Embed Size (px)
Citation preview

Unstructured Data and Text Mining
D. Silver

Unstructured Data
• Definition: Information that either does not have a pre-defined data model or is not organized in a predefined manner
• Imprecise for several reasons:– Structure of data may be easily
implied, but not explicit– Data may have explicitly structure but
not for the task at hand– Data may have some underlying
structure that is not understood
Copyright 2003-4, SPSS Inc. 3
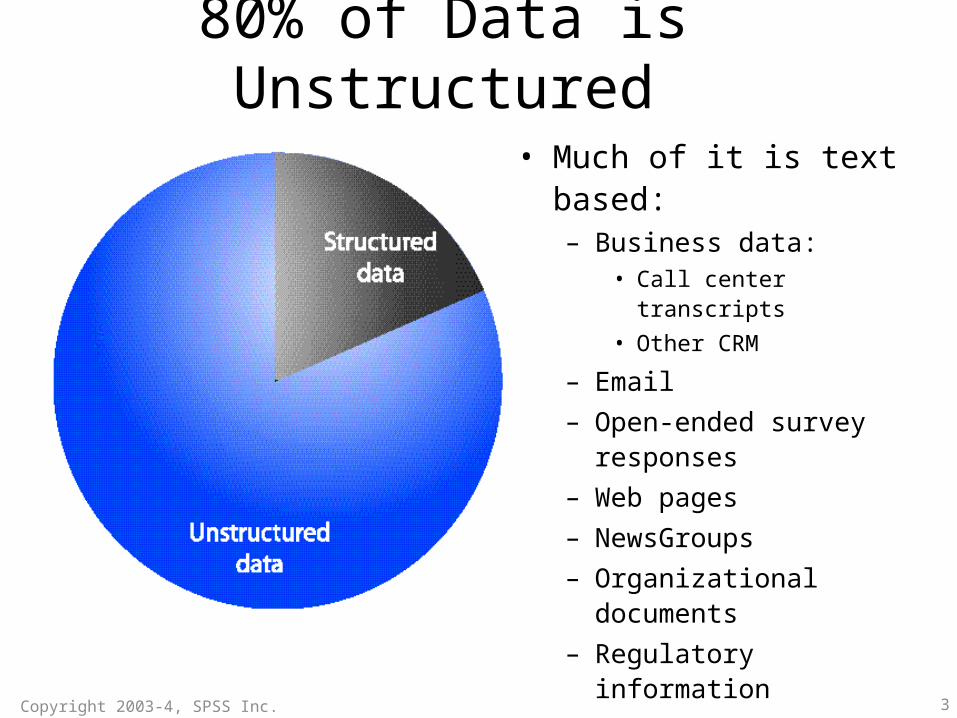
80% of Data is Unstructured
• Much of it is text based:– Business data:
• Call center transcripts• Other CRM
– Email– Open-ended survey responses– Web pages– NewsGroups– Organizational documents– Regulatory information
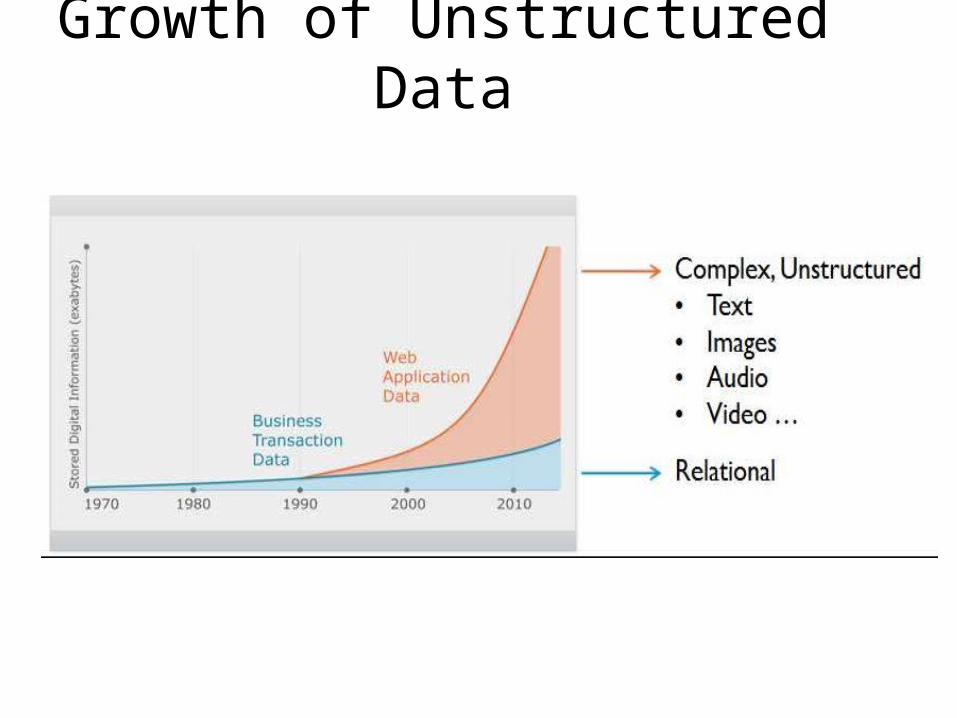
Growth of Unstructured Data

