Embed Size (px)
Citation preview

Joe Bruneau, General MillsJustin Murray, Technical Marketing, VMware
VIRT1400BU
#VMworld #VIRT1400BU
Real-World Customer Architecture for Big Data on VMware vSphere
VMworld 2017 Content: Not fo
r publication or distri
bution

• This presentation may contain product features that are currently under development.
• This overview of new technology represents no commitment from VMware to deliver these features in any generally available product.
• Features are subject to change, and must not be included in contracts, purchase orders, or sales agreements of any kind.
• Technical feasibility and market demand will affect final delivery.
• Pricing and packaging for any new technologies or features discussed or presented have not been determined.
Disclaimer
2#VIRT1400BU CONFIDENTIAL
VMworld 2017 Content: Not fo
r publication or distri
bution

Agenda
#VIRT1400BU CONFIDENTIAL 3
1 Introductions
2 Why Enterprises are Deploying Big Data on vSphere, and how
3 Reference Architectures – an Overview
4 Introduction to General Mills
5 Architecture Details from the General Mills Hadoop Deployment
6 Experiences in Deployment – hurdles and how to overcome them
7 Best Practices - discovered along the way
8 Lessons Learned
9 Future Work
10 Conclusions
VMworld 2017 Content: Not fo
r publication or distri
bution

Our Roles
• Joe is a Systems Administrator at General Mills and has worked with VMware for over a decade. He started out deploying VDI and Lab Manager and then on to virtualizing servers with the Windows team. After that he joined the enterprise infrastructure team to build the VMware landscape for the SAP migration from HPUX super domes to RHEL, implementing SRM and introducing Fault Tolerance. Joe also supports the fibre channel infrastructure and works on backup and DR.
• Justin is a senior Technical Marketing architect at VMware. He works closely with the company’s customers and partners to help them deploy big data and analytics applications systems on VMware vSphere. He writes best practice documents and other material on these subjects and has spoken in public events on these technical topics.
#VIRT1400BU CONFIDENTIAL 4
VMworld 2017 Content: Not fo
r publication or distri
bution

Why are Enterprises Deploying Big Data?
• They want to get off existing costly data platforms (for OLAP rather than OLTP)
• Older data warehouse technology is not serving their needs
• Want to do queries and analytics against many different forms of data (structured, unstructured, streaming, images, clickstream)
• Provide data access to their own customers – with analytic tools (e.g. VMware telemetry data)
• Integrate systems that have been islands till now
– Single source of truth for the enterprise
• Exploit new application architectures for developer productivity
• Want to do data science, machine learning, deep learning to predict their customer behaviors or detect fraud at time of occurrence (as examples)
#VIRT1400BU CONFIDENTIAL 5
VMworld 2017 Content: Not fo
r publication or distri
bution

