize each, and these chunks serve as input splits to thecomputation. If the file contains variable length records, thesplits coincide with record boundaries. Recall our implemen-tation goal which states that the computation for each inputsplit must happen within memory. It is, therefore, necessaryto ensure that the blocksize must not exceed the limit wherethe output generated (for that split) cannot be entirely con-tained within memory. Since the exact limit is dependent onthe processing environment, this parameter is user-defined.
The PDQ file output classes implement the Mergeable in-terface by generating replicas that are standard java.io out-put classes for files where the filename is appended with apart identifier (e.g., filename.part0000).
3.2 Thread Pool Execution ModeThis section describes the PDQ library’s shared-memory
parallel execution mode of the computation. As the nameimplies, the concurrency is achieved by thread pools, andwe make use of the java.util.concurrent.ThreadPoolExecutorservice for the thread pool creation and management.
This execution mode is applicable when the output of thecomputation can be contained within memory. For a poolof N threads, the input is first split into N partitions. If theinput is a file, then the blocksize is automatically computedto create N chunks. The output containers are replicatedN times as well, and the N instances of computations areassigned to the thread pool. At this point, the main threadinvokes the thread pool and waits until all threads within thepool complete, which can be viewed as an implied barrier forthe main thread. Subsequently, the main thread shuffles thedelegates of the replicas for merging, in accordance with the
f, input, output = [Da, Db]
loop [There are more splits] Get at most 2 splits
Thread Pool Execution (f, input, output)
[Externalize output?]
Db
<<Sort>>
Da
<<Serialize & Write to File>>
<<External Merge>>
opt
Implied Barrier
ref
Main Thread #1 Thread #2
Figure 1: Sequence diagram for the disk-backed ex-ecution model for a pool of 2 threads
process described previously, and assign these merge tasksto the thread pool. There is a second implied barrier, at theend of which the partial results are merged back into theoutput containers.
As the cost of splitting, replicating and shuffling/distribut-ing delegates is essentially negligible, this execution modeeffectively utilizes all the processing cores throughout theprogram execution.
3.3 Disk-backed ComputationThe previous execution mode is extended to handle cases
when the output of the computation is too large to fit inmemory, thus necessitating the need to store the output dataon to the disk. In the following description, we refer to theprocess of storing the output disk on disk as externalization.
The first difference from the memory-bound executionmode is that the number of the input splits, M , can begreater than the number of processing cores, N . In this casethe computation unfolds in multiple iterations. In the firstiteration, the first N splits are processed, in accordance withthe thread-pool execution mode described previously; in thesecond iteration, the next N splits are processed similarlyand the results from this iteration are merged back into thepreviously accumulated results. This process continues untilall M splits are processed, at the end of which the accumu-lated result (obtained by merging partial results from eachiteration) will be the final output of the computation.
At the some point, the accumulated results will be largeenough to overflow the memory. Before reaching this state,we enforce externalization of memory contents to the disk,thus freeing up memory for further processing. At the end ofeach iteration, the library determines whether the memorycontents must be externalized to the disk. In our implemen-tation, we check the currently available memory in JVM (viathe freeMemory() method of the java.lang.Runtime class)and decide to externalize if it falls below a threshold.
When externalizing the output container, each of the del-egates of the output container are externalized in parallel.

The process involves sorting the key space of the delegatecontainer, if it was not already sorted, and serializing thekey-value pairs to a flat file. We use the Java’s native serial-ization framework for externalizing data. At this end of thisexternalization step there will be N files on disk, which con-tains the memory contents of the N delegates respectively,with each file written in parallel. The next externalizationstep will write data into a new set of N files.
When all the M splits are processed, these files are mergedinto a Mapfile. A mapfile is a file that stores a sorted list ofkey-value mappings along with an index (typically kept inmemory) that maps a subset of the keys to the offset withinthe file where they are located. To retrieve the value for akey, the index is consulted to locate the offset of the closestkey, and then the file is read sequentially from that offsetuntil the said key is located. Since the externalized filesare already sorted on disk, the O(N) disk merge algorithmis used to merge them into the mapfiles. These mapfiles,subsequently, serve as the delegates for the output container.
