
A Phylogenetic Model of Language Diversification
Robin J. Ryder1 et Geoff K. Nicholls2
1CEREMADE, Université Paris-Dauphine
2Department of Statistics, University of Oxford
UCLA, March 2013www.slideshare.net/robinryder
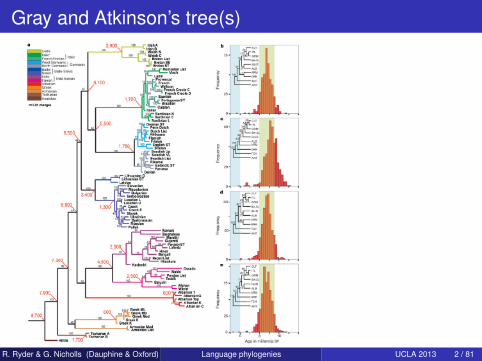
Gray and Atkinson’s tree(s)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 2 / 81

Caveats
I am not a linguistStatistics: additional insight alongside the comparative methodI use the word "evolution" in a broad sense"All models all false, but some are useful"
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 3 / 81

Advantages of statistical methods
Analyse (very) large datasetsTest multiple hypothesesCross-validationEstimate uncertainty
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 4 / 81

Questions to answer
Topology of the treeAge of ancestor nodesAge of root: 6000-6500 BP or 8000-9500 BP (Before Present) ?6000 BP: Kurgan horsemen ; 8000 BP: Anatolian farmers
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 5 / 81

Statistical method in a nutshell
1 Collect data2 Design model3 Perform inference (MCMC, ...)4 Check convergence5 In-model validation (is our inference method able to answer
questions from our model?)6 Model mis-specification analysis (do we need a more complex
model?)7 Conclude
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 6 / 81

Outline
1 Data
2 Model
3 Inference
4 In-model validation
5 Model mis-specification
6 Results
7 Semitic lexical data
8 Bergsland and Vogt
9 Punctuational bursts
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 7 / 81

Morris Swadesh and glottochronology
200/100 word listCompares 2 languages (c=fraction of shared cognates)Assumes r=fraction of shared cognates after 1000 years constantfor all languages (86%)Infers age t of Most Recent Common Ancestor
t =ln c
2 ln r
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 8 / 81

all
and
animal
ashes
at
back
bad
bark
because
belly
big
bird
bite
black
blood
blow
bone
breast
breathe
burn
child
claw
cloud
cold
come
count
cut
day
die
dig
dirty
dog
drink
dry
dull
dust
ear
earth
eat
egg
eye
fall
far
fat
father
fear
feather
few
fight
fire
fish
five
float
flow
flower
fly
fog
foot
four
freeze
full
give
good
grass
green
guts
hair
hand
he
head
hear
heart
heavy
here
hit
hold
horn
how
hunt
husband
I
ice
if
in
kill
knee
know
lake
laugh
leaf
left
leg
lie
live
liver
long
louse
man
many
meat
moon
mother
mountain
mouth
name
narrow
near
neck
new
night
nose
not
old
one
other
person
play
pull
push
rain
red
right(cor-rect)
right(side)
river
road
root
rope
rotten
round
rub
salt
sand
say
scratch
sea
see
seed
sew
sharp
short
sing
sit
skin
sky
sleep
small
smell
smoke
smooth
snake
snow
some
spit
split
squeeze
stab
stand
star
stick
stone
straight
suck
sun
swell
swim
tail
ten
that
there
they
thick
thin
think
this
thou
three
throw
tie
tongue
tooth
tree
turn
two
vomit
walk
warm
wash
water
we
wet
what
when
where
white
who
wide
wife
wind
wing
wipe
with
woman
woods
worm
ye
year
yellow
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 9 / 81

Bergsland and Vogt (1962)
Found different rates for different pairs of languages: Old Norseand Icelandic, Georgian and Mingrelian, Armenian and OldArmenianDiscredited GlottochronologySankoff (1973): sample selection bias, no estimation ofuncertaintyFair criticismBad observation protocol from SwadeshDoes not apply (so much) to modern methods
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 10 / 81

Core vocabulary
100 or 200 words, present in almost all languages: bird, hand, toeat, red...Borrowing can occur (evolution not along a tree), but:
“Easy” to detectRareDoes not bias the results
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 11 / 81

