Embed Size (px)
Citation preview

UStore: A Distributed Storage With Rich Semantics
Anh Dinh1, Ji Wang1, Sheng Wang1, Gang Chen2, Wei-Ngan Chin1, Qian Lin1, Beng Chin Ooi1,Pingcheng Ruan1, Kian-Lee Tan1, Zhongle Xie1, Hao Zhang1, and Meihui Zhang3
1National University of Singapore2Zhejiang University
3Singapore University of Technology and Design
AbstractToday’s storage systems expose abstractions which areeither too low-level (e.g., key-value store, raw-blockstore) that they require developers to re-invent thewheels, or too high-level (e.g., relational databases, Git)that they lack generality to support many classes of ap-plications. In this work, we propose and implement ageneral distributed data storage system, called UStore,which has rich semantics. UStore delivers three keyproperties, namely immutability, sharing and security,which unify and add values to many classes of today’sapplications, and which also open the door for new ap-plications. By keeping the core properties within thestorage, UStore helps reduce application development ef-forts while offering high performance at hand. The stor-age embraces current hardware trends as key enablers.It is built around a data-structure similar to that of Git,a popular source code versioning system, but it alsosynthesizes many designs from distributed systems anddatabases. Our current implementation of UStore hasbetter performance than general in-memory key-valuestorage systems, especially for version scan operations.We port and evaluate four applications on top of US-tore: a Git-like application, a collaborative data scienceapplication, a transaction management application, anda blockchain application. We demonstrate that UStoreenables faster development and the UStore-backed ap-plications can have better performance than the existingimplementations.
Keywords: Versioning, Branching, Collaborative Ana-lytics, Blockchain
1 Introduction
Application developers today can choose from a vastarray of distributed storage systems. As storage costsare going down drastically, storage systems differentiate
themselves by the levels of abstractions offered to the ap-plications. At one extreme, key-value stores such as Dy-namo [25], Voldemort [7], Redis [8], Hyperdex [28] pro-vide simple interface to build highly available and scal-able applications. However, many systems have morecomplex data models than simple key-value records, forinstance social graphs or images, such that to implementthem on top of a key-value storage requires re-buildingcomplex software stacks and therefore risks re-inventingthe wheel. At the other extreme, relational databasesare highly optimized, but enforce strict relational datamodels which limit the range of applications, and theACID guarantees limit their scalability. Currently, wesee a shift towards more structured storage systems, forexamples, TAO [16], MongoDB [6], PNUTS [20], Log-Base [68], which offer more scalability, but their datamodels are specific to the given domain, therefore theydo not generalize well to other domains. Amid thesechoices, we ask the question whether there is still a gap tobe filled by another storage system, and if there is, whatwould be the right level of abstraction?
We observe that many recent distributed applicationsshare three core properties. First, data immutability, inwhich data never changes and any update results in a newversion, is being exploited to build popular version con-trol systems like Git [3]. Immutability also plays a keyrole in many data intensive systems [33] wherein it helpssimplify the design for fault tolerance and replication.MapReduce [23] and Dyrad [36], for instance, split com-putation tasks into smaller units each taking immutableinput and storing immutable output to HDFS or GFS.Immutability in these settings make it easy to handlefailures by simply restarting the units without complexcoordination. Second, data sharing is the key propertyin the growing number of social network and collabora-tive applications, driven by the growth of user-generateddata and the need for collaborative analytics [52]. Earlypeer-to-peer content sharing systems [39, 19] are beingreplaced by more centralized alternatives [15] with dif-
1
arX
iv:1
702.
0279
9v1
[cs
.DB
] 9
Feb
201
7

ferent data models and collaborative workflows. For ex-ample, DataHub [15] exposes a dataset model with infre-quent updates, whereas GoogleDocs assumes text doc-uments and real-time updates. Third, data security isbecoming increasingly important due to data breachesarising from insider threats (NSA, Target, Sony hack,for example), and due to the vulnerability of third-partycloud providers to attacks. For confidentiality protec-tion, systems such as CryptDb [56] and M2R [26] en-able database and big-data analytics tasks to be per-formed over encrypted data, by employing novel encryp-tion schemes and trusted hardwares. Blockchain systemslike Bitcoin [50], Ethereum [30] and Hyperledger [35]ensure integrity of the data stored on a shared ledger evenunder Byzantine failures.
Given these trends, we argue that there are clear ben-efits in unifying data immutability, sharing and securityin a single storage system. By focusing on optimizingthese properties in the storage, one immediate value isto reduce development efforts for new applications thatneed any combination of these properties, as they areprovided out of the box. In addition, existing applica-tions can be ported to the new storage, thereby achievingall three properties at the same time and with better per-formance.
In this paper, we propose a new distributed storagesystem, called UStore, that accomplishes the followinggoals. First, it has rich semantics: the storage supportsdata immutability, sharing and security. Second, it isflexible: performance trade-offs can be tuned, and it canbe easily extended to accommodate new hardware or ap-plication’s needs. Third, it is efficient and scalable: itoffers high throughput and low latency, and it can scaleout to many servers. Existing systems fall shorts at ac-complishing all three goals at the same time. For in-stance, temporal databases [40] or HDFS provide onlyimmutability, whereas P2P systems [19] focus mainlyon sharing. Git [3] and Datahub [15] implement bothimmutability and sharing, but forgo security. Further-more, Git is designed for P2P environment, thus it islimited in efficiency [9]. Datahub is restricted to rela-tional data models (hence, it is inflexible) and has notbeen shown to scale to multiple servers. Several systemslike SPORC [29] and Bitcoin [50] support all three prop-erties, but they are not general and efficient enough forother applications beside collaborative text editing andcrypto-currency.
UStore’s data model is based on a novel data struc-ture called UObject, which is identified by a unique keyand its content is a direct acyclic graph of UNode objects.Each UNode in the graph is identified by a unique ver-sion, its value contains the data, and connections betweenthem represent derivation relation between different ver-sions of the data. An update to UObject creates a new
version in the graph, and the complete version historycan be traced by following the backward pointers. This issimilar to the commit history in Git, but unlike Git, US-tore partitions and replicates UNode objects over multiplenodes for better read and write performance. UStore’spartitioning scheme is locality-aware, in the sense thatrelated versions are likely to be grouped together in thesame node. Together with caching, and native supportfor Remote Direct Memory Access (RMDA), UStore candeliver high performance on operations that scan histori-cal versions. UStore supports non-realtime collaborativeworkflows by providing a publish/subscribe channel withwhich users can be notified when there are new versionsof the objects of interest. It guarantees integrity of boththe data and version history against untrusted providersby using tamper-evident version numbers which are sim-ilar to hash pointers in blockchains. Furthermore, it al-lows for flexible and fine-grained sharing policies basedon the entire UObject or a set of UNode objects. UStoreprovides a number of parameters for tuning performancetrade-offs between the access operations, storage capac-ity and overall availability guarantees. Finally, UStoresupports push-down semantics by allowing user-definedlogics for data compression, and for detecting and merg-ing of data conflicts.
We implement four applications on top of the cur-rent in-memory implementation of UStore. The first ap-plication is an extension of Git for distributed settings,in which multiple users collaborate on a single repos-itory. Another application implements the relationaldata model and data science workflows as supported inDatahub [15]. The third application is a transactionmanagement protocol based on TARDiS [21] that sup-ports weak consistency with branch-and-merge seman-tics. Finally, we implement a simple private blockchainapplication based on Ethereum [30] which supports an-alytical queries on the blockchain data. Each applica-tion is implemented in fewer than 1300 lines of code,demonstrating that UStore enables fast application de-velopment. We then benchmark UStore’s performanceindividually, and evaluate the four applications againstsystems that support the same operations. The resultsshow that UStore’s performance is comparable to Redisin basic read/write operations, and is better than Redis inscanning operations. The Git-like application achievesup to 3 orders of magnitude lower latency than Git inversioning operations (commit and checkout). The col-laborative data science application achieves up to 10xlower latency than Decibel [45] in 3 out of 4 popularqueries. The transaction management application re-duces the number of states accessed by 2 orders of mag-nitudes compared to TARDiS. The blockchain applica-tion outperforms Ethereum by 2 orders of magnitudes in4 out of 5 queries.
2

In summary, in this paper we make the following con-tributions:
• We identify common trends in today’s distributedapplications and argue for the need of a distributedstorage targeting a large classes of existing andemerging applications.
• We design and implement UStore, a flexible, effi-cient and scalable distributed storage with three coreproperties: data immutability, sharing and security.
• We benchmark UStore against Redis, showing com-parable performance for basic operations and sig-nificant improvement for scan operations. We im-plement four applications on top of UStore, namelyGit, collaborative data science, transaction manage-ment and blockchain. We evaluate them against sys-tems supporting the same operations, and demon-strate that UStore improve the applications’ perfor-mance while reducing development efforts.
In the next section, we motivate UStore by discussingthe trends in distributed applications and the challengesfaced by these systems. We present the detailed designin Section 3, and describe our implementation of fourapplications in Section 4. We report the performance ofUStore and of its applications in Section 5. We discussUStore’s current states and future work in Section 6, be-fore concluding in Section 7.
2 Related Work and Motivations
In this section, we discuss several trends in distributedsystems that underpin many interesting applications, in-cluding version control, data versioning, collaborationand security-aware applications, and related work. Ta-ble 1 lists research and open source systems along threecommon properties: immutability, sharing and security.We then review new hardware capabilities that are keyenablers for next-generation distributed systems.
2.1 ImmutabilityGit [3] is a widely used open-source distributed versioncontrol system (DVCS), which outperforms other VCS(such as Subversion, CVS, Perforce) due to its uniquefeatures like cheap local branching, convenient stagingareas, and multiple workflows. Fundamental to Git’s de-sign is data immutability, that is, all changes commit-ted to Git are permanently archived in version histories.Viewed as an append-only key-value store, Git allowsefficient tracking of the entire version history. Further-more, it is easy in Git to compare, merge and resolveconflicts over branches. Git can automatically resolve
System Immutability Sharing SecurityGFS/HDFS [31] XRDD [69] XDatomic [22] XLogBase [68] XBittorent [19] XDropbox [2] XTahoe LAFS [10] X XDatahub [15] X XGit [3] X XIrmin [5] X XNoms [12] X XPachyderm [54] X XOri [47] X XSUNDR [43] X X XBitcoin [50] X X XEthereum [30] X X X
UStore X X X
Table 1: Systems built around data immutability, sharing andsecurity.
many conflicts arising from source code versioning, andonly notifies users for conflicts it cannot resolve. Git en-ables offline collaboration models in decentralized, P2Psettings in which each user has a complete copy of therepository.
Beside Git, we observe immutability in many otherdata-oriented applications. In particular, massively par-allel systems such as MapReduce and Dryad are basedon immutable inputs stored in HDFS or GFS, whichgreatly simplifies failure handling by restarting the failedtasks. Similarly, Spark [69] is based on Resilient Dis-tributed Datasets (RDDs) abstraction, which are indeedimmutable datasets tracking the operation history. Otherexamples of immutability include LSM-like data stor-ages such as HBase [1], in which immutability enablessuperior write throughput for ingesting updates whilesimplifying failure recovery.
One particular manifestation of immutability in datamanagement systems is data versioning, which has beenemployed for tolerating failures, errors and intrusions,and for analysis of data modification history. Ele-phantFS [62] is one of the first file systems with built-in multi-version support. Later systems like S4 [66],CVFS [64], RepareStore [71] and OceanStore [39],improve the early design by maintaining all versionsin full scope and upon each update operation. Mostof these systems use journal/log-structure file system(e.g., SpriteLFS [58]) as the underlying storage, becausethey leverage the latter’s high performance in append-only workloads. In databases, data versioning tech-niques are used for transactional data access. Post-gres [65], for example, achieved performance compa-rable to other database systems without versioning sup-
3

