
Instruction Level Parallelism
Appendix C and Chapter 3, HP5e

Outline● Pipelining, Hazards● Branch prediction● Static and Dynamic Scheduling● Speculation● Compiler techniques, VLIW● Limits of ILP.

Pipelining Basics

Implementation of RISC ISA - Stages● Instruction Fetch (IF)● Instruction Decode/Register Fetch (ID)
– Fixed field decoding
● Execution/Effective address (EX)● Memory Access (MEM)● Write back (WB)
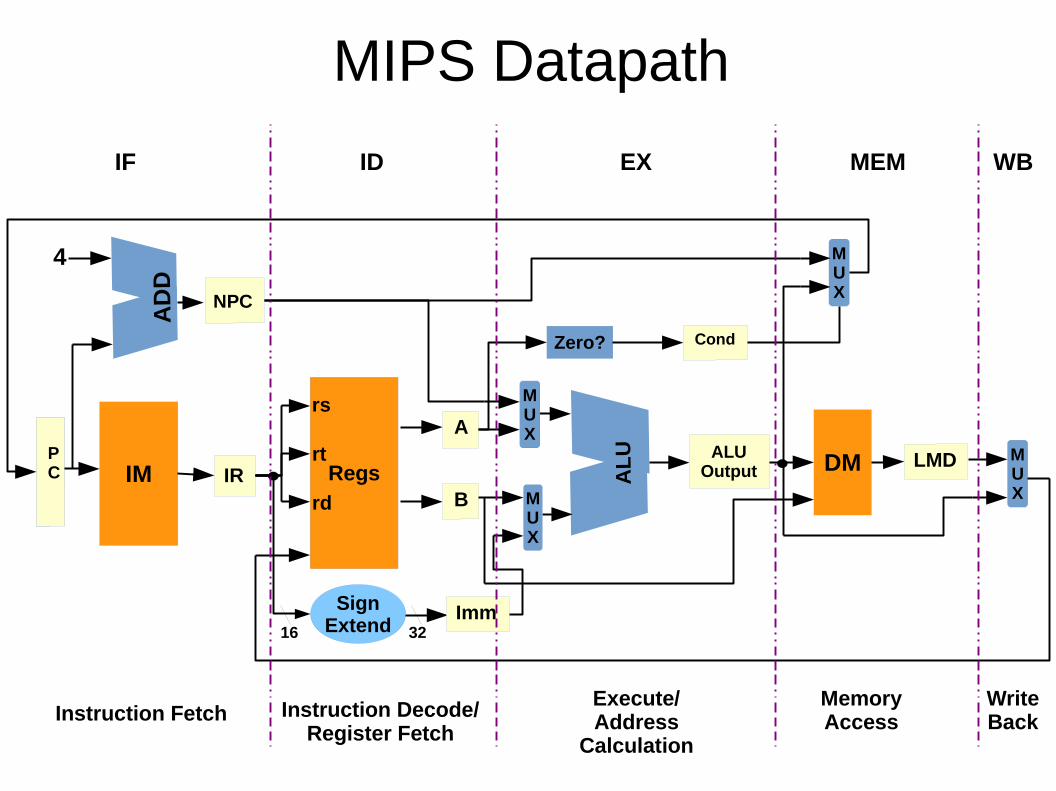
MIPS Datapath
AD
D
PC
4
IM
NPC
RegsIR
SignExtend
A
B
Imm16 32
rs
rt
rd
AL
U ALUOutput
MUX
MUX
Zero? Cond
DM LMD MUX
MUX
Instruction Fetch Instruction Decode/Register Fetch
Execute/Address
Calculation
MemoryAccess
WriteBack
IF ID EX MEM WB

Multiple Issue Integer Pipeline
IMRF
Read
AB
DM
RF
Write
IR0
IR1
Zero?
IF ID EX MEM WB