Core vocabulary
100 or 200 words, present in almost all languages: bird, hand, toeat, red...Borrowing can occur (evolution not along a tree), but:“Easy” to detectRareDoes not bias the results
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 11 / 81
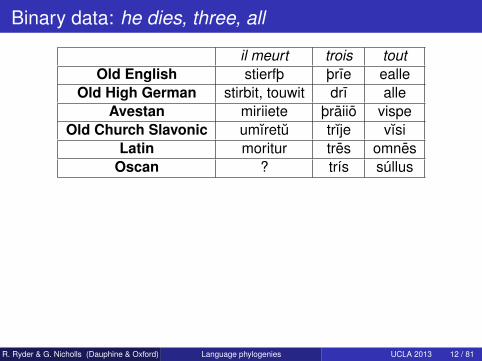
Binary data: he dies, three, all
il meurt trois toutOld English stierfþ þrıe ealle
Old High German stirbit, touwit drı alleAvestan miriiete þraiio vispe
Old Church Slavonic umıretu trıje vısiLatin moritur tres omnes
Oscan ? trís súllus
Cognacy classes (traits) for themeaning he dies:
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 12 / 81
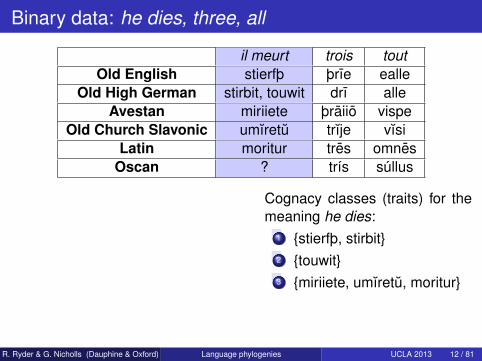
Binary data: he dies, three, all
il meurt trois toutOld English stierfþ þrıe ealle
Old High German stirbit, touwit drı alleAvestan miriiete þraiio vispe
Old Church Slavonic umıretu trıje vısiLatin moritur tres omnes
Oscan ? trís súllus
Cognacy classes (traits) for themeaning he dies:
1 stierfþ, stirbit2 touwit3 miriiete, umıretu, moritur
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 12 / 81
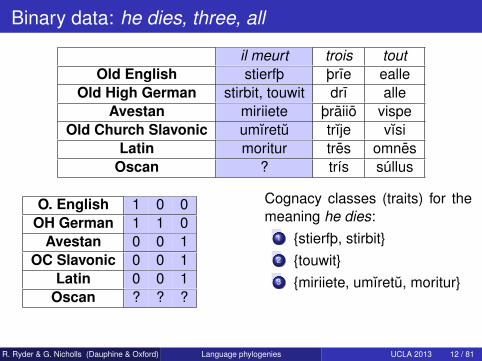
Binary data: he dies, three, all
il meurt trois toutOld English stierfþ þrıe ealle
Old High German stirbit, touwit drı alleAvestan miriiete þraiio vispe
Old Church Slavonic umıretu trıje vısiLatin moritur tres omnes
Oscan ? trís súllus
O. English 1 0 0OH German 1 1 0
Avestan 0 0 1OC Slavonic 0 0 1
Latin 0 0 1Oscan ? ? ?
Cognacy classes (traits) for themeaning he dies:
1 stierfþ, stirbit2 touwit3 miriiete, umıretu, moritur
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 12 / 81
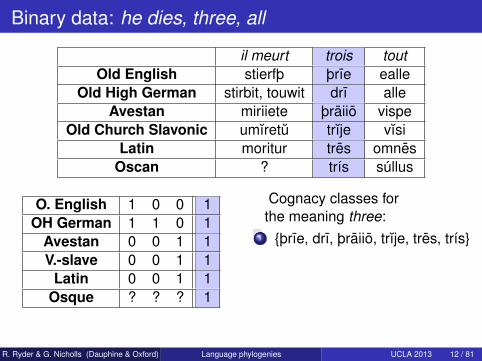
Binary data: he dies, three, all
il meurt trois toutOld English stierfþ þrıe ealle
Old High German stirbit, touwit drı alleAvestan miriiete þraiio vispe
Old Church Slavonic umıretu trıje vısiLatin moritur tres omnes
Oscan ? trís súllus
O. English 1 0 0 1OH German 1 1 0 1
Avestan 0 0 1 1V.-slave 0 0 1 1
Latin 0 0 1 1Osque ? ? ? 1
Cognacy classes forthe meaning three:
1 þrıe, drı, þraiio, trıje, tres, trís
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 12 / 81
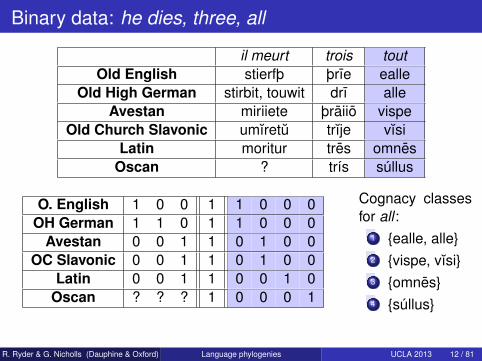
Binary data: he dies, three, all
il meurt trois toutOld English stierfþ þrıe ealle
Old High German stirbit, touwit drı alleAvestan miriiete þraiio vispe
Old Church Slavonic umıretu trıje vısiLatin moritur tres omnes
Oscan ? trís súllus
O. English 1 0 0 1 1 0 0 0OH German 1 1 0 1 1 0 0 0
Avestan 0 0 1 1 0 1 0 0OC Slavonic 0 0 1 1 0 1 0 0
Latin 0 0 1 1 0 0 1 0Oscan ? ? ? 1 0 0 0 1
Cognacy classesfor all :
1 ealle, alle2 vispe, vısi3 omnes4 súllus
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 12 / 81
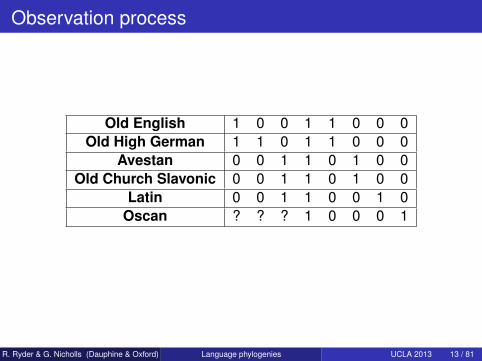
Observation process
Old English 1 0 0 1 1 0 0 0Old High German 1 1 0 1 1 0 0 0
Avestan 0 0 1 1 0 1 0 0Old Church Slavonic 0 0 1 1 0 1 0 0
Latin 0 0 1 1 0 0 1 0Oscan ? ? ? 1 0 0 0 1
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 13 / 81
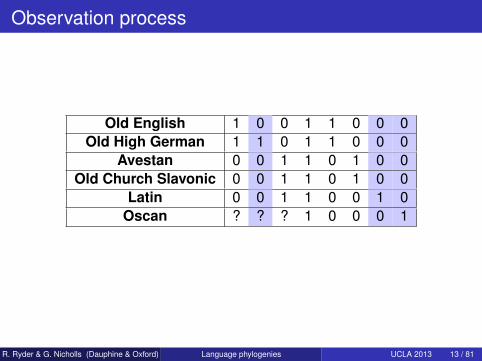
Observation process
Old English 1 0 0 1 1 0 0 0Old High German 1 1 0 1 1 0 0 0
Avestan 0 0 1 1 0 1 0 0Old Church Slavonic 0 0 1 1 0 1 0 0
Latin 0 0 1 1 0 0 1 0Oscan ? ? ? 1 0 0 0 1
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 13 / 81

Observation process
Old English 1 0 1 1 0Old High German 1 0 1 1 0
Avestan 0 1 1 0 1Old Church Slavonic 0 1 1 0 1
Latin 0 1 1 0 0Oscan ? ? 1 0 0
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 13 / 81