Figure 1 illustrates this execution mode as a sequence di-agram. The outer loop in the diagram represents the iter-ations, and the opt block represents the optional step ofexternalizing the delegates to disk.
Observe that the actual computation, at each iteration,is entirely memory bound. While the merged results maybe externalized to the disk, the output data is always withinmemory while the computation is being executed. This elim-inates any need for disk-based data structures, which aresubstantially more costly than the in-memory structures.This design also not employ any form of caching disk datawithin memory, and thus avoids caching relating scalabilityoverheads. Finally, the data is always read and written se-quentially from the files, which also eliminates random diskseek overheads.
If multiple hard drives are available, the disk I/O canbe further improved by storing the externalized files ontothese multiple disks. In the thread pool environment withN threads, each externalization step generates N files, andat the end of the computation, there are N delegate mapfilesfor the output container. These files can be spread across thehard drives, and given that the file I/O operations are par-allelized in our implementation, it follows that the data canbe read or written simultaneously from all the hard drives.
3.4 Distributed ModeIn this final section, we describe our implementation strat-
egy for distributed execution. As noted previously, our de-sign goal is catered towards small to medium sized clus-ters. The implementation follows a master-slave architec-ture, where the master executes the main application andrequests the workers to participate in the computation. Themain application jar file is added to the classpath of theworkers to ensure the visibility of the classes that define thecomputation.
When the main program, executing at the master node,invokes the computation via the PDQ.run(...) method (seeline 22 in Listing 2), the PDQ library contacts the workerdaemon processes and prepares for the distributed execu-tion. The master first notifies to each worker their uniquerank, which is a number between 1 and total number of work-ers. The workers use the rank to determine the portions ofthe input that they are responsible for processing. Subse-quently, the master serializes and transmits over the wire
the computation method and its input/output arguments.At this point, the workers have sufficient information to be-gin processing their share of the input. Each worker executesindependently of others, and after processing its input, se-rializes and transmits the results back to the master. Themaster may choose to merge the results gathered from theworkers either locally (if the data is small enough), or em-ploy the slaves again for distributed merge.
A brief note on sharing the input and output data: insimple cases, the master and workers may exchange theentire data set over the wire. This simple approach doesnot require any cluster configuration, however, it is not themost efficient method of sharing data, for example, it addsthe serialization and deserialization overhead. Alternatively,the data may be stored on shared file system, for example,Network File System (NFS), or distributed file system, forexample, Hadoop Distributed File System (HDFS). In thiscase, only the reference to the file needs to be shared.
4. DESIGN ANALYSISIn this section, we compare the PDQ programming model
against representative data structures for the memory-bound,disk-bound and distributed computations. Our objective isto gain an insight into the fundamental nature of the PDQcomputation model and illustrate the impact of our designchoices towards overall performance of data-centric compu-tations. We are not interested in raw performance compar-isons between two systems, as those statistics vary widelybased on parameters of implementation, programming style,efficiency of the libraries used (e.g., threading, serialization,networking). Instead, we wish to expose those salient char-acteristics of our model that makes the PDQ library consis-tently outperform traditional designs, irrespective of actualimplementations under consideration.
The summary of our findings is as follows: with memory-bound workloads, the PDQ library avoids locks and anyother form of synchronization, and thus significantly scalesbetter with number of processing cores than the lock-baseddata structures, such as ConcurrentMap. For large disk-bound workloads, the PDQ library does not employ anyform of caching and always accesses the disk with sequentialread and write requests. In contrast, the disk-backed datastructures, such as BerkeleyDB and KyotoCabinet, are two-tiered with in-memory cache for the on-disk B-tree, wherethe efficacy of the cache diminishes with smaller cache ratio.By avoiding the cache miss penalties and random disk seekoverheads, the PDQ library significantly scales better withdata size. Finally, with distributed workloads, the PDQ li-brary accesses remote data resources sequentially and onlyonce, and is thus able to significantly outperform distributeddata structures.
