
Memory Hierarchy DesignMemory Hierarchy Design

2
OutlineOutline Introduction Cache Basics Cache Performance Reducing Cache Miss Penalty Reducing Cache Miss Rate Reducing Hit Time Main Memory and Organizations Memory Technology Virtual Memory Conclusion

3
Many Levels in Memory HierarchyMany Levels in Memory Hierarchy
Pipeline registers
Register file1st-level cache
(on-chip)2nd-level cache
(on same MCM as CPU)Physical memory
(usu. mounted on same board as CPU)
Virtual memory(on hard disk, often in same enclosure as CPU)
Disk files(on hard disk often in same enclosure as CPU)
Network-accessible disk files(often in the same building as the CPU)
Tape backup/archive system(often in the same building as the CPU)
Data warehouse: Robotically-accessed room full of shelves of tapes (usually on the same planet as the CPU)
Our focusin chapter 5
Usually madeinvisible to
the programmer(even assemblyprogrammers)
Invisible only to high-levellanguage programmers
There can also bea 3rd (or more)
cache levels here

4
Simple Hierarchy ExampleSimple Hierarchy Example
Note many orders of magnitude change in characteristics between levels:
×128→ ×8192→ ×200→
×4 → ×100 → ×50,000 →

5
CPU vs. Memory Performance TrendsCPU vs. Memory Performance Trends
Relative performance (vs. 1980 perf.) as a function of year
+7%/year
+55%/year
+35%/year

6
OutlineOutline Introduction Cache Basics Cache Performance Reducing Cache Miss Penalty Reducing Cache Miss Rate Reducing Hit Time Main Memory and Organizations Memory Technology Virtual Memory Conclusion

7
Cache BasicsCache Basics
A cachecache is a (hardware managed) storage, intermediate in size, speed, and cost-per-bit between the programmer-visible registers and main physical memory.
The cache itself may be SRAM or fast DRAM.There may be >1 levels of cachesBasis for cache to work: Principle of LocalityPrinciple of LocalityWhen a location is accessed, it and “nearby”
locations are likely to be accessed again soon. “Temporal” locality - Same location likely again soon. “Spatial” locality - Nearby locations likely soon.

8
Four Basic Questions Four Basic Questions Consider levels in a memory hierarchy.
Use blockblock for the unit of data transfer; satisfy Principle of LocalityPrinciple of Locality.Transfer between cache levels, and the memory
The level design is described by four behaviorsBlock Placement:
Where could a new block be placed in the level?Block Identification:
How is a block found if it is in the level?Block Replacement:
Which existing block should be replaced if necessary?Write Strategy:
How are writes to the block handled?

9
Block Placement SchemesBlock Placement Schemes

10
Direct-Mapped PlacementDirect-Mapped PlacementA block can only go into one frame in the
cacheDetermined by block’s address (in memory space)
Frame number usually given by some low-order bits of block address.
This can also be expressed as:(Frame number) =
(Block address) modmod (Number of frames (sets) in cache)
Note that in a direct-mapped cache, block placement & replacement are both
completely determined by the address of the new block that is to be accessed.

11
Direct-Mapped IdentificationDirect-Mapped Identification
Tags Block framesAddress
Decode & Row Select
?Compare Tags
Hit
Tag Frm# Off.
Data Word
Muxselect
One Selected &Compared

12
Fully-Associative PlacementFully-Associative PlacementOne alternative to direct-mapped is:
Allow block to fill anyany empty frame in the cache.
How do we then locate the block later?Can associate each stored block with a tag
Identifies the block’s location in cache.
When the block is needed, treat the cache as an associative memory, using the tag to match all frames in parallel, to pull out the appropriate block.
Another alternative to direct-mapped is placement under full program control.A register file can be viewed as a small programmer-
controlled cache (w. 1-word blocks).

13
Block addrs Block framesAddress
Parallel Compare& Select
Block addr Off.
Data Word
Muxselect
Note that, compared to Direct:
•More address bits have to be stored with each block frame.
•A comparator is needed for each frame, to do the parallel associative lookup.
Hit
Fully-Associative IdentificationFully-Associative Identification

