Embed Size (px)
Citation preview

Wide-area cooperative storage with CFS
Frank Dabek, M. Frans Kaashoek, David Karger, Robert Morris, Ion
Stoica

Quick recap of some other p2p systems
• File sharing systems (focus is on sharing files, persistence and reliable content location is not important)– Napster
• Centralized lookup, Storage of data is distributed, keyword search
– Gnutella• Distributed lookup and fetching based on scoped flooding, keyword search
– Freenet• Distributed lookup and storage, anonymity is a major design goal, queries are
routed based on lexical closeness of keys
• Storage utilities (focus is on persistence, efficient lookups, fault tolerance)– PAST
• Self-organizing overlay network that co-operatively route queries, caches and replicates data to provide a large-scale storage utility.

Introduction Peer-to-peer read only storage system Decentralized architecture focusing mainly on
efficiency of data access robustness load balance scalability
Provides a distributed hash table for block storage Uses Chord to map keys to nodes. Does not provide
anonymity strong protection against malicious participants
Focus is on providing an efficient and robust lookup and storage layer with simple algorithms.

CFS Software Structure
FS
DHASH
CHORD
DHASH
CHORD
DHASH
CHORD
CFS Client CFS ServerCFS Server
RPC API
Local API

Layer functionalities• Client file system layer interprets Dhash blocks in a format
adapted from SFSRO (similar to Unix)
• Client dhash layer uses client chord layer to locate blocks.
• Client chord layer uses the server Chord layer as a proxy to map key to the node that is responsible for the key.
• Server dhash layer stores the blocks, maintains proper level of replication and caching.
• Server chord layer interacts with peer chord layers to implement key lookup. Interacts with the local dhash layer to integrate checking for cached copies of the block during lookup.

Client identifies the root block using a public key generated by the publisher. Uses the public key as the root block identifier to fetch the root block and checks for the validity of the block using the signature File inode key is obtained by usual search through directory blocks . These contain the keys of the file inode blocks which are used to fetch the inode blocks. The inode block contains the block numbers and their corr. keys which are used to fetch the data blocks.

Properties of CFS• decentralized control – no administrative relationship between servers
and publishers.
• scalability – lookup uses space and messages at most logarithmic in the number of servers.
• availability – client can retrieve data as long as at least one replica is reachable using the underlying network.
• load balance – for large files, it is done through spreading blocks over a number of servers. For small files, blocks are cached at servers involved in the lookup.
• persistence – once data is inserted, it is available for the agreed upon interval.
• quotas – are implemented by limiting the amount of data inserted by any particular IP address
• efficiency - delay of file fetches is comparable with FTP due to efficient lookup, pre-fetching, caching and server selection.

Chord • Consistent hashing
– maps node IP address + Virtual host number into a m-bit node identifier.
– maps block keys into the same m bit identifier space.• Node responsible for a key is the successor of the key’s id with wrap-
around in the m bit identifier space.
• Consistent hashing balances the keys so that all nodes share equal load with high probability. Minimal movement of keys as nodes enter and leave the network.
• For scalability, Chord uses a distributed version of consistent hashing in which nodes maintain only O(log N) state and use O(log N) messages for lookup with a high probability.

……the details• two data structures used for performing lookups
– Successor list : This maintains the next r successors of the node. The successor list can be used to traverse the nodes and find the node which is responsible for the data in O(N) time.
– Finger table : ith entry in the finger table contains the identity of the first node that succeeds n by at least 2i –1 on the ID circle.
• lookup pseudo code– find id’s predecessor, its successor is the node responsible for the key– to find the predecessor, check if the key lies between the node-id and its
successor. Else, using the finger table , find the node which is the closest predecessor of id and repeat this step.
– since finger table entries point to nodes at power-of-two intervals around the ID ring, each iteration of above step reduces the distance between the predecessor and the current node by half.

Node join/failure• Chord tries to preserve two invariants
– Each node’s successor is correctly maintained.– For every key k, node successor(k) is responsible for k.
• To preserve these invariants, when a node joins a network– Initialize the predecessors, successors and finger table of node n– Update the existing finger tables of other nodes to reflect the addition of n– Notify higher layer software so that state can be transferred.
• For concurrent operations and failures, each Chord node runs a stabilization algorithm periodically to update the finger tables and successor lists to reflect addition/failure of nodes.
• If lookups fail during the stabilization process, the higher layer can lookup again. Chord provides guarantees that the stabilization algorithm will result in a consistent ring.