Constraints
Constraints on the tree topology30 constraints on the age of some nodes or ancient languagesThese constraits are used to estimate the evolution rates and theage.
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 14 / 81
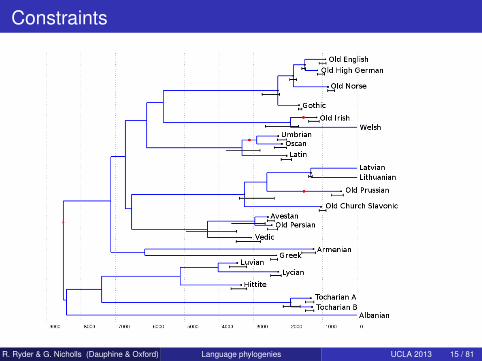
Constraints
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 15 / 81

Outline
1 Data
2 Model
3 Inference
4 In-model validation
5 Model mis-specification
6 Results
7 Semitic lexical data
8 Bergsland and Vogt
9 Punctuational bursts
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 16 / 81
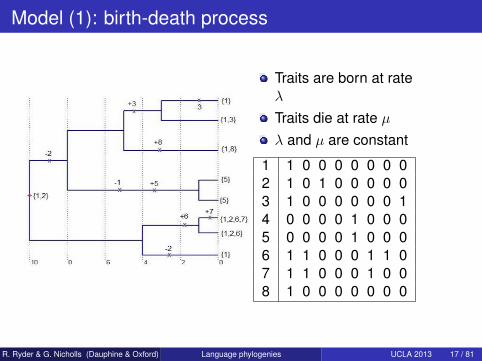
Model (1): birth-death process
Traits are born at rateλ
Traits die at rate µλ and µ are constant
1 1 0 0 0 0 0 0 02 1 0 1 0 0 0 0 03 1 0 0 0 0 0 0 14 0 0 0 0 1 0 0 05 0 0 0 0 1 0 0 06 1 1 0 0 0 1 1 07 1 1 0 0 0 1 0 08 1 0 0 0 0 0 0 0
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 17 / 81
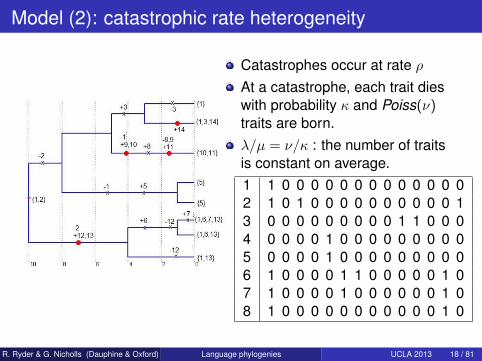
Model (2): catastrophic rate heterogeneity
Catastrophes occur at rate ρAt a catastrophe, each trait dieswith probability κ and Poiss(ν)traits are born.λ/µ = ν/κ : the number of traitsis constant on average.1 1 0 0 0 0 0 0 0 0 0 0 0 0 02 1 0 1 0 0 0 0 0 0 0 0 0 0 13 0 0 0 0 0 0 0 0 0 1 1 0 0 04 0 0 0 0 1 0 0 0 0 0 0 0 0 05 0 0 0 0 1 0 0 0 0 0 0 0 0 06 1 0 0 0 0 1 1 0 0 0 0 0 1 07 1 0 0 0 0 1 0 0 0 0 0 0 1 08 1 0 0 0 0 0 0 0 0 0 0 0 1 0
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 18 / 81
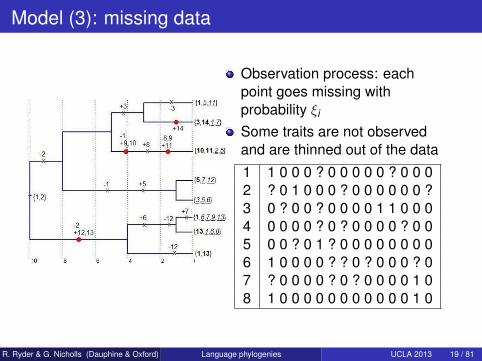
Model (3): missing data
Observation process: eachpoint goes missing withprobability ξi
Some traits are not observedand are thinned out of the data
1 1 0 0 0 ? 0 0 0 0 0 ? 0 0 02 ? 0 1 0 0 0 ? 0 0 0 0 0 0 ?3 0 ? 0 0 ? 0 0 0 0 1 1 0 0 04 0 0 0 0 ? 0 ? 0 0 0 0 ? 0 05 0 0 ? 0 1 ? 0 0 0 0 0 0 0 06 1 0 0 0 0 ? ? 0 ? 0 0 0 ? 07 ? 0 0 0 0 ? 0 ? 0 0 0 0 1 08 1 0 0 0 0 0 0 0 0 0 0 0 1 0
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 19 / 81

Observation process
0 1 0 0 1 0 1 1 00 0 0 1 1 0 0 1 11 1 0 1 1 1 1 1 11 0 0 1 0 1 1 1 00 0 1 1 1 1 0 0 1
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 20 / 81

Observation process
0 1 0 0 1 0 1 1 00 0 0 1 1 0 0 1 11 1 0 1 1 1 1 1 11 0 0 1 0 1 1 1 00 0 1 1 1 1 0 0 1
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 20 / 81

Observation process
? 1 0 0 ? 0 1 1 00 0 ? ? 1 0 0 1 1? 1 ? ? ? 1 ? 1 11 0 0 1 0 1 1 1 00 ? ? 1 1 1 0 0 1
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 21 / 81

Observation process
? 1 0 0 ? 0 1 1 00 0 ? ? 1 0 0 1 1? 1 ? ? ? 1 ? 1 11 0 0 1 0 1 1 1 00 ? ? 1 1 1 0 0 1
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 21 / 81

Observation process
1 0 ? 0 1 1 00 ? 1 0 0 1 11 ? ? 1 ? 1 10 1 0 1 1 1 0? 1 1 1 0 0 1
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 22 / 81

Outline
1 Data
2 Model
3 Inference
4 In-model validation
5 Model mis-specification
6 Results
7 Semitic lexical data
8 Bergsland and Vogt
9 Punctuational bursts
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 23 / 81

