
Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Analisis Regresi 2
Pokok Bahasan :
Memilih Persamaan Regresi Terbaik
TUJUAN INSTRUKSIONAL KHUSUS :Mahasiswa dapat memilih persamaan regresi terbaik dengan
mencobakan berbagai prosedur.

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Analisis Regresi 2
Sub Pokok Bahasan :
SEMUA KEMUNGKINAN REGRESI
(ALL POSSIBLE REGRESSION)

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
ALL POSSIBLE REGRESSION
Merupakan suatu prosedur statistik dalam pemilihan persamaan regresi terbaik.
Ciri dari prosedur ini :
• tidak praktis
• dilakukan dengan bantuan komputer berkecepatan tinggi
Tiga kriteria yang akan dievaluasi pada setiap persamaan regresi :
1. nilai R2 yang dicapai
2. nilai s2, Jumlah Kuadrat Sisa
3. statistik Cp Mallow
Penentuan persamaan mana yang terbaik untuk dipilih dilakukan melalui evaluasi pola-pola yang teramati.

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Statistik R2
Definisi : R2 merupakan suatu ukuran mengenai seberapa baik model (persamaan regresi) dapat menjelaskan keragaman data.
Semakin tinggi R2 maka model tersebut semakin baik menjelaskan keragaman data, sehingga tidak terlalu sulit menginterpretasikannya.
Namun statistik R2 tidaklah cukup untuk memeriksa semua kemungkinan regresi.

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Penggunaan Statistik R2
pada ALL POSSIBLE REGRESSION
1. Kelompokkan persamaan-persamaan ke dalam kelompok yang dikelompokkan berdasarkan banyaknya peubah peramal yang ada dalam persamaan regresi contohnya :
kelompok yang terdiri dari sejumlah persamaan regresi tanpa peubah peramal ( E(Y)=β0 )
kelompok yang terdiri dari sejumlah persamaan regresi dengan 1 peubah peramal ( E(Y)=β0+ β1x1 )
Sampai dengan kelompok yang terdiri dari sejumlah persamaan regresi dengan semua peubah peramal yang ada ( E(Y)=β0+…+ βixi )
2. Urutkan persamaan regresi dalam setiap kelompok menurut besarnya kuadrat koefisien korelasi berganda R2 yang dicapai.

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
3. Periksalah persamaan regresi urutan pertama yang terbesar dalam setiap kelompok dan lihatlah apakah ada suatu pola peubah yang konsisten dalam persamaan.
4. Periksalah matriks korelasi data tersebut.
5. Tentukan persamaan regresi terbaik yang cukup konsisten, bila diperlukan informasi lain mengenai sumber data yang diteliti dan peranan fisis peubah-peubah x.
Penggunaan Statistik R2
pada ALL POSSIBLE REGRESSIONLanjutan…

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Penggunaan Kuadrat Tengah Sisa, S2
pada ALL POSSIBLE REGRESSION
1. Evaluasi terhadap rata-rata kuadrat tengah sisa untuk setiap kelompok masing-masing dengan p peubah.
(p = banyaknya parameter dalam model termasuk β0)
2. Overfitting menggambarkan stabilisasi tipikal s2 dan mendekati nilai σ2
sebenarnya. Overfitting adalah pendugaan persamaan regresi yang melibatkan lebih banyak peubah peramal daripada yang dibutuhkan untuk memperoleh persamaan yang memuaskan.
3. Melihat nilai yang sangat baik bagi σ2 melalui tebaran rata-rata s2(p) lawan p.
4. Untuk setiap kelompok dilihat yang memiliki kuadrat tengah sisa yang paling kecil.
5. Model yang memiliki nilai dugaan bagi ragam sisanya kecil dan mengandung sedikit mungkin peubah peramalnya maka prosedur ini telah menghasilkan suatu nilai dugaan “asimtotik” bagi σ2 (nilai dugaan terbaik bagi σ2).