14
Set-Associative PlacementSet-Associative Placement
The block address determines not a single frame, but a frame setframe set (several frames, grouped together). Frame set # = Block address mod # of frame sets
The block can be placed associatively anywhere within that frame set.
If there are n frames in each frame set, the scheme is called “n-way set-associative”.
Direct mapped = 1-way set-associative.
Fully associative: There is only 1 frame set.
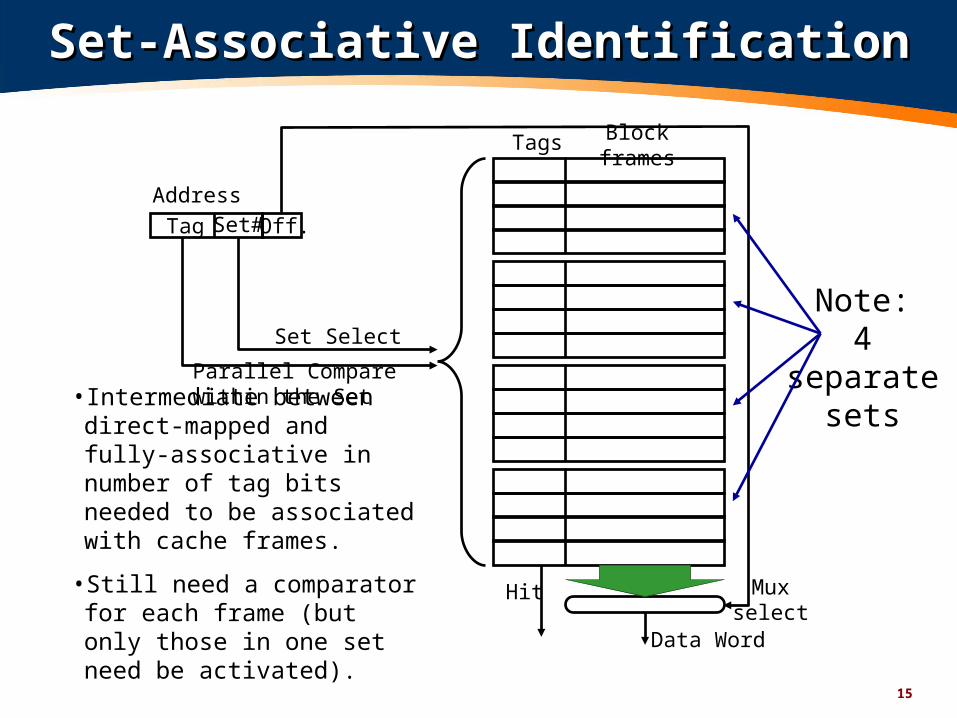
15
Set-Associative IdentificationSet-Associative Identification
Tags Block frames
Address
Hit
Tag Set# Off.
Data Word
Muxselect
Set Select
Parallel Compare within the Set
• Intermediate between direct-mapped and fully-associative in number of tag bits needed to be associated with cache frames.
• Still need a comparator for each frame (but only those in one set need be activated).
Note:4
separatesets

16
Simple equation for the size of a cache:(Cache size) = (Block size) × (Number of sets)
× (Set Associativity)
Can relate to the size of various address fields:(Block size) = 2(# of offset bits)
(Number of sets) = 2(# of index bits)
(# of tag bits) = (# of memory address bits) (# of index bits) (# of offset bits)
Cache Size EquationCache Size Equation
Memory address

17
Replacement StrategiesReplacement Strategies
Which block do we replace when a new block comes in (on cache miss)?
Direct-mapped: There’s only one choice!
Associative (fully- or set-):If any frame in the set is empty, pick one of those.Otherwise, there are many possible strategies:
Random: Simple, fast, and fairly effectiveLeast-Recently Used (LRU), and approximations thereof
Require bits to record replacement info., e.g. 4-way requires 4! = 24 permutations, need 5 bits to define the MRU to LRU positions
FIFO: Replace the oldest block.

18
Write StrategiesWrite Strategies
Most accesses are reads, not writesEspecially if instruction reads are included
Optimize for reads – performance mattersDirect mapped can return value before valid check
Writes are more difficultCan’t write to cache till we know the right blockObject written may have various sizes (1-8 bytes)
When to synchronize cache with memory?Write through - Write to cache and to memory
Prone to stalls due to high bandwidth requirementsWrite back - Write to memory upon replacement
Memory may be out of date

19
Another Write StrategyAnother Write Strategy
Maintain a FIFO queue (write buffer) of cache frames (e.g. can use a doubly-linked list)
Meanwhile, take items from top of queue and write them to memory as fast as bus can handleReads might take priority, or have a separate bus
Advantages: Write stalls are minimized, while keeping memory as up-to-date as possible

20
Write Miss StrategiesWrite Miss Strategies
What do we do on a write to a block that’s not in the cache?
Two main strategies: Both do not stop processorWrite-allocate (fetch on write) - Cache the block.No write-allocate (write around) - Just write to memory.
Write-back caches tend to use write-allocate.White-through tends to use no-write-allocate.Use dirty bit to indicate write-back is needed in
write-back strategy

21
Example – Alpha 21264Example – Alpha 21264
64KB, 2-way, 64-byte block, 512 sets
44 physical address bits

22
Instruction vs. Data CachesInstruction vs. Data Caches
Instructions and data have different patterns of temporal and spatial localityAlso instructions are generally read-only
Can have separate instruction & data cachesAdvantages
Doubles bandwidth between CPU & memory hierarchyEach cache can be optimized for its pattern of locality
DisadvantagesSlightly more complex designCan’t dynamically adjust cache space taken up by
instructions vs. data