Unstructured Information Management Architecture (UIMA)
• Architecture for the development, discovery, composition, and deployment of analytics on unstructured data
• Provides a common framework for processing unstructured data to extract meaning and create structured data and information
• IBM’s Watson uses UIMA for real-time content analytics

References:
• Text to attributes p.328-329• Text mining Section 9.5• Web mining and beyond , Section 9.6-9.8• String conversion p.439• http://en.wikipedia.org/wiki/Unstructured_data• http://en.wikipedia.org/wiki/UIMA• http://bigdataintegration.blogspot.ca/2012/02/u
nstructured-data-is-myth.html

Text Mining
• Text is: – Unstructured, amorphous and challenging to parse– Most common form of information exchange– Motivation to extract information is compelling
• Text Mining differs from Data Mining – Most authors strive to clearly inform the reader– But humans do not have time to read/interpret
everything– TM focuses on extracting information ready for rapid
machine or human consumption

Text Mining
• Two broad approaches:– Natural Language Processing (Comp. Linguistics)
• Extracts concepts based on semantics • Relies heavily on language morphology, syntax, and
semantics
– Information Retrieval• Exploits bag of word approach • Term weighting and text similarity measures
Copyright 2003-4, SPSS Inc. 9
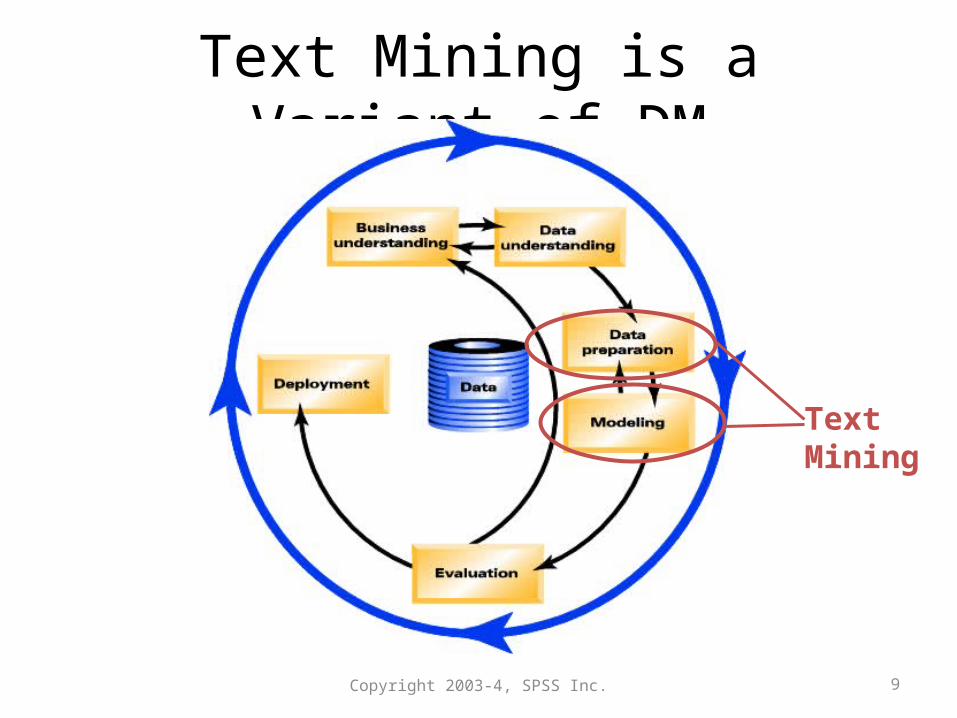
Text Mining is a Variant of DM
Text Mining
Copyright 2003-4, SPSS Inc. 10
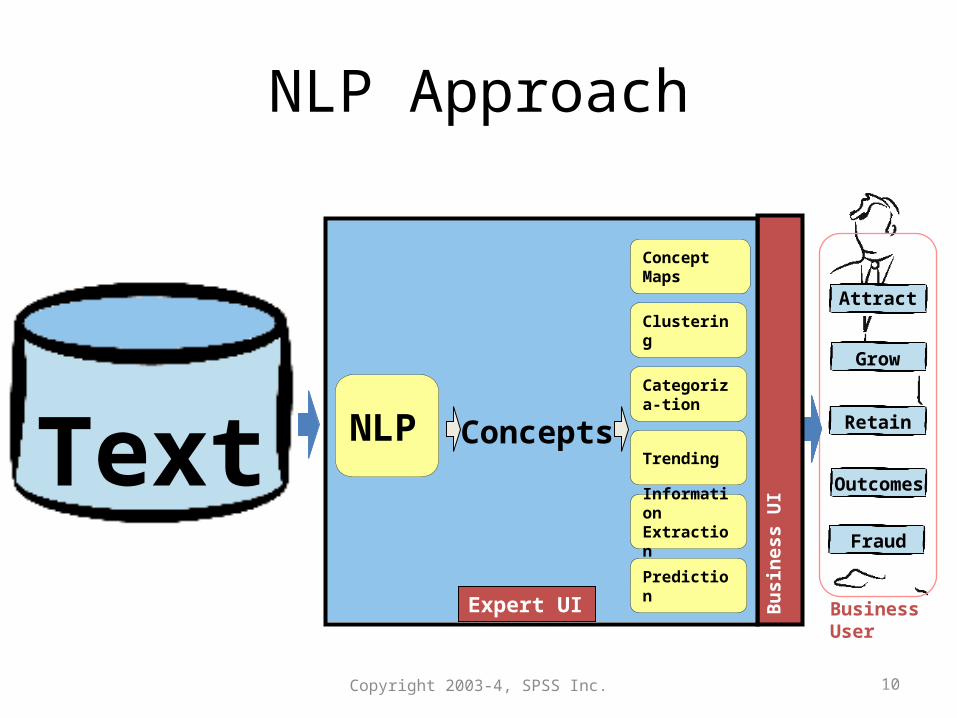
NLP Approach
Customer
Data
Attitudes
Actions
Attributes
Business User
Grow
Retain
Fraud
Outcomes
Attract
Data Collection
Text
Surveys
WebChannel
OperationalSystems
Text
Busi
ness
UI
Expert UIExpert UI
Concepts
Concept Maps
Clustering
Categoriza-tion
Trending
Information Extraction
Prediction
NLP