Server selection• added to Chord as part of CFS implementation.• basic idea is to select a server from the list of all servers n’ such that n’ € (n , id)
with minimum cost where– C(n’) = di + davg * H(n’)
H(n’) = ones ((n’ – id) >> (160 – log N)) where
H(n’) is an estimate of the number of the chord hops that would remain after contacting n’
davg is the average latency of all RPCs that node n ever issued.
di is the latency to n’ as reported by node m.
• Latencies are measured during finger table creation, so no extra measurements necessary.
• This works only well for latencies such that low latencies from a to b and from b to c => that the latency is low between a and c
– Measurements suggest this is true. [A case study of server selection, Masters thesis]

Node Id Authentication
• Attacker can destroy chosen data by selecting a node ID which is the successor of the data key and then deny the existence of the data.
• To prevent this, when a new node joins the system, existing nodes check– If the hash (node ip + virtual number) is same as the professed node id
– send a random nonce to the claimed IP to check for IP spoofing
• To succeed, the attacker would have to control a large number of machines so that he can target blocks of the same file (which are randomly distributed over multiple servers)

Dhash Layer
• Provides a distributed hash table for block storage
• reflects a key CFS design decision – split each file into blocks and randomly distribute the blocks over many servers.
• This provides good load distribution for large files .
• disadvantage is that lookup cost increases since lookup is executed for each block. The lookup cost is small though compared to the much higher cost of block fetches.
• Also supports pre-fetching of blocks to reduce user perceived latencies.
• Supports replication, caching, quotas , updates of blocks.

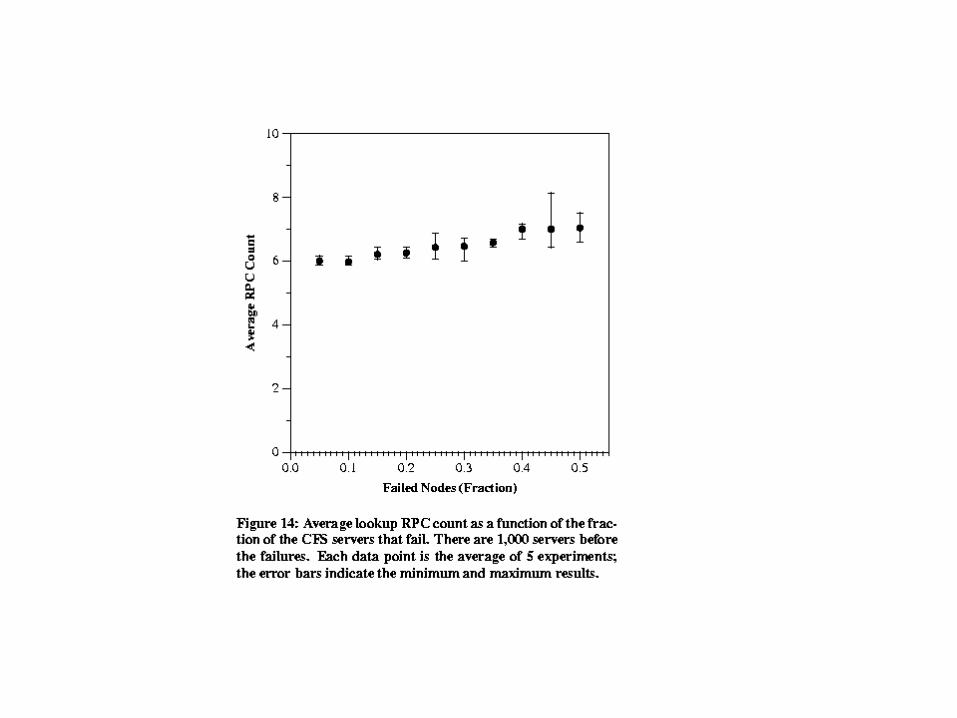
Replication• Replicates the blocks on “k” servers to increase availability.
– Places the replicas at the “k” servers which are the immediate successors of the node which is responsible for the key
– Can easily find the servers from the successor list (r >=k)– Provides fault tolerance since when the successor fails, the next server can
serve the block.– Since in general successor nodes are not likely to be physically close to
each other , since the node id is a hash of the IP + virtual number, this provides robustness against failure of multiple servers located on the same network.
– The client can fetch the block from any of the “k” servers. Latency can be used as a deciding factor. This also has the side-effect of spreading the load across multiple servers. This works under the assumption that the proximity in the underlying network is transitive.