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Statistik Cp Mallow
• Ditemukan oleh C. L. Mallows
Ket :
JKSp = Jumlah Kuadrat Sisa dari model yang mengandung P parameter
p = banyak parameter dalam model, termasuk β0
s2 = Kuadrat Tengah Sisa dari persamaan terbesar yang dipostulatkan mengandung semua z (semua peubah peramal termasuk peubah boneka)
p)(ns
JKSpCp 2
2

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Jika suatu persamaan sudah memadai, maka E(JKSp)=(n-p)σ2 dan diasumsikan E(s2)= σ2, kira-kira nisbah JKSp/s2 mempunyai nilai harapan (n-p)σ2/σ2=n-p sehingga kira-kira E(Cp)=p, jika modelnya memadai.
Tebaran Cp lawan p akan memperlihatkan “model-model yang memadai” sebagai titik yang cukup dekat pada garis Cp=p.
Persamaan regresi yang memiliki ketidakpastian model (persamaan yang berbias), akan menghasilkan titik di atas garis Cp=p.
Penggunaan Statistik Cp Mallow
pada ALL POSSIBLE REGRESSIONLanjutan…

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Nilai Cp setiap sebaran menunjukkan nilai duga bagi Jumlah Kuadrat Simpangan (galat ragam dan galat bias) persamaan regresi tersebut.
Persamaan dengan parameter lebih banyak sehingga mempunyai kepasan lebih baik terhadap data (Cp≈p) namun simpangan total (galat ragam + galat bias) yang lebih besar dari model yang sebenarnya tidak diketahui.
Penggunaan Statistik Cp Mallowpada ALL POSSIBLE REGRESSION
Lanjutan…

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Analisis Regresi 2
Sub Pokok Bahasan :
REGRESI BERTATAR

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Stepwise RegressionStepwise Regression

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Regresi Bertatar
Prosedur regresi bertatar (stepwise regression)merupakan prosedur statistik untuk menentukan peubah mana yang akan dimasukkan ke dalam persamaan regresi.
Prosedur ini pada dasarnya merupakan kombinasi dari prosedur eliminasi langkah mundur (backward regression) dan prosedur eliminasi langkah maju (forward regression).

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Prosedur regresi bertatar (stepwise regression) biasanya digunakan pada regresi linier berganda dengan banyak peubah bebas.
Prosedur ini juga digunakan untuk mencari model regresi terbaik serta untuk mengatasi multikolinieritas.
Regresi BertatarKegunaan :

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Regresi Bertatar :Taraf Nyata ( )
Dalam regresi bertatar, terdapat dua taraf nyata ( ): untuk masuk untuk keluar.
Taraf nyata yang digunakan dalam pengujian untuk memasukkan peubah bebas ke dalam persamaan regresi ialah untuk masuk
Taraf nyata yang digunakan dalam pengujian untuk mengeluarkan peubah bebas ke dalam persamaan regresi ialah untuk keluar.
Taraf nyata ditentukan oleh peneliti, namun disarankan untuk menggunakan nilai =0,05 atau
=0,01, baik untuk uji masuk maupun untuk uji keluar.

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Algoritma :
a. Hitung korelasi setiap peubah bebas (X1, X2,…Xk) terhadap peubah tak bebas (Y). Peubah bebas dengan nilai korelasi tertinggi dimasukkan dalam model regresi (syarat uji F menunjukkan peubah ini berpengaruh nyata). Jika tidak nyata, berhenti dan mengambil model sebagai yang terbaik.
b. Hitung korelasi parsial setiap peubah bebas tanpa menyertakan peubah bebas yang telah masuk model. Masukkan peubah bebas dengan korelasi parsial tertinggi ke dalam model
Regresi Bertatar