Pipeline PerformanceAn unpipelined processor has 1ns clock cycle. ALU Operation and branches take 4 cycles and Memory ops take 5 cycles. Relative frequencies of the operations are 40%, 20%, and 40%. Suppose Clock skew and setup, pipelining adds 0.2ns of overhead to the clock. What is the speedup?
Average Instruction Execution time = Clock cycle * Average CPI
CPI=∑i=1
n IC i
InstructionCount×CPI i

Dependences
Pipeline Hazards – Structural & Data

Outline● Data dependences● Name dependences● Structural hazards● Data hazards
– Stalling, Forwarding

Basic Block● A straight line code sequence with no branches in
except to the entry and no branches out except at the exit
Loop: L.D F0, 0(R1)
ADD.D F4, F0, F2
S.D F4, 0(R1)
DADDUI R1, R1, #-8
BNE R1, R2, Loop

Dependence
● Name dependences
– Register renaming● Hazard
– Overlap during execution could change the order of access to the operand involved in the dependence.
for (i=0; i<=999; i=i+1)x[i] = x[i] + a;
Loop: L.D F0, 0(R1)
ADD.D F4, F0, F2
S.D F4, 0(R1)
DADDUI R1, R1, #-8
BNE R1, R2, LoopData Dependence (RAW)Name Dependences (WAR, WAW)
ADD.D F4, F0, F2ADD.D F4, F6, F8

Hazards● Program Order
– ILP preserves program order only where it affects the outcome of the program
● Structural Hazards– Resource conflicts
● Data Hazards– RAW, WAW, WAR
● Control Hazard– Whether or not an instruction should be executed
depends on a control decision made by an earlier instruction

Structural Hazard
MEM ID EX MEM WB
MEM ID EX MEM WB
MEM ID EX MEM WB
MEM ID EX MEM WB
i1
i2
i3
i4
...
1 2 3 4 5 6 7 8 9
MEM ID EX MEM WBi5
HAZARD!!!
● Unified Memory example● Register File – WB, ID example.

Cost of a Load Structural Hazard● Data references constitute 40% of the instruction
mix. Ideal CPI = 1 (with no structural hazards). Assume that the processor with the structural hazard has a clock rate that is 1.1 times higher than the clock rate of the processor without the hazard. Which processor is faster, and by how much?
Avg. InstructionTime =CPI×Clock cycle time
Avg. InstructionTime ideal=CPI×Clock cycle timeideal

Cost of a Load Structural Hazard
Avg. InstructionTime =CPI×Clock cycle time
Avg. InstructionTime =(1+0.4×1)×Clock cycle timeideal
1.1
Avg. InstructionTime =1.27×Clock cycle timeideal

