Embed Size (px)
Citation preview

1
Using Compression to Improve Chip Multiprocessor Performance
Alaa R. Alameldeen
Dissertation Defense
Wisconsin Multifacet Project
University of Wisconsin-Madison
http://www.cs.wisc.edu/multifacet
2
Motivation
� Architectural trends
– Multi-threaded workloads
– Memory wall
– Pin bandwidth bottleneck
� CMP design trade-offs
– Number of Cores
– Cache Size
– Pin Bandwidth
� Are these trade-offs zero-sum?
– No, compression helps cache size and pin bandwidth
� However, hardware compression raises a few questions

2
3
Thesis Contributions� Question: Is compression’s overhead too high for
caches?
� Contribution #1: Simple compressed cache design
– Compression Scheme: Frequent Pattern Compression
– Cache Design: Decoupled Variable-Segment Cache
� Question: Can cache compression hurt performance?
+ Reduces miss rate
‒ Increases hit latency
� Contribution #2: Adaptive compression
– Adapt to program behavior
– Cache compression only when it helps
4
Thesis Contributions (Cont.)� Question: Does compression help CMP performance?
� Contribution #3: Evaluate CMP cache and link compression
– Cache compression improves CMP throughput
– Link compression reduces pin bandwidth demand
� Question: How does compression and prefetching interact?
� Contribution #4: Compression interacts positively with prefetching
– Speedup (Compr, Pref) > Speedup (Compr) x Speedup (Pref)
� Question: How do we balance CMP cores and caches?
� Contribution #5: Model CMP cache and link compression
– Compression improves optimal CMP configuration

3
5
Outline
� Background
– Technology and Software Trends
– Compression Addresses CMP Design Challenges
� Compressed Cache Design
� Adaptive Compression
� CMP Cache and Link Compression
� Interactions with Hardware Prefetching
� Balanced CMP Design
� Conclusions
6
Technology and Software Trends
� Technology trends:
– Memory Wall: Increasing gap between processor and
memory speeds
– Pin Bottleneck: Bandwidth demand > Bandwidth Supply
4
7
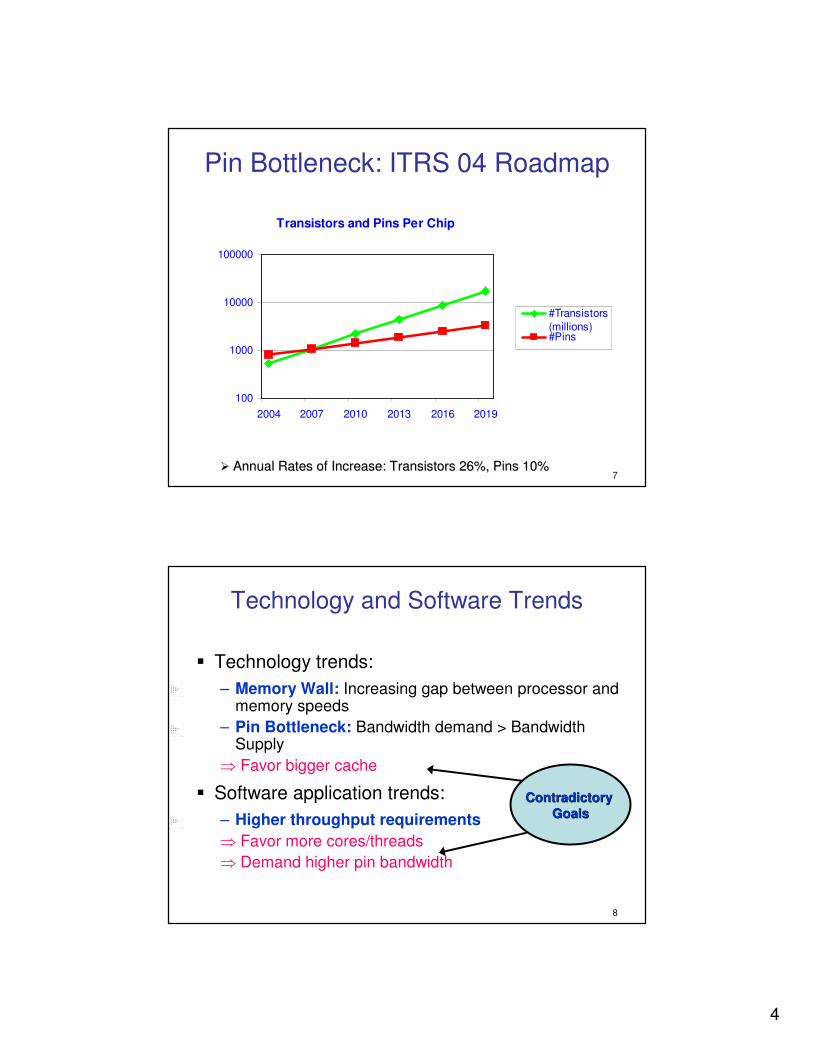
Pin Bottleneck: ITRS 04 Roadmap
�� Annual Rates of Increase: Transistors 26%, Pins 10%Annual Rates of Increase: Transistors 26%, Pins 10%
Transistors and Pins Per Chip
100
1000
10000
100000
2004 2007 2010 2013 2016 2019
#Transistors
(millions)#Pins
8
� Technology trends:
– Memory Wall: Increasing gap between processor and memory speeds
– Pin Bottleneck: Bandwidth demand > Bandwidth Supply
⇒ Favor bigger cache
� Software application trends:
– Higher throughput requirements
⇒ Favor more cores/threads
⇒ Demand higher pin bandwidth
Technology and Software Trends
Contradictory Contradictory
GoalsGoals

5
9
Using Compression
� On-chip Compression
– Cache Compression: Increases effective cache size
– Link Compression: Increases effective pin bandwidth
� Compression Requirements
– Lossless
– Low decompression (compression) overhead
– Efficient for small block sizes
– Minimal additional complexity
�Thesis addresses CMP design with compression support
10
Outline
� Background
� Compressed Cache Design
– Compressed Cache Hierarchy
– Compression Scheme: FPC
– Decoupled Variable-Segment Cache
� Adaptive Compression
� CMP Cache and Link Compression
� Interactions with Hardware Prefetching
� Balanced CMP Design
� Conclusions
6
11
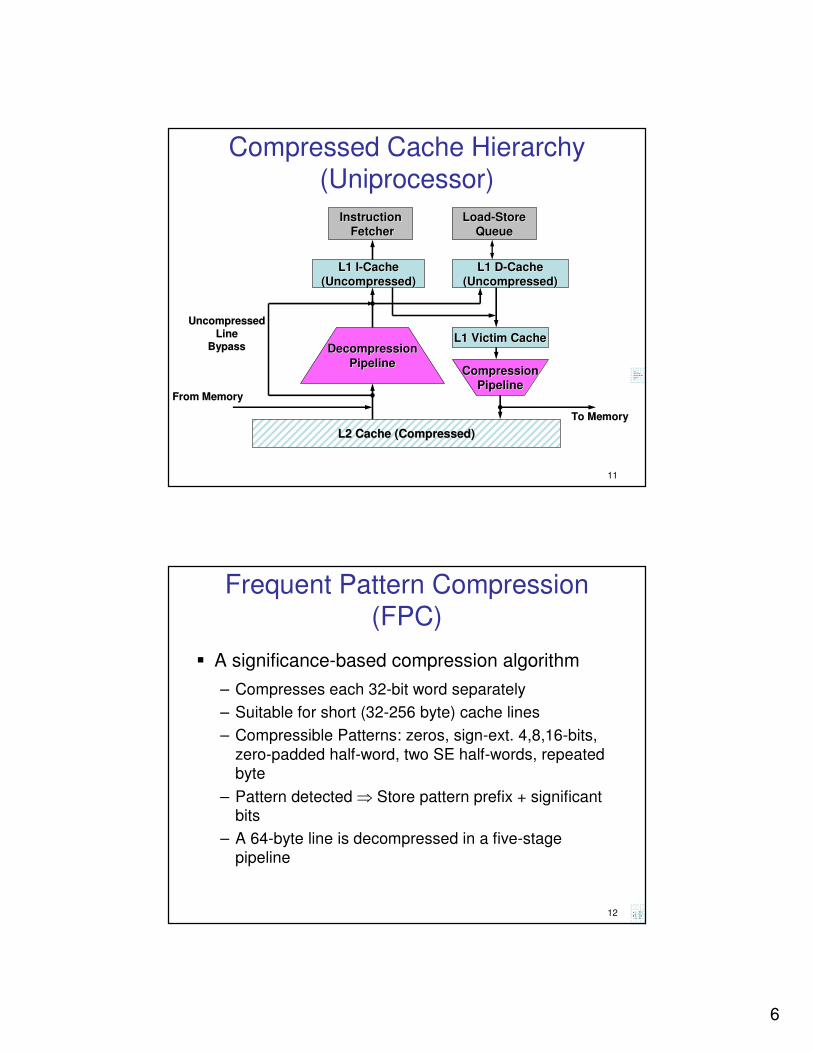
Compressed Cache Hierarchy (Uniprocessor)
InstructionInstruction
FetcherFetcher
L2 Cache (Compressed)L2 Cache (Compressed)
L1 DL1 D--CacheCache
(Uncompressed)(Uncompressed)
LoadLoad--StoreStore
QueueQueue
L1 IL1 I--CacheCache
(Uncompressed)(Uncompressed)
L1 Victim CacheL1 Victim Cache
CompressionCompression
PipelinePipeline
DecompressionDecompression
PipelinePipeline
UncompressedUncompressed
LineLine
BypassBypass
From MemoryFrom Memory
To MemoryTo Memory
12
Frequent Pattern Compression (FPC)
� A significance-based compression algorithm
– Compresses each 32-bit word separately
– Suitable for short (32-256 byte) cache lines
– Compressible Patterns: zeros, sign-ext. 4,8,16-bits,
zero-padded half-word, two SE half-words, repeated byte
– Pattern detected ⇒ Store pattern prefix + significant bits
– A 64-byte line is decompressed in a five-stage pipeline

7
13
Decoupled Variable-Segment Cache
� Each set contains twice as many tags as uncompressed lines
� Data area divided into 8-byte segments
� Each tag is composed of:
– Address tag
– Permissions
– CStatus : 1 if the line is compressed, 0 otherwise
– CSize: Size of compressed line in segments
– LRU/replacement bits
Same as Same as
uncompressed uncompressed
cachecache
14
Decoupled Variable-Segment Cache
� Example cache set
Addr B compressed 2 Addr B compressed 2
Data AreaData Area
Addr A uncompressed 3Addr A uncompressed 3
Addr C compressed 6Addr C compressed 6
Addr D compressed 4Addr D compressed 4
Tag AreaTag Area
Compression StatusCompression Status Compressed SizeCompressed SizeTag is present Tag is present
but line isnbut line isn’’tt
8
15
Outline
� Background
� Compressed Cache Design
� Adaptive Compression
– Key Insight
– Classification of Cache Accesses
– Performance Evaluation
� CMP Cache and Link Compression
� Interactions with Hardware Prefetching
� Balanced CMP Design
� Conclusions
16
Adaptive Compression
� Use past to predict future
� Key Insight:
– LRU Stack [Mattson, et al., 1970] indicates for each reference whether compression helps or hurts
Benefit(Compression) Benefit(Compression)
> Cost(Compression> Cost(Compression))
Do not compress Do not compress
future linesfuture linesCompress Compress
future linesfuture lines
YesYes NoNo

9
17
Cost/Benefit Classification
� Classify each cache reference
� Four-way SA cache with space for two 64-byte lines
– Total of 16 available segments
Addr B compressed 2 Addr B compressed 2
Data AreaData Area
Addr A uncompressed 3Addr A uncompressed 3
Addr C compressed 6Addr C compressed 6
Addr D compressed 4Addr D compressed 4
Tag AreaTag Area
18
An Unpenalized Hit
� Read/Write Address A
– LRU Stack order = 1 ≤ 2 � Hit regardless of compression
– Uncompressed Line � No decompression penalty
– Neither cost nor benefit
Addr B compressed 2 Addr B compressed 2
Data AreaData Area
Addr A uncompressed 3Addr A uncompressed 3
Addr C compressed 6Addr C compressed 6
Addr D compressed 4Addr D compressed 4
Tag AreaTag Area

10
19
A Penalized Hit
� Read/Write Address B
– LRU Stack order = 2 ≤ 2 � Hit regardless of compression
– Compressed Line � Decompression penalty incurred
– Compression cost
Addr B compressed 2 Addr B compressed 2
Data AreaData Area
Addr A uncompressed 3Addr A uncompressed 3
Addr C compressed 6Addr C compressed 6
Addr D compressed 4Addr D compressed 4
Tag AreaTag Area
20
An Avoided Miss
� Read/Write Address C
– LRU Stack order = 3 > 2 � Hit only because of compression
– Compression benefit: Eliminated off-chip miss
Addr B compressed 2 Addr B compressed 2
Data AreaData Area
Addr A uncompressed 3Addr A uncompressed 3
Addr C compressed 6Addr C compressed 6
Addr D compressed 4Addr D compressed 4
Tag AreaTag Area

11
21
An Avoidable Miss
� Read/Write Address D
– Line is not in the cache but tag exists at LRU stack order = 4
– Missed only because some lines are not compressed
– Potential compression benefit
Sum(CSize) = 15 Sum(CSize) = 15 ≤≤ 1616
Addr B compressed 2 Addr B compressed 2
Data AreaData Area
Addr A uncompressed 3Addr A uncompressed 3
Addr C compressed 6Addr C compressed 6
Addr D compressed 4Addr D compressed 4
Tag AreaTag Area
22
An Unavoidable Miss
� Read/Write Address E
– LRU stack order > 4 � Compression wouldn’t have helped
– Line is not in the cache and tag does not exist
– Neither cost nor benefit
Addr B compressed 2 Addr B compressed 2
Data AreaData Area
Addr A uncompressed 3Addr A uncompressed 3
Addr C compressed 6Addr C compressed 6
Addr D compressed 4Addr D compressed 4
Tag AreaTag Area