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
c. Setelah diuji, perhatikan peningkatan R2 dan nilai-F parsial/nilai-t parsial untuk kedua peubah yang ada di dalam persamaan. Nilai-F parsial terendah kemudian dibandingkan nilai-F tabel, dan peubah bebas tersebut dipertahankan (nilai-F parsial terendah > F tabel/ nilai-t parsial> nilai-t tabel) atau dikeluarkan dari persamaan tergantung pada apakah uji ini nyata atau tidak.
d. Kembali ke langkah b
e. Jika tidak ada peubah yang dapat dikeluarkan atau dimasukkan, proses akan terhenti.
Algoritma (lanjutan)
Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
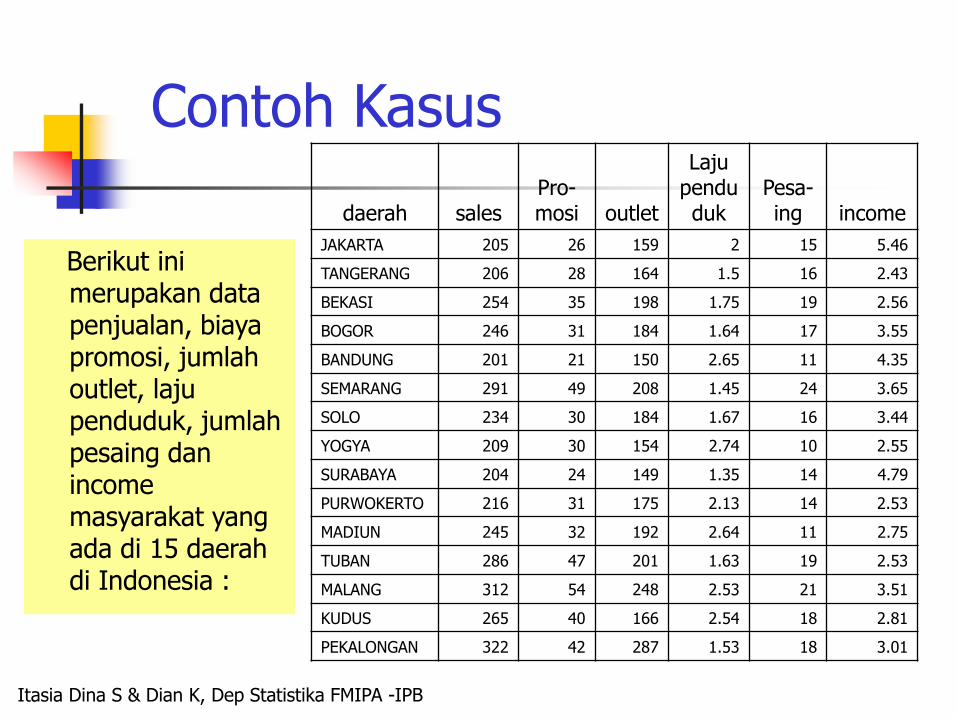
Contoh Kasus
Berikut inimerupakan data penjualan, biaya promosi, jumlah outlet, laju penduduk, jumlah pesaing dan income masyarakat yang ada di 15 daerah di Indonesia :
daerah salesPro-mosi outlet
Lajupenduduk
Pesa-ing income
JAKARTA 205 26 159 2 15 5.46
TANGERANG 206 28 164 1.5 16 2.43
BEKASI 254 35 198 1.75 19 2.56
BOGOR 246 31 184 1.64 17 3.55
BANDUNG 201 21 150 2.65 11 4.35
SEMARANG 291 49 208 1.45 24 3.65
SOLO 234 30 184 1.67 16 3.44
YOGYA 209 30 154 2.74 10 2.55
SURABAYA 204 24 149 1.35 14 4.79
PURWOKERTO 216 31 175 2.13 14 2.53
MADIUN 245 32 192 2.64 11 2.75
TUBAN 286 47 201 1.63 19 2.53