TraitLab softwareBayesian inferenceMarkov Chain Monte Carlo(Almost) uniform prior over the age of the root
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 24 / 81

Why be Bayesian?
In the settings described in this talk, it usually makes sense to useBayesian inference, because:
The models are complexEstimating uncertainty is paramountThe output of one model is used as the input of anotherWe are interested in complex functions of our parameters
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 25 / 81

Frequentist statistics
Statistical inference deals with estimating an unknown parameterθ given some data D.In the frequentist view of statistics, θ has a true fixed(deterministic) value.Uncertainty is measured by confidence intervals, which are notintuitive to interpret: if I get a 95% CI of [80 ; 120] (i.e. 100± 20)for θ, I cannot say that there is a 95% probability that θ belongs tothe interval [80 ; 120].
Frequentist statistics often use the maximum likelihood estimator:for which value of θ would the data be most likely (under ourmodel)?
L(θ|D) = P[D|θ]
θ = arg maxθ
L(θ|D)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 26 / 81

Frequentist statistics
Statistical inference deals with estimating an unknown parameterθ given some data D.In the frequentist view of statistics, θ has a true fixed(deterministic) value.Uncertainty is measured by confidence intervals, which are notintuitive to interpret: if I get a 95% CI of [80 ; 120] (i.e. 100± 20)for θ, I cannot say that there is a 95% probability that θ belongs tothe interval [80 ; 120].Frequentist statistics often use the maximum likelihood estimator:for which value of θ would the data be most likely (under ourmodel)?
L(θ|D) = P[D|θ]
θ = arg maxθ
L(θ|D)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 26 / 81

Bayesian statistics
In the Bayesian framework, the parameter θ is seen as inherentlyrandom: it has a distribution.Before I see any data, I have a prior distribution on π(θ), usuallyuninformative.Once I take the data into account, I get a posterior distribution,which is hopefully more informative.
π(θ|D) ∝ π(θ)L(θ|D)
Different people have different priors, hence different posteriors.But with enough data, the choice of prior matters little.We are now allowed to make probability statements about θ, suchas "there is a 95% probability that θ belongs to the interval[78 ; 119]" (credible interval)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 27 / 81

Advantages and drawbacks of Bayesian statistics
More intuitive interpretation of the resultsEasier to think about uncertaintyIn a hierarchical setting, it becomes easier to take into account allthe sources of variabilityPrior specification: need to check that changing your prior doesnot change your resultComputationally intensive
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 28 / 81
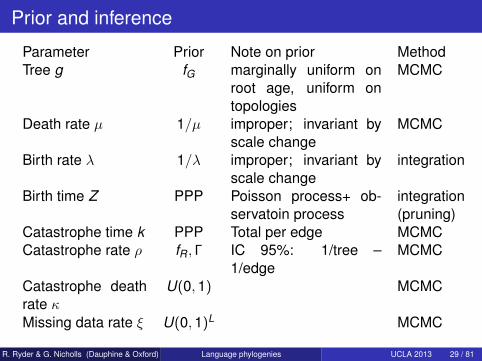
Prior and inference
Parameter Prior Note on prior MethodTree g fG marginally uniform on
root age, uniform ontopologies
MCMC
Death rate µ 1/µ improper; invariant byscale change
MCMC
Birth rate λ 1/λ improper; invariant byscale change
integration
Birth time Z PPP Poisson process+ ob-servatoin process
integration(pruning)
Catastrophe time k PPP Total per edge MCMCCatastrophe rate ρ fR, Γ IC 95%: 1/tree –
1/edgeMCMC
Catastrophe deathrate κ
U(0,1) MCMC
Missing data rate ξ U(0,1)L MCMC
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 29 / 81

Posterior distribution
p(g, µ, λ, κ, ρ, ξ|D = D)
=1
N!
(λ
µ
)N
exp
−λµ
∑〈i,j〉∈E
P[EZ |Z = (ti , i),g, µ, κ, ξ](1− e−µ(tj−ti +ki TC))
×
N∏a=1
∑〈i,j〉∈Ea
∑ω∈Ωa
P[M = ω|Z = (ti , i),g, µ](1− e−µ(tj−ti +ki TC))
× 1µλ
p(ρ)fG(g|T )e−ρ|g|(ρ|g|)kT
kT !
L∏i=1
(1− ξi)Qi ξN−Qi
i
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 30 / 81

Likelihood calculation
∑ω∈Ω
(c)a
P[M = ω|Z = (ti , c),g, µ] =
δi,c ×∑ω∈Ω
(c)a
P[M = ω|Z = (tc , c),g, µ] if Y (Ω(c)a ) ≥ 1
(1−δi,c)+δi,c×∑ω∈Ω
(c)a
P[M=ω|Z=(tc , c),g, µ] if Y (Ω(c)a ) = 0 and Q(Ω
(c)a )≥1
(1− δi,c) + δi,cv (0)c if Y (Ω
(c)a ) + Q(Ω
(c)a ) = 0
(i.e. Ω(c)a = ∅)
∑ω∈Ω
(c)a
P[M = ω|Z = (tc , c),g, µ] =
1 if Ω
(c)a = c, ∅ or c
(i.e. Dc,a ∈ ?,1)0 if Ω
(c)a = ∅ (i.e. Dc,a = 0)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 31 / 81

MCMC
Fit the model to the dataTrees that make the data likelyObtain a sample of trees and datesSamples weighted by quality of fit to data
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 32 / 81

