Embed Size (px)
Citation preview

Sandia is a multiprogram laboratory operated by Sandia Corporation, a Lockheed Martin Company,for the United States Department of Energyʼs National Nuclear Security Administration
under contract DE-AC04-94AL85000.
Brett W. BaderSandia National Laboratories
NSF Tensor Workshop
February 20, 2009
Unusual Tensor Decompositions for Informatics Applications

Acknowledgements
• Richard Harshman (Univ. Western Ontario)
• Peter Chew (Sandia)
• Tammy Kolda (Sandia)
• Ahmed Abdelali (NMSU)

Tucker
Tensor Decompositions
+ + ...
3-way DEDICOM
PARAFAC
Tensor
PARAFAC2
...and many more!
Each provides a different interpretation of the data

Sandia is a multiprogram laboratory operated by Sandia Corporation, a Lockheed Martin Company,for the United States Department of Energyʼs National Nuclear Security Administration
under contract DE-AC04-94AL85000.
Temporal Analysis of Enron email using 3-way DEDICOM

Three-way DEDICOM
• Introduced by Harshman (1978)• DEcomposition into DIrectional COMponents• Columns of A are not necessarily orthogonal• Central matrix R contains asymmetric information from X• *Unique* solution with enough slices of X with sufficient variation- i.e., no rotation of A possible- greater confidence in interpretation of results• Alternating algorithms; least-squares and approximations• Early applications:- World trade (import/export matrices)- Car switching• Variations: constrainted DEDICOM
=X AR AT
Xx = ADkRDkAT k = 1, . . . ,K
DD

Application: Enron Email Analysis
• Links consist of email communications
• What can we learn about this network strictly from their communication patterns? (Social network analysis)
David
Ellen
Bob
Frank
Alice Carl
IngridHenk
Gary

