Embed Size (px)
Citation preview

Weka를 이용한 데이터마이닝 기초(I)
Application Guide of Weka for Data Mining Analysis(I)
박보국
부산대학교 전자전기컴퓨터공학과
Abstract
생산되는 자료의 양이 크게 증가함에 따라 주어진 자료를 분석하여 의미를 찾아내는
데이터마이닝이 중요해졌다. 또한 대용량 자료를 처리하는 소프트웨어 기술 발전과 더불어
하드웨어의 계산 성능의 증대는 이러한 흐름에 힘을 더하고 있다. 기업에서는 이 기법을
활용하여 고객의 성향이나 욕구를 분석하여 마케팅에 활용하고 있다. 실제로 보험 사기나
카드 부정 사용 등을 적발하는데 사용되고 있다. 본 보고서는 대표적인 무료 데이터마이닝
도구인 Weka(Waikato Environment for Knowledge Analysis)의 사용 방법을 간단한 예제를
통해 소개하고자 한다. 이론으로만 알고있었던 데이터마이닝 기법들을 데이터마이닝 도구
를 곧바로 테스트 해볼 수 있다.
Keywords: Weka, 데이터마이닝
1 데이터마이닝 개요
“데이터마이닝은 통계 및 수학적 기술뿐만 아니라 패턴인식 기술들을 이용하여 데이터 저장
소에 저장된 대용량의 데이터를 조사함으로써 의미있는 새로운 상관관계, 패턴, 추세 등을 발
견하는 과정이다.”라고 정의할 수 있다 [1]. 데이터마이닝은 생산되는 자료의 양이 급격하게
증가함에 따라 그 중요성이 재조명 되었다. 1950년 가장 큰 규모의 회사들이 보유한 전자문서
형태의 자료가 수십메가바이트 정도에 불과했다. 반면에 2003년 당시 대규모 유통 소매업체인
월마트는 10테라바이트(terabyte)용량의데이터베이스에매일 2천만건의거래데이터를저장하
였다. IDC가 예측한 2011년에 생성될 디지털정보량은 약 1.8ZB(1.8조 기가바이트)에 달한다고
예측하였다. 점점 더 많은 양의 자료들이 수집될 뿐만 아니라 각 사건에 대해 보다 상세한 정
보들까지 기록되고 있다. 예를 들어 이동 경로, 검색 기록 등 이 모든 행위들은 매우 상세한
단위로 측정되고 있다. 이를 이용하여 기업에서는 고객과 고객의 욕구 등을 분석하고 있다.
1

데이터마이닝은 다양한 분야에서 사용될 수 있다. 군사분야에서는 미사일의 정확도에 영
향을 주는 요인들을 알아내기 위해 데이터마이닝을 사용하고 있으며, 국가정보기관은 엄청난
양으로 도청되는 통신들 가운데 특히 중요성이 높은 통신을 찾아내기 위해 데이터마이닝을
활용하기도 한다. 그리고 의학연구자들은 암의 재발가능성을 예측하기 위해 데이터마이닝을
사용한다. 구체적으로 비즈니스 분야에서는 다음과 같은 문제들을 생각해볼 수 있다. 첫째, 수
많은고객목록중어느고객이신규보험상품에가입할가능성이높은가?보험가입가능성이
높은 고객들에게 적극적으로 마케팅하여 마케팅의 효율을 높일 수 있다. 둘째, 보험 사기인
고객을 적발하여 부정 고객을 적발할 수 있다. 셋째, 대출신청자의 파산 확률을 예측하여 대충
승인 여부를 결정할 수 있다. 넷째, 전화, 잡지 등의 가입서비스를 이탈할 고객들을 식별하여
할인 또는 다른 유인책들을 선별적으로 내놓을 수 있다.
지금까지 데이터마이닝이 대두된 이유와 이를 사용하여 분석하고자 하는 목표에 대해서
알아보았다. 본 보고서에서는 대표적인 무료 데이터마이닝 도구인 Weka [2]를 이용하여 교사
학습을 적용해보고 그 결과를 분석를 분석하는 지표에 대해 살펴볼 것이다.