Data HazardsA
DD
PC
4
IM
NPC
RegsIR
SignExtend
A
B
Imm16 32
rs
rt
rd
AL
U ALUOutput
MUX
MUX
Zero? Cond
DM LMD MUX
MUX
IR IR IR
R1 ← R2 + R3
R4 ← R1 + R5
R1 is updated in the WB stage.
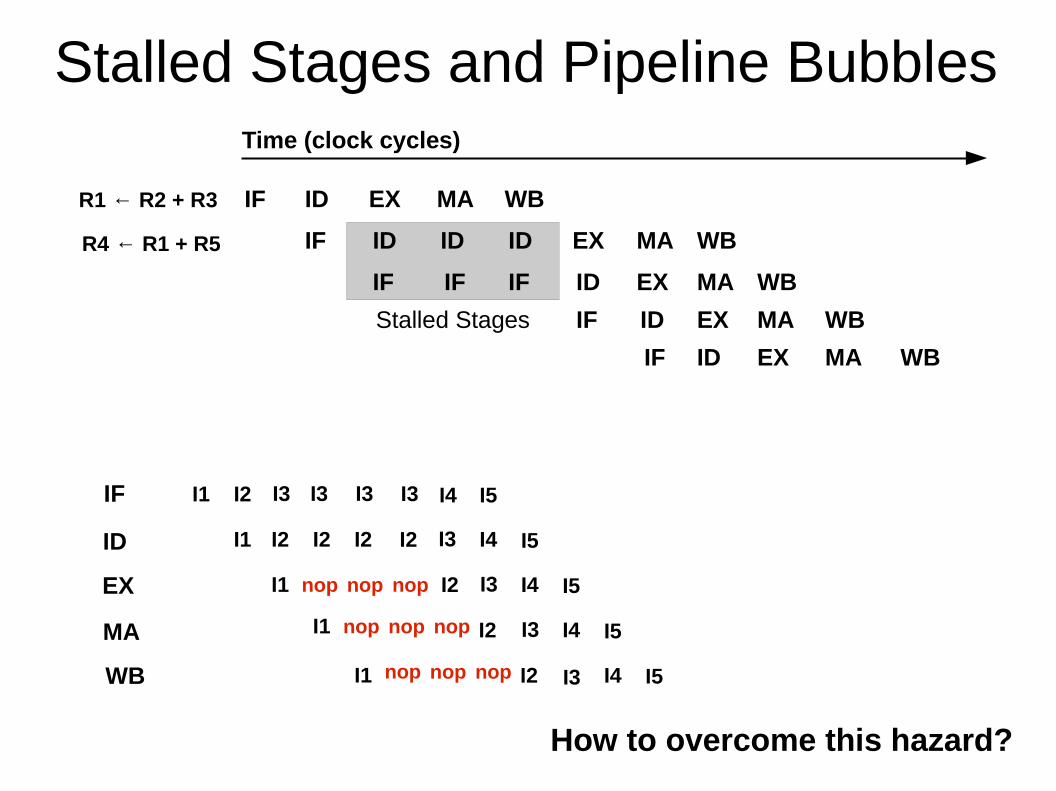
Stalled Stages and Pipeline BubblesTime (clock cycles)
R1 ← R2 + R3
R4 ← R1 + R5
IF ID
IF
EX MA WB
ID
IF
EX MA WB
IF IF
ID ID
EX MA WBID
I1 I2 I3
I4
Stalled Stages EX MA WBIDIF
I5
EX MA WBIDIF
EX
MA
WB
ID
IF
I1
I1
I1
I1
I2 I2 I2 I2
I2
I2
I2
I3 I3 I3
I3
I3
I3
I3
I4
I4
I4
I4
I5
I5
I5
I5
nop nop nop
nop nop nop
nop nop nop
How to overcome this hazard?

