
Lecture10:PrinciplesofParallelAlgorithmDesign
1
CSCE569ParallelComputing
DepartmentofComputerScienceandEngineeringYonghong Yan
[email protected]://cse.sc.edu/~yanyh

Lasttwolectures:AlgorithmsandConcurrency
• IntroductiontoParallelAlgorithms– Tasksanddecomposition– Processesandmapping• DecompositionTechniques– Recursivedecomposition(divide-conquer)– Datadecomposition(input,output,input+output,intermediate)
• Termsandconcepts– Taskdependencygraph,taskgranularity,degreeofconcurrency– Taskinteractiongraph,criticalpath• Examples:– Dense vectoraddition,matrixvectorandmatrixmatrixproduct– Databasequery,quicksort,MIN– Imageconvolution(filtering)andJacobi
2

Today’slecture
• DecompositionTechniques- continued– ExploratoryDecomposition– HybridDecomposition
Mappingtaskstoprocesses/cores/CPU/PEs• CharacteristicsofTasksandInteractions– TaskGeneration,Granularity,andContext– CharacteristicsofTaskInteractions• MappingTechniquesforLoadBalancing– StaticandDynamicMapping• MethodsforMinimizingInteractionOverheads• ParallelAlgorithmDesignModels
3

ExploratoryDecomposition
4
• Decompositionisfixed/staticfromthedesign– Dataandrecursive
• Exploration(search)ofastatespaceofsolutions– Problemdecompositionreflectsshapeofexecution– Goeshand-in-handwithitsexecution• Examples– discreteoptimization,e.g.0/1integerprogramming– theoremproving– gameplaying

ExploratoryDecomposition:Example
5
Solvea15puzzle• Sequenceofthreemovesfromstate(a)tofinalstate(d)
• Fromanarbitrarystate,mustsearchforasolution

ExploratoryDecomposition:Example
6
Solvinga15puzzle• Search– generatesuccessorstatesofthecurrentstate– exploreeachasanindependenttask

ExploratoryDecompositionSpeedupSolvea15puzzle
• Thedecompositionbehavesaccordingtotheparallelformulation– May change the amount of work done
7Executionterminatewhenasolutionisfound

SpeculativeDecomposition
8
• Dependenciesbetweentasksarenotknowna-priori.– Impossibletoidentifyindependenttasks• Twoapproaches– Conservativeapproaches,whichidentifyindependenttasks
onlywhentheyareguaranteedtonothavedependencies• Mayyieldlittleconcurrency
– Optimisticapproaches,whichscheduletasksevenwhentheymaypotentiallybeinter-dependent• Roll-backchangesincaseofanerror

SpeculativeDecomposition:Example
9
Discreteeventsimulation• Centralizedtime-orderedeventlist– yougetupàgetreadyàdrive toworkàworkàeat lunchà
worksomemoreàdrive backàeat dinneràand sleep• Simulation– extractnexteventintimeorder– processtheevent– ifrequired,insertneweventsintotheeventlist• Optimisticeventscheduling– assumeoutcomesofallpriorevents– speculativelyprocessnextevent– ifassumptionisincorrect,rollbackitseffectsandcontinue

SpeculativeDecomposition:Example
10
Simulationofanetworkofnodes• Simulatenetworkbehaviorforvariousinputandnodedelays– Theinputaredynamicallychanging• Thustaskdependencyisunknown
• Speculateexecution:tasks’input– Correct:parallelism– Incorrect:rollbackandredo

Speculativevs Exploratory
• Exploratorydecomposition– Theoutputofmultipletasksfromabranchisunknown– Parallelprogramperformmore,lessorsameamountofwork
asserialprogram• Speculative– Theinputatabranchleadingtomultipleparalleltasksis
unknown– Parallelprogramperformmoreorsameamountofworkasthe
serialalgorithm
11

HybridDecompositions
12
Usemultipledecompositiontechniquestogether• Onedecompositionmaybenotoptimalforconcurrency– Quicksortrecursivedecompositionlimitsconcurrency(Why?)
• CombinedrecursiveanddatadecompositionforMIN

