
DMLA 2008-06-17小町守

(自分の博士論文に関係のある)半教師あり学習についての紹介 長所と短所のサーベイ
半教師あり学習使ってみようという人を増やす
2

半教師あり学習( Semi-supervised learning ) ラベルありデータとラベルなしデータの両方を
利用した学習法全般 ラベルありデータ : 正解が付与されているデータ ラベルなしデータ : 正解が付与されていないデータ
種類 クラスタリング、分類、回帰、ランキング、…
3
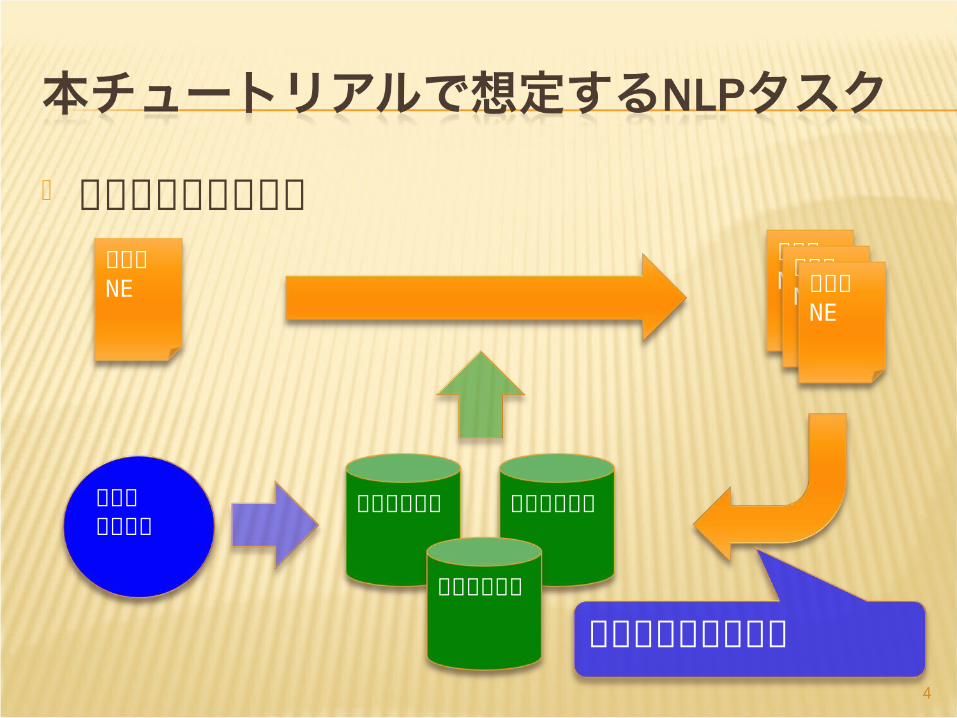
固有表現抽出タスク
大規模データ
シードNE
大規模データ
大規模データ
新しいNE
シードパターン
4
新しいNE
新しいNE
新たなパターン獲得