Use Cases: Virtualization of Big Data
• Enterprises have development, test, pre-prod staging and production clusters that are required to be separated from each other and provisioned independently
• Organizations need different versions of Hadoop/Spark/machine learning platforms to be available to different teams - with possibly different services available (e.g. HBase, MapReduce, Spark)
• Enterprises do not wish to dedicate a specific set of hardware to each different requirement above, and want to reduce overall costs
• IT wants to provide Hadoop clusters as a service on-demand for its end users
#VIRT1400BU CONFIDENTIAL 6
VMworld 2017 Content: Not fo
r publication or distri
bution
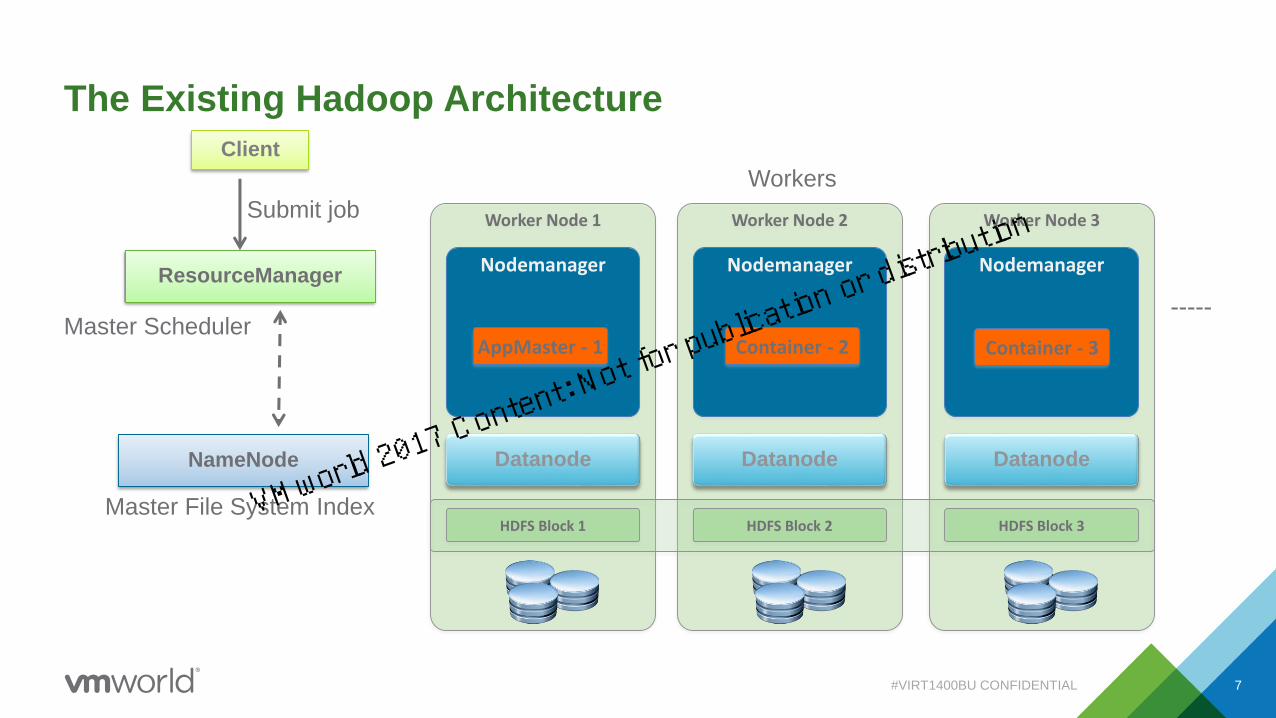
Worker Node 1 Worker Node 2 Worker Node 3
The Existing Hadoop Architecture
ResourceManager
Client
Datanode
Nodemanager
AppMaster - 1
Nodemanager Nodemanager
Datanode Datanode
HDFS Block 1 HDFS Block 2 HDFS Block 3
Container - 2 Container - 3
Master File System Index
NameNode
Submit job
Workers
Master Scheduler
#VIRT1400BU CONFIDENTIAL 7
VMworld 2017 Content: Not fo
r publication or distri
bution