Today’slecture
• DecompositionTechniques- continued– ExploratoryDecomposition– HybridDecomposition
Mappingtaskstoprocesses/cores/CPU/PEs• CharacteristicsofTasksandInteractions– TaskGeneration,Granularity,andContext– CharacteristicsofTaskInteractions• MappingTechniquesforLoadBalancing– StaticandDynamicMapping• MethodsforMinimizingInteractionOverheads• ParallelAlgorithmDesignModels
13

CharacteristicsofTasks
14
• Theory– Decomposition:toparallelizetheoretically• Concurrencyavailableinaproblem
• Practice– Taskcreations,interactionsandmappingtoPEs.• Realizingconcurrencypractically
– Characteristicsoftasksandtaskinteractions• Impactchoiceandperformanceofparallelism
• Characteristicsoftasks– Taskgenerationstrategies– Tasksizes(theamountofwork,e.g.FLOPs)– Sizeofdataassociatedwithtasks

TaskGeneration
15
• Statictaskgeneration– Concurrenttasksandtaskgraphknowna-priori (beforeexecution)– Typicallyusingrecursiveordatadecomposition– Examples• Matrixoperations• Graphalgorithms• Imageprocessingapplications• Otherregularly structuredproblems
• Dynamictaskgeneration– Computationsformulateconcurrenttasksandtaskgraphonthefly• Notexplicitapriori,thoughhigh-levelrulesorguidelinesknown
– Typicallybyexploratoryorspeculativedecompositions.• Alsopossiblebyrecursivedecomposition,e.g.quicksort
– Aclassicexample:gameplaying• 15puzzleboard

TaskSizes/Granularity
16
• Theamountofworkà amountoftimetocomplete– E.g.FLOPs,#memoryaccess• Uniform:– Oftenbyeven datadecomposition,i.e.regular• Non-uniform– Quicksort,thechoiceofpivot

SizeofDataAssociatedwithTasks
17
• Maybesmallorlargecomparedtothetasksizes– Howrelevanttotheinputand/oroutputdatasizes– Example:• size(input)<size(computation),e.g.,15puzzle• size(input)=size(computation)>size(output),e.g.,min• size(input)=size(output)<size(computation),e.g.,sort
• Consideringtheeffortstoreconstructthesametaskcontext– smalldata:smallefforts:taskcaneasilymigratetoanother
process– largedata:largeefforts:tiesthetasktoaprocess• Contextreconstructingvs communicating– Itdepends

CharacteristicsofTaskInteractions
• Aspects of interactions– What: shared data or synchronizations, and sizes of the media– When: the timing– Who: with which task(s), and overall topology/patterns– Do we know details of the above three before execution– How: involve one or both?• The implementation concern, implicit or explicit
Orthogonalclassification• Staticvs.dynamic• Regularvs.irregular• Read-onlyvs.read-write• One-sidedvs.two-sided
18

CharacteristicsofTaskInteractions
• Aspects of interactions– What: shared data or synchronizations, and sizes of the media– When: the timing– Who: with which task(s), and overall topology/patterns– Do we know details of the above three before execution– How: involve one or both?
• Static interactions– Partners and timing (and else) are known a-priori– Relatively simpler to code into programs.• Dynamic interactions– The timing or interacting tasks cannot be determined a-priori.– Harder to code, especially using explicit interaction.
19

CharacteristicsofTaskInteractions
20
• Aspects of interactions– What: shared data or synchronizations, and sizes of the media– When: the timing– Who: with which task(s), and overall topology/patterns– Do we know details of the above three before execution– How: involve one or both?
• Regular interactions– Definite pattern of the interactions• E.g. a mesh or ring
– Can be exploited for efficient implementation.• Irregularinteractions– lackwell-definedtopologies– Modeledasagraph

ExampleofRegular StaticInteraction
21
Imageprocessingalgorithms:dithering,edgedetection• Nearestneighborinteractionsona2Dmesh

ExampleofIrregular StaticInteraction
22
Sparsematrixvectormultiplication

CharacteristicsofTaskInteractions
23
• Aspects of interactions– What: shared data or synchronizations, and sizes of themedia
• Read-onlyinteractions– Tasksonlyreaddataitemsassociatedwithothertasks• Read-writeinteractions– Read,aswellasmodifydataitemsassociatedwithothertasks.– Hardertocode• Requireadditionalsynchronizationprimitives– toavoidread-writeandwrite-writeorderingraces
Shareddata
T2T1 write
read