Single-host experiments were conducted on a machine host-ing a dual hyper-threaded 6-core Intel Xeon 2.30GHz pro-cessor with 32GB of memory and a 500GB of disk. Themachine runs CentOS 6.3 with kernel version 2.6.32. Fordistributed experiments, we used a cluster of eight machines,each of which is comprised of two quad core Intel Xeon 2.33GHz processors with no hyper-threading, 8GB memory anda 200GB hard drive, with CentOS release 5.8 and 2.6.18 ker-nel. The cluster nodes are connected with infiniband switch-ing as well as 100 MBps ethernet. All machines have JavaHotspot 1.6 runtime available.

●
●
●
●●
●●
●●
●●
●
2 4 6 8 10 12
02
46
8
Number of threads
Spe
edup
Fac
tor
Figure 2: Scalability Performance with respect tosequential processing
4.1 Multi-Threaded Data StructuresWe begin our analysis with the thread pool execution
mode (section 3.2). “Term frequency” is one of the commonapplication of maps, which counts the number of occurrencesof each unique term in a document. An implementation,using the PDQ library, was discussed earlier in Listing 2,which we compare against the ConcurrentHashMap classfrom the java.util.concurrent package, as well as a criticalsection (using Java’s synchronized keyword) around a regu-lar java.util.HashMap. Our dataset comprised of a collectionof web documents containing a total of 300 million words,from a set of 5.2 million unique words [3]. We investigatehow efficiently these three implementations exploit varyinglevels of concurrency.
We measure the performance as the ratio of parallel to se-quential execution time (factor speedup), which is shown inFigure 2 for the three implementations, for varying num-ber of threads ranging from 1 through 12. Notice that,regardless of the type of data structure selected, each ofthe k threads processed only 1/k of the input data. Thisimplies that difference between the theoretic speedup fac-tor of k and the observed speedup can be attributed tothe overhead of maintaining consistency of the output data(although, there are other factors in play as well, such asgarbage collection, memory allocation, context switches etc,but we believe their contribution is relatively small). Fromthe figure, we observe that the concurrent and synchro-nized maps are constrained by their lock-based approachto data consistency. This locking overhead is significant andin fact lead to a runtime degradation in comparison to se-quential data processing for this benchmark problem. Incontrast, the divide-and-conquer approach of the PDQ li-brary offers an alternative mechanism to achieve data con-sistency, which we have shown to outperform locking-basedconsistency for data-centric computations. Furthermore, thePDQMaps don’t exhibit diminishing speedup with increas-ing number of threads as was observed with concurrent andsynchronized maps.
4.2 Disk-backed Data StructuresTo analyze the merits of the PDQ library in processing
large datasets (Section 3.3) we compared it with embed-ded disk-based database implementations from Berkeley DBJava Edition (BDB JE) and Kyoto Cabinet (KC). To focusexclusively on the disk I/O performance, we have limitedthe benchmarks to single-threaded execution. In any case,we have shown previously that locking-based data consis-
tency (which is employed by BDB and KC) does not scalefor data-centric computations.
“Reverse index” is another common application of mul-timaps, which creates a mapping from values to their keysin the original index. We used the dataset from DBpedia[4] which lists the URLs of English Wikipedia pages and theURLs of other Wikipedia web pages they point to. The re-verse index is a mapping from a page URL to URLs thatlink to it. The input is a 21GB text file, where each line rep-resents one outgoing link and has the format “〈url of sourcepage〉 ... 〈url of linked page〉”. The input was read usingthe PDQFileReader class, which automatically partitionsthe input file, and the output was stored in a PDQMul-timap object in case of the PDQ library, StoredMap objectin case of BDB and the DB object for KC.
Figure 3 (next page) is a time series of the disk read andwrite activities (top plot), CPU utilization (middle plot) andrate at which the input data is processed, for both PDQ-Multimap (the left plots) and BDB StoredMap. In case ofPDQMultimap, we can clearly observe the cycles of pro-cessing input (when the disk read rate and data processingrates peak) and externalizing the intermediate results to disk(when the disk write rate peaks while the CPU waits as nodata processing occurs). Around the 300s mark, we observethis cycle ends and the external merge begins. During theexternal merge, data is read and written in rapid successionwhile CPU utilization observes a marked drop.