2 데이터마이닝 프로세스
Weka는 데이터마이닝 기법들과 각종 전처리 기법 등을 모듈 형태로 구현해놓았다. 우리는 이
것을 적재적소에 사용하여야 한다. 따라서 전체적인 데이터마이닝 프로세스를 파악하는 것은
중요하다.이번장에서는데이터마이닝에서가장기초적인개념과프로세스에대해서소개한다.
2.1 데이터마이닝의 주요 개념
• 분류(classification) - 어떤 개체를 규칙에 따라 사전에 정해진 집단 중 하나로 분류하는
것이다. 질병환자는 병이 완치되든지 아니면 여전히 아프거나 사망으로 분류할 수 있다.
대출신청자는 제때 또는 늦게 돈을 갚거나 파산을 선언하는 사람으로 분류할 수 있다.
• 예측(prediction) -수치형변수의값을예측한다는점을제외하고는분류문제와유사하다.
• 연관성규칙(association rules) -대량의고객거래데이터베이스에서구매항목들간의연관
성을분석하는데알맞다.예를들어넷플릭스또는아마존등의온라인상점들에서새로운
구매를 추천해주는 추천시스템의 핵심기법으로 이 기법들이 사용되고 있다.
• 지도학습(supervised learning) -분류와예측을위해사용되는알고리즘이다.이를위해서
는 주요 출력변수의 값(예를 들어 구매 또는 비구매)이 알려져 있어야 한다. 지도학습은
학습용데이터(training data)를이용하여예측변수와출력변수간의관계를학습한다.학
습을 통해 만들어진 모형을 검증용 데이터(validation data)를 통해 모형의 성능이 실제로
2

적용 가능한가 검증하는데 사용된다.
• 비지도학습(unsupervised learning) - 예측 또는 분류를 위해 필요한 출력변수가 없는 경
우에 사용되는 알고리즘이다. 알려진 출력변수가 없음으로 학습과정은 존재하지 않는다.
• 과적합화(overfitting) - 복잡한 형태를 갖는 함수를 이용하여 잡음들까지도 만족시키는
모델을 생성할 수 있다.
2.2 변수 전처리와 정제과정
변수의 종류는 여러 가지가 있다. 여기에는 숫자형(numerical) 변수, 명목형(nominal) 변수, 텍
스트형(string)변수,날짜(date)변수가있다.숫자형은실수값을의미한다.두개의숫자형값은
서로비교가가능하며연속적인값이다.상황에따라서이산적인특징을띌수있으며서열화도
가능하다. 예를들어 사이트에 로그인한 횟수 등이 있다. 명목형은 종교의 경우 불교, 개신교,
천주교, 무교, 기타 중 하나가 될 수 있을 것이다. 명목형 속성은 값의 대소 비교가 불가능하다.
속성들 간에는 변환이 가능한데, 숫자형 속성을 이산형으로 바꾸고자 한다면 특정 숫자
범주를 특정 이산 값으로 할당해 속성변환이 가능하다. 예를 들어 홈페이지 하루 방문자수에
따라 사이트의 규모를 “소형”, “중형”, “대형”으로 이산화하기 위해 0-1,000명을 “소형”, 1,001-
100,000명을 “중형”, 100,001이상을 “대형” 홈페이지로 할당할 수 있을 것이다.
2.3 데이터마이닝의 수행단계
1. 데이터마이닝 프로젝트의 목적을 확인한다.
2. 분석에 사용될 데이터를 획득한다.
대량의 데이터베이스에서 무작위로 표본을 추출한다.
3. 데이터를 탐색, 정제 그리고 전처리한다.
결측치(missing values)를 어떻게 처리해야 하는가?
4. 필요한경우데이터를축소하고지도학습의경우학습용,평가용,검증용데이터집합으로
분할한다.