!
"#$%&'()
*&$+,#-+.#/,(01+&.(/2(3,&/,(0/&4
!"#$"%"&'"(
!"#$"
)(*+$#,-
!"#$"
.$+(#/01#,(*'"2
!"#$"
31-/01#,(*'"2
!"#$"
3("(#1*'$"
!"#$"
)$#*4
56(#'71
!"#$"
/!"(#28
/9(#:'7(-
!"#$"
;#$1<=1"<
!"#$"
.'>(?'"(-
!"#$"
@#1"->$#*1*'$"
9(#:'7(-
!"#$"/A$#>
+,5(6783(9+.#/,+:(3,'&$;(7&/%4<((=1'(.'+>(+:?/(>'.(@#.1(&'4&'?',.+.#A'?(/2(.1'(9'@
B/&C(D'&E+,.#:'(3FE1+,$'(G9BD3HI(+,5(.1'(9'@(B/&C(J./EC(3FE1+,$'(G9BJ3I(./
:'+&,(/2(.1'#&('F4'&#',E'?(@#.1(':'E.&/,#E(.&+5#,$(+,5(+,;(4&/K:'>?(.1';(2/&'?''(@#.1
','&$;('L.&+5#,$(+?(#.('A/:A'?<((M,(+55#.#/,N(.1'(.'+>(>'.(@#.1(&'4&'?',.+.#A'?(/2(O#/5'FN(+
2#,+,E#+:(?/2.@+&'(2#&>N(.1+.(#?(5'A':/4#,$(+(,'@('L.&+5#,$(?;?.'>(2/&(.1'(9BD3H(+,5
@1/?'(&#?C(>+,+$'>',.(?/2.@+&'(#?(>+5'(+A+#:+K:'(/,(3*P(./(#.?(E%?./>'&?<((=1'
>'>K'&?(/2(.1'(.'+>(+:?/(.//C(E/%&?'?(#,(','&$;(5'&#A+.#A'?(+,5(2#,+,E#+:(+,5(','&$;
>+&C'.(.&+5#,$<
!"#$%&'()*
=1'(K%?#,'??(E/,E'4.(%,5'&:;#,$(3*P(#?(?#>4:'<((=&+5#,$(/,(3*P(%?#,$(.1'
M,.'&,'.(&'4:+E'?(>+&C'.#,$(.1+.(4&'A#/%?:;(.//C(4:+E'(K;(.':'41/,'(+,5(2+F<((*,(3*PN
3,&/,(>+&C'.'&?(+&'(/,(/,'(?#5'(/2('A'&;(.&+5'(Q%?.(+?(.1';(+&'(@1',(.1';(%?'(41/,'(+,5
2+F(./(.&+5'<((3,&/,*,:#,'(#?(+(E/>4%.'&(?;?.'>(/4'&+.'5(K;(+,(3,&/,(?%K?#5#+&;(E+::'5
3,&/,(9'.@/&C?N(M,E<((3,&/,(>+&C'.#,$(?%K?#5#+&#'?(3,&/,(6/@'&(D+&C'.#,$N(M,E<(
G3D6MI(+,5(3,&/,(9/&.1(R>'&#E+N(M,E<((G39RI(E/,5%E.(3,&/,S?(':'E.&#E(4/@'&(+,5
,+.%&+:($+?(.&+5#,$N(&'?4'E.#A':;+,,"#$%&'()(#?(+(?.;:#-'5(/&$+,#-+.#/,(E1+&.(/2(3,&/,(0/&4<
?1/@#,$(@1'&'(3*P(#?(:/E+.'5(#,(&':+.#/,(./($+?(+,5(4/@'&(>+&C'.#,$N(+,5(.1'(4#4':#,'?<
3*P(%?'?(+(/,'L./L>+,;(.&+5#,$(>/5':N(@1'&'(3,&/,(.+C'?(/,'(?#5'(/2('A'&;
.&+,?+E.#/,(.+C#,$(4:+E'(/,(3*P<((3*P(5#22'&?(2&/>(.&+5#.#/,+:('FE1+,$'?(:#C'(.1'(9BJ3
Case Study: Enron
N D 99 F M A M J J A S O N D 00 F M A M J J A S O N D 01 F M A M J J A S O N D 02 F M A M J0
500
1000
1500
2000
2500
3000
3500
Month
Messages
Figure 1: Number of emails per month in the Enron email graph.
biasing from prolific emailers. Other weightings are possibleas well.
An obvious di!culty in dealing with the Enron corpusis the lack of information regarding the former employees.Without access to a corporate directory or organizationalchart at Enron at the time of these emails, it is di!cult toascertain the validity of our results and assess the perfor-mance of the DEDICOM model. Other researchers usingthe Enron corpus have had this same problem, and informa-tion on the participants has been collected and slowly madeavailable.
The Priebe data set [32] provided partial information onthe 184 employees of the small Enron network, which ap-pears to be based largely on information collected by Shettyand Adibi [36]. It provides most employees’ position andbusiness unit. To facilitate a better analysis of the DEDI-COM results, we collected extra information on the partic-ipants from the email messages themselves. We searchedfor corroborating information of the preexisting data or fornew identification information, such as title, business unit,or manager to help analyze our results. We also collectedsome relevant information posted on the FERC website [9].
5. EXPERIMENTAL RESULTSIn this section we summarize our findings of applying two-
way and three-way DEDICOM on the Enron email network.Our algorithms were written in MATLAB, using sparse ex-tensions of the Tensor Toolbox [2].
Table 1 shows the A and R matrices for a single decompo-sition (p = 3) of the two-way DEDICOM model. The largeadjacency matrix X, showing nonsymmetric relations amongemployees at Enron, related by flows of email, is condensedinto a smaller matrix R giving the same kind of asymmetricrelations but among “types” or abstract idealized individ-uals. In this case, the relations among elements in R areexchanges of email. The latent components are patterns ofthe same kind of flow as among the surface objects, justabstracted into a “higher level” summary of patterns.
DEDICOM does not actually identify clusters, except inspecial circumstances when such clusters happen to exist inthe data as we are partially seeing in the Enron data. Thecomponents or patterns of asymmetric relationships that itidentifies have loadings in A that are continuously-valued,like factor loadings, rather than discrete cluster membershipassignments.
Here, DEDICOM describes the employees by the di"erentlatent dimensions. The first factor (a1) describes an execu-
tive role that fits many of the top executives. The secondfactor (a2) describes a legal role, and the third factor (a3)describes a pipeline employee.
The R matrices show that most of the communication isamong employees that share the same role, as evidenced bythe large diagonal values in R. We do see some asymmetriccommunication. The entries in the lower triangular por-tion are typically larger than the corresponding transposeentry in the upper triangular. This suggests that slightlymore communication “flows up” the management chain than“down.”
As a point of reference, we compute the singular valuedecomposition X = U#V T . Table 1 shows the first threecolumns of the left singular vectors (U matrix) and rightsingular vectors (V matrix). Because X is nearly symmetric,the left and right singular vectors are nearly the same. Anydi"erences between U and V indicate whether the person ismore likely to send mail (U) or receive mail (V).
The SVD solution is somewhat similar to the DEDICOMmodel. Many of the same people are identified and weightedsimilarly by DEDICOM and SVD. However, there are manymore negative entries in SVD than in DEDICOM. The DEDI-COM model also provides directional information betweenthe latent groups in the R matrix that the SVD does notshow.
Table 2 shows the A and R matrices for three instances(p = 2, 3, 4) of the three-way DEDICOM model. The 2-dimensional solution groups the employees largely from thelegal department and those executives dealing with govern-ment and regulatory a"airs. The 3-dimensional solutionadds a another role of top executives, and the 4-dimensionalsolution includes those from the pipeline business in a fourthrole.
The aggregate communication patterns over the 44 monthsamong these 2-4 groups is summarized in the R matrix. Inthe 2-dimensional solution we see that most of the com-munication is within each group as evidenced by the largediagonal elements and small o"-diagonal elements. The 3-dimensional solution shows some communication betweenthe government/regulatory a"airs people and other seniorVP’s (dimensions 2 and 3, respectively). However, the com-munication is substantially asymmetric in that the r2,3 ele-ment is larger than r3,2. This indicates that the VP’s weremostly recipients of messages while the government/regulatorya"airs employees were senders. With the addition of thepipeline employees in the 4-dimensional solution, we see thatthey interact almost exclusively with themselves due to the
Email communications at Enron (1998-2002)
• Enron created energy markets• EnronOnline: e-trading business- natural gas- electric power• Investigations- FERC• energy market manipulation• involved energy traders- SEC• accounting fraud• insider trading

