Embed Size (px)
Citation preview

BioMed CentralBMC Systems Biology
ss
Open AcceResearch articleUnderstanding network concepts in modulesJun Dong and Steve Horvath*Address: Department of Human Genetics and Department of Biostatistics, University of California, Los Angeles, CA 90095, USA
Email: Jun Dong - [email protected]; Steve Horvath* - [email protected]
* Corresponding author
AbstractBackground: Network concepts are increasingly used in biology and genetics. For example, theclustering coefficient has been used to understand network architecture; the connectivity (alsoknown as degree) has been used to screen for cancer targets; and the topological overlap matrixhas been used to define modules and to annotate genes. Dozens of potentially useful networkconcepts are known from graph theory.
Results: Here we study network concepts in special types of networks, which we refer to asapproximately factorizable networks. In these networks, the pairwise connection strength(adjacency) between 2 network nodes can be factored into node specific contributions, namednode 'conformity'. The node conformity turns out to be highly related to the connectivity. Toprovide a formalism for relating network concepts to each other, we define three types of networkconcepts: fundamental-, conformity-based-, and approximate conformity-based concepts.Fundamental concepts include the standard definitions of connectivity, density, centralization,heterogeneity, clustering coefficient, and topological overlap. The approximate conformity-basedanalogs of fundamental network concepts have several theoretical advantages. First, they allow oneto derive simple relationships between seemingly disparate networks concepts. For example, wederive simple relationships between the clustering coefficient, the heterogeneity, the density, thecentralization, and the topological overlap. The second advantage of approximate conformity-basednetwork concepts is that they allow one to show that fundamental network concepts can beapproximated by simple functions of the connectivity in module networks.
Conclusion: Using protein-protein interaction, gene co-expression, and simulated data, we showthat a) many networks comprised of module nodes are approximately factorizable and b) in thesetypes of networks, simple relationships exist between seemingly disparate network concepts. Ourresults are implemented in freely available R software code, which can be downloaded from thefollowing webpage: http://www.genetics.ucla.edu/labs/horvath/ModuleConformity/ModuleNetworks
BackgroundNetwork terminology is used to study important ques-tions in systems biology. For example, networks are usedto study functional enrichment [1], to analyze the struc-
ture of cellular networks [2], to model biological signal-ling or regulatory networks [1,3], to reconstruct metabolicnetworks [4], and to study the dynamic behavior of generegulatory networks [5].
Published: 4 June 2007
BMC Systems Biology 2007, 1:24 doi:10.1186/1752-0509-1-24
Received: 22 January 2007Accepted: 4 June 2007
This article is available from: http://www.biomedcentral.com/1752-0509/1/24
© 2007 Dong and Horvath; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Page 1 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
Here we study the meaning of network concepts in rela-tively simple networks, e.g. gene co-expression networksand protein-protein interaction (PPI) networks. Specifi-cally, we consider undirected networks that can be repre-sented by a symmetric adjacency matrix A = [aij], wherethe pairwise adjacency (connection strength) aij takes val-ues in the unit interval, i.e., 0 ≤ aij ≤ 1. For an unweightednetwork, the adjacency aij = 1 if nodes i and j are con-nected and 0 otherwise. For a weighted network, 0 ≤ aij ≤ 1.For notational convenience, we set the diagonal elementsto 1.
Fundamental network conceptsOther authors refer to network concepts as network statis-tics or network indices. Network concepts include connec-tivity, mean connectivity, density, variance of theconnectivity (related to the heterogeneity) etc. Networkconcepts can be used as descriptive statistics for networks.While some network concepts (e.g. connectivity) havefound important uses in biology and genetics, other net-work concepts (e.g. network centralization) appear lessinteresting to biologists. Before attempting to understandwhy some concepts are more interesting than others, it isimportant to understand how network concepts relate toeach other in biologically interesting networks. As a steptoward this goal, we explore the meaning of network con-cepts in module networks, which are defined below.
In the following, we review fundamental network con-cepts. Further details on the definitions and notations canbe found in the Methods section.
The node connectivity is given by
In unweighted networks, the connectivity ki of node iequals the number of directly linked neighbors. Inweighted networks, the connectivity equals the sum ofconnection weights with all other nodes. Highly con-nected 'hub' genes are thought to play an important rolein organizing the behavior of biological networks [6-9].Connectivity has been found to be an important comple-mentary gene screening variable for finding biologicallysignificant genes in cancer [10,11] and primate braindevelopment [12].
The line density [13] is defined as the mean off-diagonaladjacency and is closely related to the mean connectivity.
where the function Sp(·) is defined for a vector v as Sp(v)
= ∑i = (vp)τ 1.
The normalized connectivity centralization (also knownas degree centralization) is a simple and widely used indexof the connectivity distribution. By definition [14], thenormalized connectivity centralization is given by
A frequent question of social network analysis concernsthe causes and consequences of centralization in networkstructure, i.e. the extent to which certain nodes are farmore central than others within the network in question.The centralization index has been used to describe struc-tural differences of metabolic networks [15].
Many measures of network heterogeneity are based on thevariance of the connectivity, and authors differ on how toscale the variance [13]. Our definition of the network het-erogeneity equals the coefficient of variation of the con-nectivity distribution, i.e.
This heterogeneity measure is scale invariant with respectto multiplying the connectivity by a scalar. Biological net-works tend to be very heterogeneous: while some 'hub'nodes are highly connected, the majority of nodes tend tohave very few connections. Describing the heterogeneity(inhomogeneity) of the connectivity (degree) distributionhas been the focus of considerable research in recent years[6,16-18].
The clustering coefficient of node i is a density measureof local connections, or 'cliquishness' [19,20]. Specifi-cally,
In unweighted networks, ni equals twice the number ofdirect connections among the nodes connected to node i,and πi equals twice the maximum possible number ofdirect connections among the nodes connected to node i.Consequently, ClusterCoefi equals 1 if and only if allneighbors of i are also connected to each other. For gen-eral weighted networks with 0 ≤ aij ≤ 1, one can prove 0 ≤ClusterCoefi ≤ 1 [21]. The relationship between the cluster-
Connectivity k ai i ijj i
= =≠∑ . (1)
Densitya
n n
S
n n
mean
n
ijj ii=−
=−
=−
≠∑∑( )
( )
( )
( ),
1 1 11 k k (2)
vip
Centralizationn
n nDensity
nDensity=
− −−⎛
⎝⎜⎞⎠⎟
≈ −2 1
max( ) max( )k k..
(3)
Heterogeneityiance
mean
nS
S= = −
var ( )
( )
( )
( ).
k
k
k
k2
12
1 (4)
ClusterCoefn a a a
ai
i
i
il lm mim i ll i
ill i
= =( ) −{ }
≠≠
≠ ≠
∑∑∑ ∑π
,
aill i
2 2.. (5)
Page 2 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
Page 3 of 20(page number not for citation purposes)
Hierarchical clustering dendrogram and module definitionFigure 1Hierarchical clustering dendrogram and module definition. A) Drosophila PPI network. The dendrogram results from average linkage hierarchical clustering. The color-band below the dendrogram denotes the modules, which are defined as branches in the dendrogram. Of the 1371 proteins, 862 were clustered into 28 proper modules, and the remaining proteins are colored in grey; B) yeast PPI network; C) weighted gene co-expression network (yeast); D) unweighted gene co-expres-sion network (yeast). To facilitate a comparison between the weighted and the unweighted gene co-expression networks, we used the module assignment of C) in D). Note that the colors of C) tend to stay together in D), which illustrates high module preservation.
A B
0.0
0.2
0.4
0.6
0.8
1.0
Fly Protein−Protein Network
Colored by module membership
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Yeast Protein−Protein Network
Colored by module membership
C D
0.5
0.6
0.7
0.8
0.9
1.0
Yeast Co−expression Network: Soft Thresholding
Colored by module membership
0.0
0.2
0.4
0.6
0.8
1.0
Yeast Co−expression Network: Hard Thresholding
Colored by module membership of Soft Thresholding

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
ing coefficient and modular structure has been investi-gated by several authors [20,22-24].
The topological overlap between nodes i and j reflectstheir relative interconnectedness [20,25]. It is defined by
where lij = ∑u≠i,jaiuauj. In an unweighted network, lij equalsthe number of nodes to which both i and j are connected.In this case, TopOverlapij = 1 if the node with fewer connec-tions satisfies two conditions: (a) all of its neighbors arealso neighbors of the other node, and (b) it is connectedto the other node. In contrast, TopOverlapij = 0 if i and j areun-connected and the two nodes do not share any neigh-bors. By convention, TopOverlapii = 1. One can prove that0 ≤ aij ≤ 1 implies 0 ≤ TopOverlapij ≤ 1 [21].
The Topological Overlap Matrix Can Be Considered as Adjacency MatrixSince the matrix TopOverlap = [TopOverlapij] is symmetricand its entries lie in [0, 1], it satisfies our assumptions onan adjacency matrix. Roughly speaking, the topologicaloverlap matrix can be considered as a 'smoothed out' ver-sion of the adjacency matrix. The elements of TopOverlapprovide an alternative measure of connection strengthbased on shared neighbors. There is evidence that replac-ing A by TopOverlap may counter the adverse effects ofspurious or missing adjacencies [25,26]. Since the adja-cency matrices of the PPI networks in our applicationswere very sparse, we replaced them by the correspondingtopological overlap matrices. In contrast, we used theoriginal adjacency matrix when analyzing gene co-expres-sion networks since high specificity is desirable for meas-uring interconnectedness in co-expression networks.
The topological overlap matrix can be used for module definitionOur main interest lies in (sub-)networks comprised ofnodes that form a module inside a larger network. Since aparticular module network may encode a pathway or aprotein complex, these special types of networks havegreat practical importance. Similar to the term 'cluster', noconsensus on the meaning of the term 'module' seems toexist in the literature. In our applications, we use a cluster-ing procedure to identify modules (clusters) of nodes withhigh topological overlap. We follow the suggestion of [20]to turn the topological overlap matrix TopOverlap into adissimilarity measure by subtracting it from 1, i.e. dissTop-Overlapij = 1 - TopOverlapij.
We use dissTopOverlapij as input of average linkage hierar-chical clustering to arrive at a dendrogram (clustering
tree) [27]. Modules are defined as the branches of the den-drogram. For example, in Figure 1 we show the dendro-grams of our network applications. Genes or proteins ofproper modules are assigned a color (e.g. turquoise, blueetc). Genes outside any proper module are colored grey.Our module definition depends on how the branches arecut off the dendrogram. Several methods and criteria foridentifying branches in a dendrogram have been pro-posed, see e.g. [20,21,28]. In practice, it is advisable tostudy how robust the results are with respect to alternativemodule detection methods. In our online R software tuto-rial, we show that our findings are highly robust withrespect to alternative module definitions. In addition, weuse a functional enrichment analysis of the resulting mod-ules to provide indirect evidence that the modules are bio-logically meaningful. Our module detection approach hasled to biologically meaningful modules in several applica-tions [9,10,12,20,28-30] but we make no claim that it isoptimal. Our theoretical results will apply to all moduledetection methods that result in approximately factoriza-ble networks.
ResultsConformity and factorizable networksWe define an adjacency matrix A to be exactly factorizableif, and only if, there exists a vector CF with non-negativeelements such that
aij = CFiCFj for all i ≠ j (7)If the non-negative solution of equation (7) is unique, itis referred to as conformity vector CF and CFi is the con-formity of node i. One can easily show that the vector CFis not unique if the network contains only n = 2 nodes.However, for n > 2 it is unique for a weighted network, seeour derivations surrounding equation (20).
We also define the concept of conformity for a general,non-factorizable network. The idea is to find an exactlyfactorizable adjacency matrix ACF = CF CFτ - diag(CF2) + Ithat best approximates A. Note that the diagonal elementsof ACF and A equal 1.
In the appendix, we define the conformity as a maximizerof the factorizability function
. Alternative methods of
decomposing an adjacency matrix are briefly discussedbelow.
In equation (43), we define a measure of network factor-izability as follows
TopOverlapl a
k k aijij ij
i j ij=
+
{ } + −min ,,
1(6)
Fa v v
aA
ij i jj ii
ijj ii
( )( )
( )v = −
−≠
≠
∑∑∑∑
1
2
2
Page 4 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
The factorizability F(A) is normalized to take on values inthe unit interval [0, 1]. The higher F(A), the better ACF - Iapproximates A - I.
Modules can be approximately factorizableApproximate factorizability is a very strong structuralassumption on an adjacency matrix. It certainly does nothold for general networks. However, we provide empiricalevidence that many clusters (modules) of genes or pro-teins in real networks are approximately factorizable.Table 1 reports the mean values of F(A) for the applica-tions considered in this paper. For example in the Dro-sophila PPI network, the mean factorizability F(A) is 0.82across 'proper' modules defined as clusters in the network.In contrast, the factorizability of the subnetwork com-prised of non-module nodes is only 0.17. In the yeast PPInetwork, the mean factorizability of proper modules is0.85 while it equals only 0.20 for the grey module. In theweighted yeast gene co-expression network, the mean fac-torizability of proper modules equals 0.73 while it is only0.18 for the improper module. Similarly in theunweighted yeast gene co-expression network, the meanfactorizability of proper modules equals 0.62 while it isonly 0.11 for the improper module. A more detailed tablepresenting network concepts in each module is also pro-vided [see Additional file 1].
Our empirical results support the following
Observation 1 For many modules defined with a clusteringprocedure, the subnetwork comprised of the module nodes isapproximately factorizable.
This observation motivates us to study network conceptsin approximately factorizable networks.
Conformity-based network conceptsWe refer to the standard network concepts known fromthe literature as fundamental network concepts. In general,fundamental network concepts are functions of the off-diagonal elements of the adjacency matrix A. More pre-cisely, we use network concept functions to define differenttypes of network concepts depending on the input matrix(see Table 2 and equation (21)). For example, wheninputting an adjacency matrix with its diagonal elementsreplaced by 0, one arrives at fundamental network con-cepts (see Definition 5 in the Methods section). Wheninputting the conformity-based (CF-based) adjacencymatrix ACF with its diagonal elements replaced by 0, onearrives at CF-based network concepts (see Definition 6 inthe Methods section). The conformity vector can be usedto define the approximate CF-based matrix
ACF,app = CF CFτ = [CFiCFj].
Note that the i-th diagonal element of ACF,app equals .
When ACF,app is used as input of a network concept func-
tion, one arrives at an approximate CF-based concept (seeDefinition 7 in the Methods section).
We will demonstrate that approximate CF-based conceptssatisfy simple relationships. Below, we show that thesesimple relationships carry over to fundamental networkconcepts in approximately factorizable networks.
In Definition 7, we provide a formula for calculatingapproximate CF-based analogs of the fundamental net-work concepts. Specifically, we find
F AA I A I
A I
CF F
F
( )( ) ( )
.= −− − −
−1
2
2
CFi2
Table 1: Summary of fundamental network concepts in real network applications.
Fly Protein Yeast Protein Yeast (Weighted) Yeast (Unweighted)
Concept Proper Grey Proper Grey Proper Grey Proper Grey
Factorizability .82 (.086) .170 .85 (.100) .200 .73 (.084) .180 .62 (.130) .110Density .21 (.074) .017 .28 (.120) .026 .08 (.056) .005 .40 (.150) .024Centralization .18 (.091) .052 .20 (.055) .036 .10 (.026) .021 .41 (.110) .140Heterogeneity .35 (.130) .460 .36 (.140) .430 .56 (.066) .580 .51 (.097) .830Mean Cluster Coef. .28 (.110) .050 .36 (.120) .093 .13 (.072) .032 .72 (.087) .370Mean Conformity .45 (.076) .130 .51 (.120) .150 .26 (.084) .062 .63 (.100) .120
Each network contained several proper modules. Non-module genes were grouped into a single (improper) grey module. For each concept, we report the mean and standard error across the proper modules. A more detailed table presenting network concepts in each module is also provided [see Additional file 1].
Page 5 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
where Sp(CF) = ∑i(CFi)p. Note that the approximate CF-based clustering coefficient does not depend on the i-index. This is why we sometimes omit this index and sim-ply write ClusterCoefCF,app.
Approximate CF-based network concepts satisfy simple relationshipsHere we demonstrate a major advantage of approximateCF-based network concepts: they exhibit simple relation-ships. Using the fact that S1(kCF,app) = S1(CF)2, and theapproximation n/(n - 1) ≈ 1, equations (8) imply the fol-lowing relationship
or equivalently,
Further, it is straightforward to derive a simple relation-ship between approximate CF-based topological overlap,connectivity and heterogeneity under the following mild
assumptions: and .
Specifically, we find
In the following subsection, we outline the conditionswhen equations (9) and (10) hold approximately for fun-damental network concepts in approximately factorizablemodule networks.
Relating fundamental- to approximate CF-based conceptsIn the Methods section, we provide a heuristic argumentfor the following
Observation 2 In approximately factorizable networks, funda-mental network concepts are approximately equal to theirapproximate CF-based analogs,
FundamentalNetworkConcept ≈ NetworkConceptCF,app.