In contrast, the BDB StoredMap observes good perfor-mance only when the database is entirely contained in thememory cache. During the first 200 seconds, StoredMaputilizes the CPU well as data is read from the disk and pro-cessed at a high rate. Once the database is too large to fit inmemory, we observe a spike in the disk write rate as the con-tents of the cache are flushed to disk. Subsequently, the diskread and data processing rates drop significantly and noneof these performance markers improve over time. Once thedatabase is too large to fit in memory, only portions of itcan be stored in the cache at a time, and cache page swapscontribute substantially to disk I/O. This is verified by highpercentage of time that CPU spends in “waiting” state. Tosummarize, once the size of output data exceeds the thresh-old of RAM, the StoredMap spends a lot of time bringingrelevant data items from disk to cache and dumping stalecache entries to disk.
There is a second fundamental limitation of StoredMapwhich is not apparent from the previous plots. As the size ofdata on disk increases, the effectiveness of cache decreases(since a random entry is less likely to be found in cache)and consequently, the performance further degrades. Thisis verified in Figure 4 which shows that the execution timeincreases exponentially with the input data size. PDQMul-timap, in contrast, offered linear scalability.
4.3 Distributed Data StructureWe compared the distributed execution mode (Section
3.4) of the PDQ library against a distributed implementa-tion of the Map container type from Hazelcast [5]. Thehazelcast map partitions the contents across the multipleJVMs based on the hashcode of the keys. The likelihoodthat a given key is present locally decreases in inverse pro-portion to the size of the cluster. Since the version of Hazel-cast we used only supported in-memory data, we used thesame “Term frequency” benchmark problem that we consid-

0
50
100
150PDQMap
Dis
k A
cces
s (M
Bp
s)
ReadWrite
0
20
40
60
80
Tim
e S
pen
t in
CP
U S
tate
s (%
)
RunningWaiting
0 50 100 150 200 250 300 350 4000
20
40
60
80
Time (s)
Dat
a P
roce
ssin
gR
ate
(MB
ps)
BDBMap
ReadWrite
RunningWaiting
0 100 200 300 400 500 600 700 800 900 1000Time (s)
Figure 3: Performance Comparison of PDQ and Berkeley DB (BDB) for Disk I/O Rate (top), CPU Utilization(middle) and Processing Rate (bottom)
1 2 3 4 5 6 7
050
100
150
Input Size (GB)
Exe
cutio
n tim
e (m
in)
PDQMapBDBMap
Figure 4: Scalability Performance of PDQMultiMapvs. Berkeley DB Map
ered for the thread pool execution mode.Figure 5 shows the ratio of the execution time with Hazel-
cast to PDQMap for varying size of cluster. In each case, theJVMs at each node executed the program on a single thread.The PDQMap outperforms the Hazelcast Map by a factorof 90, and the reason for this vast difference in performanceturns out to be that Hazelcast is in fact limited by the effectsof concurrent access. For a randomly distributed input, n−1
n(where n is the size of cluster) access to a map entry willtravel over the network and the proportion of such accessincreases as more nodes participate in the computation.
●
●
● ● ● ●● ●
1 2 3 4 5 6 7 8
5070
9011
0
Number of Machines
PD
Q:H
azel
cast
Exe
cutio
n T
ime
Rat
io
Figure 5: Performance Comparison of PDQMap vs.Hazelcast
Notice that it is not just the amount of data transferredover the network that influences the performance, it is alsothe network access pattern. In case of Hazelcast map, re-mote data is accessed while the computation is being exe-cuted, which implies that the processor would remain idlewhile waiting for the remote data to be fetched. In contrast,the PDQMap transfers data only twice: first, the initial in-put workload is distributed by the master to the slaves, andsecondly, by the slaves when they transmit their computedresults back to the master. In between these two networkaccess, the processors are fully occupied with computationand never wait for network activity. The figure 6 illustratesthe breakdown of the execution times with PDQMap intofour phases. As a summary, whereas distributed maps like
Number of Machines
Ru
nti
mes
(s)
2 3 4 5 6 7 80
10
20
30
40
50
60
70
80Split and Distribute InputLocal Split and MergeGather ResultsFinal Merge at Master
Figure 6: Breakdown of execution times forPDQMap by operation
Hazelcast are latency-bound, the PDQMaps are throughput-bound. What makes this observation pressing is that it iseasier to cater to network throughput bound operations. Forexample, the data can be compressed, faster network inter-connects may be used in the cluster, network parametersmay be tuned and so on.
