Embed Size (px)
Citation preview

Visual Description of Skin Lesions
Matteo ZanottoT
HE
U N I V E RS
IT
Y
OF
ED I N B U
RG
H
Master of Science
Artificial Intelligence
School of Informatics
University of Edinburgh
2010

Abstract
The work of this dissertation was aimed at getting a better understanding about the
way people evaluate visual similarity of skin lesions. Experiments testing the evalua-
tion performance achieved following the ABCD rule were run at first. Results showed
a substantial variability in the obtained evaluations which puts the usefulness of this
qualitative guideline under questioning. According to additional analysis, the use of
the ABCD rule in the development of automatic classifiers can be arguably discour-
aged. Experiments purely based on visual similarity, on the other hand, showed the
emergence of homogeneous visual classes of Basal Cell Carcinomas. These classes
delineate some visual criteria possibly followed by the observers during the assess-
ment. A system is developed to learn these criteria from the experimental data and
promising results are reported despite the limited availability of training and testing
data.
i

Acknowledgements
First of all I want to thank my supervisor, Dr. Lucia Ballerini, for her friendly help and
constant guidance. A warm thank you goes to Prof. Fisher for the numerous sugges-
tions he gave throughout the project. The long discussions and the precious comments
provided by Dr. Aldridge and Prof. Rees from the Department of Dermatology were
extremely helpful and I want to thank them for sharing their non-informatics point of
view on several topics.
Finally, I want to thank my family for their constant support, my friends back at home
who took part in rather disgusting surveys to grant me some data to work on, and those
here in Edinburgh with whom I spent long hours in the lab over the last 12 months.
ii

Declaration
I declare that this thesis was composed by myself, that the work contained herein is
my own except where explicitly stated otherwise in the text, and that this work has not
been submitted for any other degree or professional qualification except as specified.
(Matteo Zanotto)
iii

Try Again. Fail Again. Fail Better.S. Beckett
iv

Contents
1 Introduction 11.1 Challenges of Skin Lesion Assessment . . . . . . . . . . . 21.2 Aims . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Novelty . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.4 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Background 62.1 Introduction to Skin Lesions . . . . . . . . . . . . . . . . 6
2.1.1 Types of Skin Lesions . . . . . . . . . . . . . . . 62.1.2 The ABCD Rule . . . . . . . . . . . . . . . . . . 8
2.2 Literature Review . . . . . . . . . . . . . . . . . . . . . . 9
3 User Performance with ABCD rule 133.1 Experimental Set-up . . . . . . . . . . . . . . . . . . . . 143.2 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2.1 Impact of Visual Anchors . . . . . . . . . . . . . 183.2.2 Correlation of Different Properties . . . . . . . . . 24
3.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4 Visual Similarity of Skin Lesions 314.1 Data Collection . . . . . . . . . . . . . . . . . . . . . . . 324.2 Definition of Visual Classes . . . . . . . . . . . . . . . . . 36
4.2.1 Multi-Dimensional Scaling . . . . . . . . . . . . . 374.2.2 Spectral Clustering . . . . . . . . . . . . . . . . . 42
4.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5 Automatic Classification System 525.1 Structure of the System . . . . . . . . . . . . . . . . . . . 52
5.1.1 Feature Extraction Stage . . . . . . . . . . . . . . 545.1.2 Classification Stage . . . . . . . . . . . . . . . . . 57
5.2 Experiments and Evaluation . . . . . . . . . . . . . . . . 585.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6 Conclusions 62
Bibliography 64
v

List of Figures
2.1 Pictures of six classes of skin lesions. . . . . . . . . . . . 72.2 Pictures of three different Basal Cell Carcinomas. . . . . . 8
3.1 Web interface used for collecting data during the first ex-periment. . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 Diagram of main database tables for experiment 1. . . . . 163.3 Example of derived anchor points . . . . . . . . . . . . . 173.4 Impact of visual anchors on lesion D414b . . . . . . . . . 193.5 Matrix of scatter-plots showing the correlation patterns be-
tween the different evaluated properties. . . . . . . . . . . 263.6 Results of correlation analysis for each of the four clinical
classes of lesions. . . . . . . . . . . . . . . . . . . . . . . 27
4.1 Basal Cell Carcinomas showing substantial differences inshape. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.2 Web interface developed to collect similarity assessmentdata. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.3 Diagram of database tables for experiment 2. . . . . . . . 354.4 Results of Multi-Dimensional Scaling with a 1D output
layout . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404.5 Results of Multi-Dimensional Scaling with a 2D output
layout. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414.6 Hierarchical structure of the derived clusters. . . . . . . . 444.7 Results of Spectral Clustering on Sample 1 . . . . . . . . 464.8 Results of Spectral Clustering on Sample 2 . . . . . . . . 474.9 Results of Spectral Clustering on the Complete Dataset . . 484.10 Results of Spectral Clustering mapped on MDS plot . . . . 49
5.1 Features obtained through topographic Independent Com-ponent Analysis. . . . . . . . . . . . . . . . . . . . . . . 58
5.2 Wrong assignments to the flat BCC class (upper row) andlow-confidence correct assignments to the non-flat BCCclass (lower row). . . . . . . . . . . . . . . . . . . . . . . 60
vi

List of Tables
3.1 Brown–Forsythe tests on changes in the variance after in-cluding visual anchors . . . . . . . . . . . . . . . . . . . 20
3.2 Statistics of the scores showing a statistically significantchange after the inclusion of the visual anchors . . . . . . 22
3.3 Mann–Whitney tests on changes of the average varianceafter including visual anchors . . . . . . . . . . . . . . . . 23
5.1 Results obtained on the image test set. True Class rep-resents the visual class the lesion belongs to, P(flat) andP(non-flat) the probabilities assigned to the two classes bythe Gaussian process . . . . . . . . . . . . . . . . . . . . 59
vii

Chapter 1
Introduction
The interest in the field of Computer-Aided Diagnosis (CAD) has been growing rapidly
over the last few years and CAD tools are expected to get higher importance and wider
application in the future. The reasons behind this quick increase in the interest shown
by the medical community is linked to the potentials automatic classification tech-
niques could have on the analysis of medical images. While object recognition tech-
nology is not yet mature to completely delegate the diagnostic process to a computer-
based system, in a few areas CAD tools are already developed enough to be of practical
use. In particular, they can have a very important role in the education of new clini-
cians, who can train having a “second opinion” provided by the system, or as a support
to non-specialised clinicians in their decision to direct patients to a specialist. One of
the disciplines in which CAD systems are increasingly popular is dermatology. There
are several reasons behind this, including the high increment of skin cancer cases re-
ported by several studies. The most interesting peculiarity of dermatology, though, is
that images of the skin can be acquired with standard equipment, such as digital cam-
eras, even without the presence of a doctor. While other kind of medical images, such
as MRI scans, can only be obtained within a hospital where specialised personnel is
available for diagnosis, skin images can be obtained easily by laypeople even without
supervision. This unique characteristic enables CAD systems to be used in the field of
dermatology even as self-screening tools, especially in those rural areas where access
to specialists is still not guaranteed. Moreover, they can be used by general practition-
ers, without the need for particular investments, to better decide whether to direct the
patient to a dermatologist or not.
Based on these observations, several papers have been recently published presenting
automatic systems for skin lesion classification. Most of the work done up to now
1

Chapter 1. Introduction 2
(see section 2.2 for a review or the relevant literature) concentrated on the detection
of melanoma which is the most dangerous but even the most rare lesion. Conversely,
very few attention has been paid to other kinds of skin lesions which, despite gener-
ally being non-life-threatening, still require treatment before they cause complications.
While this specialisation on melanoma is generally overlooked, the ability to classify
all the potentially dangerous types of lesion is paramount to obtain systems which can
have a real impact on healthcare.
In order to bridge this gap, a lot of research effort has been dedicated in this University
to the classification of non-melanoma skin lesions and this dissertation is meant to give
a contribution, exploring some new research directions.
1.1 Challenges of Skin Lesion Assessment
Even though skin lesion classification might seem very similar to any other object
recognition task at a first analysis, sharp differences emerge when closer attention is
paid to its specific characteristics. At the highest level, these differences can be divided
in two major classes. The first class regards specificities which make the assessment
difficult for humans, while the second class focuses on those aspects which challenge
automatic classifiers. Obviously the boundary between the two classes is not always
well defined, but this subdivision provides a good general approximation.
The main problems faced by humans as they assess skin lesions are due to the guide-
lines currently in use in the dermatological community. Regardless being addressed
to clinicians or laypeople, these guidelines generally rely upon descriptions based on
concepts which are assumed to be universally valid as a sort of implicit standard. Some
examples would be concepts like light vs. dark, regular vs. irregular, symmetric vs.
asymmetric. Even though their general meaning is clear to anyone, evaluating the de-
gree of one of them, say asymmetry, can give rather subjective results.
A second major issue for people lays in the fact that, because of the structure of the
visual system, our perception is context dependent. The same shade of grey, for ex-
ample, is perceived lighter or darker according to the colour pattern of its surrounding
area. The same phenomenon happens for skin lesions, and has a lot of implications on
the assessment phase.
Even limiting the attention to these two aspects without getting into more subtle details,
we observe that evaluation can depend not only on the subjectivity of each individual,
but even on the context which, in the case of skin lesions, consists in the aspect of the

Chapter 1. Introduction 3
surrounding normal skin. This situation can be seen as a problem in finding a standard
representation of specific concepts, a description which regardless any subjectivity and
variation of context still uniquely identifies the relevant details.
While considering automatic classification, on the other hand, the opposite problem
is faced as it is still difficult to equip computer systems with enough abstraction and
generalisation capabilities to avoid pitfalls. Coupling this with the extreme variability
in colour and texture that normal skin can exhibit, it is not surprising that automatic
systems often provide a segmentation of the image in region of interest (lesion) and
background (surrounding skin) which is far from being ideal.
Another limitation of computer systems is the difficulty in dealing with high-level fea-
tures which are easily managed by humans. The presence of a blood vessels on a patch
of skin, for example, can be effortlessly recognised by an observer, but due to the vari-
ability in its configuration and the presence of “clutter” (e.g. visible skin pattern or
hair) it is not always easily detected by computer vision systems.
Both of these classes of difficulties must be considered when designing an automatic
system for skin lesion classification and each of them had been investigated in the work
of this dissertation.
1.2 Aims
The two main hypotheses underlying the project are that qualitative guidelines like the
ABCD rule (see section 2.1.2 for details) do not reflect properly the knowledge used
by dermatologists in the diagnostic process and that a new approach to classification
can be derived from results obtained in experiments based on visual similarity.
Empirical observations show that people with no medical training and no specific der-
matological knowledge are capable of grouping images of skin lesions in coherent
classes and subclasses. This evidence suggests that some intrinsic visual characteris-
tics can act as guidance in the classification task. If such features exist, image analysis
and machine learning techniques can be used in an attempt to extract them from the
visual classes created by humans, and ultimately to develop an automatic classification
system relying upon them.
As mentioned before, implementing a system to automatically classify skin lesions is
not trivial and many specificities regarding their appearance need to be taken into con-
sideration in order to succeed. The aim of this thesis is investigating more accurately
than it has been done before about the two classes of challenges introduced in the previ-

Chapter 1. Introduction 4
ous section. In particular, the first part of the dissertation will concentrate on providing
a better understanding about how well people can follow qualitative guidelines like
the ABCD rule. This will be done analysing the data of an experiment simulating the
self-screening procedure people are encouraged to perform on a regular basis to detect
melanomas in early stages. Shedding light into this is expected to give a better under-
standing on whether automatic classifiers should be based on such guidelines or not.
The second part, on the other hand, will focus more on how to design systems capable
of dealing effectively with the second class of challenges, those linked to the limited
abstraction capability of automatic classifiers. To do so, an experiment has been set up
to obtain groups of skin-lesion images judged by humans to be visually similar. The
resulting data have then be used in an attempt to develop an automatic system capable
of replicating these visual classes. The aim of this second stage was testing new design
strategies which could be effective in order to overcome the limitations often shown
by classifiers proposed for application in dermatology.
1.3 Novelty
Several aspects of this dissertation are dissimilar, a least to some degree, to the work
which has been previously proposed in the field. Performance of people’s ability to
assess skin lesions using the ABCD rule has been evaluated before, but in a different
way and never with the perspective of testing whether this rule could prove useful in
the development of automated classifiers. Secondly, to the knowledge of the author,
the whole process used to design the proposed system starting from humans’ percep-
tion and trying to replicate their ability to evaluate visual similarity has never been
used before. Finally no work regarding visually recognising sub-classes of Basal Cell
Carcinoma has been previously proposed.
1.4 Overview
The dissertation is organised as follows. Chapter 2 gives an introduction to the der-
matological concepts needed to understand the following chapters. Additionally, it
provides a review of the literature related to the classification systems specifically de-
signed to work on skin-lesion images. Chapter 3 presents the outcomes of the exper-
iment performed to evaluate people’s ability to use the ABCD rule. The part more
closely related to the development of the automatic classifier starts with Chapter 4,

Chapter 1. Introduction 5
presenting both the experiment used to gather data regarding visual similarity and the
obtained visual classes, and continues with Chapter 5 where a detailed description of
the developed system is given along with a discussion regarding its performance. Fi-
nally Chapter 6 draws conclusions and proposes future directions of research.