Copyright 2003-4, SPSS Inc. 11
NLP Relies on the Building Blocks of Language
• Morphology• Syntax• Semantics• Objective is to go from syntactic phrase
– Using a tool like Text Mining is a great idea for any organization that is interested in maintaining information on competitive intelligence.
• To semantic concept:– Competitive Intelligence
Copyright 2003-4, SPSS Inc. 12
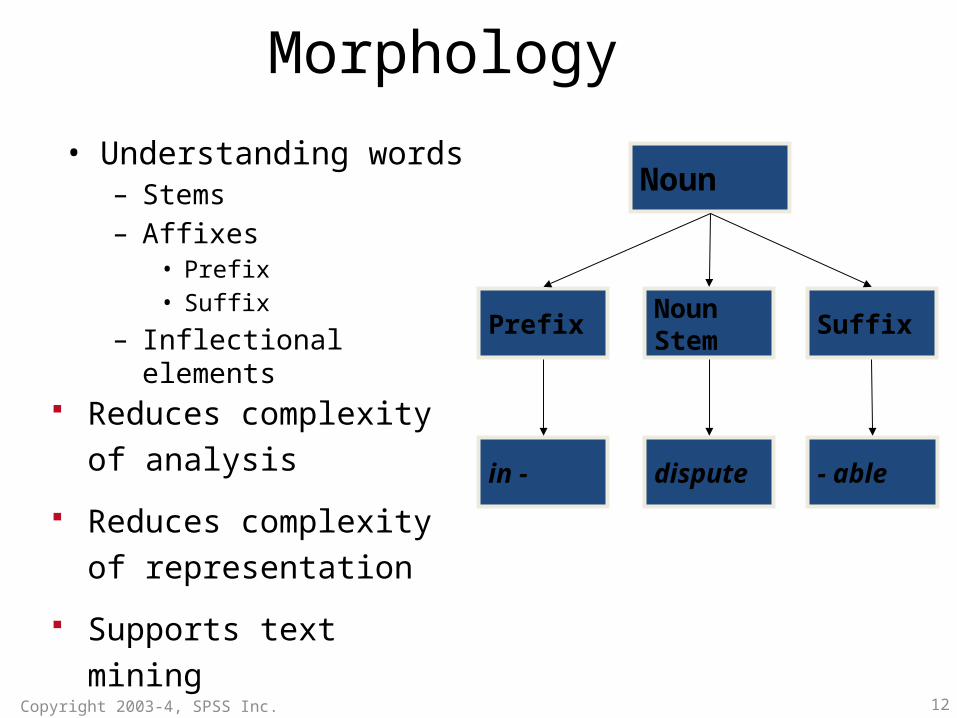
Morphology
• Understanding words– Stems– Affixes
• Prefix• Suffix
– Inflectional elements
Reduces complexity of analysis
Reduces complexity of representation
Supports text mining
Noun
Prefix Noun Stem Suffix
- abledisputein -

Copyright 2003-4, SPSS Inc. 13
Syntax• The Bank of Canada will curb inflation with higher
interest rates
Prepositional phraseAdjective
Sentence
Noun phrase Verb phrase
NounVerbAux
Noun phrase
NounAdjective
Noun
The Bank ofCanada
inflationcurbwill
Interest rateshigher
with

Copyright 2003-4, SPSS Inc. 14
Semantics
• The meaning of it all• Approaches to meaning
– Semantic networks– Deductive logic– Rule-based systems
• Useful for classification of documents

Copyright 2003-4, SPSS Inc. 15
Problems with NLP
• Limitations of Natural Language Processing– Correctly identifying the role of noun phrases– Representing abstract concepts– Classifying synonyms– Representing the number of concepts
• Limitations of technology– Language specific designs are required– Classification speed– Classifying hybrid words and sentences