23
I/D Split and Unified CachesI/D Split and Unified Caches
Miss per 1000 accessesMuch lower instruction miss rate than data miss rate
Size I-Cache D-Cache Unified Cache
8KB 8.16 44.0 63.016KB 3.82 40.9 51.0
32KB 1.36 38.4 43.3
64KB 0.61 36.9 39.4
128KB 0.30 35.3 36.2256KB 0.02 32.6 32.9

24
OutlineOutline Introduction Cache Basics Cache Performance Reducing Cache Miss Penalty Reducing Cache Miss Rate Reducing Hit Time Main Memory and Organizations Memory Technology Virtual Memory Conclusion

25
Cache Performance EquationsCache Performance Equations
Memory stalls per program (blocking cache):
CPU time formula:
More cache performance will be given later!
TimeCyclenInstructio
CycleStallMemoryCPIICTimeCPU Execu )(
yMissPenaltMissRatenInstructio
ssesMemoryAcceIClCycleMemoryStal )(
yMissPenaltnInstructio
MissesIClCycleMemoryStal )(

26
Cache Performance ExampleCache Performance Example
Ideal CPI=2.0, memory references / inst=1.5, cache size=64KB, miss penalty=75ns, hit time=1 clock cycle
Compare performance of two caches:Direct-mapped (1-way): cycle time=1ns, miss rate=1.4%2-way: cycle time=1.25ns, miss rate=1.0%
ICnsICTimeCPU way 575.31)755.1%4.10.2(1
Cyclesns
nsPenaltyMiss way 75
1
751
Cyclesns
nsPenaltyMiss way 60
25.1
752
ICnsICTimeCPU way 625.325.1)605.1%10.2(2

27
Out-Of-Order ProcessorOut-Of-Order Processor
Define new “miss penalty” considering overlap
Compute memory latencymemory latency and overlapped latencyoverlapped latency
Example (from previous slide)
Assume 30% of 75ns penalty can be overlapped,
but with longer (1.25ns) cycle on 1-way design due
to OOO
)(.
latencymissOverlaplatencymissTotalnInstructio
Misses
nInstructio
CyclesStallMem
Cyclesns
nsPenaltyMiss way 42
25.1
%70751
ICnsICTimeCPU OOOway 60.325.1)425.1%4.10.2(,1

28
Cache Performance ImprovementCache Performance Improvement
• Consider the cache performance equation:
• It obviously follows that there are three basic ways to improve cache performance:– Reducing miss penalty (5.4) – Reducing miss rate (5.5)– Reducing miss penalty/rate via parallelism (5.6)– Reducing hit time (5.7)
• Note that by Amdahl’s Law, there will be diminishing returns from reducing only hit time or amortized miss penalty by itself, instead of both together.
(Average memory access time) = (Hit time) + (Miss rate)×(Miss penalty)
“Amortized miss penalty”

29
Cache Performance ImprovementCache Performance ImprovementReduce miss penalty:
Multilevel cache; Critical word first and early restart; priority to read miss; Merging write buffer; Victim cache
Reduce miss rate:Larger block size; Increase cache size; Higher
associativity; Way prediction and Pseudo-associative caches; Compiler optimizations;
Reduce miss penalty/rate via parallelism:Non-blocking cache; Hardware prefetching; Compiler-
controlled prefetching;
Reduce hit time:Small simple cache; Avoid address translation in indexing
cache; Pipelined cache access; Trace caches

30
OutlineOutline Introduction Cache Basics Cache Performance Reducing Cache Miss Penalty Reducing Cache Miss Rate Reducing Hit Time Main Memory and Organizations Memory Technology Virtual Memory Conclusion

31
Multi-Level CachesMulti-Level Caches
What is important: faster caches or larger caches?
Average memory access time = Hit time (L1) + Miss rate (L1) x Miss Penalty (L1)
Miss penalty (L1)Hit time (L2) + Miss rate (L2) x Miss Penalty (L2)
Can plug 2nd equation into the first:Average memory access time =
Hit time(L1) + Miss rate(L1) x (Hit time(L2) + Miss rate(L2)x Miss
penalty(L2))

32
Multi-level Cache TerminologyMulti-level Cache Terminology“Local miss rate”
The miss rate of one hierarchy level by itself.# of misses at that level / # accesses to that levele.g. Miss rate(L1), Miss rate(L2)
“Global miss rate”The miss rate of a whole group of hierarchy levels# of accesses coming out of that group
(to lower levels) / # of accesses to that groupGenerally this is the product of the miss rates at
each level in the group.Global L2 Miss rate = Miss rate(L1) × Local Miss
rate(L2)

33
Effect of 2-level CachingEffect of 2-level CachingL2 size usually much bigger than L1
Provide reasonable hit rateDecreases miss penalty of 1st-level cacheMay increase L2 miss penalty
Multiple-level cache inclusion propertyInclusive cache: L1 is subset of L2; simplify cache
coherence mechanism, effective cache size = L2Exclusive cache: L1, L2 are exclusive; increase
effect cache sizes = L1 + L2Enforce inclusion property: Backward invalidation on
L2 replacement