MALANG 312 54 248 2.53 21 3.51
KUDUS 265 40 166 2.54 18 2.81
PEKALONGAN 322 42 287 1.53 18 3.01
Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
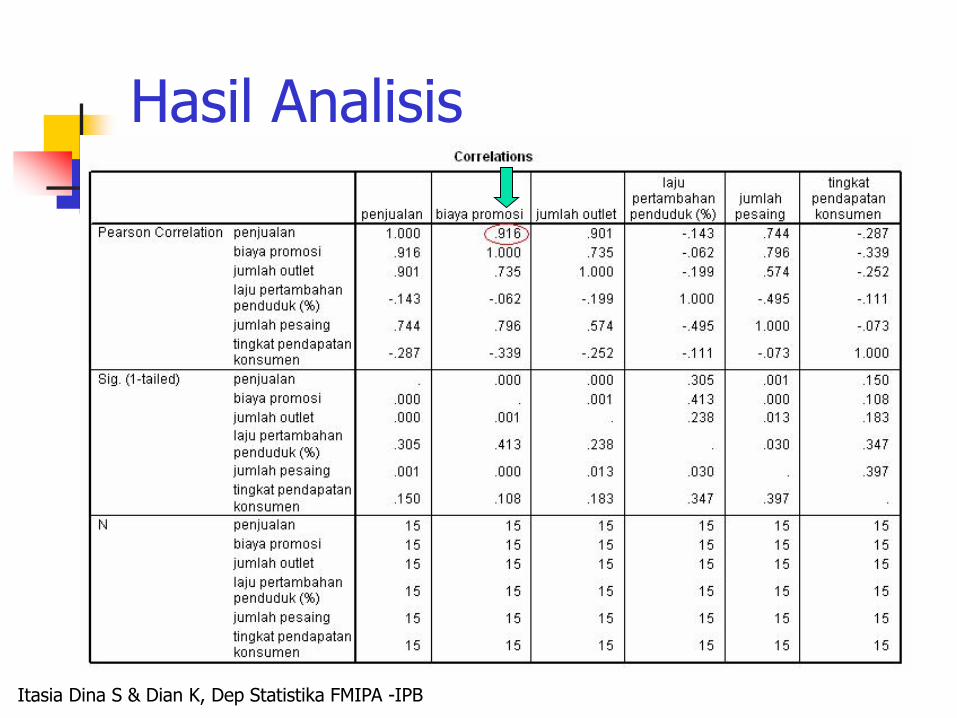
Hasil Analisis
Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
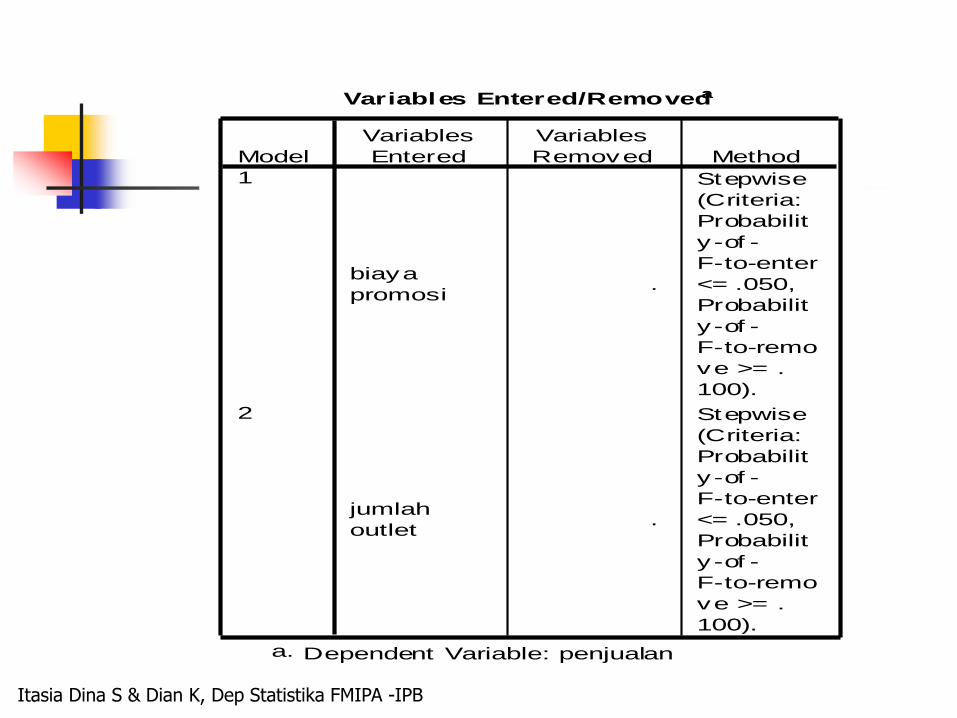
Variables Entered/Removeda
biaya
promosi.
Stepwise
(Criteria:
Probabilit
y -of -
F-to-enter
<= .050,
Probabilit
y -of -
F-to-remo
ve >= .
100).
jumlah
outlet.
Stepwise
(Criteria:
Probabilit
y -of -
F-to-enter
<= .050,
Probabilit
y -of -
F-to-remo
ve >= .
100).
Model
1
2
Variables
Entered
Variables
Removed Method
Dependent Variable: penjualana.
Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
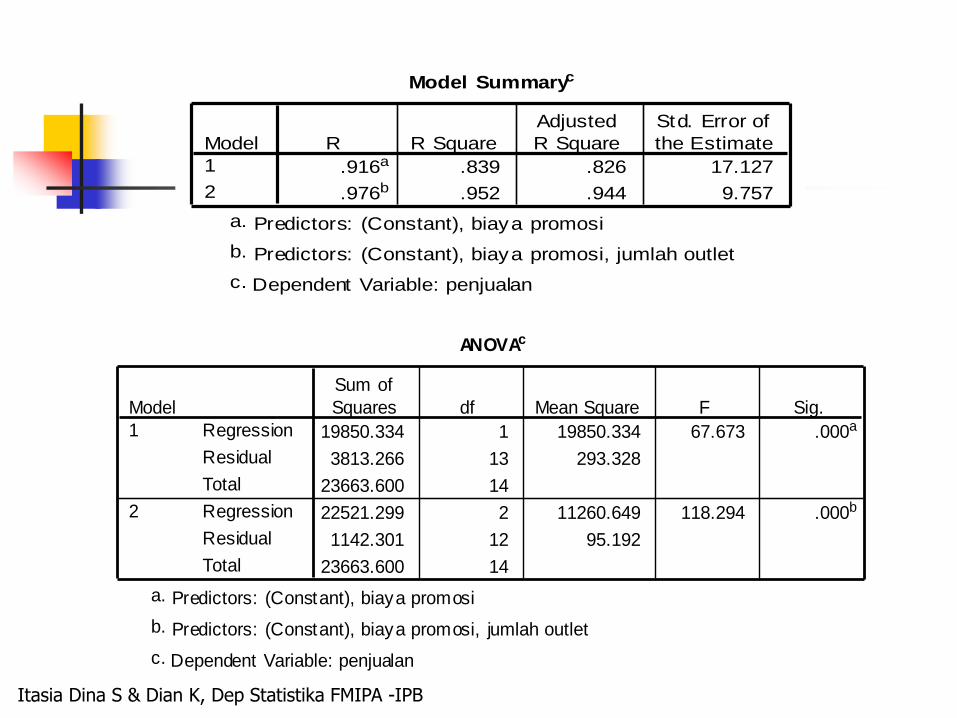
Model Summaryc
.916a .839 .826 17.127
.976b .952 .944 9.757
Model
1
2
R R Square
Adjusted
R Square
Std. Error of
the Estimate
Predictors: (Constant), biaya promosia.
Predictors: (Constant), biaya promosi, jumlah outletb.
Dependent Variable: penjualanc.
ANOVAc
19850.334 1 19850.334 67.673 .000a
3813.266 13 293.328
23663.600 14
22521.299 2 11260.649 118.294 .000b
1142.301 12 95.192
23663.600 14
Regression
Residual
Total
Regression
Residual
Total
Model
1
2
Sum of
Squares df Mean Square F Sig.
Predictors: (Constant), biaya promosia.