Outline
1 Data
2 Model
3 Inference
4 In-model validation
5 Model mis-specification
6 Results
7 Semitic lexical data
8 Bergsland and Vogt
9 Punctuational bursts
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 33 / 81
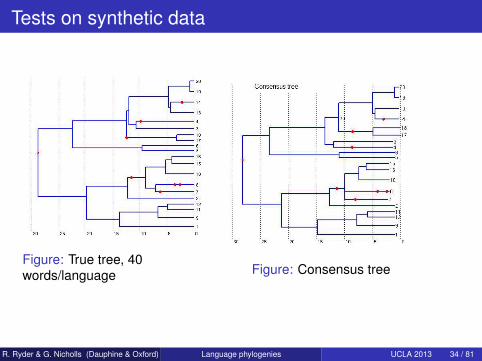
Tests on synthetic data
Figure: True tree, 40words/language Figure: Consensus tree
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 34 / 81
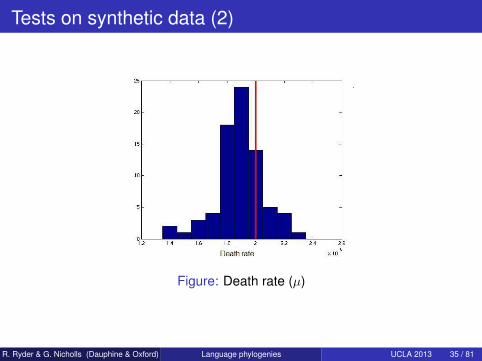
Tests on synthetic data (2)
Figure: Death rate (µ)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 35 / 81
Outline
1 Data
2 Model
3 Inference
4 In-model validation
5 Model mis-specification
6 Results
7 Semitic lexical data
8 Bergsland and Vogt
9 Punctuational bursts
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 36 / 81
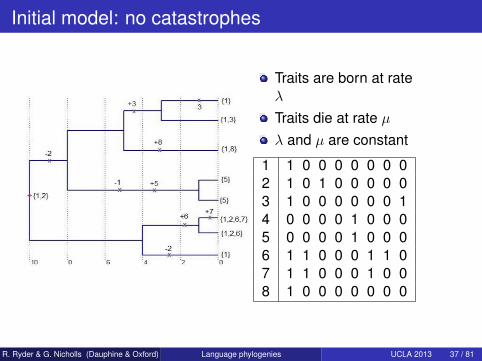
Initial model: no catastrophes
Traits are born at rateλ
Traits die at rate µλ and µ are constant
1 1 0 0 0 0 0 0 02 1 0 1 0 0 0 0 03 1 0 0 0 0 0 0 14 0 0 0 0 1 0 0 05 0 0 0 0 1 0 0 06 1 1 0 0 0 1 1 07 1 1 0 0 0 1 0 08 1 0 0 0 0 0 0 0
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 37 / 81
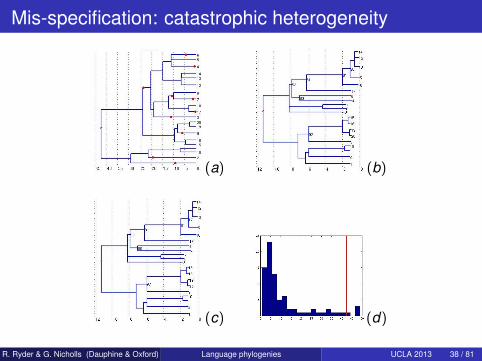
Mis-specification: catastrophic heterogeneity
(a) (b)
(c) (d)
(e)
Figure: Importance of including the catastrophes: given data synthesizedunder a true tree with catastrophes (a), which was well reconstructed by amodel with catastrophes, as shown in the consensus tree (b), we tried to fit amodel without catastrophes. The topology shown in the consensus tree (c),root age tr (d) and death rate µ (e) were all badly reconstructed.
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 38 / 81
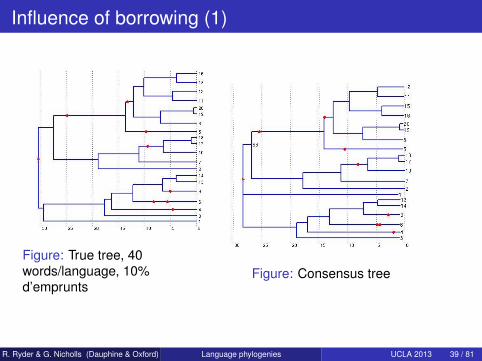
Influence of borrowing (1)
Figure: True tree, 40words/language, 10%d’emprunts
Figure: Consensus tree
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 39 / 81
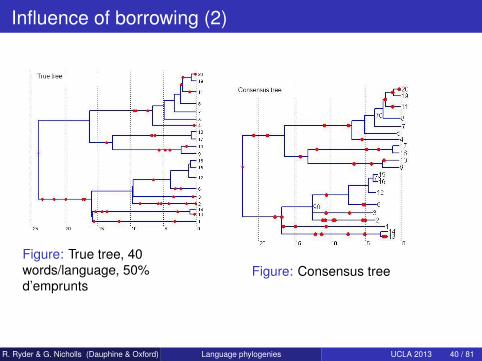
Influence of borrowing (2)
Figure: True tree, 40words/language, 50%d’emprunts
Figure: Consensus tree
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 40 / 81
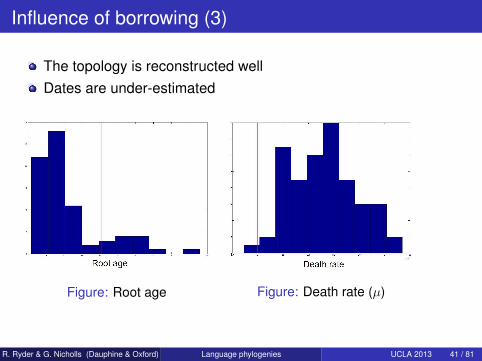
Influence of borrowing (3)
The topology is reconstructed wellDates are under-estimated
Figure: Root age Figure: Death rate (µ)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 41 / 81
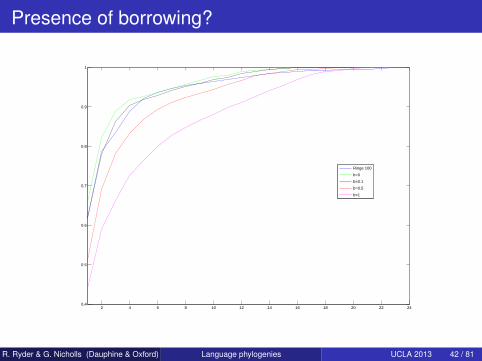
Presence of borrowing?
2 4 6 8 10 12 14 16 18 20 22 240.4
0.5
0.6
0.7
0.8
0.9
1
Ringe 100
b=0
b=0.1
b=0.5
b=1
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 42 / 81