Temporal Social Network Analysis
N D 99 F M A M J J A S O N D 00 F M A M J J A S O N D 01 F M A M J J A S O N D 02 F M A M J0
500
1000
1500
2000
2500
3000
3500
Month
Messages
Figure 1: Number of emails per month in the Enron email graph.
biasing from prolific emailers. Other weightings are possibleas well.
An obvious di!culty in dealing with the Enron corpusis the lack of information regarding the former employees.Without access to a corporate directory or organizationalchart at Enron at the time of these emails, it is di!cult toascertain the validity of our results and assess the perfor-mance of the DEDICOM model. Other researchers usingthe Enron corpus have had this same problem, and informa-tion on the participants has been collected and slowly madeavailable.
The Priebe data set [32] provided partial information onthe 184 employees of the small Enron network, which ap-pears to be based largely on information collected by Shettyand Adibi [36]. It provides most employees’ position andbusiness unit. To facilitate a better analysis of the DEDI-COM results, we collected extra information on the partic-ipants from the email messages themselves. We searchedfor corroborating information of the preexisting data or fornew identification information, such as title, business unit,or manager to help analyze our results. We also collectedsome relevant information posted on the FERC website [9].
5. EXPERIMENTAL RESULTSIn this section we summarize our findings of applying two-
way and three-way DEDICOM on the Enron email network.Our algorithms were written in MATLAB, using sparse ex-tensions of the Tensor Toolbox [2].
Table 1 shows the A and R matrices for a single decompo-sition (p = 3) of the two-way DEDICOM model. The largeadjacency matrix X, showing nonsymmetric relations amongemployees at Enron, related by flows of email, is condensedinto a smaller matrix R giving the same kind of asymmetricrelations but among “types” or abstract idealized individ-uals. In this case, the relations among elements in R areexchanges of email. The latent components are patterns ofthe same kind of flow as among the surface objects, justabstracted into a “higher level” summary of patterns.
DEDICOM does not actually identify clusters, except inspecial circumstances when such clusters happen to exist inthe data as we are partially seeing in the Enron data. Thecomponents or patterns of asymmetric relationships that itidentifies have loadings in A that are continuously-valued,like factor loadings, rather than discrete cluster membershipassignments.
Here, DEDICOM describes the employees by the di"erentlatent dimensions. The first factor (a1) describes an execu-
tive role that fits many of the top executives. The secondfactor (a2) describes a legal role, and the third factor (a3)describes a pipeline employee.
The R matrices show that most of the communication isamong employees that share the same role, as evidenced bythe large diagonal values in R. We do see some asymmetriccommunication. The entries in the lower triangular por-tion are typically larger than the corresponding transposeentry in the upper triangular. This suggests that slightlymore communication “flows up” the management chain than“down.”
As a point of reference, we compute the singular valuedecomposition X = U#V T . Table 1 shows the first threecolumns of the left singular vectors (U matrix) and rightsingular vectors (V matrix). Because X is nearly symmetric,the left and right singular vectors are nearly the same. Anydi"erences between U and V indicate whether the person ismore likely to send mail (U) or receive mail (V).
The SVD solution is somewhat similar to the DEDICOMmodel. Many of the same people are identified and weightedsimilarly by DEDICOM and SVD. However, there are manymore negative entries in SVD than in DEDICOM. The DEDI-COM model also provides directional information betweenthe latent groups in the R matrix that the SVD does notshow.
Table 2 shows the A and R matrices for three instances(p = 2, 3, 4) of the three-way DEDICOM model. The 2-dimensional solution groups the employees largely from thelegal department and those executives dealing with govern-ment and regulatory a"airs. The 3-dimensional solutionadds a another role of top executives, and the 4-dimensionalsolution includes those from the pipeline business in a fourthrole.
The aggregate communication patterns over the 44 monthsamong these 2-4 groups is summarized in the R matrix. Inthe 2-dimensional solution we see that most of the com-munication is within each group as evidenced by the largediagonal elements and small o"-diagonal elements. The 3-dimensional solution shows some communication betweenthe government/regulatory a"airs people and other seniorVP’s (dimensions 2 and 3, respectively). However, the com-munication is substantially asymmetric in that the r2,3 ele-ment is larger than r3,2. This indicates that the VP’s weremostly recipients of messages while the government/regulatorya"airs employees were senders. With the addition of thepipeline employees in the 4-dimensional solution, we see thatthey interact almost exclusively with themselves due to the
Email communications at Enron (1998-2002)
Emails among 184 employeesover 44 months
April
March
January
February
Time series of communication graphs
among employees
(data released by U.S. Federal Energy Regulatory Commission)
Joint work with R. Harshman (UWO) and T. Kolda
DEDICOM
Adjacencyarray