Hadoop – in Virtual Machines
Worker Node 1 Worker Node 2 Worker Node 3
Input File
ResourceManagerJob
Datanode
Nodemanager
AppMaster - 1
Nodemanager Nodemanager
Datanode Datanode
HDFS Block 1 HDFS Block 2 HDFS Block 3
Container - 2 Container - 3
Namenode
Master Scheduler
Master File System Index
A virtual machineKey: #VIRT1400BU CONFIDENTIAL 8
VMworld 2017 Content: Not fo
r publication or distri
bution
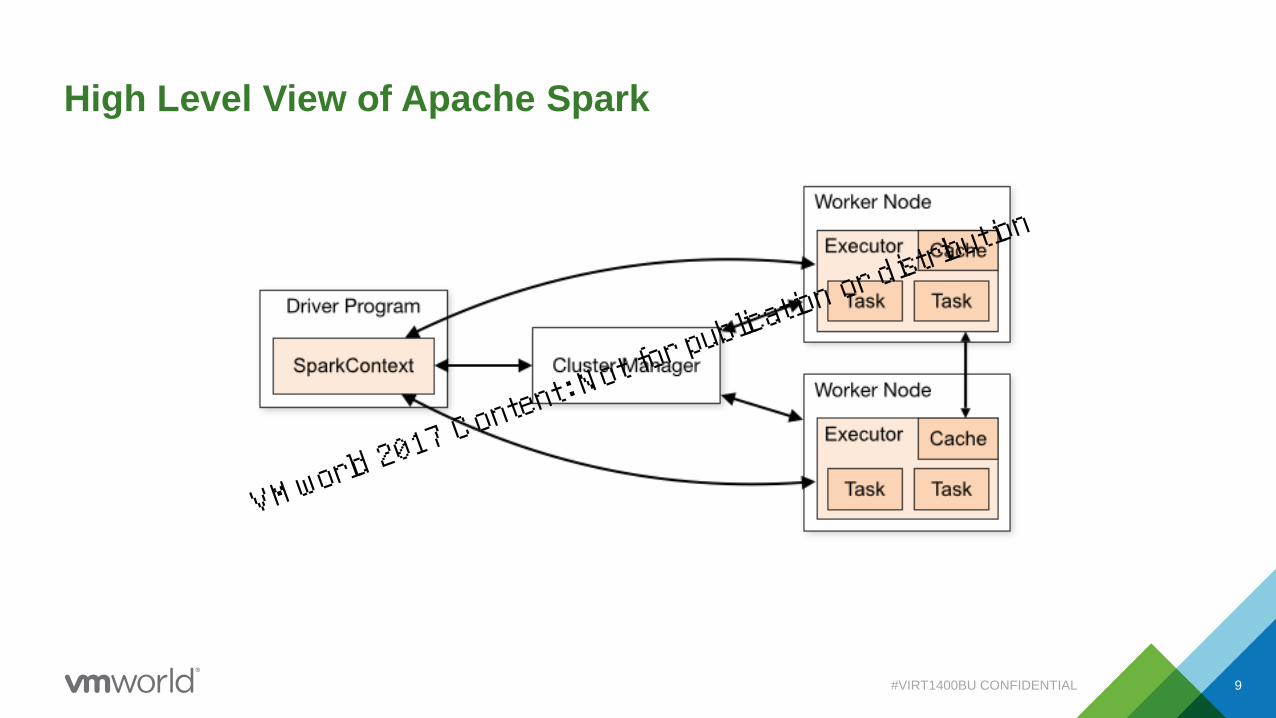
High Level View of Apache Spark
#VIRT1400BU CONFIDENTIAL 9
VMworld 2017 Content: Not fo
r publication or distri
bution

