Embed Size (px)
Citation preview

Weaving Your Own Semantic Web
Dennis QuanDecember 4, 2002

“Information at your fingertips” Where are we now? How did we get here? Where are we headed?
Who has done this before? Why might this not work? What can we do about it? What will “the user” think?

The status quo The Web is a great place to find all
sorts of information: Weather forecasts News reports Stock charts Phone numbers and addresses TV program schedules and reviews Airline reservations … and much, much more

The origins of the Web Physicist turned hacker Tim Berners-Lee
developed method for linking together network-accessible documents
HTML: easy to read, easy to write, easy to share
HTTP: universal transport for getting at shared documents via Web browsers
Apache, Perl, et al.: easy to hack together scripts for producing Web content en masse
Mosaic, Internet Explorer, Mozilla, etc.

The future of the Web Today’s Web is great, but…
Users: give them an inch; they want a mile Vicious (virtuous?) cycle of automation
Right now most Web content is human-readable “04 05 2002”: part number? birthdate? price? Possibilities for automation are limited
Screen scraping: pre-interpreting pieces of Web content for use by scripts
Semantic Web: make Web content machine-readable in the first place

Oh, the possibilities! Once content is directly interpretable, barriers to
creative use of such content will be lowered Appointment scheduling Price comparison and negotiation Ontology-based search
Examples: Find me the cheapest French-speaking city to fly to in
March and a hotel others found to be “romantic”. Schedule the meetings that must occur today for the
afternoon and postpone the rest until the next 3 days. Where can I buy A Tale of Two Cities for the
cheapest? I’m willing to buy used if the cost savings is at least 50%.

Lingua franca
Resource Description Framework (RDF): “circle and arrow diagram” method for encoding knowledge
A Tale of Two Cities
Booktype
$10.95
price
Charles Dickensauthor

Agents
Programs that do things on behalf of humans
A Tale of Two Cities
$10.95price
$4.95
used price
Acme Books
says
Honest Joe’s Used Books
says
condition Good

Déjà vu?
Flexible data representation Knowledge representations, ontologies
and descriptive logic systems? Relational databases?
Number crunching and deduction Internet price search engines? Perl scripts? Multi-agent environments?

Problem #1: information Information for the Semantic Web must
come from somewhere CyC approach
Spend $25m and 20 years time Results in highly consistent corpus Problem: requires $25m and 20 years time
Distributed approach Piece by piece incrementally Each user contributes Problem: requires tools for inputting information

Problem #2: “Grandma” Grandma doesn’t know
about SLAD-DOS: Scripting Logic Agent interaction Data types Distributed systems Ontologies Schemas
Technology irrelevant if user interface cannot expose it

Problem #3: the web monkey
Web monkeys like: Simple, easy-to-understand languages
(e.g., JavaScript, Perl, HTML) Granular, hands-on, reusable
components (e.g., CGI scripts, Web pages, Java applets)
Ability to cycle through edit-run-debug quickly (e.g., with a Web browser)

The generation gapGrandma wants to: Tell her friends how
great the toaster she bought is
Find a romantic comedy on TV tonight
Get a doctor’s appointment when Days of Our Lives isn’t on
See latest pictures of grandchildren
Web monkey will need: Distributed, P2P
database with flexible schema
Sophisticated Boolean query language
Online representation of personal calendars and agent negotiation protocol
Content management system

RDF to the rescue Distributed: easily shared
between systems and highly granular
Flexible: doesn’t restrict how people think about their information
Plus all the benefits of 50 years of AI and database research
RDF

Web monkeys like toys Standard RDF databases RDF-enabled scripting
language Distributed agent
communication layer Transports RDF over SOAP, POP3,
SMTP, etc. Drag and drop ontology
designers
… kind of like httpd, perl, and mysql
DB + scripting
RDF

Toys that let users play If users don’t tell their
computers things, agents will have nothing to work with PIM that automagically records
calendar, address book, e-mail, to-do list, etc. as RDF
Editors that can take RDF ontologies written by developers and intelligently allow input from users
… kind of like Web browsers and e-mail clients
UI components
DB + scripting
RDF