CharacteristicsofTaskInteractions
24
• Aspects of interactions– What: shared data or synchronizations, and sizes of the media– When: the timing– Who: with which task(s), and overall topology/patterns– Do we know details of the above three before execution– How: involve one or both?• The implementation concern, implicit or explicit
• One-sided– initiated&completedindependentlyby1of2interactingtasks• GETandPUT
• Two-sided– bothtaskscoordinateinaninteraction• SEND+RECV

Today’slecture
• DecompositionTechniques- continued– ExploratoryDecomposition– HybridDecomposition
Mappingtaskstoprocesses/cores/CPU/PEs• CharacteristicsofTasksandInteractions– TaskGeneration,Granularity,andContext– CharacteristicsofTaskInteractions• MappingTechniquesforLoadBalancing– StaticandDynamicMapping• MethodsforMinimizingInteractionOverheads• ParallelAlgorithmDesignModels
25

MappingTechniques
26
• Parallelalgorithmdesign– Programdecomposed– Characteristicsoftaskandinteractionsidentified
Assignlargeamountofconcurrenttaskstoequalorrelativelysmallamountofprocessesforexecution• Thoughoftenwedo1:1mapping

MappingTechniques
27
• Goalofmapping:minimizeoverheads– Thereiscosttodoparallelism• Interactions and idling(serialization)
• Contradictingobjectives:interactionsvs idling– Idling(serialization)ñ:insufficientparallelism– Interactionsñ:excessiveconcurrency
– E.g.Assigningallworktooneprocessortriviallyminimizesinteractionattheexpenseofsignificantidling.

MappingTechniquesforMinimumIdling
28
• Execution:alternatingstagesofcomputationandinteraction
• Mappingmustsimultaneouslyminimizeidlingandloadbalance– Idlingmeansnotdoingusefulwork– Loadbalance:doingthesameamountofwork• Merelybalancingloaddoesnotminimizeidling
Apoormapping,50%waste

MappingTechniquesforMinimumIdling
Staticordynamic mapping• StaticMapping– Tasksaremappedtoprocessesa-prior– Needagoodestimateoftasksizes– OptimalmappingmaybeNPcomplete
• DynamicMapping– Tasksaremappedtoprocessesatruntime– Because:• Tasksaregeneratedatruntime• Theirsizesarenotknown.
• Otherfactorsdeterminingthechoiceofmappingtechniques– thesizeofdataassociatedwithatask– thecharacteristicsofinter-taskinteractions– eventheprogrammingmodelsandtargetarchitectures
29

SchemesforStaticMapping
• Mappingsbasedondatadecomposition– Mostly1-1mapping
• Mappingsbasedontaskgraphpartitioning• Hybridmappings
30