5. APPLICATIONSIn this section, we illustrate several applications of our
PDQ library in the different fields of Computer Science. Thek-Nearest Neighbor Classification in Machine Learning andthe FP Tree Growth Algorithm in Data Mining illustratehow the PDQ programming model transforms the problemof parallelization to that of “adding” data structures. ThePageRank algorithm for Graph Processing illustrates the ef-ficient operation of PDQ data structures for large datasetsin distributed environments. The PDQ programming modelhas a broad scope of applicability, which we illustrate byexamples in the relational processing of structured-data andincremental processing of log data.
5.1 Machine Learning: k-Nearest Neighborbased Classification
We consider the problem of handwriting recognition, andspecifically, recognizing handwritten numerical digits. Ourtraining dataset consists of 42,000 images, where each im-age is 28x28 pixels and represents one handwritten digit [6].Each of these images is correctly labeled with the repre-sented digit. The machine learning objective is stated as:given a new image, ascertain the digit it represents. We em-ploy the k-Nearest Neighbors based Classification approach,which employs the following steps: (a) represent each sam-ple item as a vector, (b) define distance between two vectors(we used the Euclidean distance), (b) determine the k vec-tors from the training samples that are closest to test vector,and (d) take the majority vote of labels of these k selectedsamples.
We defined a LimitedPriorityQueue that contains no morethan k entries, that is, if a new entry is less than the great-
●
●
●
●●
●
●
●
●●
●
●
2 4 6 8 10 12
24
68
10
Number of Machines
Fact
or S
peed
up
Figure 7: Parallel Speedup of k-Nearest NeighborComputation
est entry in queue, the former is inserted and the latter isremoved. To execute the computation in parallel, we simplyneed to define the aAIJaddaAI operator for the LimitedPri-orityQueue objects, as shown below:
def add ( f i r s t , second ) :r e s u l t = f i r s t . copy ( )for d , l a b e l in second :
r e s u l t . i n s e r t (d , l a b e l )return r e s u l t
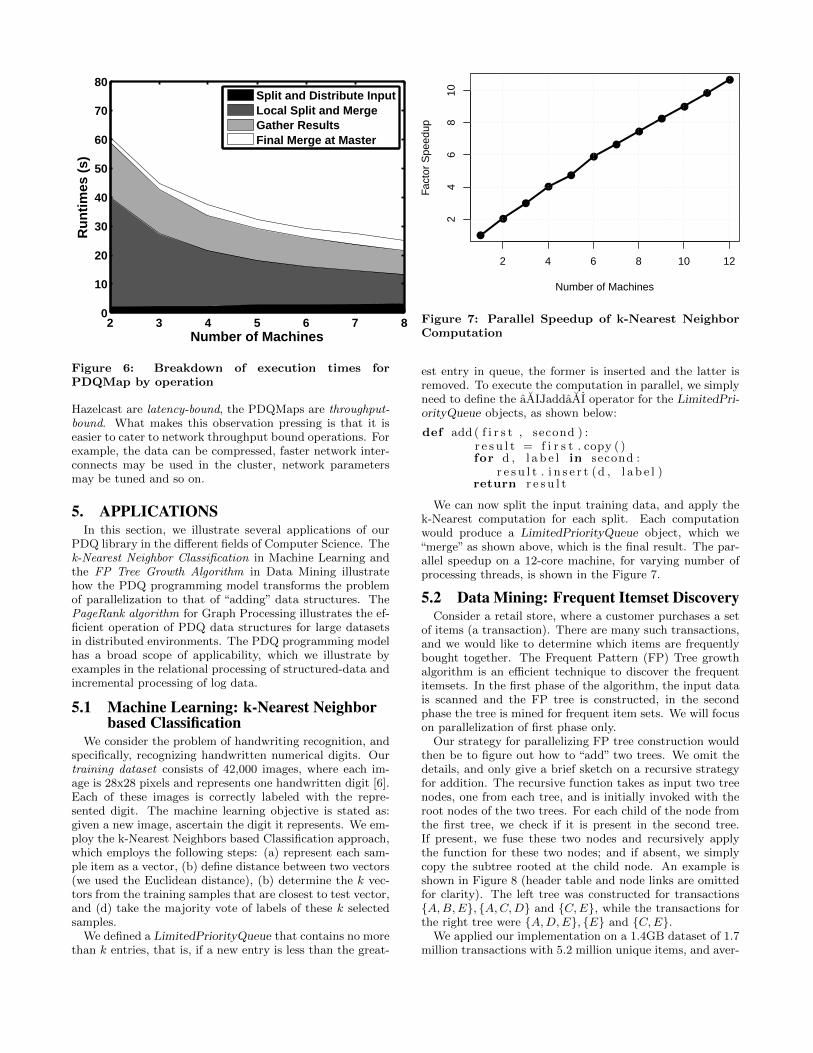
We can now split the input training data, and apply thek-Nearest computation for each split. Each computationwould produce a LimitedPriorityQueue object, which we“merge” as shown above, which is the final result. The par-allel speedup on a 12-core machine, for varying number ofprocessing threads, is shown in the Figure 7.
