1 개념2 특징3 집계하기4 성능개선

1. 개념

“ 중복되지 않은 아이템들의 갯수”
수학적 용어로 기수 (CARDINAL NUM-BER)

1233 3개
1. 예제

2. 대표적인 사례
* UV vs PV
UV (Unique Visitor) - 설정된 기간동안 방문한 순방문- 해당사이트를 1 회 방문하건 , 10 회
방문하건 , 방문자는 1 로 체크
PV (Page View) - 페이지가 열린 횟수- 구분없이 페이지가 열린 경우 카운팅
됨
PV 에서는 극단적으로 1 명의 헤비유저가 데이터를 훼손 할 수 있음( 새로고침으로 신공으로 PV 올리기 )

2. 특징

2-1. 부분집계의 재활용 불가
날짜 요소 Count/SUM Max Min UC
2014-01 1, 2, 3, 4, 4 5 4 1 4
2014-02 1, 4, 1 3 4 1 2
2014-03 2, 6 2 6 2 2
2014-05 7, 5 2 7 5 2
2014-06 5, 1, 3 3 5 1 2
2014-01 ~ 2014-06 의 결과 ?

2-1. 부분집계의 재활용 불가
날짜 요소 Count/SUM Max Min UC
2014-01~ 2014-06
1, 2, 3, 4, 41, 4, 12, 67, 55, 1, 3
15 6 1 7
2014-01 ~ 2014-06 의 결과임 .

2-1. 부분집계의 재활용 불가
날짜 요소 Count/SUM Max Min UC
2014-01 1, 2, 3, 4, 4 5 4 1 4
2014-02 1, 4, 1 3 4 1 2
2014-03 2, 6 2 6 2 2
2014-05 7, 5 2 7 5 2
2014-06 5, 1, 3 3 5 1 2
15 7 1
하지만 , UC 를 제외한 값은 부분집계 값 (value) 를 통해 더 쉽게 구할 수 있음
????

UC 에서는 집계한 결과 (Value) 로는 전체결과를 유도 할 수 없음
즉 , 모든 요소를 유지 해야 함

2-2. 요소의 분배
값은 부모 단계로 승계 안되나 , 부분집합형태로 구성이 가능함집합 개념으로 보면 이해가 편함 .
1
23
4
6
1
2
34
6
∪
5 개 2 개 3 개
2-2. 요소의 분배
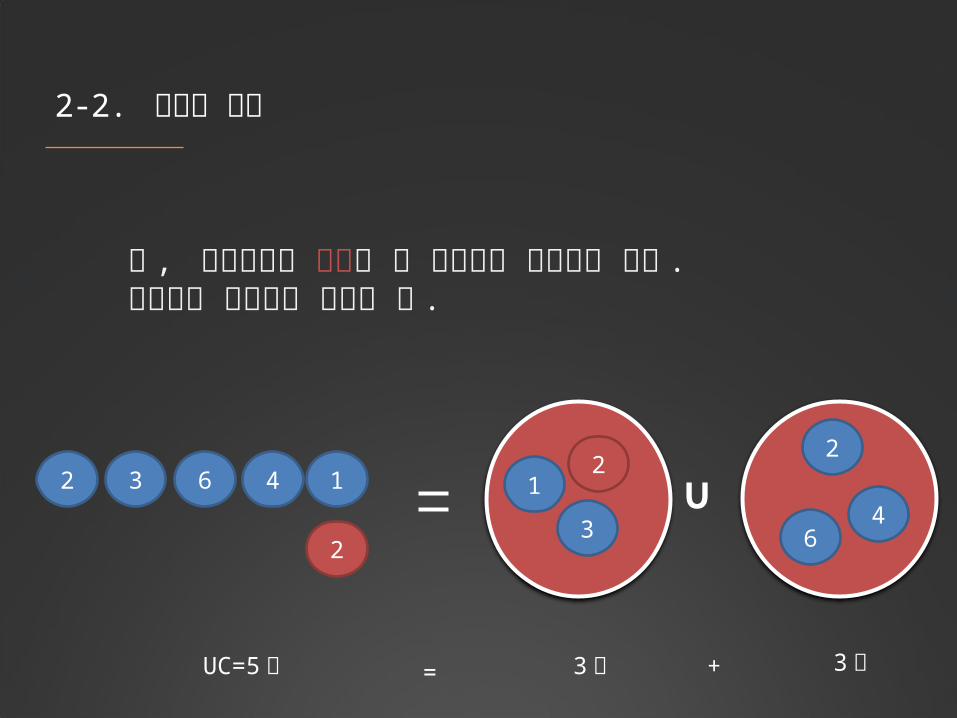
단 , 서브셋으로 구성할 때 교집합이 존재하면 안됨 .분배할때 상호배제 되어야 함 .
12 3 46 1
2
34
6
∪
UC=5 개 3 개 3 개
2
2
+=