Deployment on vSphere –Proven Architectures
VMworld 2017 Content: Not fo
r publication or distri
bution
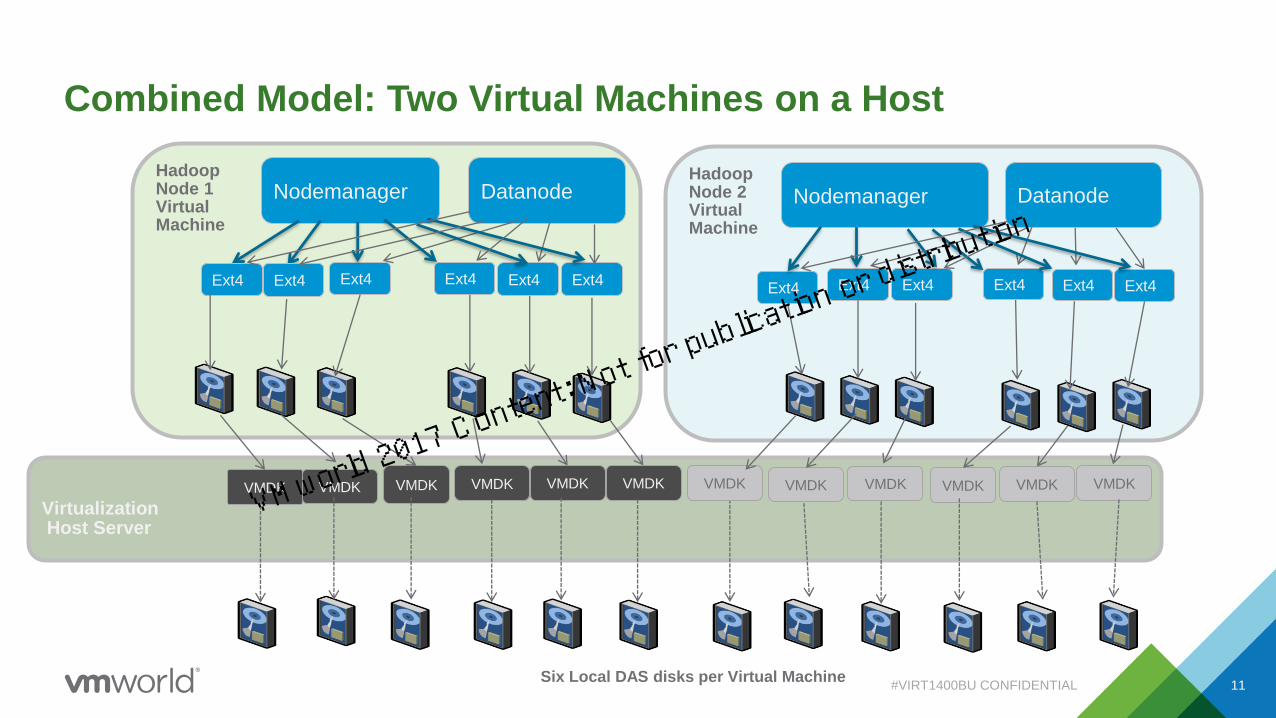
VirtualizationHost Server
VMDK
HadoopNode 1Virtual Machine
Datanode
Ext4
Nodemanager
Ext4 Ext4 Ext4
Six Local DAS disks per Virtual Machine
VMDK VMDK VMDK VMDK VMDK VMDK VMDK
HadoopNode 2VirtualMachine
Datanode
Ext4
Nodemanager
Ext4 Ext4 Ext4Ext4
VMDKVMDK VMDKVMDK
Ext4Ext4Ext4
Combined Model: Two Virtual Machines on a Host
#VIRT1400BU CONFIDENTIAL 11
VMworld 2017 Content: Not fo
r publication or distri
bution

#1 Reference Architecture from Cloudera
#VIRT1400BU CONFIDENTIAL 12
VMworld 2017 Content: Not fo
r publication or distri
bution

Data/Compute Separation (with External Access to HDFS)
HadoopVirtualNode 2
NN
NN
NN
NN
NN
NN
data
no
de
Isilon
VirtualizationHost
VMDKOS Image –
VMDKOS Image –
VMDK VMDK
VMDK
HadoopVirtualNode 1
Ext4
ResourceManager
Ext4
Temp
OS Image –
VMDK
Ext4
NodeManager
Ext4
HadoopVirtualNode 3
Ext4
NodeManager
Ext4
Temp
HDFS requests
#VIRT1400BU CONFIDENTIAL 13
VMworld 2017 Content: Not fo
r publication or distri
bution

Key Requirements for Big Data Architecture
• Performance
• Scaling
– to dozens or hundreds of nodes (VMs)
• Robustness – distributed file system, no one process is a single point of failure
• High Availability
• Fault Tolerance
• Capable of handling new workloads with new compute demands
#VIRT1400BU CONFIDENTIAL 14
VMworld 2017 Content: Not fo
r publication or distri
bution

A Customer Journey: General MillsJoe Bruneau
VMworld 2017 Content: Not fo
r publication or distri
bution

General Mills
• 1886 started as a flour mill on the banks of the Mississippi river as the Washburn Crosby Company
• 1928 General Mills is formed and starts trading on NYSE
• Acquired Pillsbury 2001
• Over 100 locations internationally, 39,000 employees, 165 on Fortune 500
• Brands
– Betty Crocker, Bisquick, Cheerios, Chex, Fiber One, Hamburger Helper, Nature Valley, Pillsbury, Yoplait, Gardettos, Gold Medal Flour, Haagen-Dazs, Old El Paso, Progresso, Cascadian Farms, Larabar, Muir Glen, Epic Provisions, Totinos,
#VIRT1400BU CONFIDENTIAL 16
VMworld 2017 Content: Not fo
r publication or distri
bution