5.2 Data Mining: Frequent Itemset DiscoveryConsider a retail store, where a customer purchases a set
of items (a transaction). There are many such transactions,and we would like to determine which items are frequentlybought together. The Frequent Pattern (FP) Tree growthalgorithm is an efficient technique to discover the frequentitemsets. In the first phase of the algorithm, the input datais scanned and the FP tree is constructed, in the secondphase the tree is mined for frequent item sets. We will focuson parallelization of first phase only.
Our strategy for parallelizing FP tree construction wouldthen be to figure out how to “add” two trees. We omit thedetails, and only give a brief sketch on a recursive strategyfor addition. The recursive function takes as input two treenodes, one from each tree, and is initially invoked with theroot nodes of the two trees. For each child of the node fromthe first tree, we check if it is present in the second tree.If present, we fuse these two nodes and recursively applythe function for these two nodes; and if absent, we simplycopy the subtree rooted at the child node. An example isshown in Figure 8 (header table and node links are omittedfor clarity). The left tree was constructed for transactions{A,B,E}, {A,C,D} and {C,E}, while the transactions forthe right tree were {A,D,E}, {E} and {C,E}.
We applied our implementation on a 1.4GB dataset of 1.7million transactions with 5.2 million unique items, and aver-

A:2
E:1
D:1 E:1
C:1 B:1
C:1 A:1
E:1
E:1
E:1
D:1
C:1
A:3
E:2
D:1 E:1
C:1 B:1
C:2
E:1
D:1
E:1
Figure 8: Adding two FP Trees
age of 177 items per transaction [3]. With the parallelizationstrategy we were able to achieve a speedup of 5X on a 8-coremachine.
5.3 Graph Processing: Pagerank AlgorithmIf we represent the web as a directed graph, with webpages
represented as nodes and links as edges, then the PageRankalgorithm [7] can be used to generate weights for each node,which measures the relative importance of that web page.
We applied the algorithm on the Wikilinks dataset [4],which is a graph of all English Wikipedia pages along withinternal page links (21 GB text file). We processed thisraw data and created a Multimap, which consumed about8GB, when serialized on disk. This dataset is too large tobe completely processed in-memory. With this example, wehighlight the capability of our associative container imple-mentations that can automatically and transparently tran-sition their behavior from in-memory to disk-backed as welldistributed execution without requiring any code changes tothe program.
Cluster Size Time per Iteration (min) Speedup1 20:382 10:58 1.88X4 5:04 4.06X8 2:25 8.54X
Table 1: Speedup of PageRank algorithm on a Clus-ter
We executed the algorithm on a distributed cluster of ma-chines, the size of which ranged from 1 through 8. Sincethe computation is mostly I/O-bound, we spawned only onethread per machine. The following table shows the speedupwith respect to the cluster size.