34
L2 Cache PerformanceL2 Cache Performance
1. Global cache miss rate is similar to the single cache miss rate2. Local miss rate is not a good measure of secondary caches

35
Early Restart, Critical Word FirstEarly Restart, Critical Word FirstEarly restart
Don’t wait for entire block to fillResume CPU as soon as requested word is
fetched
Critical word first wrapped fetch, requested word firstFetch the requested word from memory firstResume CPUThen transfer the rest of the cache block
Most beneficial if block size is largeCommonly used in all the processors

36
Read Misses Take PriorityRead Misses Take Priority
Processor must wait on a read, not on a writeMiss penalty is higher for reads to begin with and more
benefit from reducing read miss penalty
Write buffer can queue values to be writtenUntil memory bus is not busy with readsCareful about the memory consistency issue
What if we want to read a block in write buffer?Wait for write, then read block from memoryBetter: Read block out of write buffer.
Dirty block replacement when readingWrite old block, read new block - Delays the read.Old block to buffer, read new, write old. - Better!

37
Sub-block PlacementSub-block Placement
• Larger blocks have smaller tags (match faster)• Smaller blocks have lower miss penalty• Compromise solution:
– Use a large block size for tagging purposes– Use a small block size for transfer purposes
• How? Valid bits associated with sub-blocks.
Tags
Blocks

38
Merging Write BufferMerging Write Buffer
A mechanism to help reduce write stalls
On a write to memory, block address and data to be written are placed in a write buffer.
CPU can continue immediatelyUnless the write buffer is full.
Write merging:If the same block is written again before it has been
flushed to memory, old contents are replaced with new contents.
Care must be taken to not violate memory consistency and proper write ordering

39
Write Merging ExampleWrite Merging Example

40
Victim CacheVictim Cache
• Small extra cache
• Holds blocks overflowing from the occasional overfull frame set.
• Very effective for reducing conflict misses.
• Can be checked in parallel with main cache
– Insignificant increase to hit time.

41
OutlineOutline Introduction Cache Basics Cache Performance Reducing Cache Miss Penalty Reducing Cache Miss Rate Reducing Hit Time Main Memory and Organizations Memory Technology Virtual Memory Conclusion

42
Three Types of MissesThree Types of MissesCompulsory
During a program, the very first access to a block will not be in the cache (unless pre-fetched)
CapacityThe working set of blocks accessed by the program is
too large to fit in the cache
ConflictUnless cache is fully associative, sometimes blocks may
be evicted too early because too many frequently-accessed blocks map to the same limited set of frames.
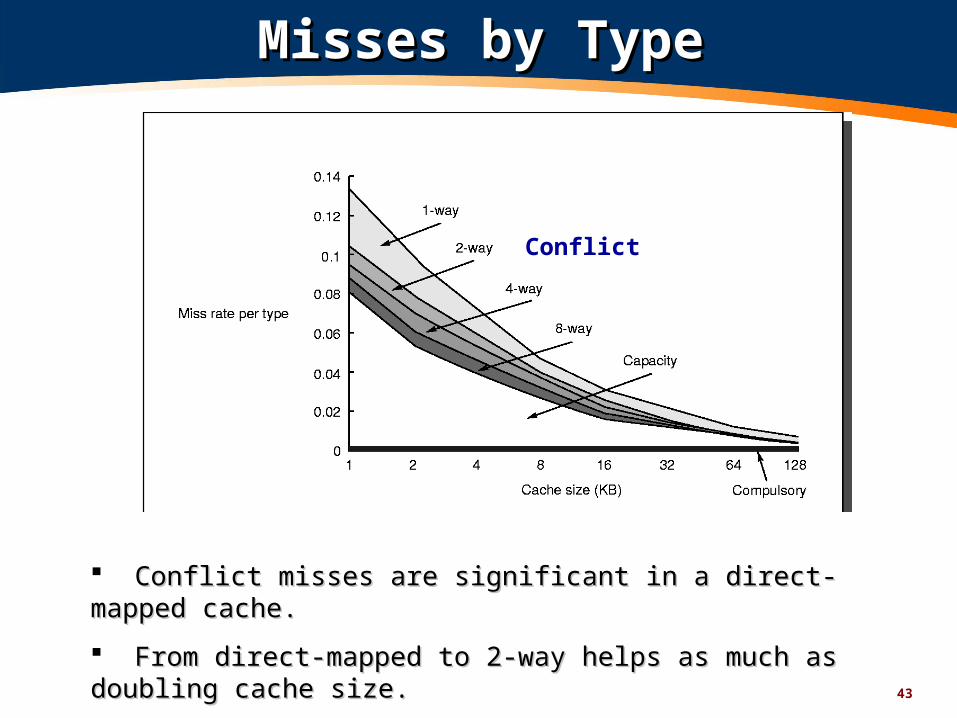
43
Misses by TypeMisses by Type
Conflict
Conflict misses are significant in a direct-mapped cache.Conflict misses are significant in a direct-mapped cache.
From direct-mapped to 2-way helps as much as doubling cache size.From direct-mapped to 2-way helps as much as doubling cache size.
Going from direct-mapped to 4-way is Going from direct-mapped to 4-way is betterbetter than doubling cache size. than doubling cache size.