Big Data / Connected Data at General Mills
• Started looking at big data 2½ years ago
• Marketing and Global Consumer Insights
• Understanding Consumer Trends
• Understanding the impact of marketing and promotions on retail sales
• Attended Virtualizing Big Data sessions VMworld 2015
• Worked with our TAM to set up a meeting with Justin
#VIRT1400BU CONFIDENTIAL 17
VMworld 2017 Content: Not fo
r publication or distri
bution

Server Landscape
Physical Landscape
• 30 node production cluster
• 700TB
Virtual Landscape
• 15 physical ( 30 VM's)
• 60 TB
#VIRT1400BU CONFIDENTIAL 18
VMworld 2017 Content: Not fo
r publication or distri
bution
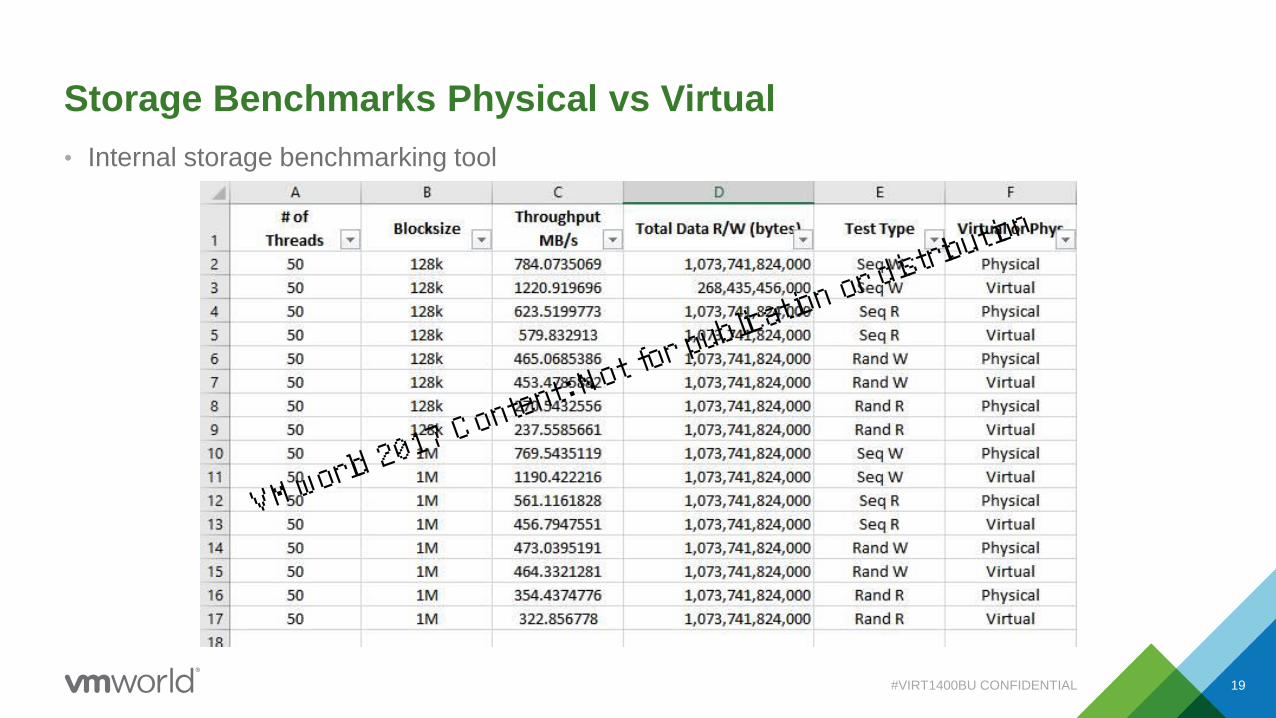
Storage Benchmarks Physical vs Virtual
• Internal storage benchmarking tool
#VIRT1400BU CONFIDENTIAL 19
VMworld 2017 Content: Not fo
r publication or distri
bution

TeraGen Benchmarking
#VIRT1400BU CONFIDENTIAL 20
VMworld 2017 Content: Not fo
r publication or distri
bution

TeraSort Benchmarking
#VIRT1400BU CONFIDENTIAL 21
VMworld 2017 Content: Not fo
r publication or distri
bution