Chapter 2
Background
In this chapter an overview of the different topics needed to understand the rest of the
dissertation will be provided. In particular, a quick introduction to skin lesions is given
in section 2.1.1, while the ABCD rule for melanoma detection is presented in section
2.1.2. A detailed coverage of the topic is beyond the scope of this work and only the
facts directly useful to understand the framework in which the research was performed
will be reported. A literature review covering the work already done in the field of
automatic classification of skin lesions is presented in section 2.2.
2.1 Introduction to Skin Lesions
This section summarises briefly the dermatological concepts which will be extensively
used in the following chapters. It includes an overview of the different types of skin
lesions and an introduction to the ABCD rule used for melanoma screening.
2.1.1 Types of Skin Lesions
The term skin lesion is fairly general and is used to refer to a variety of phenomena.
Roughly speaking, a skin lesion is any kind of skin patch which presents different
characteristics when compared to its surrounding area. Examples of some types of
skin lesions can be found in Figure 2.1 showing six classes of major interest:
• Seborrhoeic Keratosis (SK)
• Melanocytic Nevus
• Actinic Keratosis (AK)
• Basal Cell Carcinoma (BCC)
6

Chapter 2. Background 7
(a) Seborrhoeic Keratosis (b) Melanocytic Nevus (c) Actinic Keratosis
(d) Basal Cell Carcinoma (e) Squamous Cell Carci-
noma
(f) Melanoma
Figure 2.1: Pictures of six classes of skin lesions.
• Squamous Cell Carcinoma (SCC)
• Melanoma
SKs and Melanocytic Nevi are benign forms of skin lesions, AKs are considered a
pre-malignant condition, while BCCs, SCCs and Melanomas are malignant forms of
skin lesions. Among the last three, Melanoma is the most dangerous causing the ma-
jority of skin-disease related deaths despite being one of the less common cutaneous
cancers. BCCs and SCCs are less dangerous than Melanoma, but are still considered
malignant lesions. They rarely metastasise, especially BCCs, but they both need treat-
ment because of their tendency to expand to nearby tissues. Despite growing slower
than SCCs, BCCs are highly destructive and, if not treated while in their early stages,
can cause significant damages possibly extending beyond the skin of the patient.
An important peculiarity of some of these classes is the extreme variability in appear-
ance they can present. As an example, Figure 2.2 shows different images of Basal Cell
Carcinomas.
As can be seen in the pictures, see Figure 2.1 and Figure 2.2, skin lesions present some
peculiar characteristics. At a first analysis it appears clear that the difference between
the types cannot simply be described by a single attribute. In other words it is not

Chapter 2. Background 8
(a) (b) (c)
Figure 2.2: Pictures of three different Basal Cell Carcinomas.
possible to visually discriminate between classes purely on the basis of one property
such as colour or shape. This is due to several reasons including the aforementioned
variability shown within each class, to the specificity of each individual’s skin and
ultimately to the difficulty faced when trying to define the border between the lesion
and the surrounding normal skin, especially when dealing with non-pigmented (such
as most of the BCCs) or pale skin lesions.
This lack of a single distinctive marker led, over the years, to the formulation of several
multi-criteria guidelines intended to be used both by clinicians during the diagnostic
process and by laypeople for self-screening. Two important examples are the ABCD
rule [23] and the 7-point check-list [7]. Only the ABCD rule will be briefly presented
as it is relevant for this work, the interested reader is pointed to the cited paper for
presentation of the 7-point check-list.
2.1.2 The ABCD Rule
The ABCD rule was proposed in 1985 by Friedman et al. [23] as a guideline both for
clinicians and laypeople to visually recognise potential melanomas in the early stages
of development. Specifically, the rule suggests to evaluate 4 properties of the lesion to
verify whether it is potentially dangerous:
• Asymmetry as melanomas tend to be asymmetric both in shape and in terms of
colour distribution
• Border irregularity as melanomas have less defined and more jagged borders
than benign lesions
• Colour variegation as melanomas tend to have a non-uniform colour distribution
• Diameter as melanomas tend to be wider than 6 mm

Chapter 2. Background 9
Major stress is put on the fact that the sooner melanomas are identified, the higher
the probability of effective surgical removal, which translates in a very high survival
rate. For this reasons, people are encouraged to actively examine their skin following
the ABCD rule in search for suspicious signs which might suggest the development of
melanoma.
Over the years studies have been conducted on the effectiveness of the ABCD rule,
such as Brandstrom et al. [13], Gunasti et al. [24], Meyer et al. [37], Reetz Muller
et al. [44]. While some papers [13, 44] claim that the use of the ABCD rule had a
positive impact on the answers given by the participants, others [24, 37] point out a
substantial variability in the way different people assess some of the criteria. Even the
results obtained by Laskaris in his Master’s thesis [27] support the claim suggesting
that people evaluate the same skin lesions in different ways.
Given the importance of a correct evaluation of the four key properties in order to
obtain successful results with the ABCD rule, the findings presented in [24, 27, 37]
highlight the necessity for a more extensive and closer study of people’s assessment
performance. An attempt to gain a better understanding of such an evaluation variabil-
ity was part in this dissertation and will be presented in chapter 3.
2.2 Literature Review
Over the past ten years many research papers applying machine learning and com-
puter vision techniques to dermatology have been proposed. This tendency reflects the
growing importance of Computer-Aided Diagnosis especially in those disciplines, like
dermatology, where images of the patients can be easily obtained, often with readily
available equipment.
From the methodological point of view a distinction must be done on the type of im-
ages that are used in the proposed systems. Two main categories can be found: papers
working on normal camera photographs and papers using dermatoscopic images. Der-
matoscopic images are obtained through a dermatoscope which consists in a magnifi-
cation device (typically 10x) equipped with a source of light and engineered to avoid
skin specularities generally through the use of a polariser. Despite the difference in
the acquisition phase, which introduces a difference in the level of available detail, the
image-analysis algorithms applied in the two cases are equivalent and hence the tech-
niques will be presented together without any particular distinction.
Most of the techniques proposed in literature focus their attention on the recognition

Chapter 2. Background 10
of melanoma (see [33, 42] for reviews), while only a few attempts to classify other
kinds of lesion have been made. Due to the considerable difference between the work
done in this dissertation and in previous research, it will be impossible to evaluate the
obtained results through comparison with benchmarks. For this reason, this literature
review is mainly aimed at giving a flavour for which techniques have been previously
used in the field, while it is not meant to report data about their performance. Another
reason for avoiding focusing on the claimed performance is that, given the substantial
lack of standardised image-sets (like Caltech-101 [5] or similar for object recognition
applications), each technique has been tested on a different image collection, making
any fair comparison impossible.
The rest of the section will be dedicated to outlining some of the most relevant papers
found in research related to computer imaging applied to skin-lesion assessment.
It is interesting to note how most of the proposed papers base their classification sys-
tems on features directly derived from the ABCD rule either in its form for normal
[23] or for dermatoscopic images [40]. While on one hand this is supposed to be a
convenient way to incorporate knowledge into the system, on the other hand it con-
strains the classification to be performed in a domain where even humans tend to have
evaluation difficulties (see chapter 3). Moreover, as LeCun pointed out in one of his
talks at UCLA during the 2005 IPAM Graduate Summer School [1], fields like natural
language processing have benefited from a learning phase not conditioned by human-
crafted added knowledge, suggesting that the same approach might prove beneficial
even in computer vision. Despite this observation, papers directly related to the ABCD
rule are still the vast majority and will be presented first.
Messadi et al. [36] derived 6 features evaluating the ABCD criteria and used them to
perform classification with an artificial neural network. In the proposed paper the seg-
mentation of the lesion is automatic and edge detection is performed on the basis of the
projection of the image in the space spanned by its first principal component obtained
through Principal Component Analysis (PCA). She et al. [50] combined together 6
features derived from the ABCD rule and 2 describing the texture of the skin pattern
obtaining a 8-dimensional vector. This descriptor is then projected in a 2-dimensional,
space through PCA reducing the dimensionality of the problem. Classification is per-
formed with a linear classifier in the obtained 2D space. The authors claim success-
ful results, but no record is given about how they addressed the risk of generating
non-linearly separable classes when operating dimensionality reduction through PCA.
Celebi et al. [17] proposed an approach where multiple features linked to the ABCD

Chapter 2. Background 11
rule are computed along with some additional texture descriptors based on the grey
level co-occurrence matrix (GLCM) [20]. All the features are pooled together and an
automatic selection of the most relevant ones is operated following several different
filtering techniques. The set of the selected features is then used to perform classifica-
tion with a Support Vector Machine (SVM). Remaining in the domain of the ABCD
rule, systems operating classification on the basis of a subset of the 4 original lesion
properties can be found. Clawson et al. [21] proposed a recognition system based only
on border irregularity as described by a harmonic wavelet transform. Seven descriptors
are obtained at different resolution levels in order to capture the various aspects of bor-
der irregularity. These features are then used both in a system for modelling experts’
perception of irregularity (using irregularity evaluations provided by dermatologists)
and for melanoma/benign lesion classification through different approaches such as
Boosting and Artificial Neural Networks. Again focusing on a subset of the ABCD
properties, more methodological papers have been presented dealing simply with find-
ing good descriptive features without any specific implementation of the classification
stage. As an example, Li et al. [31] measured asymmetry (only for shape, colour dis-
tribution was not considered) and border irregularity with a multi-scaled local fractal
algorithm, claiming an advantage over benchmark features in terms of discrimination
power. More generally Celebi et al. [16] reviewed a variety of approaches for auto-
matic border detection, a fundamental step for all the previously mentioned techniques
which heavily rely upon a good segmentation of the lesion in order to compute the
descriptors which are then used for classification. Border detection, in fact, is the fun-
damental step underlying the evaluation of any measurement used to assess asymmetry
and border irregularity, and plays an important role when determining where the de-
gree of colour uniformity must be estimated.
Reflecting the attention given in recent years to visual patterns for skin lesion classifi-
cation (e.g. [7]), automatic systems based on pattern analysis techniques have emerged
as a useful alternative to avoid relying upon the ABCD rule. As an example, Serrano
and Acha [48] proposed a method of classification based on a formulation of Markov
Random Fields extended to model the interdependence of the different colour planes.
Another example is the system presented by Tabatabaie et al. [52] using Independent
Component Analysis (ICA) and colour features for melanoma detection through the
use of a Support Vector Machine. While the use of ICA is an interesting peculiarity of
this paper, a few implementation choices present some critical aspects. The first is that
ICA is performed only on the region of the lesion, requiring a segmentation algorithm

Chapter 2. Background 12
capable of separating it from the normal skin. This process, even when performed cor-
rectly, might result in the loss of some important characteristics of the lesions if they are
located along the border. Secondly, two sets of filters are learnt and used as coding dic-
tionaries to decide whether a test image is better represented by the filter bank learnt on
melanoma images or, conversely, by the one derived by the benign lesions. While this
strategy is probably easier to deal with in the classification phase, this training method
might result in 2 sets of very similar filters with just a few of them having very high
discriminative power. Considering the computational cost of performing ICA, more-
over, the derivation of a single set of filters from a mixed collection of images might be
more appropriate. A work by Mendoza et al. [35] presents a series of scale-invariant
pattern descriptors which alleviate the problems generally caused by differences in the
size of the lesions. The 24 features consist of measurements performed on the different
regions of a black-and-white mask obtained from the original image in a way that pre-
serves the important characteristics of the lesion pattern. Classification is performed in
the feature space following the nearest-neighbour methodology. Finally, Capdehourat
et al. [15] used Adaptive Boosting applied to decision trees to classify melanocytic
skin lesions as benign or melanoma. Lesions are preprocessed to remove hairs, auto-
matically segmented and subdivided in three different regions (interior, outer border
and inner border) where properties are evaluated. A total of 57 features focusing on
colour and texture are extracted and used for classification. The authors point out that
texture analysis is done using Gabor filters without investigating the presence of par-
ticular geometric structures relevant to the 7-point check-list [7] due to the inherent
difficulties presented by the task. This limitation, found in many other systems, puts
serious constraints on how close the machine performance can get to that of humans,
especially in cases where a correct classification can only be achieved evaluating com-
plex properties of the lesion.
All the classifiers presented up to now are aimed at detecting melanoma and little work
has been produced on other kinds of skin lesions. One example is the system pro-
posed by Chaudhry et al. [18] which classifies BCCs and SCCs using features based
on wavelets.
In order to expand this area, a considerable amount of research has been done at the
University of Edinburgh (e.g. McDonagh et al. [34], Ballerini et al. [8]) to produce
better classifiers for non-melanoma skin lesion.

Chapter 3
User Performance with ABCD rule
The ABCD rule proposed by Friedman et al. [23] and supported by the American
Academy of Dermatology relies strongly on the assumption that people can effectively
describe what they see in terms that, albeit qualitative, show consistency across differ-
ent observers. This is true for all the qualitative rules currently in use in dermatology
either to support the diagnostic process or as self screening guidelines.
During experiments performed last year and reported in Laskaris’s MSc Thesis [27],
evidence emerged suggesting a substantial variability in the assessment different peo-
ple give when evaluating characteristics of the same skin-lesion image. Specifically, it
was observed that when asked to assess five properties of skin-lesion images (namely
colour, colour uniformity, asymmetry, border regularity and roughness of texture) peo-
ple gave very different evaluations for the same picture.
The first task of this dissertation regarded investigating more rigorously the consis-
tency of the qualitative judgement people provide when presented with a skin-lesion
image, in order to understand whether the variability observed was caused by the spe-
cific experimental set-up or rather by a real difference in the way each person interprets
the concepts given by the guidelines.
As in last year’s experiment people were asked to rank the qualities moving a slider
on a scale having only linguistic expressions as references (e.g. light/medium/dark for
colour), separating the effect of a subjective interpretation of the extrema and that of
the intrinsic variability in the assessment was impossible. In order to isolate the two,
a new experiment has been performed, modifying the interface with the addition of
visual anchor points to the linguistic references. A new image-set has been provided
for the experiment by the Department of Dermatology of the University of Edinburgh.
While nearly half of the images were the same of those used in Laskaris’s research
13

Chapter 3. User Performance with ABCD rule 14
[27], new ones have been introduced in order to get a more balanced representation
of the main diagnostic classes. Thanks to the better coverage of the types of lesions,
additional studies on the distribution of the answers could be performed.
As three of the tested characteristics (asymmetry, border regularity and colour unifor-
mity) are the first three elements of the ABCD rule introduced in section 2.1.2, this
experiment constitutes an empirical study on how such a guideline can prove useful in
the self-screening for melanomas.
In this chapter the interface used to collect the data and the experimental set-up will be
presented at first, then the obtained results will be discussed.
3.1 Experimental Set-up
In order to guarantee comparability with the answers previously obtained [27], the web
interface used for collecting data has been kept substantially unchanged from the one
used last year. The page (see Figure 3.1) is structured to present 45 skin-lesion images
to the user in a randomly selected order, requiring the assessment of the 5 previously
mentioned properties: colour, colour uniformity, asymmetry, border regularity and
roughness of texture. The evaluation is provided through the use of a set of analogue
sliders (one for each property) which can be moved left-to-right producing an asso-
ciated score in the continuous 0–10 range. The random ordering was introduced to
minimise the evaluation bias known to be an issue in perceptual-based experiments on
sequences of samples [12]. The bias is mainly due to the fact that people tend to adjust
their evaluations on the basis of what they have previously seen, often considering,
in the assessment, the evaluation given to previous samples. The effect is greater in
cases where people are presented with subjects they are not familiar with, as the aid
provided by prior knowledge is limited. While the randomisation cannot eliminate the
bias for each single observer, the effect on the final dataset, if any, should be substan-
tially smoothed out as each user is presented with a different sequence of images. The
presence of the visual anchors should also contribute to a reduction of this bias as the
user has static references to compare the images against.
Technically, the web interface consists in a set of php pages and JavaScript scripts
which record the answers of the user and store them on a PostgreSQL database. Minor
changes were necessary on the web pages, while the tables of the PostgreSQL database
have been recreated by reverse engineering starting from the php code since the origi-
nal structure was lost during last year’s server clean-up. A diagram of the main tables

Chapter 3. User Performance with ABCD rule 15
Figure 3.1: Web interface used for collecting data during the first experiment.