Roles of Employees
−0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7−0.2
−0.1
0
0.1
0.2
0.3
0.4
0.5
0.6J. Dasovich − Employee, Government Relationship ExecutiveJ. Steffes − VP, Government Affairs
R. Shapiro − VP, Regulatory AffairsS. Kean − VP, Chief of Staff
R. Sanders − VP, Enron Wholesale Services
T. JonesFinancial Trading GroupENA Legal
S. ShackletonENA Legal
M. TaylorManagerFinancial Trading GroupENA Legal
Column 1
Colu
mn
2
Bi-plots of two roles
−0.1 0 0.1 0.2 0.3 0.4 0.5 0.6−0.1
0
0.1
0.2
0.3
0.4
0.5
0.6K. WatsonTranswestern Pipeline Company (ETS)
M. LokayAdmin. Asst.Transwestern Pipeline Company (ETS)
L. Donoho − Employee, Transwestern Pipeline Company (ETS)
M. McConnell − Employee, Transwestern Pipeline Company (ETS)L. Blair − Employee, Northern Natural Gas Pipeline (ETS)
L. KitchenPresidentEnron Online
J. LavoratoCEO, Enron America
Column 3
Colu
mn
4
UnaffiliatedExecutiveLegal (ENA)Pipeline (ETS)Energy Trader
role
s
time patterns
LegalExecutive (govʼt a
ffairs)
Executive (trade)
Pipeline4-Dimensional
SolutionEmployee 1 2 3 4
L. Kitchen - President, Enron Online 0.11 -0.09 0.53 0.00
R matrix 440.2 1.6 -15.0 0.41.6 278.3 135.4 1.6
-29.3 70.7 201.6 -6.21.4 -4.6 -7.5 172.3
Figure 1:
1
Identify shared characteristics to
label groupSoft clustering

Communication Patternsro
les
time patterns
• Mostly communication within roles• Some asymmetric exchanges
Legal
role
Gov't
affairs
role
Executive
role
Pipeline
role
157.8
93.5
13.4
13.8
440.2
211.6 286.7
172.4