Making use of the toys Users must be able to ask their
computers for their information Natural language schemas for
mapping onto RDF representations Natural language query engines
(e.g. START) Agents must be made easily
accessible Users maintain their own agents
much like they do their bookmark collections
… kind of like Google and Priceline.com
Agents + search
UI components
DB + scripting
RDF

Sharing your toys Not all users will understand how to model
data Let those who can share their ontologies Make the UI capable of finding these ontologies
automatically Must also model “hints” or “templates” that give
users suggested defaults UI components and agents must also be
sharable “Onto-Google”?

Client? Server?What’s the difference?
Both users and developers create content
Both clients and servers store information in RDF
Agents can reside on users’ machines (personal agents) or can be distributed across the Internet (like Web Services)
Truly peer-to-peer
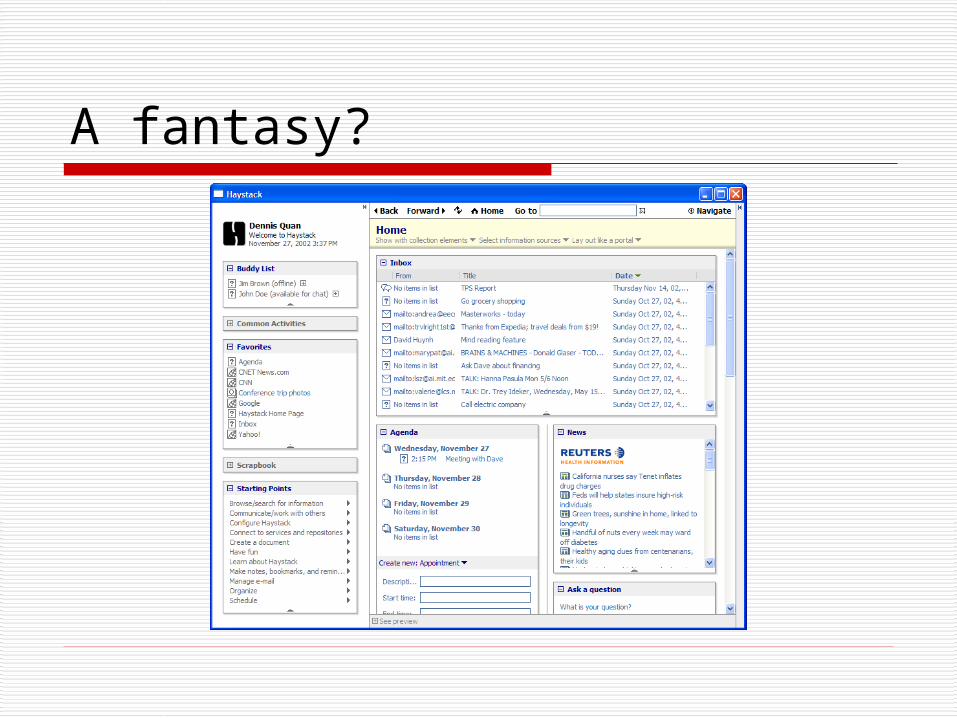
A fantasy?

Exercises for the reader My home page
(http://www.ai.mit.edu/people/dquan/) Haystack
(http://haystack.lcs.mit.edu/) Semantic Web
(http://www.w3.org/2001/sw/) RDF
(http://www.w3.org/RDF/)
Thank you for your attention
















![Introduction to the Semantic Webolmedilla/events/2007/TENC-WS/20070124_TENC... · 2012. 7. 7. · Weaving Meaning : An Overview of The Semantic Web. 2003 ] Olmedilla, Siberski TENCompetence](https://img.dokumen.tips/doc/110x75/5fd27e03e04168263302d85e/introduction-to-the-semantic-web-olmedillaevents2007tenc-ws20070124tenc.jpg)