port. Fastrek [18] enhanced Postgres with intrusion tol-erance by maintaining an inter-transaction dependencygraph based on the versioned data, and relying on thegraph to resolve data access conflicts.
2.2 Sharing and CollaborationThe exponential growth of data can be attributed to thegrowth in user-generated, machine-generated data andthe need to log and collect data for future analytics. Be-fore the data can be meaningfully used, the owners mustbe able to share their data among each other and amongdifferent systems. Past [59] and Bittorrent [19], for ex-amples, are optimized for object discovery, durability,availability and network bandwidth. Data sharing amongusers is fundamental to recent social network platforms,for which many techniques have been developed to opti-mize both throughput and latency [14].
Efficient data sharing makes it possible to implementvarious collaboration models. Unlike classic multi-user,time-sharing systems like databases which give a userthe illusion of owning the entire system, collaborativesystems explicitly provide different views to differentusers, and synchronization between different views aredirectly observed and controlled by the users. Most col-laborative systems expose file system interface where aset of files can be mounted locally from a remote server.Dropbox, NFS and CIFS, for example, assume central-ized servers, whereas Git [3], IPFS [4], Ori [47] workin decentralized settings. These systems employ light-weight synchronization techniques such as versioningand content-addressable files in order to minimize syn-chronization cost. They can be characterized by theirsupported workflows: from infrequent updates (versioncontrol systems like Git), frequent updates (shared filesystems like Dropbox), to real-time updates (documentediting systems like GoogleDocs). Recent systems suchas DataHub [15] exposes a dataset interface to supportcollaborative big-data workloads. Datahub targets sci-entific domains wherein multiple users and teams per-form data-intensive computations on shared data [52],for which existing databases or version control systemsare inadequate.
2.3 SecurityThere is an inherent threat from moving data into thehand of untrusted parties, i.e. cloud providers. Re-cent high-profile data breaches and system attacks (NSA,Target, Sony hack, for examples) further demonstratethe challenges in protecting data from insider threats.Protecting data confidentiality can be readily imple-mented on existing cloud storage systems, by simplyencrypting the data. However, there is a need to per-
form computation on the encrypted data, for which sys-tems like CryptDb [56] employ homomorphic encryptionschemes. In order to support a rich set of database opera-tions, these systems make strong assumptions on the dataand security model, which may not hold in practice [51].Recent systems, namely Haven[13] and M2R [26], relyon trusted hardware to deliver high security guarantee forgeneral computations using small trusted code base.
In a collaborative setting with an untrusted provider,integrity protection refers to the ability to detect forks.Specifically, the provider can present different sequencesof updates to the shared state to different users, therebyforking multiple views. SUNDR [43] is the first sys-tem to provide fork-consistent file systems, meaning thatif the server presents two users with different views,these users can either never see each other’s view, orthey can detect that there is a fork. Later works, suchas Venus [63] and Depot [46] extended SUNDR to im-prove performance and conflict resolutions. In the de-centralized setting where peers distrust each other, re-cent blockchain systems achieve integrity for a globaldata structure resembling a ledger [50, 30, 35]. In thesesystems, users reach agreement via distributed consen-sus protocols which can tolerate certain numbers of ma-licious adversaries. In public blockchain systems, inwhich peers can freely join and leave, the consensusprotocol is based on proof-of-work which gives eachuser a probability of updating the blockchain propor-tional to his computing power. Recent proposals of pri-vate blockchains can achieve better performance by us-ing cheaper consensus protocols such as PBFT [17].
2.4 Hardware Trend
The increased availability of large memory has given riseto in-memory computing [67, 70], from general comput-ing frameworks like Spark [69], to databases like Hy-Per [38] and SAP HANA [40], or data storage systemslike RAMCloud [60] and Redis [61]. In-memory sys-tems deliver low latency and thus can be used for real-time analytics.
Beside memory, new hardware primitives such asNon-uniform Memory Access (NUMA) [44], Hard-ware Transactional Memory (HTM) [42], Remote Di-rect Memory Access (RDMA) networking [37], Non-Volatile memory (NVM) [24], etc. offer new oppor-tunities to improve system performance by leveragingthe hardware. However, changes in hardware oftenrequire re-examining the existing designs in order tofully exploit the hardware benefits. For example, Hy-Per [41] proposes a new query evaluation frameworkto overcome overheads with non-NUMA-aware data ac-cess. Pilaf [48], HERD [37], and FaRM [27] proposeenhancement to existing key-value storage and transac-
4

Access Control
content-based
Consistency
merge semantics
Transaction Management
Private Blockchain Git Collaborative
AnalyticsApplications
APIs
Physical
Admin BAdmin A
View
Representation
Put(key, base_version, value) → versionGet(key, version) → valueGetPrevious(key, version) → {values}
Notification
pub/sub
Data Security
confidentiality, integrity
Figure 1: UStore stack consists of multiple layers. The datarepresentation layer constitutes the narrow waist.
tional systems to fully exploit RDMAs. New trustedcomputing capabilities such as the new Intel SGX arebeing employed by privacy-preserving systems such asHaven [13], M2R [26] to significantly reduce overheadof computing on encrypted data.
3 UStore Design
In this section, we present the detailed design of UStore.The system follows a layered design, with the narrowwaist being the core abstraction called UObject. Wefirst discuss the high level design goals, and then describehow we achieve them at different layers of the system.
3.1 OverviewInspired by the software and hardware trends discussedin the previous section, we design UStore with threehigh-level goals.
G1: Rich semantics. UStore provides data im-mutability, data sharing, and data security out of thebox. Once data is inserted, it remains unchanged. Thedata can be shared among applications and users in fine-grained manner. Finally, integrity of the data and ofthe update history are protected against untrusted cloudproviders.
G2: Flexibility. UStore APIs give its applicationsfreedom to configure and combine the immutability,sharing and security properties. It also allows user topush down application semantics via a number of well-defined interfaces.
G3: Efficiency & scalability. UStore delivers highthroughput, low latency for its data access operations,and it can scale out to many nodes.
Figure 1 shows multiple layers of UStore’s stack. Atthe bottom, the physical layer is responsible for stor-
ing, distributing and replicating data over many servers.We consider settings in which servers belong to a num-ber of independent administrative domains, i.e. they aremutually distrustful. The next layer contains UStore’score data structure which bears some similarity to Git’s.In particular, it implements immutability with supportfor branching and merging. UStore differentiates fromGit in the structure and operational semantics of eachdata value. The distinction to Git becomes more appar-ent at the next two layers. The APIs layer exposes ac-cess operations which are specific to a version of data.The view layer adds fine-grained access control, security,customizable consistency model and a notification ser-vice. Finally, applications such as transaction manage-ment, blockchains, data science collaboration, etc. canexploit UStore’s rich semantics by building directly onthe APIs and the views from the lower layers.
The Git-like data structure embedded at the secondlayer makes up the narrow waist of the design. In otherwords, UStore enforces a single representation and un-changed semantics of this data structure, but allows fordifferent implementations of the physical, view and ap-plication layers. By fixing the representation, UStorecan accommodate innovations at the physical layer andchanges in application requirements. This layered de-sign achieves the three goals as follows. First, G1 is re-alized by the data representation and view layer. Second,flexibility (G2) is achieved by exposing parameters andapplication hooks at the physical layers for specifyingconstraints on resources, on distribution and replicationstrategies. In addition, UStore lets the applications over-write the consistency view to implement their own mod-els. Third, UStore’s high performance (G3) comes fromthe careful use of the available hardware at the physicallayer.
3.2 Abstraction and APIs
UStore is based on a novel abstraction, called UObject,for reading and writing data. Each UObject managesall data related to a specific key and supports retrieval ofexisting values and tracking of version history.
3.2.1 UObject
A UObject is identified by a unique key, and comprisesa directed acyclic graph (DAG), as shown in Figure 2.Each node in this graph, called UNode, contains a pairof data: a unique version number and the correspond-ing value of that key, as shown in Figure 3. The con-nections between UNodes represents derivation relationsamong different versions of the data. In other words, aUObject contains all historical information of a key. Itsconcrete data structure is as follows:
5