語義曖昧性解消タスク
5
大規模データ
シード用例
大規模データ
大規模データ
分類器
新たな用例獲得

ラベルありデータとラベルなしデータが存在
ラベルなしデータを使って性能向上したい (前提)
ラベルなしデータは大量に獲得可能 ラベルありデータは作成にコストがかかる
人手でつけるのは面倒 専門知識が必要 アノテーションツールが使いにくい(などなど……)
6
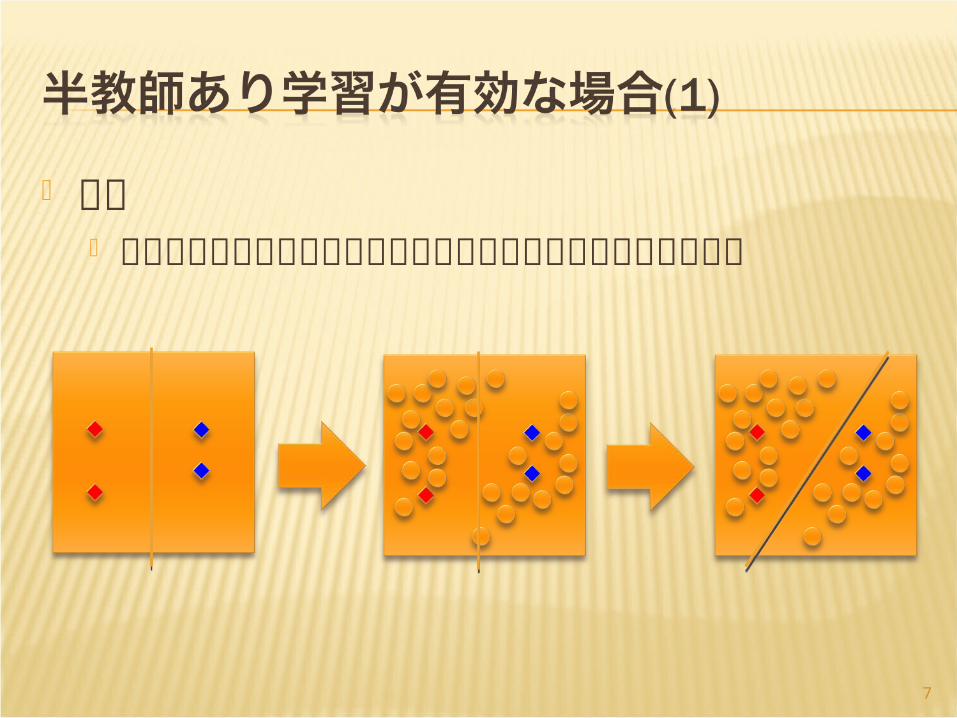
前提 インスタンスがたくさんあるところに分離平面
を引きたくない
7
8
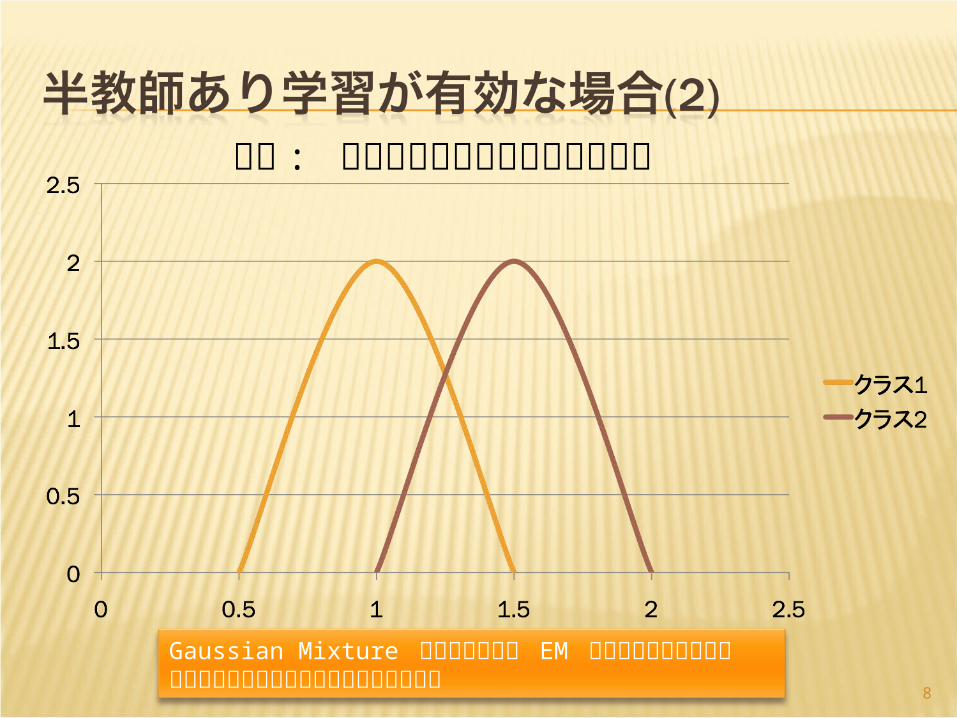
Gaussian Mixture のパラメータは EM で求めることができるクラスのラベルは正解付きデータから推定
前提 : データのよい生成モデルがある

分類器に基づく手法 初期分類器から始め、反復的に分類器を洗練 Self-training/co-training
データに基づく手法 データに備わっている構造を発見し、分類器を
構築する際に用いる グラフベースの手法
9