12
23
Compression Predictor
� Estimate: Benefit(Compression) – Cost(Compression)
� Single counter : Global Compression Predictor (GCP)
– Saturating up/down 19-bit counter
� GCP updated on each cache access
– Benefit: Increment by memory latency
– Cost: Decrement by decompression latency
– Optimization: Normalize to memory_lat / decompression_lat, 1
� Cache Allocation
– Allocate compressed line if GCP ≥ 0
– Allocate uncompressed lines if GCP < 0
24
Simulation Setup
� Workloads:
– Commercial workloads [Computer’03, CAECW’02] : • OLTP: IBM DB2 running a TPC-C like workload
• SPECJBB
• Static Web serving: Apache and Zeus
– SPEC2000 benchmarks:• SPECint: bzip, gcc, mcf, twolf
• SPECfp: ammp, applu, equake, swim
� Simulator:
– Simics full system simulator; augmented with:
– Multifacet General Execution-driven Multiprocessor Simulator (GEMS) [Martin, et al., 2005, http://www.cs.wisc.edu/gems/]

13
25
System configuration
� Configuration parameters:
Dynamically scheduled SPARC V9, 4-wide
superscalar, 64-entry Instruction Window, 128-
entry reorder buffer
Processor
4GB DRAM, 400-cycle access time, 16
outstanding requests
Memory
Unified 4MB, 8-way SA, 64B line, access latency
15 cycles + 5-cycle decompression latency (if
needed)
L2 Cache
Split I&D, 64KB each, 4-way SA, 64B line, 3-
cycles/access
L1 Cache
26
Simulated Cache Configurations
� Always: All compressible lines are stored in compressed format
– Decompression penalty for all compressed lines
� Never: All cache lines are stored in uncompressed format
– Cache is 8-way set associative with half the number of sets
– Does not incur decompression penalty
� Adaptive: Adaptive compression scheme
14
27
0
0.2
0.4
0.6
0.8
1
1.2
bzi
p
gcc
mcf
two
lf
am
mp
ap
plu
equ
ak
e
swim
ap
ach
e
zeu
s
olt
p
jbb
Norm
alized R
untim
e
Never
Always
Adaptive
Performance
SpecINTSpecINT SpecFPSpecFP CommercialCommercial
28
Performance
0
0.2
0.4
0.6
0.8
1
1.2
bzi
p
gcc
mcf
two
lf
am
mp
ap
plu
equ
ak
e
swim
ap
ach
e
zeu
s
olt
p
jbb
Norm
alized R
untim
e
Never
Always
Adaptive
15
29
Performance
0
0.2
0.4
0.6
0.8
1
1.2
bzi
p
gcc
mcf
two
lf
am
mp
ap
plu
equ
ak
e
swim
ap
ach
e
zeu
s
olt
p
jbb
Norm
alized R
untim
e
Never
Always
Adaptive
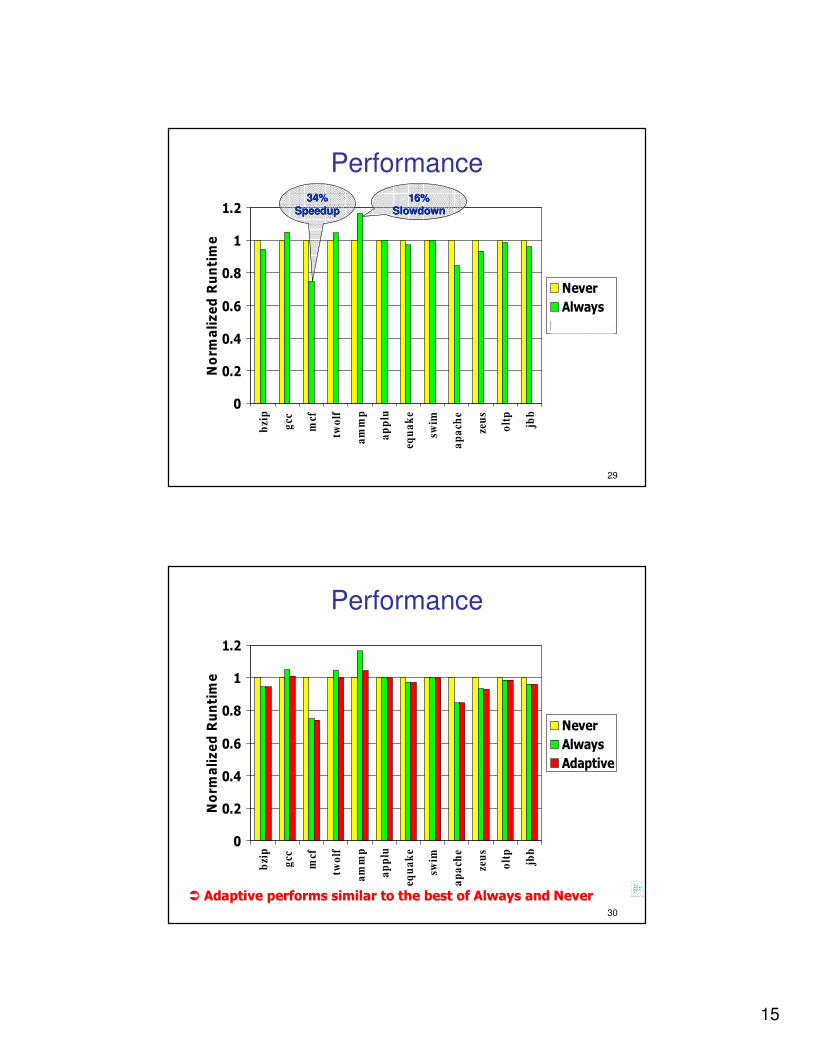
34% 34%
SpeedupSpeedup16% 16%
SlowdownSlowdown
30
Performance
0
0.2
0.4
0.6
0.8
1
1.2
bzi
p
gcc
mcf
two
lf
am
mp
ap
plu
equ
ak
e
swim
ap
ach
e
zeu
s
olt
p
jbb
Norm
alized R
untim
e
Never
Always
Adaptive
�� Adaptive performs similar to the best of Always and NeverAdaptive performs similar to the best of Always and Never

16
31
Cache Miss Rates
0.0
0.5
1.0N
orm
ali
zed M
iss
Rate
Never
Always
Adaptive
1.3
bzip
2.9
gcc
39.9
mcf
5.0
twolf
0.2
ammp
15.7
applu
11.1
equake
41.6
swim
15.7
apache
15.3
zeus
3.6
oltp
3.9
jbb
32
Optimal Adaptive Compression?
� Optimal: Always with no decompression penalty
0.0
0.5
1.0
No
rmali
zed R
un
tim
e
Never
Always
Adaptive
Optimal
bzip gcc mcf twolf ammp applu equake swim apache zeus oltp jbb

17
33
Adapting to L2 Size
0.0
0.5
1.0
No
rmal
ized
Ru
nti
me
ammp
Never
Always
Adaptive
256K/80.9
512K/81.1
1M/85.8
2M/89.0
4M/88252
8M/8164923
16M/81722811
0.0
0.5
1.0
Norm
aliz
ed R
unti
me
mcf
Never
Always
Adaptive
256K/85.9
512K/85.8
1M/83.3
2M/82.9
4M/810.8
8M/880.7
16M/86631841
Penalized Hits
Per Avoided Miss
34
Adaptive Compression: Summary
� Cache compression increases cache capacity but slows down cache hit time
– Helps some benchmarks (e.g., apache, mcf)
– Hurts other benchmarks (e.g., gcc, ammp)
� Adaptive compression
– Uses (LRU) replacement stack to determine whether compression helps or hurts
– Updates a single global saturating counter on cache accesses
� Adaptive compression performs similar to the better of Always Compress and Never Compress
18
35
Outline
� Background
� Compressed Cache Design
� Adaptive Compression
� CMP Cache and Link Compression
� Interactions with Hardware Prefetching
� Balanced CMP Design
� Conclusions
36
Compressed Cache Hierarchy (CMP)
Shared L2 Cache (Compressed)Shared L2 Cache (Compressed)
CompressionCompression
DecompressionDecompression
UncompressedUncompressed
LineLine
BypassBypass
Processor 1Processor 1
L1 Cache L1 Cache
(Uncompressed)(Uncompressed)
L3 / Memory Controller (Could L3 / Memory Controller (Could compress/decompress)compress/decompress)
…………………………………………
Processor nProcessor n
L1 Cache L1 Cache
(Uncompressed)(Uncompressed)
To/From other chips/memoryTo/From other chips/memory

19
37
Link Compression
� On-chip L3/Memory
Controller transfers compressed messages
� Data Messages
– 1-8 sub-messages (flits), 8-
bytes each
� Off-chip memory controller combines flits
and stores to memoryL3/Memory ControllerL3/Memory Controller
Memory ControllerMemory Controller
Processors / L1 CachesProcessors / L1 Caches
L2 CacheL2 Cache
CMPCMP
To/From MemoryTo/From Memory
38
Hardware Stride-Based Prefetching
� L2 Prefetching
+ Hides memory latency
- Increases pin bandwidth demand
� L1 Prefetching
+ Hides L2 latency
- Increases L2 contention and on-chip bandwidth demand
- Triggers L2 fill requests ⇒ Increases pin bandwidth demand
� Questions:
– Does compression interfere positively or negatively with
hardware prefetching?
– How does a system with both compare to a system with only
compression or only prefetching?

20
39
Interactions Terminology
� Assume a base system S with two architectural enhancements A and B, All systems run
program P
Speedup(A) = Runtime(P, S) / Runtime(P, A)
Speedup(B) = Runtime(P, S) / Runtime (P, B)
Speedup(A, B) = Speedup(A) x Speedup(B)
x (1 + Interaction(A,B) )
40
Compression and Prefetching Interactions
� Positive Interactions:
+ L1 prefetching hides part of decompression overhead
+ Link compression reduces increased bandwidth demand because of prefetching
+Cache compression increases effective L2 size, L2 prefetching increases working set size
� Negative Interactions:
– L2 prefetching and L2 compression can eliminate the same misses
�Is Interaction(Compression, Prefetching) positive or negative?

