
Content-Mining for Clinical TrialsPeter Murray-Rust
contentmine.orgCochrane UK, Oxford, 2015-03-16
• OPEN Platform for Machines+humansto automatically “read” the trials literature
• Grow communities and give everyonethe tools and know-how to mine trials

• 09:30 - Introductions10:00 - Overview of ContentMine10:30 - Discussion: why might content mining clinical trials be useful?11:00 - Tea/coffee break11:15 - Discussion: current tools and what is needed12:00 - Discussion: imagining the clinical trials mining pipeline12:30 - Lunch13:30 - Demo and introduction to software14:30 - Technical session 1 (hands-on content mining)15:30 - Tea/coffee break15:45 - Technical session 2 (hands-on content mining)17:00 - Event close

Background for Today• Contentmine aims to make large areas of scientific fact OPEN (100
million facts/year)• We’re working with WellcomeTrust, Europe PubMedCentral, etc.• A politically “hot” area (Hargreaves legislation, EU activity)• A week ago WellcomeTrust workshop on TDM and Neuroscience;
“rough consensus” on what was needed.• In the last few days we’ve prototyped what we think is a good
starting point…• NOTE: The software is very “bleeding edge”! Please treat in a spirit
of adventure!!
• Vision/enthusiasm from Amy Price, Anna Noel-Storr, Emily Sena(E’burgh) and yourselves!

Questions we could tackle
• How to we find (mentions of) clinical trials?
• Is a document a (clinical) trial?
• What is the subject of the trial?
• What is the methodology used?
• Does the design and practice conform to CONSORT?
• What are the outcomes?
• Can we extract specific re-usable information?
• Who are involved? (researchers, sponsors, patients?)
• Has a proposed trial been completed and reported?

Afternoon session
• Work in groups; mixture of skills and experience
• Take different sections of CONSORT
• Scrape articles from trialsjournal.com
• Explore word frequency – create your own lists of frequent words
• Design regexes to extract CONSORT 8a->11

https://en.wikipedia.org/wiki/Irrigation#mediaviewer/File:Pump-enabled_Riverside_Irrigation_in_Comilla,_Bangladesh,_25_April_2014.jpg CC BY-SA 3.0
Daily Stream of 100,000 Open Facts
Twitter?Indexed by CAT


What is “Content”?
http://www.plosone.org/article/fetchObject.action?uri=info:doi/10.1371/journal.pone.0111303&representation=PDF CC-BY
SECTIONS
MAPS
TABLES
CHEMISTRYTEXT
MATH
contentmine.org tackles these

What is “Content”?

Machine-Human symbioses
• Wikipedia
• Open StreetMap
We aim to make it trivial for a human+machineto mine the scientific literature.
By building Communities

ContentMine Workshops and Hackdays
Open Science Brazil, 2014-08
Easily distributed software
Get started in 30 mins
Build application in a morning
Start simple: bagOfWords, Stemming, Regex, templates

Oxford 2013
Berlin 2014
Delhi 2014
Jenny Molloy with mascot AMI

Workshops (1-hour -> full day or more)
2014-May->Nov• Budapest/Shuttleworth• Leicester Univ• Electronic Theses and Dissertations• Austrian Science Fund AT• OKFest DE• Eur. Bioinformatics Institute• Open Science Rio de Janeiro BR• Sci DataCon , Delhi IN• Univ of Chicago US• OpenCon 2014, Wash DC. US• JISC , London
Upcoming• LIBER • Cochrane• BL• Wellcome Trust (April)• WHO
Collaborators
• Wikimedia/Wikidata
• Mozilla
• Open Knowledge
• LIBER (European Research Libraries)
• British Library
• Wellcome Trust
• EBI (Eur. Bioinf. Inst.)
• JISC
• Open Access Button
• SPARC
• Creative Commons
• CORE
• EuropePubmedCentral