Resolving Data Hazards● Stalling one of the instructions● Data Forwarding (Bypassing)● Scheduling hazardous instructions away from
each other
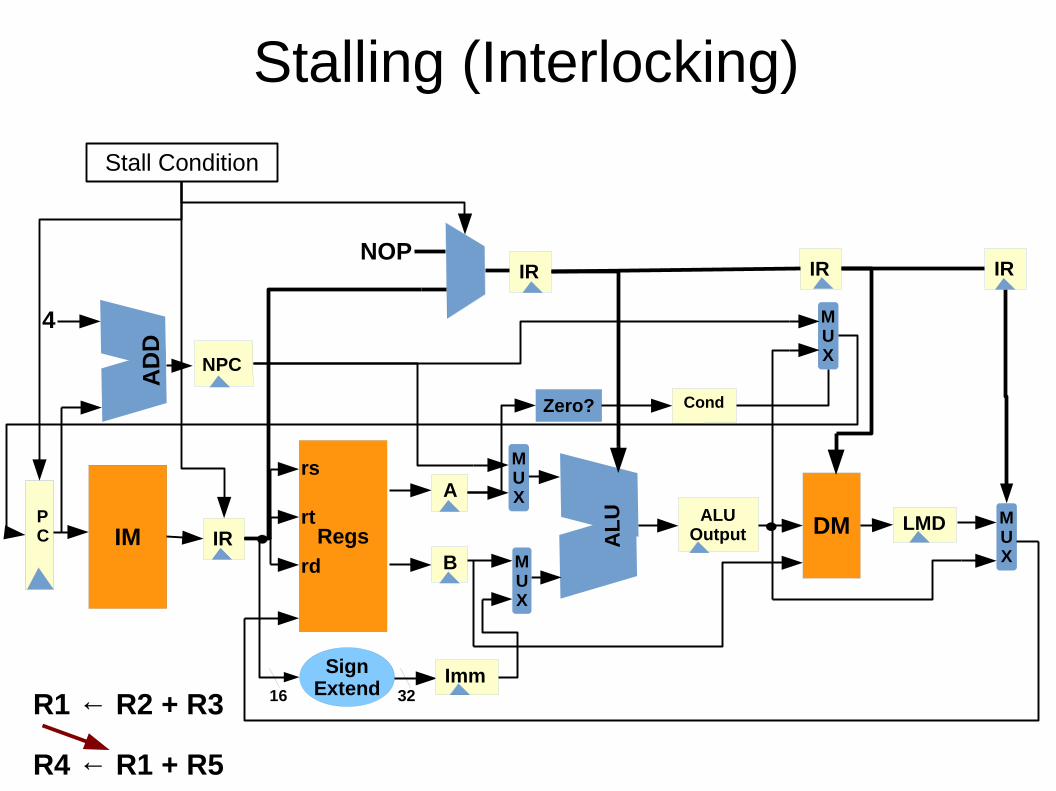
Stalling (Interlocking)A
DD
PC
4
IM
NPC
RegsIR
SignExtend
A
B
Imm16 32
rs
rt
rd
AL
U ALUOutput
MUX
MUX
Zero? Cond
DM LMD MUX
MUX
IR IR IR
R1 ← R2 + R3
R4 ← R1 + R5
NOP
Stall Condition
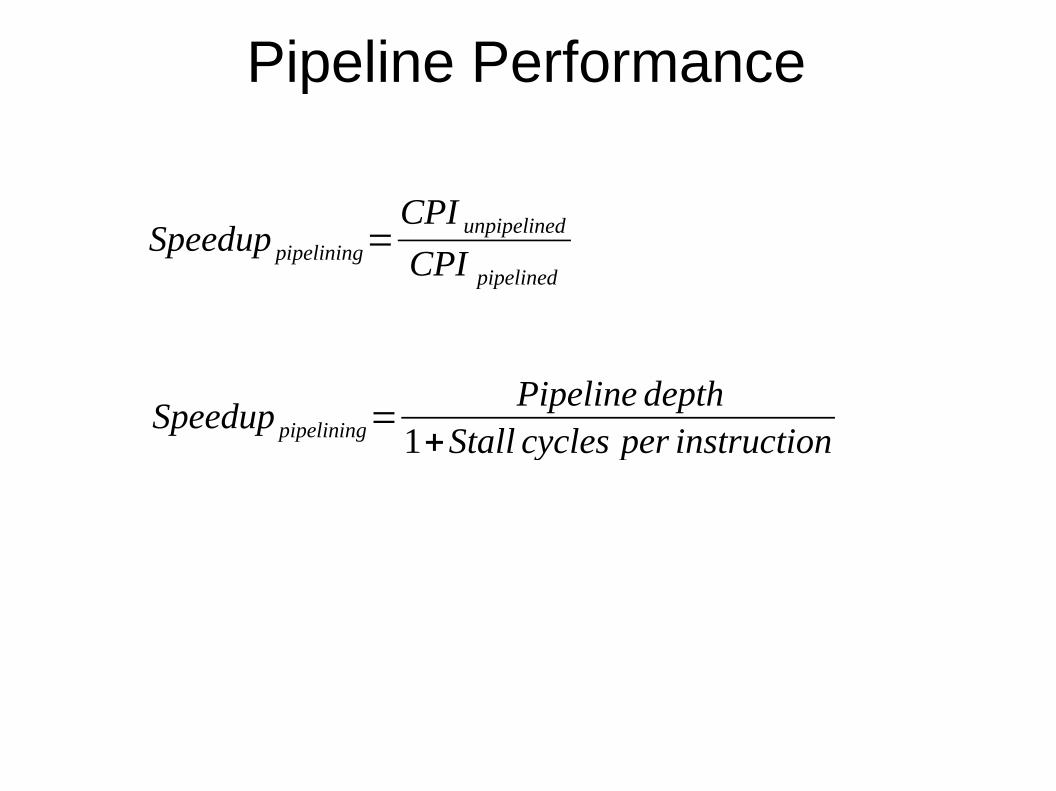
Pipeline Performance
Speedup pipelining=Pipeline depth
1+Stall cycles per instruction
Speedup pipelining=CPI unpipelined
CPI pipelined