21
41
Evaluation� 8-core CMP
� Cores: single-threaded, out-of-order superscalar with a 64-entry IW, 128-entry ROB, 5 GHz clock frequency
� L1 Caches: 64K instruction, 64K data, 4-way SA, 320 GB/sec total on-chip bandwidth (to/from L1), 3-cycle latency
� Shared L2 Cache: 4 MB, 8-way SA (uncompressed), 15-cycle uncompressed latency, 128 outstanding misses
� Memory: 400 cycles access latency, 20 GB/sec memory bandwidth
� Prefetching:
– Similar to prefetching in IBM’s Power4 and Power5
– 8 unit/negative/non-unit stride streams for L1 and L2 for each processor
– Issue 6 L1 prefetches on L1 miss
– Issue 25 L2 prefetches on L2 miss
42
Performance
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
apache zeus oltp jbb art apsi fma3d mgrid
Speedup
No Compression orPrefetching
Cache Compression
Link Compression
Cache and LinkCompression
CommercialCommercial SPECompSPEComp
22
43
Performance
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
apache zeus oltp jbb art apsi fma3d mgrid
Speedup
No Compression orPrefetching
Cache Compression
Link Compression
Cache and LinkCompression
44
Performance
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
apache zeus oltp jbb art apsi fma3d mgrid
Speedup
No Compression orPrefetching
Cache Compression
Link Compression
Cache and LinkCompression
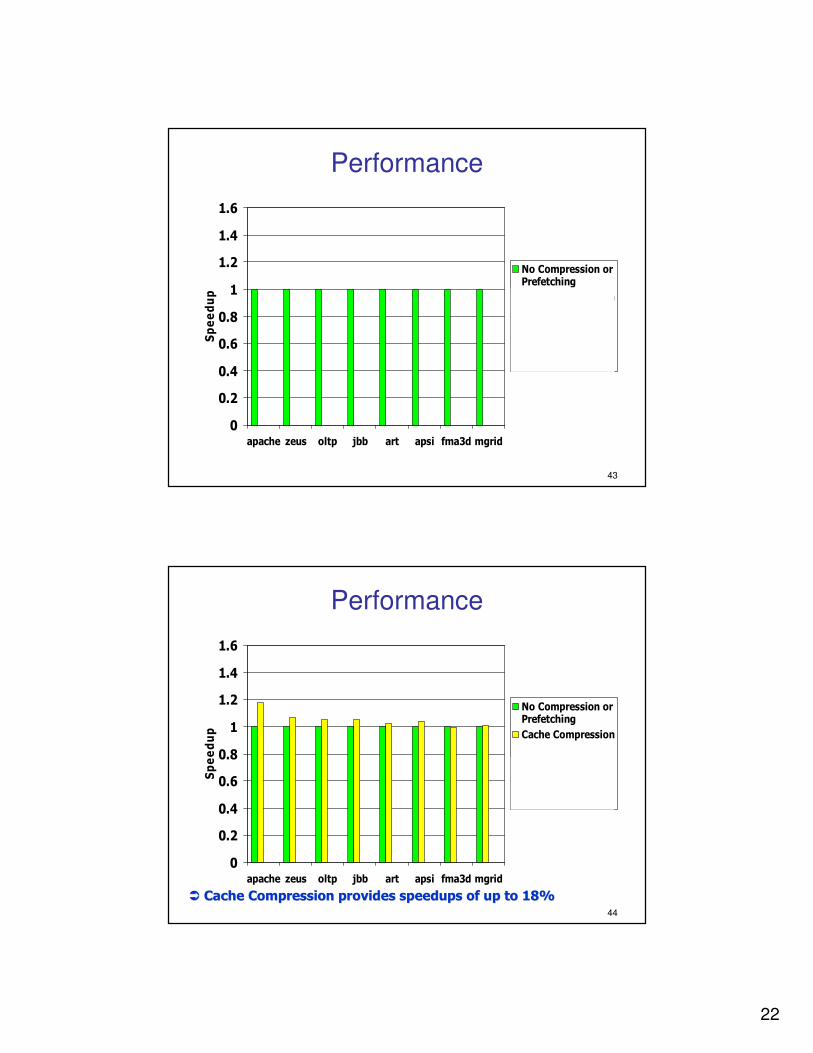
�� Cache Compression provides speedups of up to 18%Cache Compression provides speedups of up to 18%
23
45
Performance
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
apache zeus oltp jbb art apsi fma3d mgrid
Speedup
No Compression orPrefetching
Cache Compression
Link Compression
Cache and LinkCompression
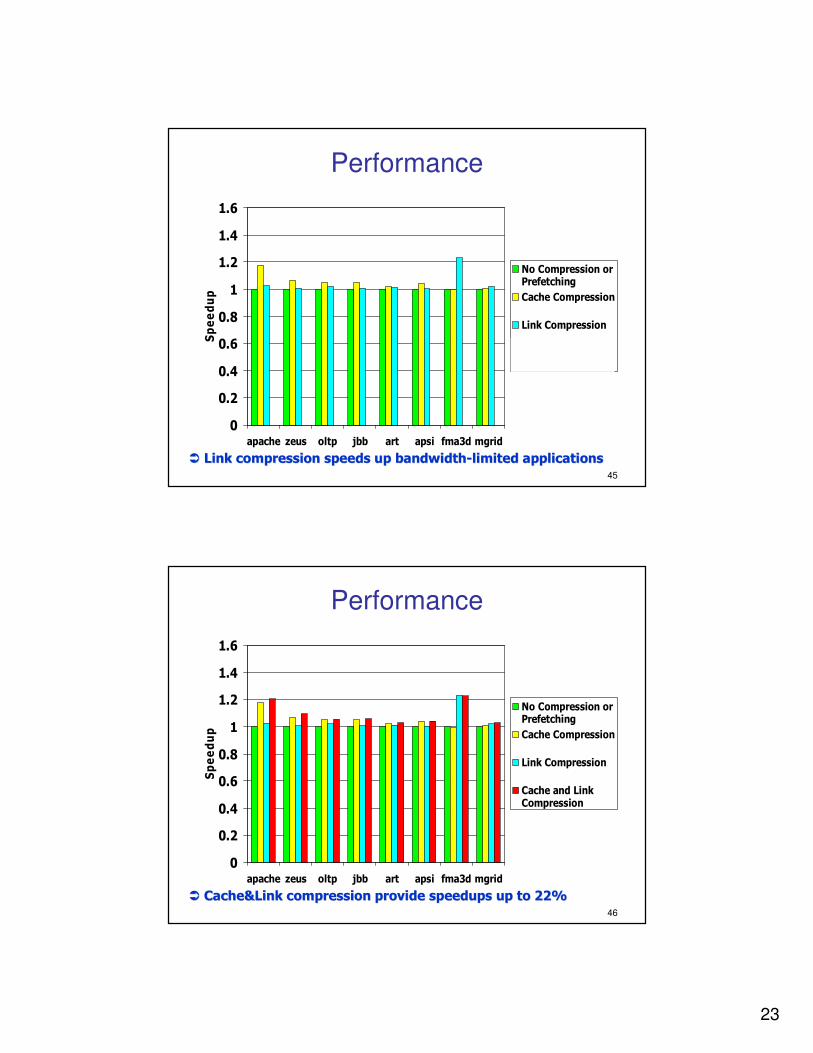
�� Link compression speeds up bandwidthLink compression speeds up bandwidth--limited applicationslimited applications
46
Performance
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
apache zeus oltp jbb art apsi fma3d mgrid
Speedup
No Compression orPrefetching
Cache Compression
Link Compression
Cache and LinkCompression
�� Cache&Link compression provide speedups up to 22%Cache&Link compression provide speedups up to 22%
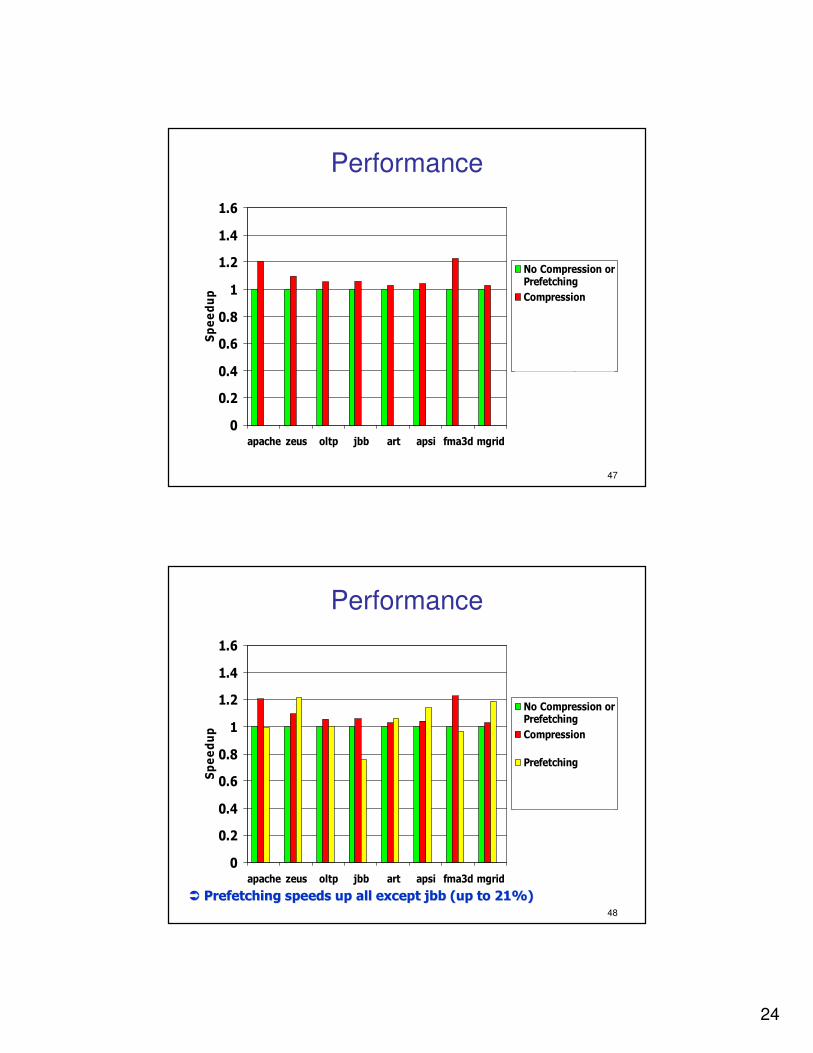
24
47
Performance
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
apache zeus oltp jbb art apsi fma3d mgrid
Speedup
No Compression orPrefetching
Compression
Prefetching
Compression andPrefetching
48
Performance
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
apache zeus oltp jbb art apsi fma3d mgrid
Speedup
No Compression orPrefetching
Compression
Prefetching
Compression andPrefetching
�� Prefetching speeds up all except jbb (up to 21%)Prefetching speeds up all except jbb (up to 21%)
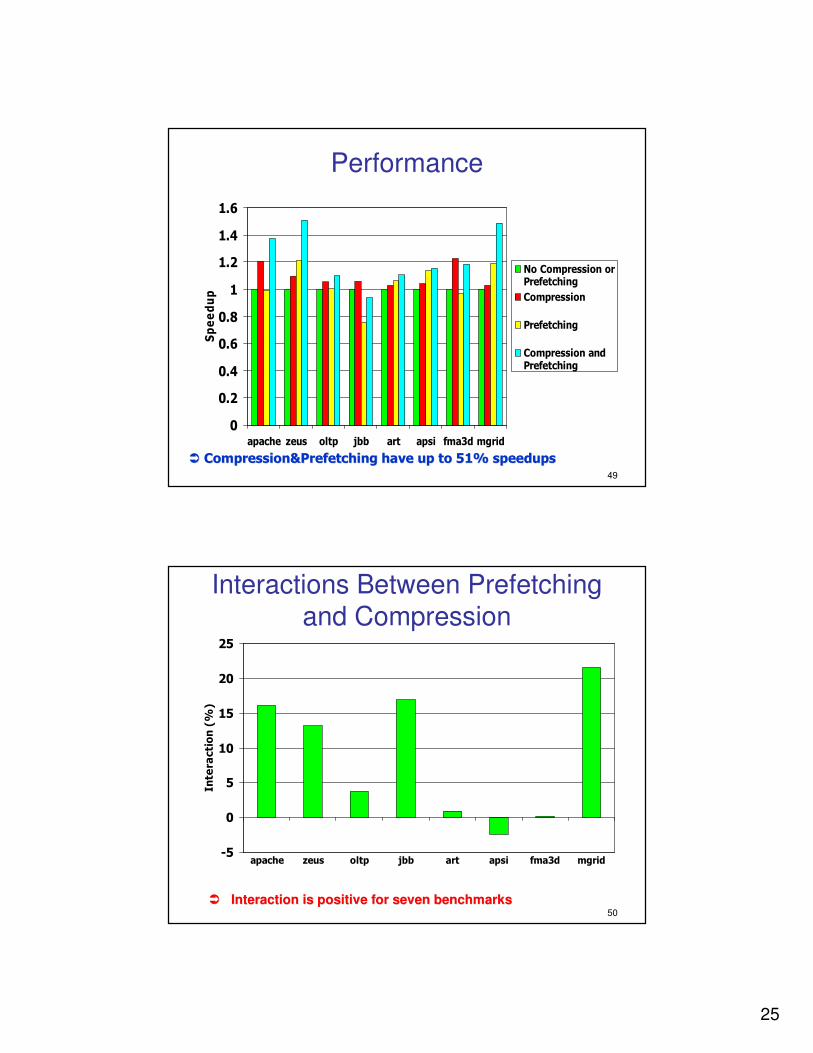
25
49
Performance
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
apache zeus oltp jbb art apsi fma3d mgrid
Speedup
No Compression orPrefetching
Compression
Prefetching
Compression andPrefetching
�� Compression&Prefetching have up to 51% speedupsCompression&Prefetching have up to 51% speedups
50
Interactions Between Prefetching and Compression
-5
0
5
10
15
20
25
apache zeus oltp jbb art apsi fma3d mgrid
Inte
raction (%
)
�� Interaction is positive for seven benchmarksInteraction is positive for seven benchmarks
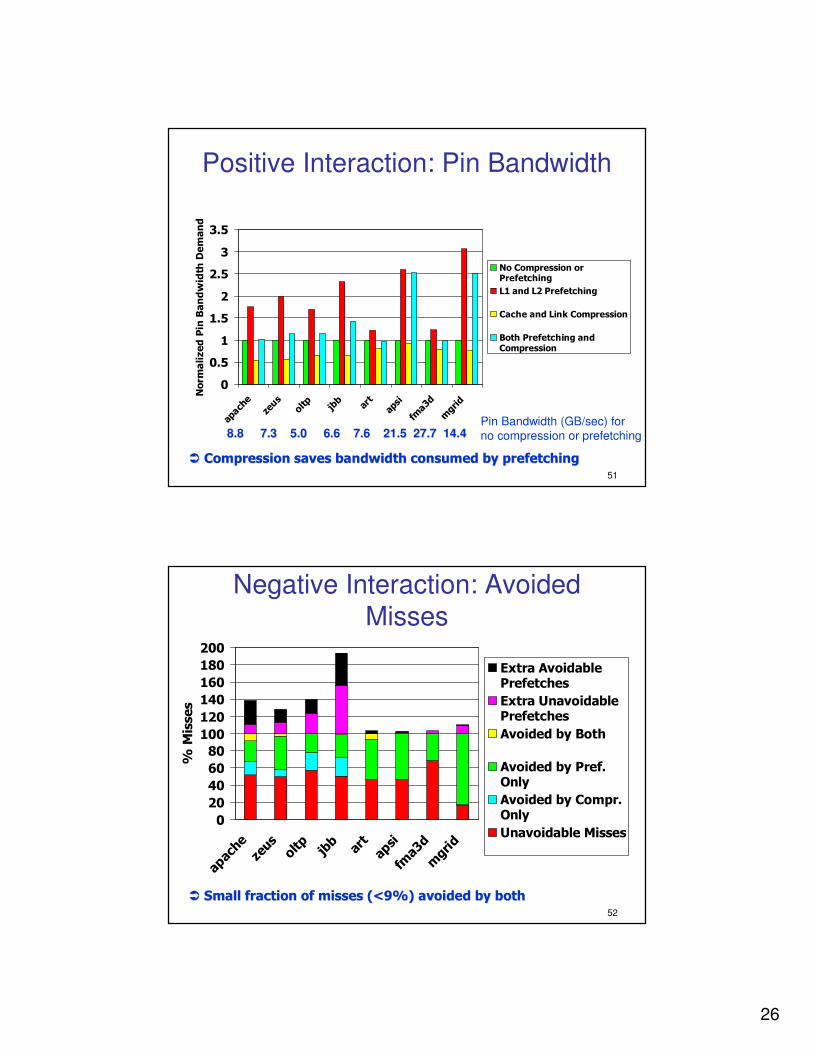
26
51
Positive Interaction: Pin Bandwidth
0
0.5
1
1.5
2
2.5
3
3.5
apache
zeus
oltp jb
bart
apsi
fma3d
mgrid
Norm
alized Pin Bandwidth Demand
No Compression orPrefetching
L1 and L2 Prefetching
Cache and Link Compression
Both Prefetching andCompression
8.8 7.3 5.0 6.6 7.6 21.5 27.7 14.48.8 7.3 5.0 6.6 7.6 21.5 27.7 14.4
�� Compression saves bandwidth consumed by prefetchingCompression saves bandwidth consumed by prefetching
Pin Bandwidth (GB/sec) for
no compression or prefetching
52
Negative Interaction: Avoided Misses
0
20
40
60
80
100
120
140
160
180
200
apache
zeus
oltp jb
bart
apsi
fma3d
mgrid
% M
isses
Extra AvoidablePrefetches
Extra UnavoidablePrefetches
Avoided by Both
Avoided by Pref.Only
Avoided by Compr.Only
Unavoidable Misses
�� Small fraction of misses (<9%) avoided by bothSmall fraction of misses (<9%) avoided by both
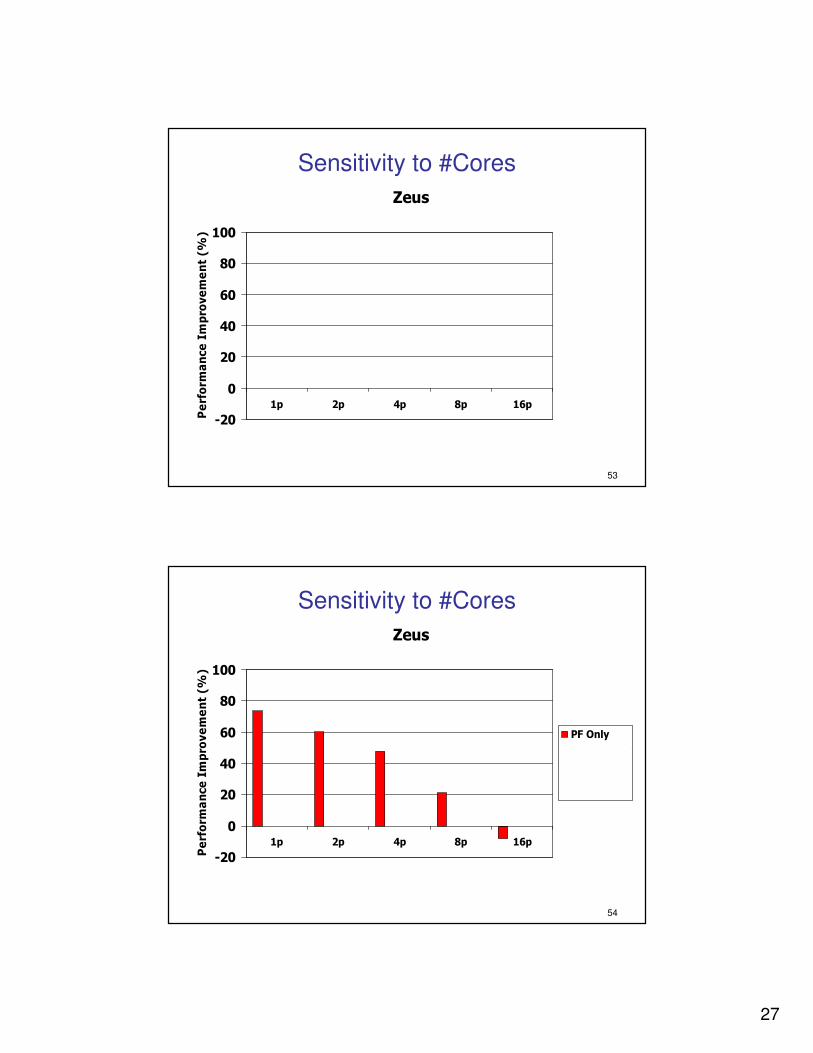
27
53
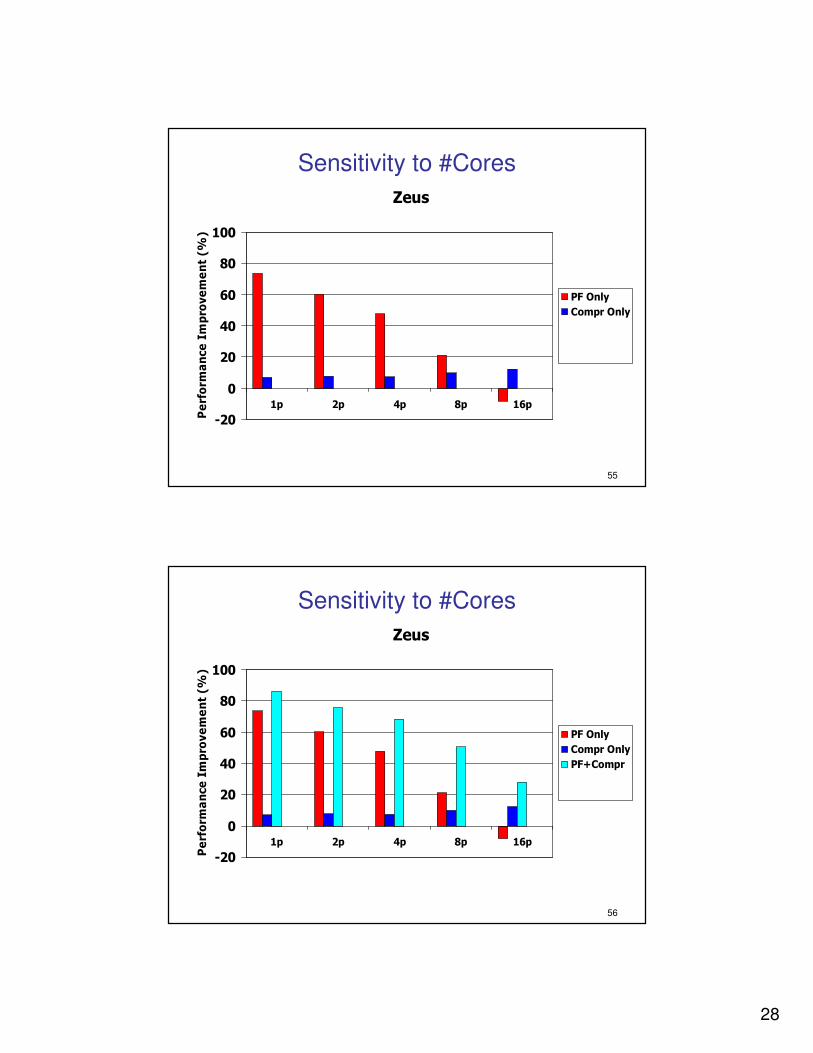
Sensitivity to #Cores
Zeus
-20
0
20
40
60
80
100
1p 2p 4p 8p 16p
Perform
ance Impro
vement (%
)
PF Only
Compr Only
PF+Compr
PF+2x BW
PF+2x L2
54
Sensitivity to #Cores
Zeus
-20
0
20
40
60
80
100
1p 2p 4p 8p 16p
Perform
ance Impro
vement (%
)
PF Only
Compr Only
PF+Compr
PF+2x BW
PF+2x L2
28
55
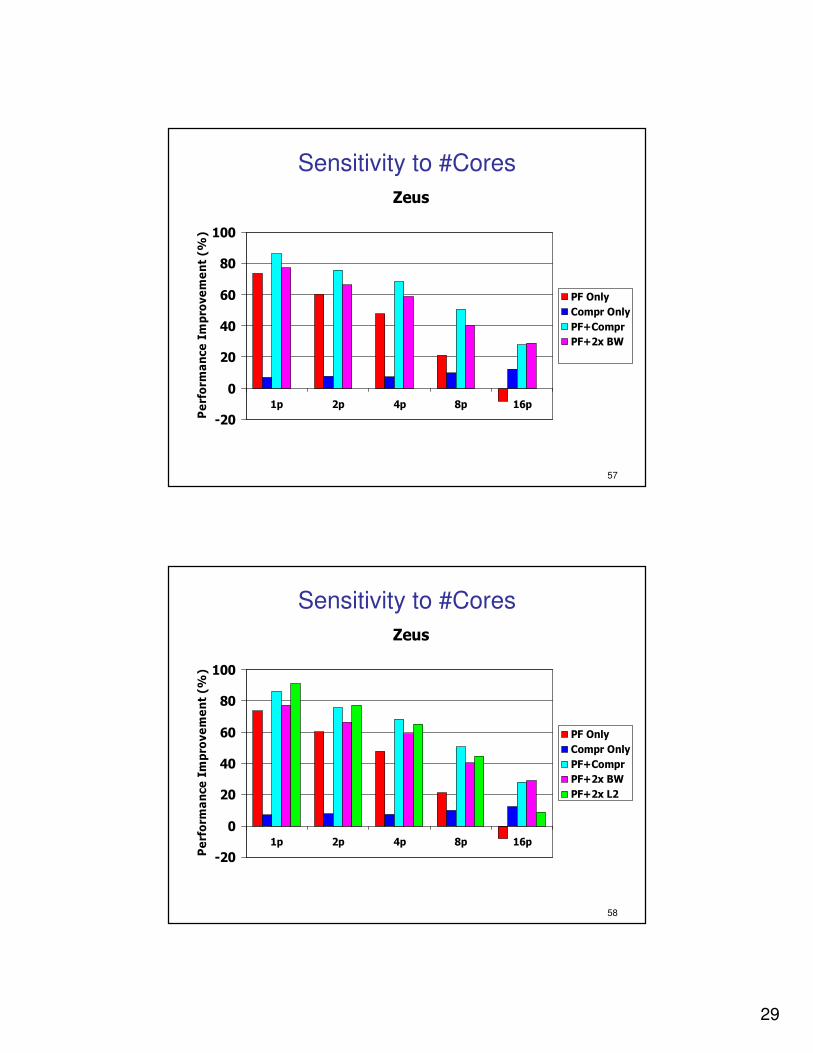
Sensitivity to #Cores
Zeus
-20
0
20
40
60
80
100
1p 2p 4p 8p 16p
Perform
ance Impro
vement (%
)
PF Only
Compr Only
PF+Compr
PF+2x BW
PF+2x L2
56
Sensitivity to #Cores
Zeus
-20
0
20
40
60
80
100
1p 2p 4p 8p 16p
Perform
ance Impro
vement (%
)
PF Only
Compr Only
PF+Compr
PF+2x BW
PF+2x L2
29
57
Sensitivity to #Cores
Zeus
-20
0
20
40
60
80
100
1p 2p 4p 8p 16p
Perform
ance Impro
vement (%
)
PF Only
Compr Only
PF+Compr
PF+2x BW
PF+2x L2
58
Sensitivity to #Cores
Zeus
-20
0
20
40
60
80
100
1p 2p 4p 8p 16p
Perform
ance Impro
vement (%
)
PF Only
Compr Only
PF+Compr
PF+2x BW
PF+2x L2
30
59
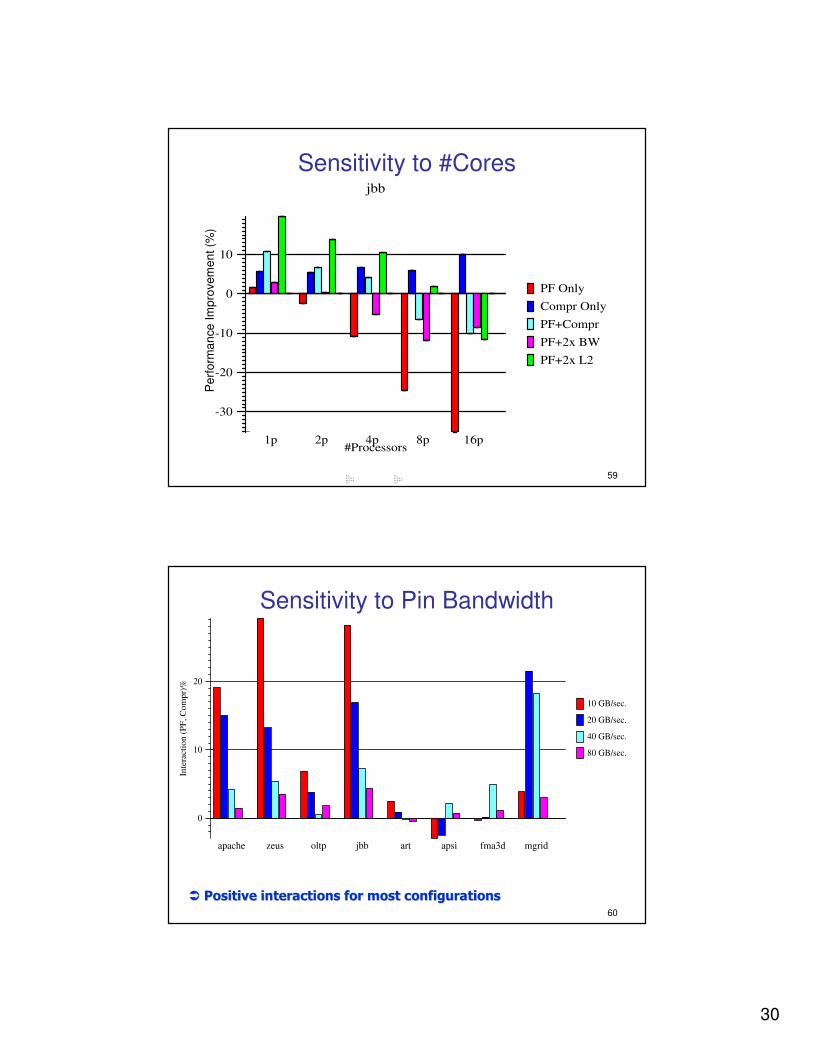
Sensitivity to #Cores
#Processors
-30
-20
-10
0
10
jbb
PF Only
Compr Only
PF+Compr
PF+2x BW
PF+2x L2
1p 2p 4p 8p 16p
Pe
rfo
rma
nce
Im
pro
vem
en
t (%
)
60
Sensitivity to Pin Bandwidth
0
10
20
Inte
racti
on (
PF
, C
om
pr)
%
10 GB/sec.
20 GB/sec.
40 GB/sec.
80 GB/sec.
apache zeus oltp jbb art apsi fma3d mgrid
�� Positive interactions for most configurationsPositive interactions for most configurations