3. 집계하기

3-1. 기본 지식
selectcount(distinct 필드명 ) as uc
fromt_table
Set<String> set = new HashSet<String>();set.add(“a”);set.add(“a”); // 중복set.add(“xxx”);set.add(“yyy”);
System.out.println( set.size() ); // print : 3
쿼리문
소스코드 (set)

그렇다면 , 대용량은 ?

3-2. Hadoop? M/R?
하둡 M/R 로는 UC 에 적당하지 않음 .
하둡은 KEY 단위로 모아서 iterator<Value> 형태로 모아줌 .즉 , Value 에서 중복을 제거해야 하는데 사이즈가 크면 메모리가 부족함
하둡은 KEY 단위로 분산을 해주는것이지 Value 단위로 분산해주는것이 아님 !!!!

3-2. Hadoop? M/R?
그럼 ? KEY 요소로 써서 카운팅 하면 되지 않을까 ?
가능함 .
하지만 결과 파일은 중복이 제거된 값들을 결과로 받음 .즉 , ‘wc –l’ 같은 명령으로 라인수를 세어야 할 것임 .
그리고 더 A 결과와 B 결과의 UC 를 구하려면 또 M/R 을 돌리기 다양한 부분집합들로 구성될 때 몹시 화가 날것임 .

아이폰유저 아이패드유저
안드로이드 유저
A
B
EC
DF
G
이런 구성도 빠르게 구하려면 ?

대용량 = 분산
빠르게 = 메모리 기반
간단한 공식

확장 가능한 메모리 서버

3-3. 메모리 분산 서버
- 대용량 INPUT 은 하둡에서 Map 작업으로 요청 ( 리듀스 안씀 )
- 메모리 서버는 별도의 서버로 존재하며 네트워크로 전송 ( 성능을 위해 건별 요청을 하지 않고 내부 버퍼를 둬서 전달 )
- 서브셋으로 구성하여 스케일아웃한 구성
- 메모리 절약을 위해 대상값은 모두 숫자형으로 전환 (=bitset사용 )

MOD( 파티셔닝 )
[4,1,123,6,2,324,234, 6, 4,1,123]
[123,6,234]
[4,1,324]
[2]
기본구성
하둡서버 ( 여러대
임 )
merge 결과

메모리를 확장한 서버를 마련하여 구하고 .Set 의 구현체를 이용한다면 쉽게 UC 를 구할수 있고 부모 /자식관계의 UC 도 구하는 비용이 비교적 손쉬움 .
Set p = new Set();Set c1 = new Set();Set c2 = new Set();
p.addAll(c1);p.addAll(c2);
p.size();
복잡한 관계도 OK