Chapter 3. User Performance with ABCD rule 16
Figure 3.2: Diagram of main database tables for experiment 1.
is shown in Figure 3.2. Although a better structure could have been obtained limiting
the redundancy of the stored information, tables had not been modified to allow an eas-
ier comparison of the results with those obtained last year. Considering the relatively
small amount of data stored in the database, the advantage of an optimised structure of
the tables would have anyway been very limited.
As previously mentioned, the interface (see Figure 3.1) differs from the one used last
year only because of the introduction of the visual references which can be seen at
each end of the sliders and in the middle. The design of the visual anchor points was
quite important for guaranteeing accurate experiments and, before being included in
the web-interface, they have been validated by the Department of Dermatology of the
University of Edinburgh.
The first design choice was that of using cartoon-like graphics, instead of real lesion
images, in order to help the user focus on the properties under evaluation one at a time.
The main risk of using real images would have been that of having the user evaluation
affected by properties not under scrutiny but suggesting high similarity between the
sample and one visual anchor. As reported in many studies of similarity perception
such as [38, 46], colour is often one of the most influential properties when evaluating
the likeness of different images. If real images were used as anchor points, people
might have been misled to move one slider, say the one for asymmetry, towards one of
the references only for a resemblance in colour between the image under assessment
and the visual anchor. The stylised grey-scale endpoint images are less prone to this
undesirable effect and careful attention has been paid to select images carrying as few
information as possible about the properties not directly linked to the afferent slider.
The only exceptions are the anchors for texture, where patches of real images needed to
be used as creating artificial samples satisfactorily representative of real lesions would
have been impossible.
Whenever possible the visual anchors were obtained through graphical elaboration of

Chapter 3. User Performance with ABCD rule 17
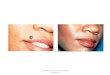
Figure 3.3: Example of original images (left) and obtained anchors (right) for asymmetry
(top) and border irregularity (bottom). Original images obtained from [4].
the examples provided by the American Academy of Dermatology on their web-page
illustrating the ABCD rule [4]. This was the case for all the references given for colour
uniformity and for the upper extrema for both asymmetry and border regularity. All
the other visual references have been obtained from real images of the DERMOFIT
database [2] after discussion with the team of dermatologists. Some examples show-
ing the original images and the obtained anchors are reported in Figure 3.3.
While volunteers were actively recruited in order to have enough answers to make a
comparison with data collected last year [27], the web-survey will be available online
even after the end of this project to allow occasional contributors to provide their an-
swers. The hope is that of obtaining a substantially wide dataset going far beyond the
42 answers currently stored, which could result in a deeper understanding of the way
laypeople assess skin-lesion images with qualitative guidelines like the ABCD rule.
The survey has been proposed to three different categories of people, ranked on their
level of education in skin-lesion assessment. The wider class consisted in people with
no medical training and the experiment could be considered as a simulation of a self-
screening procedure conducted on a variety of skin lesions. The results from this group
were expected to shed more light on how precisely people evaluate the key properties
on which self-screening guidelines, in particular the ABCD rule, rely upon. The sec-
ond group was that of dermatologists. Given the substantial prior knowledge derma-
tologists have on skin lesions, this was considered a control group to verify whether
variability in the evaluation is mainly due to lack of prior knowledge of laypeople or
rather to differences in personal perception and assessment. Finally a group of people
with some dermatology-related knowledge (medical doctors with different specialisa-
tions, nurses, medicine/nursing students, etc.) was included as an intermediate level
between the two extremes. At the time of writing, answers have been obtained from
33 laypeople, 4 dermatologists and 5 non-dermatologist medically-trained people.

Chapter 3. User Performance with ABCD rule 18
3.2 Results
The data analysis phase is divided in two stages each focusing on some specific aspects.
In the first stage the effect of the inclusion of visual anchors is tested comparing the
results of the experiment with those obtained using only the linguistic references. The
second phase, on the other hand, is related to the distribution of the collected data, with
particular attention given to the correlation observed between the answers obtained for
the different properties.
In order to correctly understand the numerical values presented in the following anal-
ysis it is useful to remember that the endpoints for each property are
colour 0 = light 10 = dark
colour uniformity 0 = uniform 10 = not uniform
asymmetry 0 = symmetric 10 = asymmetric
border regularity 0 = regular 10 = irregular
roughness of texture 0 = smooth 10 = rough
3.2.1 Impact of Visual Anchors
The first and probably most important part of the data analysis was dedicated to eval-
uate how the inclusion of visual anchors affected the answers given by the volunteers
who took part in the experiment. The reason behind this experiment was, in fact, un-
derstanding whether the extremely high variance in the scoring reported by Laskaris
[27] was due to the lack of standardisation of the extrema of the scoring scale or rather
to a more intrinsic variability in the answers linked to the subjectivity of the evaluation
process.
Only the 20 images shown both in this experiment and in previous ones were consid-
ered in this part. For each of them, statistical testing has been performed to verify if
the inclusion of the visual references resulted in a statistically significant change in
the variance of the answers. It is important to underline that only the variance of the
measurements is comparable between the two sets of data, while any observed change
in mean does not carry any useful information. This is due to the fact that, regardless
the careful selection procedure, any choice of visual anchors is somehow arbitrary, es-
pecially for the central reference. It is reasonable to assume, hence, that a different
set of visual references would result in a shift in mean, while the spread around this
mean should remain substantially stable. A notable exception are those skin-lesion

Chapter 3. User Performance with ABCD rule 19
−−−−−−
−−−−
−
−−−
−−−−
−
−
−−
−−
−−−−−−
−
−
−
Answers for Lesion D414b
scor
e
−
−
−
−−−
−
−−−
−
−
−
−
−
−
−−
−−
−
−
−
−
−
−
−
−−
−
−
−−−−
−
−
−
−−
−
−−
−
−
−
−
−
−
−−−
−
−
−−
−
−
−
−
−
−
−
−
−−
−
−
−
−−−
−−
−
−
−−
−
−
−
−
−−
−
−
−
−−
−
−−
−
−
−
−
−−
−
−−
−−
−−−
−
−
−
−
−
−
−
−
−
−
−−
−
−−
−
−−−
−
−−−−−−
+
++
++
+
+
++
+
+
+
+
+
+
+
+
+
+
+
+
++
+
+
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
−−−−−
−−−
−
−
−
−−
−−
−−
−
−−
−−−
−
−−−−
−
−
− −
−−
−−−−
−
−
−−−
−
−
−
−−−
−
−
−−−
−
−
−−
−−−
−
−−
−
−
−
−
−−
−
−
−
−
−
−
−
−−
−
−
−
−
−
−
−
−
−−
−−−−
−−−−−
−−
−
−
−
−
−
−
−−
−
−
−
−
−
−
−
−−−−
−
−−−−
−−
−
−−
−−−
−
−−−−−
−
−
−
−−
−
−
−−
−−
−−−
−−−●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
01
23
45
67
89
colou
r
col. u
nifor
mity
asym
met
ry
bord
er re
g.
roug
hnes
s
without visual anchorswith visual anchors
Figure 3.4: Impact of visual anchors on answers for lesion D414b. Marks encoding level
of skin-related knowledge: ’-’ laypeople, ’+’ medically-trained people, ’◦’ dermatologists
images whose average scoring for some of the properties is very near to the extrema
of the scale. Since the score scale is bounded to the 0–10 range, in fact, the closer the
score gets to the maximum (or minimum), the lower the variance tends to become as
an effect of the upper (or lower) bound.
In the first place each of the 20 images was considered separately and the significance
of the observed change in variance was tested. Given the specific characteristics of the
scoring system (e.g. the limited 0–10 scoring range) and of the collected answers (such
as small dimension of the samples, heavy-tails and skewness of their distribution) the
data could not be considered to be distributed according to a Gaussian. The Bartlett’s
test [9] was hence inappropriate for the analysis due to its assumption of Normality
of the data. As an alternative, the Brown–Forsythe [14] test was used. The Brown–
Forsythe test is a variation of the Levene’s [30] test in which the median is used in
place of the mean of the sample. This difference makes the test more robust in cases
where the data under analysis show a highly skewed distribution. Given the aforemen-
tioned bounded score scale, skewed distributions are often observed and hence this test

Chapter 3. User Performance with ABCD rule 20
Significant Changes Reduction IncreaseColour - - -
Colour Uniformity 5/20 3/20 2/20
Asymmetry 2/20 2/20 -
Border Regularity 10/20 10/20 -
Texture Roughness 6/20 2/20 4/20
Table 3.1: Summary of the results of the Brown–Forsythe tests (at 95%) on changes in
the variance after including the visual anchor points. Each column reports the number
of significant changes for each feature over the 20 test images.
is more appropriate. Specifically, the computed test statistic is
(N− k)(k−1)
∑ki=1 ni(zi·− z··)2
∑ki=1 ∑
Nij=1(zi j− zi·)2
∼ Fk−1,N−k
where
zi j = |yi j− yi·|
z·· =1N
k
∑i=1
ni
∑j=1
zi j
zi· =1ni
ni
∑j=1
zi j
and N is the total number of samples, k is the number of groups, ni is the number of
samples in group i, yi j is the value of the j-th sample of the i-th group (in our case
i = {1,2} representing the answers before and after the introduction of the visual an-
chors), yi· is the median of the i-th group, z·· is the mean of all zi j, zi· is the mean of zi j
for elements of group i and Fk−1,N−k represents the F distribution with k−1 and N−k
degrees of freedom.
The tests have been run at a 95% confidence level and the results are presented in
table 3.1, where the number of the significant changes in variance is reported along
with their direction (increase/reduction). While it is clear that the introduction of the
visual anchors had no effect whatsoever on the variance of the answers obtained for
the colour of the lesion, the other results cannot be interpreted without further analysis.
The reason behind this necessity lies in the fact that since the gathered scores belong to
the 0–10 real interval, they should be modelled as censored distributions, with censor-
ing taking place both on the lower and on the upper side. What happens in practice is

Chapter 3. User Performance with ABCD rule 21
that as the mean approaches one of the extreme values, let us consider the lower bound
0 as an example, the data will progressively show less variability since no value lower
than 0 is allowed. This shrinkage of the distribution is actually artificially induced by
the bounded scale and for this reason all the variances obtained for values near the
extremes are to be considered unreliable. While the statistical tests used cannot cope
effectively with it, this situation should not be overlooked as an observed reduction in
the variance might actually be the effect of a shift in the mean of the distribution to the
region of one of the extreme values. As it turns out this is often the case. Table 3.2 is
a more detailed version of table 3.1. For each statistically significant change detected
by the Brown–Forsythe tests, the values of the variance and of the median before and
after the inclusion of the visual anchors are reported. As it can be seen, most of the
cases of statistically significant changes in the variance are actually associated with a
shift of the median of the distribution (considered instead of the mean given the small
dimension of the samples) towards one of the extremes of the 0–10 range. Finding a
fixed value of the median above or below which the results of the test can be consid-
ered reliable is not easy, but if we assume the interval 2–8 to be a safe guess (having
20% of the possible 0–10 values on either side) we see that only 5 of the cases reported
in table 3.2 have the median in this interval both before and after the inclusion of the
visual anchors: one increment in variance for colour uniformity (lesion P206c), two
reductions in variance for border regularity (lesions D414b and D578a) and two in-
crements for roughness of texture (lesions P206b and P337a). Two border-line cases
are represented by the significant increment in variance for the roughness of texture of
lesions D414b and D578a despite the shift of their medians towards the upper bound.
On the basis of these considerations, it is important to interpret the data presented in
table 3.3 with extreme care. These data were obtained testing the statistical signifi-
cance of the changes in the average variance for each of the five properties with the
Mann–Whitney test. The Mann–Whitney test [22] is an extension of the Wilcoxon test
[22] to cases where the samples have different sizes. In turn, the Wilcoxon test is a
non-parametric test often used in place of the Welch’s t-test [54] when the assumption
of Gaussianity does not hold for the samples.
As pointed out before, there is no statistical means of deciding which of the cases
should be considered and which should be ignored because their median is too close
to one of the extreme values of the scoring scale. For this reason all the data have been
included in the test, but the results must be considered with the caveat that the relia-
bility of reductions or increments cannot be guaranteed and each specific case must be

Chapter 3. User Performance with ABCD rule 22
Colour Uniformity
Lesion reference σ2before σ2
after Median before Median afterD262b 2.840 0.980 2.407 0.500
D726 3.266 1.00 1.593 0.667
P206c 1.985 5.709 6.444 5.426
P337a 6.027 0.525 1.926 0.538
P446 2.365 5.277 8.074 7.500
Asymmetry
Lesion reference σ2before σ2
after Median before Median afterD262b 5.608 2.498 3.074 0.741
P337c 2.344 0.807 1.704 0.370
Border Regularity
Lesion reference σ2before σ2
after Median before Median afterD262b 5.133 2.257 2.407 0.834
D270 6.620 1.723 2.815 1.315
D414b 8.849 3.746 6.000 2.982
D578a 9.402 4.667 6.593 4.519
D726 2.984 1.890 2.037 1.019
P257 7.762 2.928 2.556 1.241
P306a 8.344 2.064 2.741 1.352
P337a 1.638 0.180 1.037 0.204
P337c 1.714 0.450 1.370 0.241
P337e 5.781 2.599 4.000 0.889
Texture Roughness
Lesion reference σ2before σ2
after Median before Median afterD262b 4.820 1.134 2.519 0.908
D414b 2.123 4.443 7.963 8.222
D578a 1.904 5.041 8.296 8.482
D726 3.972 1.718 2.630 1.037
P206b 3.737 6.558 6.926 6.834
P337a 3.798 7.601 7.667 7.074
Table 3.2: Statistics of the scores obtained before and after the introduction of the visual
anchors for the statistically significant changes detected by the Brown–Forsythe tests.