44
As fraction of total missesAs fraction of total misses

45
Larger Block SizeLarger Block Size
Keep cache size & associativity constantReduces compulsory misses
Due to spatial localityMore accesses are to a pre-fetched block
Increases capacity missesMore unused locations pulled into cache
May increase conflict misses (slightly)Fewer sets may mean more blocks utilized per setDepends on pattern of addresses accessed
Increases miss penalty - longer block transfers

46
Block Size EffectBlock Size Effect
Miss rate is actually goes up if the block is too large relative to the cache size

47
Larger CachesLarger Caches
Keep block size, set size, etc. constantNo effect on compulsory misses.
Block still won’t be there on its 1st access!
Reduces capacity missesMore capacity!
Reduces conflict misses (in general)Working blocks spread out over more frame setsFewer blocks map to a set on averageLess chance that the number of active blocks that
map to a given set exceeds the set size.
But, increases hit time! (And cost.)

48
Higher Associativity Higher Associativity Keep cache size & block size constant
Decreasing the number of setsNo effect on compulsory missesNo effect on capacity misses
By definition, these are misses that would happen anyway in fully-associative
Decreases conflict missesBlocks in active set may not be evicted early
for set size smaller than capacity
Can increase hit time (slightly)Direct-mapped is fastestn-way associative lookup a bit slower for larger n

49
Performance ComparisonPerformance Comparison
Assume:
4KB, 1-way miss-rate=9.8%; 4-way miss-rate=7.1%
waywayway TimeCyclePenaltyMissTimeCycleTimeHit 111 25
wayway TimeCycleTimeHit 12 36.1
wayway TimeCycleTimeHit 14 44.1
wayway TimeCycleTimeHit 18 52.1
2500.11 RateMissTimeAccessMemAverage way
45.325098.000.1
2544.14 RateMissTimeAccessMemAverage way
215.325071.044.1

50
Higher Set-AssociativityHigher Set-Associativity
Cache Size 1-way 2-way 4-way 8-way4KB 3.44 3.25 3.22 3.288KB 2.69 2.58 2.55 2.62
16KB 2.23 2.40 2.46 2.5332KB 2.06 2.30 2.37 2.4564KB 1.92 2.14 2.18 2.25
128KB 1.52 1.84 1.92 2.00256KB 1.32 1.66 1.74 1.82512KB 1.20 1.55 1.59 1.66
Higher associativity increase the cycle timeThe table shows the average memory access timeaverage memory access time
1-way is better most of cases

51
Way PredictionWay PredictionKeep in each set a way-prediction information to
predict the block in each set will be accessed next
Only one tag may be matched at the first cycle; if miss, other blocks need to be examined
Beneficial in two aspectsFast data access: Access the data without knowing
the tag comparison resultsLow power: Only match a single tag; if majority of the
prediction is correct
Different systems use variations of the concept

52
Pseudo-Associative CachesPseudo-Associative Caches
Essentially this is 2-way set-associative, but with sequential (rather than parallel) lookups.“Fast” hit time if first frame checked is right.An occasional slow hit if an earlier conflict had
moved the block to its backup location.

53
Placement:Place block b in frame (b mod n).
Identification:Look for block b first in frame (b mod n), then in its
secondary location ((b+n/2) mod n). (flip the most-significant bit) If found there, primary and secondary blocks are swapped.
May maintain a “MRU bit” to reduce the search and for better replacement.
Replacement:Block in frame (b mod n) is moved to secondary location
((b+n/2) mod n). (Block there is flushed.)
Write strategy:Any desired write strategy can be used.
Pseudo-Associative CachesPseudo-Associative Caches

54
Compiler OptimizationsCompiler Optimizations
Reorganize code to improve locality properties.
“The hardware designer’s favorite solution.”Requires no new hardware!
Various techniques – Cache awareness:Merging ArraysLoop InterchangeLoop FusionBlocking (in multidimensional arrays)Other source-source transformation technique

55
Loop Blocking – Matrix MultiplyLoop Blocking – Matrix Multiply
Before:
After:

56
Effect of Compiler OptimizationsEffect of Compiler Optimizations

57
OutlineOutline Introduction Cache Basics Cache Performance Reducing Cache Miss Penalty Reducing Cache Miss Rate Reducing Hit Time Main Memory and Organizations Memory Technology Virtual Memory Conclusion
via Parallelism