v2v1
v3v4
v5
v6
v7v8
v9
Figure 2: UObject data structure.
U-Node 𝑣𝑗U-Node 𝑣𝑖
𝑣𝑖 . ℎ
𝑣𝑖 . 𝑙
𝑣𝑖 . 𝑛
value𝑖
𝑣𝑗 . 𝑛
value𝑗
𝑣𝑗 . 𝑙=𝑣𝑖 . 𝑙 + 1
𝑣𝑗 . ℎ=H(𝑣𝑖 . ℎ, 𝑣𝑗 . 𝑙, value𝑗)
Figure 3: UNode data structure.
struct UObject {
string key
collection<UNode> versions
}
struct UNode {
version_t version;
string value;
version_t prev_1, prev_2;
}
struct version_t {
string h;
int l;
string n;
}
We have no restrictions on how each version can beextended. That is, a version can be extended multipletimes, leading to independent branches, for example v2is extended to v5,v7 in Figure 2. Correspondingly, diver-gent branches can be combined (or merged), for exam-ple v2 and v4 are merged into v5. This abstraction canbe viewed as an extension of key-value, in which the ap-plication can treat each update as a (key, version, value)tuple, and retrieve existing values via composite keys.
3.2.2 Versions
In UStore, version numbers not only serve as uniqueidentifier of UNode objects, they also play a key role insecurity and load balancing. More specifically, UStoreensures three properties of version numbers:
1. Unique: UNode objects have distinct version num-bers.
2. Verifiable: Version numbers can be used to proveintegrity of the retrieved objects.
3. Locality-aware load balancing: UNode objectscan be partitioned over multiple nodes, and objectsof the same branch have high probabilities to bestored in the same node.
Essentially, a UStore version is a 3-field tuple:
v = (v.h,v.l,v.n)
where v.h is the cryptographic hash tied to the object con-tent, v.l is the depth (from root of the DAG), and v.n is arandom value generated by a storage server. The rootversion is defined as vNULL = (NULL, NULL, NULL).We explain how UStore achieves its three properties laterin this section.
3.2.3 APIs
To write a new value to a key, the application needs tospecify the base version from which the new value is de-rived. Optionally, it can specify whether it wants to com-press the value, which we discuss later in Section 3.3.1.
Put(key, base version, value, compress)
→ version
When receiving the request, UStore creates a UNode ob-ject for the value and connects to the base object. Anew version number is returned so that the applicationcan retrieve this value later. The most important advan-tage of this operation is high throughput, as no requestsare blocked or aborted. Since requests with the samebase version will result in multiple branches, no locksare required and thus many requests can be served at thesame time.
To retrieve a value, the application supplies both a keyand a version number in order to identify the unique dataversion.
Get(key, version)→ value
UStore first locates the target UObject based on thekey, then it returns the corresponding UNode value forthe given version. Note that this operation is also non-blocking, as existing versions are immutable and avail-able for reading all the time. UStore provides no APIsfor getting all the latest versions of a key, i.e., the ver-sions without any successors. This is our design choiceto minimize the overhead incurred by consistency mech-anisms when there are concurrent updates. Nevertheless,
6

we provide an option for the application to receive noti-fications of updates via a publish/subscribe channel.
To merge two branches, we rely on the applications tospecify merge semantics (discussed later), and only passthe consequent merged value to the storage.
Merge(key, version 1, version 2, merged value)
→ version
UStore handles this operation similarly to a Put opera-tion, but creating two connections to the two base UNodeobjects. Data immutability is not affected by Merge,since the operation creates a new version for the mergedvalue.
To track previous versions or values of a given UNode,the application can invoke:
GetPreviousVersion/Value(key, version)
→{versions/values}
which returns a single version/value of the current UNodeas derived from a put operation, or two versions/values ifit is derived from a merge operation. For example, inFigure 2, given v8, this operation returns v7, and given v5it returns {v2,v4}. When receiving this request, UStorefirst locates the current UNode using the given version,then follows the backward connections to fetch the pre-vious objects. By invoking this operation repeatedly, theapplication can trace the full history of the UObject.
To avoid calling GetPreviousVersion/Value manytimes, the application can use a batch operation that re-trieves up to m previous UNodes.
GetKPreviousVersion/Value(key, version, m)
→{versions/values}
UStore first locates the current UNode object, then re-cursively fetches the previous object, stopping when oneof two following conditions occurs: when it reachesm hops away from the original requested object, orwhen it encounters a merged object. When the oper-ation returns m objects with versions 〈v1,v2, ..,vm〉, itmeans that vi is the predecessor of vi−1, v1 is the pre-decessor of version, and there are no branches in be-tween. When it returns m′ < m objects, it means thereis a branch at vm′ . Using this information, the ap-plication can determine which branch to follow next.For example, GetKPreviousVersion(k,v8,3) returns〈v7,v2,v1〉, whereas GetKPreviousVersion(k,v9,3)returns 〈v6,v5〉.
3.3 Physical LayerWe now describe how UStore implements the abstractionabove at the physical layer. Our current design assumesall data is kept in memory, and support for migration tosecondary storages is part of future work.
3.3.1 UObject storage and indexing
There are two strategies to materialize UObject’s con-tent: complete or incremental. In the former, UNode ob-jects are stored in their entirety. In the latter, each ob-ject contains only the compressed data (e.g, the delta,which is the diff with its previous version), thus sig-nificantly reducing the storage consumption for a largeUObject. However, there is a trade-off between the stor-age consumption and computation cost to reconstruct theobjects. Thus, for the incremental strategy, in order toavoid traversing a long path to get a complete value, US-tore allows the application to specify whether it wantsto compress or not at each step. In addition, the applica-tion can register its specific compress() and decompress()functions based on their own data characteristics, whichwill be used by UStore during the compression and de-compression processes. As a result, UStore is flexibleenough to achieve a variety of compression strategies.In UStore, the value is compressed based on its previ-ous versions only if its previous version is local and isuncompressed. Otherwise, it will be based on its near-est uncompressed ancestor within the same node. Thelocality-aware partitioning scheme (discuss later), makesit highly possible that the previous version is located inthe same node. We do not choose to compress the databased on a compressed one, because this will increaseboth the compression and de-compression cost.
As a UNode is uniquely identified by its key and ver-sion, we adopt a simple hash-based indexing to quicklylocate the object with O(1) complexity. The Put(k,vp,o)generates a new UNode version number as follows:
v = (v.h,v.l,v.n) = (H(k||vp.h||vp.l||o),vp.l+1,η) (1)
where H is a cryptographic hash function and η a ran-dom value generated by the storage node. The versiongenerated by Merge(k,v1,v2,o) is similar, except thatv.l = max(v1.l,v2.l) + 1. This means a merged objectwill be on the longest branch of its two ancestors, for ex-ample in Figure 2, v5.l = 3. H ensures that version num-bers are verifiable because both the content and link tothe previous version are used to compute v.h. It also en-sures uniqueness: for any two inserts v1← Put(k,vp,o),v2← Put(k′,v′p,o
′) such that (k,vp,o) 6= (k′,v′p,o′), then
v1 6= v2.
3.3.2 Locality-aware partitioning
UObject granularities and volumes may vary consider-ably, for instance from large numbers of small objects asin a database application, to small numbers of large ob-jects as in a Git-like application. In order to scale out tomany nodes, we need to distribute UObjects evenly tomultiple storage nodes, which can be achieved by hash-ing the key. The challenge, however, is in partitioning
7

a single, large UObject to multiple nodes, as shown inFigure 2.
One approach to achieve load balancing is to distributeUNode objects based on their versions using consistenthashing. Specifically, a version v is first hashed to iden-tify the storage node, then it is used to index into thenode’s local hash table. However, this approach failsto preserve locality: if v2 is derived from v1, the prob-ability of both being in the same node is the same asthat of any two random versions. Figure 2 shows an ex-ample of locality-preserving partitioning schemes whichdistributes related objects together onto the same node.Note that locality hashing schemes are not useful in ourcase, because the way we compute version numbers us-ing a cryptographic hash function (Eq. 1) destroys therelationship between two related versions. Instead, US-tore achieves this property by generating versions usingadditional inputs from the storage nodes.
For each UObject, each server reserves a memoryregion t for storing its UNodes. The application canadjust t dynamically to better suit its storage require-ments1. For a write request, i.e. Put(k,vp,o) wherevp = (vp.h,vp.l,vp.n), the application uses (k||vp.n) tolocate a storage node S via consistent hashing, and routesthe request to S. The node S handles the request as fol-lows:
• If its reserved memory region for the UObject
is not full, it stores the object and returns aSUCCESS status, together with a new version v =(H(k||vp.h||vp.l||o),vp.l +1,vp.n).
• When the reserved region is full, it generates a ran-dom value η such that (k||η) maps to a differentregion in the consistent hashing space. It returns aREDIRECT status and η to the application.
When the application receives a REDIRECT, it repeats thewrite request, but using (k||η) for consistent hashing, un-til it gets a SUCCESS response. The application can askthe server to increase t after a pre-defined number of redi-rected request. In one extreme, for example, the applica-tion may want to ensure all the write operations wherevp = vNULL (root versions of top-level branches) resultin the data being stored in the same node. In this case,when REDIRECT is returned, it asks the server to increaset immediately instead of following the redirection.
This protocol ensures object locality, because an writeoperation based on version vp implies the new object hasderivation relation with vp, and its first priority of stor-age node is the same as that of vp. Only when the nodeexhausts its capacity is the object spilled over to anothernode. Unlike the common load-balancing approach indistributed hash tables which uses redirection pointers,
1via an out-of-band protocol
coordinator
node 1 node 2 node 3
client coordinator
node 1 node 2 node 3
client
Write Workflow Read Workflow
data flowREQ / ACKno data RESP
Figure 4: Workflow of write and read request
UStore returns a new mapping in the form of η , thusfuture requests are routed directly to the new node. Inparticular, a read operation, i.e. Get(k,v), proceeds byforwarding the request to the storage node identified viaconsistent hashing of (k||v.n). The node finds the objectindexed by v and returns the object. By being able to ad-just t, the application has full control of how to balancethe workload.
3.3.3 Caching and replication
The locality afforded by UStore’s partitioning doesnot help when objects are in different nodes. Forexample, given the objects in Figure 2, the requestGetKPreviousValue(k,v5) incurs 3 network requestssent to 3 different servers. UStore provides a cachinglayer, that is each server maintains a cache of remote ob-jects fetched during scan operations. In our example, v2and v4 are cached at the same node of v5, thus the nextrequest for immediate predecessors of v5 can be returnedright away. By exploiting temporal locality of scanningoperations, the server can answer requests more quickly.The cache is simple to maintain, since there is no cachecoherence problems with immutable objects. For eachUNode object, the server caches up to 2 remote prede-cessors, because the benefit of caching diminishes withincreased number of cached predecessors.
UStore replicates UNode objects to achieve scalabilityand fault tolerance. Neighboring nodes in the consistenthashing space are replicas of each other. Replication iscontrolled by two parameters: number of replicas N anda write set size W . Figure 4 illustrates the workflow forwrite and read requests (for simplicity, we assume thatall inserts return SUCCESS). During a write operation, thePut request is sent to all the replicas in parallel, and it re-turns once there are acknowledgements from W servers.Note that W guarantees that the data is available whenthere are no more than W failures during the write op-eration. For a Get operation, the request is sent to thereplicas in turn until the requested data is returned.
It can be seen that W balances the cost of read andwrite requests: larger W increases write latency, but mayreduce read latency with high probability. On the otherhand, larger W means less availability for write oper-ations which only succeed when there are fewer than
8