Chapter 3. User Performance with ABCD rule 23
σ2before σ2
after Ha p-valueColour 2.230 2.386 σ2
be f ore < σ2a f ter 0.3086
Colour Uniformity 3.892 4.190 σ2be f ore < σ2
a f ter 0.2317
Asymmetry 5.030 5.073 σ2be f ore < σ2
a f ter 0.3507
Border Regularity 5.600 3.417 σ2be f ore > σ2
a f ter 0.0004
Texture Roughness 4.955 5.840 σ2be f ore < σ2
a f ter 0.0542
Table 3.3: Results of the Mann–Whitney (one-sided) tests on the change of the aver-
age variance after the inclusion of the visual anchors. The alternative hypothesis is
presented in column Ha.
separately evaluated. In particular, the extremely high significance of the reduction of
the average variance for border regularity could arguably be considered a wrong esti-
mate as table 3.2 shows clearly that most of the cases of reduction in the variance of
this property are obtained when the median is near either 0 or 10. The other significant
change (nearly at 95%) is the increase in the average variance of texture roughness
observed despite the fact that 4 out of the 6 lesions for which the change is significant
had the median of the recorded score moved towards one of the extremes. Considering
this, it can probably be concluded that such result is reliable. The other three proper-
ties (colour, colour uniformity and asymmetry) do not show any significant change and
hence there is no reason to question the soundness of the associated tests.
Overall, two conclusions can be drawn. First of all the inclusion of the visual anchors
did not have any considerable impact on the variability of the answers. The only sta-
tistically significant result seems to be an increase in the variance measured for the
evaluation of the roughness of texture, while the reliability of the figures obtained for
the border regularity is debatable.
These results are quite important as they prove that the variability observed in the eval-
uation of skin lesions obtained following qualitative guidelines like the ABCD rule is
not mainly due to a subjective interpretation of the concepts on which the guideline is
based (e.g. regular/irregular, symmetric/asymmetric, ...) since the inclusion of visual
cues did not reduce the observed variance. If the variability could be really ascribed
to the intrinsic subjectivity of the assessment, as the experimental results seem to sug-
gest, the usefulness of guidelines like the ABCD rule would be under serious question.
Secondly, even after the inclusion of the visual anchors, the value of the variance is
quite high. The obtained standard deviations, in fact, range from a minimum of 1.545

Chapter 3. User Performance with ABCD rule 24
for colour to a maximum of 2.417 for roughness of texture, which are quite high when
considering that the scoring values range between 0 and 10. This substantial lack of
agreement about the evaluated concepts, makes learning useful rules from the gathered
data virtually impossible for any machine learning technique.
The analysis of the difference between the answers given by people with different level
of skin-related knowledge could not be performed as precisely as hypothesised in the
first place. This was due to the fact that 4 dermatologists and 5 medically-trained peo-
ple are insufficient to get any meaningful estimate of the variance within these groups.
It can be reported, though, that the range in which the answers of these two groups
are observed is comparable to that of laypeople, suggesting that the subjectivity of the
evaluation is predominant on other elements such as prior knowledge derived by edu-
cation or experience. It is fair to say, though, that this observation is based on a limited
amount of data and hence cannot be considered relevant without further study.
3.2.2 Correlation of Different Properties
Other kinds of analysis that can give an interesting insight into the data are based on
the study of the distribution of the answers. In particular, the analysis of correlation
between the five properties evaluated by the survey participants can give a better un-
derstanding of the collected data under two different points of view. On one hand par-
ticular correlation structures can suggest relations between the elements of the ABCD
rule which might affect the evaluation process of the observer. On the other hand, un-
derstanding the correlation between different elements is interesting from the point of
view of the development of automatic systems, as the decision on the balance between
redundant and independent features is a key part in the design of any classifier.
The correlation analysis has been performed on all the 45 images shown, not only on
the 20 in common with previous experiments, and at different levels. At first all the
data were considered together to get a general idea of any possible correlation pattern,
then the clinical classes have been analysed one at a time to verify whether the corre-
lation was stronger in some classes than in others.
Figure 3.5 shows the scatter-plots obtained from the five lesion properties over 1,890
observations. Each of the five properties is represented by a row and a column of the
matrix and, for each pair, both the scatter-plot and the correlation coefficients are re-
ported. Along the main diagonal a histogram showing the distribution of each single
property is included.

Chapter 3. User Performance with ABCD rule 25
In order to better capture the correlation of the data two different coefficients were
considered. Along with the classical Pearson’s correlation coefficient [45]
ρP =cov(x,y)σx ·σy
Spearman’s rank correlation coefficient ρS was computed [22]. Spearman’s ρS is a non-
parametric measurement of the monotonicity of the correlation between two variables.
In particular, it is based on the ranking of the observed samples rather than on their
raw values. In other words, considering n observations characterised by two variables
each, x and y, observations are ranked according to their value so that, say for variable
x, rank(i) < rank( j) if xi > x j where i and j represent two different observations.
Once the ranking according the two variables has been obtained, a ranking difference
is computed di = rxi − ry
i where rxi and ry
i represent the ranking position of observation
i with respect to variables x and y. The correlation coefficient ρS is then computed as
ρS = 1− 6∑d2i
n(n2−1)
Spearman’s coefficient is useful to complement the information obtained with Pear-
son coefficient. In particular, since Spearman’s coefficient is computed on the rank of
the observation, it is better suited to capture correlation when the monotonic relation
between the variables is non-linear. Moreover, it is more robust to the presence of out-
liers and hence produces more stable results. Both from the coefficients and by visual
inspection, it appears clear that while colour and roughness of texture do not show any
significant correlation with the other variables, colour uniformity, asymmetry and bor-
der irregularity are positively correlated. The fact that colour and roughness of texture
appear uncorrelated to the other properties allows to exclude that the observed correla-
tions are only due to some bias induced by the way users answer, such as preference for
high or low scores. If that was the case, in fact, all the variables should be correlated
and not only those which are part of the ABCD rule.
As all the data are considered together very different distributions are mixed and, as a
result, the correlation coefficients tend to be a less precise representation of the struc-
ture of the data. Visual inspection, on the other hand, guarantees a better understanding
of the different tendencies which can be seen as regions of the graph with high density
of points. Besides the marked presence of points along the diagonal in those scatter-
plots where correlation is significant, horizontal and vertical lines in correspondence to
the middle of the grading scale (around 5) can be observed in most graphs, suggesting
that people used an intermediate value very often. Moreover, some clustering of the

Chapter 3. User Performance with ABCD rule 26
Colour
0 4 8 0 4 8
04
8
04
8 ρP = 0.19
ρS = 0.18
Col.Uniformity
ρP = 0.12
ρS = 0.11
ρP = 0.66
ρS = 0.66
Asymmetry
04
8
04
8 ρP = 0.097
ρS = 0.097
ρP = 0.50
ρS = 0.50
ρP = 0.64
ρS = 0.63
Border
0 4 8
ρP = 0.26
ρS = 0.25
ρP = 0.17
ρS = 0.18
0 4 8
ρP = 0.23
ρS = 0.25
ρP = 0.16
ρS = 0.17
0 4 8
04
8Roughness
All Classes
Figure 3.5: Matrix of scatter-plots showing the correlation patterns between the different
evaluated properties. The correlation coefficients ρP (Pearson’s) and ρS (Spearman’s)
are reported. The data of all clinical classes were included.

Chapter 3. User Performance with ABCD rule 27
Col.Uniformity
0 2 4 6 8 10
02
46
810
02
46
810
ρP = 0.67
ρS = 0.69
Asymmetry
0 2 4 6 8 10
ρP = 0.51
ρS = 0.54
ρP = 0.63
ρS = 0.65
0 2 4 6 8 10
02
46
810
Border
Benign Nevus
(a)
Col.Uniformity
0 2 4 6 8 10
02
46
810
02
46
810
ρP = 0.74
ρS = 0.75
Asymmetry
0 2 4 6 8 10
ρP = 0.61
ρS = 0.61
ρP = 0.73
ρS = 0.72
0 2 4 6 8 10
02
46
810
Border
Melanoma
(b)
Col.Uniformity
0 2 4 6 8 100
24
68
10
02
46
810
ρP = 0.56
ρS = 0.55
Asymmetry
0 2 4 6 8 10
ρP = 0.25
ρS = 0.24
ρP = 0.38
ρS = 0.36
0 2 4 6 8 10
02
46
810
Border
Seborrhoeic Keratosis
(c)
Col.Uniformity
0 2 4 6 8 10
02
46
810
02
46
810
ρP = 0.56
ρS = 0.54
Asymmetry
0 2 4 6 8 10
ρP = 0.47
ρS = 0.45
ρP = 0.68
ρS = 0.65
0 2 4 6 8 10
02
46
810
Border
Dysplastic Nevus
(d)
Figure 3.6: Results of correlation analysis for each of the four clinical classes of lesions.
data can be observed. The scores for border irregularity, as an example, show a clear
concentration in the 0–1 interval.
In order to understand if particular situations like this are due to one specific clinical
class, the analysis has been repeated to a finer level of granularity, dividing the obser-
vations according to the type of lesion they refer to. Within the single classes, likewise
the general case, no significant correlation is found for colour and roughness of texture,
hence Figure 3.6 reports only the results of correlation analysis for colour uniformity,
asymmetry and border irregularity.
Both benign nevi and melanomas show high values of correlation between the consid-
ered properties, dysplastic nevi follow with a strong correlation between asymmetry

Chapter 3. User Performance with ABCD rule 28
and border irregularity, while seborrhoeic keratoses show a less sharply defined corre-
lation between the properties, with only a weak correlation between colour uniformity
and asymmetry. While in general cases the magnitude of the correlation coefficients
would not be considered particularly high, especially for the coefficients in the 0.60
range, it is interesting that values as high as 0.75 have been reached despite the ex-
tremely high variability in the answers reported in previous sections. This suggests
that even though people express very different personal judgements about the same
image, their evaluation of colour uniformity, asymmetry and border irregularity is usu-
ally highly correlated. In part this was expected as, following the guidelines of the
ABCD rule, the distribution of colour affects both colour uniformity and asymmetry,
and similarly a jagged edge would in many cases affect border irregularity as well as
asymmetry, but to the knowledge of the author no report of this has been made before
and no empirical evidence has been presented.
These findings have at least two important implications, one more related to the assess-
ment performance of humans, the other linked to the design of automatic classification
systems.
If on one hand asking people to evaluate correlated properties can be useful as fewer
doubtful cases should be faced, since the properties should be consistent (e.g. it is rare
to find a symmetric lesion with highly irregular borders) and help spotting the danger-
ous lesions, on the other hand the information content of a set of redundant properties is
reduced and hence different evaluation criteria might capture more information about
the lesions.
Considering the observed correlation, then, one problem related to the design of au-
tomatic classifiers based on the ABCD rule appears clear: if one of the criteria is not
evaluated correctly, then highly likely the others will be incorrect as well. Since a
correct evaluation of colour uniformity, asymmetry and border irregularity is highly
dependent on the detection of the border of the lesion, a sub-optimal segmentation
could lead to a wrong evaluation to all the three property resulting in a inaccurate
classification. Considering that segmentation is a very difficult task for the reasons
previously discussed, relying so heavily on it to obtain a correct classification seems
quite inappropriate.
Additionally, from the distribution of the answers given for melanomas another in-
teresting fact emerges. As shown in Figure 3.6(b), the histogram of both asymme-
try and border irregularity resembles a lot the probability density function of a Beta
distribution with α = β = 0.5, having high probability for the extreme values and a

Chapter 3. User Performance with ABCD rule 29
substantially uniform distribution between them. Since the ABCD rule recommends
to classify as possible melanomas lesions showing high values for at least one of the
ABCD criteria, the distribution of the answers obtained in this empirical study sug-
gests that many of the cases would not be detected. This is especially true because, for
the high correlation previously highlighted, it is unlikely to observe cases with two out
of the three ABC properties ranked as “non suspicious” and the third as “potentially
dangerous”. This gives another good reason to avoid developing automatic classifiers
implementing directly the ABCD rule.
3.3 Discussion
In this chapter the results from an empirical study on the performance obtained from
people when following the ABCD rule have been presented. Several conclusions can
be drawn to answer the initial question regarding whether the ABCD rule could be
useful in the development of automatic classifiers.
The first important point emerging from the data analysis is that providing visual cues
to the participants did not help reducing the variability of the their answers. The most
likely explanation behind this is the subjectivity in the evaluation of the degree of
similarity given by different people when comparing the same item to standard visual
references.
While at the beginning a Fuzzy Inference System implementing the ABCD guideline
was regarded as a possibly valuable tool to be developed during the dissertation, the
results presented show that this approach is clearly infeasible. This is due to the ex-
treme variability of the obtained answers which would make it impossible to learn any
rule on how to classify, for example, a lesion as asymmetric. For the same reason,
any system trying to learn the human decision process from the gathered data would
arguably fail.
A second result, even more important from the point of view of the development of
automatic classifiers, is the evidence of a high correlation between colour uniformity,
asymmetry and border irregularity. This correlation between the different properties
would make an automatic system based on them extremely prone to errors due to the
limited amount of information used in the classification process caused by the lack of
independence between them.
In conclusion, the ABCD rule seems overall inappropriate for automatic classification
systems and its use is discouraged.

Chapter 3. User Performance with ABCD rule 30
As a side-note, the results obtained in the experiment would suggest that the ABCD
rule is not an appropriate guideline for humans as well. Being the subject complex,
though, any conclusion on this final claim should be drawn and motivated by derma-
tologists whose expertise in the field can provide better grounded opinions.

Chapter 4
Visual Similarity of Skin Lesions
As previously explained, automatic classification of skin-lesion images is a hard task
for several reasons. One of the most relevant lies in the fact that since classification is
performed according to medical criteria, lesions belonging to the same class can have
very different appearance. Apart from the “soft” characterisation of the melanoma pro-
vided by the ABCD rule [23] or the 7-point check-list [7], which present a series of
possible warning signs rather than a real visual classification, to the author’s knowl-
edge there is no available classification of skin lesions purely based on their visual
properties. While this is clearly not a problem for specialists, it makes classification
quite challenging for automatic systems. The results of the experiment presented in the
previous chapter, moreover, show how visual guidelines developed by dermatologists,
such as the ABCD rule, can give a very high variability in the results when followed
by laypeople. Such finding suggests the need for guidelines reflecting more closely the
criteria spontaneously used by people with no medical training when evaluating skin
lesions. A deeper understanding of these criteria would, additionally, provide a good
starting point to find characterising features which can be used for automatic classifi-
cation. For this reason a study focused on extracting the specific aspects of perceived
similarity has been set up.
Given the short amount of time available for data collection, it was decided to focus
the study on Basal Cells Carcinoma (BCC) for several reasons. First of all the class
of BCCs contains lesions having very different appearance (see Figure 2.2). Even
though some properties are coherent in the whole class (for example BCCs are gener-
ally non-pigmented, i.e. “pale”, lesions) others vary quite a lot. An example of these
non-homogeneous properties is shape, as shown in Figure 4.1. Using only BCC im-
ages, hence, increases the probability of avoiding uninteresting trivial classes such as
31

Chapter 4. Visual Similarity of Skin Lesions 32
(a) (b) (c)
(d) (e) (f)
Figure 4.1: Basal Cell Carcinomas showing substantial differences in shape.
pigmented vs. non-pigmented lesions which could arise in a mixed image-set contain-
ing, for example, Melanocytic Nevi and BCCs. Furthermore, given its variability of
appearance, the BCC class is harder to classify than others using automatic systems
based on image-analysis techniques. A new classification system based on the features
which show good discriminative power among the visual classes would surely be a
useful addition to the ones under continuous development at this University.
In this chapter the procedure followed to define visual classes will be presented. An
overview of the system developed for data collection will be given in section 4.1, while
the actual procedure followed to define the visual classes will be outlined in section 4.2.
4.1 Data Collection
The decision to define visual classes through the evaluation of the feedback provided
by users highlights the importance of an appropriate data collection infrastructure. In
order to avoid biases in the obtained data, the system should simply support the action
of the users without significantly affecting their behaviour.
Aldridge et al. [6] reported how people with no medical training could successfully
group skin-lesion images in visually coherent classes during some experiments. Com-

Chapter 4. Visual Similarity of Skin Lesions 33
parable approaches have been presented in visual similarity studies [38, 46] conducted
on colour patterns and natural images. Since the approach proposed in [6] and [38]
required a direct comparison between all the pairs of images in the image-set, it could
not be directly scaled to a wide image-set without an unreasonable increment in the
time required to the user. Rogowitz et al. [46], on the other hand, chose a more time
effective approach showing, on a computer, a sequence of screens containing one tar-
get image and eight samples each, and asking volunteers to match the target with the
most similar sample. While keeping the required time manageable, this experimental
set-up induced the drawback of obtaining a very limited amount of information from
each of the proposed screens. Specifically, that was due to the request of matching the
target with the most similar sample. In case two or more very similar samples were
shown, in fact, only one could be matched with the target, loosing records of similarity.
More subtly this approach could increase the effect of the subjectivity of the evalua-
tion. Since two similar samples have roughly the same probability of being chosen, in
fact, the recorded match would give more importance to the subjective preference of
the user than to the actual similarity with the target. Even though this condition is rare
due to the randomised generation of the screens, it is nonetheless undesirable since it
can lead to obtain votes evenly spread over similar sample stimuli, possibly inducing to
wrong interpretations in the data analysis. Moreover no mention is made in [46] to any
option given to the user to avoid providing any match if all the samples are considered
dissimilar to the target.
The application developed during this dissertation for data collection was designed to
avoid the aforementioned shortcomings. The interface, see Figure 4.2, consists in a
sequence of 10 screens each presenting to the user 2 target images (top of the screen)
and 24 samples (pooled at the bottom of the screen). When generating the screens,
images are randomly selected to satisfy two conditions:
1. each image must appear only once as a target in the whole experiment
2. if one lesion is chosen as a target, it cannot appear as a sample in the same screen
The user is required to assign 0–6 samples to each target simply by moving the corre-
sponding image in one of the slots available in the central part of the screen. Allowing
the user to match multiple samples to the same target alleviates one of the limitation
highlighted for [46], since whenever similar samples are present in a screen, they can
all be matched to the same target. This is expected to reduce the impact of the subjec-
tive evaluation of the resemblance on the final result, supporting the emergence of the

Chapter 4. Visual Similarity of Skin Lesions 34
Figure 4.2: Web interface developed to collect similarity assessment data.