The observation implies that in approximately factoriza-ble networks, Connectivity ≈ ConnectivityCF,app and Density ≈DensityCF,app, etc. Observation 2 is illustrated for networkdensity, centralization, heterogeneity, and clustering coef-ficients in Figure 2 (Drosophila PPI network), Figure 3(yeast PPI network), and Figure 4 (weighted andunweighted yeast gene co-expression networks; density isnot included due to limited space). A consequence of thisobservation is that the simple relationships satisfied byapproximate CF-based network concepts also apply totheir corresponding fundamental network concepts inapproximately factorizable networks. In particular, equa-tions (9) and (10) imply the following
Observation 3 In approximately factorizable networks,the following relationships hold among fundamental net-work concepts
mean(ClusterCoef) ≈ (1 + Heterogeneity2)2 × Density,(11)
and
k CF S
DensityS
n n
S
n
CF app i i
CF app
, ,
,
( ),
( )
( )
( )
=
=−
≈ ⎛⎝⎜
1
12
1
1
CF
CF CF ⎞⎞⎠⎟
=− −
−
2
1 1
1 2
,
( )
( )( )max( )
( ),Centralization
nS
n n
SCF app
CFCF
CF
nn
S
n
S
n
HeterogeneityCF app
⎛⎝⎜
⎞⎠⎟
≈ −⎛⎝⎜
⎞⎠⎟
=
1 1( )max( )
( ),
,
CFCF
CF
nnS
S
ClusterCoefS
SCF app i
2
12
2
1
1( )
( ( )),
( )
( ), ,
CF
CF
CF
CF
−
=⎛
⎝⎜
⎞
⎠⎟22
2
1
1
,
( ( ) )
min( , ) ( ), ,TopOverlapCF CF S
CF CF SCF app iji j
i j=
++
CF
CF 11 − CF CFi j,
(8)
HeterogeneityClusterCoef
DensityCF appCF app
CF app,
,
,,≈ −1
ClusterCoef Heterogeneity DensityCF app i CF app CF ap, , , ,( )≈ + ×1 2 2pp .
(9)
10
2S ( )CF≈
10
1
−≈
CF CF
CF CF Si j
i jmin( , ) ( )CF
TopOverlap CF CFS
S
CF SCF app ij i j
i, , max( , )
( )
( )
max( ( )≈ =2
1
1CF
CF
CF ,, ( )) ( )
( )
max( , )(
, , , ,
CF S
n
nS
S
k k
nHe
j
CF app i CF app j
1 2
12
1
CF CF
CF
≈ + tterogeneityCF app, ).2
(10)
TopOverlapk k
nHeterogeneityij
i j≈ +max( , )
( ).1 2
(12)
Table 2: Brief overview of different types of network concepts.
Input Matrix Type of Concept
Example: Connectivity
A - I fundamental Connectivityi(A - I) = ∑j≠iaij
ACF - I = CF CFτ - diag(CF2) CF-based Connectivityi(ACF - I) = CFi∑j≠iCFj
ACF,app = CF CFτ approximate CF-based
Connectivityi(ACF,app) = CFi∑jCFj
A network concept arises by evaluating a network concept function on a special type of input matrix. We assume that the diagonal elements of the matrix A - I are 0.
Page 6 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
Observation 3 is important since it highlights the fact thatseemingly disparate network concepts satisfy simple andintuitive relationships in approximately factorizable net-works. Equations (11) and (12) are illustrated in Figure 5(Drosophila PPI network), Figure 6 (yeast PPI network),and Figure 7 (weighted and unweighted yeast gene co-expression networks; TOM plots are not included due tolimited space). Equation (12) has several important con-sequences. To begin with, it illustrates that the topologicaloverlap between the most highly connected node and allother nodes is approximately constant. Specifically, if wedenote the index of the most highly connected node by[1] and its connectivity by k[1] = max(k), then
As an aside, we briefly mention that TopOverlap[1]j has asimple interpretation in terms of the hierarchical cluster-ing dendrogram that results from using dissTopOverlapij =1 -TopOverlapij as input. In this case, TopOverlap[1]j isrelated to the longest branch length in the dendrogram.
In the following, we relate TopOverlap[1]j to the funda-
mental network concept Centralization. According to
equation (3), ≈ Centralization + Density. Substi-
tuting this expression in equation (13) implies
TopOverlap[1]j ≈ (Centralization + Density)(1 + Heterogeneity2) (14)
Equation (14) is illustrated in Figure 5 (Drosophila PPInetwork), Figure 6 (yeast PPI network), and Figure 7(weighted and unweighted yeast gene co-expression net-works).
In factorizable networks, fundamental network concepts are simple functions of the connectivityHere we demonstrate another advantage of approximateCF-based network concepts. They allow one to relatefundamental network concepts to simple functions ofthe connectivity. Toward this end, note the followingsimple relationship between the conformity CF and theapproximate CF-based connectivity kCF,app:
TopOverlapk
nHeterogeneityj[ ]
[ ]( ).1
1 21≈ + (13)
max( )k
n
Yeast PPI module networks: the relationship between funda-mental network concepts NetworkConcept(A - I) (y-axis) and their approximate CF-based analogs NetworkConceptCF,app (x-axis)Figure 3Yeast PPI module networks: the relationship between fundamental network concepts Network-Concept(A - I) (y-axis) and their approximate CF-based analogs NetworkConceptCF,app (x-axis). This figure demonstrates Observation 2. A) Density versus DensityCF,app; B) Centralization versus CentralizationCF,app; C) Heterogeneity versus HeterogeneityCF,app; D) Intramodular clustering coeffi-cients ClusterCoefi versus ClusterCoefCF,app. In Figures A), B) and C), each dot corresponds to a module since these net-work concepts summarize an entire network module. In Fig-ure D), each dot corresponds to a node since these network concepts are node specific. A reference line with intercept 0 and slope 1 has been added to each plot.
A B
0.0 0.1 0.2 0.3 0.4 0.5 0.6
0.1
0.2
0.3
0.4
0.5
0.6
R^2=0.99
Approximate CF−Based Density
Den
sity
0.05 0.10 0.15 0.20 0.25 0.30 0.35
0.05
0.10
0.15
0.20
0.25
0.30
0.35
R^2=0.71
Approximate CF−Based Centralization
Cen
tral
izat
ion
C D
0.2 0.4 0.6 0.8 1.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
R^2=0.88
Approximate CF−Based Heterogeneity
Het
erog
enei
ty
− −
−
−
−−
− −−−
− −−
−
−−
−−
−−− −
−
−−
−−
−
−−
−−
−
−
−
−
−−
−
−
−−
− −
−
0.1 0.2 0.3 0.4 0.5 0.6
0.0
0.2
0.4
0.6
0.8
Approximate CF−Based Clustering Coefficients
Clu
ster
ing
Coe
ffici
ents
oo
ooooo
ooooo
oo
oooo
o
oo
o
oooooo
o
o
o
ooo
o
o
o
ooo
ooo
o
oo
o
oo
o
oo
o
oooooo
o
ooo
o
oo
o
oo
o
oo
o
o
ooooooooo
oo
o
ooooooooo
oooooooo
o
o
ooo
o
o
o
oooo
o
o
o
ooo
ooooooooooooo
o
o
oo
o
ooo
oo
o
oooo
oo
oo
o
o
o
ooo
oo
ooo
ooo
ooooo
ooo
ooo
oooooooooo
oo
o
oooooo
o
ooooooooooo
oo
oo
o
ooo
oo ooo
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
oo
o
o
oo
oo
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
o
o
oo
o
oo
o
o
oo
o
oo
oo
oo
o
o
oo
oo
oo
oooo
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
oo
o
o
oo
o
o
oo
o
o
o
o
oo
o
o
o
o
o
oooo
o
o
o
ooo
oo
ooooo
o
oo
o
o
o
o
o
ooooo
o
oo
oo
oo
o
o
oo
o
o
o
ooo
o
ooo
o
o
o
o
oo
o
o
o
ooo
o
o
o
ooo
o
o
oo
o
o
o
o oo
ooooo
oooooooo
oo
oo
o
o
ooo
o
ooo
oo
o
ooo
o
o
ooo
o
o
o
o
o
oooooo
oo
o
oo
oo
o
o
oo
oo
oo
o
o
o
o
o
oo
o
oooo
oo
oo
oo
oooooooooooo
oooo
oooooooooooooooooo
o
o
o
ooooooooo
ooo
o
o
o
o
oo
o
o
o
o
o
oo
o
ooo
o
o
o
ooooooo
o
o
oo
o
o
o
o
oooo
o
o
o
o
o
o
o
o
o
oooo
o
o
o
oo
o
ooo
o
o
ooo
o
ooo
o
oo
oo
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
oo
oo
o
o
o
oo
o
o
o
o
o
o
oo
o
ooooo
o
o
o
o
o
oo
oooo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
o
oo
oo
ooooo
o
o
ooo
oo
ooo
ooo
o
oo
o
oo
o
o
o
o
oo
ooo
ooooo
oooooooo
oo
o
oo
oo
o
oo
oo
o
o
oooo
o
o
ooooo
o
ooo
o
oooo
o
o
o
o
o
o
o
ooooooooooooooo
oo
o
o
ooo
o
ooo
o
oooooo
ooooo
oo
o
ooo
ooooo
o
oooo
o
oo
o
ooo
o
o
o
ooooo
o
oooooooo
ooo
o
o
oo
o
oo
o
oo
ooo
oooooooooo
oooo
oo
ooooo
oo
o
o
o
o
o
o
o
oo
o
o
oo
o
o
ooo
o
oo
oo
o
o
o
oo
o
o
o
o
o
o
o
oo
o
oo
oo
o
o
o
o
o
o
o
o
o
o
ooooooooo
oo
o
oo
o
ooo
o
oo
o
oo
o
oo
o
oo
o
o
o
o
o
o
o
ooo
o
oo
o
o
o
oo
o
o
o
o
o
ooo
o
oooo
o
ooo
ooooooo
o
o
oo
oooooooo
ooooo
o
o
oooooo
ooo
oo
o
oooo
o
oo
o
o
o
o
o
o
ooooo
o
ooo
ooooo
o
o
o
o
ooo
o
o
oo
oo
oo
ooo
oo
oo
oo
o
oo
o
o
o
o
ooo
o
o
oo
o
o
oo
o
o
oo
o
ooooo
o
o
oo
o
ooo
oo
oo
o
o
ooo
o
o
o
oo
oo
o
oooooo
oo
o
oo
o
oooo
oo
o
ooo
oo
oo
o
o
oooo
o
o
oo
oo
oo
o
oo
o
oo
o
o
oo
o
o
o
oo
o
oo
o
o
ooo
o
o
oo
o
oooo
o
o
o
oo
ooo
o
o
oo
o
o
o
ooooooooooooooooooooooooooooooooooooooooooooooooooo
oooooooooooooooooooooooooooooooooooooooooooo
o
o
ooooo
ooo
ooooooooooooooo
o
o
o
ooooooooo
ooo
o
oo
oooo
oo
o
o
ooo
o
o
o
o
oooooooooooo
oooo
o
o
o
o
o
o
o
oo
o
o
oooo
o
o
o
o
o
oo
oo
o
o
o
o
o
o
o
oo
o
oo
o
ooo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
ooo
oooo
ooooo
o
o
oooo
o
o
oo
o
o
ooo
o
oo
o
oo
o
oooooooooooooooooooo
oooooo
o
oooooooooo
ooooo
o
oo
oo
o
oo
o
o
oooooo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
oo
oo
oooo
o
o
o
oo
oo
o
o
o
o
oo
o
oo
o
o
ooo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
ooooo
ooo
ooo
o
o
o
ooo
oo
ooooooooooooo
o
ooo
o
oooooooooo
ooooooooo
o
oo
ooo
o
ooo
oo
o
o
o
ooo
o
oo
o
oo
o
o
o
oo
oooooooooooo
o
o
o
o
o
oo
o
o
o
oooooo
o
o
ooo
oo
ooooo o
o
o
o
o
o
o
o
o
o
o
o
oo
oooo
o
o
o
ooo
o
o
o
o
o
oooo
o
oo
o
o
oo
oo
ooooooooo
o
ooo
o
ooo
o
o
o
o
o
o
o
oo
o
oo
oo
o
o
o
oo
o
ooooo
o
oooo
oo
ooo
o
o
o
o
o
oo
o
o
ooo
o
o
o
o
o
ooooooooooooooo
oo
o
oooo
o
o
oo
o
o
oo
o
ooo
o
ooooo
o
o
o
o
ooo
o
oo
oooo
oo
o
ooo
o
oo
oo
o
o
ooo
oooo
oooooooo
o
ooo
ooo
oo
ooo
ooo
oooooooo
ooooooooo
oo o
oo
ooo
oo
oo
o
o
oo
oo
o
ooo
o
o
o
o
o
o
ooo
oo
o
o
oooooo
o
o
o
oooooo
ooo
ooooooo
o
o
o
ooo
oooooo
ooooooo
o
ooo
o
oo
o
o
o
o
oo
oo
o
oo
o
ooo
ooo
o
ooooo
o
ooooooooooooo
oooo
o
oo
o
ooooo
o
oooo
oo
o
o
oo
oo
o
oo
oo
ooooooooo
o
ooooo
o
oo
o
o
o
o
oooo
o
oooooo
o
o
o
oooo
o
oo
o
oooooooo
o
o
o
o
o
oooo
o
oooooo
ooooo
oooooo
o
o
o
o
oo
o
ooo
o
oo
o
o
o
o
o
oo
R^2=0.7
Drosophila PPI module networks: the relationship between fundamental network concepts NetworkConcept(A - I) (y-axis) and their approximate CF-based analogs NetworkConceptCF,app (x-axis)Figure 2Drosophila PPI module networks: the relationship between fundamental network concepts Network-Concept(A - I) (y-axis) and their approximate CF-based analogs NetworkConceptCF,app (x-axis). This figure demonstrates Observation 2. A) Density versus DensityCF,app; B) Centralization versus CentralizationCF,app; C) Heterogeneity versus HeterogeneityCF,app; D) Intramodular clustering coeffi-cients ClusterCoefi versus ClusterCoefCF,app. In Figures A), B) and C), each dot corresponds to a module since these net-work concepts summarize an entire network module. In Fig-ure D), each dot corresponds to a node since these network concepts are node specific. A reference line with intercept 0 and slope 1 has been added to each plot.
A B
0.0 0.1 0.2 0.3 0.4
0.0
0.1
0.2
0.3
0.4
R^2=0.99
Approximate CF−Based Density
Den
sity
0.1 0.2 0.3 0.4 0.5
0.1
0.2
0.3
0.4
R^2=0.9
Approximate CF−Based Centralization
Cen
tral
izat
ion
C D
0.2 0.3 0.4 0.5 0.6 0.7 0.8
0.2
0.3
0.4
0.5
0.6
0.7
R^2=0.87
Approximate CF−Based Heterogeneity
Het
erog
enei
ty
−− −−
−−−
−
−−
−−
−− −−
−
−−− −−
−
−
−−−
−−
0.1 0.2 0.3 0.4 0.5 0.6
0.0
0.2
0.4
0.6
0.8
1.0
Approximate CF−Based Clustering Coefficients
Clu
ster
ing
Coe
ffici
ents
oooooooooo
ooo
ooo
ooo
o
ooooo
oo
o
o
oooo
oo
ooooo
ooooooo
o
ooo
o
o
ooooo
oo
ooo
oo
ooo
o
ooo
o
oo
oooo
oo
o
ooooooo
o
o
ooooo
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
ooooo
o
oooo
oo
oo
o
o
o
o
o
o
o
ooo
oo
o
o
oo
o
ooo
o
o
o
o
o
oo
o
ooo
o
o
o
o
o
oo
o
o
o
o
o
oo
o
oo
o
ooo
o
oooo
o
o
o
ooo
oooooooo
oo
o
oooo
oooooo
oo
o
ooo
oooooooooo
o
ooo
o
ooo
ooo
o
o
ooooooo
oooooooooooooooooooooooooo
o
oooooooooooooooooooooooooo
oooo
ooo
ooo
oo
o
o
oo
o
oooo
oo
o
oooo
o
oooo
o
ooo
o
oo
o
ooo
o
oooooooo
o
oooo
oo
o
o
o
o
o
o
o
oo
o
oo
ooooooo
oo
oo
ooooooo
o
oo
oooo
oooo
o
o
o
o
o
o
o
o
oo
oo
o
oo
o
ooo
oo
o
ooo
oo
o
oo
o
ooooo
o
o
o
o
ooo
oo
oo
ooooo
o
oo
o
ooooooooooooooooo
oooooo
o
o
oooooooooooooo
oooooooooooooooooooo
o
o
ooooooooooo
o
o
ooooooo
o
oooooo
ooo
oo
o
oooooooooooo
oooooooo
ooo
ooooo
o
o
o
o
ooo
ooo
oo
oo
oooo
o
oo
o
oo
o
ooooooooooooooooooooooooooooooo
ooo
o
ooooooooooo
o
oooooooo
ooooooo
o
o
oo
oooooooooo
o
oooooooooo
ooooooooooo
o
o
o
ooooo
oo
oo
o
o
o
o
o
oooooo
o
o
oooooooo
oo
ooo
oooo
o
o
oooo
oooooooooo
o
o
oo
o
ooo
o
ooooo
o
oooooooo
ooooooooo
oooo
oo
ooooo
o
oooooooo
o
ooo
o
o
ooo
oo
o
o
oo
o
o
o
ooooooooo
ooooooooooooo
o
oo
o
ooooo
o
ooooooooooooooooooooooooooooooooooooo
o
oooooooooooooooooo
ooooooooo
oo
o
o
oooooooo
oooooo
o
o
o
oooo
oooooooooooooooooo
oooooooooooooooooooo
o
oooooooooooooo
o
oooo
o
oooooooooooo
o
oooooooooooooooooooooooooooo
o
oooooooooooooooooooooooooooooooooooooooooooooooo
o
ooooo
ooooo
oo
o
oooooooooooooooo
o
oo
o
oooooo
o
ooooooooooooooo
o
o
o
oo
o
oooooooooooooooooooooooooooooooooooooooooooooooooooo
o
ooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
o
oooooo
o
oooooo
oooooooooooooooooooooooooooooooooo
o
oooooooooooooooooooooooooooooooooooo
o
oo
o
ooo
R^2=0.87
Page 7 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
Since in approximately factorizable networks kCF,i ≈ ki, wefind that the conformity CF is approximately given by thescaled connectivity, i.e.