Mis-specifications
Heterogeneity between traits Analyse subset of data+ sim-ulated data
Heterogeneity in time/space(non catastrophic)
Simulated data analysis withedge rate from a Γ distribution
Borrowing Simulated data analysis +check level of borrowing
Data missing in blocks Simulated data analysisNon-empty meaning cate-gories
Simulated data analysis
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 43 / 81
Outline
1 Data
2 Model
3 Inference
4 In-model validation
5 Model mis-specification
6 Results
7 Semitic lexical data
8 Bergsland and Vogt
9 Punctuational bursts
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 44 / 81

Data
Indo-European languagesCore vocabulary (Swadesh 100 ou 207)Two (almost) independent data setsDyen et al. (1997) : 87 languages, mostly modernRinge et al. (2002) : 24 languages, mostly ancient
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 45 / 81

Cross-validation
Predict age of nodes for which we have a constraint: would wereject the truth?Γ space of trees which respect all constraintsΓ−c : remove constraint c = 1 . . . 30M0 : g ∈ Γ, M1; g ∈ Γ−c . Bayes factor:
B(c) =P[g ∈ Γ|D,g ∈ Γ−c]
P[g ∈ Γ|Γ−c]
Constraint c conflicts with the model if 2 log B(c) < −5.
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 46 / 81
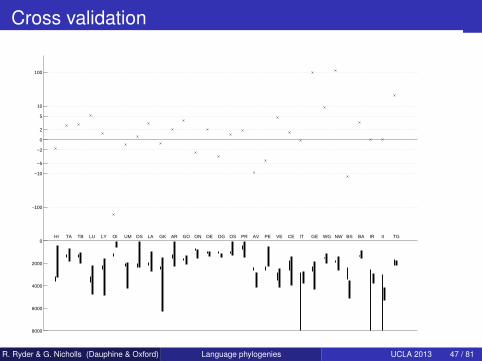
Cross validation
8000
6000
4000
2000
0
−100
−10
−5
−2
0
2
5
10
100
HI TA TB LU LY OI UM OS LA GK AR GO ON OE OG OS PR AV PE VE CE IT GE WG NW BS BA IR II TG
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 47 / 81
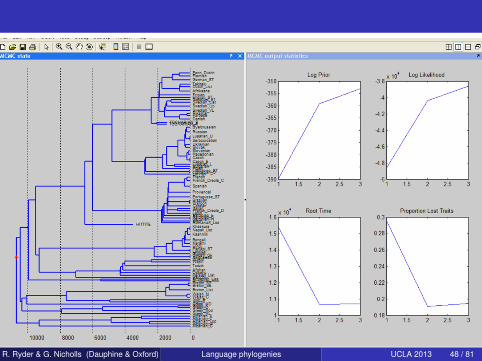
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 48 / 81
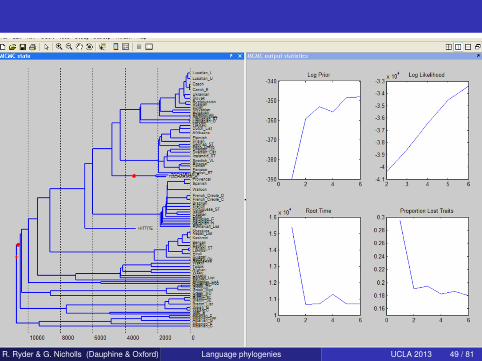
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 49 / 81
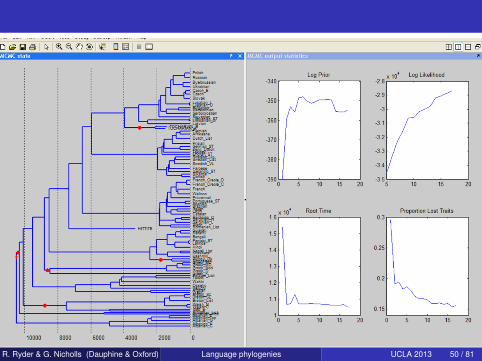
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 50 / 81
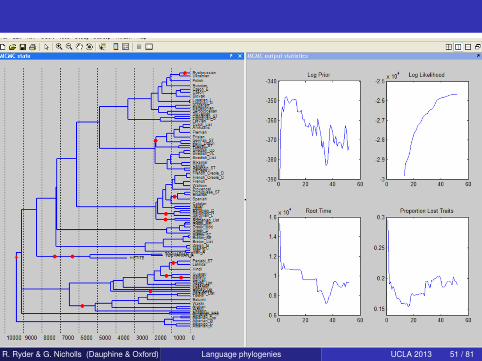
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 51 / 81
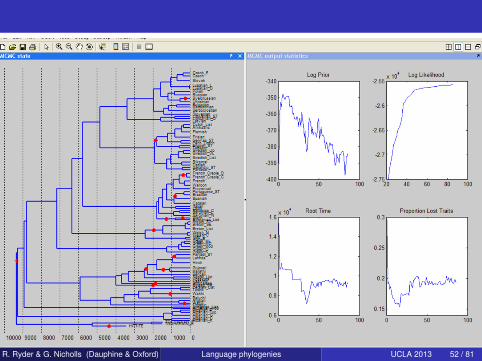
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 52 / 81
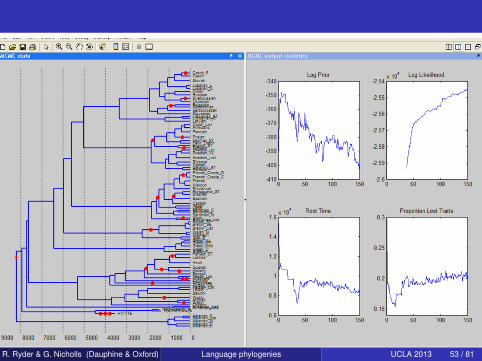
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 53 / 81
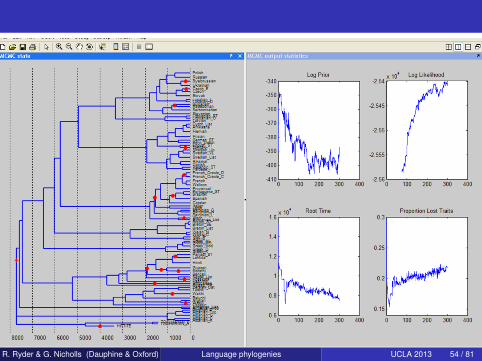
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 54 / 81
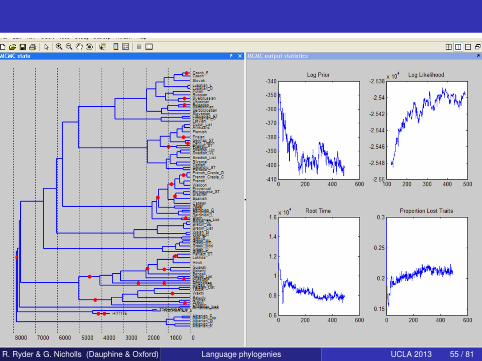
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 55 / 81
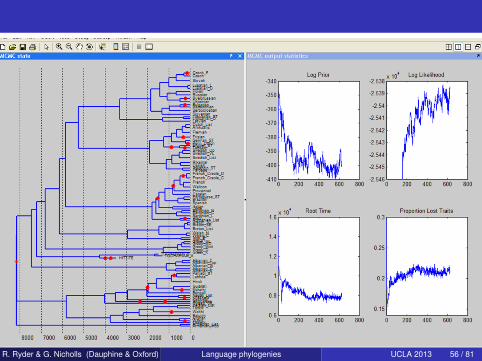
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 56 / 81
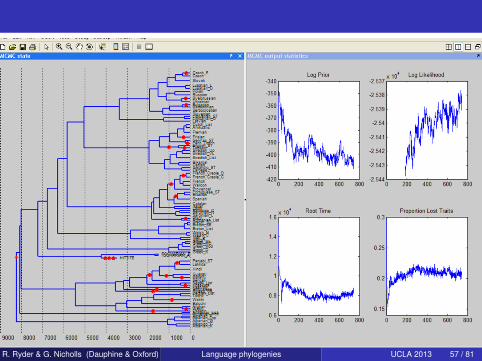
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 57 / 81
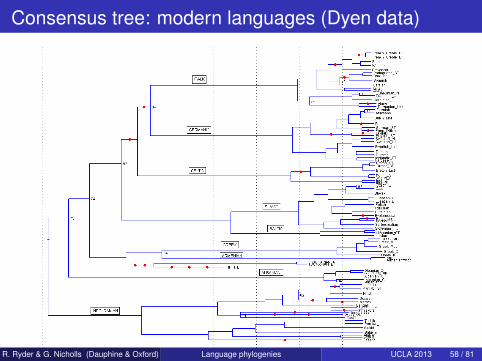
Consensus tree: modern languages (Dyen data)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 58 / 81