불필요한 변수를 제거하고, 변수를 변환하며(예를 들어 지출비용을 100달러를 초과하는
비용과 100달러 이하인 비용으로 변환하기), 새로운 변수를 생성시키는(예를 들어 여러
제품 중 최소 1개 이상의 제품을 구입했는지 알려주는 변수)등의 작업을 포함한다.
5. 데이터마이닝 업무(분류, 예측, 군집 등)를 결정한다.
데이터마이닝 프로젝트의 목적에 맞는 분석유형을 선택하는 단계이다.
3

6. 사용할 데이터마이닝 기법들(회귀분석, 신경망모형, 계층적 군집분석 등)을 선택한다.
7. 알고리즘을 적용하여 데이터마이닝 작업을 수행한다. 이 단계는 일반적으로 반복적인 과
정으로서,하나의알고리즘내에서변수또는알고리즘의세부조건등을달리하여다양한
변인들을 적용해본다. 이러한 조건들이 적절한 경우 평가용 데이터를 이용한 알고리즘의
성과로부터 피드백을 받아서 적합하게 개선되는 변인들을 사용하도록 한다.
8. 알고리즘의 결과를 해석한다.
9. 모형을 활용한다.
3 Weka를 이용한 데이터마이닝 적용
이번 장에서는 Weka의 GUI를 통해 데이터마이닝을 적용하는 방법에 대해 설명한다. Weka
는 3가지 인터페이스 GUI, CLI(command-line interface), API를 제공한다. CLI는 쉘이나 명
령 프롬프트에서 Weka의 클래스 모듈을 직접 호출 할 수 있도록 한다. 이를 이용하면 단순한
작업을 반복 수행할 때 유용할 것이다. API는 Java 소스코드 상에서 Weka의 인스턴스를 생
성할 수 있다. 다시 말해서 소스코드 상에서 Weka의 기능을 그대로 사용할 수 있다. 따라서
어플리케이션에서 Weka의 기능을 이용하고자 할 때 또는 전처리부터 결과분석까지 자동화된
데이터마이닝 프로세스를 만들고자 할 때 사용할 수 있다. 본 보고서에서는 Weka의 CLI와
API방식은제외하고 GUI방식으로데이터마이닝하는방법을소개한다.그리고Weka의자료
입력 형식인 ARFF(Attribute-Relation File Format)에 대해 살펴본다. 마지막으로 교사학습을
수행한 뒤 실험결과를 분석하는 지표에 대해서 소개한다. 사용한 Weka의 버전은 3.6이며 예제
자료는 $WEKAHOME/data/iris.2D.arff에 있다.
3.1 Weka GUI
Weka는 총 3가지 인터페이스를 제공하는데 그 중에 하나가 GUI다. GUI 환경에서는 이것저
것 다양한 데이터마이닝 기법을 적용하기 편리하며 또한 산점도 행렬(scatter plot matrix)이나
Boundary Visualizer등시각적요소를통해자료의변수간의관계를파악하기좋다. Weka를실
행한화면은그림 1과같다.크게 Explorer, Experimenter, KnowledgeFlow, Simple CLI 4가지의
메뉴가 있다.
• Explorer - 1개의 데이터에 대해 다양한 기법을 적용하고 여러 시각적 분석 환경을 제공
한다.
• Experimenter - 다수의 데이터에 대해 여러 기법을 한 번에 적용하고, 알고리즘이나 데이
터간 성능을 비교해볼 수 있는 환경이다.
4
그림 1: Weka GUI 메인 메뉴.
• KnowledgeFlow - 기능적으로는 Explorer와 동일하지만, 기능을 하나씩 추가해가며 증분
학습(Incremental Learning)을 할 수 있다.
• Simple CLI - command-line 인터페이스로 Weka의 자바 클래스를 바로 실행할 수 있다.
그림 2: Explorer에서자료를불러온화면.좌측에자료의종류가나열되어있고,우측하단에는petallength별 클래스 분포를 보여줌.