31
61
Compression and Prefetching: Summary
� More cores on a CMP increase demand for:
– On-chip (shared) caches
– Off-chip pin bandwidth
� Prefetching further increases demand on both
resources
� Cache and link compression alleviate such demand
� Compression interacts positively with hardware
prefetching
62
Outline
� Background
� Compressed Cache Design
� Adaptive Compression
� CMP Cache and Link Compression
� Interactions with Hardware Prefetching
� Balanced CMP Design
– Analytical Model
– Simulation
� Conclusions
32
63
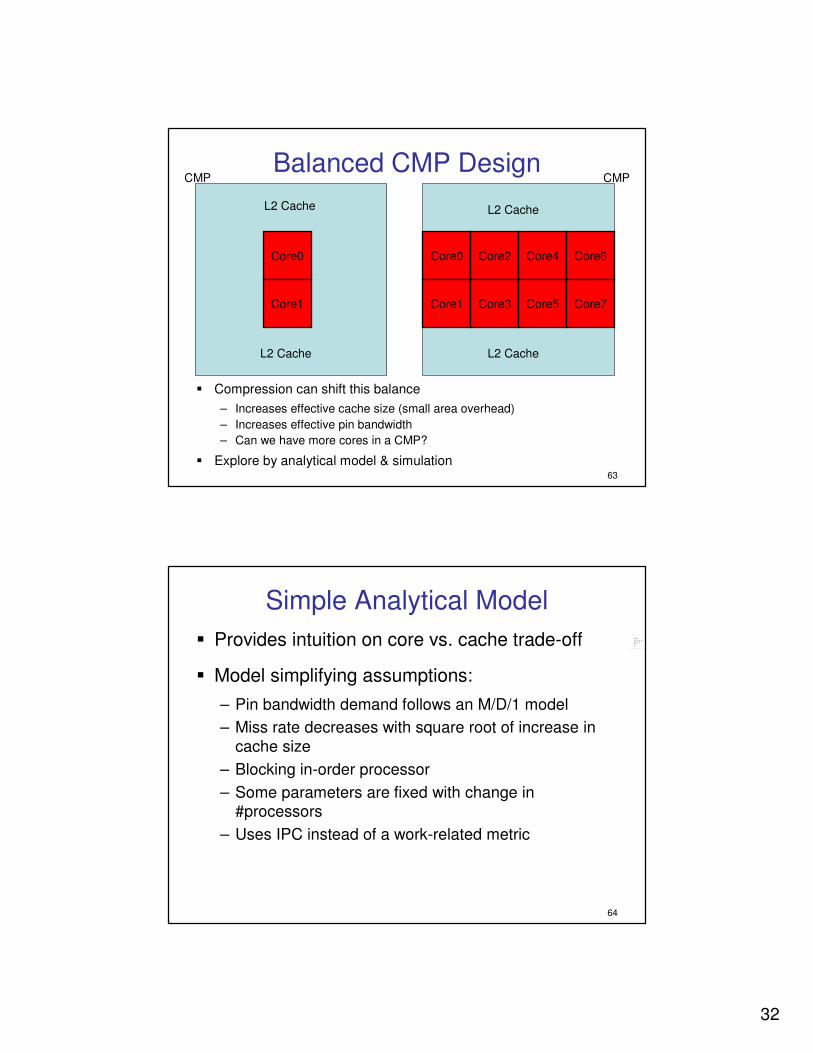
Balanced CMP Design
� Compression can shift this balance
– Increases effective cache size (small area overhead)
– Increases effective pin bandwidth
– Can we have more cores in a CMP?
� Explore by analytical model & simulation
Core0
Core1
Core0
Core1
Core2
Core3
Core4
Core5
Core6
Core7
L2 Cache L2 Cache
L2 CacheL2 Cache
CMP CMP
64
Simple Analytical Model
� Provides intuition on core vs. cache trade-off
� Model simplifying assumptions:
– Pin bandwidth demand follows an M/D/1 model
– Miss rate decreases with square root of increase in
cache size
– Blocking in-order processor
– Some parameters are fixed with change in #processors
– Uses IPC instead of a work-related metric