Consensus tree; ancient languages (Ringe data)
armenian
albanian
oldirish
welsh
luvian
oldnorse
oldenglish
oldhighgerman
gothic
lycian
oldcslavonic
latvian
lithuanian
oldprussian
tocharian_a
tocharian_b
hittite
greek
vedic
avestan
oldpersian
latin
umbrian
oscan
62
78
66
85
58
0 10002000300040005000600070008000
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 59 / 81
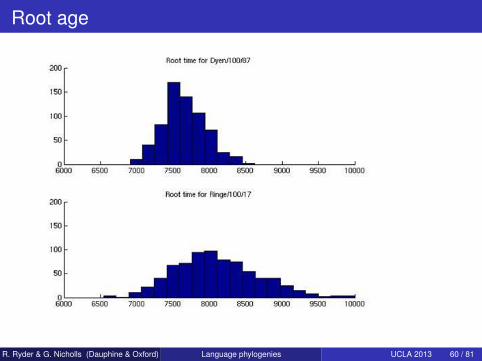
Root age
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 60 / 81

Conclusions
Strong support for Anatolian farming hypothesis: root around 8000BPStatistics reconstruct known linguistic facts and answerunresolved questionsTraitLab: it’s free! (Though Matlab is not...)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 61 / 81

Outline
1 Data
2 Model
3 Inference
4 In-model validation
5 Model mis-specification
6 Results
7 Semitic lexical data
8 Bergsland and Vogt
9 Punctuational bursts
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 62 / 81

Semitic lexical data
Data: Kitchen et al. (2009)25 languages, 96 meanings, 674 cognacy classesQuestions of interest: root age (constraint known), topology,outgroup
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 63 / 81
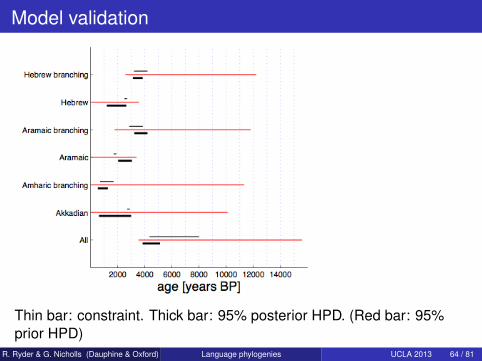
Model validation
Thin bar: constraint. Thick bar: 95% posterior HPD. (Red bar: 95%prior HPD)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 64 / 81
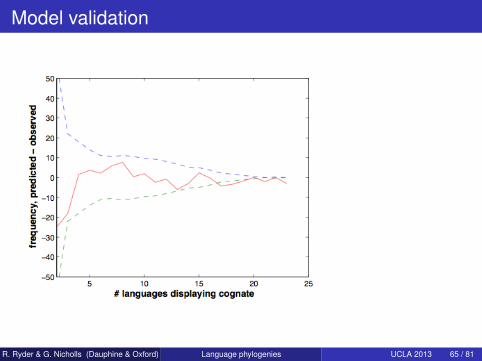
Model validation
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 65 / 81
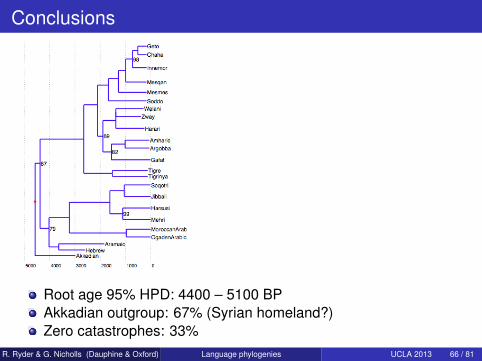
Conclusions
Root age 95% HPD: 4400 – 5100 BPAkkadian outgroup: 67% (Syrian homeland?)Zero catastrophes: 33%
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 66 / 81
Outline
1 Data
2 Model
3 Inference
4 In-model validation
5 Model mis-specification
6 Results
7 Semitic lexical data
8 Bergsland and Vogt
9 Punctuational bursts
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 67 / 81