(N−W ) failures, but increased availability for read, asthere are more replicas with the data. We note that thereis similarity between UStore’s replication scheme andDynamo’s [25] which is configurable by two parametersW and R. UStore does not require specifying R (or infact, in UStoreR = 1), because there is no read inconsis-tency in our system, thanks to the data being immutable.
3.4 View Layer
This layer enhances the immutability semantics of thelayers below with fine-grained access control, datasecurity. It increases the system’s flexibility by adding anotification service and an application hook for pushed-down merge semantics.
3.4.1 Access control and data security
UStore enables fine-grained access control at UObjectlevel, allowing users to specify policies concerning spe-cific UNode objects. The current design supports onlyread policies, and it assumes that storage servers aretrusted, that users are authenticated (Section 6 discussesthe challenges in supporting more expressive policieswith stronger trust models). By default, UObjects arereadable by all users. For a private UObjects, US-tore maintains a shadow object, called, ACUObject,with the same key. The ACUObject contains policiesof the form 〈userId, list of versions〉, indicatingwhich users can read which versions of the associatedUObject.
Only the owner of the UObject can update its corre-sponding ACUObject, using the extended Put API. TheACUObject is stored at the same server with the versionsbeing protected. When receiving a read request for somelocal versions, the server scans the local ACUObject fora policy granting access to the versions, before returningthem to the user. Each new policy results in at most NACUObjects where N is the total number of servers stor-ing the associated UObject. This overhead can be miti-gated by batching multiple policy into the same update.We also note that the number of policy updates in UStoreis smaller than in other systems with mutable states, be-cause there is no need for revocation (once read access isgranted to a version, it is considered permanent).
UStore protects integrity of both the data and of theversion history against untrusted servers. Specifically,the version number is computed via a cryptographic hashfunction over both the data content and previous versionnumber (Eq. 1), thus it is not possible for the untrustedserver to return different data (for Get operations) or dif-ferent predecessors (for GetPreviousVersion/Valueoperations). We consider two update operations with the
same data and the same base version to be duplicate,and therefore it is safe to return the same version. Forstronger guarantees, each server can also generate signa-tures for successful Put operations that can be used asproof of data storage.
3.4.2 Consistency model
Many distributed storage systems adopt the eventual con-sistency model: they allow reads to see stale values.However, reasoning about the returned value of a readis difficult in this model, because it depends on a multi-tude of factors: the concurrency model, the read-repairprotocols, etc. In UStore, there are no stale reads, sinceevery Get operation is specific to a version which is un-changed. There are only two possible outputs of a readoperation: the correct value, or an error. The error in-dicates that the version has not been propagated to thisreplica, thus the request should be retried later. This se-mantics is clean and simple, making it easy to reasonabout the system’s states and correctness. Write opera-tions in UStore are highly efficient for two reasons. First,once a UNode is written, it does not have to be sent im-mediately to other replicas. Second, concurrent writes tothe same object in UStore have no order, therefore theyrequire no locks and can be executed in parallel.
Merge semantics. Applications built on UStore mustexplicitly deal with conflicting branches caused by con-current writes. UStore supports branch reconciliation viaa function which merges two branches together. Specif-ically, the function Merge(v1,v2, fm)→ {(o),⊥} takesas input two version v1, v2 belonging to two branches, auser-defined function fm, and generates a merged valuedefined by fm (if successful). Our current design uses3-way merge strategy, although we note that there existsseveral alternatives. This merge function first finds theclosest ancestor, say v0, to both v1 and v2. v0 is wherethe two branch containing v1, v2 forked. Next, it invokesfm(v0,v1,v2) to perform 3-way merge, which returns avalue o if successful. Finally, it calls the lower-layerfunction Merge to write a new version to UStore.
We observe that different applications may follow dif-ferent logics when merging branches, and user’s inter-vention maybe needed because the conflict cannot be re-solved automatically. For example, in Ficus [57], twoversions adding two files to the same directory can bemerged by appending one file after another. In Git, ver-sions that modified two different lines can be merged byincorporating both changes, but if they modified the sameline the merge should fail. UStore allows an applicationto define its own function fm(.) and use it when initializ-ing the store. There is a number of pre-built functions inUStore, such as append, aggregation and choose-one.
9

3.4.3 Notification service
Recall that UStore does not provide APIs for retrievingthe latest UNode objects. The main reason for omittingthese APIs is to keep the storage semantics simple andclean. Under replication and failure, reasoning about thelatest version is difficult, since the APIs may return dif-ferent results for the same two requests. However, theneed to track latest versions is essential to many applica-tions, but we also note that many applications do not re-quire real-time notification, hence they are tolerant of no-tification delays. One example is the collaborative ana-lytics application in which collaborators need to be awareof each other’s updates in a timely manner, but not nec-essarily in real time, in order to avoid repeating work andcomplex conflicts.
To enable version tracking, UStore provides a notifi-cation service to which applications can subscribe. Theservice is essentially a publish/subscribe system in whichthe storage servers are the publishers and applications arethe subscribers. It maintains pairs of events and applica-tion IDs, and is responsible for routing the events to theappropriate applications. When an application wishes tobe informed of new versions of a UObject, it invokesregister(.) function with its ID and the key of inter-est. When there is an update to the UObject, the storageserver creates a new version and invokes publish(.). Theservice receives the new version and routes it to the regis-tered subscribers. Our current design uses Zookeeper forthis service, but we are adapting the design of Thialfi [11]to make the service more scalable.
4 UStore Applications
In this section, we present our implementations of fourapplications on top of UStore. They are a mix of estab-lished and emerging applications that exploit UStore’score APIs to achieve high performance while reducingdevelopment effort.
4.1 GitThere are four main types of data structures in Git: Blobwhich contains unstructured data (e.g., text or binarydata); Tree which contains references to other blobs andtrees; Commit which contains meta data for a commit,i.e., commit message, root tree reference and previouscommit reference; and Tag which contains tag name andcommit reference. These data types are managed in akey-value store as records, and object references (i.e.,keys of an object record) are explicitly recorded in thecontent. As a result, to extract references, the wholerecord has to be fetched and de-serialized. In UStore, wecan easily separate history-based references (e.g., previ-
ous commit of a commit) from content-based references(e.g., blobs in a tree) since the storage’s version track-ing naturally supports history-based references. We dis-cuss here a simple version of Git implemented in UStore,providing the same properties as the existing implemen-tation. We refer readers to the Appendix for an extensionof this design that provides richer functionalities, such asfile-level history tracking.
The original Git implementation supports content-addressable storage by identifying an object by the cryp-tographic hash of its content. In UStore, version num-bers can readily be used to uniquely identify objects.We maintain one UObject for each data type T whichthen manages all objects of that type. Fetching an ob-ject with a hash content h can be done via Get(T,h).Similarly, to commit a new version with content o, weuse Put(T,NULL,o), which returns a deterministic andunique version. Since the version number can be pre-computed, we can check if the version exists before com-mitting. Note that when writing a Commit object to US-tore, the previous version is tracked implicitly, enablingfast traversal of the commit history. Other Git com-mands, such as checkout, branch and merge can be im-plemented directly on top of these two fetch and commitprimitives.
One benefit of using UStore is the ability to separatecontent and history references, making it more efficientto implement commands like git log. Furthermore, weno longer need to fetch the whole repository to checkout a specific version, which is inefficient for reposito-ries with long histories. Another benefit comes fromUStore’s flexibility to support customized compressionfunctions which can be more effective than the defaultzlib function. Our implementation totals 289 lines ofC++ code. As a reference, the Git codebase adds up toover 1.8 million lines of C code (but it supports manymore features than our UStore based implementation).
4.2 Collaborative Data Science
It is becoming increasingly common for a large groupof scientists to work on a shared dataset but with differ-ent analysis goals [52, 15]. For example, on a dataset ofcustomer purchasing records, some scientists may focuson customer behavior analysis, some on using it to im-prove inventory management. At the same time, the datamay be continually cleaned and enhanced by other sci-entists. As the scientists simultaneously work on the dif-ferent versions or branches of the same dataset, there isa need for a storage system with versioning and branch-ing capabilities. Decibel [45] is one of such systems thatsupports relational data model. We implement an appli-cation on UStore for the same collaborative workflowssupported in Decibel.
10