• CRAWL the web for scientific documents(articles, grey literature, repositories)• quickSCRAPE pages (text, graphics, images, data)• NORMA-lize page to semantic form
…Open semantic science …• MINE pages with your methods and tools (AMI)
• CAT-alogue results in searchable index• Automate daily process (CANARY)
contentmine.org Infrastructure
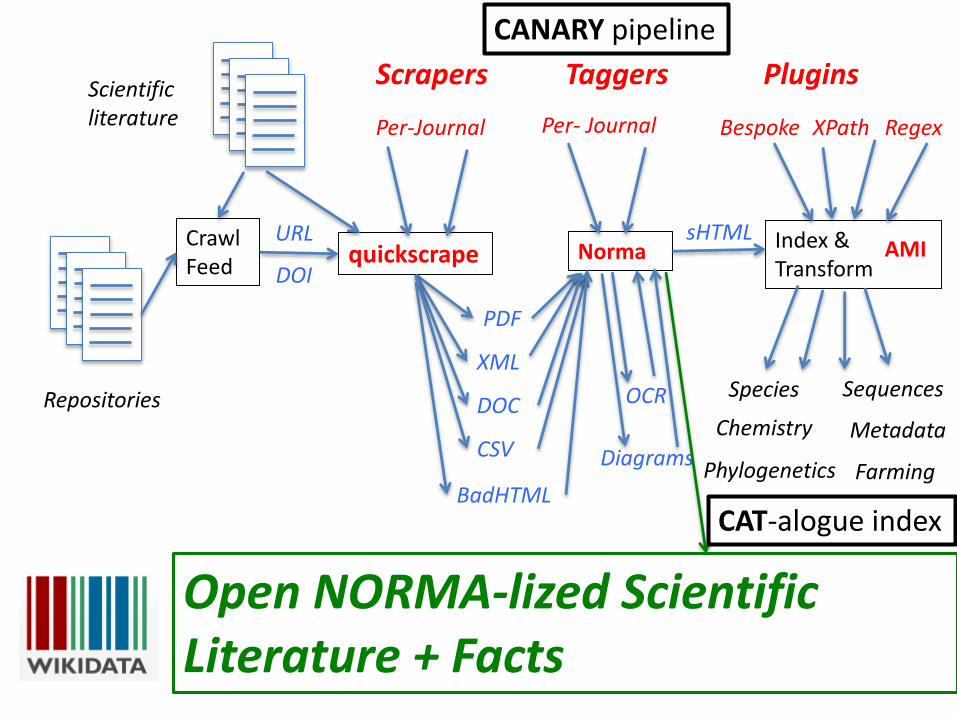
quickscrapeCrawlFeed
Norma Index &Transform
XML
URL
DOI
Scientificliterature
Repositories DOC
CSV
sHTML
Plugins
Regex
SequencesSpecies
Bespoke
Scrapers
XPathPer-Journal
Taggers
Per- Journal
MetadataChemistry
Phylogenetics Farming
AMI
BadHTML
OCR
Diagrams
Open NORMA-lized Scientific Literature + Facts
CANARY pipeline
CAT-alogue index

https://commons.wikimedia.org/wiki/File:Flickr_-_DVIDSHUB_-_RSP_Warrior_Challenge_Prepares_Soldiers_Mentally,_Physically_%281%29.jpg
CRAWLing the Literature
NO Central Table of Contents
Massive technical, political, legal opposition
Little interest from Academia
Tedious
Few general tools

The Right to Read is The Right To Mine
PMR in 2012: http://blog.okfn.org/2012/06/01/the-right-to-read-is-the-right-to-mine/

SCRAPE
https://en.wikipedia.org/wiki/Gleaning#mediaviewer/File:Millet_Gleaners.jpg PublicDomain
HTML
XML quickscrape*
*Scrapers created by Richard Smith-Unna +
Community
HTMLPDFXMLPNGSVGCSVDOCLaTeXCIF…
Non-standard per-publisher site

https://en.wikipedia.org/wiki/W._Heath_Robinson#mediaviewer/File:Robinson%28WH%29-%28%27Uncle_Lubin%27%29.jpg PublicDomain
NORMA-lization of Scientific Literature
PDFs, Broken HTMLPNGs for Math, etc.
NORMA
UnicodeDiacriticsWell-formedSectionedTaggedSVG diagrams

AMI-plugins
• BagOfWords, Stemming and Regular Expressions• Species• Biological Sequences• Chemical compounds & reactions
• Farming * (Rory Aaronson)
• Crystallography * (Saulius Grazulis, COD)• Clinical Trials * (Amy Price)
• Phylogenetics * (Ross Mounce)
• Phytochemistry * (Chris Steinbeck, PMR)
* subcommunities

Text-based plugins
• Bag of words (https://en.wikipedia.org/wiki/Bag-of-words_model)
• https://en.wikipedia.org/wiki/Tf%E2%80%93idf
(Term-frequency, inverse document frequency)
• Templates and regexes (regular expressions).

“Bag of Words”
Three fulltext articles from trialsjournal.com

Facts Marked by “non-scientists” in ContentMine workshops
With Wikipedia everyone can be a scientist

“nuggets” in a scientific paper
quantity
units
Value ranges
Humans aren’t designed to mine this … chemical
project places

Advanced Plugins

http://chemicaltagger.ch.cam.ac.uk/
• Typical
Typical chemical synthesis

Open Content Mining of FACTs
Machines can interpret chemical reactions
We have done 500,000 patents. There are > 3,000,000 reactions/year. Added value > 1B Eur.


UNITS
TICKS
QUANTITYSCALE
TITLES
DATA!!2000+ points

Dumb PDF
CSV
SemanticSpectrum
2nd Derivative
Smoothing Gaussian Filter
Automaticextraction

AMI https://bitbucket.org/petermr/xhtml2stm/wiki/Home
Example reaction scheme, taken from MDPI Metabolites 2012, 2, 100-133; page 8, CC-BY:
AMI reads the complete diagram, recognizes the paths and generates the molecules. Then she creates a stop-fram animation showing how the 12 reactions lead into each other
CLICK HERE FOR ANIMATION
(may be browser dependent)

https://blogs.ch.cam.ac.uk/pmr/2014/06/25/content-mining-we-can-now-mine-images-of-phylogenetic-trees-and-more/ for story of extraction
Thinning Topology
Serialization
Newick

Phytochemistry extraction
O. dayi
“volatile composition of “
A.sibeiri
A. judaica
Displayed by CAT (CottageLabs)

contentmine.org proposed Services
• Workshops
• Repository indexing
• Funder Compliance
• Publication enhancement
• Extraction of scientific data

contentmine.org team
Recommended


