IR Approach
• Statistics applied to syntax yields pretty good results for:– Information Filtering– Text Categorization– Document/Term Clustering– Text Summarization
17
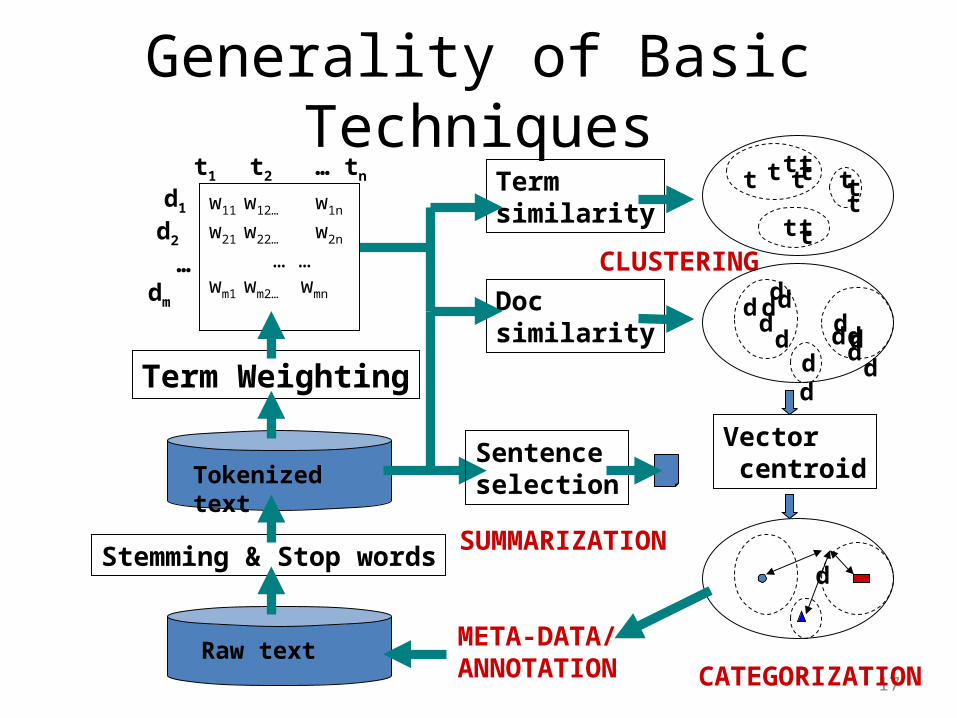
Generality of Basic Techniques
Raw text
Term similarity
Doc similarity
Vector centroid
CLUSTERING
d
CATEGORIZATION
META-DATA/ANNOTATION
d d d
d
d d
d
d d d
d d
d d
t t
t t
t t t
t t
t
t t
Stemming & Stop words
Tokenized text
Term Weighting
w11 w12… w1n
w21 w22… w2n
… …wm1 wm2… wmn
t1 t2 … tn
d1
d2 … dm
Sentenceselection
SUMMARIZATION


Stemming• General:
– http://en.wikipedia.org/wiki/Stemming– http://www.comp.lancs.ac.uk/computing/research/stemming/general/ – http://snowball.tartarus.org/texts/introduction.html *READ*
• Julie B. Lovins (1968)– http://www.comp.lancs.ac.uk/computing/research/stemming/general/lovins.htm– http://snowball.tartarus.org/algorithms/lovins/stemmer.html
• Martin Porter (1979)– http://www.comp.lancs.ac.uk/computing/research/stemming/general/porter.htm
• Snowball (~2000)– Framework for writing stemming algorithms– Language and compiler for stemming algorithms– http://snowball.tartarus.org