• 仮定– 分類器の出した確信度の高い予測結果は正しい
• アルゴリズム1. ラベルありデータから分類器を教師あり学習2. ラベルなしデータのラベルを予測3. ラベルなしデータと予測結果(擬似的な正解ラ
ベル)をラベルありデータに追加4. 繰り返し
10
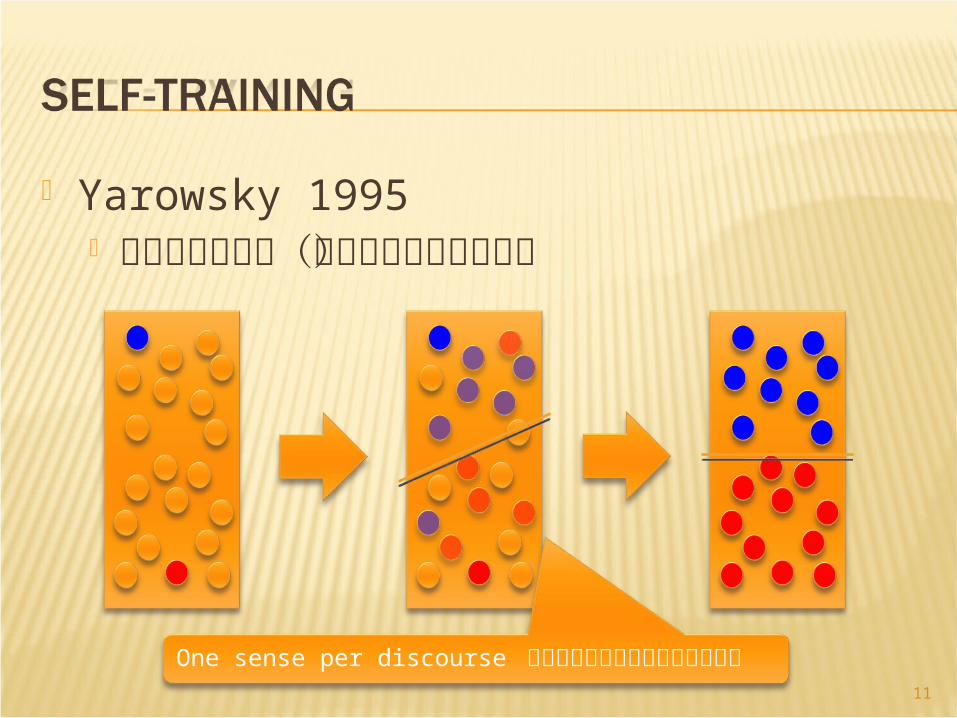
Yarowsky 1995 語義曖昧性解消(インスタンスは語義)
11
One sense per discourse の制約により新しいパターン獲得