MappingsBasedonDataPartitioning
31
• Partitionthecomputationusingacombinationof– Datadecomposition– The``owner-computes''rule
Example:1-Dblockdistribution of2-Ddensematrix1-1mappingoftask/dataandprocess
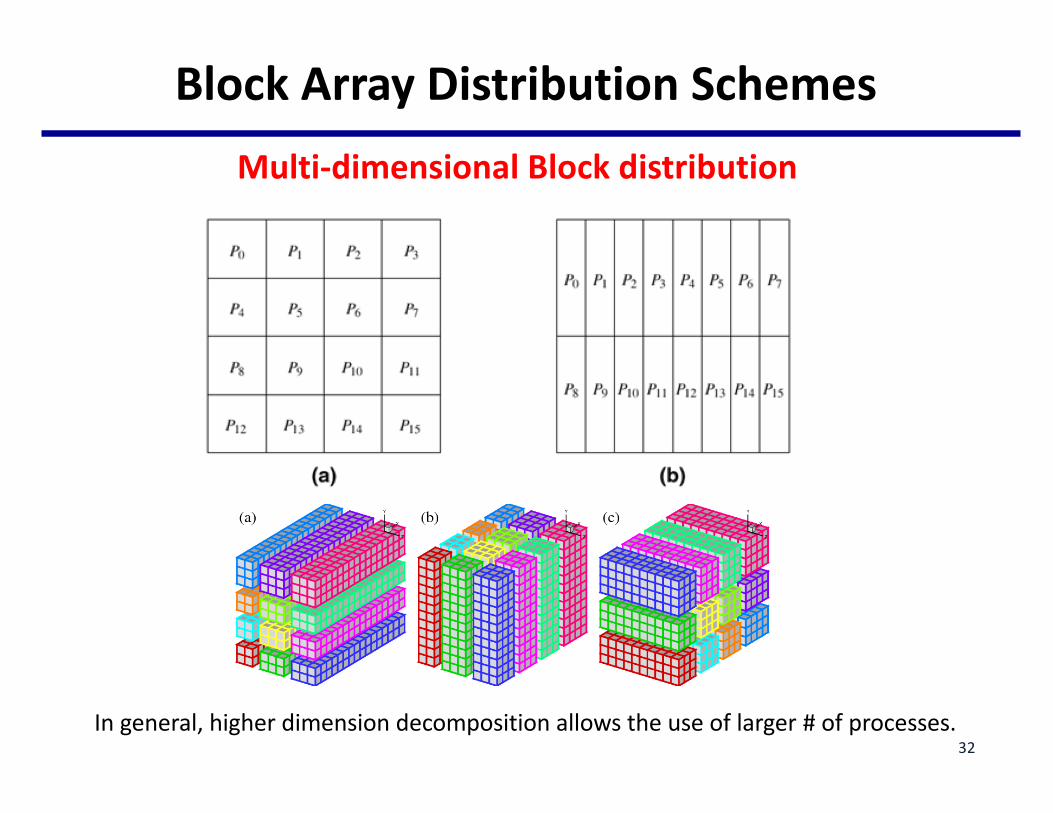
BlockArrayDistributionSchemes
32
Multi-dimensionalBlockdistribution
Ingeneral,higherdimensiondecompositionallowstheuseoflarger#ofprocesses.

BlockArrayDistributionSchemes:Examples
Multiplyingtwodensematrices:A*B=C• PartitiontheoutputmatrixC usingablockdecomposition– Loadbalance:Eachtaskcomputethesamenumberof
elementsofC• Note:eachelementofCcorrespondstoasingledotproduct
– Thechoiceofprecisedecomposition:1-D(row/col)or2-D• Determinedbytheassociatedcommunicationoverhead
33

BlockDistributionandDataSharingforDenseMatrixMultiplication
34
X=
AXB=C
P0P1P2P3
X=
AXB=C
P0P1P2P3
• Row-based1-D
• Column-based1-D
• Row/Col-based2-D

CyclicandBlockCyclicDistributions
• ConsiderablockdistributionforLUdecomposition(GaussianElimination)– Theamountofcomputationperdataitemvaries– Blockdecompositionwouldleadtosignificantloadimbalance
35

LUFactorizationofaDenseMatrix
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
36
AdecompositionofLUfactorizationinto14tasks

BlockDistributionforLU
Noticethesignificantloadimbalance
37

BlockCyclicDistributions
• Variationoftheblockdistributionscheme– Partitionanarrayintomanymoreblocks(i.e.tasks)thanthe
numberofavailableprocesses.– Blocksareassignedtoprocessesinaround-robinmannerso
thateachprocessgetsseveralnon-adjacentblocks.– N-1mappingoftaskstoprocesses• Usedtoalleviatetheload-imbalanceandidlingproblems.
38

Block-CyclicDistributionforGaussianElimination
39
• Activesubmatrix shrinksaseliminationprogresses• Assigningblocksinablock-cyclicfashion– EachPEsreceivesblocksfromdifferentpartsofthematrix– Inonebatchofmapping,thePEdoingthemostwillmostlikely
receivetheleastinthenextbatch

Block-CyclicDistribution
• Acyclicdistribution:aspecialcasewithblocksize=1• Ablockdistribution:aspecialcasewithblocksize= n/p• n isthedimensionofthematrixandp isthe#ofprocesses.
40

BlockPartitioningandRandomMapping
Sparsematrixcomputations• Loadimbalanceusingblock-cyclicpartitioning/mapping– morenon-zeroblockstodiagonalprocessesP0,P5,P10,and
P15thanothers– P12getsnothing
41