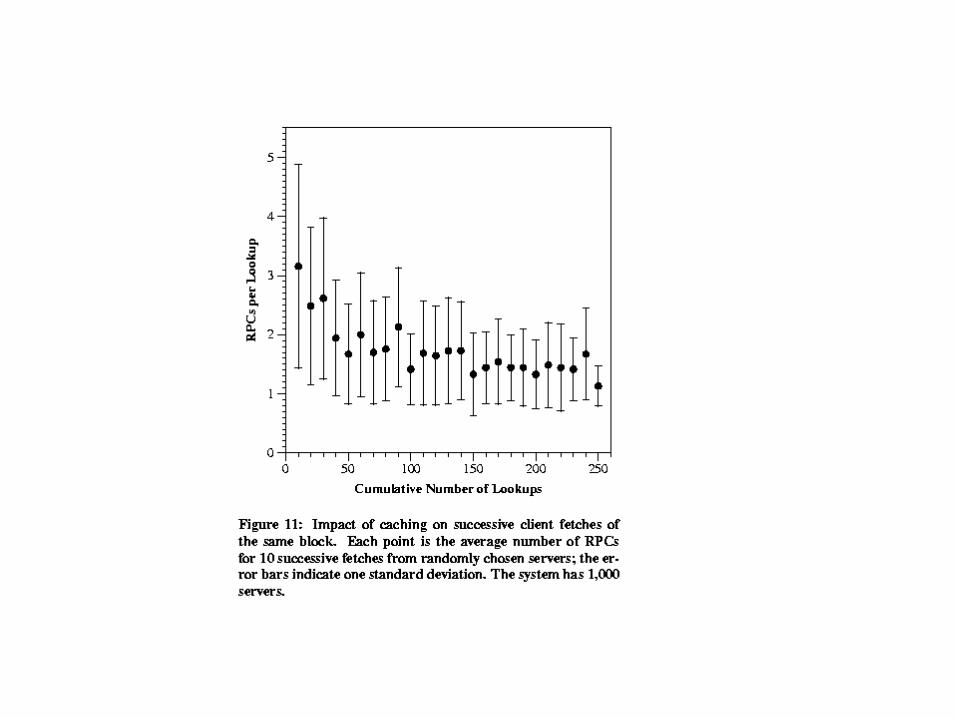
Caching• Dhash implements caching to avoid overloading servers for popular
data.
• Caching is based on the observation that as the lookup proceeds more and more towards the desired key, the distance traveled across the key space with each hop decreases. This implies that with a high probability, the nodes just before the key are involved in a large number of lookups for the same block. So when the client fetches the block from the successor node, it also caches it at the servers which were involved in the lookup .
• Cache replacement policy is LRU. Blocks which are cached on servers at large distances are evicted faster from the cache since not many lookups touch these servers. On the other hand, blocks cached on closer servers remain alive in the cache as long as they are referenced.

Implementation• Implemented in 7000 lines of C++ code including 3000 lines of Chord• User level programs communicate over UDP with RPC primitives
provided by the SFS toolkit.• Chord library maintains the successor lists and the finger tables. For
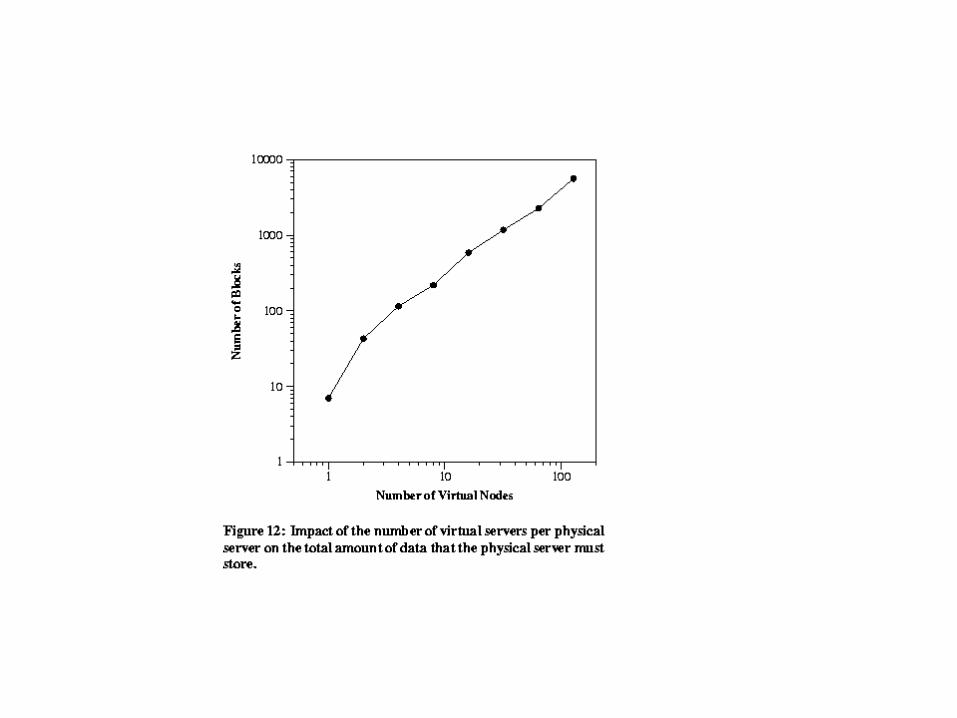
multiple virtual servers on the same physical server, the routing tables are shared for efficiency.
• Each Dhash instance is associated with a chord virtual server. Has its own implementation of the chord lookup protocol to increase efficiency.
• Client FS implementation exports an ordinary Unix like file system. The client runs on the same machine as the server, uses Unix domain sockets to communicate with the local server and uses the server as a proxy to send queries to non-local CFS servers.