Temporal Patterns
N D 99 F M A M J J A S O N D 00 F M A M J J A S O N D 01 F M A M J J A S O N D 02 F M A M J0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
Month
No
rma
lize
d s
ca
le
Group 1
Group 2
Group 3
Group 4
Figure 2: Scales in D indicate the strength of participation of each group’s communication over time.
derive useful information from any directed graph. New pos-sibilities include analyzing a network of web tra!c betweenservers over time or perhaps a web/citation graph, whereedges convey authority among vertices. A third mode enterswhen the 2-way data are categorized by time, demographic,click number, or some other feature of the data.
Finally, we suggest a few extensions to the DEDICOMmodel and its application in data mining that we intend topursue. First, constrained DEDICOM [23] is an extensionof DEDICOM that has been suggested in the 90’s and pur-sued more recently. The idea is to put constraints on theA factors themselves so that the columns of A lie in a pre-scribed column space. For example, in the email graph, onemight want to impose a constraint on the first column ofA so that it contains only the top executives. Many othervariations are possible. This procedure allows for includingdomain knowledge or incorporating human understandinginto the problem. Kiers and Takane [23] o"ered an algorithmfor handling di"erent subspace constraints on A. More re-cently, Rocci [33] proposed a new algorithm for fitting anyconstrained DEDICOM model.
Second, a nonnegative factorization of DEDICOM, whereA and/or R are nonnegative, would preserve the non-negativityof the data, which could be desirable in some domains andapplications.
Finally, DEDICOM has been applied to skew-symmetricdata [17] and has yielded some benefits. There might beways to apply this technique to semantic graphs as well.
7. REFERENCES[1] E. Acar, S. A. Camtepe, M. S. Krishnamoorthy, and
B. Yener. Modeling and multiway analysis ofchatroom tensors. In Intelligence and SecurityInformatics: IEEE Intl. Conf. on Intelligence andSecurity Informatics, ISI 2005, volume 3495 of LectureNotes in Computer Science, pages 256–268. SpringerVerlag, 2005.
[2] B. W. Bader and T. G. Kolda. MATLAB tensorclasses for fast algorithm prototyping. TechnicalReport SAND2004-5187, Sandia NationalLaboratories, Albquerque, NM 87185 and Livermore,CA 94550, Oct. 2004. Submitted to ACM Trans.Math. Software.
[3] M. W. Berry and M. Browne. Email surveillance usingnonnegative matrix factorization. In Workshop on
Link Analysis, Counterterrorism and Security, SIAMConf. on Data Mining, Newport Beach, CA, 2005.
[4] J. D. Carroll and J. J. Chang. Analysis of individualdi"erences in multidimensional scaling via an N-waygeneralization of ‘Eckart-Young’ decomposition.Psychometrika, 35:283–319, 1970.
[5] A. Chapanond, M. S. Krishnamoorthy, and B. Yener.Graph theoretic and spectral analysis of Enron emaildata. In Workshop on Link Analysis,Counterterrorism and Security, SIAM Conf. on DataMining, Newport Beach, CA, 2005.
[6] W. W. Cohen. Enron email dataset. Webpage.http://www.cs.cmu.edu/!enron/.
[7] J. E. Dennis, Jr. and R. B. Schnabel. NumericalMethods for Unconstrained Optimization andNonlinear Equations. Prentice-Hall, Englewood Cli"s,NJ, 1983.
[8] J. Diesner and K. M. Carley. Exploration ofcommunication networks from the Enron emailcorpus. In Workshop on Link Analysis,Counterterrorism and Security, SIAM Conf. on DataMining, Newport Beach, CA, 2005.
[9] Federal Energy Regulatory Commision. Ferc:Information released in Enron investigation.http://www.ferc.gov/industries/electric/indus-act/wec/enron/info-release.asp.
[10] C. W. Harris and H. F. Kaiser. Oblique factor analyticsolutions by orthogonal transformations.Psychometrika, 29(4):347–362, 1964.
[11] R. A. Harshman. Foundations of the PARAFACprocedure: models and conditions for an“explanatory” multi-modal factor analysis. UCLAworking papers in phonetics, 16:1–84, 1970.
[12] R. A. Harshman. Models for analysis of asymmetricalrelationships among n objects or stimuli. In FirstJoint Meeting of the Psychometric Society and theSociety for Mathematical Psychology, McMasterUniversity, Hamilton, Ontario, August 1978.http://publish.uwo.ca/!harshman/asym1978.pdf.
[13] R. A. Harshman. Alternating least squares estimationfor the single domain DEDICOM model, 1981.Unpublished technical memorandum, BellLaboratories, Murray Hill, NJhttp://publish.uwo.ca/!harshman/asym1981.pdf.
[14] R. A. Harshman. DEDICOM: A family of models
Enron crisis breaks; investigation begins
Communication patterns over time
role
s
time patterns
LegalGovernment & regulatory affairsTrade executivesPipeline employee
Filed for bankruptcy

