Embed Size (px)
DESCRIPTION
Understanding Hadoop Clusters and the Network
Citation preview

Understanding Hadoop Clusters and the Network
Part 1. Introduction and Overview
BRAD HEDLUND .com
Brad Hedlund http://bradhedlund.com http://www.linkedin.com/in/bradhedlund @bradhedlund

Hadoop Server Roles
Data Node & Task Tracker
Data Node & Task Tracker
Data Node & Task Tracker
Data Node & Task Tracker
Data Node & Task Tracker
Data Node & Task Tracker
slaves
masters
Clients
Name Node Job Tracker Secondary
Name Node
Map Reduce HDFS
Distributed Data Analytics Distributed Data Storage
BRAD HEDLUND .com

Hadoop Cluster
Rack 1
DN + TT
DN + TT
DN + TT
DN + TT
Name Node
Rack 2
DN + TT
DN + TT
DN + TT
DN + TT
Job Tracker
Rack 3
DN + TT
DN + TT
DN + TT
DN + TT
Secondary NN
Rack 4
DN + TT
DN + TT
DN + TT
DN + TT
Client
Rack N
DN + TT
DN + TT
DN + TT
DN + TT
DN + TT
DN + TT
World
switch switch switch switch switch
switch switch
BRAD HEDLUND .com

Typical Workflow
• Load data into the cluster (HDFS writes)
• Analyze the data (Map Reduce)
• Store results in the cluster (HDFS writes)
• Read the results from the cluster (HDFS reads)
How many times did our customers type the word “Fraud” into emails sent to customer service?
Sample Scenario:
File.txt Huge file containing all emails sent to customer service
BRAD HEDLUND .com

Writing files to HDFS
• Client consults Name Node • Client writes block directly to one Data Node • Data Nodes replicates block • Cycle repeats for next block
Name Node
Data Node 1 Data Node 5 Data Node 6 Data Node N
Client
I want to write Blocks A,B,C of
File.txt
OK. Write to Data Nodes
1,5,6
Blk A Blk B Blk C
File.txt
Blk A Blk B Blk C
BRAD HEDLUND .com

Hadoop Rack Awareness – Why?
Name Node
File.txt= Blk A: DN1, DN5, DN6 Blk B: DN7, DN1, DN2 Blk C: DN5, DN8,DN9
metadata
Rack 1
Data Node 1
Data Node 2
Data Node 3
Data Node 5
switch
A
Rack 5
Data Node 5
Data Node 6
Data Node 7
Data Node 8
switch
Rack 9
Data Node 9
Data Node 10
Data Node 11
Data Node 12
switch
• Never loose all data if entire rack fails
• Keep bulky flows in-rack when possible
• Assumption that in-rack is higher bandwidth, lower latency
A
A
B B
B
C C
C
switch
Rack 1: Data Node 1 Data Node 2 Data Node 3 Rack 5: Data Node 5 Data Node 6 Data Node 7
Rack aware
BRAD HEDLUND .com

switch
switch switch
Preparing HDFS writes
Name Node
Data Node 1 Data Node 5
Data Node 6
Client
I want to write File.txt Block A
OK. Write to Data Nodes
1,5,6
Blk A Blk B Blk C
File.txt
Ready Data Nodes
5,6
Ready?
Rack 1 Rack 5
Rack 1: Data Node 1 Rack 5: Data Node 5 Data Node 6
Ready Data Node 6
Rack aware
Ready! • Name Node picks two nodes in the same rack, one node in a different rack
• Data protection • Locality for M/R
Ready!
BRAD HEDLUND .com

switch
switch switch
Pipelined Write
Name Node
Data Node 1 Data Node 5
Data Node 6
Client Blk A Blk B Blk C
File.txt
Rack 1 Rack 5
Rack 1: Data Node 1 Rack 5: Data Node 5 Data Node 6
A A
A
• Data Nodes 1 & 2 pass data along as its received
• TCP 50010
Rack aware
BRAD HEDLUND .com

switch
switch switch
Pipelined Write
Name Node
Data Node 1 Data Node 2
Data Node 3
Client Blk A Blk B Blk C
File.txt
Rack 1 Rack 5
Rack 1: Data Node 1 Rack 5: Data Node 2 Data Node 3
A A
A
Block received
Success
File.txt Blk A: DN1, DN2, DN3
BRAD HEDLUND .com