58
Non-blocking CachesNon-blocking Caches
Known as lockup-free cache, hit under missWhile a miss is being processed,
Allow other cache lookups to continue anyway
Useful in dynamically scheduled CPUsOther instructions may be in the load queue
Reduces effective miss penaltyUseful CPU work fills the miss penalty “delay slot”
hit under multiple miss, miss under miss:Extend technique to allow multiple misses to be
queued up, while still processing new hits
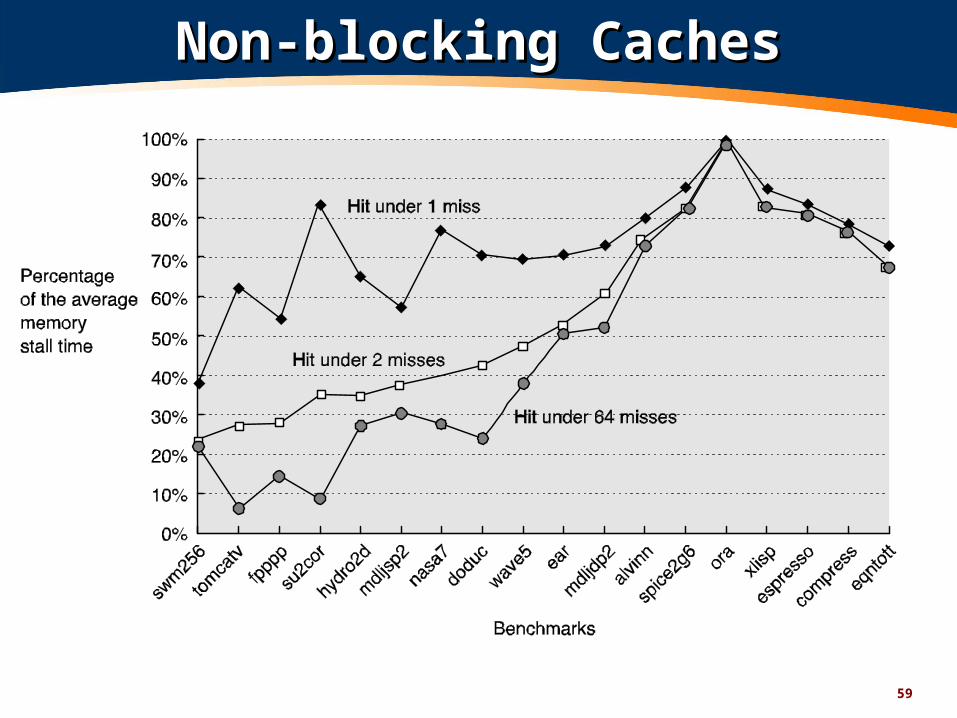
59
Non-blocking CachesNon-blocking Caches

60
Hardware PrefetchingHardware Prefetching
When memory is idle, speculatively get some blocks before the CPU first asks for them!Simple heuristic: Fetch 1 or more blocks that are
consecutive to last one(s) fetchedOften, the extra blocks are placed in a special
stream buffer so as not to conflict with actual active blocks in the cache, otherwise the prefetch may pollute the cache
Prefetching can reduce misses considerablySpeculative fetches should be low-priority
Use only otherwise-unused memory bandwidth
Energy-inefficient (like all speculation)

61
Compiler-Controlled PrefetchingCompiler-Controlled Prefetching
Insert special instructions to load addresses from memory well before they are needed.
Register vs. cache, faulting vs. nonfaultingSemantic invisibility, nonblocking-nessCan considerably reduce missesCan also cause extra conflict misses
Replacing a block before it is completely used
Can also delay valid accesses (tying up bus)Low-priority, can be pre-empted by real access

62
OutlineOutline Introduction Cache Basics Cache Performance Reducing Cache Miss Penalty Reducing Cache Miss Rate Reducing Hit Time Main Memory and Organizations Memory Technology Virtual Memory Conclusion

63
Small and Simple CachesSmall and Simple Caches
Make cache smaller to improve hit timeimprove hit time
Or (probably better), add a new & smaller L0 cache between existing L1 cache and CPU.
Keep L1 cache on same chip as CPUPhysically close to functional units that access it
Keep L1 design simple, e.g. direct-mappedAvoids multiple tag comparisons
Tag can be compared after data cache fetchReduces effective hit time

64
Access Time in a CMOS CacheAccess Time in a CMOS Cache

65
Avoid Address TranslationAvoid Address Translation
In systems with virtual address spaces, virtual addr. must be mapped to physical addresses.
If cache blocks are indexed/tagged w. physical addresses, we must do this translation before we can do the cache lookup. Long hit time!
Solution: Access cache using the virtual address. Call this a “Virtual Cache”Drawback: Cache flush on context switch
Can fix by tagging blocks with Process Ids (PIDs)
Another problem: “Aliasing”, i.e. two virtual addresses mapped to same real addressFix with anti-aliasing or page coloring

66
Benefit of PID Tags in Virtual CacheBenefit of PID Tags in Virtual Cache
Mis
s ra
te
W/o PIDs, purge
W. PIDs
W/o context switching