Predictors: (Constant), biaya promosi, jumlah outletb.
Dependent Variable: penjualanc.
Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
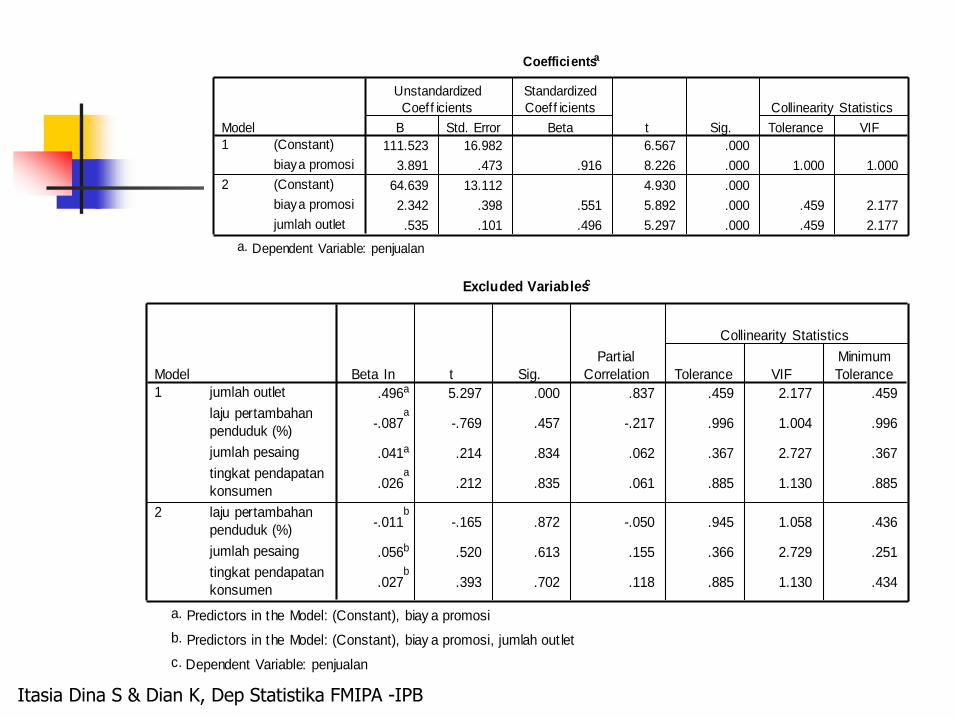
Coefficientsa
111.523 16.982 6.567 .000
3.891 .473 .916 8.226 .000 1.000 1.000
64.639 13.112 4.930 .000
2.342 .398 .551 5.892 .000 .459 2.177
.535 .101 .496 5.297 .000 .459 2.177
(Constant)
biaya promosi
(Constant)
biaya promosi
jumlah outlet
Model
1
2
B Std. Error
Unstandardized
Coeff icients
Beta
Standardized
Coeff icients
t Sig. Tolerance VIF
Collinearity Statistics
Dependent Variable: penjualana.
Excluded Variablesc
.496a 5.297 .000 .837 .459 2.177 .459
-.087a
-.769 .457 -.217 .996 1.004 .996
.041a .214 .834 .062 .367 2.727 .367
.026a
.212 .835 .061 .885 1.130 .885
-.011b
-.165 .872 -.050 .945 1.058 .436
.056b .520 .613 .155 .366 2.729 .251
.027b
.393 .702 .118 .885 1.130 .434
jumlah outlet
laju pertambahan
penduduk (%)
jumlah pesaing
tingkat pendapatan
konsumen
laju pertambahan
penduduk (%)
jumlah pesaing
tingkat pendapatan
konsumen
Model
1
2
Beta In t Sig.
Part ial
Correlation Tolerance VIF
Minimum
Tolerance
Collinearity Statistics
Predictors in the Model: (Constant), biay a promosia.
Predictors in the Model: (Constant), biay a promosi, jumlah out letb.
Dependent Variable: penjualanc.