Hadoop on vSphere
#VIRT1400BU CONFIDENTIAL 22
VMworld 2017 Content: Not fo
r publication or distri
bution

CPU, Memory & Disk Configuration
23#VIRT1400BU CONFIDENTIAL
VMworld 2017 Content: Not fo
r publication or distri
bution

24#VIRT1400BU CONFIDENTIAL
VMworld 2017 Content: Not fo
r publication or distri
bution
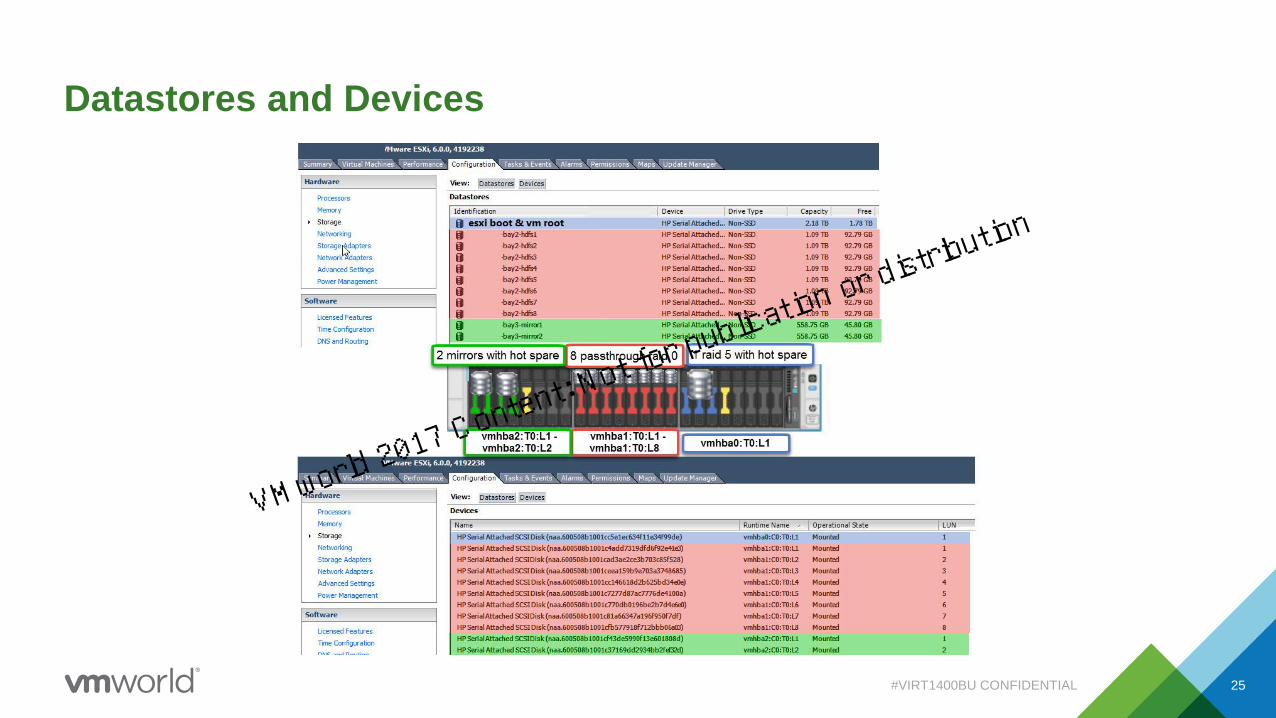
Datastores and Devices
25#VIRT1400BU CONFIDENTIAL
VMworld 2017 Content: Not fo
r publication or distri
bution

Applications
• Impala for interactive analysis using tools like Tableau
• Hive & Spark for batch processing
• Limited Machine Learning using python and R
#VIRT1400BU CONFIDENTIAL 26
VMworld 2017 Content: Not fo
r publication or distri
bution

Business Applications That Hadoop is Used For
• Data sources are across the enterprise, from master data to transactional data, web activity analytics, supply chain, IoT, manufacturing analytics, consumer sentiment.
• We see the data lake as an enabler for enterprise wide analytics
#VIRT1400BU CONFIDENTIAL 27
VMworld 2017 Content: Not fo
r publication or distri
bution