Like Decibel, we provide two storage strategies forversioned relational databases, namely Tuple-First andVersion-First. In the former, we treat tuples from differ-ent tables and versions the same. Specifically, a tuple isstored as a UObject, where the key is the tuple’s primarykey and the different versions of the tuple correspondto the UNode objects. To realize the relational model,we use another type of UObject to maintain the tuples’membership to tables and versions, where the key is thetable name and version, and each UNode stores a bitmapindex to track whether a tuple is present in the versionedtable. In the Version-First strategy, tuples from one ver-sioned table are stored in a single UObject object. Wesupport large numbers of tuples by storing them withtwo-level paging. More specifically, in the first level, theUObject’s key is the table name and version, while itsvalue contains a set of keys of the second-level UObjectswhich actually store the tuples.
There are two advantages in our UStore-based imple-mentation compared to Decibel. First, UStore stores tu-ples in memory instead of on disk, thus the operations arefaster. Second, it can be scaled out easily to support largedatasets, whereas Decibel is currently restricted to a sin-gle node. Our implementation amounts to 640 lines ofC++ code (as a reference, the Decibel’s codebase addsup to over 32K lines of Java code).
4.3 Transaction Management
TARDiS [21] is a branch-and-merge approach to weaklyconsistent storage systems. It maintains a data structurecalled state DAG to keep track of the database states aswell as the availability of data versions to any transac-tion. Unlike Git which creates branches explicitly on de-mand, TARDiS generates branches implicitly upon con-flicts of data accesses. By doing so, TARDiS can keeptrack of all conflicting data accesses in branches. LikeUStore, it enables flexible conflict resolution by allowingthe high-level application to resolve the conflicts basedon its own logic.
In TARDiS, a transaction T issued by client C startsby searching the state DAG for a valid state that it canread from. A state is valid when it is both consistent andcompatible to C’s previous commits. It could be a statethat is previously created by C or whose ancestor stateis created by C. Once a read state is selected, denotedas ST , the transaction can perform read operations by re-ferring to ST . Specifically, when reading an object Or, itchecks all the versions of Or in the storage starting fromthe latest version, and greedily finds the version (identi-fied by the corresponding state which created it) that iscompatible with ST . Here, compatibility means that theversion T is reading must be in the same branch with ST .When writing an object Ow, the transaction creates a new
PrevBlock
TxnRootHash
…
AccRootHash
Transaction list
Account state list
PrevBlock
TxnRootHash
…
AccRootHash
Transaction list
Account state list
Figure 5: Blockchain data structure, transaction and accountlist are stored beyond block layer.
version of Ow based on the transaction identifier. Whencommitting, it checks whether ST is still valid. As longas ST is valid, T will eventually commit (e.g., commitafter the ST in the state DAG). Because other concurrenttransactions may not have conflicts with T in terms ofupdates, it ripples down from ST to find and commit af-ter the deepest compatible state.
The structure of state DAG in TARDiS can be mappeddirectly to UStore. In fact, we implement TARDiS inUStore by simply using UObject to store the states. Thisimplementation, referred to as TARDiS+UStore, lever-ages UStore’s efficient version scan operation to carryout backward search from the latest DAG states. Whendata accesses are skewed, there is a high probability thatdata read by a transaction is updated in a recent state.Therefore, searching for data versions by backtracking(as in TARDiS+UStore) is more efficient than by scan-ning the topologically sorted version list for each dataitem (as in TARDiS). Our implementation adds up to1068 lines of C++ code (there is no open source ver-sion of TARDiS, so we implement both systems fromscratch).
4.4 BlockchainA blockchain is a decentralized shared ledger distributedamong all participants of the system. Data immutabil-ity and transparency are two key properties that fuel therecent rise of blockchains. Figure 5 illustrates a typi-cal blockchain data structure, where the data is packedinto a block that is linked to the previous block, all theway back to the first (genesis) block, through crypto-graphic hash pointers. If the data is tampered in anyblock, all hash pointers in the subsequent blocks becomeinvalid. In a blockchain network, the participants agreeon a total order of transactions, i.e. a unique evolutionhistory of the system states. In some blockchain sys-tems, like Bitcoin [50], the blocks keep no account state(e.g., balance), but only the unspent crypto-currencies (orcoins). In other systems such as Ethereum [30], the ac-count states are stored explicitly in the blocks as shownin Figure 5.
We implement a blockchain data structure similar toEthereum using UStore, in which we maintain the ac-count states inside the blocks. There are two layers of
11

data in our design, namely a block layer and an accountlayer. In the block layer, each block contains metadata,such as the proposer of this block, the root hash of ac-count list, etc. It is stored as a UNode object whose key isthe same for every block. When we append a new block(using Put), we use the version of its preceding block asits base version. This way, UNode’s version numbers be-come the hash pointers of the blockchain. In the accountlayer, each account object, stored as a UNode, keeps trackof the account balance, where the UNode’s key is the ac-count address.
Existing blockchain systems still lack an efficient andscalable data management component, which also helpsenhance the security and robustness of the blockchain.For instance, the recent DDoS attack on Ethereum is at-tributed to inefficiency in fetching state information fromdisk. A new blockchain built on UStore can benefitdirectly from the scalability and efficiency of the stor-age. Moreover, by exploiting UStore’s versioning capa-bilities, the new blockchain system can support efficientanalytical queries which are useful for gaining insightsfrom the data in the blockchain. We implemented theblockchain logics on UStore using 1,231 lines of code inC++. As a reference, the popular Ethereum client (Geth)comprises 539,584 lines of Go code.
5 Evaluation
In this section, we report the performance of UStore andof the four applications discussed above. We first evalu-ate UStore’s data access operations (read, write and ver-sion scan) and compare them against Redis. The resultsshow that UStore achieves comparable performance withRedis for basic read and write operations. By exploitinglocality-aware partitioning, UStore achieves 40x lowerlatency than Redis for scan operations. We also examinethe performance trade-off against availability and com-pression strategies, which can be controlled by the ap-plications. Next, we evaluate four UStore-based appli-cations against systems supporting the same operations.The Git-like application improves commit and checkoutlatency by up to 240x and 4000x respectively, thanks todata being stored in memory and the simplicity of thecheckout operation. The collaborative data science ap-plication achieves up to 10x better latency in 3 out of4 queries, due to the in-memory design. The transac-tion management application reduces reduces the num-ber of states accessed by up to 80x for skewed workloadsby leveraging the efficient scan operations. Finally, forblockchain application, UStore’s datastructure matcheswell with blockchain data, and the system’s efficient dataaccess operations account for up to 400x lower latency in4 out of 5 queries.
All experiments were conducted in a 20-node,
1 2 4 8Number of clients
050
100150200250300350400450
Kops/
s
Throughput
Redis
UStore/TCP
UStore/RDMA
Figure 6: Throughput vs. Redis
1 2 4 8 16 32History size
10-1
100
101
ms
Latency
Redis
UStore-TCP
UStore-RDMA
Figure 7: Branch scan queries
RDMA-enabled cluster. Each node is equipped with aE5-1650 3.5GHz CPU, 32GB RAM, 2TB hard drive,running Ubuntu 14.04 Trusty. There are two network in-terfaces per node: one 1Gb Ethernet, and one Mellanox40Gb Infiniband.
5.1 Microbenchmark
Basic operations. We ran the YCSB benchmark tomeasure UStore’s read and write operations and com-pare them against Redis (v3.2.5 release). To supportpure key-value workloads (without versioning), we re-place UStore’s default hash function with another thatignores version numbers when locating the objects. Fig-ure 6 shows the throughput for a varying number ofclients over the workload with 50/50 read and write ra-tio, each client using 64 threads. Without RDMA, US-tore’s performance is comparable to Redis’s. With a sin-gle client, Redis achieves higher throughput, at 86K op-erations per second (Kops), than UStore does at 60 Kops.This is due coarse-grained locks implemented at US-tore clients (future optimization will likely improve thecurrent client throughput). However, with more clients,Redis server becomes saturated and UStore performsslightly better. The performance gain is due to multi-threaded implementation of UStore, as opposed to Redis’single-threaded implementation. Using RDMA, UStoreachieves much higher throughputs, which is as expectedbecause of the high bandwidth and efficient networks. Inparticular, the RDMA version requires 8 clients to sat-urate it at 430 Kops, whereas Redis is saturated by 4
12

27 28 29 210 211 212 213 214
Number of commits
10-3
10-2
10-1
100
101
102
s
Latency
GIT-1
GIT-128
UStore-1
UStore-128
Figure 8: Checkout latency in origin Git vs. in UStore. Git-Xand UStore-X mean there are X different checkout operations.
clients at 110 Kops. We note that this gap could be elim-inated when Redis includes native support for RDMA.
Scan operations. Next, we considered versionscan operations which are common in many applica-tions. Given a version v and value m, the query re-turns m predecessors of v, assuming a linear versionhistory. This is supported directly in UStore by theGetKPreviousValue/Version APIs. We implementedthis operation in Redis for comparison, in which we em-bedded the previous version number into the value of thecurrent version. Figure 7 illustrates the differences inlatency between UStore and Redis. With increasing m,Redis incurs an overhead growing linearly with m, sinceit must issue m sequential requests to the server. On theother hand, the number of requests in UStore is constantsince the server can send up to m versions back in oneresponse. Since each request involves a network round-trip, the query latency at m= 32 is much lower in UStore,at 0.4ms (and 0.07ms with RDMA), than in Redis (over3ms).
Performance trade-offs. We benchmarked UStore’svarious performance trade-offs by examining its perfor-mance with different values of W and different compres-sion strategies. We briefly explain the findings here, andrefer readers to the Appendix for the detailed results andanalysis. We observed that increasing W leads to slowerwrites, but it has no impact on read latency. Further-more, our default compression strategy outperforms arandom compression strategy, and achieves a good bal-ance in terms of throughputs and memory consumptionsas compared to a no-compression strategy.
5.2 GitWe evaluated our UStore-based Git implementation (re-ferred to as UStore) against the original Git in two data-versioning related operations, i.e. checkout and commit.We measured both implementations in terms of opera-tion latency and storage consumption. First, we gener-ated a synthetic workload containing varying numbers ofdata versions. Each version consists of a single fixed-size (32KB) file with random printable characters. For
each commit operation, we overwrite the file with con-tent of the next version, and commit it into Git or US-tore. For Git, we use a practical work-flow for commits,in which each commit is first saved into a local repository(git commit), and then pushed to a remote server (gitpush) running GitLab. For UStore, we set up one serverand have the client sending requests from a remote node.
Figure 8 shows the latency for checkout operationswith varying repository sizes (number of commits). Werefer readers to the Appendix for the results of commitoperations and of the storage cost. For single-versioncheckout operations, Git is significantly slower than US-tore (4000x), because the former requires the client tofetch the entire history even when only a single version isneeded. The checkout latency in Git also increases withlonger history, whereas UStore’s latency remains con-stant, because the latter fetches only one version. For themultiple-version checkout operations, we observe simi-lar, but smaller gap. In this case, UStore’s latency in-creases linearly with the number of checkouts becauseeach operation is independent, whereas in Git the initialcost of fetching the entire history is amortized over sub-sequent checkouts which are done locally.
To compare the cost of commit operations in UStoreand in Git, we performed one commit operation withvarying file size. We observe that UStore is up to 200xfaster than Git, mainly due to Git’s overhead when push-ing commits to the remote server. In particular, beforeconnecting to server, Git triggers object packing — atime consuming process — that compressed multiple ob-jects to save network bandwidth.
5.3 Collaborative Data Science
We evaluated Decibel against our implementation forthe collaborative workflows (referred to as UStore) on asingle-node setting, since Decibel does not support run-ning on multiple nodes. We first populated both systemswith a synthetic dataset similar to what was used in [45].The dataset consists of 832,053 tuples, each has 10 inte-ger fields with the first being the primary key. We usedthe science branching pattern, in which new brancheseither start from the head of an active branch, or fromthe head commit of the master branch. We set the pagesize in Decibel to 4MB. We considered four queries asin [45]. The first query (Q1) scans all the active tu-ples on master branch. The second query (Q2) scans allthe active tuples on the master branch but not on an an-other branch. The third query (Q3) scans all the tuplesactive on both the master and on another branch. Thefourth query (Q4) scans all the tuples active in at leastone branch. We implement these queries in UStore usingthe Version-First storage strategy.
Figure 9 compares the latency for the four queries.
13