ラベルなしデータのラベルを予測 予測ラベルを正解と見なしてラベルあり
データに追加 閾値以上の確信度の予測結果のみを追加 確信度の上位 k 個の予測結果のみを追加 重み付きで全ての予測結果を追加
ラベルありデータ + 予測ラベル付きラベルなしデータで分類器を教師あり学習
12
23/04/21
13
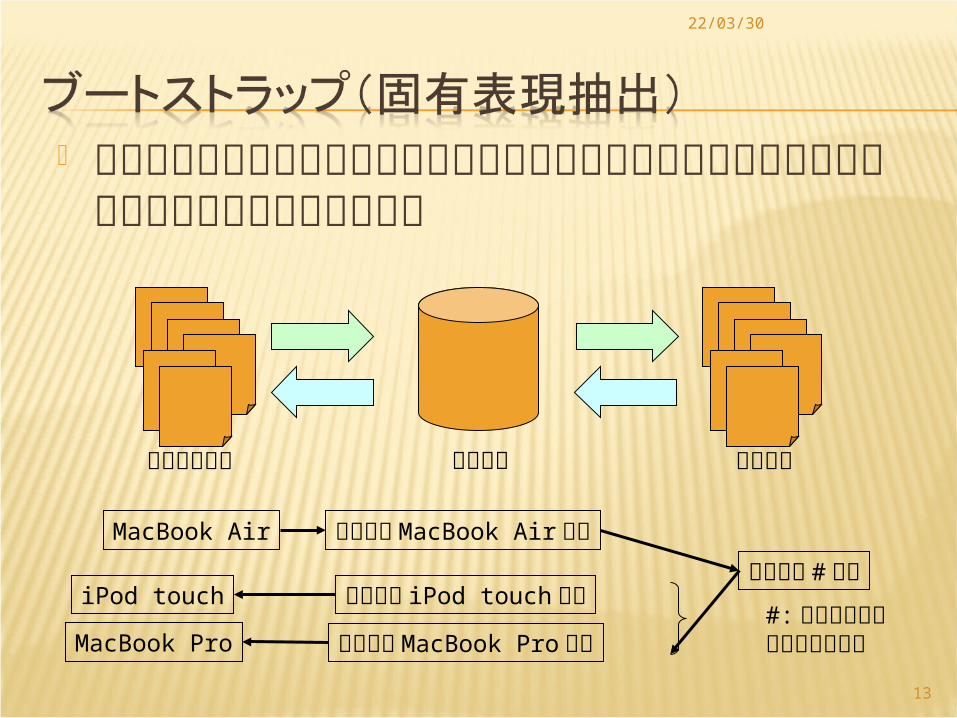
パターン抽出とインスタンス獲得を交互に繰り返して少量のシードインスタンスを反復的に増やす
インスタンス パターンコーパス
MacBook Air アップル MacBook Air 注文
アップル # 注文アップル iPod touch 注文
アップル MacBook Pro 注文
iPod touch
MacBook Pro#: インスタンスが入るスロット

特長 複雑な仮定が不要 ラッパーとして用いることができる
既存の分類器との親和性が高い NLP で実際よく使われている
問題点 真の分布に基づく分類器の実現は困難 初期に間違えると間違いが増幅される 収束条件がよく分からない
14

高次元スパース空間(素性の数が膨大で、訓練事例にはほとんど現れない場合)には不向き NLP では典型的には高次元スパース空間
本質的な性能の向上は見込めない 分類器自身が知っていることを再学習しても情報量
は増えない ( Cf. 能動学習 active learning )
ラベルなしデータの量を増やしても性能が向上しないことが多い
15

• 仮定– 素性分割が可能– 分割した素性それぞれで十分な分類器が学習可能– 分割した素性が条件付き独立
• アルゴリズム– 分割した素性から 2 つの学習器を学習– ラベルなしデータをそれぞれの分類器で分類– 分類器 1 の確信度上位 k 個を分類器 2 のラベルあり
データに追加– 分類器 2 の確信度上位 k 個を分類器 1 のラベルあり
データに追加– 繰り返し
16
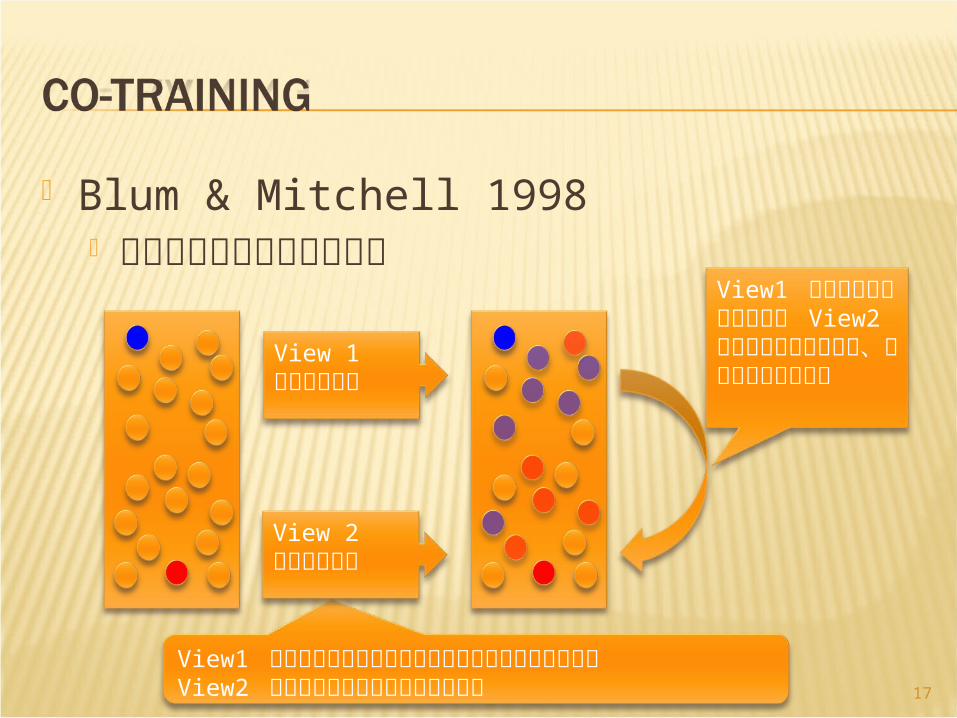
Blum & Mitchell 1998 ウェブページのラベル付け
17
View1 ページにリンクしているハイパーリンクのテキストView2 ウェブページのテキストそのもの
View 1による分類器
View 2による分類器
View1 の分類器の予測ラベルを View2 の分類器の訓練事例に、逆も同様にして反復