33
65
Throughput (IPC)
0 2 4 6 8 10 12 14
#Processors
0.0
0.2
0.4
Thr
ough
put (
IPC
)20 GB/sec. B/W- 400 cycles memory latency - 10 misses/1K inst
no compr
cache compr
link compr
cache + link compr
�� Cache compression provides speedups of up to 26% (29% Cache compression provides speedups of up to 26% (29%
when combined with link compressionwhen combined with link compression
�� Higher speedup for optimal configurationHigher speedup for optimal configuration
Cache+Link Compr
Cache compr
Link compr
No compr
66
Simulation (20 GB/sec bandwidth)
0 2 4 6 8 10 12 14
#processors
0
5000
10000
15000
Th
ro
ug
hp
ut
(T
r/1
B c
ycle
s)
zeus
No PF or Compr.
PF Only
Compr Only
Both
�� Compression and prefetching combine to significantly Compression and prefetching combine to significantly
improve throughput improve throughput
34
67
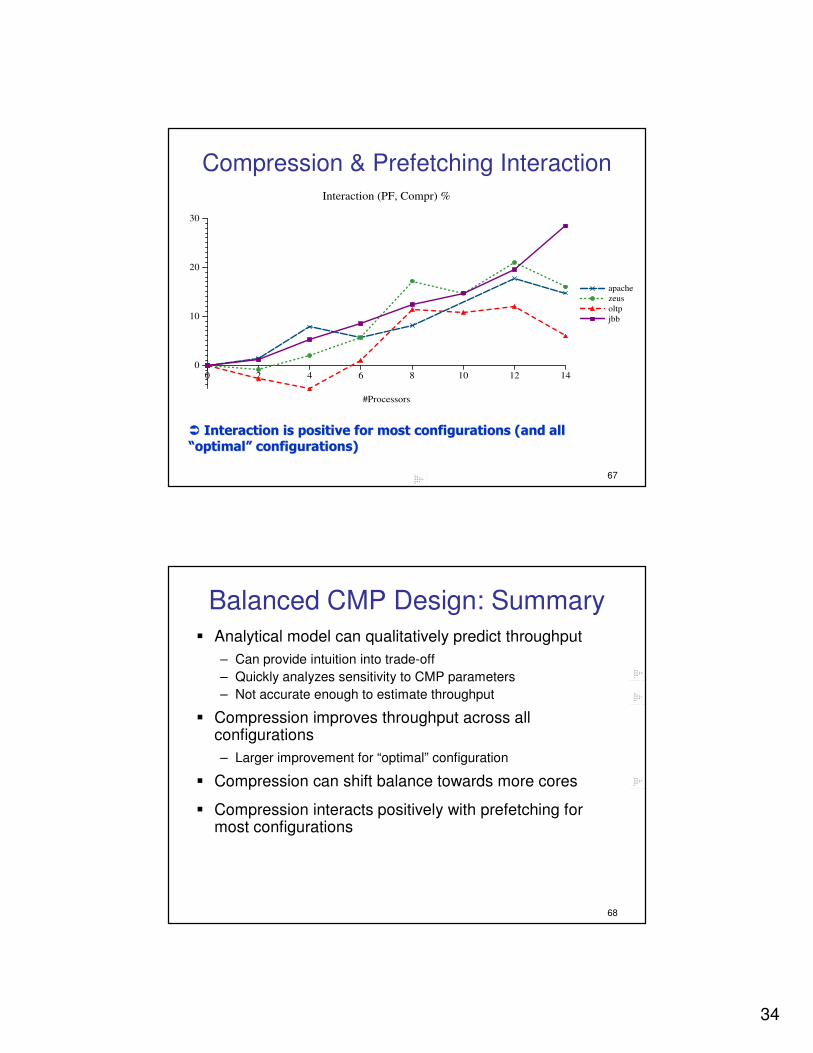
Compression & Prefetching Interaction
0 2 4 6 8 10 12 14
#Processors
0
10
20
30
Interaction (PF, Compr) %
apache
zeus
oltp
jbb
�� Interaction is positive for most configurations (and all Interaction is positive for most configurations (and all
““optimaloptimal”” configurations)configurations)
68
Balanced CMP Design: Summary
� Analytical model can qualitatively predict throughput
– Can provide intuition into trade-off
– Quickly analyzes sensitivity to CMP parameters
– Not accurate enough to estimate throughput
� Compression improves throughput across all configurations
– Larger improvement for “optimal” configuration
� Compression can shift balance towards more cores
� Compression interacts positively with prefetching for most configurations

35
69
Related Work (1/2)
� Memory Compression
– IBM MXT technology
– Compression schemes: X-Match, X-RL
– Significance-based compression: Ekman and Stenstrom
� Virtual Memory Compression
– Wilson et al.: varying compression cache size
� Cache Compression
– Selective compressed cache: compress blocks to half size
– Frequent value cache: frequent L1 values stored in cache
– Hallnor and Reinhardt: Use indirect indexed cache for compression
70
Related Work (2/2)
� Link Compression
– Farrens and Park: address compaction
– Citron and Rudolph: table-based approach for address & data
� Prefetching in CMPs
– IBM’s Power4 and Power5 stride-based prefetching
– Beckmann and Wood: prefetching improves 8-core performance
– Gunasov and Burtscher: One CMP core dedicated to prefetching
� Balanced CMP Design
– Huh et al.: Pin bandwidth a first-order constraint
– Davis et al.: Simple Chip multi-threaded cores maximize throughput

36
71
Conclusions
� CMPs increase demand on caches and pin bandwidth
– Prefetching further increases such demand
� Cache Compression
+ Increases effective cache size - Increases cache access time
� Link Compression decreases bandwidth demand
� Adaptive Compression
– Helps programs that benefit from compression
– Does not hurt programs that are hurt by compression
� CMP Cache and Link Compression
– Improve CMP throughput
– Interact positively with hardware prefetching
� Compression improves CMP performance
72
Backup Slides� Moore’s Law: CPU vs. Memory Speed
� Moore’s Law (1965)
� Software Trends
� Decoupled Variable-Segment Cache
� Classification of L2 Accesses
� Compression Ratios
� Seg. Compr. Ratios SPECint SPECfp Commercial
� Frequent Pattern Histogram
� Segment Histogram
� (LRU) Stack Replacement
� Cache Bits Read or Written
� Sensitivity to L2 Associativity
� Sensitivity to Memory Latency
� Sensitivity to Decompression Latency
� Sensitivity to Cache Line Size
� Phase Behavior
� Commercial CMP Designs
� CMP Compression – Miss Rates
� CMP Compression: Pin Bandwidth Demand
� CMP Compression: Sensitivity to L2 Size
� CMP Compression: Sensitivity to Memory Latency
� CMP Compression: Sensitivity to Pin Bandwidth
� Prefetching Properties (8p)
� Sensitivity to #Cores – OLTP
� Sensitivity to #Cores – Apache
� Analytical Model: IPC
� Model Parameters
� Model - Sensitivity to Memory Latency
� Model - Sensitivity to Pin Bandwidth
� Model - Sensitivity to L2 Miss rate
� Model-Sensitivity to Compression Ratio
� Model - Sensitivity to Decompression Penalty
� Model - Sensitivity to Perfect CPI
� Simulation (20 GB/sec bandwidth) – apache
� Simulation (20 GB/sec bandwidth) – oltp
� Simulation (20 GB/sec bandwidth) – jbb
� Simulation (10 GB/sec bandwidth) – zeus
� Simulation (10 GB/sec bandwidth) – apache
� Simulation (10 GB/sec bandwidth) – oltp
� Simulation (10 GB/sec bandwidth) – jbb
� Compression & Prefetching Interaction – 10 GB/sec pin bandwidth
� Model Error apache, zeus oltp, jbb
� Online Transaction Processing (OLTP)
� Java Server Workload (SPECjbb)
� Static Web Content Serving: Apache
37
73
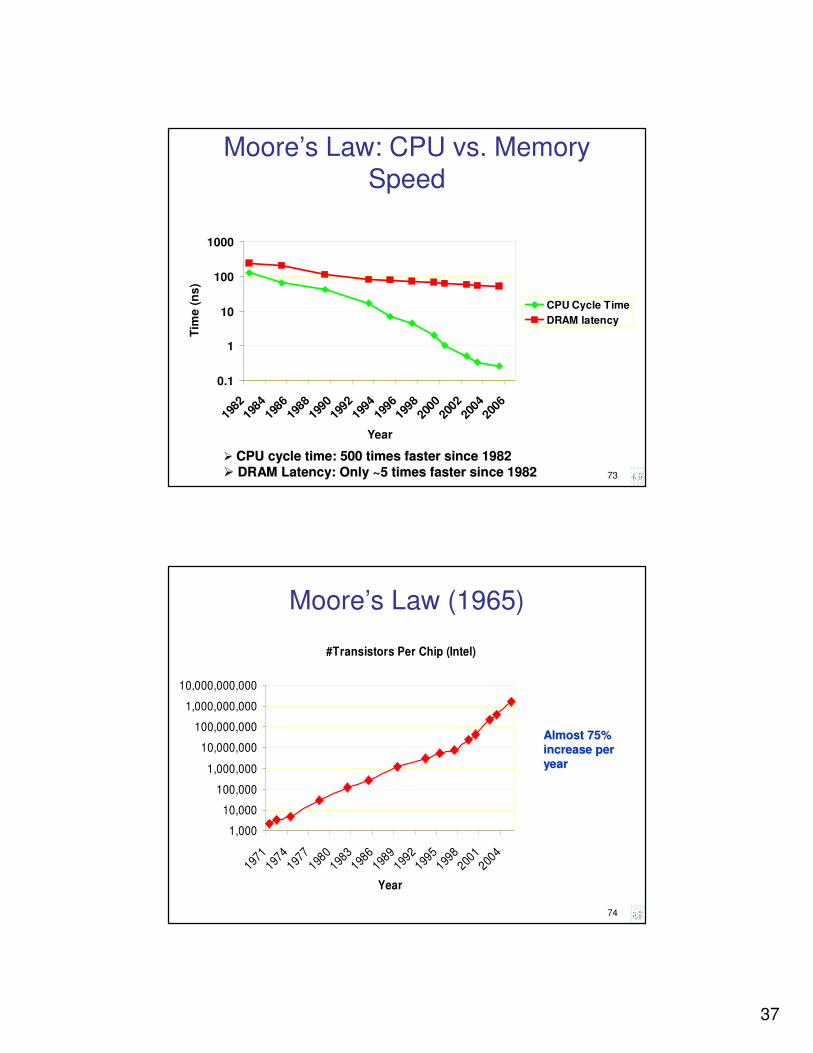
Moore’s Law: CPU vs. Memory Speed
0.1
1
10
100
1000
1982
1984
1986
1988
1990
1992
1994
1996
1998
2000
2002
2004
2006
Year
Tim
e (
ns
)
CPU Cycle Time
DRAM latency
�� CPU cycle time: 500 times faster since 1982CPU cycle time: 500 times faster since 1982
�� DRAM Latency: Only ~5 times faster since 1982DRAM Latency: Only ~5 times faster since 1982
74
Moore’s Law (1965)
#Transistors Per Chip (Intel)
1,000
10,000
100,000
1,000,000
10,000,000
100,000,000
1,000,000,000
10,000,000,000
1971
1974
1977
1980
1983
1986
1989
1992
1995
1998
2001
2004
Year
Almost 75% Almost 75%
increase per increase per
yearyear
38
75
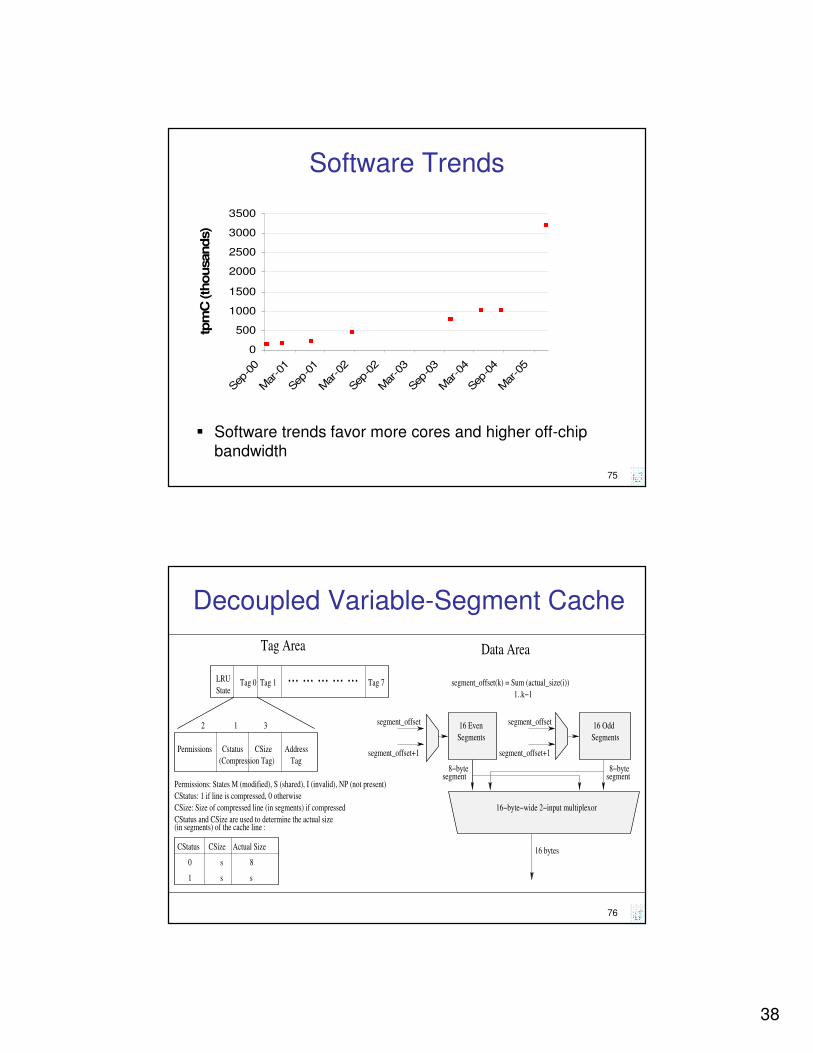
Software Trends
� Software trends favor more cores and higher off-chip
bandwidth
0
500
1000
1500
2000
2500
3000
3500
Sep
-00
Mar
-01
Sep
-01
Mar
-02
Sep
-02
Mar
-03
Sep
-03
Mar
-04
Sep
-04
Mar
-05
tpm
C (th
ousands)
76
LRU
StateTag 7Tag 0 Tag 1 ... ... ... ... ...
Segments
Tag Area Data Area
Cstatus
312
Permissions: States M (modified), S (shared), I (invalid), NP (not present)
CStatus: 1 if line is compressed, 0 otherwise
CSize: Size of compressed line (in segments) if compressed
CStatus and CSize are used to determine the actual size(in segments) of the cache line :
CStatus CSize Actual Size
0 s 8
1 s s
1..k−1
16−byte−wide 2−input multiplexor
16 bytes
Permissions
segment
segment_offset(k) = Sum (actual_size(i))
segment_offset
segment_offset+1
segment_offset
segment_offset+1
16 Even
Segments
segment8−byte 8−byte
Tag
AddressCSize
(Compression Tag)
16 Odd
Decoupled Variable-Segment Cache