Sandia is a multiprogram laboratory operated by Sandia Corporation, a Lockheed Martin Company,for the United States Department of Energyʼs National Nuclear Security Administration
under contract DE-AC04-94AL85000.
Multilingual Text Analysis using PARAFAC2
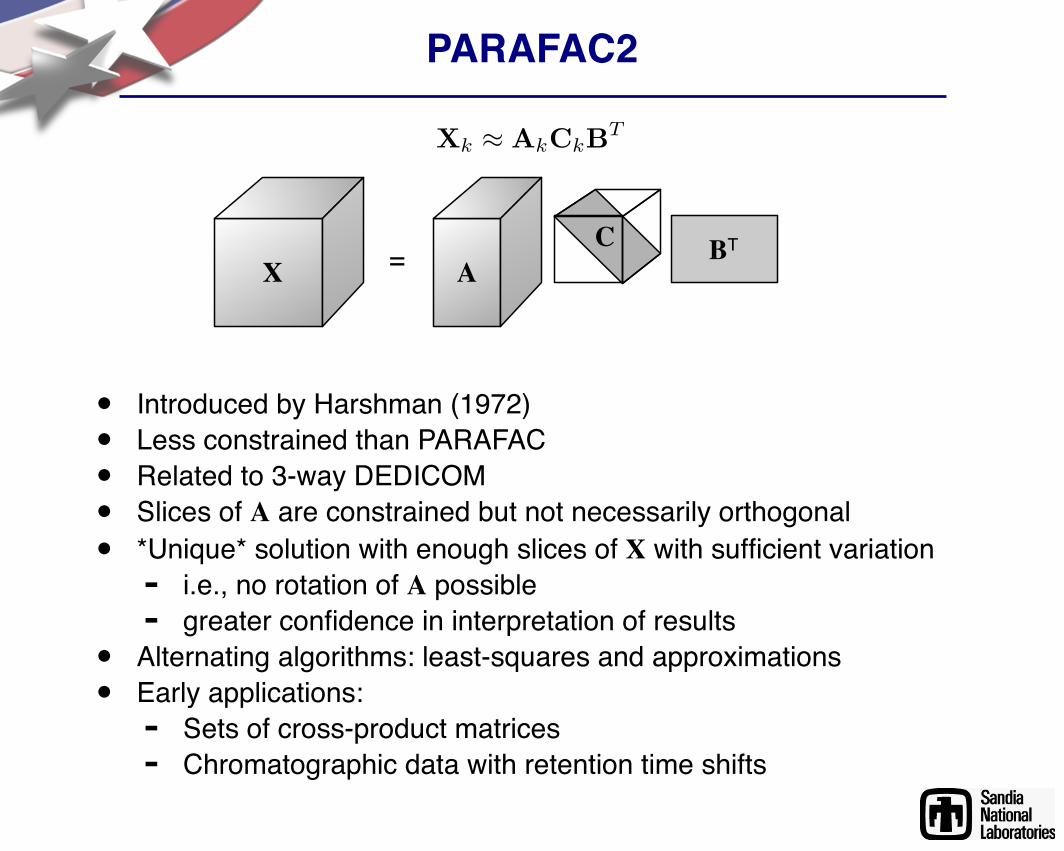
PARAFAC2
• Introduced by Harshman (1972)• Less constrained than PARAFAC• Related to 3-way DEDICOM• Slices of A are constrained but not necessarily orthogonal• *Unique* solution with enough slices of X with sufficient variation- i.e., no rotation of A possible- greater confidence in interpretation of results• Alternating algorithms: least-squares and approximations• Early applications:- Sets of cross-product matrices- Chromatographic data with retention time shifts
= AC BT
X
Xk ! AkCkBT