BlockPartitioningandRandomMapping
42

GraphPartitioningBasedDataDecomposition
• Array-basedpartitioningandstaticmapping– Regulardomain,i.e.rectangular,mostlydensematrix– Structuredandregularinteractionpatterns– Quiteeffectiveinbalancingthecomputationsandminimizing
theinteractions
• Irregulardomain– Sparsmatrix-related– Numericalsimulationsofphysicalphenomena• Car,water/bloodflow,geographic
• Partitiontheirregulardomainsoasto– Assignequalnumberofnodestoeachprocess– Minimizingedgecountofthepartition.
43
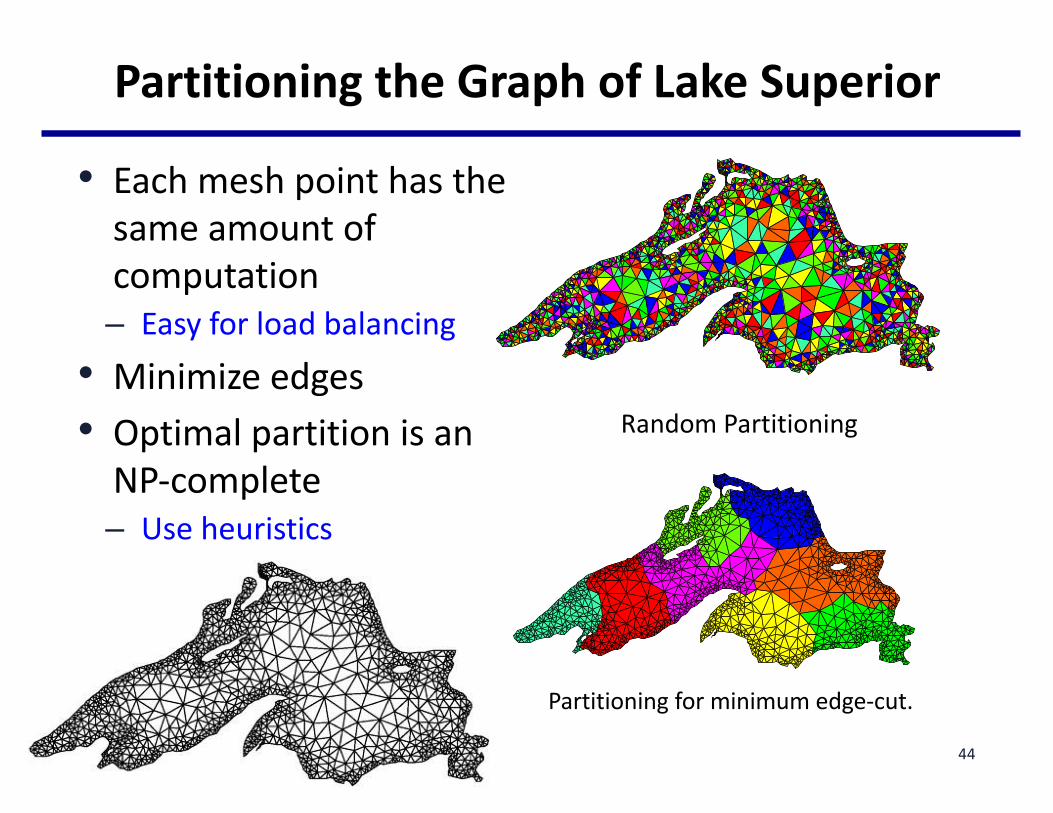
PartitioningtheGraphofLakeSuperior
RandomPartitioning
Partitioningforminimumedge-cut.
44
• Eachmeshpointhasthesameamountofcomputation– Easyforloadbalancing• Minimizeedges• OptimalpartitionisanNP-complete– Useheuristics

MappingsBasedonTaskParitioning
• SchemesforStaticMapping– Mappingsbasedondatapartitioning• Mostly1-1mapping
– Mappingsbasedontaskgraphpartitioning– Hybridmappings
• Datapartitioning– Data decompositionandthen1-1mappingoftaskstoPEs
Partitioningagiventask-dependencygraphacrossprocesses• Anoptimalmappingforageneraltask-dependencygraph– NP-completeproblem.• Excellentheuristicsexistforstructuredgraphs.
45