39
77
Classification of L2 Accesses
� Cache hits:
• Unpenalized hit: Hit to an uncompressed line that would have
hit without compression
- Penalized hit: Hit to a compressed line that would have hit
without compression
+ Avoided miss: Hit to a line that would NOT have hit without
compression
� Cache misses:
+ Avoidable miss: Miss to a line that would have hit with
compression
• Unavoidable miss: Miss to a line that would have missed
even with compression
78
Compression Ratios
0
2
4
6
Com
prs
sion R
atio
FPC
XRL
BRCL
gzip
bzip gc
cm
cf
twol
f
amm
p
appl
u
equa
ke
swim
apac
heze
usol
tp jbb
L

40
79
Seg. Compression Ratios - SPECint
0
1
2
3
Com
prs
sio
n R
ati
o FPC
Segmented FPC
XRL
Segmented XRL
BRCL
Segmented BRCL
bzip gcc mcf twolf
80
Seg. Compression Ratios - SPECfp
0
1
2
Co
mp
rssio
n R
ati
o FPC
Segmented FPC
XRL
Segmented XRL
BRCL
Segmented BRCL
ammp applu equake swim

41
81
Seg. Compression Ratios - Commercial
0
1
2
Co
mp
rssio
n R
ati
o FPC
Segmented FPC
XRL
Segmented XRL
BRCL
Segmented BRCL
apache zeus oltp jbb
82
Frequent Pattern Histogram
0
20
40
60
80
100
Patt
ern
%
Uncompressible
Compr. 16-bits
Compr. 8-bits
Compr. 4-bits
Zeros
bzip
bzipgcc
gccmcf
mcftwolf
twolfammp
ammpapplu
appluequake
equakeswim
swimapache
apachezeus
zeusoltp
oltpjbb
jbb

42
83
Segment Histogram
0
20
40
60
80
100P
att
ern
%
8 Segments
7 Segments
6 Segments
5 Segments
4 Segments
3 Segments
2 Segments
1 Segments
bzip gcc mcf twolf ammp applu equake swim apache zeus oltp jbb
84
� Differentiate penalized hits and avoided misses?
– Only hits to top half of the tags in the LRU stack are penalized hits
� Differentiate avoidable and unavoidable misses?
� Is not dependent on LRU replacement
– Any replacement algorithm for top half of tags
– Any stack algorithm for the remaining tags
(LRU) Stack Replacement
16)( )()(
1)(≤⇔∑
=
=
kLRUiLRU
iLRUiCSizeMiss(k)Avoidable_

43
85
Cache Bits Read or Written
0
1
2
No
rmali
zed
Bit
s R
ead
/Wri
tten
Never
Always
Adaptive
bzip gcc mcf twolf ammp applu equake swim apache zeus oltp jbb
86
Sensitivity to L2 Associativity
0.0
0.5
1.0
Norm
ali
zed R
unti
me
apache
Never
Always
Adaptive
4M
/2
6.1
4M
/4
5.5
4M
/8
4.9
4M
/16
4.5
0.0
0.5
1.0
Norm
ali
zed R
unti
me
mcf
Never
Always
Adaptive
4M
/2
6653
4M
/4
22.8
4M
/8
10.8
4M
/16
9.1

44
87
Sensitivity to Memory Latency
0.0
0.5
1.0
No
rmali
zed
Ru
nti
me
mcf
Never
Always
Adaptive
20010.8
30010.8
40010.8
50010.8
60010.8
70010.8
80010.8
0.0
0.5
1.0N
orm
ali
zed
Ru
nti
me
apache
Never
Always
Adaptive
2004.9
3004.9
4004.9
5004.9
6004.9
7004.9
8004.9
88
Sensitivity to Decompression Latency
0 5 10 15 20 25
Decompression Latency (Cycles)
0.0
0.5
1.0
1.5
Norm
ali
zed R
unti
me
ammp
never
always
adapt
0 5 10 15 20 25
Decompression Latency (Cycles)
0.0
0.5
1.0
Norm
ali
zed R
unti
me
mcf
never
always
adapt

45
89
Sensitivity to Cache Line Size
0.0
0.5
1.0
No
rmali
zed
Ru
nti
me
zeus
Never
Always
Adaptive
160.36
320.57
640.98
1281.57
2562.55
0.0
0.5
1.0
No
rmali
zed
Ru
nti
me
mcf
Never
Always
Adaptive
160.75
321.34
643.05
1288.34
25616.75 Pin Bandwidth
Demand
90
Phase BehaviorPredictor Value (K)Predictor Value (K)
Cache Size (MB)Cache Size (MB)
0 1 2 3 4
-200
-100
0
100
200
GC
P (x
1000
)
0 1 2 3 4
Time (Billion Cycles)
0
2
4
6
8
Eff
ectiv
e C
ache
Siz
e (M
B)

46
91
Commercial CMP Designs
� IBM Power5 Chip:
– Two processor cores, each 2-way multi-threaded
– ~1.9 MB on-chip L2 cache
• < 0.5 MB per thread with no sharing
• Compare with 0.75 MB per thread in Power4+
– Est. ~16GB/sec. max. pin bandwidth
� Sun’s Niagara Chip:
– Eight processor cores, each 4-way multi-threaded
– 3 MB L2 cache
• < 0.4 MB per core, < 0.1 MB per thread with no sharing
– Est. ~22 GB/sec. pin bandwidth
92
CMP Compression – Miss Rates
0.0
0.5
1.0
Norm
ali
zed M
issra
te
No Compression
L2 Compression
15.2
apache
11.3
zeus
3.3
oltp
3.5
jbb
75.2
art
9.3
apsi
17.5
fma3d
5.1
mgrid
47
93
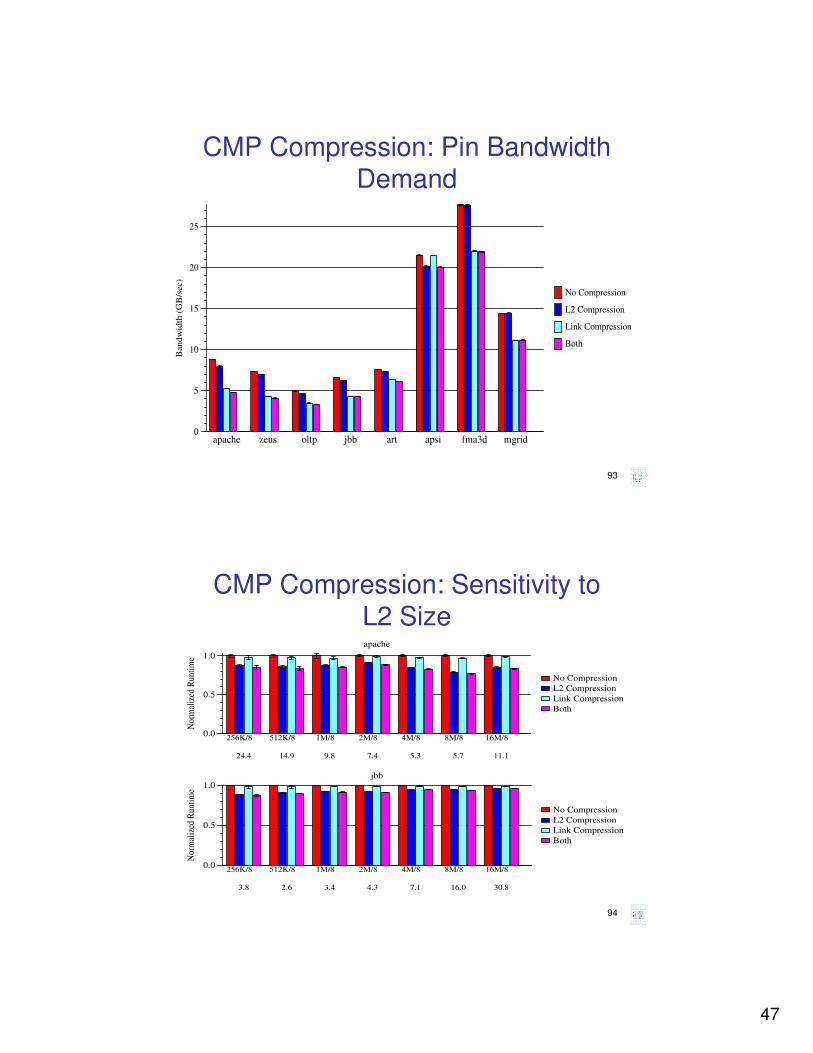
CMP Compression: Pin Bandwidth Demand
0
5
10
15
20
25
Bandw
idth
(G
B/s
ec)
No Compression
L2 Compression
Link Compression
Both
apache zeus oltp jbb art apsi fma3d mgrid
94
CMP Compression: Sensitivity to L2 Size
0.0
0.5
1.0
Nor
mal
ized
Run
tim
e
jbb
No Compression
L2 Compression
Link Compression
Both
256K/8
3.8
512K/8
2.6
1M/8
3.4
2M/8
4.3
4M/8
7.1
8M/8
16.0
16M/8
30.8
0.0
0.5
1.0
Nor
mal
ized
Run
tim
e
apache
No Compression
L2 Compression
Link Compression
Both
256K/8
24.4
512K/8
14.9
1M/8
9.8
2M/8
7.4
4M/8
5.3
8M/8
5.7
16M/8
11.1
48
95
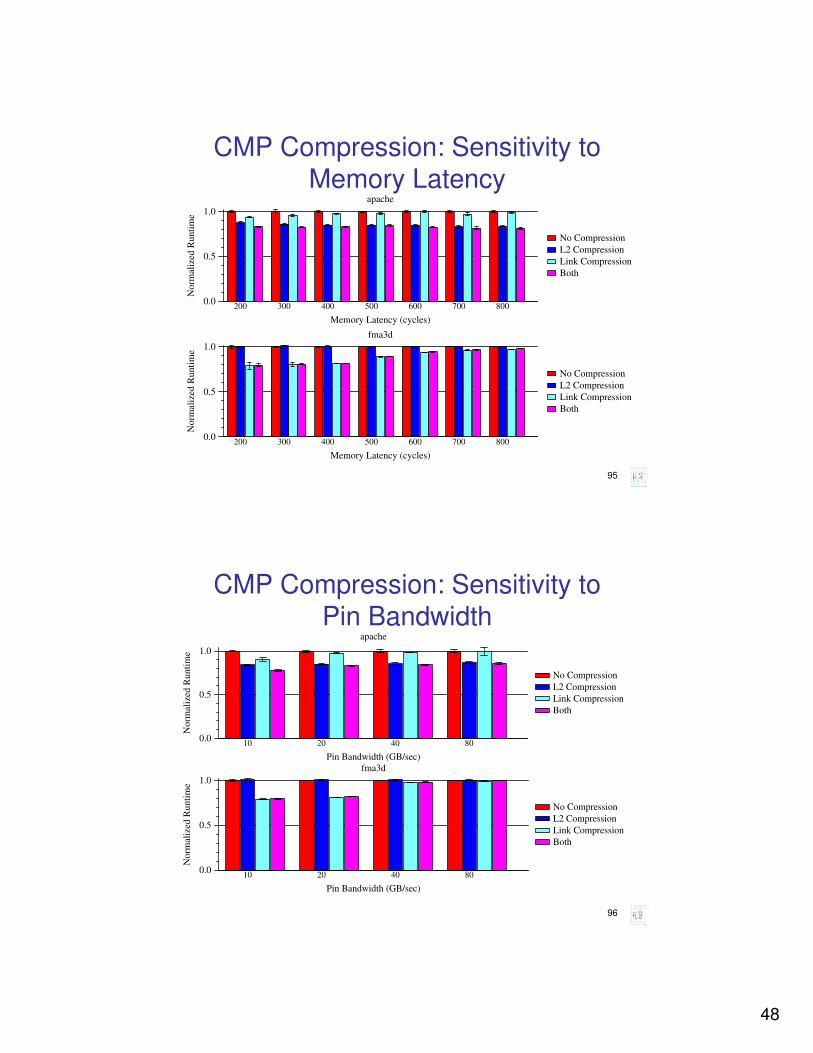
CMP Compression: Sensitivity to Memory Latency
Memory Latency (cycles)
0.0
0.5
1.0
No
rmal
ized
Ru
nti
me
apache
No Compression
L2 Compression
Link Compression
Both
200 300 400 500 600 700 800
Memory Latency (cycles)
0.0
0.5
1.0
No
rmal
ized
Ru
nti
me
fma3d
No Compression
L2 Compression
Link Compression
Both
200 300 400 500 600 700 800
96
CMP Compression: Sensitivity to Pin Bandwidth
Pin Bandwidth (GB/sec)
0.0
0.5
1.0
Norm
aliz
ed R
unti
me
fma3d
No Compression
L2 Compression
Link Compression
Both
10 20 40 80
Pin Bandwidth (GB/sec)
0.0
0.5
1.0
Norm
aliz
ed R
unti
me
apache
No Compression
L2 Compression
Link Compression
Both
10 20 40 80
49
97
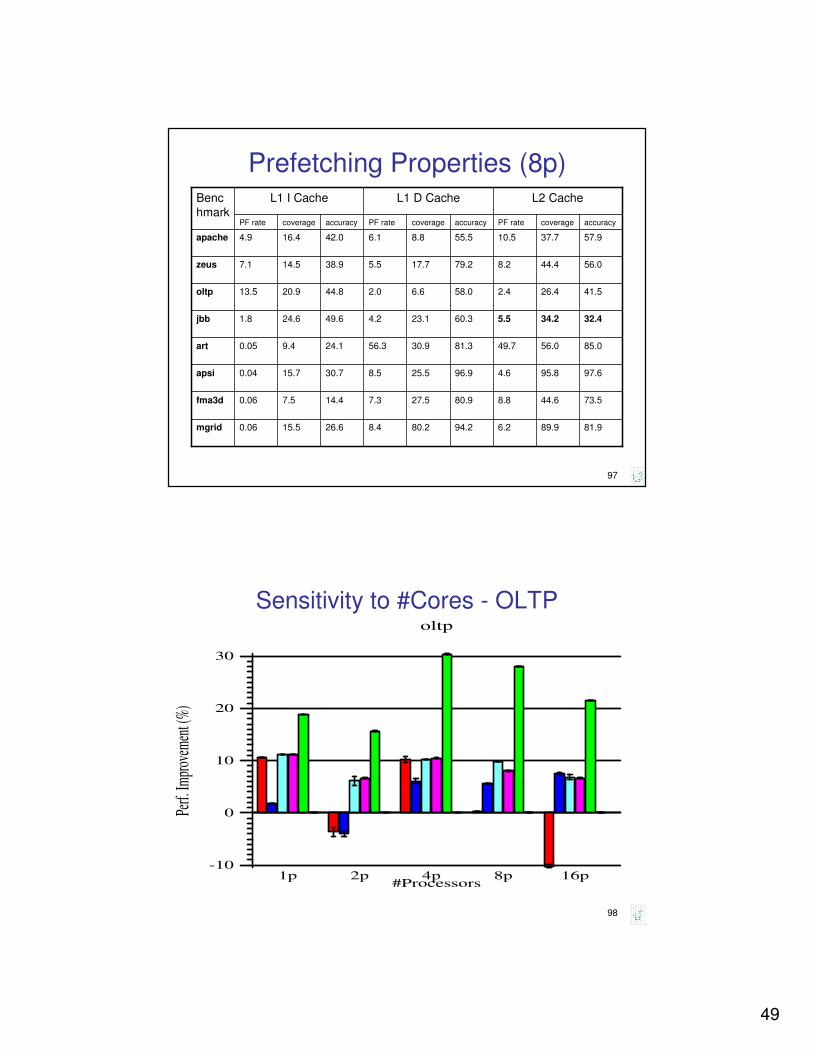
Prefetching Properties (8p)
81.989.96.294.280.28.426.615.50.06mgrid
73.544.68.880.927.57.314.47.50.06fma3d
97.695.84.696.925.58.530.715.70.04apsi
85.056.049.781.330.956.324.19.40.05art
32.434.25.560.323.14.249.624.61.8jbb
41.526.42.458.06.62.044.820.913.5oltp
56.044.48.279.217.75.538.914.57.1zeus
57.937.710.555.58.86.142.016.44.9apache
accuracycoveragePF rateaccuracycoveragePF rateaccuracycoveragePF rate
L2 CacheL1 D CacheL1 I CacheBenc
hmark
98
Sensitivity to #Cores - OLTP
#Processors
-10
0
10
20
30
Perf.
Impr
ovem
ent (
%)
oltp
1p 2p 4p 8p 16p

