Embed Size (px)
Citation preview

Jialin Liu, Quincey Koziol, Houjun Tang, Francois Tessier, Wahid Bhimji, Brandon Cook, Brian Austin, Suren Byna, Bhupender Thakur, Glenn Lockwood, Jack Deslippe, Prabhat
Understanding the IO Performance Gap Between Cori KNL and Haswell
May102017CrayUserGroupMee2ng,Sea7le,2017

Background: New Architectures
u CoriPhaseIIwasinstalledin2016§ IntelXeonPhi2ndgenera2on
§ KnightsLanding(KNL)KNL Haswell
CPU 1.4GHz 2.3GHz
Memory 96GDDR4,16GHBM 128GDDR4
Cache(L1,L2,L3) 64K,1M 64K,256K,40M
Node 68core,singlesocket 32core,twosocket
Capacity 9688nodes 2388nodes

Problem: Performance Gap u DifferentArchitectures,PerformanceDifferenceDetected
§ NESAPprogramatNERSC,focusesoncomputa2onperformance[1]
§ HowaboutIO?~2Xgap,why?
IORFilePerProcess• 1Gperprocess,1to32processes,POSIXIO
1.52X
[1]T.Barnes,etc.Evalua2ngandOp2mizingtheNERSCWorkloadonKnightsLanding.PMBS2016

Mysterious IO Gap
u IOistypicallysloweddownbydisk,notCPU§ CPUisfasterenoughthandisk,andhasrela2velysmaller
impacttotheIOperformance
u ButIOstackunderneathHaswellandKNLissame
§ CraySonexion2000Lustreappliance
§ CrayArieswithDragonflytopology

IO Stack
248 OSS OSS … …
OST OST OST OST OST OST… …
MDS4MDS3
MDS1 MDS2
1primaryMDS,4addi2onalMDS
ADU1
ADU2MDS
248
OSS OSSOSS OSS
Infiniband
130
HaswellwithAriesNetwork…CMP CMP
……CMP
…
CMP
LNET
…
…
…
CMP CMP
LNET LNET
KNLwithAriesNetwork…CMP CMP
……CMP
…
CMP
LNET
…
…
…
CMP CMP
LNET LNET…
2338 9688
Compu
teSide
StorageSide

IO Benchmarks
u DDu IORu HDF5

DD
u dd:Simple,commonlyusedintes2ngdiskbandwidth§ Copyafile,conver2ngandformahngaccordingtotheoperands.
§ dd if=input of=outputu IO:
§ dd_copy(){§ posix_read();§ posix_write();}
u 512bytesbydefault§ 1Mblocksizeisusedinourtest
§ 10000count

IOR
u IOR:HPCIOBenchmarkformeasuringpeakperformanceu IO:
§ FilePerProcess(FPP)
§ SingleSharedFile(SSF)
u FlexibleConfigura2ons:
§ Transfer/block/segmentsize
§ Fsync/dsync/directIO
§ POSIX/MPIIO/HDF5

HDF5
u HDF5:IOmiddlewareusedinmanyHPCapplica2ons§ Constructlogicalaccesspa7ern
§ MPIIndependent/Collec2veIO
u MPIIO:
§ H5Dwrite() and H5Dread()§ Collective buffer
u CustomizedIOBenchmarks

Varying CPU Frequencies: Haswell
WithoutTurboMode§ r2=0.79
Haswell,SingleCore,10Gwrite
WithTurboMode§ r2=0.76

Varying CPU Frequencies: KNL
WithoutTurboMode§ r2=0.95
KNL,SingleCore,10Gwrite
WithTurboMode§ r2=0.94

How Well is the Fitting
u IO~CPUFrequencyu SingleCoreIO=f(CPUfrequency,other),ifIOfitsinpagebuffer
§ r2haswell<r2knl:ComplexHaswellchip;WiderrangeofCPUfrequencies,morepipelinedKNLchip
§ intercept>>0:PageCache.
ParDDon Haswell KNL
r2 0.79 0.95
intercept(MB/s) 286.11 41.28
v Notethat,theIOcanfitinthepagebufferwell