ForwardingDADDDSUBANDORXOR
R4,R1,R5R6,R1,R7
R1,R2,R3
R8,R1,R9R10,R1,R11
IM REG DMDADD
DSUB
AND
Time (clock cycles)
ALU REG
IM REG DMALU REG
IM REG DMALU REG

Forwarding
Time (clock cycles)
R1 ← R2 + R3
R4 ← R1 + R5
IF ID
IF
EX MA WB
ID
IF
EX MA WB
IF IF
ID ID
EX MA WBIDIF
ID
Stalled Stages
Before Bypassing
Time (clock cycles)
R1 ← R2 + R3
R4 ← R1 + R5
IF ID
IF
EX MA WB
EX MA WBID
After Bypassing
CPI > 1
CPI = 1IF EX MA WBID

Cost of Forwarding
● In longer pipelines?● In multiple issue pipelines?
● All the dependences have been solved?
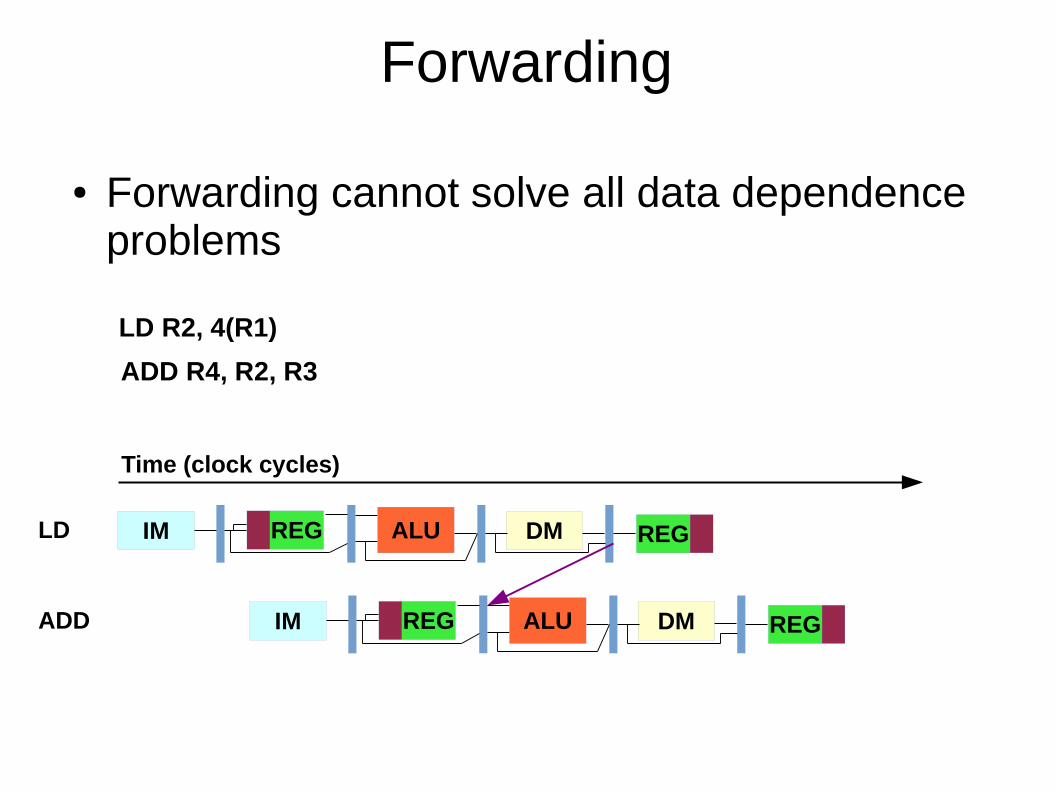
Forwarding
● Forwarding cannot solve all data dependence problems
LD R2, 4(R1)