50
99
Sensitivity to #Cores - Apache
#Processors
0
20
40
60
80
Perf.
Impr
ovem
ent (
%)
apache
1p 2p 4p 8p 16p
100
Analytical Model: IPC
)..(
1)(..
)(
22Nkmc
NsharersNyMissPenaltdpCPI
NNIPC
p
avLPerfectL
−
+−++
=
α
yLinkLatencncyMemoryLateyMissLatenc L +=2
)).().(1.(2
).().(
2
2
2
XSMissrateNIPC
XSMissrateNIPCXyLinkLatenc
pL
pL
−
+=

51
101
Model Parameters
� Divide chip area between cores and caches
– Area of one (in-order) core = 0.5 MB L2 cache
– Total chip area = 16 cores, or 8 MB cache
– Core frequency = 5 GHz
– Available bandwidth = 20 GB/sec.
� Model Parameters (hypothetical benchmark)
– Compression Ratio = 1.75
– Decompression penalty = 0.4 cycles per instruction
– Miss rate = 10 misses per 1000 instructions for 1proc, 8 MB Cache
– IPC for one processor, perfect cache = 1
– Average #sharers per block = 1.3 (for #proc > 1)
102
Model - Sensitivity to Memory Latency
�� CompressionCompression’’s impact similar on both extremess impact similar on both extremes
�� Compression can shift optimal configuration towards more Compression can shift optimal configuration towards more
cores (though not significantly)cores (though not significantly)
0 2 4 6 8 10 12 14
#Processors
0.0
0.5
1.0
Th
rou
gh
put
(IP
C)
200 cycle mem. lat..- no compr
200 cycle mem. lat..- cache + link compr
300 cycle mem. lat..- no compr
300 cycle mem. lat..- cache + link compr
400 cycle mem. lat..- no compr
400 cycle mem. lat..- cache + link compr
600 cycle mem. lat..- no compr
600 cycle mem. lat..- cache + link compr
800 cycle mem. lat..- no compr
800 cycle mem. lat..- cache + link compr
52
103
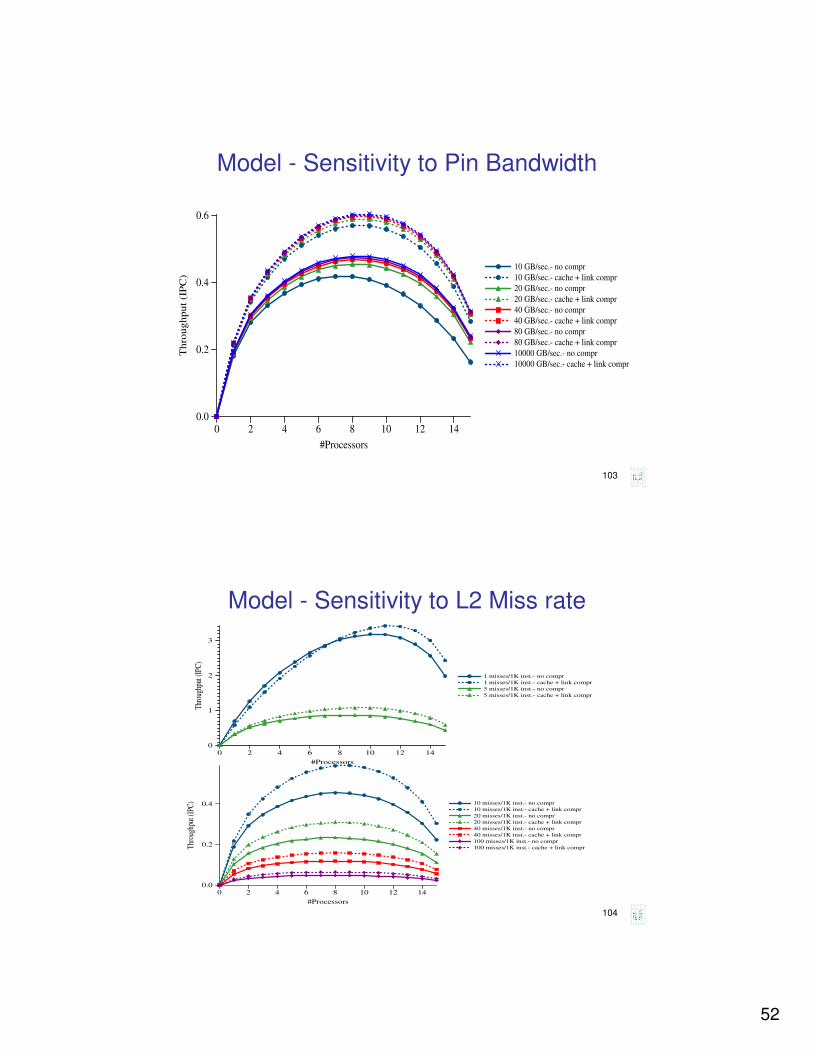
Model - Sensitivity to Pin Bandwidth
0 2 4 6 8 10 12 14
#Processors
0.0
0.2
0.4
0.6
Th
rou
gh
pu
t (I
PC
)
10 GB/sec.- no compr
10 GB/sec.- cache + link compr
20 GB/sec.- no compr
20 GB/sec.- cache + link compr
40 GB/sec.- no compr
40 GB/sec.- cache + link compr
80 GB/sec.- no compr
80 GB/sec.- cache + link compr
10000 GB/sec.- no compr
10000 GB/sec.- cache + link compr
104
Model - Sensitivity to L2 Miss rate
0 2 4 6 8 10 12 14
#Processors
0.0
0.2
0.4
Thr
ough
put (
IPC
) 10 misses/1K inst.- no compr
10 misses/1K inst.- cache + link compr
20 misses/1K inst.- no compr
20 misses/1K inst.- cache + link compr
40 misses/1K inst.- no compr
40 misses/1K inst.- cache + link compr
100 misses/1K inst.- no compr
100 misses/1K inst.- cache + link compr
0 2 4 6 8 10 12 14
#Processors
0
1
2
3
Thr
ough
put (
IPC
)
1 misses/1K inst.- no compr
1 misses/1K inst.- cache + link compr
5 misses/1K inst.- no compr
5 misses/1K inst.- cache + link compr
53
105
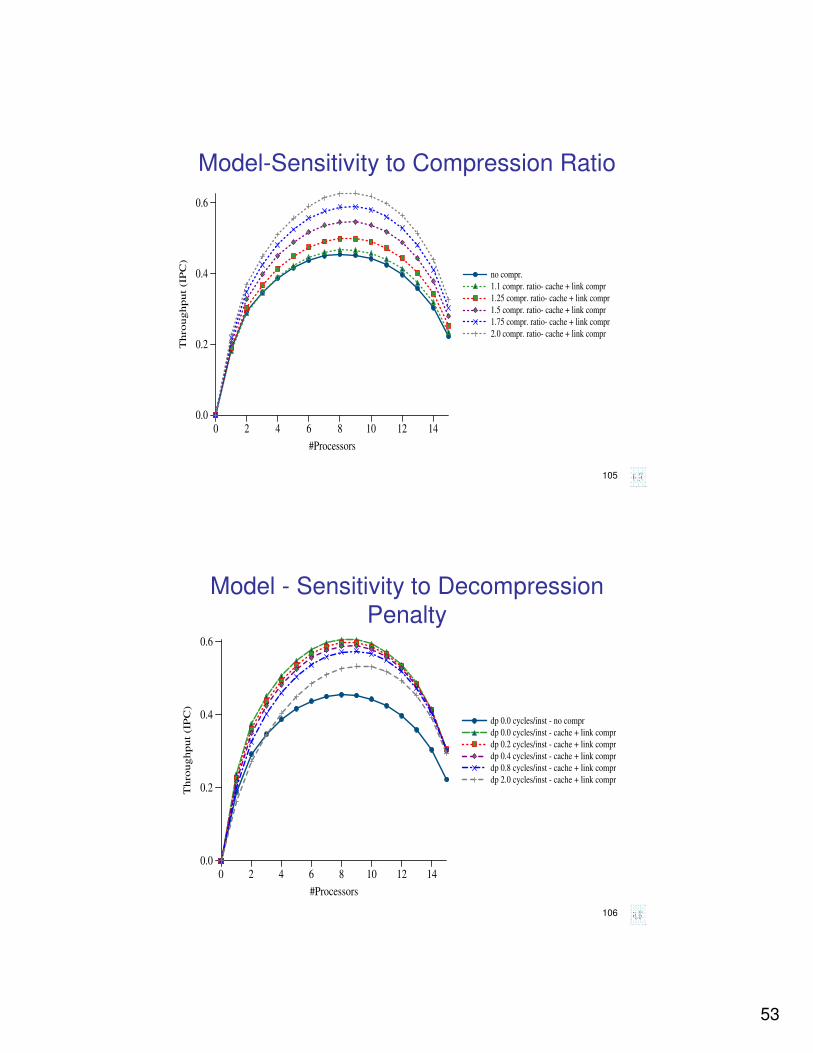
Model-Sensitivity to Compression Ratio
0 2 4 6 8 10 12 14
#Processors
0.0
0.2
0.4
0.6
Th
rou
gh
pu
t (I
PC
)
no compr.
1.1 compr. ratio- cache + link compr
1.25 compr. ratio- cache + link compr
1.5 compr. ratio- cache + link compr
1.75 compr. ratio- cache + link compr
2.0 compr. ratio- cache + link compr
106
Model - Sensitivity to Decompression
Penalty
0 2 4 6 8 10 12 14
#Processors
0.0
0.2
0.4
0.6
Thro
ug
hp
ut
(IP
C)
dp 0.0 cycles/inst - no compr
dp 0.0 cycles/inst - cache + link compr
dp 0.2 cycles/inst - cache + link compr
dp 0.4 cycles/inst - cache + link compr
dp 0.8 cycles/inst - cache + link compr
dp 2.0 cycles/inst - cache + link compr
54
107
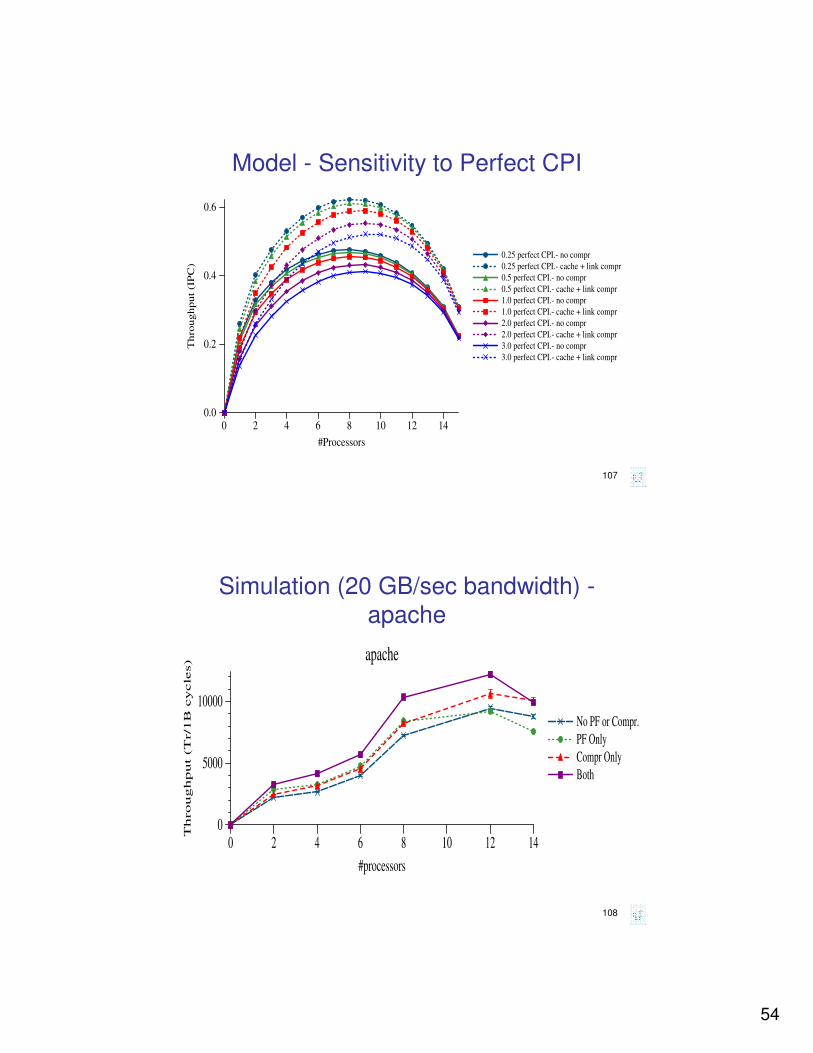
Model - Sensitivity to Perfect CPI
0 2 4 6 8 10 12 14
#Processors
0.0
0.2
0.4
0.6
Th
rou
gh
pu
t (I
PC
)
0.25 perfect CPI.- no compr
0.25 perfect CPI.- cache + link compr
0.5 perfect CPI.- no compr
0.5 perfect CPI.- cache + link compr
1.0 perfect CPI.- no compr
1.0 perfect CPI.- cache + link compr
2.0 perfect CPI.- no compr
2.0 perfect CPI.- cache + link compr
3.0 perfect CPI.- no compr
3.0 perfect CPI.- cache + link compr
108
Simulation (20 GB/sec bandwidth) -
apache
0 2 4 6 8 10 12 14
#processors
0
5000
10000
Throughput (
Tr/1B
cycles)
apache
No PF or Compr.
PF Only
Compr Only
Both