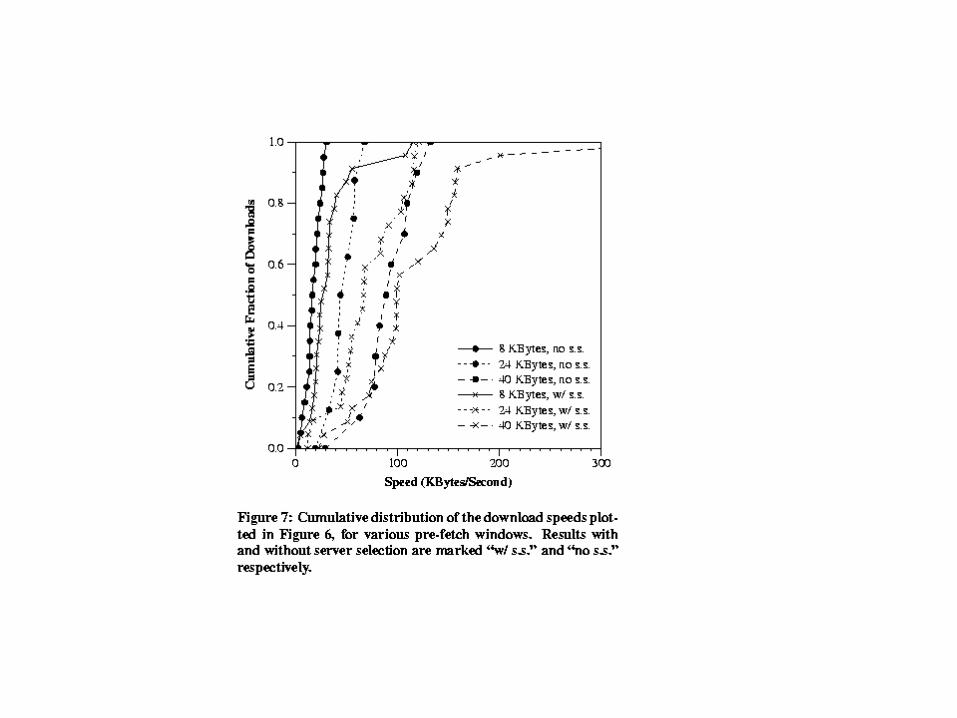
Experimental results• Two sets of tests
– To test real-world client-perceived performance , the first test explores performance on a subset of 12 machines of the RON testbed.
• 1 megabyte file split into 8K size blocks
• All machines download the file one at a time .
• Measure the download speed with and without server selection
– The second test is a controlled test in which a number of servers are run on the same physical machine and use the local loopback interface for communication. In this test, robustness, scalability, load balancing etc. of CFS are studied.







Future Research
• Support keyword search– By adopting an existing centralized search engine (like Napster)– use a distributed set of index files stored on CFS
• Improve security against malicious participants.– Can form a consistent internal ring and can route all lookups to nodes internal to the
ring and then deny the existence of the data– Content hashes help guard against block substitution.– Future versions will add periodic “routing table” consistency check by randomly
selected nodes to see try to detect malicious participants.
• Lazy replica copying to reduce the overhead for hosts which join the network for a short period of time.
• Adapting the pre-fetch window size dynamically based on RTT and network bandwidth much like TCP






![Chdhord (CAN,Tapestry, Pastry) [Stoica01a]mhchen/CN2010/Slides/P2P_overview_… · Stoica, R. Morris, D. Karger, F. Kaashoek, and H B l krishn n H.Balakrishnan. Chord: A peer-to-peer](https://img.dokumen.tips/doc/110x75/5fccde7353a14158566afd66/chdhord-cantapestry-pastry-stoica01a-mhchencn2010slidesp2poverview.jpg)






