67
Pipelined Cache AccessPipelined Cache Access
Pipeline cache access so that Effective latency of first level cache hit can be
multiple clock cycles Fast cycle time and slow hits Hit times: 1 for Pentium, 2 for P3, and 4 for P4
Increases number of pipeline stages Higher penalty on mispredicted branches More cycles from issue of load to use of data
In reality Increases the bandwidth of instructions than
decreasing the actual latency of a cache hit

68
Trace CachesTrace Caches
Supply enough instructions per cycle without dependencies Finding ILP beyond 4 instructions per cycle
Don’t limit instructions in a static cache block to spatial locality Find dynamic sequence of instructions including
taken branches NetBurst (P4) uses trace caches
Addresses are no longer aligned. Same instruction is stored more than once
If part of multiple traces
69
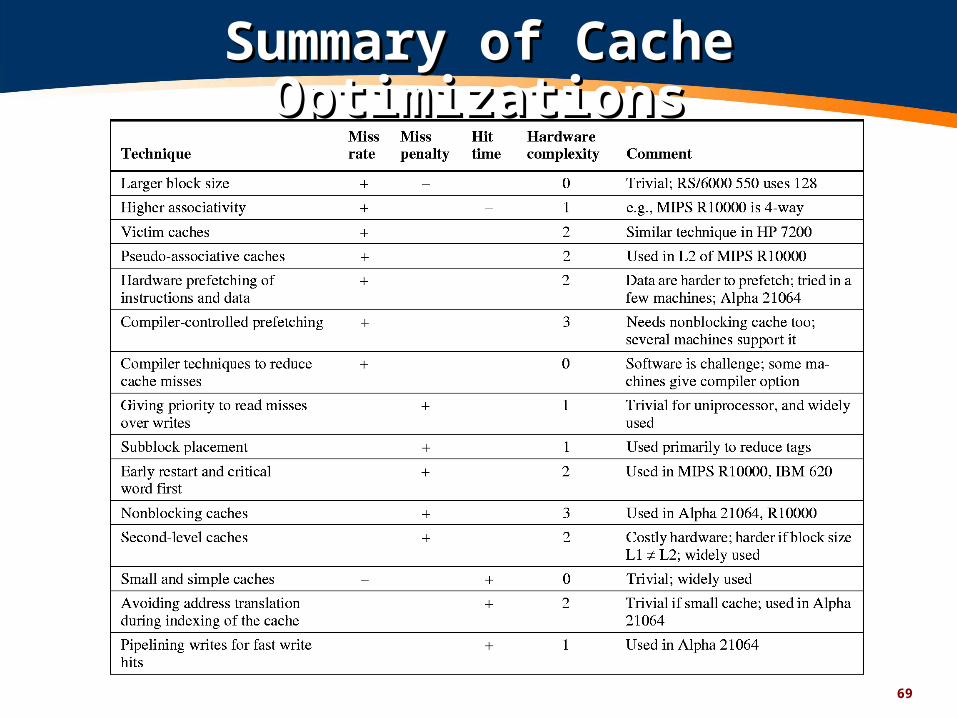
Summary of Cache OptimizationsSummary of Cache Optimizations

70
OutlineOutline Introduction Cache Basics Cache Performance Reducing Cache Miss Penalty Reducing Cache Miss Rate Reducing Hit Time Main Memory and Organizations for Improving
Performance Memory Technology Virtual Memory Conclusion

71
Wider Main MemoryWider Main Memory

72
Simple Interleaved MemorySimple Interleaved Memory
Adjacent words found in different mem. banksBanks can be accessed in parallelOverlap latencies for accessing each word
Can use narrow bus To return accessed words sequentially
Fits well with sequential access e.g., of words in cache blocks

73
Independent Memory BanksIndependent Memory Banks
Original motivation for memory banks Higher bandwidth by interleaving seq. accesses
Allows multiple independent accesses Each bank requires separate address/data lines
Non-blocking caches allow CPU to proceed beyond a cache miss Allows multiple simultaneous cache misses
Possible only with memory banks

74
OutlineOutline Introduction Cache Basics Cache Performance Reducing Cache Miss Penalty Reducing Cache Miss Rate Reducing Hit Time Main Memory and Organizations Memory Technology Virtual Memory Conclusion

75
Main MemoryMain Memory
Bandwidth: Bytes read or written per unit timeLatency: Described by
Access Time: Delay between initiation/completionFor reads: Present address till result ready.
Cycle time: Minimum interval between separate requests to memory.
Address lines: Separate bus CPUMem to carry addresses.
RAS (Row Access Strobe)First half of address, sent first.
CAS (Column Access Strobe)Second half of address, sent second.