5.4 Relational Processing of Structured DataLet us consider a motivating example from the DBLP
repository [8] of academic publications in Computer Sci-ence. We extracted two database tables: paper (paperId, au-thorId), which lists all published papers and their authors,
and citations (paperId, citedpaperId), which lists citationsfor each paper. Equivalently, we can view them as mul-timaps of paperId to authorId, and paperId to citedpaperId,respectively. We chose multimaps, since each paper mayhave multiple authors, and may cite multiple papers.
Sometimes authors cite their own papers, or of their col-leagues. Colleagues are the researchers that an author hasco-authored some paper with, or equivalently:
A is-colleague-of B ⇔ ∃p, (p,A) ∈ paper ∧ (p,B) ∈ paper
We would like to find out, for each author, the percentageof papers they cited that were their own or of their colleagues(which should give us some insight into how clustered the re-search community is!). The following is an intuitive (but un-optimized) SQL statement to count the number of citations,for each author, that were their own or from colleagues:
SELECT author , count ( paper )FROM
(SELECT author , paper , coauthors ,group concat ( coauthors ) AS C
FROM−− for each author , the papers they c i t e(SELECT paper . uid AS author ,
c i t a t i o n . c i t edpaper Id AS c i t edpaperFROM paper INNER JOIN c i t e sON author = c i t edpaper ) AS Y1
INNER JOIN−− for each paper , i t s coauthor se t(SELECT P1 . pid AS paper , X1 . coauthor AS coauthorsFROM paper AS P1 INNER JOIN−− for each author , l i s t of coauthors(SELECT P1 . authorId AS author ,
P2 . authorId AS coauthorFROM paper AS P1 INNER JOIN paper AS P2WHERE P1 . paperId = P2 . paperIdGROUP BY P1 . uid , P2 . uid ) AS X1
ON P1 . authorId = X1 . authorGROUP BY P1 . pid , X1 . coauthor ) AS Y2
ON Y1 . c i t edpape r s = Y2 . paperGROUP BY author , paper ) AS Z1
WHERE(SELECT f i n d i n s e t ( author , C) ) > 0
GROUP BY author
In context of associative containers, we can imagine adata-flow programming paradigm where the data can betransformed using some set of relational operators. If A :K→ V and B : K→ T are two associative containers, thenwe have defined for following operations (only a subset listedhere, relevant for this problem):
Operation Definitionreverse(A) : V→ K v → k ∈ reverse(A)⇔ k → v ∈ A
join(A,B) : k →< v, t >∈ join(A,B)⇔K→< V,T > k → v ∈ A ∧ k → t ∈ B
mix(A,B) : V→ T v → t ∈ mix(A,B)⇔∃k ∈ K, k → v ∈ A ∧ k → t ∈ B
unique(A) : K→ V remove duplicate values for each key
We omit the proof and only claim that each of these oper-ations can be parallelized by the PDQ library both in multi-core and distributed environments, for memory-bound aswell as disk-bound workloads. We can now describe a coun-terpart sequence of data flow statements to compute thesame result as the SQL statement, as shown in the follow-ing:
#T1 = (Multimap from papers t a b l e )#T2 = (Multimap from c i t a t i on s t a b l e )

T3 = rev e r s e (T1) # papers wri t ten by each authorT4 = mix (T1 , T1) # coauthors for each authorT5 = unique (T4) # unique coauthors for each authorT6 = mix (T3 , T5) # coauthor se t for each paperT7 = unique (T6)T8 = mix (T2 , T1) # for each paper , authors tha t c i t e i tT9 = j o i n (T8 , T7) # for each paper , authors tha t c i t e i t
# and the coauthor se t of t h i s paper
PDQ. run ( compute , T9 , r e s u l t )
# where , the ’ compute ’ funct ion i s def ined as :def compute (T9 , r e s u l t ) :
for key , ( c i t i n g au tho r s , coauthors ) in T9 :for c i t i n g au tho r in c i t i n g au t h o r s :
i f c i t i n g au tho r in coauthors :r e s u l t [ c i t i n g au tho r ] ++
5.5 Incremental Log ProcessingIn several contexts, logs are generated continuously (e.g.
web traffic) and several statistics rely on cumulative pro-cessing of logs (e.g. top web pages visited). Processing theentire log dataset for these statistics, for every time a reportis requested, may not be practical. Alternatively, statisticscan be generated incrementally; however, in traditional pro-gramming approaches, custom code has to be developed forthis purpose.