Back to Bergsland and Vogt
Norse family, 8 languages.Selection biasClaim that the rate of change is significantly different for thesedata.B&V included words used only in literary Icelandic, which weexcludeWe can handle polymorphismDo not include catastrophes
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 68 / 81
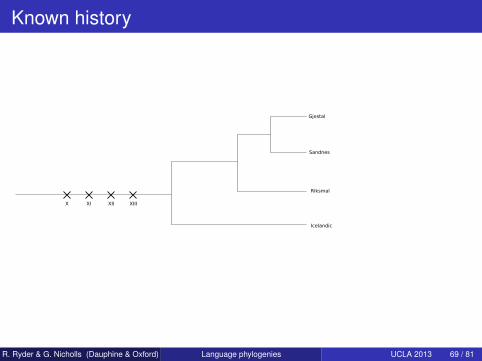
Known history
Icelandic
Riksmal
Sandnes
Gjestal
X XI XII XIII
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 69 / 81

Tests
Two possible ways to test whether the same model parameters applyto this example and to Indo-European:
1 Assume parameters are the same as for the generalIndo-European tree, and estimate ancestral ages.
2 Use Norse constraints to estimate parameters, and compare toparameter estimates from general Indo-European tree
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 70 / 81

Results
If we use parameter values from another analysis, we can try toestimate the age of 13th century Norse.True constraint: 660–760 BP. Our HPD: 615 – 872 BP.If we analyse the Norse data on its own, we estimate parameters.Value of µ for Norse: 2.47± 0.4 · 10−4
Value of µ for IE: 1.86± 0.39 · 10−4 (Dyen), 2.37± 0.21 · 10−4
(Ringe)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 71 / 81

But...
We can also try to estimate the age of Icelandic (which is 0 BP)Find 439–560 BP, far from the true valueB&V were right: there was significantly less change on the branchleading to Icelandic than averageHowever, we are still able to estimate internal node ages.
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 72 / 81

Georgian
Second data set: Georgian and MingrelianAge of ancestor: last millenium BCCode data given by B&V, discarding borrowed itemsUse rate estimate from Ringe et al. analysis
95% HPD: 2065 – 3170 BP
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 73 / 81

Georgian
Second data set: Georgian and MingrelianAge of ancestor: last millenium BCCode data given by B&V, discarding borrowed itemsUse rate estimate from Ringe et al. analysis95% HPD: 2065 – 3170 BP
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 73 / 81

B&V: conclusions
Third data set (Armenian) not clear enough to be recoded.There is variation in the number of changes on an edgeNonetheless, we are still able to estimate ancestral language ageVariation in borrowing ratesB& V: "we cannot estimate dates, and it follows that we cannotestimate the topology either".We can estimate dates, and even if we couldn’t, we might still beable to estimate the topology
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 74 / 81

Outline
1 Data
2 Model
3 Inference
4 In-model validation
5 Model mis-specification
6 Results
7 Semitic lexical data
8 Bergsland and Vogt
9 Punctuational bursts
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 75 / 81

Atkinson et al. (2008)
Hypothesis: when a language is founded by a migration, thefounder effect leads to fast change over a short period of time.There is a catastrophe at each branching event.Indirect estimation: correlation between number of changesbetween root and leaf, and number of branching events along thesame pathAtkinson: 21% of changes in the history of IE are due topunctuational bursts
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 76 / 81
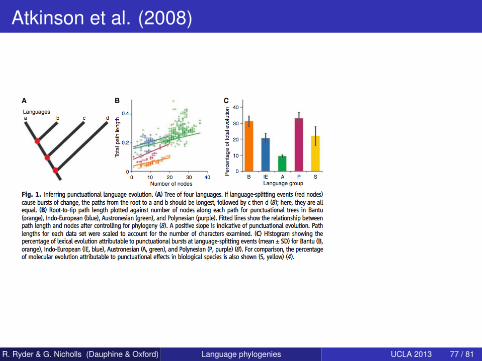
Atkinson et al. (2008)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 77 / 81

Direct analysis
We force a catastrophe on each edge.Infer size of catastrophes.Find κ very close to 0.Less than 1% of change can be attributed to punctuational bursts.Reason for discrepancy unclear.
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 78 / 81

Conclusions
Strong support for age of PIE around 8000 BPStatistical methods can help answer questions which traditionalmethods cannotMany more questions and models to comeTraitLab: it’s free! (although Matlab is not...)
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 79 / 81

Questions
otázky kessesspørgsmåler cwestiwnau
pytania preguntespreguntas vraekláusimai Fragenvoprosy quaestionesîntrebari questionsvragen ερωτ ησεις
zapitanni spurningardomande spørsmålerquestões frågorvprašanja
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 80 / 81

References
R. J. Ryder & G. K. Nicholls, Missing data in a stochastic Dollomodel for cognate data, and its application to the dating ofProto-Indo-European (2011), JRSS CG. K. Nicholls, Horses or farmers? The tower of Babel andconfidence in trees (2008), Significance (popular science)G. K. Nicholls & R. J. Ryder, Phylogenetic models for Semiticvocabulary (2011), IWSMR. J. Ryder, Phylogenetic Models of Language Diversification(2010), DPhil. thesis, University of Oxford
R. Ryder & G. Nicholls (Dauphine & Oxford) Language phylogenies UCLA 2013 81 / 81
Recommended

