This equation shows that conformity can be interpreted asa scaled connectivity in approximately factorizable net-works. Since approximate CF-based network concepts are
simple functions of the conformity, substituting
for CF implies that approximate CF-based concepts can beapproximated by simple functions of the connectivity. Forexample, we find the following simple expressions for thecluster coefficient and the topological overlap.
Observation 4CFk
SiCF app i
CF app= , ,
,( ).
1 k(15)
CFk
k≈
S1( ). (16)
k
kS1( )
ClusterCoefS
S
TopOverlapk k S S
i
iji j
≈
≈+
( ( ))
( ( )),
( ( ) (
22
13
2 1
k
k
k k)))
min( , ) ( ) ( )
( , ) ( )
( ),
k k S S k k
k k
n
S
Si j i j
i j
1 1
2
1k kkk+ −
≈max
Drosophila PPI module networks: the relationship between fundamental network conceptsFigure 5Drosophila PPI module networks: the relationship between fundamental network concepts. This figure demonstrates Observation 3 and equation (14). In Figures A) and B), each point is a protein colored by its module assign-ment, and the red line has intercept 0 and slope 1. Figure A) illustrates the relationship between the mean clustering coef-ficient (short horizonal line) and (1 + Heterogeneity2)2 * Den-sity (equation (11)). Figure B) illustrates the relationship between the topological overlap with the hub node and (Den-sity + Centralization) * (1 + Heterogeneity2) (equation (14)). Figure C) is a color-coded depiction of the topological over-lap matrix TopOverlapij in the turquoise module network. Fig-ure D) represents the corresponding approximation max(ki,kj)(1 + Heterogeneity2)/n (equation (12)). Figures E) and F) are their analogs for the brown module. The turquoise and the brown module represent the largest and third largest module. Analogous plots for the other modules can be found in our online supplement.
A B
−− −−
−−−
−
−−
−−
−− −−
−
−−
− −−
−
−−
−−−
−0.1 0.2 0.3 0.4 0.5
0.0
0.2
0.4
0.6
0.8
1.0
(1+Heterogeneity^2)^2*Density
Clu
ster
ing
Coe
ffici
ent
oooooooo
oo
o
oo
oo
o
ooo
o
ooooo
oo
o
o
oo
oo
oo
o
oooo
oo
o
oo
o
o
o
ooo
o
o
oo
oo
o
oo
ooo
oo
ooo
o
ooo
o
oo
ooo
o
oo
o
ooooooo
o
o
ooo
oo
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
ooooo
o
oooo
oo
oo
o
o
o
o
o
o
o
ooo
oo
o
o
oo
o
ooo
o
o
o
o
o
oo
o
ooo
o
o
o
o
o
oo
o
o
o
o
o
oo
o
oo
o
ooo
o
oooo
o
o
o
ooo
oooooooo
oo
o
o
ooo
o
ooooo
oo
o
ooo
o
oooooo
ooo
o
ooo
o
o
oo
ooo
o
o
oooooo
o
oooooooooooooooooooooooooo
o
oooo
ooooooooooooooooooooo
o
oooo
ooo
o
oo
oo
o
o
oo
o
oooo
oo
o
oooo
o
ooo
o
o
ooo
o
o
o
o
ooo
o
oooooo
oo
o
oooo
oo
o
o
o
o
o
o
o
oo
o
oo
ooo
oo
oo
oo
oo
ooooooo
o
oo
oooo
oooo
o
o
o
o
o
o
o
o
oo
oo
o
oo
o
oo
o
oo
o
ooo
oo
o
oo
o
ooooo
o
o
o
o
ooo
oo
oo
ooooo
o
oo
o
ooooooooooooooooo
oooo
oo
o
o
ooooo
ooooooooo
oooooooooooooooooooo
o
o
ooooooooooo
o
o
ooo
ooo
o
o
oooooo
ooo
oo
o
ooo
o
ooooooo
o
oooooooo
o
oo
oo
ooo
o
o
o
o
ooo
ooo
oo
oo
oooo
o
o
o
o
oo
o
ooo
ooooooooooooooooooooo
ooooooo
ooo
o
ooo
oooooooo
o
oooooooo
ooooooo
o
o
o
o
o
oooo
o
oooo
o
oooooooooo
ooooooooooo
o
o
o
ooooo
o
o
oo
o
o
o
o
o
o
ooooo
o
o
oooooooo
oo
oo
o
ooo
o
o
o
oooo
oooooooooo
o
o
oo
o
ooo
o
ooo
oo
o
ooooooo
o
ooooooooo
oooo
oo
ooooo
o
ooooooo
o
o
ooo
o
o
oo
o
oo
o
o
oo
o
o
o
ooooooo
oo
o
ooo
ooooooooo
o
oo
o
ooooo
o
oooooooooooooooooooooooooooooooooo
ooo
o
ooooooooooooo
o
oooo
o
oooooooo
oo
o
o
ooooooo
o
oooooo
o
o
o
oooo
ooooooooooooooooo
o
oooooooooooooooooooo
o
oooooooooooooo
o
oooo
o
oooooooooooo
o
ooooooooooooooooooooooooooo
o
o
ooooooooooooooooooooo
o
oooooooooooooooooooooooooo
o
oooo
o
ooooo
oo
o
o
ooooooooooooooo
o
oo
o
oooooo
o
ooooooooooooooo
o
o
o
oo
o
oooooooo
oo
ooo
oooooooooooooooo
o
oooooooooooooooooooooo
o
oooooooooooooooooooooooooooooooooooooooooooooo
ooooooooooooooooo
o
oooooo
o
oooooo
oooooooooooooooooooooooooooooooooo
o
oooooooooooooooooooooooooooooooooooo
o
oo
o
ooo
R^2=0.87
o
o
o
o
o
o
o
oo
o
o
ooo
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
o
o
oo
ooo
oo
ooo
ooo
oo
o
o
o
oooo
o
oo
oo
o
o
o
ooo
ooooo
o
o
oo
o
ooo
o
o
o
o
o
oooo
o
o
o
oo
o o
o
o
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
o
o
ooo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
oo
o
o
o
oo
o
o
oo
oo
oooo
ooo
o
oo
o
o
oo
o
o
oo
o
o
o
o
o
o
o
o
oo
ooo
o
oooo
oooo
oo
ooo
ooo
ooo
o
oooo
o
oo
oo
ooooo
o
o
o
o
o
oooooooo
o
oooooooooooo
o
oooo
ooo
o
o
o
o
oo
o
o
o
oo
o
o
o
o
oo
o
o
oooooo
o
o
oo
o
oooo
o
o
o
o
oooo
oo
ooo
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
ooooooooo
o
oooo
oo
o
o
oo
ooooo
o
oo
o
o
o
o
o
ooo
o
oo
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
ooo
o
oo
oo
o
o
oo
ooo
oo
oooooooooooooooooooooooooooooooooooo
o
o
o
ooooo
ooo
o
oo
oo
oooo
o
oo
o
o
o
oooooo
oo
o
ooooo
ooo
ooo
o
oo
oo
o
oo
oooo
oooo
o
oo
oo
ooo
oooo
o
o
oo
ooo
o
o
o
oo
o
ooooooo
ooo
o
o
oo
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
o
o
oo
ooo
oo
o
ooooooo
o
oooooo
o
oo
o
ooooooo
ooo
o
o
o
o
ooo
o
oo
o
o
o
o
o
oo
o
ooo
o
o
o
oo
o
o
o
o
oo
o
oooo
o
oooo
o
o
oo
ooooo
oo
oo
o
oooo
o
o
o
o
o
o
o
o
o
ooo
oo
oo
o
o
o
o
o
oooooo
o
ooooooooo
oo
o
o
o
o
oo
o
o
ooo
o
ooo
oo
o
oo
ooooo
oo
o
ooo
o
o
o
o
oo
o
o
o
o
ooo
ooo
o
oooooo
o
o
o
o
o
o
o
o
o
oooo
o
o
o
o
oo
oooooo
o
o
o
o
oo
o
ooo
o
o
o
ooooooooooo
oooooooo
o
ooo
o
oo
oo
o
oo
o
o
oo
o
ooo
oo
oo
oooooo
oooo
ooo
ooo
oo
oooo
o
oo
o
o
o
o
oo
o
o
o
o
ooooo
o
oo
oooooo
o
oo
o
oo
o
oooo
o
oooo
oooooo
o
o
oooo
o
ooooo
ooo
o
ooooo
o
o
oo
o
o
ooo
ooo
o
o
o
o
o
ooo
o
oo
o
o
oo
oo
oo
o
o
o
oooo
o
oo
o
ooooooooo
oooo
oo
oo
o
o
oo
oooo
o
o
o
o
o
ooo
ooo
ooooooo
o
o
o
o
ooooooo
oo
o
o
o
o
oooooo
o
ooo
o
ooo
ooooooo
o
o
o
o
oo
o
oooo
o
oooo
o
oo
o
ooooooo
o
o
o
ooooo
ooo
oo
o
oo
o
o
oo
o
o
o
oo
oo
o
oo
o
oo
o
o
oooo
o
oo
o
o
o
o
oo
o
oo
oo
ooooo
o
o
ooooo
o
ooooooo
ooooo
o
o
o
ooo
ooo
oo
oooo
ooo
o
oooo
o
o
o
o
o
oo
oo
o
oooo
o
oo
oo
o
ooo
o
oooo
o
oo
oo
o
o
oo
o
o
o
o
oo
o
oo
o
o
oooooo
o
oooooo
ooo
o
oooooo
o
o
o
ooo
ooo
o
o
oo
oo
o
ooo
o
o
ooooo
o
o
oo
ooo
oo
ooo
oo
o
o
o
o
ooo
ooo
o
ooo
o
ooooo
o
o
oo
oo
oo
o
oo
o
o
oooo
ooo
o
oo
o
o
0.2 0.4 0.6 0.8
0.0
0.2
0.4
0.6
(Centralization+Density)*(1+Heterogeneity^2)
TO
M w
ith th
e H
ub N
ode
R^2=0.91
C D E F
Yeast gene co-expression module networks: the relationship between fundamental network concepts NetworkConcept(A - I) (y-axis) and their approximate CF-based analogs Network-ConceptCF,app (x-axis)Figure 4Yeast gene co-expression module networks: the rela-tionship between fundamental network concepts NetworkConcept(A - I) (y-axis) and their approximate CF-based analogs NetworkConceptCF,app (x-axis). This figure demonstrates Observation 2. A reference line with intercept 0 and slope 1 has been added to each plot. The fig-ures on the left (right) hand side depict network concepts from the weighted (unweighted) network. A) and B) Central-ization versus CentralizationCF,app; C) and D) Heterogeneity versus HeterogeneityCF,app; E) and F) Intramodular clustering coefficients ClusterCoefi versus ClusterCoefCF,app. The analogous plots for Density are not presented since the fundamental network concepts and their approximate CF-based analogs are almost identical and the dots fall near the reference line with R2 = 1 for both weighted and unweighted networks, and thus are omitted due to limited space. In Figures A), B), C) and D), each dot corresponds to a module since these net-work concepts summarize an entire network module. In Fig-ure E) and F), each dot corresponds to a node since these network concepts are node specific.
A B
0.04 0.06 0.08 0.10 0.12 0.14 0.16
0.02
0.04
0.06
0.08
0.10
0.12
0.14
p=7, R^2=0.99
Approximate CF−Based Centralization
Cen
tral
izat
ion
0.15 0.20 0.25 0.30 0.35 0.40
0.2
0.3
0.4
0.5
tau=0.65, R^2=0.97
Approximate CF−Based Centralization
Cen
tral
izat
ion
C D
0.5 0.6 0.7 0.8 0.9 1.0
0.50
0.55
0.60
0.65
p=7
Approximate CF−Based Heterogeneity
Het
erog
enei
ty
0.4 0.6 0.8 1.0 1.2 1.4 1.6
0.3
0.4
0.5
0.6
0.7
0.8
tau=0.65
Approximate CF−Based Heterogeneity
Het
erog
enei
ty
E F
−−−−
−
−
−−−
0.05 0.10 0.15 0.20 0.25 0.30
0.00
0.10
0.20
0.30
Approximate CF−Based Clustering Coefficients
Clu
ster
ing
Coe
ffici
ents
o
o
o
o
o
ooooooo
oo
o
o
o
o
o
o
oo
o
oo
o
o
oo
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
oo
o
o
o
oo
ooo
o
o
o
o
o
ooo
oo
o
o
oo
ooo
o
oo
o
oooo
o
oo
oooooo
ooooooo
oo
o
oo
o
oo
o
o
oooooooooo
o
ooooooooooo
oo
o
o
oo
oo
oo
oo
oo
o
o
oooo
o
oo
o
o
ooooo
oo
o
oo
o
ooo
oo
oo
ooooo
o
ooooo
o
o
oo
o
ooooo
oo
o
ooo
o
o
o
ooo
oo
ooooo
o
oo
ooo
o
ooooooooo
ooo
o
o
o
oooo
o
o
o
o
o
oo
o
o
oo
o
oo
o
ooo
o
o
ooo
o
o
o
oooo
oooo
o
ooo
oooooooo
oooooooo
o
ooooo
oooooooo
o
oooooo
oo
o
ooooo
o
o
o
o
oo
ooooo
o
oooooooo
o
o
oooo
o
oooooo
o
ooo
oo
o
oooooooo
oooooooo
o
ooooo
o
ooooooo
ooooooo
o
oooo
oo
oo
oo
o
oo
ooo
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
oo
ooooo
o
oooo
o
o
o
o
o
ooooo
ooo
o
ooo
ooo
oo
o
o
oooo
ooo
o
o
oo
oo
ooooo
o
o
oooooooo
oo
o
oo
o
ooooo
o
o
oooo
oo
ooooooooooooo
o
oooooooooooo
o
oooooo
o
oooooo
o
o
o
oooooo
o
ooo
o
ooooooo
o
oooo
o
oo
o
oooooooooooooooooooo
ooooooo
ooooooooooooooooooooooooooooo
o
o
o
ooooo
o
ooooooooo
o
oooooooo
ooo
o
o
o
ooooooo
o
ooo
o
ooooooooooo
o
ooooooooooo
o
oooo
o
ooooo
ooooooooooooooooooooooooo
o
ooo
o
oooooooo
ooooo
o
o
oo
oooooooooo
oooooo
o
ooooo
o
oooooo
o
o
oooooooooooo
ooo
o
o
ooooooooooooo
o
oooooooo
oooooooooooooooooooooooooooooo
oooooooo
o
ooooooooooo
oo
oooo
ooooo
ooo
ooooo
o
oo
o
oooooooooooooooooooo
ooooooo
o
oooooooooo
o
oo
o
o
o
ooo
o
o
ooooooooooooooooooooooo
o
ooooooo
o
ooo
ooooooo
ooooooooooooooo
oo
ooo
o
o
oo
o
ooo
o
oooo
o
o
o
o
ooo
oooooo
ooo
o
ooo
o
ooooooooooooo
o
ooooooooo
o
o
oooooooo
o
ooooooooo
o
oooo
ooooooooooooooooooo
o
oo
oooooo
o
oo
ooooo
ooooooooooooooooooooo
o
ooooooo
oooooooooooooooo
o
oooo
o
ooooooooooooooooo
ooo
o
oooo
o
oooooooooooooo
o
oo
oooooooo
o
ooo
o
oo
o
ooooooooooooooooo
o
ooooooooooo
o
ooooo
oo
ooooooooo
ooo
ooooooooooooooo
o
oo
ooooooooooo
oooooooooooooo
o
ooooooooo
o
o
o
o
ooo
o
ooooooooooooooooooooooo
o
ooooooo
o
ooooooo
o
oooooooooooo
o
o
ooo
ooooo
oo
ooooo
oooooooooo
o
ooooooo
o
oooooo
o
o
o
oo
o
o
ooo
o
oo
o
o
o
o
o
o
o
oo
o
oo
o
o
o
ooo
o
o
oooooooo
ooo
ooo
o
oo
o
o
o
oooo
ooo
ooooo
o
oo
o
oooo
o
ooooooo
oo
oooo
o
o
oo
o
ooooo
o
o
oooo
oo
oo
oo
oooooo
o
oo
o
ooo
o
ooooo
o
oo
oooooooo
ooo
oooooooooooooo
oooooooooooo
o
oooooo
o
ooo
ooooooooooooooooo
oo
oooooooooo
ooooo
oooo
o
o
ooooo
ooo
o
o
o
ooooooooooooo
o
oooooooooooo
oooooooooo
ooooooooooooooooo
oooooooo
oo
o
oooooooo
oooo
ooooooooooooooooo
oooooooo
o
ooooooooooooooooooo
oo
o
o
o
oooo
ooooooooooooooooo
ooooo
oooo
oo
ooooo
o
o
oooooooooo
o
ooo
ooo
ooooo
oooooooo
o
ooo
o
oo
ooooooooooooooooooooo
o
oo
o
ooooo
oo
o
o
o
oooooo
oooo
ooo
o
ooooooooooooooooooooooo
o
oo
oooo
oooooooooo
oooooooooo
o
ooooo
p=7, R^2=0.82
−− −
−
−
−
−−−
0.2 0.4 0.6 0.8
0.0
0.2
0.4
0.6
0.8
1.0
Approximate CF−Based Clustering Coefficients
Clu
ster
ing
Coe
ffici
ents
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
oo
o
oo
o
o
o
o
o
ooo
oo
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
o
o
ooo
o
o
oo
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
oo
ooo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
ooo
o
o
o
oo
oo
o
ooo
o
ooo
o
o
ooo
o
ooo
ooo
oo
oo
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
oo
o
o
ooo
ooo
ooo
o
o
oo
o
o
o
oo
o
oo
o
o
o
o
o
o
ooo
o
o
oo
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
ooo
o
o
o
o
o
o
o
o
o
oooo
o
o
o
oo
o
o
ooo
o
oo
ooo
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
oo
o
o
o
o
o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
o
oo
oo
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
ooo
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
oo
o
oo
oo
o
o
o
o
oo
o
o
o
oo
o
o
oooo
o
o
o
o
o
o
o
ooo
o
oo
o
o
o
o
ooo
oo
ooo
o
o
o
o
o
o
o
o
o
o
ooo
o
oo
o
o
oo
o
o
o
o
o
o
oo
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oooo
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oooo
oo
o
o
oo
o
o
o
o
o
ooo
ooo
o
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
oo
oo
oo
o
o
o
o
o
o
o
oo
o
o
o
ooo
o
oo
o
o
o
o
o
o
oooo
o
o
o
o
o
o
o
ooo
o
ooo
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
oooooo
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
oo
o
o
oo
o
o
o
o
o
ooo
o
o
o
o
o
o
ooo
o
oo
o
o
o
o
o
o
o
o
o
o
o
oooo
oo
o
oo
o
oo
o
o
o
ooo
o
o
o
o
o
o
o
oo
o
o
oo
o
o
oo
oo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
oo
ooo
oo
o
o
ooo
o
oo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
oo
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
oo
o
o
o
oo
oo
o
o
o
o
o
o
o
o
o
oo
o
ooo
oo
o
oooo
oo
o
o
o
oo
o
o
o
o
o
o
ooo
o
oo
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
oo
o
o
o
oo
o
o
oooo
o
ooo
o
o
oo
o
o
o
oo
o
o
oo
o
o
ooo
o
o
o
ooo
o
oo
oo
ooo
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
ooo
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
oooo
o
o
o
oo
o
oo
o
o
oo
o
o
o
oo
o
oo
oo
o
o
o
oo
oo
o
o
oo
o
oo
o
o
o
o
oo
ooooo
o
oo
o
oo
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
ooo
o
o
o
o
o
ooo
o
o
o
o
o
o
oo
oo
oooo
o
o
o
o
oo
o
o
oo
o
o