Haswell vs KNL
§ BandwidthRa2oHaswell/KNL=2.30(atsameCPUfreq) =3.46(Turbo)

Other Facts
§ IPChaswell/IPCknl=2.23(average)§ IPChaswell/IPCknl=2.35(atsamecpufreq)

Similar Result with HDF5 Parallel IO
§ IOhaswell/IOknl=1.83(atsameCPUfreq)=3.06(Turbo)

IPC Statistics
§ IPChaswell/IPCknl=1.88(average)§ IPChaswell/IPCknl=1.93(atsamecpufreq)

Same KNL IO Issue Confirmed at ANL
§ ddwrite10Gtoscratch§ IOBandwidth:262MB/s,1.398GHz(Turbo),ANL 306MB/s,NERSC

Summary I for Single Core IO Performance
u IO~F(CPUFrequency)§ Haswell:r2=0.79(DD),r2=0.89(HDF5)§ KNL:r2=0.95(DD),r2=0.96(HDF5)
u KNL/Haswell§ HDF5:IPCRa2o=51%,IOBWRa2o=55%§ DD:IPCRa2o=44%,IOBWRa2o=43%
u TurboMode(Default)§ IOBWRa2o(KNL/Haswell)=32%(HDF5),29%(DD)
PageBuffer
IO IOIO

Node Local IO Path Deep Dive
u WiththeSameCPUFrequencies§ Whatisthedifferenceinthetwonode’sIOpath?
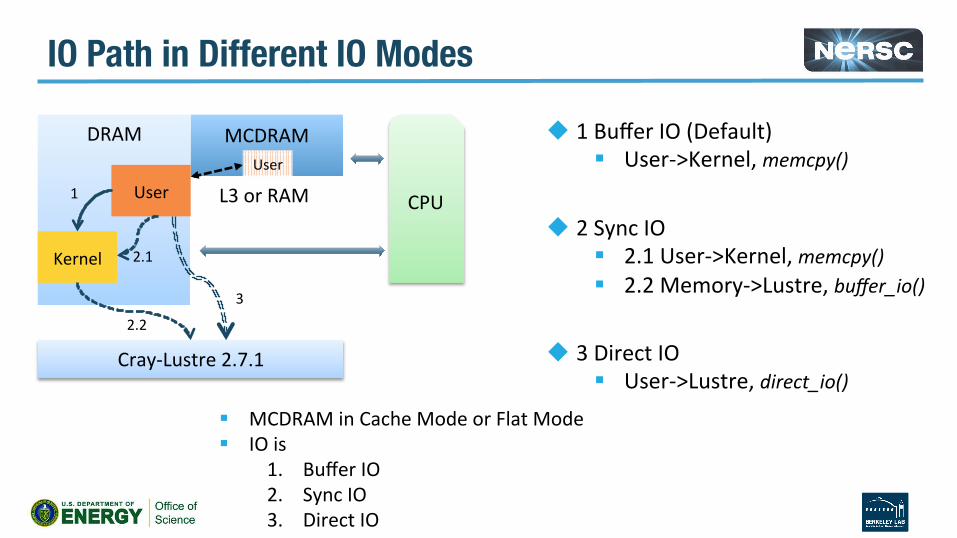
IO Path in Different IO Modes
§ MCDRAMinCacheModeorFlatMode§ IOis
1. BufferIO2. SyncIO3. DirectIO
u 1BufferIO(Default)§ User->Kernel,memcpy()
DRAM
L3orRAM
Kernel
User1
Cray-Lustre2.7.1
2.1
2.2
3
CPU
User
MCDRAM
u 2SyncIO§ 2.1User->Kernel,memcpy()§ 2.2Memory->Lustre,buffer_io()
u 3DirectIO§ User->Lustre,direct_io()