Chapter 4. Visual Similarity of Skin Lesions 35
Figure 4.3: Diagram of database tables for experiment 2.
underlying similarity of the images. Since the user is not forced to assign at least one
sample to each target, moreover, another possible bias of [46] is eliminated. Finally,
limiting the maximum number of matches to 6 should avoid selections made according
to loose similarity criteria.
The choice of showing 2 targets for each screen has the double function of maximising
the data gathered and of forcing the user to make a decision between two possibilities,
which should cause a more careful evaluation of similarities and differences observed
between the images.
One problem of this set-up is that, due to the completely random selection procedure,
the targets in a screen could be very similar to one another, making it difficult for the
user to decide how to match the samples. The effects of this drawback, though, have
been considered less important than the benefit gained by the presence of multiple tar-
gets.
In order to reach as many people as possible, the interface was implemented as a web-
application running on a Tomcat server and is available, as of August 2010, at the
address http://demos.inf.ed.ac.uk:8848/webs2. The application was designed to guar-
antee easy user interaction and to facilitate image evaluation. Some of the implemen-
tation choices made in this direction include presenting the lesion images on a black
background, which enhances colour perception, and providing easy zooming for the
small sample images.
Along with the matches, the structure of each screen and some demographic data of
the users are stored on a PostgreSQL server. A diagram of the database tables can be
found in Figure 4.3.
In total, a set of 115 BCC images have been used in the experiment. Given the short
time available for the data collection phase, a small number of participants was hypoth-
esised for the experiment. In this scenario, including all the images in the first place
would have resulted in a similarity matrix providing only a rough approximation of
the similarity structures. This is due to the fact that, as discussed later in section 4.2.1,
the similarity between two images is modelled by the frequency with which they have

Chapter 4. Visual Similarity of Skin Lesions 36
been matched together. By a parallel with a frequentist approach to probability, we
know that this approximation is only asymptotically unbiased and in small samples
can present substantial errors. For this reason, images need to appear a fair number
of times in the same screen before the computed index of similarity can be considered
reliable. In order to grant this, in the first phase of the experiments only 30 out of
the 115 images were actually used. Once a reasonable number of answers had been
collected, then, the image set have been enlarged, but in an asymmetric way. Ten more
images have been added to the pool from which targets are selected, while all the 115
images have been considered as possible samples. This approach is intended to widen
the coverage of the study by making the similarity matrix less sparse, while still grant-
ing as much reliability in the estimates as possible. At the time of writing 43 people
have contributed giving their answers to the survey for a total of 2,395 sample-target
matches. While the number can seem big, it would have been widely insufficient to
estimate unbiased indexes for the total 6,555 possible pairs had all the 115 images been
used in the first place.
4.2 Definition of Visual Classes
Once collected, the data regarding the similarity expressed by the survey participants
through the matching of samples and targets had to be analysed. The goal of the anal-
ysis was the creation of visual classes to be used for two different purposes. In the first
place, the creation of classes from the data was aimed at showing the groups defined
by the users on the basis of visual similarity. The visualisation of these groups was
meant to give both an insight on the criteria followed by people while assessing simi-
larity, and an outlook of the topological organisation of the groups, which is useful to
understand their relation. This was important especially from the point of view of the
dermatologists as they could evaluate whether people were able to group together simi-
lar lesions without any instruction regarding the similarity criteria to follow. Secondly,
the definition of visual classes was functional to the creation of the training image-set
for an automatic classifier designed to learn the principles used by humans during the
experiment.
Even though the two tasks present several similarities, the peculiar needs of the two
purposes of the classification required the use of two specific techniques.
In order to understand the criteria used to assess visual similarity, visual classes should
be defined in a “soft” way, allowing elements to act as a connection between differ-

Chapter 4. Visual Similarity of Skin Lesions 37
ent homogeneous clusters. Moreover, the groups must be displayed together in a way
which makes immediately clear how similar or dissimilar images or groups of images
have been considered. For this task real boundaries between classes are not needed,
but the similarity structure must appear clear at a glance. The best technique to per-
form this kind of analysis is Multi-Dimensional Scaling which will be presented in
section 4.2.1.
The training of a classification system, on the other hand, requires homogeneous and
well separated classes as supervised learning algorithms need the training samples to
be uniquely labelled as belonging to one specific class. While fuzzy classifiers or prob-
abilistic mixture models could have been used to relax this necessity, it was decided to
learn separated classes and cope with intermediate cases through probabilistic classifi-
cation. In order to define the appropriate groups a technique called Spectral Clustering
(presented in section 4.2.2) has been used.
The following part of the chapter will concentrate on explaining these two techniques
and reporting the obtained results.
4.2.1 Multi-Dimensional Scaling
As in many other studies based on perceptual similarity [6, 38, 46] the data gathered
in the evaluation sessions have been used as an input for Multi-Dimensional Scaling
(MDS) [11]. Multi-Dimensional Scaling is a technique used to map the similarity
structure of a given set of elements, as expressed by a distance matrix, to a geometric
configuration sitting in a space with a specified number of dimensions. Being a data
visualisation technique, Multi-Dimensional Scaling is generally used to produce 1D
or 2D plots in which the points, representing the elements whose similarity is known,
are laid out in a configuration reflecting the relations expressed by the distance matrix.
The use of Multi-Dimensional Scaling to produce configurations in higher-dimensional
spaces is rare because of the inherent difficulties in the visualisation. It is nonetheless
possible provided that a suitable solution for inspecting the data is found.
Incrementing the number of dimensions of the target space has the effect of allowing
new dimensions in which the data can be organised. In practice, progressively adding
new dimensions it is possible to try to capture at a finer level the hierarchy of evalua-
tion criteria which the users followed to generate the similarity structure.
Various formulations of MDS exist [11] and may differ in the way they find the fi-
nal layout of the points. In general MDS is formulated as an optimisation problem

Chapter 4. Visual Similarity of Skin Lesions 38
where the the cost function to be minimised is a measurement of how much the dis-
tance between each pair of points di, j is different from the corresponding element δi, j
of the distance matrix given as an input. The specific formulation depends on the kind
of MDS algorithm chosen. Without going through very specific details, the two most
important types of MDS are metric and non-metric MDS. The difference lays in the as-
sumptions each of the two models makes on the structure of the distance matrix given
as the input. These, in turn, translate in different formulations of the optimisation prob-
lem. For our purposes non-metric MDS was chosen, as it is more flexible posing less
restrictions on the structure of the distance matrix. This was necessary as the way such
matrix is derived cannot guarantee some of the key properties of metric models. The
price to pay to get this flexibility is a less informative final layout, where the observed
distances cannot be interpreted as real metric distances but rather as ranking informa-
tion. In other words given three points A, B and C, if the distance between A and B
is lower than that between A and C we can only conclude that B is more similar to A
than C but the magnitude of the distances does not carry any significant meaning.
Before running the MDS algorithm, two preparation steps are necessary: first of all the
collected data must be translated into a similarity matrix, then the similarity matrix has
to be converted in a distance matrix which can be used for MDS.
The similarity matrix S was created on the basis of the recorded matches. Each ele-
ment si j of the matrix represents the similarity between lesion i and lesion j and was
computed as
si j =recorded matches between i and j
total appearances of i and j in the same screen
By definition each lesion is considered to be maximally similar to itself, so it is im-
posed that sii = 1. This is necessary as the elements on the diagonal of the similarity
matrix are ignored by the previous formula, since one image cannot appear in a screen
both as a target and as a sample. Since Multi-Dimensional Scaling algorithms take
distance measurements as an input, the similarity matrix S was converted to a distance
matrix D. A standard conversion formula was used, where
di j =√
sii + s j j−2si j
It is important to underline that even though in general this conversion guarantees the
non-degeneracy property
di j = 0 ⇐⇒ i = j

Chapter 4. Visual Similarity of Skin Lesions 39
since, for a set of non corresponding points, only the elements on the diagonal of the
similarity matrix have value 1, in our case this is not necessarily the case. Even though
it is rare, in fact, it can happen that two lesions are matched every single time they ap-
pear in the same screen. This would cause their similarity to be 1 and their distance to
be 0. In order to avoid this inconvenience, if any off-diagonal element of the similarity
matrix equals 1, it is decreased to be slightly lower. This artificial modification of the
similarity matrix has the only effect of avoiding the fusion of multiple points and al-
lows a better structure of the final layout without substantially affecting the similarity
structure expressed by the users. It must be said, though, that up to now this procedure
has never been necessary since the highest similarity recorded is 0.90.
While in the exploratory data analysis phase the package ggobi [3] proved extremely
useful for its flexibility, for the final MDS analysis the R function isoMDS was used.
The results obtained for MDS in 1D and 2D can be seen in Figure 4.4 and Figure 4.5
respectively. In both cases MDS was performed on a subset of the complete collec-
tion of images, in particular on the 30 images which were included in the study in
the first place. The main reason behind this choice is that since the purpose of MDS
is understanding the main dimensions evaluated by people when assessing similar-
ity, the similarity measurement fed into the algorithm must be correct. As previously
mentioned, this happens only for pairs of images which have appeared several times
together in the same screen. For this reason, only the 30 images included in the survey
from the beginning constituted an appropriate sample.
Performing MDS in one dimension is equivalent to allow for only one criterion in the
evaluation of the similarity between the different skin-lesion images. This analysis,
hence, is supposed to find the most important aspect which guides the assessment pro-
cess followed by the observers. Figure 4.4 shows the results of a 1D MDS, where the
horizontal axis represents the only dimension of variation allowed while the vertical
displacement of the elements is introduced merely for visualisation purposes and car-
ries no meaning. In order to avoid confusion, only some of the images have been added
to the graph to make clear why the lesions had been considered similar without having
too much clutter on the plot. Conversely, the id of all the lesions is reported for readers
interested in consulting the DERMOFIT lesions database. For a correct interpretation
of the plots, please note that both in Figure 4.4 and in Figure 4.5 the real configuration
is that of the labels. Pictures have been added where they fitted best, but sometimes
their position might be misleading. Always refer to the labels when making consider-
ations about the layout produced by the MDS algorithm.

Chapter 4. Visual Similarity of Skin Lesions 40
Figure 4.4: Results of Multi-Dimensional Scaling with a 1D output layout. The vertical
displacement is added only for visualisation purposes and does not carry any specific
meaning.

Chapter 4. Visual Similarity of Skin Lesions 41
Figure 4.5: Results of Multi-Dimensional Scaling with a 2D output layout.
From visual inspection it seems reasonable to assume that the most important similar-
ity criterion used in the evaluation of BCCs is vertical prominence. On the left of the
graph, in fact lesions are flat and relatively smooth. Moving towards the right-hand-
side, the elevation of the lesion from the skin level progressively grows, up to the point
where, to the extreme right, the lesions are dome-shaped with a clear rise above the
surrounding skin.
When performing MDS in two dimensions a second evaluation criterion is allowed to
emerge. Figure 4.5 shows the obtained results. Examining the plot, the importance of
the elevation from the skin level is still considerable and is captured by the horizontal
dimension, while the meaning attributed to the vertical axis is less sharply defined.
Apparently, this should be linked to a general concept of smoothness, but it is not clear
whether importance is given to the smoothness of the surface of the lesion per se or to
the presence of scabs or bleeding patches, as in both cases exceptions to the general
rule seem to be present. Regardless the real meaning of the second dimension, though,
the presence of visually homogeneous lesions in each region of the plot and the appar-
ently smooth transaction between harshly different groups, would suggest that people
can effectively perceive similarity between skin lesions. To better understand this find-
ings, more effort should be dedicated to investigating the similarity criteria used. To

Chapter 4. Visual Similarity of Skin Lesions 42
go in this direction, the web application used to collect data will be available on-line
even after the end of this project, since a wider collection of answers is expected to
shed more light into the actual hierarchy of evaluation criteria.
4.2.2 Spectral Clustering
Despite its usefulness for visualising the structure of the data expressed by the simi-
larity matrix, Multi-Dimensional Scaling is not an appropriate technique for creating
the visual classes necessary for the training of an automatic classifier. The reason be-
hind this is that MDS algorithms do not create any group but simply a configuration of
points which is as coherent as possible to the underlying similarity structure. In order
to obtain a set of separate classes, then, a clustering algorithm needed to be used.
While many clustering algorithms have been presented in the years, most of them are
not suitable to solve the problem at hand. Nearly all the clustering algorithms, in fact,
need as an input the coordinates of the points which have to be divided in groups. As
the data collected from the experiments do not provide any form of coordinates, these
approaches to clustering could not be followed.
Even though clustering the points obtained through MDS might seem a solution to this
problem, it is not the case as after non-metric MDS the distance between the points
carries only ranking information while its magnitude, which would be needed for clus-
tering, is not significant. As most of the studies regarding perceptual similarity (e.g.
[38, 46]) are not really aimed at creating classes but rather at understanding the cri-
teria followed by people to decide whether two elements are similar or dissimilar, no
application of clustering is on average required in this kind of research. Clustering,
on the other hand, is generally applied when a set of well defined points located in a
specific space need to be divided in groups according to their position. The result of
such specificities, is that hardly any documentation can be found concerning how to
cluster elements when the only available data is represented by a measurement of their
similarity.
The solution to this situation was found in the partial application of a technique known
as spectral clustering. Since one of the first steps of any spectral clustering algo-
rithm is the derivation of a similarity matrix starting from the coordinates of the points
which are to be grouped, skipping this first passage and providing the algorithm di-
rectly with the similarity matrix obtained from the matching experiments seemed a
principled workaround to obtain the desired clustering of elements (skin-lesion im-