PDQ library offers a native and efficient mechanism forincremental processing of data. Recall that the our SRMcomputation model splits the inputs, creates replicas of out-put, applies computation to each split/replica pair, and fi-nally merges the replicas back to the output container. Sofar we had assumed that the output container is initiallyempty. However, if the output container has some data tobegin with, the replicas will be merged into the existing data.Since the PDQ data structures are natively Serializable, in-cremental processing is easily accomplished, as illustratedbelow:
def f i r s t r e p o r t ( input , output ) :PDQ. run ( gene ra t e r epo r t , input , output )s aveF i l e ( output , ”timestamp 1 ”)
def i n c r ementa l r epo r t ( last t imestamp ,i npu t s i n c e l a s t t ime s t amp ) :
output = readF i l e ( ”timestamp ” + last t imestamp )PDQ. run ( gene ra t e r epo r t ,
i npu t s i n c e l a s t t ime s t amp ,output )
s aveF i l e ( output ,”timestamp ” + (++last t imestamp ) )
After producing the first report, the output is saved todisk; while for the subsequent reports, the previously savedreport is loaded from disk and used as output.
We used the WorldCup98 dataset [9] which is website re-quest logs over 92 days, from 30 servers in four countries.Each log entry is 20B and the total data set size is 26GB. Areport was generated each week, and the Figure 9 shows theexecution time of incremental processing each week, com-pared with full processing of data.
6. CONCLUSIONWe have presented PDQCollections, a library of associa-
tive containers that inherently encapsulate parallelism anda computation model that transforms the problem of paral-lelization to that of defining addition operator for value datatypes. We provided the Data Model, which describes what
IncrementalFull
1 2 3 4 5 6 7 8 9 10 11 12 130
100
200
300
400
500
600
700
800
Week
Pro
cess
ing
Tim
e (s
)
Figure 9: Comparison of Incremental processing ofdata against full processing
problems can be solved, the Split-Replicate-Merge Compu-tation Model, our strategy for parallelism, the Program-ming APIs and shown the equivalence with the Map Re-duce programming model. We have shown that the PDQ li-brary can efficiently exploit parallelism in multi-core as welldistributed environments, for in-memory as well as largedatasets. We discussed our implementation that includedthe data structure design, the thread pool execution modefor shared-memory and memory-bound workloads, the diskbacked execution mode to handle computations when outputdata is too large to fit in memory and finally, the distributedexecution mode for small to medium sized clusters.
Our comparative study with concurrent data structures(for memory bound computation), BerkeleyDB’s StoredMap(for disk-backed computation) and Hazelcast (for distributedcomputation) highlighted the salient characteristics of ourmodel that explained how it significantly outperforms thesetraditional data structures. We also illustrated the applica-tion of our library in several fields of Computer Science.
7. REFERENCES[1] J. Han, J. Pei, and Y. Yin, “Mining frequent patterns
without candidate generation,” SIGMOD, 2000.
[2] R. Power and J. Li, “Piccolo: building fast, distributedprograms with partitioned tables,” OSDI, 2010.
[3] C. Lucchese, S. Orlando, R. Perego, and F. Silvestri,“Webdocs: a real-life huge transactional dataset,”
[4] S. Auer, C. Bizer, J. Lehmann, G. Kobilarov,R. Cyganiak, and Z. Ives, “DBpedia: A nucleus for aweb of open data,” (ISWC/ASWC, 2007.
[5] Hazelcast, “http://www.hazelcast.com/.”
[6] Y. LeCun and C. Cortes, “MNIST handwritten digitdatabase,” http://yann.lecun.com/exdb/mnist/.
[7] L. Page, S. Brin, R. Motwani, and T. Winograd, “Thepagerank citation ranking: Bringing order to the web.,”tech. rep., Stanford InfoLab, 1999.
[8] M. Ley, “DBLP - some lessons learned,” PVLDB, 2009.
[9] M. Arlitt and T. Jin, “1998 world cup web site accesslogs.”
Recommended

