特長 Self-training より間違いに強い タスクの特徴をうまく捉えた使い方をした場合、
ラベルありデータの数が少ない場合は性能が向上したという報告あり
問題点 自然に素性を分割できる場合のみ有効
全素性を使って教師あり学習したほうがよい性能を得られる場合が多い(ランダムに素性を分割する話もある)
18

• Co-EM– 上位 k 個だけでなく全部の結果を追加する– 各分類器が確率的にラベルなしデータを予測– ラベルなしデータと予測結果を重み P(y|x) で追
加• Multiview Learning
– 素性分割なし– 複数のタイプの分類器を学習– ラベルなしデータを全ての分類器で予測– ラベルの多数決の結果を追加
19

ラベルありデータとラベルなしデータの対数尤度を最大化
€
log(P(y i |π )P(x i | y i,θ)) + log( P(y |π )P(x j | y,θ))y
∑j
∑i
∑
Ll: ラベルありデータの対数尤度
Lu: ラベルなしデータの対数尤度
20
θ
x
π
y

ラベルありデータとラベルなしデータの対数尤度を線形補間
EM で最適化することができる 最適な λ の値を求めるためのステップが必
要€
(1− λ )Ll − λLu
21

特長 ラベルなしデータを自然に組み込むことができる テキスト分類タスクではよい性能を示している
問題点 適切な生成モデルを使わないとよい性能は出ない パラメータを決めるステップが入る 少量のラベルありデータのときは性能向上するが
大量にラベルありデータがあるときは性能が悪化するという報告 (Merialdo, 1994) もある
22

仮定 類似サンプルは同一ラベルを持つ傾向にある
前提 サンプル間の類似度を定義可能
事前知識 , kNN
アイデア 類似度グラフに対してグラフベースのアルゴリ
ズムを用いてクラスタリング
23

Overlap がない状態でも propagation でうまくいく
隣接するノードは類似のラベルを持つ(図は Zhu 2007 より引用)
24

25

• 特長– グラフ理論など数学的な背景が確立– よいグラフが得られていればよい性能が得られる
• 問題点– 適切なグラフ構造(やエッジの重み)を得ることが
難しい– 計算量が相対的に大きい– Transductive な方法が多い
• Transductive: テスト事例が既知のときの学習• Inductive: 未知データを含む全データを対象
26

Self/co-training 教師あり学習との親和性が高いのでよく使われ
てきた うまくいったりいかなかったり、タスクに応じ
て使わないといけない グラフに基づく手法
NLP タスクにおけるよいグラフは自明でない 計算量が相対的に大きい
27

言語処理学会第 14 回年次大会チュートリアル : 半教師あり学習による分類法 :— 現状と自然言語処理への適用— , 鈴木潤・藤野昭典
ICML 2007 Tutorial: Semi-supervised Learning, Xiaojin Zhu.
NAACL 2006 Tutorial: Inductive Semi-supervised Learning with Applicability to NLP, A. Sarkar and G. Haffari.
28
Recommended

