본보고서에서는Weka의 explorer메뉴에대해집중적으로살펴볼것이다.그림 2는Weka의
explorer를 실행하고 자료를 불러온 화면이다. 이 자료는 꽃잎의 길이(petallength)와 폭(petal-
width) 그리고 꽃의 종류(class)를 변수로 가진다. 그림의 아래쪽에 위치한 차트는 클래스(꽃의
종류)별로 petallength의 분포를 보여준다. 상단의 탭 메뉴는 Preprocess, Classify, Cluster, As-
sociate, Select attributes, Visualize가 있다. 각각을 간략히 소개하자면 Preprocess는 데이터
5
불러오기 및 기계학습 알고리즘을 적용하기 전 데이터에 전처리 작업에 관련된 기능을 제공
한다. 자료 중 일부 변수를 제거하거나 자료 값을 수정하는 등을 할 수 있다. Filter 기능은
데이터의 속성을 바꾸거나(예를들어 Numeric에서 Nominal로 변경), 주성분 분석, 정규화 등
여러가지 전처리 기능을 지원한다. 그리고 각 메뉴는 다음과 같은 기능이 있다. Classify는 지도
학습(분류), Cluster는 비지도 학습(군집화), Associate는 연관성규칙 분석을 수행할 수 있다.
그리고 Visualize는 자료의 모든 변수 쌍에 대한 산점도 행렬을 보여준다. 이는 변수 간의 상
관관계 등 데이터를 이해하는데 큰 도움이 된다. 마지막으로 Select attributes이다. 기계학습의
성능이변수의종류가많다고좋은좋아지는것이아니라,클래스들의특징을잘나타낼수있는
변수를 선택하는 것이 중요하다. 이 메뉴를 사용하면 출력변수와 관계있는 입력변수를 추출할
수 있도록 도와준다.
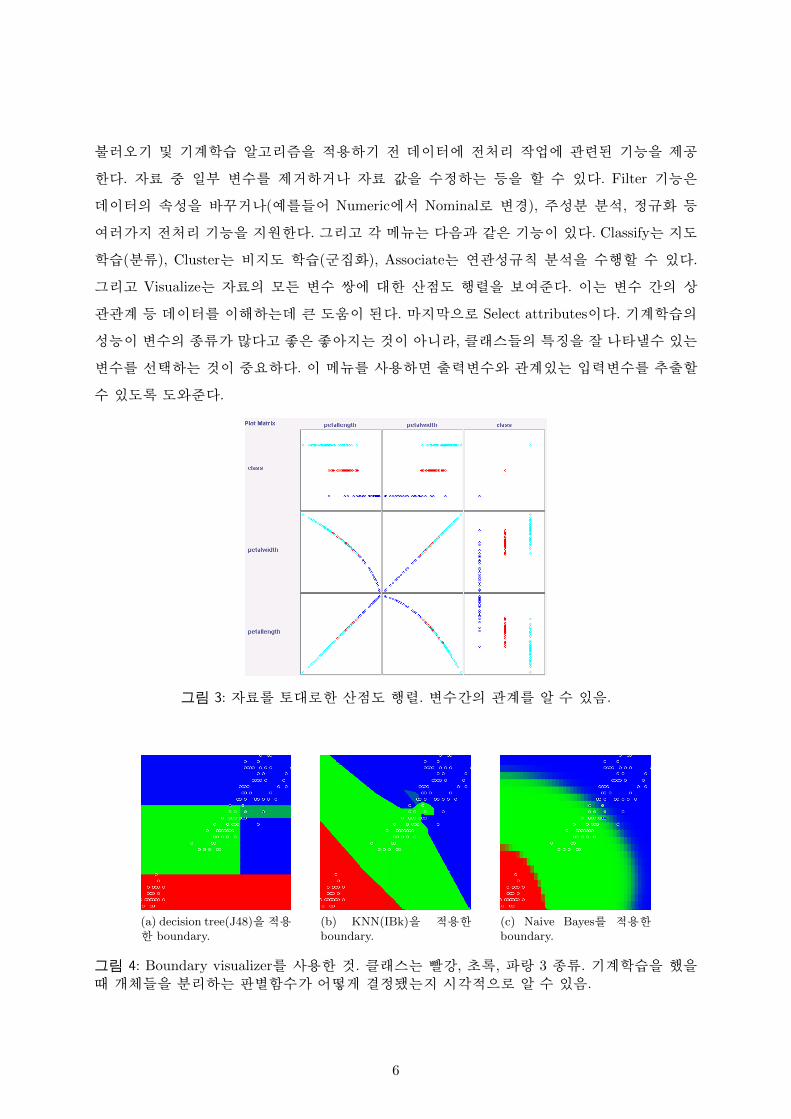
그림 3: 자료롤 토대로한 산점도 행렬. 변수간의 관계를 알 수 있음.