o
oo
ooo
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o
oo
o
o
oo
o
oo
o
oo
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
o
oo
o
o
oo
o
oo
o
o
o
o
o
o
o
ooo
o
o
o
ooo
o
o
o
o
o
o
oo
oo
oo
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
oo
ooo
oooo
o
oo
ooo
oooo
o
o
ooooooo
ooooo
o
o
o
o
o
oo
o
oo
oo
oooooo
o
ooo
o
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
oo
o
o
o
o
oo
oo
oo
oo
oo
oo
o
oo
oo
oo
o
oo
oooo
o
o
o
o
o
o
o
ooo
o
o
oo
o
o
o
oo
o
o
o
o
ooooo
o
o
oo
oo
oo
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
ooooo
o
o
o
o
o
ooo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
ooo
o
oo
oooo
oo
o
oo
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
oo
oo
o
o
oo
ooo
o
o
o
oo
oo
o
o
ooo
o
oo
o
o
oo
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
ooo
o
o
o
oo
oo
ooo
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
oo
ooo
o
oo
oooo
o
o
o
o
o
o
oo
o
o
o
o
o
oo
oo
o
oo
o
ooo
o
o
o
o
o
o
o
o
o
ooooo
o
ooo
oo
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
oo
o
o
oo
oo
oo
oo
o
o
oo
o
oo
o
o
o
o
o
o
o
o
oooo
o
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
oo
o
o
o
o
oo
oo
o
o
o
oo
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
oo
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
tau=0.65, R^2=0.6
5
Page 8 of 20(page number not for citation purposes)
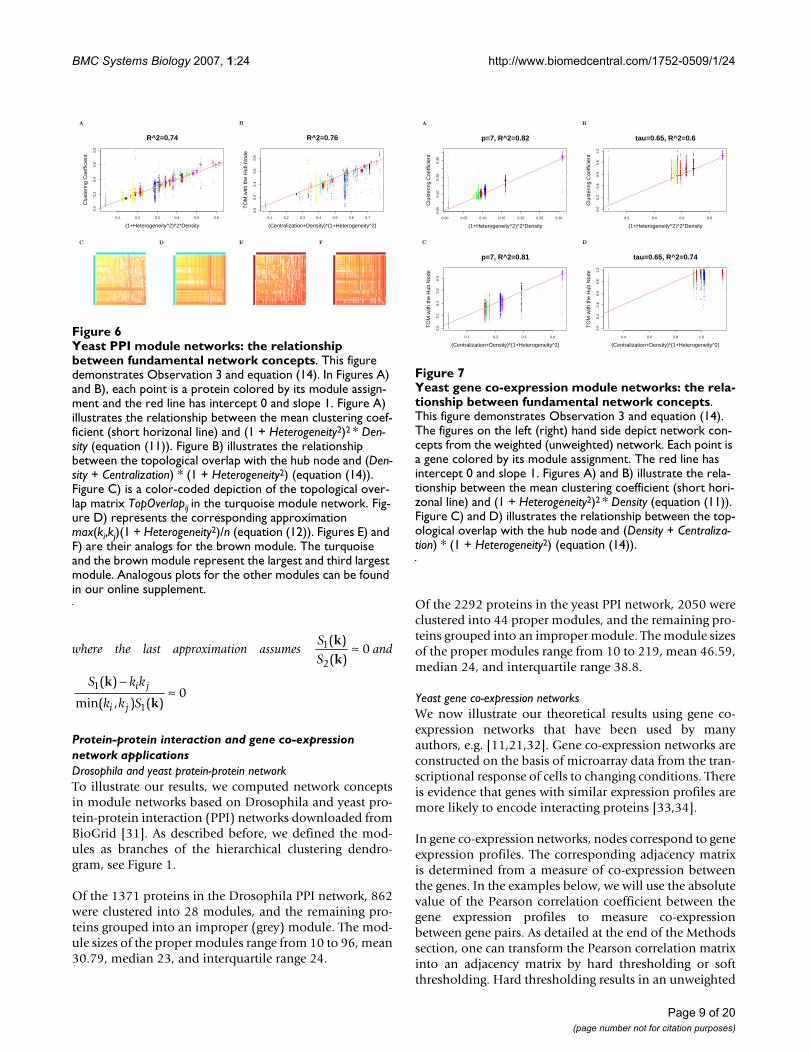
BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
where the last approximation assumes and
Protein-protein interaction and gene co-expression network applicationsDrosophila and yeast protein-protein networkTo illustrate our results, we computed network conceptsin module networks based on Drosophila and yeast pro-tein-protein interaction (PPI) networks downloaded fromBioGrid [31]. As described before, we defined the mod-ules as branches of the hierarchical clustering dendro-gram, see Figure 1.
Of the 1371 proteins in the Drosophila PPI network, 862were clustered into 28 modules, and the remaining pro-teins grouped into an improper (grey) module. The mod-ule sizes of the proper modules range from 10 to 96, mean30.79, median 23, and interquartile range 24.
Of the 2292 proteins in the yeast PPI network, 2050 wereclustered into 44 proper modules, and the remaining pro-teins grouped into an improper module. The module sizesof the proper modules range from 10 to 219, mean 46.59,median 24, and interquartile range 38.8.
Yeast gene co-expression networksWe now illustrate our theoretical results using gene co-expression networks that have been used by manyauthors, e.g. [11,21,32]. Gene co-expression networks areconstructed on the basis of microarray data from the tran-scriptional response of cells to changing conditions. Thereis evidence that genes with similar expression profiles aremore likely to encode interacting proteins [33,34].
In gene co-expression networks, nodes correspond to geneexpression profiles. The corresponding adjacency matrixis determined from a measure of co-expression betweenthe genes. In the examples below, we will use the absolutevalue of the Pearson correlation coefficient between thegene expression profiles to measure co-expressionbetween gene pairs. As detailed at the end of the Methodssection, one can transform the Pearson correlation matrixinto an adjacency matrix by hard thresholding or softthresholding. Hard thresholding results in an unweighted
S
S1
20
( )
( )
kk
≈
S k k
k k Si j
i j
1
10
( )
min( , ) ( )
k
k
−≈
Yeast PPI module networks: the relationship between funda-mental network conceptsFigure 6Yeast PPI module networks: the relationship between fundamental network concepts. This figure demonstrates Observation 3 and equation (14). In Figures A) and B), each point is a protein colored by its module assign-ment and the red line has intercept 0 and slope 1. Figure A) illustrates the relationship between the mean clustering coef-ficient (short horizonal line) and (1 + Heterogeneity2)2 * Den-sity (equation (11)). Figure B) illustrates the relationship between the topological overlap with the hub node and (Den-sity + Centralization) * (1 + Heterogeneity2) (equation (14)). Figure C) is a color-coded depiction of the topological over-lap matrix TopOverlapij in the turquoise module network. Fig-ure D) represents the corresponding approximation max(ki,kj)(1 + Heterogeneity2)/n (equation (12)). Figures E) and F) are their analogs for the brown module. The turquoise and the brown module represent the largest and third largest module. Analogous plots for the other modules can be found in our online supplement.
A B
−−−
−−
−
− −−−
−−
−
−
−−
− −
−−−
−−
−−
−−
−
−
−−
−−
−
−
−−
−
−
−
−−
−−
−
0.1 0.2 0.3 0.4 0.5 0.6
0.0
0.2
0.4
0.6
0.8
(1+Heterogeneity^2)^2*Density
Clu
ster
ing
Coe
ffici
ent
oo
oo
ooo
oooo
o
oo
oooo
o
oo
o
ooo
o
oo
o
o
o
ooo
o
o
o
oo
o
ooo
o
oo
o
oo
o
oo
o
ooooo
o
o
o
oo
o
oo
o
oo
o
oo
o
o
ooooo
oooo
oo
o
ooooooooo
oooooooo
o
o
o
oo
o
o
o
ooo
o
o
o
o
ooo
oooooo
ooooooo
o
o
oo
o
ooo
oo
o
oooo
oo
oo
o
o
o
ooo
oo
ooo
ooo
ooooo
ooo
ooo
oooo
oooooo
oo
o
o
ooooo
o
oooo
ooooooo
oo
oo
o
ooo
o
o ooo
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
oo
o
o
oo
oo
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
oo
oo
oo
o
ooo
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
o
oo
o
o
oo
o
o
o
o
oo
o
o
o
o
o
oooo
o
o
o
ooo
oo
o
oooo
o
oo
o
o
o
o
o
ooooo
o
o
o
oo
oo
o
o
o
o
o
o
o
ooo
o
ooo
o
o
o
o
o
o
o
o
o
ooo
o
o
o
ooo
o
o
oo
o
o
o
ooo
ooooo
oooooo
oo
oo
oo
o
o
ooo
o
ooo
o
o
o
ooo
o
o
ooo
o
o
o
o
o
oooooo
o
o
o
oo
oo
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
oo
oo
oo
oooooooooooo
oooo
oooo
ooooooooo
ooooo
o
o
o
ooooooooo
ooo
o
o
o
o
oo
o
o
o
o
o
oo
o
ooo
o
o
o
ooooooo
o
o
oo
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
oo
o
ooo
o
o
ooo
o
ooo
o
oo
oo
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
o
oo
o
o
o
o
o
o
oo
o
o
oooo
o
o
o
o
o
oo
o
ooo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
o
oo
oo
ooooo
o
o
ooo
oo
ooo
ooo
o
oo
o
oo
o
o
o
o
oo
oo
o
o
oo
oo
ooo
oo
oo
o
oo
o
oo
o
o
o
o
o
oo
o
o
oooo
o
o
o
oooo
o
ooo
o
oooo
o
o
o
o
o
o
o
oooooo
oo
oooo
oo
o
oo
o
o
oo
o
o
oo
o
o
oooooo
ooooo
oo
o
o
oo
o
o
ooo
o
oo
oo
o
o
o
o
oo
o
o
o
o
o
oooo
o
oooooooo
ooo
o
o
oo
o
o
o
o
oo
o
oo
oooooo
oo
oo
oooo
oo
ooooo
oo
o
o
o
o
o
o
o
oo
o
o
oo
o
o
ooo
o
oo
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
oo
oo
o
o
o
o
o
o
o
o
o
o
ooooooooo
oo
o
o
o
o
oo
o
o
oo
o
oo
o
oo
o
oo
o
o
o
o
o
o
o
ooo
o
oo
o
o
o
oo
o
o
o
o
o
ooo
o
oooo
o
ooo
oo
ooo
oo
o
o
oo
oooooooo
o
ooo
o
o
o
ooooo
o
ooo
oo
o
ooo
o
o
oo
o
o
o
o
o
o
oooo
o
o
ooo
oo
ooo
o
o
o
o
ooo
o
o
o
o
oo
oo
ooo
o
o
oo
oo
o
oo
o
o
o
o
ooo
o
o
oo
o
o
o
o
o
o
oo
o
ooooo
o
o
oo
o
ooo
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
ooooo
o
oo
o
oo
o
oooo
oo
o
oo
o
oo
o
o
o
o
oooo
o
o
oo
oo
oo
o
oo
o
o
o
o
o
oo
o
o
o
oo
o
oo
o
o
o
oo
o
o
oo
o
oooo
o
o
o
oo
ooo
o
o
o
o
o
o
o
ooooooooooooooooooooooooooooooooooooooooooooooooooo
ooooooooooooooooooo
ooooooooooooooooooooooooo
o
o
o
o
ooo
o
oo
o
oooooooooooooo
o
o
o
ooo
oooooo
ooo
o
o
o
o
ooo
oo
o
o
oo
o
o
o
o
o
oooo
oo
ooooo
o
o
ooo
o
o
o
o
o
o
o
oo
o
o
ooo
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o
o
oo
o
oo
o
o
oo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
ooo
ooo
o
ooooo
o
o
oooo
o
o
oo
o
o
o
oo
o
oo
o
oo
o
oooooooooooo
oooooooo
oooooo
o
oooooooooo
ooooo
o
oo
oo
o
oo
o
o
o
ooooo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
oo
oo
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
ooooo
ooo
ooo
o
o
o
ooo
o
o
ooooooooooooo
o
ooo
o
o
ooooooooo
ooooooooo
o
oo
ooo
o
ooo
o
o
o
o
o
o
oo
o
oo
o
oo
o
o
o
oo
oooooooo
oooo
o
o
o
o
o
oo
o
o
o
o
ooo
oo
o
o
ooo
oo
ooo
o
o o
o
o
o
o
o
o
o
o
o
o
o
oo
oooo
o
o
o
oo
o
o
o
o
o
o
oooo
o
oo
o
o
oo
oo
oooooooo
o
o
ooo
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
oo
o
ooooo
o
oooo
o
o
ooo
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
ooooooo
o
ooooooo
oo
o
o
ooo
o
o
oo
o
o
oo
o
oo
o
o
ooooo
o
o
o
o
o
oo
o
oo
oooo
oo
o
ooo
o
oo
oo
o
o
ooo
oooo
o
ooooooo
o
ooo
o
o
o
o
o
o
oo
o
oo
ooooooo
o
ooooooooo
oo o
oo
ooo
oo
oo
o
o
oo
oo
o
ooo
o
o
o
o
o
o
ooo
oo
o
o
oo
o
oo
o
o
o
o
o
ooooo
ooo
ooooooo
o
o
o
ooo
ooooo
o
ooooooo
o
oo
o
o
oo
o
o
o
o
oo
oo
o
oo
o
ooo
oo
o
o
ooooo
o
ooooooooooooo
oooo
o
oo
o
ooooo
o
oooo
oo
o
o
oo
o
o
o
oo
oo
ooooo
oooo
o
ooooo
o
oo
o
o
o
o
oooo
o
oooooo
o
o
o
oooo
o
oo
o
oooooooo
o
o
o
o
o
oo
oo
o
oooooo
ooooo
oooo
oo
o
o
o
o
oo
o
ooo
o
oo
o
o
o
o
o
oo
R^2=0.74
ooooo
oo
o
o
o
oo
o
ooo
oo
ooooooo
ooooooooooooooooooooooooo
oo
o
ooo
ooo
o
ooooooooo
o
ooo
oo
o
ooo
o
oooo
oo
ooooooooo
ooooo
oo
o
o
o
ooooooooo
o
oooooooooooooooo
o
o
oooooooo
ooooooo
o
oo
oooo
o
oooooo
o
oooo
o
oooo
ooo
ooo
o
ooo
ooo
o
o
o
oo
o
oooooooo
o
oo
oo
oooo
o
oo
ooooo
oo
o
o
oo
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
ooooo
oooo
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
o
oo
oo
o
oo
o
o
o
o
oo
oo
oo
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
ooo
o
ooo
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
o
oo
o
o
o
o
o
oooo
o
o
o
o
oooo
o
o
o
ooooo
o
o
o
o
o
o
oooo
o
oo
o
o
oo
o
o
o
o
o
o
o
ooo
o
ooo
o
o
o
o
o
o
o
o
o
ooo
o
o
o
ooo
o
o
oo
o
o
o
o
oo
oooooooooooooooooo
o
ooooooooooooooooooooooooooooooooooooooooooooo
oooooooooooooooooooooooooooooooo
o
ooo
oooooooooooooooooooooooooooooo
o
o
o
o
o
o
o
ooo
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
oo
o
o
o
ooo
oo
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
ooo
o
oo
oo
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
oo
oo
ooo
o
oo
o
oooo
o
o
o
o
o
oo
ooo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
ooooo
oooo
oo
o
ooo
o
oo
o
oooo
oooo
ooooo
ooooo
o
ooooooo
o
oooo
o
o
o
o
oooo
oo
o
o
o
o
o
oooo
o
o
oo
o
oooo
o
o
oooo
ooooo
ooooooooo
o
oooooooo
o
o
o
o
o
o
ooo
oooo
o
ooooo
oo
ooo
oo
o
oo
o
o
o
oooo
ooo
oo
ooo
o
o
oooooo
o
ooo
oo
oo
o
o
o
o
o
o
oo
o
o
o
o
oo
ooo
o
o
o
oo
o
o
ooo
o
oo
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
oooo
oooo
ooo
o
oo
o
ooo
o
oo
o
o
o
o
oo
o
oo
o
oo
o
o
o
ooo
o
o
oo
o
o
o
oo
o
o
o
o
o
oo
oooo
oo
o
o
oooo
o
ooo
o
o
o
ooooooo
o
oooooooo
o
oooo
o
oooo
o
oo
oo
oo
o
oo
ooo
o
o
oo
o
o
o
o
o
o
ooooooooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
oo
o
oo
o
o
o
oooo
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
oo
oo
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
oooo
o
o
oo
o
ooooooo
ooo
o
o
o
o
o
o
o
o
ooo
oo
o
o
ooo
o
o
o
o
o
oo
oo
o
ooo
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
ooooooooooooooooooooooooooooooooooooooooooooooooooo
ooooooooooooooooooo
ooooooooooooooooooooooooo
o
o
oooooo
ooooo
oo
ooooooo
oooo
oo
ooooo
o
oo
o
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o
o
o
o
o
o
oooo
oo
o
o
o
ooo
oo
o
o
oo
o
oo
o
oo
o
o
o
oo
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
oo
o
oo
o
oo
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
oooooooo
o
oo
o
o
o
o
ooo
o
o
oooooo
o
o
oo
oo
o
o
oo
o
ooo
oooo
oooo
ooooooo
oooo
ooooo
ooooooo
oo
o
oo
o
oo
oo
o
oo
o
oooooo
oo
o
o
o
oo
o
o
ooo
oo
o
o
ooo
o
o
o
oo
oo
o
o
o
o
o
o
o
oo
o
o
oo
o
o
o
o
ooo
o
o
o
oo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
oo
oooo
o
oo
ooo
o
o
o
o
o
o
oo
o
oo
ooooo
ooooo
o
o
oo
o
o
ooooo
o
o
o
o
ooooooo
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oo
oooooo
o
oo
o
o
o
o
o
oo
o
o
o
o
o
oo
oo
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
oo
o
o
o
o
o
o
oooo
ooo
oo
oo
ooo
o
ooooooooooooo
o
o
o
oo
o
o
o
o
o
oo
oooo
o
oooo
o
o
o
o
oooo
oooo
oo
o
o
o
o
o
o
o
o
o
o
oo
o
oo
oo
o
o
o
o
o
ooo
o
o
o
o
o
o
o
ooooo
o
oo
oooooo
o
o
oo
oo
o
oo
o
o
ooo
oo
o
o
o
o
o
oo
o
oo
oooo
o
o
o
o
oo
o
o
ooo
o
oo
o
o
oooo
oo
o
ooo
o
o
o
oo
o
o
oo
ooooo
o
o
o
ooo
o
o
o
oo
o
oooo
o
oooo
o
o
o
o
o
o
o
oo
oo
oo
oooooo
oo
ooo
o
oo
o
o
ooo
ooooo
o
o
oooo
ooooooo
ooo
o
ooooooo
ooo
o
ooooo
o
o
o
oooo
ooo
o
ooo
ooo
o
o
oooo
oo
o
ooo
oooo
oo
oooooo
o
o
o
o
oo
ooo
oooooo
ooooooooooooooooooo
o
o
o
oo
oooo
oooo
ooooooo
o
oooo
oo
oooooooo
o
o
oo
oo
o
o
o
oooooooooo
o
ooo
o
oo
oo
oooooooo
oo
o
o
oo
oooo
ooo
ooo
oo
o
oooooooooooooo
oo
o
o
0.1 0.2 0.3 0.4 0.5 0.6 0.7
0.0
0.2
0.4
0.6
0.8
(Centralization+Density)*(1+Heterogeneity^2)
TO
M w
ith th
e H
ub N
ode
R^2=0.76
C D E F
Yeast gene co-expression module networks: the relationship between fundamental network conceptsFigure 7Yeast gene co-expression module networks: the rela-tionship between fundamental network concepts. This figure demonstrates Observation 3 and equation (14). The figures on the left (right) hand side depict network con-cepts from the weighted (unweighted) network. Each point is a gene colored by its module assignment. The red line has intercept 0 and slope 1. Figures A) and B) illustrate the rela-tionship between the mean clustering coefficient (short hori-zonal line) and (1 + Heterogeneity2)2 * Density (equation (11)). Figure C) and D) illustrates the relationship between the top-ological overlap with the hub node and (Density + Centraliza-tion) * (1 + Heterogeneity2) (equation (14)).