MappingaBinaryTreeDependencyGraph
46
Mappingdependencygraphofquicksorttoprocessesinahypercube
• Hypercube:n-dimensionalanalogueofasquareandacube– nodenumbersthatdifferin1bitareadjacent
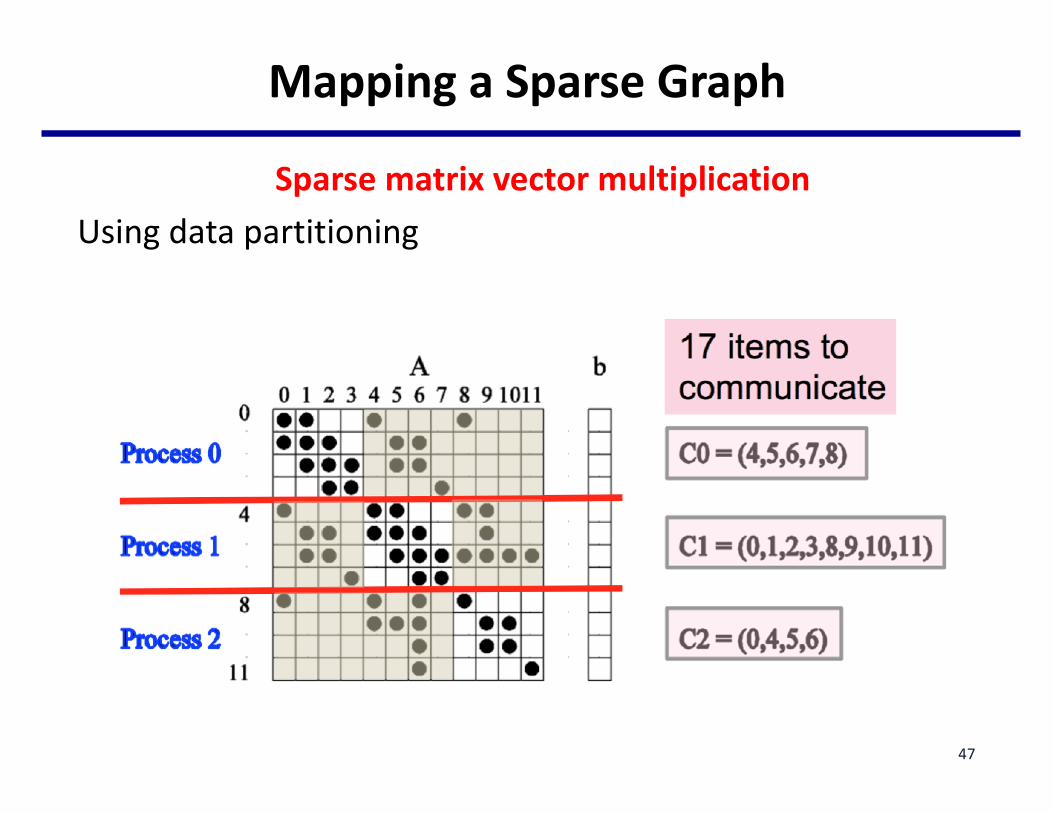
MappingaSparseGraph
SparsematrixvectormultiplicationUsingdatapartitioning
47

MappingaSparseGraph
SparsematrixvectormultiplicationUsingtaskgraphpartitioning
48
13itemstocommunicate
Process0 0,4,5,8Process1 1,2,3,7
Process2 6,9,10,11

Hierarchical/HybridMappings
• A singlemappingisinadequate.– E.g.taskgraphmappingofthebinarytree(quicksort)cannot
usealargenumberofprocessors.• Hierarchicalmapping– Taskgraphmappingatthetoplevel– Datapartitioningwithineachlevel.
49

Today’slecture
• DecompositionTechniques- continued– ExploratoryDecomposition– HybridDecomposition
Mappingtaskstoprocesses/cores/CPU/PEs• CharacteristicsofTasksandInteractions– TaskGeneration,Granularity,andContext– CharacteristicsofTaskInteractions• MappingTechniquesforLoadBalancing– StaticMapping– DynamicMapping• MethodsforMinimizingInteractionOverheads• ParallelAlgorithmDesignModels
50