Chapter 4. Visual Similarity of Skin Lesions 43
Algorithm 1 Spectral Clustering Algorithm by Ng et al. [41]Task: divide a set of points S = {s1, . . . ,sn}, with si ∈ Rl , in k clusters
1. Form the affinity matrix A ∈ Rn×n defined by Ai j = exp(−‖si−s j‖2
2σ2
)if i 6= j and
Aii = 0
2. Define D to be the diagonal matrix whose (i, i)-element is the sum of the i-th row
of matrix A
3. Construct the L matrix: L = D−1/2AD−1/2
4. Find the k largest eigenvectors of L: x1, . . . ,xk
5. Form the n× k matrix X = [x1 . . .xk] by stacking the found eigenvectors as
columns
6. Form matrix Y from X by renormalising the rows of X to have unit length i.e.
Yi j = Xi j/(∑ j X2i j)
1/2
7. Treating each row of Y as a point in Rk, use a clustering algorithm, such as k-
means, to find k clusters
8. Replicate the clustering on the original points assigning si to cluster j if and only
if the i-th row of matrix Y was assigned to cluster j
ages) which could in no way be interpreted as points of a given space.
Among the different perspectives from which spectral clustering can be seen (see von
Luxburg [53] for an extended tutorial), the more intuitive one is that based on similarity
graphs. It can be proved, in fact, that performing spectral clustering is mathematically
equivalent to solving a partitioning problem on a graph so that edges between different
groups have low weight and edges within the same group have high weight. If a graph
is built so that each edge connecting two vertexes has an associated weight represent-
ing the similarity between them, solving the aforementioned partitioning of the graph
leads to a clustering of the vertexes based on their similarity. Finding this partitioning
passes through spectral graph theory (see Chung [19]) and implies the computation of
the graph Laplacian.
A wide variety of spectral clustering algorithms can be found in literature, the one im-
plemented and used to find the visual classes is that proposed by Ng et al. [41] which is
outlined in Algorithm 1. As mentioned before, the data obtained from the experiments
cannot be directly represented as points in any particular space, but a similarity ma-
trix can easily be derived from the stored matches between samples and targets. Due to

Chapter 4. Visual Similarity of Skin Lesions 44
Figure 4.6: Hierarchical structure of the derived clusters.
this, spectral clustering techniques can be used to derive visual classes. In particular, in
order to apply the algorithm by Ng et al. outlined in Algorithm 1, it is sufficient to sub-
stitute the first step with the procedure presented in section 4.2.1 to obtain a similarity
matrix (or affinity matrix as in Algorithm 1) which can then be used to follow the rest
of the procedure. A minor intervention is required on the similarity matrix computed
from the matches, as many of its elements have value zero while, by construction, the
affinity matrix computed in the spectral clustering algorithm does not have any off-
diagonal zero elements. To avoid issues during the computations, all the zero elements
of the similarity are changed to an arbitrarily small number before beginning to follow
the algorithm.
Due to the mathematical operations performed on the similarity matrix in the first
steps of the algorithm, though, complications might emerge if quasi-multicollinearity
of the similarity matrix could cause instability in the achieved results. Even though it
is rare, there is no way to guarantee, in fact, that the similarity matrix does not show
quasi-multicollinearity, especially considering the high number of its elements having
value zero. In order to test the stability of the clustering procedure and verify if such
a problem should be of major concern, the data have been split in two separate sam-
ples (respectively including the answers of 22 and 21 people) and clustering has been
performed independently on them. In order to obtain better results, a hierarchical ap-
proach was chosen, creating 2 clusters for every clustering level. Given this choice,
only the first 2 eigenvector of matrix L had to be retained (see Algorithm 1) and hence
the similarity configuration was basically projected in a 2-dimensional space. Cluster-
ing was then performed with k-means [51] requiring 2 clusters for each hierarchical
run. Given its homogeneity, cluster 1 was never further divided, and the hierarchical

Chapter 4. Visual Similarity of Skin Lesions 45
procedure focused on cluster 2 for which three more levels were extracted. In order
to better understand the hierarchical structure, an schematic outline is provided in Fig-
ure 4.6.
The clusters resulting from the analysis on the 30 images included in the experiment
from the beginning are shown in Figure 4.7 for sample 1 and in Figure 4.8 for sample
2. As can be seen by comparison, at the first hierarchical level the two sets of answers
gave the same results, as cluster 1 and cluster 2 have the same elements in the two
cases. Looking at the lower levels in the hierarchy, conversely, some differences can
be seen. Despite these discrepancies, consistent overlap can be found in the two cases.
Sub-cluster 2.1 of Figure 4.7, for example, is the same of sub-cluster 2.2a in Figure 4.8
with the inclusion of one additional lesion. Similarly, sub-cluster 2.2b of Figure 4.8
has many elements in common with the union of sub-clusters 2.2a and 2.2b of Fig-
ure 4.7. Even though the clustering results are not identical beyond the first level of the
hierarchy, it is fair to say that the differences are not extreme and, most importantly,
that the classes show some peculiar aspects which may lead to define the belonging
lesions as visually similar.
Considering the coherence in the highest level of the hierarchy and the relatively small
dimensionality of the two samples, it can be concluded that the differences observed at
lower hierarchical levels are not of major concern and may ultimately disappear with
wider samples. For this reason, spectral clustering can be considered stable enough de-
spite the structure of the similarity matrix, and can be used to define the visual classes
which will eventually be used in the automatic classification system. The results ob-
tained running the implemented code on the complete dataset can be seen in Figure 4.9.
The first hierarchical level is the same obtained on the two partial datasets, while the
following levels present some differences with previous results. Despite that, a lot of
commonalities can be observed. Sub-cluster 2.2b of Figure 4.9, for example, is gener-
ally preserved in both the previous cases and aggregates similar to sub-cluster 2.2a can
be found in the other figures as well.
Given the homogeneity shown by the elements of each of the obtained visual classes,
it can be concluded that the intuition of using spectral clustering in this unusual way
was correct and produced the expected outcomes.
As a further test, the results of spectral clustering have been mapped to the output
configuration provided by Multi-Dimensional Scaling (MDS). The result is shown in
Figure 4.10. The colours are used as coding for the different clusters. Red has been
used for the first homogeneous set of lesions found at the first level of the hierarchical

Chapter 4. Visual Similarity of Skin Lesions 46
Cluster 1
Cluster 2
Sub-cluster 2.1
Sub-cluster 2.2a Sub-cluster 2.2b
Sub-cluster 1
D288
D333
D547b
D584
D652 D670a
P36P110
P149
P483
P504
D254 D489 D700a P370aD565 P84a
D511 D642 D662 P91P316
D232a D472 P140a
P243b P469a P387 P72
P102
Figure 4.7: Results of Spectral Clustering (hierarchical with 2 clusters for each level) on
sample 1 (22 sets of answers).

Chapter 4. Visual Similarity of Skin Lesions 47
Cluster 1
Cluster 2
Sub-cluster 2.1
Sub-cluster 2.2a Sub-cluster 2.2b
Sub-cluster 1
D288
D333
D547b
D584
D652 D670a
P36P110
P149
P483
P504
P102 D254 D700a P370a
D232a D489D565 P72 P84aP316
D472
P140aP243b
P387 P469a
P91D662
D642D511
Figure 4.8: Results of Spectral Clustering (hierarchical with 2 clusters for each level) on
sample 2 (21 sets of answers).

Chapter 4. Visual Similarity of Skin Lesions 48
Cluster 1
Cluster 2
Sub-cluster 2.1
Sub-cluster 1
Sub-cluster 2.2a Sub-cluster 2.2b
D232a
D254
D288
D333
D472
D489
D511
D547b
D565
D584
D642
D652
D662
D670a
D700a
P36
P72
P84a
P91
P102
P110
P140a
P149
P243b
P316
P370a
P387
P469a
P483
P504
Figure 4.9: Results of Spectral Clustering (hierarchical with 2 clusters for each level) on
the complete dataset (43 sets of answers).

Chapter 4. Visual Similarity of Skin Lesions 49
−0.6 −0.4 −0.2 0.0 0.2 0.4 0.6
−0.
6−
0.4
−0.
20.
00.
20.
40.
6
Non−Metric MDS (2D)
Coordinate 1
Coo
rdin
ate
2D232a
D254
D288
D333D472
D489
D511
D547b
D565
D584
D642
D652
D662
D670a
D700a
P102
P110
P140a
P149
P243b
P316
P36
P370a
P387
P469a
P483
P504
P72
P84a
P91
Figure 4.10: Results of Spectral Clustering mapped on the output of Multi-Dimensional
Scaling. Red represents cluster 1 while all the other colours are used for sub-clusters
of cluster 2: light blue coding for sub-cluster 1, blue for sub-cluster 2.1, green for sub-
cluster 2.2a and purple for sub-cluster 2.2b.
clustering procedure (cluster 1 in Figure 4.9). All the other colours, on the other hand,
have been used for the single sub-clusters of cluster 2, with light blue coding for sub-
cluster 1, blue for sub-cluster 2.1, green for sub-cluster 2.2a and purple for sub-cluster
2.2b.
It is interesting to note how the dimension represented by the horizontal axis in the
plot, which in section 4.2.1 was hypothesised to reflect the vertical prominence of the
lesion, seems to be far more important than the other one in terms of definition of the
visual classes. This can be seen from the fact that each class tends to be in a sub-
stantially characteristic horizontal position while having a considerable spread in the
vertical direction. It is interesting, moreover, the fact that successive levels in the hi-
erarchy are obtained moving progressively to the right-hand side of the MDS graph.
While this is not entirely surprising as more similar clusters, like those found in lower

Chapter 4. Visual Similarity of Skin Lesions 50
levels of the hierarchy, are expected to be next to each other in the MDS plot, it is
rather peculiar to observe such a monotonic movement towards the right-hand side of
the plot. At the time of writing the available data is not enough to support further spec-
ulation about the reasons behind this phenomenon, but the collection of more answers
and the progressive inclusion of new skin-lesion images are expected to provide a bet-
ter understanding of the dynamics which led to it.
Despite the availability of different readily available functions implementing spectral
clustering, it is often difficult to understand from the documentation which of the many
algorithms the code is really implementing. Moreover, given the rather peculiar use
which was made of spectral clustering, skipping completely the first part of the algo-
rithm, an own implementation was developed in R (scripting language for statistical
applications). Implementing the code gave better visibility on the matrix operations
performed and hence allowed to run appropriate tests, like comparing the clusters ob-
tained on two subsets of the data, to verify whether the structure of the similarity matrix
could induce mathematical instability producing potentially unreliable results.
4.3 Discussion
After the presentation of the experiment designed to obtain an estimate of the visual
similarity perceived between different skin-lesion images, and an overview of the web-
application developed to support the data collection, the attention was focused on the
analysis of the gathered data. This analysis had two main purposes. In the first place
the similarity structure emerging from the recorded sample-target matches had to be
studied to verify the presence of meaningful evaluation criteria followed by the people
who took part in the experiment. Secondly a partitioning of the lesions in visual classes
characterised by coherent properties had to be found, as labelled examples were needed
for the supervised training of the automatic classifier presented in the next chapter.
Multi-Dimensional Scaling (MDS) was used to display the similarity structure ex-
pressed by the recorded matches and showed two main facts. First of all, the consis-
tency of the obtained configuration, showing a smooth transaction between extremely
different images, allowed to conclude that people can effectively match together sim-
ilar skin-lesion images even without any guideline defining what makes them similar.
This is a very important finding as it suggests that the extreme variability of the results
obtained in the experiment testing the ABCD rule was not due to the inability of people
to give evaluations, but more likely to the rule itself which seems to guide the assess-

Chapter 4. Visual Similarity of Skin Lesions 51
ment in a wrong way. The fact that people could match together similar skin lesions
supports the idea that the innate ability humans have to recognise patterns might be
more useful for diagnostic purposes than guidelines based on an explicit evaluation of
a set of properties, as partly pointed out by Aldridge et al. [6]. This may lead to a
new approach to skin-lesion assessment based more on visual examples than on sets of
properties. The second important outcome obtained from MDS is evidence that people
tend to give very high importance to the vertical prominence of BCCs while evaluat-
ing their similarity. Other criteria are surely part of the evaluation but this property
is by far the most important as underlined by the obtained visual classes. This obser-
vation would suggest that a good classification system should take into consideration
the 3D structure of the lesion, for example through the use of depth data. Due to time
constraints, it will not be possible to include this type of information in the system
proposed in this dissertation. Nonetheless, this addition is an interesting direction for
future research, particularly considering that Li et al. [32] had already highlighted the
importance of 3D data for skin-lesion analysis.
In order to obtain visual classes, an uncommon use of spectral clustering has been
made, following only part of the algorithm in order to take advantage of the form in
which the similarity data have been collected during the experiments. The results show
the presence of two very stable classes: flat and non-flat BCCs. Given the low internal
homogeneity, the class of non-flat BCCs could further be divided in sub-clusters but
the results show only relative stability. This issue, though, is believed to be due to the
limited amount of data currently available, and is expected to disappear, or anyway to
reduce considerably, as more data are stored.
Starting from the defined visual classes, a classification system has been developed. Its
description can be found in the next chapter.