A B
−−−−
−
−
−−−
0.00 0.05 0.10 0.15 0.20 0.25 0.30
0.00
0.10
0.20
0.30
(1+Heterogeneity^2)^2*Density
Clu
ster
ing
Coe
ffici
ent
o
o
o
o
o
ooooooo
oo
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
oo
o
o
o
oo
o
oo
o
o
o
o
o
ooo
o
o
o
o
oo
ooo
o
oo
o
oooo
o
oo
ooooo
o
oo
ooooo
oo
o
o
o
o
oo
o
o
oooooooooo
o
oooooooooo
o
o
o
o
o
oo
oo
o
o
oo
oo
o
o
oooo
o
oo
o
o
ooooo
oo
o
oo
o
o
oo
oo
oo
oooo
o
o
ooooo
o
o
oo
o
o
oo
oo
oo
o
ooo
o
o
o
ooo
oo
ooooo
o
o
o
ooo
o
oooo
o
oooo
ooo
o
o
o
oooo
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
ooo
o
o
ooo
o
o
o
oooo
ooo
o
o
ooo
oooooooo
oooooooo
o
oo
oo
o
oooooooo
o
oooooo
oo
o
ooooo
o
o
o
o
oo
ooooo
o
oooooooo
o
o
oooo
o
oooo
oo
o
oo
o
o
o
o
oo
o
ooooo
oooooooo
o
o
ooo
o
o
ooooooo
ooooooo
o
oooo
oo
oo
oo
o
oo
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
ooooo
o
oooo
o
o
o
o
o
ooooo
ooo
o
o
oo
ooo
o
o
o
o
ooo
o
ooo
o
o
oo
oo
ooooo
o
o
oooo
ooo
o
oo
o
oo
o
oooo
o
o
o
oooo
oo
oooooo
oo
ooooo
o
oooooooooooo
o
oooooo
o
oooooo
o
o
o
oooooo
o
ooo
o
oooooo
o
o
oooo
o
oo
o
oooooo
oooooooooooooo
oooooo
o
oooooooooooo
oooo
o
oooooo
oooooo
o
o
o
ooooo
o
ooo
oooooo
o
ooo
ooooo
ooo
o
o
o
ooooooo
o
ooo
o
oooooooooo
o
o
oooo
ooooooo
o
oooo
o
ooooo
ooooooooooo
oooooooooooooo
o
ooo
o
oooooooo
ooooo
o
o
oo
ooooo
ooo
oo
o
ooooo
o
ooooo
o
oooooo
o
o
o
ooooooooooo
ooo
o
o
oooo
ooooooooo
o
oooooooo
oooo
oo
oooooooooooooo
oooooooooo
o
ooooooo
o
oooooooooo
o
o
o
oooo
ooooo
ooo
o
oooo
o
oo
o
oooooooooooooooooooo
ooooo
oo
o
oooooooooo
o
o
o
o
o
o
oo
o
o
o
oooooooooooooooooooooo
o
o
ooo
o
ooo
o
ooo
ooooo
o
o
o
ooooooo
ooooooo
oo
o
oo
o
o
oo
o
ooo
o
oooo
o
o
o
o
ooo
o
ooooo
o
oo
o
ooo
o
ooooooooooooo
o
ooooooooo
o
o
oooooooo
o
ooooooooo
o
oooo
ooooooooooooooooooo
o
oo
oooooo
o
oo
o
oooo
ooooooo
oooooooooooooo
o
ooooooo
ooooooooooooooo
o
o
oooo
o
o
oooooooooooooooo
oo
o
o
oooo
o
oooooooooooooo
o
oo
o
oooooo
o
o
ooo
o
oo
o
ooooooooooooooooo
o
ooooooo
oooo
o
ooooo
oo
ooooooooo
ooo
o
oooooooooooooo
o
oo
ooooooooooo
oooooooooo
oooo
o
ooooooooo
o
o
o
o
oo
o
o
ooooooooooooooooooooooo
o
oooooo
o
o
oooo
ooo
o
oo
oooooooooo
o
o
ooo
oo
ooo
oo
o
o
ooo
oooooooooo
o
ooooooo
o
o
ooooo
o
o
o
oo
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
o
oooooooo
o
o
o
oo
o
o
oo
o
o
o
ooo
o
o
oo
ooo
oo
o
oo
o
oooo
o
ooooooo
oo
ooo
o
o
o
oo
o
o
oooo
o
o
oooo
o
o
oo
oo
o
ooo
o
o
o
oo
o
ooo
o
ooooo
o
oo
ooooooo
o
o
oo
o
oooooooooooo
o
oooooooooooo
o
oooooo
o
ooo
ooooooooooo
oooooo
oo
oooooooooo
oo
ooo
oooo
o
o
ooo
oo
ooo
o
o
o
o
o
oooo
ooooooo
o
oooo
oooooooo
o
oooo
ooo
o
o
oooooooo
o
ooooooo
o
oooooooo
o
o
o
oooooooo
oooo
ooo
oooooo
ooooooo
o
oooooooo
o
oooo
o
ooooo
ooooooooo
oo
o
o
o
oooo
oo
ooooo
ooooo
ooooo
ooooo
o
ooo
oo
ooooo
o
o
oooooooooo
o
oo
o
ooo
oooo
o
oooooooo
o
ooo
o
oo
oooooooooo
ooooo
oooooo
o
oo
o
oo
ooo
o
o
o
o
o
oooooo
o
ooo
ooo
o
ooooooooooooooooooooooo
o
oo
ooo
o
oooooooooo
oooooooo
oo
o
ooooo
p=7, R^2=0.82
−− −
−
−
−
−−−
0.2 0.4 0.6 0.8
0.0
0.2
0.4
0.6
0.8
1.0
(1+Heterogeneity^2)^2*Density
Clu
ster
ing
Coe
ffici
ent o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
oo
o
oo
o
o
o
o
o
ooo
oo
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
ooo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
oo
o
o
ooo
o
o
ooo
o
ooo
ooo
oo
oo
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
ooo
ooo
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
oo
o
o
o
oo
o
oo
ooo
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
o
oo
oo
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
oo
o
oo
oo
o
o
o
o
o
o
o
o
o
oo
o
o
oooo
o
o
o
o
o
o
o
ooo
o
oo
o
o
o
o
ooo
oo
ooo
o
o
o
o
o
o
o
o
o
o
ooo
o
oo
o
o
oo
o
o
o
o
o
o
oo
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
ooo
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oooo
oo
o
o
oo
o
o
o
o
o
ooo
ooo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
oo
oo
oo
o
o
o
o
o
o
o
oo
o
o
o
oo
o
o
oo
o
o
o
o
o
o
oooo
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
ooooo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
oo
o
oo
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
oo
o
o
oo
o
o
o
o
oo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
ooo
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
oo
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oo
oo
o
oooo
oo
o
o
o
oo
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
oo
o
o
o
oo
o
o
oooo
o
oo
o
o
o
oo
o
o
o
oo
o
o
oo
o
o
ooo
o
o
o
ooo
o
oo
oo
o
oo
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
ooo
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
ooo
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
oo
o
oo
oo
o
o
o
oo
o
o
o
o
o
o
o
oo
o
o
o
o
oo
ooo
oo
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
o
o
oo
o
o
oo
o
o
o
oo
o
oo
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
oo
o
o
oo
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
oo
o
oo
oooo
o
oo
o
oo
oooo
o
o
ooooooo
oo
ooo
o
o
o
o
o
oo
o
oo
oo
oooo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
oo
oo
oo
o
o
o
o
o
oo
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
ooooo
o
o
oo
oo
oo
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
ooooo
o
o
o
o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
ooo
o
oo
o
oo
o
oo
o
oo
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
oo
oo
o
o
oo
ooo
o
o
o
o
o
oo
o
o
o
oo
o
oo
o
o
oo
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
ooo
o
o
o
oo
oo
ooo
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
oo
ooo
o
oo
ooo
o
o
o
o
o
o
o
oo
o
o
o
o
o
oo
oo
o
oo
o
ooo
o
o
o
o
o
o
o
o
o
ooooo
o
ooo
oo
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
oo
oo
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
tau=0.65, R^2=0.6
C D
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
ooooo
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
oo
o
o
o
o
o
o
ooo
o
oo
o
oo
oo
o
oo
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
o
oo
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
oooo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oo
oo
o
o
o
o
o
o
o
o
o
oooo
oo
o
oo
o
oo
o
ooo
oo
oo
o
o
o
oo
o
o
o
o
o
o
ooo
o
o
o
ooo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
ooo
o
oo
oo
o
o
ooo
o
o
ooo
oo
o
oo
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
oo
o
o
oooo
o
ooo
o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
oooo
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
ooo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o
o
oo
oo
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
oo
o
oo
o
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
oo
o
oo
o
oo
o
o
o
o
o
o
o
o
o
oo
oo
o
o
o
oo
o
oo
o
o
o
oo
oo
o
o
o
o
o
o
o
oo
o
ooo
o
o
o
o
o
oo
o
o
o
o
ooooo
o
oooooo
o
oo
o
o
o
o
o
o
oo
ooo
o
oo
ooo
oooo
o
o
o
o
ooooooo
oo
oo
o
o
o
o
oo
o
o
o
o
oo
o
o
o
oooo
o
oo
oo
o
o
o
ooo
o
o
o
o
o
ooo
o
o
o
ooo
oo
o
o
o
o
o
oooo
o
o
o
oooo
oo
o
oo
o
ooo
o
o
oo
o
ooo
o
o
o
o
o
o
oo
oo
o
ooo
o
o
o
o
o
ooo
o
o
o
o
o
ooo
o
o
ooo
oo
o
o
o
oooo
o
oooooo
ooo
o
ooo
o
oo
o
o
o
o
oo
oooo
oooo
o
o
o
ooo
oo
o
o
o
o
o
oo
o
o
o
o
oo
oo
o
ooo
o
o
oooo
o
o
o
o
o
o
o
o
oooooo
oo
ooo
o
ooo
o
oo
o
ooo
o
o
o
o
o
o
o
o
o
o
o
oo
oooo
oo
o
ooooo
o
oo
o
o
o
o
oo
oo
o
o
o
oo
oooo
oo
o
oo
oo
o
o
ooo
o
o
oo
ooo
ooo
oo
o
o
o
oo
o
o
oo
o
o
o
oooo
o
o
o
o
oooo
o
o
oo
o
oo
ooo
ooo
oo
o
o
o
o
o
o
o
oo
oo
oo
oo
o
oo
o
o
o
o
o
o
oo
o
ooo
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
oo
o
o
o
oo
o
oo
o
o
o
o
o
ooo
o
o
o
o
o
o
oo
o
o
oo
o
o
oooo
oooo
o
o
o
o
oo
o
o
o
o
oo
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o
oo
o
ooo
oo
o
o
oooo
oo
o
oo
o
oo
o
o
o
oo
ooo
o
o
o
o
o
oo
o
o
o
o
o
o
ooo
o
ooo
o
o
o
o
oooo
o
ooo
oo
oo
o
ooo
o
oo
o
oo
ooooo
ooo
oo
o
o
o
oo
o
o
o
ooooo
ooo
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
oo
o
o
oo
ooo
ooo
o
oo
o
o
o
o
oooo
o
o
ooo
o
o
o
o
o
ooo
o
o
ooo
o
o
o
o
o
o
o
o
o
oo
oooo
o
o
oo
oooo
oo
o
o
oooo
o
o
oo
ooo
o
o
o
o
oo
o
o
o
oo
o
ooooo
o
o
o
oo
oo
o
o
ooo
o
ooo
o
o
o
oo
o
o
ooo
ooo
oo
o
oo
o
o
oo
o
ooo
o
oooooo
oo
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
oo
o
oo
o
o
o
ooo
o
o
o
o
o
o
oo
o
o
ooooo
o
o
o
o
o
o
o
o
o
o
ooo
o
oo
o
o
o
o
oo
oo
o
oo
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
oo
o
o
oo
o
oo
oooo
oo
o
o
ooo
o
oooo
oo
o
o
o
o
oooo
o
oooooo
ooo
o
oo
oo
oo
o
o
ooooo
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
oo
o
o
o
ooo
o
o
o
o
oo
o
o
o
o
o
oo
o
o
oo
o
ooooo
o
oo
o
oo
o
ooo
o
o
oo
o
o
o
o
o
o
o
o
o
ooo
oo
o
o
oo
oo
oo
o
ooo
o
o
o
o
o
o
o
o
oo
o
o
o
oo
o
oo
ooo
o
ooo
o
o
o
o
oo
o
oo
o
o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
ooooo
o
o
o
o
ooo
oo
o
o
oo
o
oooo
o
o
oo
oo
o
o
o
oo
oo
oo
o
o
o
o
o
o
o
ooo
oo
o
o
o
o
o
o
o
oo
o
oo
o
oo
o
o
oo
o
o
o
o
o
oo
oo
oo
o
o
o
o
o
oo
oo
oo
ooo
oo
ooo
o
o
o
oo
o
o
o
o
o
oo
oo
oo
o
o
o
o
o
o
o
oooo
o
oo
oo
oo
o
o
o
ooo
o
oo
o
o
o
o
oo
o
oo
oo
o
o
o
o
o
ooo
ooo
o
o
o
oo
oo
o
oo
ooo
oo
oo
o
oo
o
o
o
o
o
o
ooo
o
o
o
o
ooo
o
o
o
o
o
o
o
o
oooo
o
o
oo
o
o
o
ooo
o
o
oo
o
oo
ooooo
o
o
oo
oo
ooooo
o
o
o
o
o
ooo
oo
oo
o
oo
o
o
ooo
o
oo
o
oo
o
o
o
o
o
oo
oo
o
o
o
o
o
ooo
o
o
oo
o
o
o
o
oooo
ooo
o
o
o
o
o
o
o
o
oo
oo
ooo
o
oooo
o
oooo
o
o
oo
o
o
o
o
o
oo
o
o
o
oo
o
o
o
ooo
o
o
o
o
o
oo
oo
o
o
ooo
o
o
o
o
o
oo
oo
o
o
o
oo
oo
o
oo
o
oo
ooo
0.1 0.2 0.3 0.4
0.0
0.1
0.2
0.3
0.4
(Centralization+Density)*(1+Heterogeneity^2)
TO
M w
ith th
e H
ub N
ode
p=7, R^2=0.81
oo
o
o
o
o
o
o
oo
o
o
o
o
o
ooo
o
oooo
oo
oo
o
o
oo
oo
o
o
o
o
o
o
o
oo
ooo
oo
o
oo
ooo
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
o
o
o
ooo
o
ooo
o
oo
o
oooo
oo
o
oooo
o
o
o
o
o
oooo
o
o
o
oooo
o
o
o
oooooooo
oo
o
o
oo
o
o
o
o
o
o
o
o
oo
o
oo
o
oo
o
ooo
o
o
o
o
o
oo
oo
o
o
o
oo
ooo
ooo
o
o
o
oo
oo
oo
o
o
o
oo
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
oooo
o
oooooo
oo
oo
o
o
o
ooooooo
ooo
oo
oo
o
o
o
o
o
ooo
o
o
o
o
oo
oo
ooo
o
o
oo
o
o
o
o
o
o
o
oo
o
o
o
oo
oo
ooooo
ooo
oo
o
o
o
o
o
o
ooo
oo
o
ooo
o
o
o
o
o
oo
ooo
o
ooo
oo
oo
o
ooo
o
o
o
o
o
oo
oo
o
oooo
o
oo
o
oo
oo
o
o
o
oo
oo
o
oo
o
o
o
o
o
o
o
oo
o
oo
o
ooo
o
o
oo
o
o
o
oo
ooooo
o
o
o
oo
o
o
ooo
o
ooo
o
oo
o
o
oooo
o
o
ooo
o
o
oo
o
oooo
oo
o
oo
o
o
o
oo
o
o
o
o
ooo
oo
o
ooo
ooo
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
oo
o
oooo
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
o
o
o
ooooo
o
o
o
o
ooo
o
oo
o
o
oo
o
o
o
oo
o
o
o
o
o
ooo
o
oo
o
oo
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
oo
oooo
o
o
o
o
ooooooo
o
oo
o
o
o
o
o
oo
o
o
o
o
oo
o
o
o
oooo
o
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
ooo
o
o
o
o
o
oo
o
o
o
o
oo
o
oo
oo
o
oo
o
o
o
o
o
o
ooo
o
o
o
o
o
ooo
o
oooo
oo
o
o
o
ooo
o
o
oooooo
o
oo
o
ooo
o
oo
o
o
oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
ooo
o
oooo
o
o
o
ooo
o
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
ooo
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o
o
o
o
o
o
o
oooo
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
oo
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o
oo
o
oo
o
o
o
o
o
oo
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
oo
o
ooo
o
o
o
o
o
o
oo
o
o
o
oo
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
ooo
o
oo
o
o
o
o
o
oooo
o
ooo
oo
oo
o
o
o
o
o
oo
o
o
o
ooooo
o
o
o
oo
o
o
o
oo
o
o
o
ooooo
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
oo
o
o
o
ooo
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o
oo
o
o
o
ooo
o
oo
o
o
o
o
o
o
o
o
o
oo
o
oooooo
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
ooooo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
ooo
o
o
o
oo
o
oo
o
o
o
o
oo
o
o
ooooo
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o
oo
o
o
o
o
o
oo
o
o
o
o
oooo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
oooo
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
ooo
o
o
ooo
o
o
o
o
o
o
o
o
oo
oooooooooooooooooo
o
oooooo
o
oooo
o
o
ooo
o
oo
o
ooooo
o
oooooooo
oo
oooooooo
o
o
ooo
ooo
o
o
o
oo
o
o
ooooooo
o
oo
o
o
o
oo
ooooooooooo
o
o
oo
o
o
o
o
o
o
o
o
o
oo
ooo
o
o
o
o
oo
o
o
oo
o
oo
ooo
o
oo
ooo
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
o
o
o
ooo
oo
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
oo
o
o
oo
ooo
o
oo
oo
o
oo
o
o
o
o
o
oo
o
o
o
o
o
o
oooo
o
o
o
o
o
oo
ooo
oo
o
oo
o
o
oooo
o
o
o
o
o
o
o
ooooo
oo
o
o
o
o
o
o
o
oo
oo
o
oo
o
ooooo
o
oo
o
o
o
oo
o
o
o
ooooooo
o
oo
ooooooo
oo
oo
o
o
ooooooo
o
oo
ooo
o
o
o
o
o
o
o
o
o
o
oo
oooooo
o
o
o
oo
o
o
o
o
o
o
ooooo
o
ooo
o
o
oo
oo
o
o
o
o
oooo
oo
o
oo
oo
ooo
o
o
oo
o
o
oo
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
o
o
oo
o
oo
oo
o
o
oo
oo
o
oo
ooo
oo
ooooo
ooo
o
oo
oooo
o
oooo
oo
o
oooo
oo
o
o
o
o
ooo
o
o
oo
oo
o
o
oo
o
o
oo
ooo
o
o
o
o
o
o
o
o
oo
o
o
o
ooo
o
o
o
ooo
oo
o
o
o
o
o
o
o
oooo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
oo
o
oooo
oo
o
o
o
o
o
o
ooo
0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
(Centralization+Density)*(1+Heterogeneity^2)
TO
M w
ith th
e H
ub N
ode
tau=0.65, R^2=0.74
Page 9 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