Sync IO
Xis1.4Ghz,1.3Ghz,1.2Ghz,eachisrepeated32mes
ddoflag=dsyncif=/dev/zeroof=$SCRATCH/1.txtbs=1mcount=10000
Kernel
User
FS
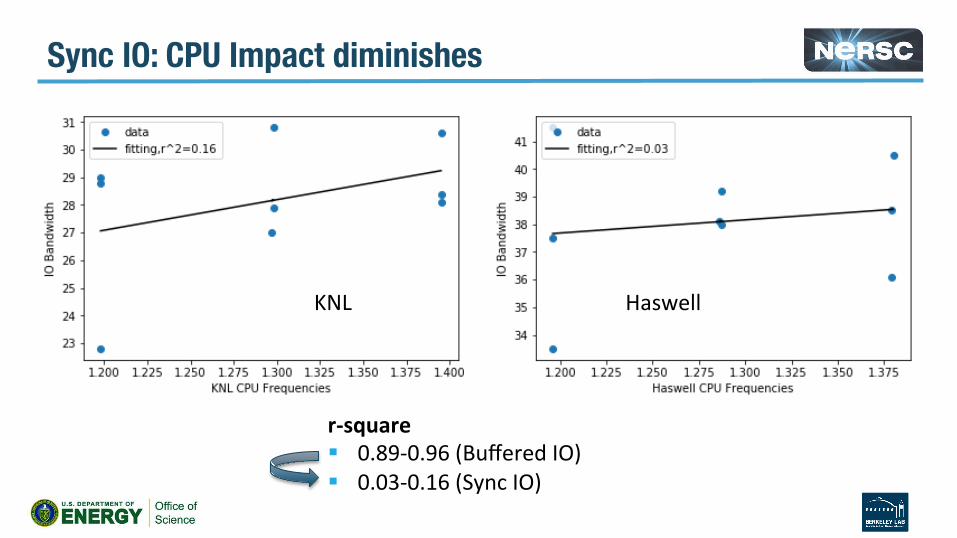
Sync IO: CPU Impact diminishes
r-square§ 0.89-0.96(BufferedIO)§ 0.03-0.16(SyncIO)
KNL Haswell

Sync IO: KNL is closer to Haswell
Kernel
User
FS
Haswell KNL-DRAM KNL-MCDRAM
STDEV 0.55 0.46 2.22
AVERAGE 45.21 31.23 30.20
MEDIAN 45.35 31.47 31.13
KNL/Haswell 69% 67%§ 10GwritewithsyncIO§ CPU1.4,1.3,1.2GHz§ Eachtestrepeated3Gmes§ Average§ UserspacememoryisinDRAMorMCDRAM,setbynumactlm=0or1§ KernelspacememoryisunknownincaseofMCDRAMasfirstprioritymemory,
i.e.,m=1

Page Cache Off, Direct IO

MCDRAMDRAM
Page Cache Off, Direct IO
User
FS
3
Haswell KNL-DRAM KNL-MCDRAM
STDEV 1.21 1.02 1.15
AVERAGE 48.99 43.83 46.78
MEDIAN 49.60 43.93 46.40
KNL/Haswell 90% 96%§ 10GwritewithdirectIO§ CPU1.4,1.3,1.2GHz§ Eachtestrepeated3Gmes§ Average§ Bypassingkernelspacebuffer§ UserspacememoryiseitherusingDRAMorMCDRAM,controlledbynumactlm=0forDRAM,1forMCDRAM

Summary II for Single Core IO Performance
u IO~CPUFrequency:CPUImpactdiminishes§ Haswellr-square:0.79(pagecacheon)--->>0.03(pagecacheoff)§ KNLr-square:0.95(on)--->>0.16(off)
u IOBWatsameCPUFrequencies§ DRAM:SyncIO67%,DirectIO90%(KNL/Haswell)§ MCDRAM:SyncIO69%,DirectIO96%
u TurboMode(Default)§ DRAM:SyncIO65%,DirectIO78%§ MCDRAM:SyncIO73%,DirectIO88%

Summary II for Single Core IO Performance
Notethattheabsoluteperformancenumberisnotrevealedinthisplot,BufferedIOtypicallydeliver10Xperformancespeedupinwrite
Ra2o=KNL/Haswell