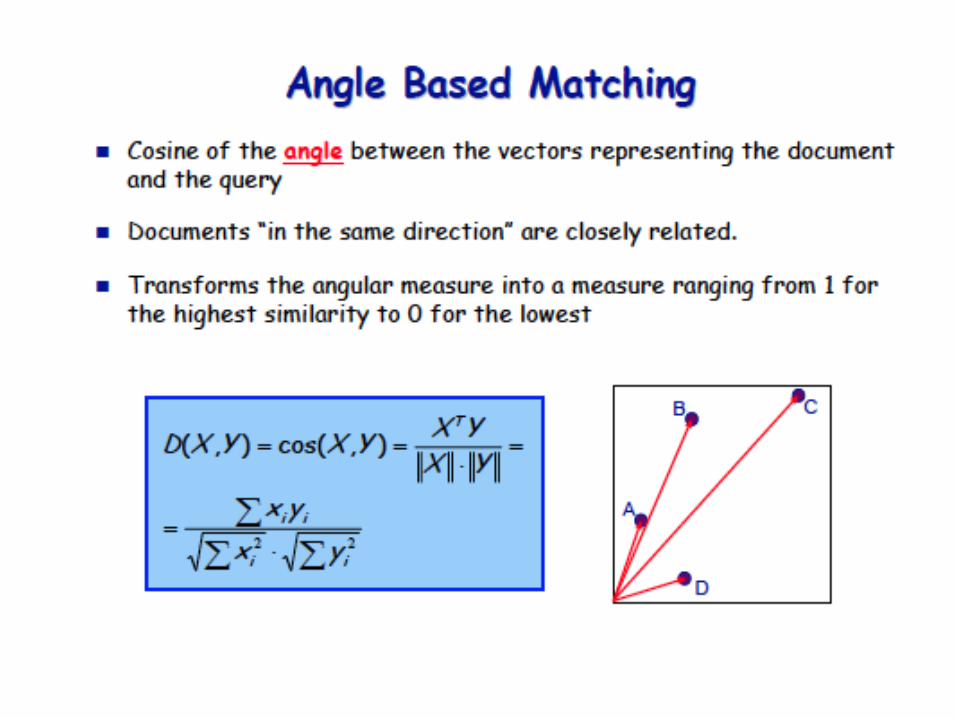
26
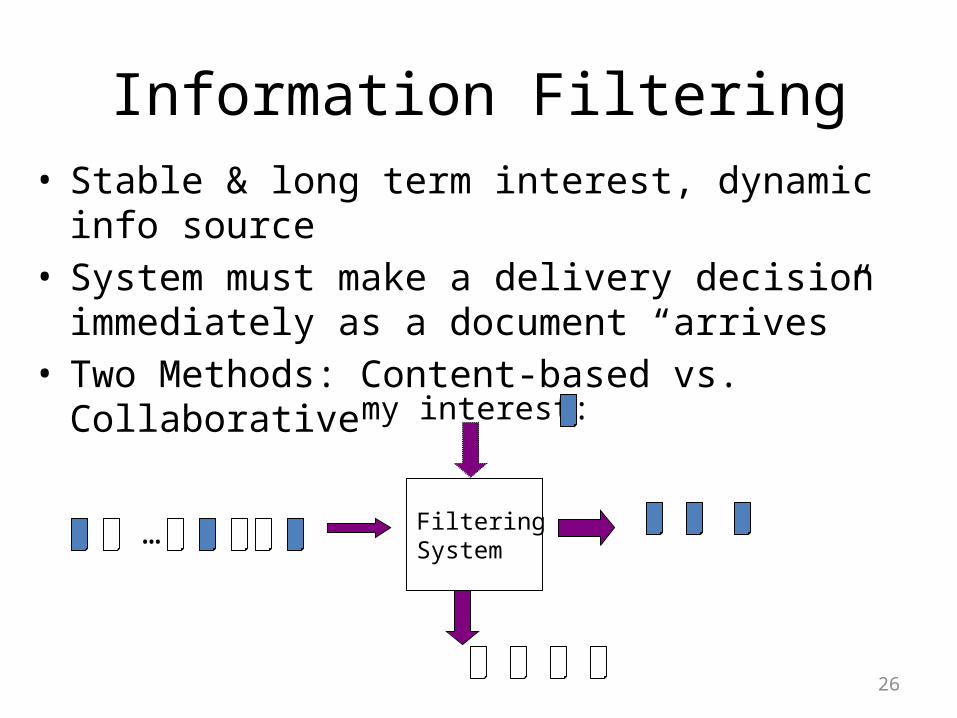
Information Filtering• Stable & long term interest, dynamic info source• System must make a delivery decision
immediately as a document “arrives”• Two Methods: Content-based vs. Collaborative
FilteringSystem
…
my interest:

27
Examples of Information Filtering
• News filtering• Email filtering• Recommending Systems• Literature alert • And many others