General Mills Big Data
• Cloudera Hadoop
• Tableau
• SAP BW on HANA
• SAP Data Services
• Data catalog / Data quality tools
#VIRT1400BU CONFIDENTIAL 28
VMworld 2017 Content: Not fo
r publication or distri
bution

Cloudera
• Superior management tools
• Cloudera Navigator
#VIRT1400BU CONFIDENTIAL 29
VMworld 2017 Content: Not fo
r publication or distri
bution

Initial Build
• Once the engineering technical specs were worked out and the hardware configured it took less than a day to build the VM infrastructure because we leveraged our existing VM deployment process
• It took about a year to configure and implement everything as we were working with a 3rd party vendor as part of the solution
#VIRT1400BU CONFIDENTIAL 30
VMworld 2017 Content: Not fo
r publication or distri
bution

Key Factors
• Cost
• Performance
• Using a hardware raid controller instead of a software raid controller
• Leverage existing virtual machine provisioning and deployment process
• Improve drive failure detection
• Ability to implement hot spare hard drives
#VIRT1400BU CONFIDENTIAL 31
VMworld 2017 Content: Not fo
r publication or distri
bution

Best Practices
• Use a hardware raid controller
• Stick to NUMA boundaries
• Proper memory size of VM's
• Don't over allocate
• Good documentation for the Hadoop admins (where VM's are located)
#VIRT1400BU CONFIDENTIAL 32
VMworld 2017 Content: Not fo
r publication or distri
bution

How Would You Do it Differently, If at All, Today?
• Develop automation to deploy and map VM's to specific Hadoop hardware configurations
• Had time permitted, I would have spent more time researching hardware options to simplify deployment and create a Hadoop as a Service infrastructure platform.
#VIRT1400BU CONFIDENTIAL 33
VMworld 2017 Content: Not fo
r publication or distri
bution

What Does the Business Gain or Hope to Gain from the Big Data Systems? Who Are the End Users of This System?
• The business has a broader “connected data” strategy and Hadoop is the foundation for the strategy
• Business Analysts
• Automated Systems
#VIRT1400BU CONFIDENTIAL 34
VMworld 2017 Content: Not fo
r publication or distri
bution

Future Plans
What plans are there to expand the cluster(s) in the future?
• Build as needed
How are the business needs/requests handled to increase the functionality of the system?
• Through the connected data steering team
Any new technologies that you are interested in using?
• nVME storage with virtual hadoop
• Investigate HP Synergy platform
#VIRT1400BU CONFIDENTIAL 35
VMworld 2017 Content: Not fo
r publication or distri
bution

How Does the Company Think about Big Data in the Private and Public Clouds as Cooperating with or Replacing Each Other?
• Long term we see the two working together in a hybrid way
• Public cloud will help us
– Google advanced analytics capabilities
– Amazon cloud only analytics capabilities
#VIRT1400BU CONFIDENTIAL 36
VMworld 2017 Content: Not fo
r publication or distri
bution

Introducing vSphere Scale-Out for Big Data and HPC Workloads
37
• Hypervisor, vMotion, vShield Endpoint, Storage vMotion, Storage APIs, Distributed Switch, I/O Controls & SR-IOV, Host Profiles / Auto Deploy and more
Features
• Sold in Packs of 8 CPU at a cost-effective price pointPackaging
• EULA enforced for use w/ Big Data/HPC workloads onlyLicensing
New package that provides all the core features required for scale-out workloads at an attractive price point
VMworld 2017 Content: Not fo
r publication or distri
bution

Conclusions
• Virtualized Big Data is in production today at customers sites such as those of General Mills
• Big Data requires some best practices at both the business level and the technical level
• VMware can help you on this journey
http://www.vmware.com/big-data
38#VIRT1400BU CONFIDENTIAL
VMworld 2017 Content: Not fo
r publication or distri
bution

VMworld 2017 Content: Not fo
r publication or distri
bution

VMworld 2017 Content: Not fo
r publication or distri
bution





