ADD R4, R2, R3
IM REG DMLD
ADD
Time (clock cycles)
ALU REG
IM REG DMALU REG
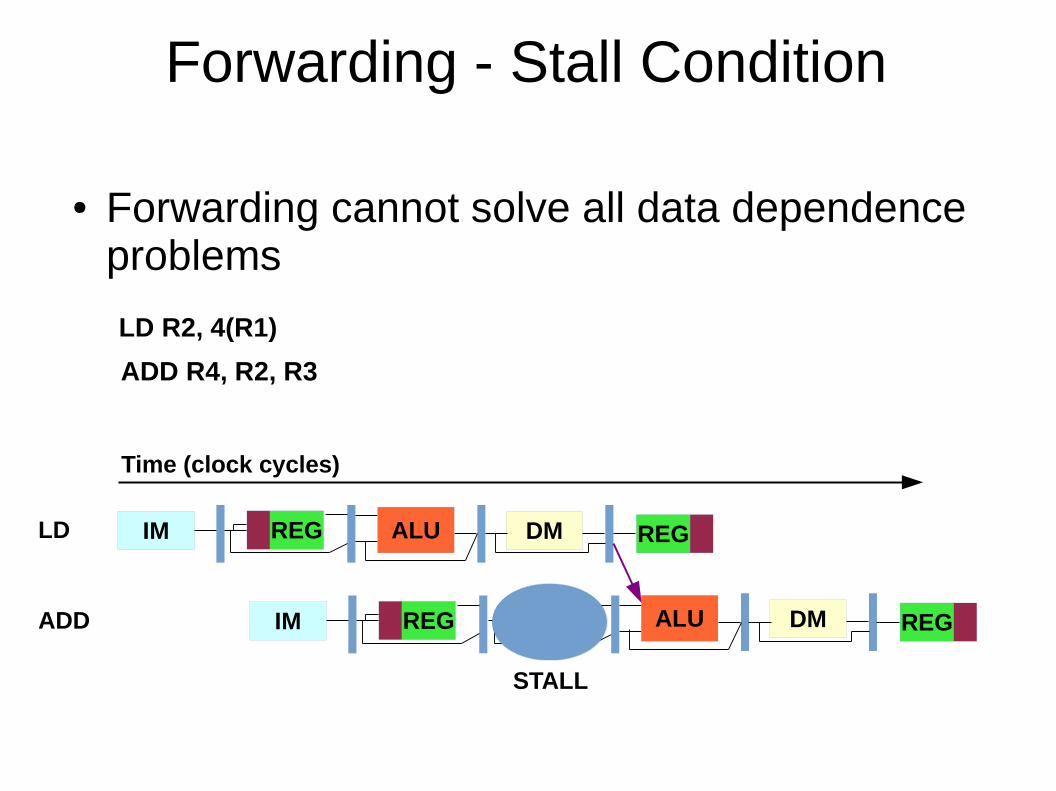
Forwarding - Stall Condition
● Forwarding cannot solve all data dependence problems
LD R2, 4(R1)
ADD R4, R2, R3
IM REG DMLD
ADD
Time (clock cycles)
ALU REG
IM REG DMALU REGREG
STALL

Instruction Level Parallelism
Static Scheduling

Outline
● ILP● Multicycle instructions● Loop unrolling, scheduling● Superscalar pipelines

ILP● Instruction-level parallelism: overlap among
instructions: pipelining or multiple instruction execution
● What determines the degree of ILP?– dependences: property of the program
– hazards: property of the pipeline