28
Sample Applications
• Information Filtering• Text CategorizationÞ Document/Term Clustering• Text Summarization
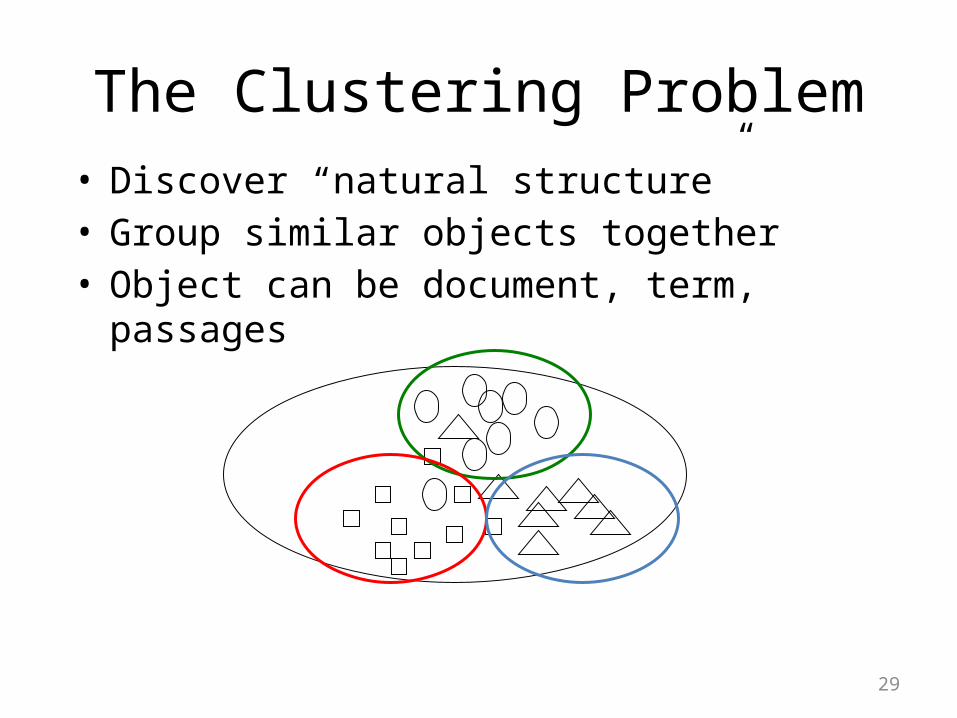
29
The Clustering Problem• Discover “natural structure”• Group similar objects together• Object can be document, term, passages
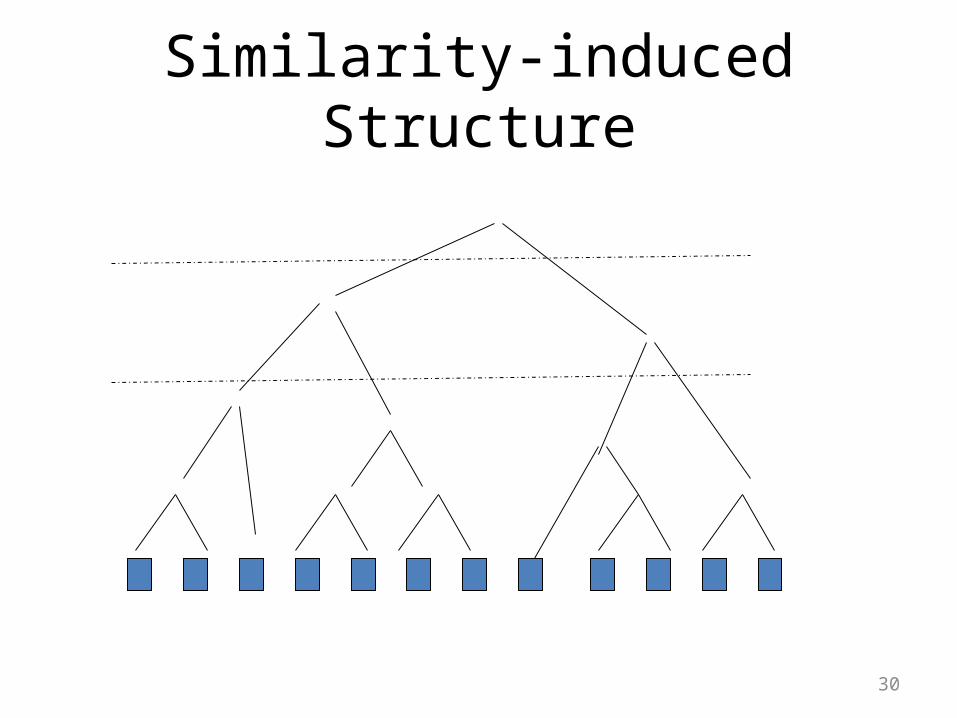
30
Similarity-induced Structure