Q1 Q2 Q3 Q4Query
100
101
102
103
104
ms
Latency
Decibel UStore
Figure 9: Comparison Between Decibel and UStore.
0 0.5 1 1.5 2 2.5Skewness
104
105
106
107
108
109
1010
# s
tate
s
Number of states accessed
TARDiS
TARDiS+UStore
Figure 10: Transaction management in TARDiS vs. UStore.
UStore outperforms Decibel for the first three queries.The performance gain is due to the fact that UStore ismemory-based, as opposed to Decibel’s disk-based stor-age backend. For example, UStore takes only 33ms toexecute Q1, while Decibel takes 328ms. However, Deci-bel is better in Q4, because it implements optimizationsbased on branch topology and with which it can avoidredundant scanning of common ancestors of differentbranches. UStore has no such optimizations and there-fore takes longer to complete a full scan. We also com-pared both systems with the Tuple-First storage strat-egy, and we observed that Decibel outperforms UStore inmost cases. This is due to another optimization in Deci-bel where it can perform sequential access by scanningtuples in a single heap file for each branch, while UStorehas to make many random accesses. We note that im-plementing these optimizations in UStore is non-trivial,hence we plan to include them as part of future work.
5.4 Transaction Management
To evaluate TARDiS+UStore against the originalTARDiS, we used workloads consistent with what de-scribed in [21]. In particular, a read-only transactionperforms 6 reads, and a read-write transaction performs3 reads and 3 writes. We considered two types ofworkloads: read-heavy which contains 75% read-onlytransactions and 25% read-write transactions, and mixedwhich contains 25% read-only transactions and 75%read-write transactions. We set the number of concur-rent clients to 1000 and generated random data accessesfollowing the Zipfian distribution. We report here the to-tal number of state accesses by the read operations. Asthe write operation is efficient in both implementations,the performance gap is determined by the efficiency of
Table 2: Ethereum performance vs. UStore on block load andaccount scan
GenesisBlock(sec)
GeneralBlock(ms)
ScanAccounts(sec)
Ethereum 622.45 19 1148.096UStore 175.516 35 167.546
read operations whose performance is proportional to thenumber of state accesses.
Figure 10 shows the results for the mixed workload(those for the read-heavy workload are similar). It canbe seen that when the skewness of data accesses is low(e.g., Zipf=0 which is equivalent to uniform distribu-tion), TARDiS outperforms TARDiS+UStore. This is asexpected, because TARDiS+UStore has to scan longerbranches to find the versions. But when the skewness ishigh (e.g., Zipf=1.5), TARDiS+UStore shows clear ad-vantages. This is because updates of frequently accesseddata can be found in recent states, therefore backtrack-ing involves small numbers of hops to locate the requiredversions. When the skewness grows even higher, the per-formance gap widens accordingly. In particular, whenZipf=2.5, the original TARDiS makes 80x more state ac-cesses than TARDiS+UStore. These results demonstratethat our UStore-based implementation achieves betterperformance when data accesses are skewed, which isa common access pattern in real-world applications.
5.5 Blockchain
We compared UStore-based blockchain implementation(referred to as UStore) against Ethereum on queries re-lated to blockchain data. We generated a syntheticdataset with 1,000,000 accounts in the genesis block,and 1,000,000 subsequent blocks containing 10 trans-actions per block on average. This dataset is consistentwith the public Ethereum data2. We deployed both US-tore and Ethereum’s Geth client on a single node, andevaluated them over five queries. The first query (genesisblock load) is to parse and load the genesis block into thestorage to initialize the system. The second query (gen-eral block load) is to load all subsequent blocks into thestorage. The third query (latest version scan) is to scanthe latest version of all the accounts. The fourth query(block scan) is to scan the content of previous blocksfrom a given block number. The fifth query (accountscan) is to scan previous balances of a given account ata given block. The last three queries represent the ana-lytical workloads anticipated in the future deployment ofprivate blockchains [49].
Table 2 summarizes the latency of the first three oper-
2https://etherscan.io/
14

1 10 100 1000Number of versions
10-1
100
101
102
103
104
105
ms
Latency
Ethereum
UStore
Figure 11: Ethereum performance vs. UStore on account levelversion scan
ations in Ethereum and in UStore. Figure 11 shows thelatency for the account scan query, in which UStore isup to 400x better (the results for block scan query aresimilar and included in the Appendix). It can be seenthat UStore outperforms Ethereum on all operations ex-cept the general block loading operation. The perfor-mance gain is attributed to three factors. One factor isthat UStore serves data from memory, and it leveragesRDMAs. Another factor is that it uses an AVL variant3
to index the accounts, which has better performance forinsertion than Ethereum’s Patricia-Merkle tree. But moreimportantly, UStore’s data structures are a better matchfor version oriented queries than Ethereum’s, and thusthe application can directly benefit from the efficient ver-sion operations provided by the storage. For instance,UStore is better for the last two queries because of theefficient version scan operation. Furthermore, for the ac-count scan query, Ethereum maintains no explicit point-ers to the previous version of an account, thus it hasto fetch and parse the content of a previous block be-fore retrieving the previous account version. This pro-cess requires reading redundant blocks and therefore in-curs more overhead. In contrast, UStore can leverage theGetKPreviousVersion/Value API to retrieve the pre-vious versions directly. Ethereum is better for generalblock load query because it imports blocks in batcheswithout verifying the content, whereas UStore importsone by one.
6 Discussion and Future Work
The current evaluation of UStore focuses only on thesystem’s core APIs. View-layer components, especiallythe access control and notification service, are still to beevaluated in isolation and as parts of the overall perfor-mance. Furthermore, the applications in UStore (exceptfor the transaction management application) were com-pared against full-fledged systems which support manyothers operations beside what were implemented in US-tore. In other words, we ported only a small number offeatures from these systems into UStore, ignoring many
3https://github.com/tendermint/go-merkle
others that may contribute to the overall performance.Adding more features to these applications are part offuture work.
Much of the future work, however, is to enhance theview layer. The current access control mechanism is re-stricted to read policies, and it assumes trusted servers.Supporting fine-grained write access is non-trivial, sincethe semantics of write access to a version needs to beformally defined, and the enforcement must be space ef-ficient. Even for read policy, it remains a challenge tocompactly represent a policy concerning multiple ver-sions, since version numbers are random. The next stepis to relax the trust assumption, for which we plan to ex-ploit trusted hardware (Intel SGX) to run the enforce-ment protocol in the trusted environment.
A view-layer module that implements more advanceddata models from the core abstraction can greatly re-duce development effort. For example, our implemen-tation of Git and collaborative applications require sev-eral levels of UObjects in which one level stores pointersto another. Such grouping of low-level UObjects intohigher-level abstractions is useful to track provenanceand changes application meta-data [34]. Most applica-tions we ported to UStore require more complex accessto the data than the current Put and Get APIs. Thus,we plan to implement a query and analytics engine asa view-layer module to support rich operations over theimmutable data. Other interesting modules that enrichthe view layer include utility modules that support au-thentication and integration with existing systems (like abig-data pipeline or a machine learning system).
The current physical layer is designed for data-centerenvironments. Extending it to non-cluster (decentral-ized) settings requires addressing two challenges: disk-based storage management (garbage collection), and datamanagement in the presence of churn. At the other end ofthe stack, we note a recent rise of big meta-data systems.As more systems are being built around interactions withhuman experts to extract contextual intelligence [53],capturing the context of such interactions is crucial forimproving the systems. Furthermore, as machine learn-ing models are becoming important for decision makingand system tuning [55], understanding their provenanceis an important step towards better interpretation of themodels. Ground [34] and Goods [32] are two meta-datasystems focusing on extracting and managing data con-text, especially data provenance. One central componentin Ground is the immutable, multi-version storage sys-tem, which the authors demonstrated that existing solu-tions fall short. UStore can be an integral part in suchsystems, and consequently serve the emerging classes ofapplications based on meta-data.
15