(a) decision tree(J48)을적용한 boundary.
(b) KNN(IBk)을 적용한
boundary.(c) Naive Bayes를 적용한
boundary.
그림 4: Boundary visualizer를 사용한 것. 클래스는 빨강, 초록, 파랑 3 종류. 기계학습을 했을때 개체들을 분리하는 판별함수가 어떻게 결정됐는지 시각적으로 알 수 있음.
6

3.2 ARFF Data Format
Weka는 데이터의 입력 포맷으로 ARFF(Attribute-Relation File Format)을 사용한다. 이 포
맷은 Relation 이름, 변수 이름 및 속성, 자료값이 포함되어 있다. 그림 5는 ARFF 파일의
예시이다. ARFF는 크게 헤더와 내용으로 구성된다. 헤더의 @relation <relation-name>에서
<relation-name>은데이터셋의이름을명시한다. @attribute <attribute-name> <datatype>에
서<attribute-name>은속성이름을의미하는문자열이오며<datatype>은 numeric, <nominal-
specification>, string, date[<date-format>]중 하나가 올 수 있다. 그리고 ARFF의 내용에는
@data 아래로 CSV와 같이 콤마(,)로 구분된 데이터 값들이 나열되어 있다. 기본적으로 속성의
마지막변수가클래스가된다. Weka에서는 CSV뿐만아니라데이터베이스를직접접근하여자
료를가져올수있다. CSV파일의경우불러올수는있으나변수에대해속성(numeric, nominal,
date, string)이 정해져있지 않아서 추가적으로 속성을 지정해주어야 한다. 따라서 CSV 형태로
자료를 가지고 있는 경우 ARFF로 변환하여 변수의 속성을 저장해둔 후 Weka에서 불러오는
것이 좋다.
(a) ARFF 헤더 (b) ARFF 내용
그림 5: 메타데이터를 토대로 정적인 설계 제한 조건을 검사
3.3 알고리즘 적용 및 결과 분석
적용 가능한 알고리즘의 종류는 자료의 변수들과 예측하고자 하는 반응변수의 속성 유형에
따라 제한된다. 독립변수와 반응변수의 종류에 따라 적용할 수 있는 알고리즘의 종류는 표 1
과 같다. 알고리즘을 선택하고 성능을 평가할 때 지도학습의 경우 성능 평가 지표로써 표 2의
분류행렬(confusion matrix)을 이용하여 성능을 평가할 수 있다. 분류행렬은 학습 자료를 통해
만들어진모형에테스트자료를넣었을때분류가잘되는지정량적으로평가할수있다.기본으
표 1: 데이터 유형에 따른 데이터마이닝 기법의 분류
연속형 반응변수 범주형 반응변수 반응변수가 없는 경우
연속형 독립변수
선형 회귀분석
신경망모형
k-최근접이웃기법
로지스틱 회귀분석
판별분석
k-최근접이웃기법
주성분 분석
군집분석
범주형 독립변수
선형 회귀분석
신경망모형
회귀나무
신경망모형
분류나무
로지스틱 회귀분석
단순 베이즈 분류모형
연관성규칙
7

로 선택되는 ZeroR은 기본 규칙(Naive Rule)로써 한 클래스만을 선택하는 규칙이다. 기계학습
알고리즘을 적용했을 때 성능의 최소 기준으로 기본 규칙을 삼을 수 있다. 성능을 평가할 때는
분석 목적에 따라 성능의 평가에 사용할 지표가 다를 수 있따. 표 3는 교사학습에서 평가에 사
용하는 지표들이다. 주로 1개의 단독값보다 pairwise criteria의 precision, recall또는 sensitivity,
specificity가주로사용된다 [3]. Combined criteria는 1개의값으로두개의성능을비교하고자할
때사용되는데 precision, recall의조화평균을 F-measure라고한다.종종 sensitivity와 specificity
의 조화평균도 평가에 사용된다 [4].