Chapter 5
Automatic Classification System
The literature review presented in section 2.2 showed that over the years very different
approaches have been followed to tackle the problem of automatic classification of skin
lesions. One of the aims of this thesis was proposing a classification system capable of
solving some of the issues observed in those presented in the past.
As previously mentioned, the presented classifier will not be like any of those currently
available. This is due the fact that it will try to reproduce the visual classes defined by
people during the similarity assessment experiments. While no attempt to solve this
problem has been previously reported, this approach is believed to be promising to
obtain better results in the recognition of Basal Cell Carcinomas (BCCs). This, in turn,
would allow to move one step further towards the practical use of Computer-Aided
Diagnosis tools in the field of dermatology.
Each section of this chapter addresses one specific part of the system development,
starting with conceptual design and implementation, and getting to the evaluation of
the obtained results.
5.1 Structure of the System
When designing the system, some of the results of previous research helped in guiding
the implementation choices.
The first and most problematic aspect of the classification of skin lesions is related to
the automatic segmentation of the images. Given the specific characteristics of skin
lesions (e.g. in terms of colour, contrast between lesion and surrounding skin, etc.)
segmentation is in general a hard task (see e.g. Capdehourat et al. [15]). Despite this
intrinsic difficulties, most of the systems presented so far heavily rely on segmenta-
52

Chapter 5. Automatic Classification System 53
tion to compute the features used for classification (see section 2.2 for more details).
The few systems which do not include a segmentation step, e.g [48], work on patches
of images extracted from the internal region of the lesion, possibly missing impor-
tant aspects of the borders. The first implementation choice made was that of creating
a system which would not require any segmentation stage. The advantages of not
performing segmentation are considerable especially considering that BCCs are non-
pigmented lesions and hence tend to be very similar, in colour, to the surrounding skin.
Moreover, this represents an unexplored direction of research an it was worth verifying
whether it could prove promising or not. This choice, though, exposes to the risk of
giving more importance to the properties of the normal skin rather than to those of the
lesion itself.
The second important choice was that of trying to mirror the latest trends in object
recognition systems in terms of their architecture. In recent years, in fact, more and
more attention has been paid to the use of hierarchical architectures in the field of vi-
sion. The main concept is that of stacking a series of different layers one on top of
the other and perform classification on the basis of the output of the last level. While
the classical structure of multi-layer perceptrons can be seen as an instance of this
class, recent advances suggested different ways of organising the layers and alternative
learning strategies. The systems based on such an architecture are generally grouped
under the name of deep learning methods, a category which embraces a wide vari-
ety of approaches. Some popular examples include the work by Prof. LeCun and his
research group (NYU) on convolutional networks (e.g. by LeCun et al. [29], or by
Kavukcuoglu et al.[26]) and some more biologically inspired systems proposed by the
group of Prof. Poggio (MIT), particularly by Serre et al. [49] and by Mutch and Lowe
[39].
A full description of deep learning architectures is not needed to motivate the imple-
mentation choices made and only the main concepts will be presented. For an extensive
introduction to the topic see the monograph by Bengio [10].
The fundamental idea behind deep architectures is that of creating a layered system
which computes, at each level, a set of features based on the output of the lower units.
The main difference with the classical multi-layer perceptron approach lays in the fact
that the features of intermediate levels are learned in an unsupervised fashion, and
only the output of the highest level is used to train a classification system in a super-
vised way. Roughly speaking, this approach lets the intermediate features be generated
on the basis of specific traits of the training image-set. As the information is propa-

Chapter 5. Automatic Classification System 54
gated through the architecture, the higher-level features are expected to capture the
co-occurrence patterns of those belonging to the next lower layer, resulting in better
descriptors of the specific set of images under analysis. The output of the top level is
then supposed to be highly informative about the variations typically occurring in the
training image-set and can be used for classification.
Different systems adopt different strategies to learn the intermediate features, but the
main point characterising this kind of techniques is that they try to pave a new way
to object recognition where the features used to discriminate between the classes are
not imposed by the researcher, but emerge autonomously. The descriptors obtained
through this procedure should reflect more closely the low-level properties of the im-
ages which otherwise could be lost. In a way this approach can be seen as moving a
step back and letting the machine learn to see instead of imposing the researcher’s idea
about how and what the machine should see.
For this reason, the idea of implementing an hierarchical system seemed appropriate
to solve the task at hand as automatically learning a low-level representation of the
skin-lesion images is expected to give better descriptors than those crafted by humans.
This is particularly true in our case since the aim of the system is replicating classes
which have been created by people evaluating visual similarity.
Another characteristic which makes these architectures particularly attractive is that
they do not require any segmentation of the image as reported by LeCun et al. [29]
and Serre et al. [49]. Considering that segmentation is one of the main issues when
dealing with skin-lesion images, systems which do not require it could provide consid-
erable advantages.
As previously mentioned, deep learning is a framework within which very different
implementations can be found. The remaining part of this section will present the im-
plementation choices made when developing the two main parts of the system: the
feature extraction stage and the classification stage.
5.1.1 Feature Extraction Stage
The feature extraction stage is of crucial importance in every hierarchical architecture
as it is the part which is supposed to capture the structure of the presented image.
Many object recognition systems have already been proposed, each having its peculiar
feature extractor. The differences are not only to be found in the type of the computed
features, but in the number of levels in the hierarchy and in the way the intermediate

Chapter 5. Automatic Classification System 55
layers combine the information coming from lower levels to obtain new features. The
systems proposed by Serre et al. [49] and Mutch and Lowe [39], for example, are
inspired by the ventral stream of primates visual cortex. They start, at the lowest level,
with features representing responses of image patches to Gabor filters. Non-linear op-
erations are then performed as the level increases, always pooling together features of
the next lower layer. The result is a progressive widening of the “receptive field” char-
acterising the feature detectors. A similar approach is followed by LeCun et al. [29]
and Kavukcuoglu et al. [26], who focus less on the biological plausibility of their sys-
tems and use convolutional networks as the basis of their architectures. In this case the
features are learned with energy-based methods, a non-probabilistic learning strategy
which grants better performance in situations where a normalised probability measure
is not required as an output (see LeCun et al. [28] for a self-contained tutorial).
The system proposed by Kavukcuoglu et al. [26] is of particular interest as it learns a
set of features which are pooled in neighbourhoods in such a way to guarantee some
degree of invariance to the transformations observed in the images of the training set.
Despite the interesting peculiarities of the system and the good performance claimed
by the authors, the architecture has been trained and tested on image-sets either includ-
ing handwritten digits or pictures of objects. The problem with these type of images is
that they are extremely different from skin lesions, as they generally show much more
structure and often sharper contrast between the object and the background. For this
reason it was not possible to guarantee that the system would have worked comparably
well on skin-lesion images. The best alternative was found in the work by Hyvarinen
et al. [25] who proposed several statistical models to describe natural images. Even
though natural images are not a good approximation of skin-lesion images either, they
are much more similar than those of objects and hence this approach was considered
more likely to succeed.
Among the various proposed in [25], the technique chosen to implement the first
layer of the feature extraction stage was topographic Independent Component Anal-
ysis (tICA). Even though statistical details are extremely important, they cannot be
included here and the reader is encouraged to refer to [25] for getting a better under-
standing about the technical aspects.
The concept behind tICA is extending standard Independent Component Analysis so
that the topological organisation of the visual cortex is reproduced. Basically, a set of
features detectors are organised on a 2D grid and statistical dependency is imposed on
the output of the detectors belonging to the same neighbourhood (in our case a 5× 5

Chapter 5. Automatic Classification System 56
square). Imposing this statistical dependency is conceptually equivalent to forcing
nearby detectors to respond to similar features. The features are then learned through
a modified version of the standard Independent Component Analysis operating on a
set of patches extracted from the images of the training set. The obtained result is a
set of feature detectors organised on a topological grid according to the similarity of
the underlying feature. It is important to underline that imposing similarity through
statistical dependency of the output of the feature detectors does not define any spe-
cific concept of similarity. Conversely, features which are often active together will
be considered similar and hence grouped in the same neighbourhood. The concept of
similarity is therefore entirely learned from the images of the training set (see [25] for
more details).
Two different strategies have been used to compute the outputs of the feature detectors.
In the first place the output s′ of the i-th feature detector was computed as
s′i =T
∑j=1
wTi p j
where wTi is the vector obtained by arranging Wi (matrix storing the coefficients of
the i-th feature detector) in a single row, p j is the j-th patch of the image organised
in a column vector, and T is the total number of patches of fixed size which can be
extracted from the image. The output s′i is, in other words, the total activation of the
i-th feature detector passed on the whole image. An alternative formulation has also
been used with s′i being
s′i = maxj(wT
i p j)
with all the variables having the same meaning as above. In this case s′i represents the
maximum activation level reached by the i-th feature detector on the analysed image.
The different results obtained are commented on in section 5.2.
Even though various authors report an increase in the performance obtained as the
number of layers increases [39, 49], the inner dynamics of the system becomes quickly
difficult to understand. For this reason it was decided to limit the architecture to 2
layers.
The second layer was designed to pool the output of neighbouring first-layer feature
detectors. The pooling was performed on 4×4 squares organised to partially overlap
with each other. The activation s′′ of the z-th element of the second layer is computed
as
s′′z =
√∑p(z)
s′p2

Chapter 5. Automatic Classification System 57
where p(z) represents the set of feature detectors of layer 1 belonging to the pooling
square of the z-th element of layer 2.
Given the layout of the pooling squares, even layer 2 is configured as a 2D grid, having
the side half of the size of that of layer 1.
5.1.2 Classification Stage
In order to implement the classification stage, a Gaussian Process (GP) have been
preferred over more common approaches based on Support Vector Machines [26, 49].
GPs are sophisticated probabilistic objects and cannot be fully covered in a short para-
graph. Only the main features of GPs will be presented here, for a full coverage please
refer to the work by Rasmussen and Williams [43]
There are three main reasons which led to the choice of using a GP.
First of all, GPs are probabilistic techniques and hence perform classification in a prob-
abilistic way. This means that the probability of the different classes is returned and
not just the chosen class. The advantages of obtaining such an output are various and
include
1. the possibility of evaluating intermediate classes (e.g when the probability of two
classes is similar)
2. the possibility of implementing a reject option when classification is not confident
enough
3. the possibility of changing the class-assignment rule without learning the classi-
fier from scratch (e.g. including additional criteria such as a cost or risk function)
The possibility of implementing a reject option is particularly well suited for a medical
setting where everything which cannot be classified with a certain level of confidence
should be marked as suspicious.
Secondly, GPs implement a fully Bayesian approach to inference and hence the learn-
ing process is not affected by the risk of over-fitting.
Finally, GPs have the ability to perform automatic relevance determination. In other
words, during the training phase they can learn in a principled way which of the input
variables are relevant for classification and which are not. Given the short time avail-
able for experiments this feature was of great help.
The code used for implementing the GP is the one supplied with [43].

Chapter 5. Automatic Classification System 58
Figure 5.1: Features obtained through topographic Independent Component Analysis.
White areas correspond to positive coefficients, black areas to negative ones. Areas in
middle-grey represent coefficients equal to zero.
5.2 Experiments and Evaluation
In order to evaluate the performance of the proposed system, an experimental frame-
work has been set up.
As pointed out in section 4.2.2, only the first level of the hierarchical visual classes
seems to be reliable enough with the available data. For this reason, the classifier
was trained to reproduce the first two visual classes, while learning the other levels of
the hierarchy has been postponed in order to wait for more data. The classes will be
henceforth referred to as the flat and non-flat Basal Cell Carcinomas (BCCs), referring
respectively to cluster 1 and 2 presented in section 4.2.2.
Given the limited amount of images classified by people, it was decided to keep 10
images for each class as a training set and use the rest as an independent test set. This
approach resulted in having only one image as a test case for the flat BCCs, but keep-
ing less than 10 training examples for each class would have been inappropriate to get
reliable results.
The feature extraction stage was trained running tICA on 10,000 square patches of

Chapter 5. Automatic Classification System 59
Lesion True Class P(flat) P(non-flat)D670a flat 0.8917 0.1083
D232a non-flat 0.1779 0.8221
D254 non-flat 0.1849 0.8151
D472 non-flat 0.9436 0.0564
D489 non-flat 0.7747 0.2253
D642 non-flat 0.2274 0.7726
P102 non-flat 0.4545 0.5455
P140a non-flat 0.4545 0.5455
P469a non-flat 0.4542 0.5458
P72 non-flat 0.6536 0.3464
Table 5.1: Results obtained on the image test set. True Class represents the visual
class the lesion belongs to, P(flat) and P(non-flat) the probabilities assigned to the two
classes by the Gaussian process
side 40 pixels. The patches were extracted from 200× 200 pixels images containing
unsegmented skin lesions, sampling with higher probability the central area where the
lesions were located. The original colour images where converted in CIELAB colour-
space [47] and only the L plane was kept. A total of 256 independent components
were required, generating a topographic structure corresponding to a 16×16 grid with
neighbourhoods being 5× 5 squares. The second layer was implemented to pool the
output of feature detectors laying in 4×4 partially overlapping squares. The obtained
first-layer features are shown in Figure 5.1.
As for the classification stage, two training scenarios have been tested providing the
GP with different inputs:
1. the square of the activation of the feature detectors s′2 (256 variables)
2. the pooling of the activation of neighbouring detectors s′′ (64 variables)
which respectively represent the output of the first and second layer of the features ex-
traction stage. The reason behind the squaring in option 1 has to be found in statistical
considerations regarding the tICA model, full details can be found in [25].
As mentioned in section 5.1.1, two different formulas have been used to compute the
output of the feature detectors. As it turned out, the formulation based on the total
activation of the detector on the whole image (s′i = ∑Tj=1 w′ip j) made it impossible to
the GP to learn anything. While the theoretical reasons behind this are not clear, the

Chapter 5. Automatic Classification System 60
(a) D472 (b) D489 (c) P72
(d) P102 (e) P140a (f) P469a
Figure 5.2: Wrong assignments to the flat BCC class (upper row) and low-confidence
correct assignments to the non-flat BCC class (lower row).
only possible conclusion is that these features are not enough informative to learn to
perform classification. As a result, the GP assigns a 0.5 probability to each of the
classes for every presented input. The same lack of learning occurred when using the
alternative formulation (s′i = max j(wTi p j)) and feeding the GP with the 256-variable
vector. When using this latter formulation and passing to the GP the output of the
second layer (64-variable vector), on the other hand, learning took place. The results
obtained on the test set by the trained system are presented in table 5.1. If we consider
a classification confident only when the probability of one class is over 55%, table 5.1
reports 3 errors and 3 low-confidence correct cases. To facilitate the interpretation of
the results these 6 lesions are shown in Figure 5.2.
As pointed out before, the test set is far from being ideal. Given its extreme unbal-
anced presence of flat and non-flat cases, for example, it is impossible to evaluate
accurately the performance of classification for flat BCCs. Some general conclusions
can be drawn nonetheless.
Despite the limited amount of training samples, the system managed to obtain reason-
able results for the non-flat BCCs. If we ignore the concept of low-confidence answers,
as it would happen for non-probabilistic classifiers, only 3 out of 9 non-flat lesions

Chapter 5. Automatic Classification System 61
were misclassified. Interestingly, by verifying their position in the layout obtained by
Multi-Dimensional Scaling (see Figure 4.10 for a clear display) it is easy to note that
these three lesions (D472, D489 and P72) are very close to one another. Such a near-
ness means that people have indeed considered them similar as the system apparently
did. Furthermore, by visual inspection of Figure 5.2(b), several traits typical of the flat
BCC class can be found in D489. This could partially justify the misclassification.
5.3 Discussion
In this chapter the classification system developed to replicate the visual classes of
Basal Cell Carcinomas created by human observers has been presented. Even though
it would not be fair to claim success on the basis of results obtained on such a limited
amount of test data, the outcomes seem to be promising. As more data will be col-
lected, the size of the visual classes will grow and a more thorough data analysis will
be possible. Given the obtained results, though, the fact that 7 out of the 10 test cases
were correctly classified suggests that the system is not performing merely random
classification and possibly learned some relevant trait of the visual classes. Whether
only the non-flat class or both of them were satisfactorily learned is, at the moment,
impossible to evaluate. Interestingly, the misclassified lesions happen to have high
similarity according to human observers, suggesting that the system is indeed able to
find some of the criteria guiding the visual similarity assessment. Whether this is true
or the situation is due to peculiarities of the training and test sets will be the subject for
further research.