network and soft thresholding results in a weighted net-work [21]. We applied our methods to a yeast cell cyclemicroarray data comprised of 44 microarrays and 2001genes. This dataset recorded gene expression levels duringdifferent stages of cell cycles in yeasts and has been widelyused before to illustrate clustering methods [35].
Of the 2001 genes (microarray probesets) in the weightedyeast gene co-expression network, 1081 were clusteredinto 8 proper modules. The module sizes of the propermodules range from 53 to 308, mean 135.1, median101.5, and interquartile range 69.3. To facilitate a com-parison between the weighted and the unweighted geneco-expression networks, we used the module assignmentof the weighted network for the unweighted network aswell. It turns out that the module assignment is highlypreserved between the weighted and the unweighted geneco-expression networks, see Figures 1C) and 1D).
Functional annotation of modulesSince the scope of this paper is a mathematical and topo-logical analysis of module networks, we defined moduleswithout regard to external gene ontology information.Also we do not provide an in-depth analysis of the biolog-ical meaning of the network modules. But we briefly men-tion that there is indirect evidence that most of theresulting modules are biologically meaningful. We usedthe functional gene annotation tools from the Databasefor Annotation, Visualization and Integrated Discovery(DAVID) [36] to test for both enriched biochemical path-ways and subcellular compartmentalization. We find thatmost modules are significantly enriched with known geneontologies. A functional enrichment analysis for each net-work application is provided. For the Drosophila PPI net-work, [see Additional file 3]; for the yeast PPI network,[see Additional file 4]; for the weighted and unweightedyeast gene co-expression networks, [see Additional file 5].
Empirical relationships in 4 different networksIn accordance with Observation 2, we find a close rela-tionship (R2 ≥ 0.6) between the fundamental networkconcepts and their approximate CF-based analogs. Specif-ically, we relate the network density, centralization, heter-ogeneity and clustering coefficients to their approximateCF-based analogs in Figures 2 (Drosophila PPI network),Figure 3 (yeast PPI network), and Figure 4 (weighted andunweighted yeast gene co-expression networks).
In accordance with Observation 3, we find a close rela-tionship (R2 ≥ 0.6) between the mean clustering coeffi-cient mean (ClusterCoef ) and (1 + Heterogeneity2)2 ×Density. Further, we find a close relationship between Top-Overlap[1]j and (Centralization + Density)(1 +Heterogeneity2), see Figures 5 (Drosophila PPI network),Figure 6 (yeast PPI network), and Figure 7 (weighted andunweighted yeast gene co-expression networks).
We find that our theoretical observations fit better in theweighted- than in the unweighted yeast gene co-expres-sion network.
Network concepts and module sizeSince the number of genes inside a module (module size)varies greatly among the modules, it is natural to wonderwhether the reported relationships between network con-cepts are due to the underlying module sizes. We find thatthe relationship between fundamental network conceptsand their approximate CF-based analogs remains highlysignificant even after correcting for module sizes [seeAdditional file 2]. The same holds for the relationshipsbetween network concepts. Thus, none of the reportedrelationships is trivially due to module sizes. But we findthat many network concepts depend on the underlyingmodule size. We find that large modules are less factoriz-able than small modules: there is a strong negative corre-lation between module factorizability F(A) and modulesize. We also find that fundamental network concepts(e.g. density) depend on module size in our applications.For the factorizability, density, centralization, heterogene-ity and mean clustering coefficient, the correlation coeffi-cients with module size are -0.84, -0.46, -0.17, 0.26, and -0.36 in Drosophila PPI module networks; they are -0.55,-0.52, 0.05, 0.5, and -0.44 in yeast PPI module networks;they are -0.93, -0.52, -0.82, 0.27, and -0.55 in weightedyeast gene co-expression module networks; they are -0.86,-0.77, -0.56, 0.87, and -0.85 in unweighted yeast gene co-expression module networks. A more detailed analysis ispresented in the Additional files [see Additional file 2].
A simple exactly factorizable network example: constant network
A simple, exactly factorizable network is given by an adja-
cency matrix A with constant adjacencies (aij = b, b ∈ (0,
1]). The adjacency matrix is exactly factorizable since aij =
CFiCFj where CFi = . This network can be interpreted as
the expected adjacency matrix of an Erdös-Rényi network[37]. One can easily derive the following expressions forthe fundamental network concepts: Connectivityi = (n - 1)b,
Density = b, Centralization = 0, Heterogeneity = 0, Cluster-Coefi = b and TopOverlapij = b.
Since A is exactly factorizable, the fundamental networkconcepts equal their CF-based analogs. However, theapproximate CF-based concepts are different from theirexact counterparts, see Table 3. For reasonably large valuesof n, the fundamental network concepts are very close totheir approximate CF-based analogs. This illustratesObservation 2. With the results in Table 3, one can easilyverify Observation 3 and equation (16) in this example.
b
Page 10 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
Example: block diagonal adjacency matrixIn the following, we will consider a block diagonal adja-cency matrix where each block has constant adjacencies,i.e.
We assume that the first and second blocks have dimen-sions n1 × n1 and n2 × n2, respectively. Such a block diago-nal matrix can be interpreted as a network with twodistinct modules. Setting n2 = 0 results in the simple con-stant adjacency matrix, which we considered before.
We denote by f1 = (1, 1,..., 1, 0, 0, ..., 0) the vector whosefirst n1 components equal 1 and the remaining compo-nents equal 0. Similarly, we define f2 = (0, 0, ...,0, 1, 1, ...,1) = 1 - f1. To simplify the calculation of the conformity,we further assume that
Then the conformity is uniquely defined by
as one can show using equations (36) and (37) in theappendix. Further, using Proposition 10 in the appendix,one can show that the factorizability is given by
A
b b
b b
b b
b b
b
=
1 0 0 0
1 0 0 0
1 0 0 0
0 0 0 1
0 0 0 1
1 1
1 1
1 1
2 2
2 bb
b b
2
2 20 0 0 1
⎛
⎝
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
. (17)
n n b
n n b2 2 2
2
1 1 12
1
11
( )
( ).
−−
< (18)
CF f= b1 1,
F An n b
n n b n n b( )
( )
( ) ( ).= −
− + −1 1 1
2
1 1 12
2 2 22
1
1 1(19)
Table 4: Network concepts in the simulated block-diagonal network.
Concept Fundamental CF-based Approx CF-based
Connectivityi
Density
Centralization
Heterogeneity
TopOverlapij
ClusterCoefi
The indicator function Ind(·) takes on the value 1 if the condition is satisfied and 0 otherwise.
( ) ( )n b Ind n b Indi n i n1 1 2 21 11 1
− + −≤ > ( )n b Indi n1 111
− ≤ n b Indi n1 1 1≤
n n b n n b
n n n n1 1 1 2 2 2
1 2 1 2
1 1
1
( ) ( )
( )( )
− + −+ + −
n n b
n n n n1 1 1
1 2 1 2
1
1
( )
( )( )
−+ + −
n b
n n n n12
1
1 2 1 2 1( )( )+ + −
n n b n b
n n n n2 1 1 2 2
1 2 1 2
1 1
1 2
(( ) ( ) )
( )( )
− + −+ − + −
( )
( )( )
n n b
n n n n1 2 1
1 2 1 2
1
1 2
−+ − + −
n n b
n n n n1 2 1
1 2 1 21 2( )( )+ − + −
( )[ ( ) ( )
[ ( ) ( ) ]
n n n n b n n b
n n b n n b1 2 1 1
212
2 22
22
1 1 1 2 2 22
1 1
1 1
+ − + −− + −
n
n2
1
n
n2
1
b Ind b Indi j n i j n1 21 1, ,≤ >+ b Indi j n1 1, ≤ bn b
n bIndi j n1
1 1
1 1
1
1 1 1
+− + ≤( ) ,
b Ind b Indi n i n1 21 1≤ >+ b Indi n1 1≤ b Indi n1 1≤
Table 3: Network concepts in the constant Erdös-Rényi network.
Network Concepts Fundamental Approximate CF-based
Connectivityi (n - 1)b nb
Density b
Centralization 0 0Heterogeneity 0 0
TopOverlapij b
ClusterCoefi b b
bn
n −1
bnb
n b
+− +
11 1( )
Page 11 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
In particular, if n1 ≈ n2 and b1 = b2, i.e. if the adjacencymatrix is comprised of two nearly identical blocks, the fac-torizability is F(A) ≈ 1/2. Similarly, one can show that ifthe matrix A is comprised of B identical blocks, then F(A)≈ 1/B.
This block diagonal network allows one to arrive atexplicit formulas for fundamental-, CF-based-, andapproximate CF-based network concepts, see Table 4.
In the following, we study the relationship between fun-damental network concepts and their approximate CF-based analogs in the limit when the block diagonal net-work becomes approximately factorizable. Specifically,we calculate network concepts in the limit b2 → 0 when n1,n2 and b1 are kept fixed. Under this assumption, b2→ 0 isequivalent to F(A) → 1. Then, one can easily show that
For reasonably large values of n1 (say n1 > 20), these limitsillustrate Observation 2. Similarly, one can easily verifyObservation 3 and equation (16) in the case when the fac-torizability F(A) is close to 1 and n1 is reasonably large.
DiscussionThis paper does not describe a new software or method forconstructing networks. Instead, it presents theoreticalresults which clarify the mathematical relationshipbetween network concepts in module networks. A deeperunderstanding of network concepts may guide the dataanalyst on how to construct and use networks in practice.Our results will pertain to any network that is approxi-mately factorizable irrespective of its constructionmethod. While the term 'factorizable' network is new,numerous examples of these types of networks can befound in the literature, e.g. [38]. A recent physical modelfor experimentally determined protein-protein interac-tions is exactly factorizable [39]. In that model, the 'affin-ity' aij between proteins i and j is the product of thecorresponding conformities. The conformities are approx-imately given by CFi = exp(-Ki) where Ki is the number of
hydrophobic residues in the i-th protein. Another relatedexample is an exactly factorizable random network modelfor which the edges between pairs of nodes are drawnaccording to a linking probability function [40,41].
We find that in many applications, the conformity ishighly related to the first eigenvector of the adjacencymatrix. The idea of using a variant of the singular valuedecomposition for decomposing an adjacency matrix hasbeen proposed by several authors [42-45]. However, weprefer to define the conformity as a maximizer of the fac-
torizability function for
the following reasons: First, the factorizability satisfiesthat FA(CF) = 1 if, and only if, A is exactly factorizable net-
work with aij = CFiCFj. Second, we prefer to define the con-
formity without reference to the diagonal elements aii of
the adjacency matrix. Third, the definition naturally fitswithin the framework of least squares factor analysiswhere conformity can be interpreted as the first factor[46]. An algorithm for computing the conformity in gen-eral networks is presented in the appendix. While networkanalysis focuses on the adjacency matrix, factor analysistakes as input a correlation or covariance matrix. In mod-ule networks, the first factor (conformity) corresponds toa normalized connectivity measure, see equation (16).Future research could explore the network interpretationof higher order factors.
The topological structure of complex networks has beenthe focus of numerous studies, e.g. [7,8,16-18,20,38,47].Here we explore the structure of special types of networks,which we refer to as module networks.
To derive results for factorizable module networks, wedefine several novel terms including a measure of networkfactorizability F(A), conformity, CF-based network con-cepts, approximate CF-based network concepts.
The first result (Observation 1) uses both PPI and gene co-expression network data to show empirically that subnet-works comprised of module nodes are often approxi-mately factorizable. This insight could be interesting toresearchers who develop module detection methods.Approximate factorizability is a very stringent structuralassumption that is not satisfied in general networks.While modules in gene co-expression networks tend to beapproximately factorizable if the corresponding expres-sion profiles are highly correlated, the situation is morecomplicated for modules in PPI networks: only afterreplacing the original adjacency matrix by a 'smoothed
lim ,
lim
( ), ,
( )
F Ai CF app i
F A
Connectivityn
nConnectivity
→
→
= −1
1
1
1
11
1
1
1
1
1
1
Densityn
nDensity
Centralizationn
CF app
F A
= −
= −→
,
( )
,
limnn
Centralization
Heterogeneity Heterogenei
CF app
F A
1
1
,
( )
,
lim→
= tty
TopOverlapn b
n bTopOverlap
CF app
F Aij
,
( )
,
lim( )
→= − +
+1
1 1
1 1
1 1
1 CCF app ij
F Ai CF app iClusterCoef ClusterCoef
, ,
( ), ,
,
lim .→
=1
Fa v v
aA
ij i jj ii
ijj ii
( )( )
( )v = −
−≠
≠
∑∑∑∑
1
2
2
Page 12 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
out' version (the topological overlap matrix), do we findthat the resulting modules are approximately factorizable.