SchemesforDynamicMapping
• Alsoreferredtoasdynamicloadbalancing– Loadbalancingistheprimarymotivationfordynamic
mapping.• Dynamicmappingschemescanbe– Centralized– Distributed
51

CentralizedDynamicMapping
• Processesaredesignatedasmasters orslaves– Workers(slaveispoliticallyincorrect)• Generalstrategies– Masterhaspooloftasksandascentraldispatcher– Whenonerunsoutofwork,itrequestsfrommasterformorework.• Challenge– Whenprocess#increases,mastermaybecomethebottleneck.• Approach– Chunkscheduling:aprocesspicksupmultipletasksatonce– Chunksize:• Largechunksizesmayleadtosignificantloadimbalancesaswell• Schemestograduallydecreasechunksizeasthecomputationprogresses.
52

DistributedDynamicMapping
• Allprocessesarecreatedequal– Eachcansendorreceiveworkfromothers• Alleviatesthebottleneckincentralizedschemes.
• Fourcriticaldesignquestions:– howaresendingandreceivingprocessespairedtogether– whoinitiatesworktransfer– howmuchworkistransferred– whenisatransfertriggered?• Answersaregenerallyapplicationspecific.
• Workstealing
53

Today’slecture
• DecompositionTechniques- continued– ExploratoryDecomposition– HybridDecomposition
Mappingtaskstoprocesses/cores/CPU/PEs• CharacteristicsofTasksandInteractions– TaskGeneration,Granularity,andContext– CharacteristicsofTaskInteractions• MappingTechniquesforLoadBalancing– StaticandDynamicMapping• MethodsforMinimizingInteractionOverheads• ParallelAlgorithmDesignModels
54

MinimizingInteractionOverheads
Rulesofthumb• Maximizedatalocality– Wherepossible,reuseintermediatedata– Restructurecomputationsothatdatacanbereusedinsmaller
timewindows.• Minimizevolumeofdataexchange– partitioninteractiongraphtominimizeedgecrossings• Minimizefrequencyofinteractions– Mergemultipleinteractionstoone,e.g.aggregatesmallmsgs.• Minimizecontentionandhot-spots– Usedecentralizedtechniques– Replicatedatawherenecessary
55

MinimizingInteractionOverheads(continued)
Techniques• Overlappingcomputationswithinteractions– Usenon-blockingcommunications– Multithreading– Prefetchingtohidelatencies.• Replicatingdataorcomputationstoreducecommunication• Usinggroupcommunicationsinsteadofpoint-to-pointprimitives.
• Overlapinteractionswithotherinteractions.
56

Today’slecture
• DecompositionTechniques- continued– ExploratoryDecomposition– HybridDecomposition
Mappingtaskstoprocesses/cores/CPU/PEs• CharacteristicsofTasksandInteractions– TaskGeneration,Granularity,andContext– CharacteristicsofTaskInteractions• MappingTechniquesforLoadBalancing– StaticandDynamicMapping• MethodsforMinimizingInteractionOverheads• ParallelAlgorithmDesignModels
57

ParallelAlgorithmModels
• Waysofstructuringparallelalgorithm– Decompositiontechniques– Mappingtechnique– Strategytominimizeinteractions.
• DataParallelModel– Eachtaskperformssimilaroperationsondifferentdata– Tasksarestatically(orsemi-statically)mappedtoprocesses• TaskGraphModel– Usetaskdependencygraph toguidethemodelforbetter
localityorlowinteractioncosts.
58

ParallelAlgorithmModels(continued)
• Master-SlaveModel– Master(oneormore)generatework– Dispatchworktoworkers.– Dispatchingmaybestaticordynamic.• Pipeline/Producer-ConsumerModel– Streamofdataispassedthroughasuccessionofprocesses,
eachofwhichperformsometaskonit– Multiplestreamconcurrently• HybridModels– Applyingmultiplemodelshierarchically– Applyingmultiplemodelssequentiallytodifferentphasesofa
parallelalgorithm.
59

References
• Adaptedfromslides“PrinciplesofParallelAlgorithmDesign”byAnanth Grama
• BasedonChapter3of“IntroductiontoParallelComputing”byAnanth Grama,Anshul Gupta,GeorgeKarypis,andVipinKumar.AddisonWesley,2003
60
Recommended

