7 Conclusion
In this paper, we identified three properties commonlyfound in many of today’s distributed applications,namely data immutability, sharing and security. We thendesigned a flexible, efficient and scalable distributedstorage system, called UStore, which is enriched withthese properties. We demonstrated how the new storageadds values to existing systems and facilitates fasterdevelopment of new applications by implementing andbenchmarking four different applications on UStore.
Acknowledgements
This work was supported by the National Research Foun-dation, Prime Minister’s Office, Singapore under Grantnumber NRF-CRP8-2011-08.
References
[1] Apache hbase. https://hbase.apache.org.
[2] Dropbox. https://www.dropbox.com.
[3] Github. https://github.com.
[4] Interplanetary file system. https://ipfs.io.
[5] Irmin: Git-like distributed, branchable storage.https://github.com/mirage/irmin.
[6] Mongodb. http://mongodb.com.
[7] Project voldermort. http://www.
project-voldermort.com.
[8] Redis. http://redis.io.
[9] Repositories with large number of files.https://git-annex.branchable.com/
tips/Repositories_with_large_number_
of_files.
[10] Tahoe-lafs: The least-authority file store. https:
//www.tahoe-lafs.org.
[11] A. Adya, G. Cooper, D. Myers, and M. Piatek.Thialfi: a client notification service for internet-scale application. In SOSP, 2011.
[12] Attic Labs. Noms. https://github.com/
attic-labs/noms.
[13] A. Baumann, M. Peinado, and G. Hunt. Shieldingapplications from an untrusted cloud with haven. InOSDI, 2014.
[14] D. Beaver, S. Kumar, H. C. Li, J. Sobel, and P. Va-jgel. Finding a needle in haystack: Facebook’sphoto storage. In OSDI, 2010.
[15] A. Bhardwaj, S. Bhattacherjee, A. Chavan,A. Deshpande, A. J. Elmore, S. Madden, andA. Parameswaran. Datahub: Collaborative data sci-ence & dataset version mangement at scale. InCIDR, 2015.
[16] N. Bronson, Z. Amsden, G. Cabrera, P. Chakka,P. Dimov, H. Ding, J. Ferris, A. Giardullo, S. Kul-lkarni, H. Li, M. Marchukov, D. Petrov, L. Puzar,Y. J. Song, and V. Venkataramani. Tao: Face-book’s distributed data store for the social graph.In USENIX ATC, 2013.
[17] M. Castro and B. Liskov. Practical byzantine faulttolerance. In OSDI, pages 173–186. USENIX As-sociation, 1999.
[18] T.-c. Chiueh and D. Pilania. Design, imple-mentation, and evaluation of an intrusion resilientdatabase system. In ICDE, pages 1024–1035, 2005.
[19] B. Cohen. Incentives build robustness in bittorrent.In Workshop on Economics of P2P Systems, 2003.
[20] B. F. Cooper, R. Ramakrishnan, U. Srivastava,A. Silberstein, P. Bohannon, H.-A. Jacobsen,N. Puz, D. Weaver, and R. Yerneni. Pnuts: Yahoo!’shosted data serving platform. In VLDB, 2008.
[21] N. Crooks, Y. Pu, N. Estrada, T. Gupta, L. Alvisi,and A. Clement. Tardis: a branch-and-merge ap-proach to weak consistency. In SIGMOD, 2016.
[22] Datomic. Datomic: the fully transactional,cloud-ready, distributed database. https://www.
datomic.com.
[23] J. Dean and S. Ghemawat. Mapreduce: simplifieddata processing on large clusters. In OSDI, 2014.
[24] J. DeBrabant, A. Joy, A. Pavlo, M. Stonebraker,S. Zdonik, and S. R. Dulloor. A prolegomenon onoltp database systems for non-volatile memory. InADMS, pages 57–63, 2014.
[25] G. Decandia, D. Hastorun, M. Jampani, G. Kakula-pati, A. Lakshman, A. Pilchin, S. Sivasubramanian,P. Vosshall, and W. Vogels. Dynamo: Amazon’shighly available key-value store. In SOSP, 2007.
[26] T. T. A. Dinh, P. Saxena, E.-C. Chang, B. C. Ooi,and C. Zhang. M2r: Enabling stronger privacyin mapreduce computation. In USENIX Security,2015.
16

[27] A. Dragojevic, D. Narayanan, O. Hodson, andM. Castro. Farm: Fast remote memory. In NSDI’14, pages 401–414, 2014.
[28] R. Escriva, B. Wong, and E. G. Sirer. Hyperdex:A distributed, searchable key-value store. In SIG-COMM, 2012.
[29] A. J. Feldman, W. P. Zeller, M. J. Freedman, andE. W. Felten. Sporc: Group collaboration using un-trusted cloud resources. In OSDI, 2010.
[30] E. Frontier. A decentralized software platform.https://www.ethereum.org/.
[31] S. Ghemawat, H. Gobioff, and S.-T. Leung. Thegoogle file system. In SOSP, 2003.
[32] A. Halevy, F. Korn, N. F. Noy, C. Olston, N. Poly-zotis, S. Roy, and S. E. Whang. Goods: organizinggoogle’s datasets. In SIGMOD, 2016.
[33] P. Helland. Immutability changes everything. InCIDR, 2015.
[34] J. M. Hellerstein, V. Sreekanti, and et al. Ground:a data context service. In CIDR, 2017.
[35] Hyperledger. Blockchain technologies for business.https://www.hyperledger.org.
[36] M. Isard, M. Budiu, Y. Y. andAndrew Birrell, andD. Fetterly. Dryad: Distributed data-parallel pro-grams from sequential building blocks. In Eurosys,2007.
[37] A. Kalia, M. Kaminsky, and D. G. Andersen. Us-ing rdma efficiently for key-value services. In SIG-COMM ’14, pages 295–306, 2014.
[38] A. Kemper and T. Neumann. Hyper: A hybridoltp&olap main memory database system based onvirtual memory snapshots. In ICDE ’11, pages195–206, 2011.
[39] J. Kubiatowicz, D. Bindel, Y. Chen, S. Czerwin-ski, P. Eaton, D. Geels, R. Gummadi, S. Rhea,H. Weatherspoon, W. Weimer, C. Wells, andB. Zhao. Oceanstore: An architecture for global-scale persistent storage. In ASPLOS, 2000.
[40] J. Lee, Y. S. Kwon, F. Farber, M. Muehle, C. Lee,C. Bensberg, J. Y. Lee, A. H. Lee, and W. Lehner.Sap hana distributed in-memory database system:Transaction, session, and metadata management. InICDE ’13, pages 1165–1173, 2013.
[41] V. Leis, P. Boncz, A. Kemper, and T. Neumann.Morsel-driven parallelism: A numa-aware queryevaluation framework for the many-core age. InSIGMOD ’14, pages 743–754, 2014.
[42] V. Leis, A. Kemper, and T. Neumann. Exploitinghardware transactional memory in main-memorydatabases. In ICDE ’14, pages 580–591, 2014.
[43] J. Li, M. Krohn, D. Mazieres, and D. Shasha. Se-cure untrusted data repository (sundr). In OSDI,2004.
[44] L. M. Maas, T. Kissinger, D. Habich, andW. Lehner. Buzzard: A numa-aware in-memory in-dexing system. In SIGMOD ’13, pages 1285–1286,2013.
[45] M. Maddox, D. Goehring, A. J. Elmore, S. Madden,A. G. Parameswaran, and A. Deshpande. Decibel:The relational dataset branching system. PVLDB,9(9):624–635, 2016.
[46] P. Mahajan, S. Setty, S. Lee, A. Clement, L. Alvisi,M. Dahlin, and M. Walfish. Depot: Cloud storagewith minimal trust. In OSDI, 2010.
[47] A. J. Mashtizadeh, A. Bittau, Y. F. Huang, andD. Mazieres. Replication, history and grafting inthe ori file system. In SOSP, 2013.
[48] C. Mitchell, Y. Geng, and J. Li. Using one-sidedrdma reads to build a fast, cpu-efficient key-valuestore. In USENIX ATC ’13, pages 103–114, 2013.
[49] J. Morgan and O. Wyman. Unlocking economicadvantage with blockchain. a guide for asset man-agers., 2016.
[50] S. Nakamoto. Bitcoin: A peer-to-peer electroniccash system. https://bitcoin.org/bitcoin.
pdf, 2009.
[51] M. Naveed, S. Kamara, and C. V. Wright. Inferenceattacks on property-preserving encryted databases.In CCS, 2015.
[52] F. A. Nothaft, M. Massie, T. Danford, and et al. Re-thinking data-intensive science using scalable ana-lytics systems. In ACM SIGMOD, 2015.
[53] B. C. Ooi, K.-L. Tan, Q. T. Tran, J. W. L. Yip,G. Chen, Z. J. Ling, T. Nguyen, A. K. H. Thung,and M. Zhang. Contextual crowd intelligence.SIGKDD Explorations, 2014.
[54] Pachyderm. A containerized data lake. https:
//www.pachyderm.io.
17

[55] A. Pavlo, G. Angulo, and et al. Self-drivingdatabase management systems. In CIDR, 2017.
[56] R. A. Popa, C. M. S. Redfield, N. Zeldovich, andH. Balakrishnan. Cryptdb: Protecting confiden-tiality with encrypted query processing. In SOSP,2011.
[57] P. Reiher, J. Heidemann, D. Ratner, G. Skinner, andG. Popek. Resolving file conflicts in the ficus filesystem. In USENIX Summer Technical Conference,1994.
[58] M. Rosenblum and J. K. Ousterhout. The designand implementation of a log-structured file system.TOCS, 10(1):26–52, 1992.
[59] A. Rowstron and P. Druschel. Storage managementand caching in past, a large-scale persistent peer-to-peer storage utility. In SOSP, 2001.
[60] S. M. Rumble, A. Kejriwal, and J. Ousterhout.Log-structured memory for dram-based storage. InFAST ’14, pages 1–16, 2014.
[61] S. Sanfilippo and P. Noordhuis. Redis.http://redis.io, 2009.
[62] D. J. Santry, M. J. Feeley, N. C. Hutchinson, andA. C. Veitch. Elephant: the file system that neverforgets. In HotOS, pages 2–7, 1999.
[63] A. Shraer, C. Cachin, A. Cidon, I. Keidar,Y. Michalevsky, and D. Shaket. Venus: Verifica-tion for untrusted cloud storage. In CCSW, 2010.
[64] C. A. N. Soules, G. R. Goodson, J. D. Strunk, andG. R. Ganger. Metadata efficiency in versioning filesystems. In FAST, 2003.
[65] M. Stonebraker. The design of the postgres storagesystem. In VLDB, 1987.
[66] J. D. Strunk, G. R. Goodson, M. L. Scheinholtz,C. A. N. Soules, and G. R. Ganger. Self-securingstorage: Protecting data in compromised system. InOSDI, 2000.
[67] K.-L. Tan, Q. Cai, B. C. Ooi, W.-F. Wong, C. Yao,and H. Zhang. In-memory databases: Challengesand opportunities from software and hardware per-spectives. SIGMOD Rec., 44(2):35–40, Aug. 2015.
[68] H. T. Vo, S. Wang, D. Agrawal, G. Chen, and B. C.Ooi. Logbase: A scalable log-structured databasesystem in the cloud. In VLDB, 2009.
[69] M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma,M. McCauley, M. J. Franklin, S. Shenker, andI. Stoica. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster comput-ing. In NSDI ’12, pages 15–28, 2012.
[70] H. Zhang, G. Chen, B. C. Ooi, K.-L. Tan, andM. Zhang. In-memory big data management andprocessing: A survey. IEEE Transactions onKnowledge and Data Engineering, 27(7):1920–1948, 2015.
[71] N. Zhu and T.-C. Chiueh. Design, implementation,and evaluation of repairable file service. In DSN,2003.
Blockchain
Application Digital AssetFinancial Securities
Cryptocurrencies …
PrevBlock
TxnRootHash
…
StateRootHash
Input, output
Smart Contract
Code
StateStorage
PrevBlock
TxnRootHash
…
StateRootHash
Input, output
Smart Contract
Code
StateStorage
Consensus Protocol
……
Figure 12: Blockchain software stack
A UStore Applications
A.1 Advanced Git Application
The simple Git implementation described in Section 4only tracks version history at commit level as in originalGit protocol. To extend this, we target to track historiesfor all data types, especially blob (file) and tree (folder).The immediate benefit is that users can view change listof a file or folder more quickly.
To achieve this, we need to separate files and foldersas different UObjects, using its their name as keys andserialized content as value. When we detect that the con-tent has changed during a commit, (e.g., same file namebut different content as in previous checkout) we invokePut(name,version,content).
The merge operation for two versions is similar. Afterresolving conflicts and generating the merged content,we invoke Merge(name,version1,version2,content).This returns a version id which can be used to fetch thatobject.
18