The second result (Observation 2) shows that fundamen-tal network concepts are approximately equal to theirapproximate CF-based analogs in approximately factoriz-able networks (e.g. modules). While fundamental net-work concepts are defined with respect to the adjacencymatrix, approximate CF-based network concepts aredefined with respect to the conformity vector. The closerelationship between fundamental and approximate CF-based concepts in module networks can be used to pro-vide an intuitive interpretation of network concepts inmodules. We demonstrate that these high correlationsbetween module concepts remain significant even afteradjusting the analysis for differences in module size [seeAdditional file 2].
The third result (Observation 3) shows that the meanclustering coefficient is determined by the density and thenetwork heterogeneity in approximately factorizable net-works. Further, the topological overlap between twonodes is determined by the maximum of their respectiveconnectivities and the heterogeneity. Thus, seemingly dis-parate network concepts satisfy simple and intuitive rela-tionships in these special but biologically important typesof networks.
The fourth result (Observation 4) is that in approximatelyfactorizable networks, fundamental network concepts canbe expressed as simple functions of the connectivity.Under mild assumptions, we argue that the clusteringcoefficient and the topological overlap matrix can beapproximated by simple functions of the connectivity.
Our empirical data also highlight how network conceptsdiffer between subnetworks of 'proper' modules and thesubnetwork comprised of improper (grey) module nodes,see Table 1. For all applications, we find that proper mod-ules have high factorizability, high density, high meanconformity. Based on our theoretical derivations, it comesas no surprise that proper modules also have a high aver-age clustering coefficient and a high centralization whencompared to the improper module. But we find no differ-ence in heterogeneity between proper and improper mod-ule networks.
As a consequence of approximate factorizability, networkconcepts with disparate meanings in social network the-ory are closely related in module networks. Our resultsshed some light on the relationship between network con-cepts traditionally used by social scientists (e.g. centraliza-tion, heterogeneity) and concepts used by systemsbiologists (e.g. topological overlap). For example, equa-tion (13) shows that in module networks, the topological
overlap between a hub gene and other module genes isrelated to the centralization.
ConclusionUsing several protein-protein interaction and gene co-expression networks, we provide empirical evidence thatsubnetworks comprised of module nodes often satisfy animportant structural property, which we call 'approximatefactorizability'. In these types of networks, simple rela-tionships exist between seemingly disparate network con-cepts. Several network concepts with very differentmeanings in general networks turn out to be highly corre-lated across modules. These results are pertinent for sys-tems biology since a biological pathways may correspondto an approximately factorizable module network.
MethodsThe adjacency matrix and notationWe study the properties of an adjacency matrix (network)A that satisfies the following three conditions:
(A.1) A is symmetric and has dimension n × n.
(A.2) The entries of A are bounded within [0, 1], that is, 0≤ aij ≤ 1 for all 1 ≤ i,j ≤ n.
(A.3) The diagonal elements of A are all 1, that is, aii = 1for all 1 ≤ i ≤ n.
Matrix and vector notation
We will make use of the following notations. We denoteby ei the unit vector whose i-th entry equals 1 and by 1 the
'one' vector whose components all equal 1. The Frobenius
matrix norm is denoted by . The
transpose of a matrix or vector is denoted by the super-script τ . For any real number p, we use the notation Mp andvp to denote the element-wise power of a matrix M and avector v respectively. We define the function Sp(·) for a
vector v as Sp(v) = ∑i = (vp)τ 1. Further denote by I the
identity matrix and by diag(v2) a diagonal matrix with its
i-th diagonal component given by ,i = 1, ...,n. We
define the maximum function max(M) as the maximumentry of matrix M and max(v) as the maximum entry ofthe vector v. Similarly we define the minimum functionmin(·). Also, we define mean(v) = S1(v)/n and variance(v)
= S2(v)/n - (S1(v)/n)2.
M mF ijji= ∑∑ 2
vip
vi2
Page 13 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
Uniqueness of the conformity for an exactly factorizable networkOne can easily show that the vector CF is not unique if anexactly factorizable network contains only n = 2 nodes.However, for n > 2 the conformity is uniquely definedwhen dealing with a weighted network where aij > 0.
Specifically, we prove the following statement. If A is an n× n (n ≥ 3) dimensional adjacency matrix with positiveentries (aij > 0), then the system of equations in (7) has atmost one solution CF with positive entries. If the solutionexists, it is given by
where denotes the 'product connectivity' of
the i-th node.
Proof: by assumption, we have aij = CFiCFj for a positive
vector CF and n ≥ 3. Multiplying both sides of equation(7) yields
.
Since is positive, we find
. Similarly, eliminat-
ing the i-th row and column from A yields
. Since , we conclude that CFi is
uniquely defined by
Network concept functions and fundamental network conceptsIn general, we define a network concept function to be a ten-sor valued function (e.g. the connectivity vector) that
takes a square matrix (e.g. the network adjacency matrix)as input.
Denote by M = [mij] a general n × n matrix. Then we willstudy the following network concept functions:
where the components of matrix BM in the denominatorof the clustering coefficient function are given by bij = 1 ifi ≠ j and bii = Ind(mii > 0). Here the indicator functionInd(·) takes on the value 1 if the condition is satisfied and0 otherwise.
For the sake of brevity, we study only a limited selectionof network concept functions and do not claim that theseare more important than others studied in the literature.Our general formalism for relating fundamental networkconcepts to their approximate CF-based analogs shouldallow the reader to adapt our derivations to alternativeconcepts as well.
Now we are ready to define the fundamental network con-cepts that are studied in this article.
Definition 5 (Fundamental Network Concept) The fun-damental network concepts of a network A are defined by eval-uating the network functions (equation (21)) on A - I, i.e.
FundamentalNetworkConcept = NetworkConcept(A - I).
As special cases of this definition, we find the followingconcepts. The connectivity (also known as degree) of thei-th node is given by
CFp
pi
i
mmn n
n
=
( )⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟=
−
−
∏ 1
1 2 1
12
/( ( )), (20)
p ai ijjn= =∏ 1
a CFCF CFlml mm l ml mm lln n
≠ ≠ =
−∏∏ ∏∏ ∏= = ( )1
2 1( )
CFlln=∏ 1
CF alln
lml mmn
= ≠−∏ ∏∏= ( )1
12 1( )
CF a a all i lml m im in
lml mm lil i≠ ≠≠−
≠ ≠∏ ∏∏ ∏∏ ∏= ( ) = ( )⎛⎝⎜
⎞⎠⎟,
( )1
2 12
12(( )n−1
CF CF CFi lln
ll i= = ≠∏ ∏1
CFa
a
ai
lml mmn
lml m im in
lml mm=( )
( )=
( )≠−
≠≠−
≠∏∏
∏∏
∏∏1
2 1
12 1
12( )
,( )
(( )
( )
/
n
lml mmn
imm
n n
i
mmn
a
a
p
p
−
≠− =
−
=
∏∏∏
∏
( )⎛
⎝⎜⎜
⎞
⎠⎟⎟
=
( )
1
12 2 1
12
1
1 (( ( )).
2 1
12
n
n
−
−⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
Connectivity M m M
Density Mm
n n
Cent
i ij ij
ijji
( ) ,
( )( )
,
= =
=−
∑
∑∑
e 1τ
1
rralization Mn
n
M
nDensity M
Heterogenei
( )max( )
( ) ,=− −
−⎛⎝⎜
⎞⎠⎟2 1
1
tty Mn MM
M
TopOverlap MMM M
iji j i j
( )( )
( ),
( )min
= −
=+
1 1
1 1
e e e e
τ
τ
τ τ
21
{{ , },
( ) ,
e 1 e 1 e e
e e
e e
i j i j
ii i
i M i
M M M
ClusterCoef MMMM
MB M
τ τ τ
τ
τ
+ −
=
1
(21)
k Connectivity A I ai i ijj i
= − =≠∑( ) .
Page 14 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
The line density [13] equals the mean adjacency, i.e
For notational convenience, we sometimes omit the refer-ence to the adjacency matrix and simply write Density todenote the fundamental network concepts.
The normalized connectivity centralization (also knownas degree centralization) [14] is given by
Our definition of the network heterogeneity equals thecoefficient of variation of the connectivity distribution,i.e.
Note that Heterogeneity(b * M) = Heterogeneity(M) for ascalar b ≠ 0.
The clustering coefficient of node i is a density measureof local connections, or 'cliquishness' [19,20]. Specifi-cally,
The topological overlap between nodes i and j reflectstheir relative interconnectedness. It is defined by
where lij = ∑u≠i,jaiuauj.
Network concepts in exactly factorizable networksIn the following, we will present explicit formulas for thefundamental network concepts in Definition 5 when theadjacency matrix A is exactly factorizable, i.e. if aij =CFiCFj. We define the CF-based adjacency matrix as fol-lows
ACF := CF CFτ - diag(CF2) + I, (27)
where diag(CF2) denotes the diagonal matrix with diago-
nal elements , i = 1 ...n. Then one can easily show that
for exactly factorizable networks
Using our definition of network concept functions inequations (21), one can easily derive the following formu-las for NetworkConcept(ACF - I) in terms of the quantities
Sp(CF) = ∑i .
Approximate CF-based network concepts in general networksWhen ACF - I is used as input of a network concept func-tion, it gives rise to a CF-based network concept asdetailed in the following
Definition 6 (CF-based Network Concepts) Assume thatthe conformity vector CF can be defined for a general adjacencymatrix A. Then the CF-based network concepts are defined byevaluating the network concept functions on ACF - I = CF CFτ -diag(CF2), i.e.
NetworkConceptCF := NetworkConcept(ACF - I).
By definition, fundamental network concepts are equal totheir CF-based analogs if A is exactly factorizable.
In the following, we define approximate CF-based analogsof the fundamental network concepts. The theoreticaladvantage of these approximate CF-based concepts is thatthey satisfy simple relationships. Define the approximateCF-based adjacency matrix as follows
ACF,app = CF CFτ. (30)Note that only the diagonal elements differ betweenACF,app and ACF . We define the approximate CF-based net-
Density A Ia
n n
S
n n
mean
n
ijj ii( )
( )
( )
( )
( ).− =
−=
−=
−≠∑∑1 1 1
1 k k
(22)
Centralization A In
n nDensity
n
n n( )
max( )
( )(− =
− −−⎛
⎝⎜⎞⎠⎟
=− −2 1 2 1
k
))(max( ) ( )).k k− mean
(23)
Heterogeneity A Iiance
mean
nS
S( )
( )
( )
( )
( ).− = = −
var k
k
k
k2
12
1
(24)
ClusterCoef ClusterCoef A In a a a
ai i
i
i
il lm mim i ll i
il
= − = = ≠≠ ∑∑( ) ,
πll i ill i
a≠ ≠∑ ∑( ) −{ }2 2.
(25)
TopOverlap TopOverlap A Il a
k k aij ijij ij
i j ij= − =
++ −
( )min{ , }
,1
(26)
CFi2
A A
NetworkConcept A I NetworkConcept A ICF
CF
=− = −
,
( ) ( ).
(28)
CFip
Connectivity A I CF S CF
Density A IS
i CF i i
CF
( ) ( ) ,
( )( )
− = −
− =
12
12
CF
CF −−−
− =−
S
n n
Centralization A In
n
ConnectivityCF
2
1
2
( )
( ),
( )max( (
CF
AA I
nDensity A I
Heterogeneity A In S
CFCF
CF
−−
− −⎛⎝⎜
⎞⎠⎟
− =
))( ) ,
( )(
1
2(( ) ( ) ( ) ( ) ( ))
( ( ) ( )),
CF CF CF CF CF
CF CF
S S S S
S S
Clus
12
3 1 4
12
22
21
− +−
−
tterCoef A IS CF S CF
S CFi CF
i i
i
( )( ( ) ) ( ( ) )
( ( ) )− =
− − −−
22 2
44
12
CF CF
CF −− −
− =− −
( ( ) ).
( )( ( )
S CF
TopOverlap A ICF CF S CF CF
i
ij CFi j i
22 2
22
CF
CF jj i j
i i j j i j
CF CF
CF S CF CF S CF CF CF
2
1 1 1
)
min( ( ( ) ), ( ( ) ))
+− − + −CF CF
(29)
Page 15 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
work concepts by using ACF,app as input of the networkconcept functions as detailed in the following
Definition 7 (Approximate CF-based Network Con-cepts) The approximate CF-based network concepts of a net-work A with conformity CF are defined by evaluating thenetwork functions (equations (21)) on ACF,app = CF CFτ, i.e.
NetworkConceptCF,app := NetworkConcept(ACF,app).
In approximately factorizable networks, fundamental network concepts are approximately equal to their approximate CF-based analogs
Here we will provide a heuristic derivation of Observation2. Since the components of CF are positive, one can easily
show that S4(CF) ≤ S2(CF)2. For many large, exactly factor-
izable networks, the ratio S4(CF)/S2(CF)2 is close to 0.
Since S4(CF)/S2(CF)2 =
, this implies that ACF -
I ≈ ACF,app. Since the network concept functions are contin-
uous functions, this implies NetworkConcept(ACF - I) ≈ Net-
workConcept(ACF,app). These derivations are summarized in
the following
Observation 8 (Approximate Formulas for CF-basedConcepts) If S4(CF)/S2(CF)2 ≈ 0, then
NetworkConcept(ACF - I) ≈ NetworkConcept(ACF,app).(31)
In particular, for exactly factorizable networks (i.e. A - I =ACF - I), this means that the fundamental network con-cepts can be approximated by their approximate CF-basedanalogs.
In our real data applications, we show empirically thatequation (31) holds even in networks that satisfy theassumptions of Observation 8 only approximately.
In the appendix (equation (43)), we define a measure ofnetwork factorizability as follows
Thus, in approximately factorizable networks (i.e. F(A)close to 1), A - I can be approximated by ACF - I. For a con-tinuous network functions, this implies
NetworkConcept(A -I) ≈ NetworkConcept(ACF - I),
i.e. the fundamental network concepts are approximatelyequal to their CF-based analogs in approximately factoriz-able networks. Observation 8 states that
NetworkConcept(ACF -I) ≈ NetworkConcept(ACF,app).
Combining the last two equations leads to NetworkCon-cept(A - I) ≈ NetworkConcept(ACF,app). These derivations aresummarized as follows.
In approximately factorizable networks, the fundamentalnetwork concepts are approximately equal to theirapproximate CF-based analogs, i.e.
FundamentalNetworkConcept ≈ NetworkConceptCF,app.
Construction of gene co-expression networksGene co-expression networks are constructed from micro-array data that measures the transcriptional response ofcells to changing conditions. We consider the case of ngenes with gene expression profiles across m microarraysamples. Thus, the gene expression profiles are given byan n × m matrix
X = [xij] = (x1 x2 � xn)τ, i = 1, ..., n; j = 1, ..., m,(33)
where the i-th row is the transcriptional responses of
the i-th gene.
Recently, several groups have suggested thresholding thepairwise Pearson correlation coefficient cor(xi, xj) in orderto arrive at gene co-expression networks, which are some-times referred to as 'relevance' networks [11,32]. In thesenetworks, a node corresponds to the gene expression pro-file of a given gene. The corresponding adjacency matrix isdetermined from a measure of co-expression between thegenes. In the examples below, we will use the absolutevalue of the Pearson correlation coefficient between thegene expression profiles to measure co-expression.
To transform the co-expression measure into an adja-cency, one can make use of an adjacency function. Thechoice of the adjacency function determines whether theresulting network will be weighted (soft-thresholding) orunweighted (hard-thresholding). The adjacency functionis a monotonically increasing function that maps theinterval [0, 1] into [0, 1]. A widely used adjacency func-tion is the signum function which implements 'hard'thresholding involving the threshold parameter τ. Specif-ically,
aij = Signum(|cor(xi, xj)|, τ) = Ind(|cor(xi, xj)| ≥ τ),(34)
( ) , ,A I A ACF CF app F CF app F− −
2 2
F AA I A I
A I
CF F
F
( )( ) ( )
,= −− − −
−1
2
2(32)
xiτ
Page 16 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
where the indicator function Ind(·) takes on the value 1 ifthe condition is satisfied and 0 otherwise. Hard threshold-ing using the signum function leads to intuitive networkconcepts (e.g., the node connectivity equals the numberof direct neighbors), but it may lead to a loss of informa-tion: if τ has been set to 0.8, there will be no connectionbetween two nodes if their similarity equals 0.79.
To avoid the disadvantages of hard thresholding, we pro-posed a 'soft' thresholding approach that raises the abso-lute value of the correlation to the power β ≥ 1 [21], i.e.
aij = Power(|cor(xi, xj)|, β) = |cor(xi, xj)|β. (35)In our yeast cell cycle gene co-expression network analy-sis, we followed the analysis steps described in [21].Briefly, we used the 2001 most varying and connectedgenes. Next, we used the power adjacency function with β= 7 (equation (35)) to construct a weighted gene co-expression network and the signum adjacency functionwith τ = 0.65 (equation (34)) to construct an unweightednetwork.
Using our R software tutorial, the reader can easily verifythat our conclusions are highly robust with respect to a)different ways of constructing co-expression networks andb) different ways of constructing modules.