Summary II for Single Core IO Performance

Parallel IO
u Parallelism§ MorethreadsonKNL§ Internalparallelism,CheckIntel’snewLustreop2miza2onLUG17
u Network,Inter-nodeCommunica2onLatency§ MPIIO
u NodeLocalCollec2veBufferSize§ Collec2veIO

Mul2pleCore,Mul2pleNodeIOTestsFileperProcess

Write, Same IO Mode, Haswell vs KNL
BufferedWrite,HaswellvsKNL DirectWrite,HaswellvsKNL
KNL/Haswell=0.58 0.83SameNumberofProcs
Maximum KNL/Haswell=0.99 2.25
MoreCores

Write: Same Node, Buffered vs Direct IO
Bufferedvs.DirectWrite,KNL Bufferedvs.DirectWrite,Haswell
§ DirectIOisscalable§ KNLhaslesspagebuffer,andprobablyless
powerfulbuffermanagement
1Node2Node
MoreBuffer

Read Once, Same IO Mode, Haswell vs KNL
BufferedRead,Haswellvs.KNL DirectRead,HaswellvsKNL
§ KNLIOBWoutperformsHaswellwithmorecoresinbothbuffered&directIO
Read12me

Read Multiple Times
BufferedRead,Haswellvs.KNL
§ KNLIOBWdropsat48-64corespernode§ Increasepagebuffer,nottriedyet
Read32mes,Don’tflushthecacheexplicitly

Read Once, Same Node, Buffered vs Direct IO
BufferedReadvs.DirectRead,KNL BufferedvsDirectRead,Haswell
§ DirectReadreachesandoutperformsBufferedRead§ Lustrereadaheadbenefitreducesasmemcopycostincreases

Lustre Read-ahead to Read Performance

Summary III Multi-Node/Core File Per Process
u Write§ KNL/Haswell0.58->0.99(32processesto64processes)§ DirectIO:Scalable,canreachBufferedIO§ MorepagebufferforbeWerbufferedIOperformance
u Read§ KNLoutperformsHaswellwithmorecoresinbothbuffered/
directIO,withreadonceIOpa7ern§ KNLdropsduetopagebufferlimitwhenreadmul2ple2mes§ Lustreread-aheadisafactor§ DirectIOoutperformsbufferedIOwithlargeone-2meread

Mul2pleCore,Mul2pleNodeIOTestsSingleSharedFile

u With0Byte,Haswell/KNLInter-nodeBW2.49X Intra-nodeBW2.73X
u KNLoutperformsHaswellwithlargermessagesizeininter-nodecommu Largerbuffersize

u With0Byte,Haswell/KNLInter-nodeBW2.49X Intra-nodeBW2.73X
u KNLoutperformsHaswellwithlargermessagesizeininter-nodecommu Largerbuffersize

Conclusion u CPUFrequency
§ Mainfactor§ IOscaleswithCPUwhenIOcanfitintopagebuffer
u PageBuffer§ KNLisclosetoHaswellwithdirectIO§ PagebuffermanagementissloweronKNL§ Pagebufferbenefitsgenerally,e.g.,write,mul2-read§ DirectIOcanbebe7erthanbufferedIOwithlargeone-2meread
u ManyCores§ KNLcouldoutperformHaswellwithmorecoresinFPPreadonce.§ DirectIOismuchmorescalablethanbufferedIO
u Network,Collec2veBufferandOthers§ KNLhaslargerinter-nodelatencythanHaswell§ IncreasingbuffersizeinMPIIOcanimproveIOBW

Future Work
u PageBufferManagementonKNL§ MCDRAMaspagebuffer
u Cross-par22onIO§ OffloadIOfromKNLtoHaswell§ Shivcomputa2onfromHaswelltoKNL§ DynamicDatahub:h7ps://github.com/NERSC/heterogeneous-IO
u Many/HeterogeneousCoreIOOp2miza2on
Pub Sub
IO Compute





