표 2: 분류 행렬표. 분류 행렬표를 통해 교사학습의 성능을 평가할 수 있음.
예측 클래스
Positive Negative
실제 클래스Positive True positive False negativeNegative False positive True negative
표 3: 지도학습 평가 지표. Pairwise criteria가 주로 사용되며 1개의 지표로 평가하고자 할 때는Combined criteria를 사용할 수 있음.
true positive(TP) - positve라고 예측한 것이 참인 경우
true negative(TN) - negative라고 예측한 것이 참인 경우
false positive(FP) - positive라고 예측한 것이 거짓인 경우
false negative(FN) - negative라고 예측한 것이 거짓인 경우
TPR(true positive rate, sensitivity, recall) = TP/P = TP/(TP+FN)
SPC(specificity) = TN/N = TN/(FP+TN)
PPV(precision) = TP/(TP+FN)
ACC(accuracy) = (TP+TN)/(P+N)
Pairwise criteria
* precision, recall
* sensitivity, specificity
Combined criteria
* F-Measure = (2*precision*recall)/(precision+recall)
4 결론
최근 대용량 데이터 처리 기술이 발전함에 따라 데이터베이스에 저장된 데이터를 바탕으로
앞으로 정보를 획득하고자 하는 시도는 폭발적으로 증가하고 있다. 본 보고서에서는 데이터
마이닝에 대한 기초적인 내용을 소개하고, 데이터마이닝 도구인 Weka를 통해 교사 학습을
수행하는 방법을 알아보았다. 데이터마이닝에서는 자료의 전처리나 알고리즘에 대한 이해가
8

중요하다. 향후에는 분석 방법에 대해서 좀 더 자세히 소개할 예정이다.
References
[1] G. Shmueli, N. R. Patel, and P. C. Bruce, 비즈니스 인텔리전스를 위한 데이터마이닝. 사
이텍미디어, 2009.
[2] M. Hall, E. Frank, G. Holmes, and B. Pfahringer, “The weka data mining software: an
update,” ACM SIGKDD, vol. 11, no. 1, pp. 10–18, 2009.
[3] D. Francois, “Binary classification performances measure cheat sheet.”
[4] bowen Song, G. Zhang, W. Zhu, and Z. Liang, “Roc operating point selection for classification
of imbalanced data with application to computer-aided polyp detection in ct colonography,”
International journal of computer assisted radiology and surgery, vol. 9, no. 1, pp. 79–89,
2014.
9


![Apache2 Ubuntu Default Page: It worksqwone.com/~jason/trg/papers/yedidia-belief-01.pdfÀ ÁY¹ÃDÄÆÅyÄÂÈÇ Ä Â É ÊyÅ yË·Ì Á Ç ¸ÍÏÎÑÐ É¸Ä Í Ò ] T¯Z f f>X0]NSY]e](https://img.dokumen.tips/doc/110x75/5f395863fd21e911b77e5c03/apache2-ubuntu-default-page-it-jasontrgpapersyedidia-belief-01pdf-yfdy.jpg)


