Cross-language Information Retrieval (CLIR)
Web documents could be in any language
English
French
Arabic
Spanish
EnglishGermanJapaneseFrenchChinese SimplifiedSpanishRussianDutchKoreanPolishPortugueseChinese TraditionalSwedishCzechNorwegianItalianDanishHungarianFinnishHebrewArabicTurkishSlovakIndonesianBulgarianCroatianCatalanSlovenianGreekRomanianSerbianEstonianIcelandicLithuanianLatvian
Languages on the web
Goal: Cluster documents by topic regardless of
language

Bible as Parallel Corpus
Linguistic differences among translations
Translation Terms Total Words
English (King James) 12,335 789,744
Spanish (Reina Valera 1909) 28,456 704,004
Russian (Synodal 1876) 47,226 560,524
Arabic (Smith Van Dyke) 55,300 440,435
French (Darby) 20,428 812,947
• Languages convey information in different number of words- Isolating language: One morpheme per word• e.g., "He travelled by hovercraft on the sea." Largely isolating, but travelled
and hovercraft each have two morphemes per word.
- Synthetic language: High morpheme-per-word ratio• e.g., Aufsichtsratsmitgliederversammlung => "On-view-council-with-limbs-
gathering" meaning "meeting of members of the supervisory board".

Term-Doc Matrix
Term-by-verse matrix for all languages
terms
Bible verses
English
Spanish
Russian
Arabic
French
163,745 x 31,230
Look for co-occurrence of terms in the same verses and across languages to capture latent concepts

Latent Semantic Indexing
Term-by-verse matrix for all languages
terms
Bible verses
English
Spanish
Russian
Arabic
French
UVΣ T
Truncated SVD
Ak = Uk!kVT
k =
k!
i=1
!iuivTi
Project new documents of interest into subspace of U -1 and compute cosine similaritiesΣ
term x concept
dimension 1 0.1375dimension 2 0.1052dimension 3 0.0341dimension 4 0.0441dimension 5 -0.0087dimension 6 0.0410dimension 7 0.1011dimension 8 0.0020dimension 9 0.0518dimension 10 0.0822dimension 11 -0.0101dimension 12 -0.1154dimension 13 -0.0990dimension 14 0.0228dimension 15 -0.0520dimension 16 0.1096dimension 17 0.0294dimension 18 0.0495dimension 19 0.0553dimension 20 0.1598
Projection
Document feature vector

Quran as Test Set
• Quran is translated into many languages, just like the Bible
• 114 suras (or chapters)
• More variation across translations = harder clustering task

Performance Metrics
• MP5: Average multilingual precision at 5 (or n) documents- The average percentage of the top 5 documents that
are translations of the query document- Calculated as an average for all languages- Essentially, MP5 measures success in multilingual
clustering
?
?
Lang 1Lang 2
query

LSA Results
Method Average MP5
SVD/LSA 65.5%
Documents tend to cluster more by language than by topic
5 languages, 240 latent dimensions

New Approach: Multi-matrix Array
X5
X4
X3X
2English
X1
Spanish
Russian
Arabic
French
Term-by-verse matrix for each language
(Chew, Bader, Kolda, Abdelali, 2007)
Array size: 55,300 x 31230 x 5 with 2,765,719 nonzeros

Tucker1
VT
S1
=U1
X1
X2
X3
U2
U3
!
!Tucker
Tucker1

Tucker1 Results
Method Average MP5
SVD/LSA 65.5%
Tucker1 71.3%
Only minor improvement because each Uk is not orthogonal
5 languages, 240 latent dimensions

PARAFAC2
Where each Uk is orthonormal and Sk is diagonal
Xk ! UkHSkV T
(Harshman, 1972)

PARAFAC2 Results
Modest improvement over LSA
Method Average MP5
SVD/LSA 65.5%
Tucker1 71.3%
PARAFAC2 78.5%
5 languages, 240 latent dimensions
Why PARAFAC2?

Tensor Methods and Modeling:Why the Proliferation?
• N-way interactions in real world applications
• Next frontier after matrix linear algebra- Lots of low hanging fruit
• New mathematical and computational challenges- Differences from matrix problems (e.g., rank of 2x2x2)- Original algorithms developed in different research
communities

Thoughts on Future Directions ofTensor-based Computation and Modeling• Need scalable algorithms- Fast, efficient for large-scale problems- Handle constraints• non-negativity• sparsity• orthogonality• etc.- Parallel algorithms
• Match models to applications- Requires creativity by domain experts and tensor
researchers- Sometimes not a straightforward extension from matrix
approaches- Danger of reinventing whatʼs already in the literature• psychometrics






