Availability and requirementsAn R implementation and the data can be obtained fromthe internet: http://www.genetics.ucla.edu/labs/horvath/ModuleConformity/ModuleNetworks
Appendix: node conformity and factorizability of a general networkEquation (20) provides an explicit formula for the con-formity of a weighted, exactly factorizable network. For ageneral, non-factorizable network, we describe here howto compute the conformity by optimizing an objectivefunction. In the following, we assume a general n × n adja-cency matrix A where n > 2. Let v = (v1,v2, ...,vn)τ be a vectorof length n. We could define the conformity as a vector v*that minimizes the following objective function f(v) = ∑i∑j≠i(aij - vivj)2. But instead, we find the following equiva-lent formulation as a maximization problem more usefulsince it naturally gives rise to a measure of factorizability.
Specifically, we define the objective function
It is clear that FA(CF) = 1 for an exactly factorizable net-work with aij = CFiCFj for i ≠ j. Note that FA(v) ≤ 1 and FA(0
) = 0. One can easily show that if v* maximizes FA(v), then-v* also maximizes FA(v). Further, all components of v*must have the same sign since otherwise, flipping the signof the negative components leads to a higher value ofFA(v). This leads us to the following
Definition 9 (Conformity, Factorizability) We define theconformity CF as the vector with non-negative entries thatmaximizes FA(v). If there is more than one such maximizer,
then a maximizer closest to k/ is chosen. Further, we
define the factorizability F (A) as the corresponding maximumvalue FA(CF).
Our definition of the conformity is a generalization ofDefinition 7 since F(A) = 1 if, and only if, A is exactly fac-torizable with aij = CFiCFj for i ≠ j. The advantages of thisDefinition are briefly described in the discussion section.
In general, FA(v) may have multiple maximizers as can bedemonstrated with the block diagonal simulated example(equation (17)) by choosing n1 = n2 and b1 = b2. By form-ing the first derivative of the factorizability function FA(v)in terms of vi, one can show that a local maximum satisfies
i.e.
Proposition 10 (Expressions for the Factorizability) Ifthe conformity vector CF of the adjacency matrix A exists, thenthe factorizability F(A) is given by
Proof Since ,
it will be sufficient to show that
. From the
definition of the Frobenius norm of a matrix B, one can
show that where the trace of a matrix is
the sum of its diagonal elements. Thus,
. Using equation (38), we find that trace((A - I)(ACF - I)) =
Fa v v
a
A I diagA
ij i jj ii
ijj ii
F( ) :( )
( )
( )v
v vv= −
−= −
− + −≠
≠
∑∑∑∑
1 1
2
2
2 τ 22
2A I F−.
(36)
S1( )k
a CF CF CFij jj i
i jj i≠ ≠
∑ ∑= 2, (37)
( ( )) || || .A I diag− + =CF CF CF CF222 (38)
F AA I
A I
S S
A I
CF F
F F
( )( ) ( )
.=−
−= −
−
2
22
242
CF CF (39)
F AA I diag
A I
F
F
( )( ) ( )
= −− + −
−1
2 2
2
CF CF CF τ
( ) ( )A I A I A I A ICF F F CF F− − − = − − −2 2 2
B trace B BF2 = ( )τ
( ) ( ) (( )( ))A I A I A I A I trace A I A ICF F F CF F CF− − − = − + − − × − −2 2 2 2
Page 17 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
tr((A - I)CF CFτ) - tr((A - I)diag(CF2)) = CFτ(A - I)CF =
. Thus,
The
remainder of the proof is straightforward.
Equation (38) suggests that the conformity is an eigenvec-tor of the 'hat' adjacency matrix
:= A - I + diag(CF2).
An algorithm for computing the conformity is based onthe following
Lemma 11 If A denotes a symmetric real matrix with eigenval-ues d1, ..., dn sorted according to their absolute values, i.e., |d1|
≥ |d2| ≥ ... ≥ |dn|, and the corresponding orthonormal eigenvec-
tors are denoted by u1, ..., un, then is minimized at
v* = u1.
The proof can be found in Horn and Johnson (1991).
Denote by CF(i - 1) an estimate of the conformity CF.Next define
(i - 1) = A - I + diag(CF(i - 1)2). (40)Define a new estimate of the conformity by
where (i - 1) and (i - 1) denote the largest eigen-
value and corresponding unit length eigenvector of (i -
1). One can easily show that all the components of (i
- 1) must have the same sign and we assume without lossof generality non-negative components. Lemma 11 with A
= (i - 1) implies that
Considering the diagonal elements, one can easily showthat
Thus, we arrive at the following
FA(CF(i)) ≥ FA(CF(i - 1)), (42)
which suggests a monotonic algorithm for computing CF.
Equation 16 suggests to choose k/ as a starting
value of the algorithm. These comments give rise to thefollowing
Definition 12 (Algorithmic Definition of Conformity,Factorizability) For a general network A, set CF(1) = k/
and apply the monotonic iterative algorithm described
by equations (40) and (41). If the limit CF(∞) exists, we
define it as the conformity CF = CF(∞). Further, we define thenetwork factorizability as
Note that the conformity satisfies equation (38) by defini-tion of convergence. One can easily show that 0 ≤ F(A) ≤1. Further, one can easily show that F(A) = 1 if, and onlyif, A is exactly factorizable with aij = CFiCFj, i.e. A - I = ACF- I.
The algorithm described by equations (40) and (41) ismonotonic (equation (42)). It is a special case of an algo-rithm described in [46] for fitting a least squares factoranalysis model with one factor. Theoretical properties ofthe algorithm are discussed in [46] and [48].
We find that for most real networks, the conformity ishighly related to the first eigenvector of the adjacencymatrix, i.e. the conformity vector CF is roughly equal to
u1 where d1 is the largest eigenvalue of A and u1 is the
corresponding unit length eigenvector with positive com-ponents.
A ICF F− 2
( ) ( )A I A I A I A ICF F F CF F− − − = − − −2 2 2
A
AF
− vvτ 2
d1
A
CF u( ) ( ) ( ),i d i i= − −1 11 1 (41)
d1 u1
A
u1
A
A I diag i i i
A I diag i
F− + − − − −
≥ − + − −
( ( ) ) ( ) ( )
( ( ) )
CF CF CF
CF CF
1 1 1
1
2 2
2
τ
(( ) ( ) .i iF
CF τ 2
A I diag i i i
A I diag i i
F− + − −
≥ − + −
( ( ) ) ( ) ( )
( ( ) ) ( ) (
CF CF CF
CF CF CF
1 2 2
2
τ
iiF
) .τ 2
S1( )k
S1( )k
F AA I A I
A I
CF F
F
( )( ) ( )
.= −− − −
−1
2
2(43)
d1
Page 18 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
Additional material
AcknowledgementsWe would like to acknowledge the grant support from Program Project Grant 1U19AI063603-01 and NINDS/NIMH 1U24NS043562-01. We are grateful for discussions with Andy Yip, Lora Bagryanova, Dan Geschwind, Johanna Hardin, Ken Lange, Peter Langfelder, Ai Li, Jake Lusis, Paul Mischel, Stan Nelson, Nan Zhang and Wei Zhao.
References1. Kim J, Bates DG, Postlethwaite I, Heslop-Harrison P, Cho KH: Least-
Squares Methods for Identifying Biochemical RegulatoryNetworks from Noisy Measurements. BMC Bioinformatics 2007,8:8.
2. Klamt S, Saez-Rodriguez J, Gilles E: Structural and FunctionalAnalysis of Cellular Networks with Cellnetanalyzer. BMC Sys-tems Biology 2007, 1(2):.
3. Schaub M, Henzinger T, Fisher J: Qualitative Networks: A Sym-bolic Approach to Analyze Biological Signaling Networks.BMC Systems Biology 2007, 1(4):.
4. Gille C, Hoffmann S, Holzhuetter H: METANNOGEN: CompilingFeatures of Biochemical Reactions Needed for the Recon-struction of Metabolic Networks. BMC Systems Biology 2007,1(5):.
5. Sotiropoulos V, Kaznessis Y: Synthetic Tetracycline-InducibleRegulatory Networks: Computer-Aided Design of DynamicPhenotypes. BMC Systems Biology 2007, 1(7):.
6. Albert R, Jeong H, Barabasi AL: Error and attack tolerance ofcomplex networks. Nature 2000, 406(6794):378-382.
7. Jeong H, Mason SP, Barabasi AL, Oltvai ZN: Lethality and central-ity in protein networks. Nature 2001, 411:41.
8. Han JD, Bertin N, Hao T, Goldberg D, Berriz G, Zhang L, Dupuy D,Walhout A, Cusick M, Roth F, Vidal M: Evidence for dynamicallyorganized modularity in the yeast protein-protein interac-tion network. Nature 2004, 430(6995):88-93.
9. Carlson M, Zhang B, Fang Z, Mischel P, Horvath S, Nelson SF: Geneconnectivity, function, and sequence conservation: Predic-tions from modular yeast co-expression networks. BMCGenomics 2006, 7(40):.
10. Horvath S, Zhang B, Carlson M, Lu K, Zhu S, Felciano R, Laurance M,Zhao W, Shu Q, Lee Y, Scheck A, Liau L, Wu H, Geschwind D, FebboP, Kornblum H, Cloughesy T, Nelson S, Mischel P: Analysis of onco-genic signaling networks in Glioblastoma identifies ASPM asa novel molecular target. Proc Natl Acad Sci USA 2006,103(46):17402-17407.
11. Carter S, Brechbuler C, MGriffin , Bond A: Gene co-expressionnetwork topology provides a framework for molecular char-acterization of cellular state. Bioinformatics 2004,20(14):2242-2250.
12. Oldham M, Horvath S, Geschwind D: Conservation and evolutionof gene co-expression networks in human and chimpanzeebrain. Proc Natl Acad Sci USA 2006, 103(47):17973-8.
13. Snijders T: The degree variance: An index of graph heteroge-neity. Social Networks 1981, 3:163-174.
14. Freeman L: Centrality in social networks: Conceptual clarifica-tion. Social Networks 1978, 1:215-239.
15. Ma HW, Zeng AP: The connectivity structure, giant strongcomponent and centrality of metabolic networks. Bioinformat-ics 2003, 19(11):1423-1430.
16. Barabasi AL, Oltvai ZN: Network Biology: Understanding thecells's functional organization. Nature Reviews Genetics 2004,5:101-113.
17. Pagel M, Meade A, Scott D: Assembly rules for protein networksderived from phylogenetic-statistical analysis of wholegenomes. BMC Evolutionary Biology 2007, 7(Suppl 1):S16.
18. Watts DJ: A simple model of global cascades on random net-works. PNAS 2002, 99(9):5766-5771.
19. Watts DJ, Strogatz SH: Collective dynamics of 'small-world'networks. Nature 1998, 393(6684):440-2.
20. Ravasz E, Somera AL, Mongru DA, Oltvai ZN, Barabasi AL: Hierar-chical organization of modularity in metabolic networks. Sci-ence 2002, 297(5586):1551-5.
21. Zhang B, Horvath S: A general framework for weighted geneco-expression network analysis. Statistical Applications in Geneticsand Molecular Biology 2005, 4:17.
22. Gutteridge A, Kanehisa M, Goto S: Regulation of metabolic net-works by small molecule metabolites. BMC Bioinformatics 2007,8:88.
23. Zhao J, Yu H, Luo JH, Cao ZW, Li YX: Hierarchical modularity ofnested bow-ties in metabolic networks. BMC Bioinformatics2006, 7:386.
24. Spirin V, Gelfand MS, Mironov AA, Mirny LA: A metabolic networkin the evolutionary context: Multiscale structure and modu-larity. PNAS 2006, 103(23):8774-8779.
25. Yip AM, Horvath S: Gene network interconnectedness and thegeneralized topological overlap measure. BMC Bioinformatics2007, 8:22.
26. Li A, Horvath S: Network neighborhood analysis with themulti-node topological overlap measure. Bioinformatics 2007,23(2):222-231.
27. Kaufman L, Rousseeuw PJ: Finding Groups in Data. An Introduction toCluster Analysis New York: John Wiley & Sons, Inc; 1990.
28. Ghazalpour A, Doss S, Zhang B, Plaisier C, Wang S, Schadt E, ThomasA, Drake T, Lusis A, Horvath S: Integrating genetics and net-work analysis to characterize genes related to mouseweight. PloS Genetics 2006, 2(8):.
29. Ye Y, Godzik A: Comparative Analysis of Protein DomainOrganization. Genome Biology 2004, 14(3):343-353.
30. Gargalovic P, Imura M, Zhang B, Gharavi N, Clark M, Pagnon J, YangW, He A, Truong A, Patel S, Nelson S, Horvath S, Berliner J, Kirch-gessner T, Lusis A: Identification of inflammatory gene mod-ules based on variations of human endothelial cell responsesto oxidized lipids. PNAS 2006, 103(34):12741-6.
31. Breitkreutz B, Stark C, Tyers M: The GRID: the general reposi-tory for interaction datasets. Genome Biol 2003, 4:R23.
Additional file 1Complete list of network concepts in the modules. An extended version of Table 1.Click here for file[http://www.biomedcentral.com/content/supplementary/1752-0509-1-24-S1.xls]
Additional file 3Functional enrichment analysis (gene ontology) of the Drosophila PPI modules (DAVID software).Click here for file[http://www.biomedcentral.com/content/supplementary/1752-0509-1-24-S3.xls]
Additional file 4Functional enrichment analysis (gene ontology) of the yeast PPI modules (DAVID software).Click here for file[http://www.biomedcentral.com/content/supplementary/1752-0509-1-24-S4.xls]
Additional file 5Functional enrichment analysis (gene ontology) of the yeast gene co-expression modules (DAVID software).Click here for file[http://www.biomedcentral.com/content/supplementary/1752-0509-1-24-S5.xls]
Additional file 2Network concepts and module size. Descriptions of how module concepts are related to module sizes in the Drosophila PPI, yeast PPI networks, and yeast gene co-expression networks.Click here for file[http://www.biomedcentral.com/content/supplementary/1752-0509-1-24-S2.pdf]
Page 19 of 20(page number not for citation purposes)

BMC Systems Biology 2007, 1:24 http://www.biomedcentral.com/1752-0509/1/24
Publish with BioMed Central and every scientist can read your work free of charge
"BioMed Central will be the most significant development for disseminating the results of biomedical research in our lifetime."
Sir Paul Nurse, Cancer Research UK
Your research papers will be:
available free of charge to the entire biomedical community
peer reviewed and published immediately upon acceptance
cited in PubMed and archived on PubMed Central
yours — you keep the copyright
Submit your manuscript here:http://www.biomedcentral.com/info/publishing_adv.asp
BioMedcentral
32. Butte AJ, Kohane IS: Mutual information relevance networks:Functional genomic clustering using pairwise entropy meas-urements. PSB 2000, 5:415-426.
33. Eisen MB, Spellman PT, Brown PO, Botstein D: Cluster analysisand display of genome-wide expression patterns. PNAS 1998,95(25):14863-14868.
34. Ge H, Liu Z, Church GM, Vidal M: Correlation between tran-scriptome and interactome mapping data from Saccharomy-ces cerevisiae. Nat Genet 2003, 33:15-16.
35. Spellman P, Sherlock G, Zhang M, Iyer V, Anders K: Comprehen-sive Identification of Cell Cycle-regulated Genes of the YeastSaccharomyces Cerevisiae by Microarray Hybridization. MolBiol Cell 1998, 9(12):3273-3297.
36. Dennis G, Sherman B, Hosack D, Yang J, Gao W, Lane HC, LempickiR: DAVID: Database for Annotation, Visualization, and Inte-grated Discovery. Genome Biology 2003, 4(5):P3.
37. Erdös P, Rényi A: On the evolution of random graphs. Publ MathInst Hung Acad Sci 1960, 5:17-60.
38. Barrat A, Barthelemy M, Pastor-Satorras R, Vespignani A: The archi-tecture of complex weighted networks. Proc Natl Acad Sci USA2004, 101:3747-52.
39. Deeds EJ, Ashenberg O, Shakhnovich EI: From The Cover: A sim-ple physical model for scaling in protein-protein interactionnetworks. PNAS 2006, 103(2):311-316.
40. Servedio V, Caldarelli G, Butta P: Vertex intrinsic fitness: How toproduce arbitrary scale-free networks. Physical Review E (Statis-tical, Nonlinear, and Soft Matter Physics) 2004, 70(5 Pt 2):056126.
41. Masuda N, Miwa H, Konno N: Geographical threshold graphswith small-world and scale-free properties. Physical Review E(Statistical, Nonlinear, and Soft Matter Physics) 2005, 71(3 Pt2A):036108.
42. Yeung MS, Tegner J, Collins J: Reverse engineering gene net-works using singular value decomposition and robust regres-sion. PNAS 2002, 99(9):6163-6168.
43. Alter O, Golub G: Reconstructing the pathways of a cellularsystem from genome-scale signals by using matrix and ten-sor computations. PNAS 2005, 102(49):17559-17564.
44. Price N, Reed J, Papin J, Famili I, Palsson B: Analysis of metaboliccapabilities using singular value Decomposition of ExtremePathway Matrices. Biophys J 2003, 84(2):794-804.
45. Bu D, Zhao Y, Cai L, Xue H, Zhu X, Lu H, Zhang J, Sun S, Ling L,Zhang N, Li G, Chen R: Topological structure analysis of theprotein-protein interaction network in budding yeast. NuclAcids Res 2003, 31(9):2443-2450.
46. de Leeuw J, Michailidis G: Block relaxation algorithms in statis-tics. Journal of Computational and Graphical Statistics 2000, 9:26-31.
47. Barabasi AL, Albert R: Emergence of scaling in random net-works. Science 1999, 286(5439):509-12.
48. Gifi A: Nonlinear multivariate analysis Wiley, Chichester, England; 1990.
Page 20 of 20(page number not for citation purposes)





