Chapter 6
Conclusions
The aims of this dissertation were trying to get a better understanding about how peo-
ple assess skin lesions and exploring new ways of using this perceptual information to
develop better classification systems. In order to do so, the entire project was divided
in three successive stages. In the first one, the ability of observers to evaluate given
properties of skin-lesion images has been assessed. The second stage tested how well
people could group skin lesions only considering their visual similarity. In this phase
no definition of similarity was provided and hence the observers were forced to look
for common traits in the different images. Starting from people’s evaluations, classes
of visually similar lesions were derived. This allowed to assess both the ability of
people to identify commonalities between skin-lesion images and the stability of these
similarity criteria across different observers. The last phase consisted in developing an
automatic system capable of learning the similarity criteria followed by people while
defining the visually homogeneous groups.
During the first phase evidence emerged supporting the hypothesis that people cannot
effectively evaluate properties of skin-lesion images despite being given fixed visual
references. These results put under serious questioning dermatological guidelines like
the ABCD rule which assume a substantial uniformity in the way people evaluate spe-
cific characteristics of the lesions. While analysing the data, furthermore, the emer-
gence of correlation patterns between different properties suggested that automatic
classifiers should not be based on the ABCD rule.
The results obtained in the second part of the project showed that when evaluating skin
lesions as a whole (i.e. not according to single properties) observers can effectively as-
sess their visual similarity even when no specific definition of similarity is given. The
high inter-observer homogeneity of the assessment suggests that guidelines based on
62

Chapter 6. Conclusions 63
visual samples might provide better results in the classification of skin lesions, espe-
cially when the task is performed by laypeople. At the time of writing, reliable results
have been obtained for only 30 of the 115 Basal Cell Carcinomas whose images are
available. Once additional feedback is obtained from the users it will be possible to
gain a more complete insight into the similarity assessment process. An interesting
topic for future research will certainly be unravelling the hierarchy of criteria followed
by observers when evaluating visual similarity of skin lesions. The first step has been
moved in this dissertation showing the importance of vertical prominence, but further
research is required for the following hierarchical levels.
Overall, the first two phases of the dissertation were successful and previously un-
reported conclusion have been drawn. Far from providing a full understanding of a
complex task like visual similarity assessment of skin lesions, this dissertation surely
provided new results offering a good starting point for future work.
In the last phase of the project, the findings regarding visual classes have been em-
ployed in the development of an automatic classification system designed to repli-
cate the similarity criteria followed by people. The system was designed to learn ev-
erything from the data, including the features used to characterise the skin lesions.
This approach was aimed at avoiding any bias which could have been introduced by
human-crafted descriptors. No system trying to classify skin-lesions according to vi-
sual classes defined through perceptual experiments has been proposed before, and the
one presented in this thesis represents the first attempt to explore this field. Due to
the limited amount of data available at the time of writing, though, a thorough evalua-
tion of the classification performance was impossible. The results are anyway looking
promising and new test data are expected to come available in the near future. In its
current configuration the proposed system does not take into account any information
regarding colour and 3D structure. As these two aspects are of utmost importance in
the humans’ visual system, future research should be addressed to integrate them into
the classifier. In particular, integration of depth information is expected to have a con-
siderable impact on the classification performance since the most important similarity
criterion emerging from Multi-Dimensional Scaling results, which seems to be vertical
prominence, can be fully captured only through the use of 3D data.
In conclusion, this dissertation answered most of the questions it was founded on and
reported new results which could possibly act as a stem for future research.

Bibliography
[1] 2005 IPAM graduate summer school: Intelligent extrac-tion of information from graphs and high dimensional data.http://www.ipam.ucla.edu/schedule.aspx?pc=gss2005, Accessed on 14/08/2010.
[2] http://homepages.inf.ed.ac.uk/rbf/dermofit/. Accessed on 16/08/2010.
[3] http://www.ggobi.org. Accessed on 22/08/2010.
[4] http://www.skincarephysicians.com/skincancernet/melanoma.html. Accessed on16/08/2010.
[5] http://www.vision.caltech.edu/image datasets/caltech101/. Accessed on22/08/2010.
[6] R. B. Aldridge, R. Fisher, L. Ballerini, K. Robertson, Y. Bisset, and J. L. Rees.Do laypersons have intrinsic pattern recognition abilities that could be harnessedto allow the accurate and early diagnosis of skin cancers? British Journal ofDermatology, 162(4):949–950, 2010.
[7] G. Argenziano, G. Fabbrocini, P. Carli, V. de Giorgi, E. Sammarco, andM. Delfino. Epiluminescence microscopy for the diagnosis of doubtfulmelanocytic skin lesions: comparison of the abcd rule of dermatoscopy anda new 7-point checklist based on pattern analysis. Archives of Dermatology,134(12):1563–1570, December 1998.
[8] L. Ballerini, X. Li, R. B. Fisher, and J. Rees. A query-by-example content-based image retrieval system of non-melanoma skin lesions. In Proceedings ofMICCAI-09 Workshop MCBR CBS 2009, volume 5853 of LNCS, pages 10–17,2009.
[9] M. S. Bartlett. Properties of sufficiency and statistical tests. In Proceedings ofthe Royal Statistical Society, volume 160 of A, pages 268–282, 1937.
[10] Y. Bengio. Learning deep architectures for AI. Foundations and Trends in Ma-chine Learning, 2(1):1–127, 2009.
[11] I. Borg and P. Groenen. Modern Multidimensional Scaling: theory and applica-tions. Springer-Verlag, New York, second edition, 2005.
[12] I. Brace. Questionnaire Design. Kogan Page, second edition, 2008.
[13] R. Brandstrom, M. Hedblad, I. Krakau, and H. Ullen. Laypersons’ perceptualdiscrimination of pigmented skin lesions. Journal of the American Academy ofDermatology, 46(5):667–673, May 2002.
[14] M. B. Brown and A. B. Forsythe. Robust tests for equality of variances. Journalof the American Statistical Association, 69:364–367, 1974.
64

Bibliography 65
[15] G. Capdehourat, A. Corez, A. Bazzano, and P. Muse. Pigmented skin lesions clas-sification using dermatoscopic images. In CIARP 2009, volume 5856 of LNCS,pages 537–544, 2009.
[16] M. E. Celebi, H. Iyatomi, G. Schaefer, and W. V. Stoecker. Lesion border de-tection in dermoscopy images. Computerized Medical Imaging and Graphics,33:148–153, 2009.
[17] M. E. Celebi, H. A. Kingravi, B. Uddin, H. Iyatomi, Y. A. Aslandogan, W. V.Stoecker, and R. H. Moss. A methodological approach to the classification ofdermoscopy images. Computerized Medical Imaging and Graphics, 31:362–373,2007.
[18] M. A. Chaudhry, R. Ashraf, M. N. Jafri, and M. Akbar. Computer aided diag-nosis of skin carcinomas based on textural characteristics. In Proceedings of theInternational Conference on Machine Vision, pages 125–128. IEEE, 2007.
[19] F. Chung. Spectral Graph Theory, volume 92 of CBMS Regional ConferenceSeries in Mathematics. Conference Board of the Mathematical Sciences, Wash-ington, 1997.
[20] D. A. Clausi. An analysis of co-occurrence texture statistics as a function of greylevel quantization. Canadian Journal of Remote Sensing, 28(1):45–62, 2002.
[21] K. Clawson, P. Morrow, B. Scotney, J. McKenna, and O. Dolan. Analysis ofpigmented skin lesion border irregularity using the harmonic wavelet transform.In Proceedings of the 13th International Machine Vision and Image ProcessingConference, pages 18–23. IEEE, 2009.
[22] G. W. Corder and D. I. Foreman. Nonparametric Statistics for non-statisticians.John Wiley and Sons, 2009.
[23] R. J. Friedman, D. S. Rigel, and A. W. Kopf. Early detection of malignantmelanoma: the role of physicians examination and self examination of the skin.CA Cancer Journal for Clinicians, 35:130–151, 1985.
[24] S. Gunasti, M. K. Mulayim, B. Fettahlioglu, A. Yucel, R. Burgut, Y. Sertdemir,and V. L. Aksungur. Interrater agreement in rating of pigmented skin lesions forborder irregularity. Melanoma research, 18:284–288, 2008.
[25] A. Hyvarinen, J. Hurri, and P. O. Hoyer. Natural Image Statistics. Springer-Verlag, 2009.
[26] K. Kavukcuoglu, M. A. Ranzato, R. Fergus, and Y. LeCun. Learning invariantfeatures through topographic filter maps. In Proceedings of the InternationalConference on Computer Vision and Pattern Recognition (CVPR’09). IEEE,2009.
[27] N. Laskaris. Fuzzy description of skin lesion images. Master’s thesis, School ofInformatics – University of Edinburgh, 2009.
[28] Y. LeCun, S. Chopra, R. Hadsell, M. A. Ranzato, and F. J. Huang. A tutorialon energy-based learning. In G. Bakir, T. Hofman, B. Scholkopf, A. Smola, andB. Taskar, editors, Predicting Structured Data. MIT Press, 2006.

Bibliography 66
[29] Y. LeCun, F. J. Huang, and L. Bottou. Learning methods for generic objectrecognition with invariance to pose and lighting. In roceedings of the Inter-national Conference on Computer Vision and Pattern Recognition (CVPR’04).IEEE Press, 2004.
[30] H. Levene. Robust tests for equality of variances. In I. Olkin, editor, Contri-butions to probability and statistics: essays in honor of Harold Hotelling, pages278–292. Stanford University Press, Stanford, CA, 1960.
[31] M. Li, G. Anzhe, Z. Shaofang, and X. Weidong. Irregularity and asymmetry anal-ysis of skin lesions based on multi-scale local fractal distributions. In Proceedingsof the 2nd International Congress on Image and Signal Processing, pages 1–5.IEEE, 2009.
[32] X. Li, B. Aldridge, L. Ballerini, B. Fisher, and J. Rees. Depth data improvesskin lesion segmentation. In Proceedings of the 12th International Conferenceon Medical Image Computing and Computer-Assisted Intervention, volume 5762of LNCS, pages 1100–1107, 2009.
[33] I. Maglogiannis and C. N. Doukas. Overview of advanced computer vision sys-tems for skin lesions characterization. IEEE Transactions on Information Tech-nology in Biomedicine, 13(5):721–733, September 2009.
[34] S. McDonagh, R. B. Fisher, and J. Rees. Using 3d information for classifica-tion of non-melanoma skin lesions. In Proc. Medical Image Understanding andAnalysis, pages 164–168, Dundee, 2008.
[35] C. S. Mendoza, C. Serrano, and B. Acha. Scale invariant descriptors in patternanalysis of melanocytic lesions. In Proceedings of the 16th IEEE InternationalConference on Image Processing, pages 4193–4196, 2009.
[36] M. Messadi, A. Bessaid, and A. Taleb-Ahmed. Extraction of specific parametersfor skin tumour classification. Journal of Medical Engineering and Technology,33(4):288–295, 2009.
[37] L. J. Meyer, M. Piepkorn, D. E. Goldgar, C. M. Lewis, L. A. Cannon-Albright,J. J. Zone, and M. H. Skolnick. Interobserver concordance in discriminating clin-ical atypia of melanocytic nevi, and correlations with histologic atypia. Journalof the American Academy of Dermatology, 34(4):618–625, April 1996.
[38] A. Mojsilovic, J. Kovacevic, J. Hu, R. J. Sarfranek, and S. K. Ganapathy. Match-ing and retrieval based on vocabulary and grammar of color patterns. IEEE Trans-actions on Image Processing, 9(1):38–54, January 2000.
[39] J. Mutch and D. G. Lowe. Object class recognition and localization using sparsefeatures with limited receptive fields. International Journal of Computer Vision,80(1):45–57, October 2008.
[40] F. Nachbar, W. Stolz, T. Merkle, A. B. Cognetta, T. Vogt, M. Landthaler, P. Bilek,O. Braun-Falco, and G. Plewig. The ABCD rule of dermatoscopy. Journal of theAmerican Academy of Dermatology, 30:551–559, 1994.
[41] A. Y. Ng, M. I. Jordan, and Y. Weiss. On spectral clustering: analysis and analgorithm. In T. Dietterich, S. Becker, and Z. Ghahramani, editors, Advances inNeural Information Processing Systems 14, pages 849–856. MIT Press, 2002.

Bibliography 67
[42] S. M. Rajpara, A. P. Botello, J. Townend, and A. D. Ormerod. Systematic reviewof dermoscopy and digital dermoscopy/artificial intelligence for the diagnosis ofmelanoma. British Journal of Dermatology, 161:591–604, 2009.
[43] C.E. Rasmussen and C.K.I Williams. Gaussian Processes for Machine Learning.MIT Press, 2006.
[44] K. Reetz Muller, R. Rangel Bonamigo, T. Antoniolli Crestani, G. Chiaradia, andM. C. Widholzer Rey. Evaluation of patients’ learning about the abcd rule: arandomized study in southern brazil. Anais Brasileiros de Dermatologia, 84(6),November/December 2009.
[45] J. L. Rodgers and W. A. Nicewander. Thirteen ways to look at the correlationcoefficient. The American Statistician, 42(1):59–66, February 1988.
[46] B. E. Rogowitz, T. Frese, J. R. Smith, C. A. Bouman, and E. Kalin. Perceptualimage similarity experiments. In B. E. Rogowitz and Pappas T. N., editors, Hu-man Vision and Electronic Imaging III, Proceedings of the SPIE, 3299, San Jose,CA, January 1998.
[47] J. Schanda, editor. Colorimetry: understanding the CIE system. Wiley-Interscience, 2007.
[48] C. Serrano and B. Acha. Pattern analysis of dermoscopic images based on markovrandom fields. Pattern Recognition, 42:1052–1057, 2009.
[49] T. Serre, L. Wolf, S. Bileschi, M. Riesenhuber, and T. Poggio. Robust objectrecognition with cortex-like mechanisms. IEEE Transactions on Pattern Analysisand Machine Intelligence, 29(3):411–426, 2007.
[50] A. She, Y. Liu, and A. Damatoa. Combination of features from skin pattern andabcd analysis for lesion classification. Skin Research and Technology, 13(1):25–33, February 2007.
[51] H. Steinhaus. Sur la division des corp materiels en parties. Bull. Acad. Polon.Sci, 1:801–804, 1956.
[52] K. Tabatabaie, A. Estek, and P. Toossi. Extraction of skin lesion texture fea-tures based on independent component analysis. Skin Research and Technology,15:433–439, 2009.
[53] U. von Luxburg. A tutorial on spectral clustering. Statistics and Computing,17(4):394–416, December 2007.
[54] B. L. Welch. The generalization of student’s problem when several differentpopulation variances are involved. Biometrika, 34(1–2):28–35, 1947.