Read Write
Operation
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
ms
Latency
Redis
UStore/TCP
UStore/RDMA
Figure 13: Latency vs. Redis.
A.2 Blockchain
We only described the data structure of blockchain inSection 4.4, but a typical blockchain system consistsof many more complex components besides the datastorage. Here we elaborate a typical architecture of ablockchain system as shown in Figure 12.
Many applications such as cryptocurrencies, digitalasset management and finical security settlement canbuilt upon blockchains. Typically, some of the nodesin a blockchain network may exhibit Byzantine behav-ior, but the majority is honest, thus, the nodes haveto reach agreement on the unique evolution history ofthe global system state through a consensus protocol(e.g., PBFT in Hyperledger[35], PoW in Bitcoin[50] andEthereum[30]). To be general and extensible, recentblockchain platforms, like Ethereum and Hyperledger,support smart contract functionality that allows users todefine their own transaction logic and develop their soft-wares called decentralized application (DApp), e.g. de-centralized online money exchange. The smart contractsare usually written in Turing-complete languages and ex-ecuted in an isolated execution environment providedby the blockchain, such as Ethereum Virtual Machine(EVM) of Ethereum. Because the nodes in blockchainnetwork cannot be fully trusted, blockchain platformsusually construct validity proofs based on Merkle hashtree and its variants that are also used as the indexes forsystem internal states.
Although the storage engine is only a part of the com-plex blockchain software stack, there is a need for effi-ciency and scalability which is critical for smart contractexecution and historical data audit. As we shown in ourexperiment, UStore can serve as the data store of choicefor high performance blockchains.
Read WriteOperation
1.0
1.2
1.4
1.6
1.8
2.0
2.2
2.4
ms
LatencyW=1 W=2 W=3
(a) Latency
Read-heavy Write-heavyWorkload
100
110
120
130
140
150
K op
s/s
ThroughputW=1 W=2 W=3
(b) Throughput
Figure 14: Performance trade-offs against the number of writereplicas W .
B Experimental Results
B.1 Microbenchmark
Figure 13 shows the latency for read and write operationswith 4 clients. It can be seen that UStore can achieve 3xlower latency thanks to RDMAs. Even without RDMAs,UStore is slightly better than Redis, because our server ismulti-threaded. Another source of overhead can be dueto Redis’ support for complex data types such as lists andsorted sets, whereas UStore supports simple, raw binaryformat.
Figure 14 illustrates UStore’s performance with vary-ing number of write replicas W . For this experiment, werun 4 UStore nodes and set N = 3. Recall that W deter-mines how many responses from the replicas are neededbefore a write operation is considered successful. As aresult, higher W leads to higher latency for writes, as wecan see for write-heavy workloads in Figure 14. W onlyaffects read operations in the extreme cases where a readrequest is sent immediately after the write request to areplica which has not finished writing the data, which israre in our cases. Thus, we observed no impact of W onread-heavy workloads.
Compression strategies. We benchmarked the ef-fect of our compression strategy, by comparing it withthe no compression strategy and a random compressionstrategy, where we randomly select an ancestor basedon which we do the compression, in terms of both the
19
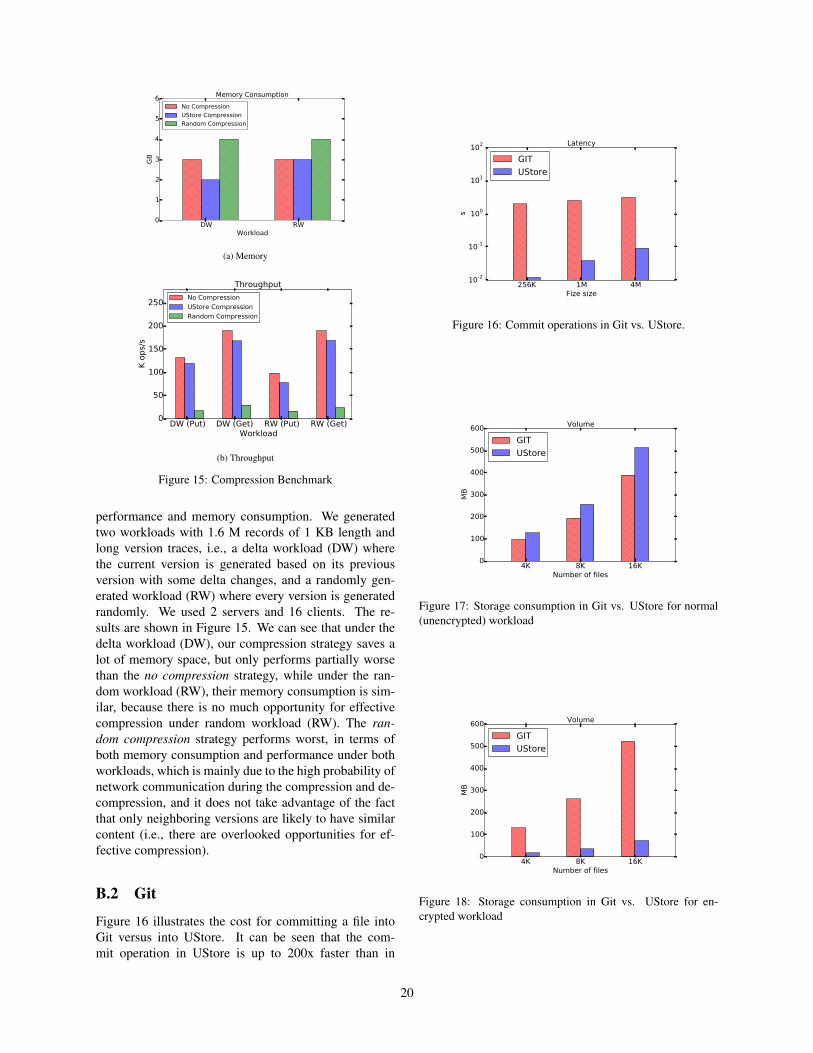
DW RWWorkload
0
1
2
3
4
5
6
GB
Memory Consumption
No Compression
UStore Compression
Random Compression
(a) Memory
DW (Put) DW (Get) RW (Put) RW (Get)Workload
0
50
100
150
200
250
K o
ps/
s
Throughput
No Compression
UStore Compression
Random Compression
(b) Throughput
Figure 15: Compression Benchmark
performance and memory consumption. We generatedtwo workloads with 1.6 M records of 1 KB length andlong version traces, i.e., a delta workload (DW) wherethe current version is generated based on its previousversion with some delta changes, and a randomly gen-erated workload (RW) where every version is generatedrandomly. We used 2 servers and 16 clients. The re-sults are shown in Figure 15. We can see that under thedelta workload (DW), our compression strategy saves alot of memory space, but only performs partially worsethan the no compression strategy, while under the ran-dom workload (RW), their memory consumption is sim-ilar, because there is no much opportunity for effectivecompression under random workload (RW). The ran-dom compression strategy performs worst, in terms ofboth memory consumption and performance under bothworkloads, which is mainly due to the high probability ofnetwork communication during the compression and de-compression, and it does not take advantage of the factthat only neighboring versions are likely to have similarcontent (i.e., there are overlooked opportunities for ef-fective compression).
B.2 Git
Figure 16 illustrates the cost for committing a file intoGit versus into UStore. It can be seen that the com-mit operation in UStore is up to 200x faster than in
256K 1M 4MFize size
10-2
10-1
100
101
102
s
Latency
GIT
UStore
Figure 16: Commit operations in Git vs. UStore.
4K 8K 16KNumber of files
0
100
200
300
400
500
600
MB
Volume
GIT
UStore
Figure 17: Storage consumption in Git vs. UStore for normal(unencrypted) workload
4K 8K 16KNumber of files
0
100
200
300
400
500
600
MB
Volume
GIT
UStore
Figure 18: Storage consumption in Git vs. UStore for en-crypted workload
20

1 10 100 1000Number of versions
10-1
100
101
102
103
104
105
ms
Latency
Ethereum Geth
UStore
Figure 19: Ethereum performance vs. UStore on block levelversion scan
Git. This performance gap is attributed to several fac-tors. First, UStore stores data in memory which avoidsexternal I/Os. Second, Git incurs much overhead whenpushing commits to the remote server. Before connect-ing to server, Git automatically triggers object packing tocombine multiple objects as compressed packages. Thisstrategy reduces network communication, but it is timeconsuming.
Figure 17 and Figure 18 show the storage space con-sumption for maintaining a Git repository at the serverside. In order to reduce space consumption, Git useszlib to compress all objects, reducing both storage andnetwork cost. We conducted a test with plain text work-load. As shown in Figure 17, Git occupies less spacethan UStore, since we do not apply any compression inUStore. However, UStore exposes the interface for usersto define own compression strategies, e.g. zlib. Moreimportantly, compression in UStore can be application-specific. Users can leverage unique characteristics oftheir data to perform much better. For example, we gen-erated an AES encrypted workload, which is ineffectiveto compress directly. We then injected a customizedcompression function into UStore which processes thedata in decrypt-compress-encrypt manner. Figure 18 val-idates the effectiveness of this application-specific com-pression. We can see that if users know their data well, itis easy for UStore to outperform the default compressionin Git.
B.3 Blockchain Application
Figure 19 illustrates comparison between Geth and US-tore on block level version scan operations described inSection 5.5. It shares a similar performance pattern withaccount level version scan operation shown in Figure 11,but incurs less overhead in Geth than account level ver-sion scan. This is because in Ethereum’s implementa-tion, when scanning account versions, it has to fetch the
block information corresponding to that account versionas well.
21





