76
RAS vs. CASRAS vs. CAS
DRAM bit-cell array
1. RAS selects a row
2. Parallelreadout of
all row data
3. CAS selectsa column to read
4. Selected bitwritten to memory bus

77
Typical DRAM OrganizationTypical DRAM Organization
(256 Mbit)
High14 bits
Low 14 bits

78
Types of MemoryTypes of MemoryDRAM (Dynamic Random Access Memory)
Cell design needs only 1 transistor per bit stored.Cell charges leak away and may dynamically (over
time) drift from their initial levels.Requires periodic refreshing to correct drift
e.g. every 8 ms
Time spent refreshing kept to <5% of bandwidth
SRAM (Static Random Access Memory)Cell voltages are statically (unchangingly) tied to
power supply references. No drift, no refresh.But needs 4-6 transistors per bit.
DRAM: 4-8x larger, 8-16x slower, 8-16x cheaper/bit

79
Amdahl/Case RuleAmdahl/Case Rule
Memory size (and I/O bandwidth) should grow linearly with CPU speedTypical: 1 MB main memory, 1 Mbps I/O bandwidth
per 1 MIPS CPU performance.Takes a fairly constant ~8 seconds to scan entire
memory (if memory bandwidth = I/O bandwidth, 4 bytes/load, 1 load/4 instructions, no latency problem)
Moore’s Law:DRAM size doubles every 18 months (up 60%/yr)Tracks processor speed improvements
Unfortunately, DRAM latency has only decreased 7%/year. Latency is a big deal.

80
Some DRAM Trend DataSome DRAM Trend Data
Since 1998, the rate of increase in chip capacity has slowed to 2x per 2 years:* 128 Mb in 1998* 256 Mb in 2000* 512 Mb in 2002

81
ROM and FlashROM and Flash
ROM (Read-Only Memory) Nonvolatile + protection
FlashNonvolatile RAMsNVRAMs require no power to maintain stateReading flash is near DRAM speedsWriting is 10-100x slower than DRAMFrequently used for upgradeable embedded SW
Used in Embedded Processors

82
DRAM VariationsDRAM VariationsSDRAM – Synchronous DRAM
DRAM internal operation synchronized by a clock signal provided on the memory bus
Double Data Rate (DDR) – uses both clock edges
RDRAM – RAMBUS (Inc.) DRAMProprietary DRAM interface technology
on-chip interleaving / multi-bank technology a high-speed packet-switched (split-transaction) bus interface byte-wide interface, synchronous, dual-rate
Licensed to many chip & CPU makersHigher bandwidth, costly than generic SDRAM
DRDRAM – “Direct” RDRAM (2nd ed. spec.)Separate row and column address/command busesHigher bandwidth (18-bit data, more banks, faster clock)

83
OutlineOutline Introduction Cache Basics Cache Performance Reducing Cache Miss Penalty Reducing Cache Miss Rate Reducing Hit Time Main Memory and Organizations Memory Technology Virtual Memory Conclusion

84
Virtual MemoryVirtual Memory
The addition of the virtual memory mechanism complicated the cache access

85
Paging vs. SegmentationPaging vs. Segmentation
Paged SegmentPaged Segment: Each segment has integral number of pages for easy replacement and can still treat each segmentation as a unit

86
Four Important QuestionsFour Important Questions Where to place a block in main memory?
Operating systems takes care of it Replacement takes very long – fully associative
How to find a block in main memory? Page table is used
Offset is concatenated when paging is used Offset is added when segmentation is used.
Which block to replace when needed? Obviously – LRU is used to minimize page faults
What happens on a write? Magnetic disks takes millions of cycles to access. Always write back (use of dirty bit).

87
Addressing Virtual MemoriesAddressing Virtual Memories

88
Fast Address CalculationFast Address Calculation Page tables are very large
Kept in main memory Two memory accesses for one read or write
Remember the last translation Reuse if the address is on the same page
Exploit the principle of locality If access have locality, the address translations
should also have locality Keep the address translations in a cache
Translation lookaside buffer (TLB) The tag part stores the virtual address and the data
part stores the page number.

89
TLB Example: Alpha 21264TLB Example: Alpha 21264
Same as PID

90
An Memory Hierarchy ExampleAn Memory Hierarchy Example
28

91
Protection of Virtual MemoryProtection of Virtual Memory
Maintain two registers Base Bound
For each address check base <= address <= bound
Provide two modes User OS (kernel, supervisor, executive)

92
Alpha-21264 Virtual Addr. MappingAlpha-21264 Virtual Addr. Mapping
Supports both segmentation and paging

93
OutlineOutline Introduction Cache Basics Cache Performance Reducing Cache Miss Penalty Reducing Cache Miss Rate Reducing Hit Time Main Memory and Organizations Memory Technology Virtual Memory Conclusion

94
Design of Memory HierarchiesDesign of Memory Hierarchies
Superscalar CPU, number of ports to cache Speculative execution and memory system Combine inst. Cache with fetch and decode Caches in embedded systems!
Real-time vs. power
I/O and consistency of cached data The cache coherence problem

95
The Cache Coherency ProblemThe Cache Coherency Problem

96
Alpha 21264Memory Hierarchy
Recommended

