Pipeline Scheduling● Reorder instructions so that dependent instructions are
far enough apart
● Done by the compiler, before the program runs:
● Static Instruction Scheduling
● Done by the hardware, when the program is running:
● Dynamic Instruction Scheduling

Static vs. Dynamic Scheduling● Dynamic scheduling:
– requires complex structures to identify independent instructions (scoreboards, issue queue)
– high power consumption
– low clock speed
– high design and verification effort
● Static: Compiler can compute instruction latencies and dependences
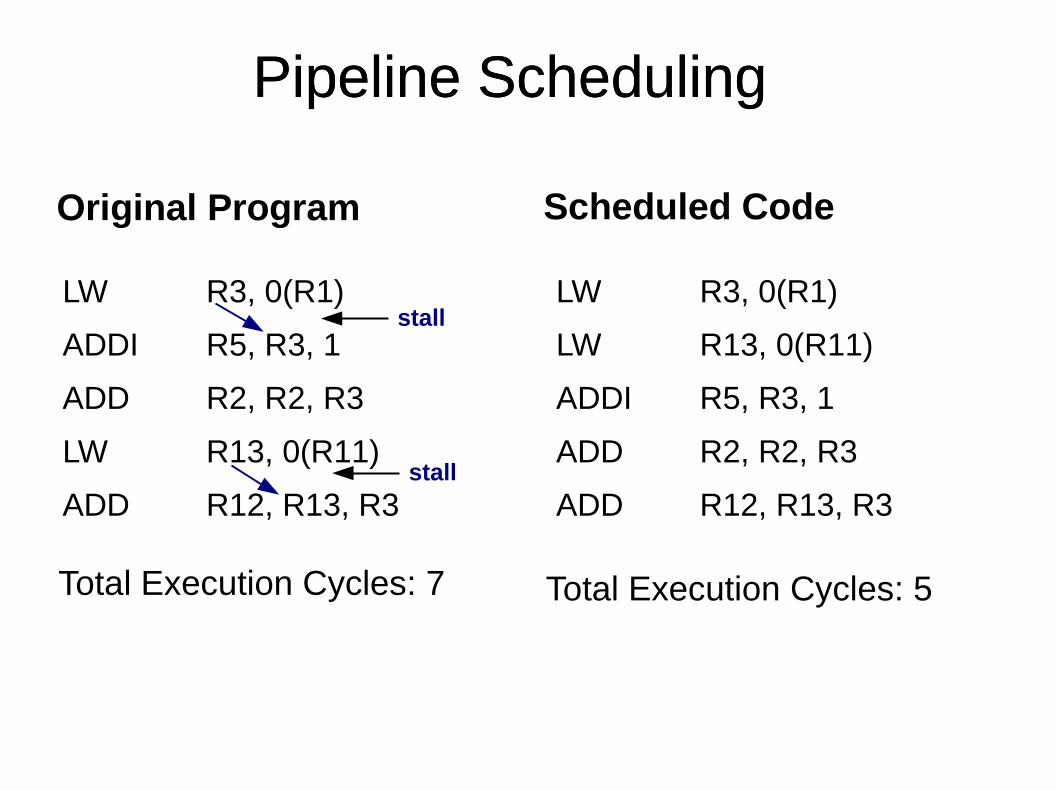
Pipeline Scheduling
LW R3, 0(R1)
LW R13, 0(R11)
ADDI R5, R3, 1
ADD R2, R2, R3
ADD R12, R13, R3
LW R3, 0(R1)
ADDI R5, R3, 1
ADD R2, R2, R3
LW R13, 0(R11)
ADD R12, R13, R3
stall
stall
Original Program
Pipeline Scheduling
Scheduled Code
Total Execution Cycles: 7 Total Execution Cycles: 5

References● HP5e. Chapter 3 – Instruction-Level Parallelism
and Its Exploitation.● HP5e. Appendix A – Instruction Set Principles.● HP5e. Appendix C – Pipelining: Basic and
Intermediate Concepts.● HP5e. Appendix H – Hardware and Software for
VLIW and EPIC.
Recommended

