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Kesimpulan
Berdasarkan indikator pemilihan model terbaik, R, R2, R2 adjusted, dan s (standar error) model yang kedua merupakan model yang terbaik karena R, R2, R2 adjusted yang diperoleh lebih besar dibandingkan dengan model pertama. Nilai s yang dihasilkan lebih kecil dibandingkan dengan model pertama.

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Prosedur eliminasi langkah mundur
(the backward elimination procedure)

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Penentuan peubah penjelas dalam modelregresi (Draper dan Smith):
1. tujuan peramalan nilai ramalan yangterandalkan memasukkan banyak
peubah penjelas.
2. banyak peubah diteliti biaya operasitinggi digunakan sedikit peubah
penjelas.

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Tingkat representatifPeramalan
Memperoleh nilai peramalan yang terandalkan --> membutuhkan sebanyak mungkin peubah penjelas

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Banyak peubah penjelas biayaoperasional tinggi.
BiayaOperasionalpenelitian
Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Mencari persamaan regresi terbaik
(sesedikit mungkin peubah penjelas tanpa mengurangi maksud dari tujuan penelitian)
Sesedikitmungkinpeubahpenjelas
MinimalisirBiaya
PencapaianTujuan
Penelitian
PersamaanRegresi
Representatif
Prosedur eliminasi langkah mundur(the backward elimination procedure)

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Proses menentukan persamaan regresi terbaikdimulai dengan:
regresi terbesar dengan menggunakan semuapeubah, dan secara bertahap mengurangibanyaknya peubah di dalam persamaan sampaisuatu keputusan dicapai untuk menggunakanpersamaan yang diperoleh

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Kita bisa melihat persamaan regresi yang mengandung semua peubah penjelas.
Lebih menghemat waktu dibandingkan dengan metode “semua kemungkinan regresi”

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Sekali suatu peubah dihilangkan, maka dia tak tersedia untuk bisa dipertimbangkan lagi.
Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Algoritma
regresi terbesar dengan semua kemungkinan peubah
Bertahap…
mengurangi banyaknya peubah
diperoleh persamaan regresi terbaik

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Regresi dengan semua (n) peubah
penjelas
F-Parsial masing2 Peubah penjelas
BandingkanF-parsial
terkecil dgnF-Tabel
F-Parsial Peubahpenjelas terkecil
If (F-Parsial >= F-Tabel)
If (F-Parsial < F-Tabel)
Persamaan Regresi Terbaik
BuangPeubahPenjelas(F-parsialterkecil)
Regresi dengan(n-1) peubah
penjelas