31
Examples of Doc/Term Clustering
• Clustering of retrieval results• Clustering of documents in the whole collection • Term clustering to define “concept” or “theme”• Automatic construction of hyperlinks• In general, very useful for text mining

32
Sample Applications
• Information Filtering• Text Categorization• Document/Term ClusteringÞ Text Summarization

33
“Retrieval-based” Summarization
• Observation: term vector summary?• Basic approach
– Rank “sentences”, and select top N as a summary
• Methods for ranking sentences– Based on term weights– Based on position of sentences– Based on the similarity of sentence and document
vector– NOTE: Similarity can be measured by inner product of vectors of
term frequencies

34
Examples of Summarization
• News summary • Summarize retrieval results
– Single doc summary– Multi-doc summary
• Summarize a cluster of documents (automatic label creation for clusters)

35
Sample Applications
• Information FilteringÞ Text Categorization• Document/Term Clustering• Text Summarization

36
Text Categorization
• Pre-given categories and labeled document examples (Categories may form hierarchy)
• Classify new documents • A standard supervised learning problem
CategorizationSystem
…
Sports
Business
Education
Science…
SportsBusiness
Education
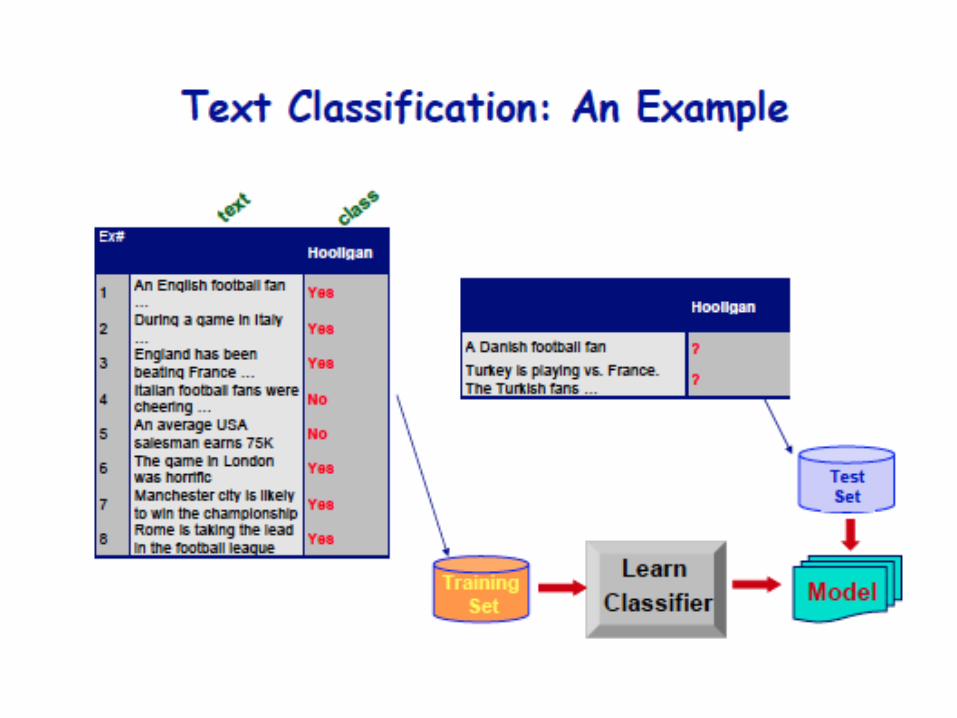

38
Examples of Text Categorization
• News article classification• Meta-data annotation• Automatic Email sorting• Web page classification


References
• http://paginas.fe.up.pt/~ec/files_0405/slides/07%20TextMining.pdf
• http://disi.unitn.it/~bernardi/Courses/CL/Slides/ir.pdf
• Multinomimal Distribution– http://onlinestatbook.com/2/probability/multinomial.h
tml– http://onlinestatbook.com/2/probability/binomial.html

WEKA Tutorials
• https://moodle.umons.ac.be/pluginfile.php/43703/mod_resource/content/2/WekaTutorial.pdf
• http://www.unal.edu.co/diracad/einternacional/Weka.pdf





