55
109
Simulation (20 GB/sec bandwidth) -
oltp
0 2 4 6 8 10 12 14
#processors
0
500
1000
1500
Throughput
(T
r/1
B c
ycle
s)
oltp
No PF or Compr.
PF Only
Compr Only
Both
110
Simulation (20 GB/sec bandwidth) - jbb
0 2 4 6 8 10 12 14
#processors
0
20000
40000
60000
80000
100000
Throughput (
Tr/1B
cycles)
jbb
No PF or Compr.
PF Only
Compr Only
Both
56
111
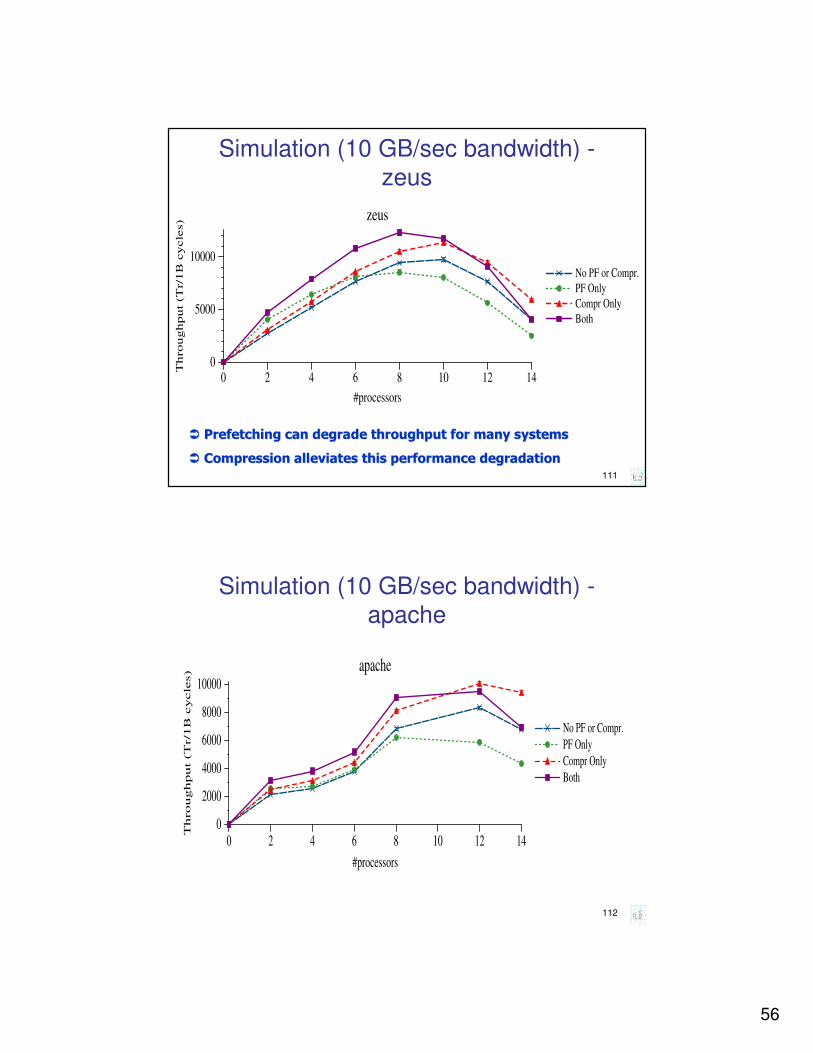
Simulation (10 GB/sec bandwidth) -
zeus
0 2 4 6 8 10 12 14
#processors
0
5000
10000
Throughput
(T
r/1
B c
ycle
s) zeus
No PF or Compr.
PF Only
Compr Only
Both
�� Prefetching can degrade throughput for many systemsPrefetching can degrade throughput for many systems
�� Compression alleviates this performance degradationCompression alleviates this performance degradation
112
Simulation (10 GB/sec bandwidth) -
apache
0 2 4 6 8 10 12 14
#processors
0
2000
4000
6000
8000
10000
Th
ro
ug
hp
ut
(T
r/1
B c
ycle
s)
apache
No PF or Compr.
PF Only
Compr Only
Both
57
113
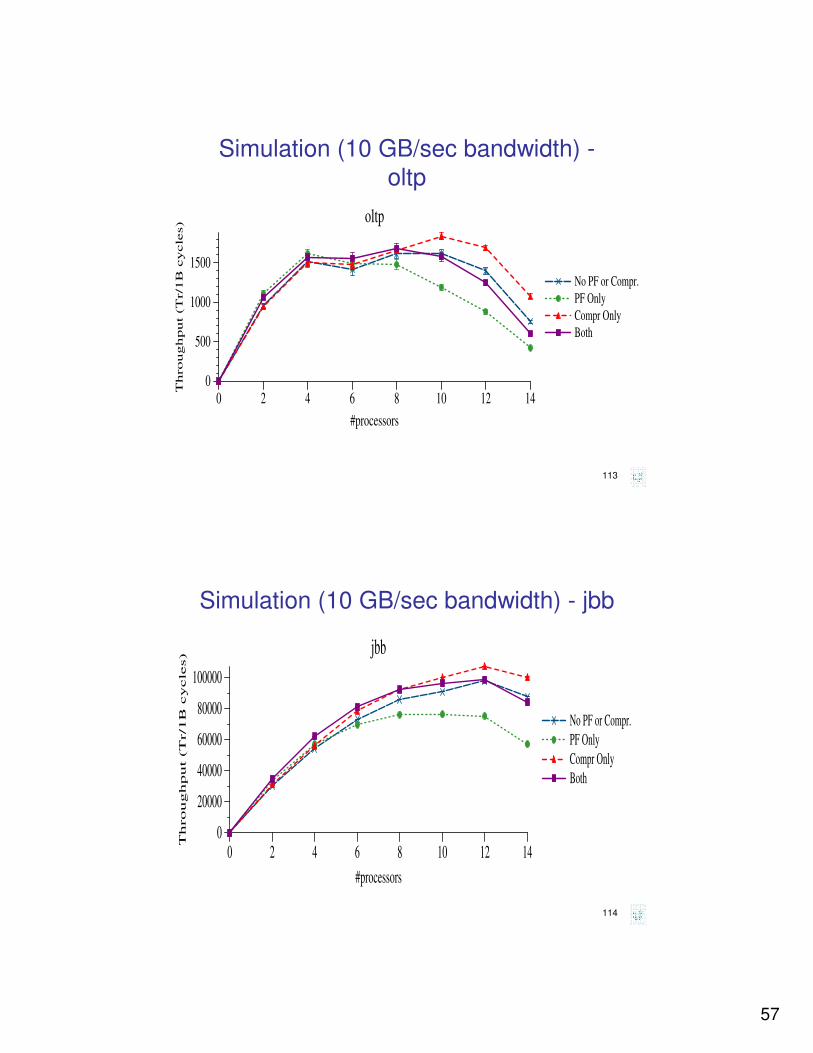
Simulation (10 GB/sec bandwidth) -
oltp
0 2 4 6 8 10 12 14
#processors
0
500
1000
1500
Th
ro
ug
hp
ut
(T
r/1
B c
ycle
s)
oltp
No PF or Compr.
PF Only
Compr Only
Both
114
Simulation (10 GB/sec bandwidth) - jbb
0 2 4 6 8 10 12 14
#processors
0
20000
40000
60000
80000
100000
Throughput (
Tr/1B
cycles)
jbb
No PF or Compr.
PF Only
Compr Only
Both

58
115
Compression & Prefetching Interaction
– 10 GB/sec pin bandwidth
�� Interaction is positive for most configurations (and all Interaction is positive for most configurations (and all
““optimaloptimal”” configurations)configurations)
0 2 4 6 8 10 12 14
#Processors
0
10
20
30
Interaction (PF, Compr) %
apache
zeus
oltp
jbb
116
Model Error – apache, zeus
0 2 4 6 8 10 12 14
#Processors
0
2000
4000
6000
8000
10000
Tra
ns.
Per
1B
Cy
cle
s
apache
Model_no compr
Model_cache&link compr.
Simulation_no compr.
Simulation_cache&link compr.
0 2 4 6 8 10 12 14
#Processors
0
5000
10000
Tra
ns.
Per
1B
Cy
cle
s
zeus
Model_no compr
Model_cache&link compr.
Simulation_no compr.
Simulation_cache&link compr.

59
117
Model Error – oltp, jbb
0 2 4 6 8 10 12 14
#Processors
0
500
1000
1500
2000
2500
Tra
ns.
Per
1B
Cycle
soltp
Model_no compr
Model_cache&link compr.
Simulation_no compr.
Simulation_cache&link compr.
0 2 4 6 8 10 12 14
#Processors
0
50000
100000
Tra
ns.
Per
1B
Cy
cle
s
jbb
Model_no compr
Model_cache&link compr.
Simulation_no compr.
Simulation_cache&link compr.
118
Online Transaction Processing (OLTP)
� DB2 with a TPC-C-like workload.
– Based on the TPC-C v3.0 benchmark.
– We use IBM’s DB2 V7.2 EEE database management system and an IBM benchmark kit to build the database and emulate users.
– 5 GB 25000-warehouse database on eight raw disks and an additional dedicated database log disk.
– We scaled down the sizes of each warehouse by maintaining the reduced ratios of 3 sales districts per warehouse, 30 customers per district, and 100 items per warehouse (compared to 10, 30,000 and 100,000 required by the TPC-C specification).
– Think and keying times for users are set to zero.
– 16 users per processor
– Warmup interval: 100,000 transactions

60
119
Java Server Workload (SPECjbb)
� SpecJBB.
– We used Sun’s HotSpot 1.4.0 Server JVM and Solaris’s
native thread implementation
– The benchmark includes driver threads to generate
transactions
– System heap size to 1.8 GB and the new object heap size to
256 MB to reduce the frequency of garbage collection
– 24 warehouses, with a data size of approximately 500 MB.
120
Static Web Content Serving: Apache
� Apache.
– We use Apache 2.0.39 for SPARC/Solaris 9 configured to use pthread
locks and minimal logging at the web server
– We use the Scalable URL Request Generator (SURGE) as the client.
– SURGE generates a sequence of static URL requests which exhibit
representative distributions for document popularity, document sizes,
request sizes, temporal and spatial locality, and embedded document
count
– We use a repository of 20,000 files (totaling ~500 MB)
– Clients have zero think time
– We compiled both Apache and Surge using Sun’s WorkShop C 6.1
with aggressive optimization





