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Regresi dengan semua (n)
peubah penjelas
P-value masing2 Peubah penjelas
BandingkanP-valueterbesar
dgn Alpha-to-
remove
P-valuePeubah penjelas
terbesarIf
(P-value <= Alpha-to-remove)
If (P-value > Alpha-to-
remove)
Persamaan Regresi Terbaik
Buang Peubah Penjelas(P-value terbesar)
Regresi dengan (n-1) peubah
penjelas
Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
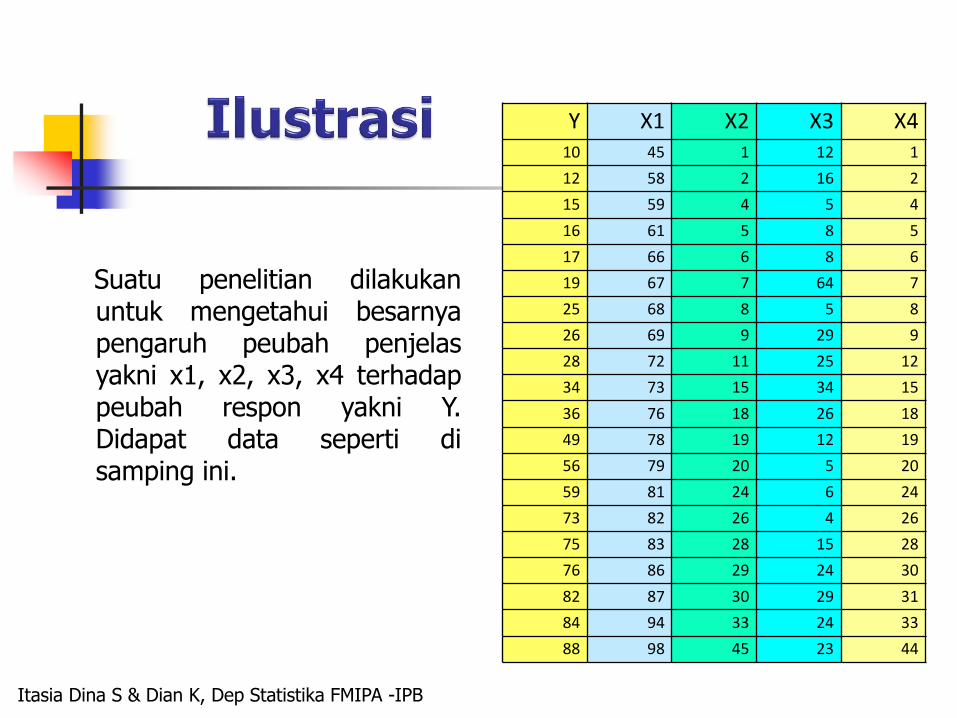
Suatu penelitian dilakukanuntuk mengetahui besarnyapengaruh peubah penjelasyakni x1, x2, x3, x4 terhadappeubah respon yakni Y.Didapat data seperti disamping ini.
Y X1 X2 X3 X410 45 1 12 1
12 58 2 16 2
15 59 4 5 4
16 61 5 8 5
17 66 6 8 6
19 67 7 64 7
25 68 8 5 8
26 69 9 29 9
28 72 11 25 12
34 73 15 34 15
36 76 18 26 18
49 78 19 12 19
56 79 20 5 20
59 81 24 6 24
73 82 26 4 26
75 83 28 15 28
76 86 29 24 30
82 87 30 29 31
84 94 33 24 33
88 98 45 23 44

Itasia Dina S & Dian K, Dep Statistika FMIPA -IPB
Interpretasi:
Lihat step 1
- P-value terbesar (pada x1)
- Bandingkan dengan nilai α=0,1
(P-value=0,915) > (α=0,1)
- Eliminasi x1
Lihat step 2
- P-value terbesar (pada x3)
- Bandingkan dengan nilai α=0,1
(P-value=0,093) < (α=0,1)
Dugaan Persamaan Regresi Tebaik
Y duga =7,894 - 6,4X2 - 0.153 X3 + 8,6 X4
Penyelesaian..
Perhatikan output dari untuk kasus di atas:
Recommended

