4. 성능개선

HashSet 의 경우 integer 타입을 쓴다고 하면 ,이론상 4 바이트로 계산하면 2.5 억개 정도 담겨야 하지만 , 실제로 테스트해보면 563 만개 정도 담을 수 있음
단일 차원으로 보면 충분해 보이지만 ,다양한 차원으로 값이 승계되어야 한다면 ,모든 상태를 유지해야 하므로 메모리가 매우 많이 필요함 .
1. HashSet 의 메모리 사용
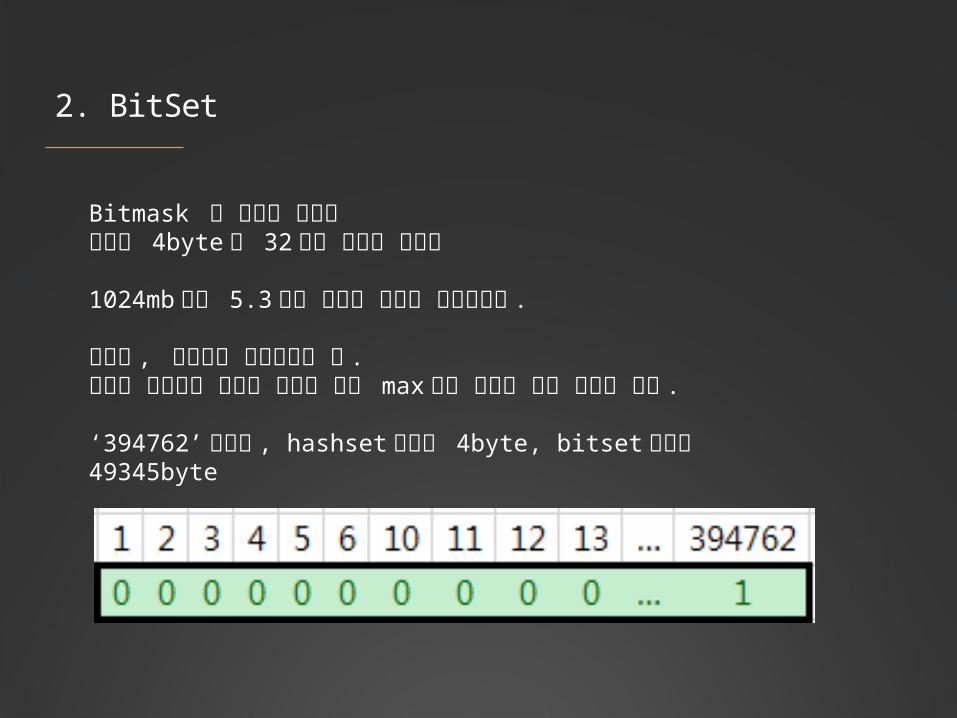
Bitmask 를 이용해 계산함이론상 4byte 면 32 개의 표현이 가능함
1024mb 에서 5.3 억개 수준의 상태가 표현가능함 .
단점은 , 숫자형만 가능하다는 점 .그리고 메모리의 크기가 개수가 아닌 max 값에 영향을 받는 문제가 있음 .
‘394762’ 이라면 , hashset 에서는 4byte, bitset 에서는 49345byte
2. BitSet

Bitset 의 단점을 보완하기 위해 1 만건 정도는 HashSet, 그 이상이 넘어가면 BitSet 으로 전환하는Set 을 구현 함 .
3. HashSet + BitSet (HybridSet)

3. HashSet + BitSet (HybridSet)
하지만 ,어느순간 대부분 1 만건이 넘어서 오히려 오버헤드가 되고 있음

4. SmartBitSet
앞의 문제를 해결 하기위해 최근 개발한 구현체
하나의 bitset 이 아니라 논리적 블럭단위로 bitset 을 사용함 .

public class SmartWappedBitSet implements Set<Integer> {private static final int DEFAULT_BLOCK_SIZE = 10000;//bit 갯수private int INIT_BLOCK_SIZE;private final Map<Integer,BitSet> folder;
public SmartWappedBitSet(final int blockSize) {this.INIT_BLOCK_SIZE = blockSize;folder = new HashMap<Integer,BitSet>();
}
public SmartWappedBitSet() {this(DEFAULT_BLOCK_SIZE);
}
@Overridepublic boolean add(Integer e) {
final int index = e / INIT_BLOCK_SIZE;final int value = e % INIT_BLOCK_SIZE;
if (!folder.containsKey(index)) {folder.put(index, new BitSet());
}folder.get(index).set(value);return true;
}
소스코드 일부

.Jvisualvm 분석결과
bit-set
smartbit-set
메모리는 반으로시간은 두배

.Jvisualvm 분석결과를 본 나

block bitset
Hybridset(HashSet + Bitset)
Hybridset 의 bitset 을 smartset 으로 바꿔봄
Hybridset2(HashSet + smartbitset)
성능이 더 안좋아짐으응 ?

Jstat 으로 GC 확인
심지어 GC 도 더 많이 발생함 .

이 결과를 본 내 생각

다시 분석
- 예상과 다르게 , HashSet 의 속도가 매우 느림 .
- Smartbitset 에서는 여러 개의 bitset 을 쓰는데 , 생성시간도 꽤 소요됨
- 데이터 분포를 본 결과 만건을 넘는 경우가 대부분이었음
- Hashset 에서 bitset 전환은 loop 로 돌아야 해서 비용이 싸지 않음

HybridSet SmartSet 으로 대체함

GC 도 확 줄어드는게 보임

반영 후 결과
- 기존대비 1/3 정도 메모리 절약
- 실행속도 3 배 상승
- 성능저하는 loop, GC, 잦은 instance 가 문제임
Recommended