Multi-block Replication Pipeline
Data Node 1 Data Node X
Data Node 3
Rack 1
switch
switch
Client
switch
Blk A Blk A
Blk A
Rack 4
Data Node 2
Rack 5
switch
Data Node Y
Data Node Z
Blk B
Blk B
Blk B
Data Node W
Blk C
Blk C
Blk C
Blk A Blk B Blk C
File.txt 1TB File = 3TB storage 3TB network traffic
BRAD HEDLUND .com

Client writes Span the HDFS Cluster
Client
Rack N
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
File.txt
Rack 4
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
Rack 3
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
Rack 2
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
Rack 1
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
• Block size • File Size
Factors:
More blocks = Wider spread
BRAD HEDLUND .com

Data Node writes span itself, and other racks
Rack N
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
Rack 4
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
Rack 3
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
Rack 2
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
C
C
B
B
A
A
Rack 1
Data Node
Data Node
Data Node
Data Node
Data Node
switch
C B A
Blk A Blk B Blk C
Results.txt
BRAD HEDLUND .com

Name Node
• Data Node sends Heartbeats • Every 10th heartbeat is a Block report • Name Node builds metadata from Block reports • TCP – every 3 seconds • If Name Node is down, HDFS is down
Name Node
Data Node 1 Data Node 2 Data Node 3 Data Node N
A A A C C
DN1: A,C DN2: A,C DN3: A,C
metadata
File.txt = A,C
C
File system Awesome!
Thanks.
I’m alive!
I have blocks:
A, C
BRAD HEDLUND .com

Re-replicating missing replicas
Name Node
Data Node 1 Data Node 2 Data Node 3 Data Node 8
A A A C C
DN1: A,C DN2: A,C DN3: A, C
metadata Rack1: DN1, DN2 Rack5: DN3, Rack9: DN8
C
Rack Awareness
Uh Oh! Missing replicas
Copy blocks A,C to Node 8
A C
• Missing Heartbeats signify lost Nodes
• Name Node consults metadata, finds affected data
• Name Node consults Rack Awareness script
• Name Node tells a Data Node to re-replicate
BRAD HEDLUND .com

Secondary Name Node
• Not a hot standby for the Name Node
• Connects to Name Node every hour*
• Housekeeping, backup of Name Node metadata
• Saved metadata can rebuild a failed Name Node
Name Node
metadata
File.txt = A,C
File system
Secondary Name Node
Its been an hour, give me your
metadata
BRAD HEDLUND .com

Client reading files from HDFS
Name Node Client
Tell me the block locations of Results.txt
Blk A = 1,5,6 Blk B = 8,1,2 Blk C = 5,8,9
Results.txt= Blk A: DN1, DN5, DN6 Blk B: DN7, DN1, DN2 Blk C: DN5, DN8,DN9
metadata
Rack 1
Data Node 1
Data Node 2
Data Node
Data Node
switch
A
Rack 5
Data Node 5
Data Node 6
Data Node
Data Node
switch
Rack 9
Data Node 8
Data Node 9
Data Node
Data Node
switch
• Client receives Data Node list for each block
• Client picks first Data Node for each block
• Client reads blocks sequentially
A
A
B B
B
C C
C
BRAD HEDLUND .com

Data Node reading files from HDFS
Name Node
Block A = 1,5,6
File.txt= Blk A: DN1, DN5, DN6 Blk B: DN7, DN1, DN2 Blk C: DN5, DN8,DN9
metadata
Rack 1
Data Node 1
Data Node 2
Data Node 3
Data Node
switch
A
Rack 5
Data Node 5
Data Node 6
Data Node
Data Node
switch
Rack 9
Data Node 8
Data Node 9
Data Node
Data Node
switch
• Name Node provides rack local Nodes first
• Leverage in-rack bandwidth, single hop
A
A
B B
B
C C
C
Tell me the locations of Block A of
File.txt switch
Rack 1: Data Node 1 Data Node 2 Data Node 3 Rack 5: Data Node 5
Rack aware
BRAD HEDLUND .com
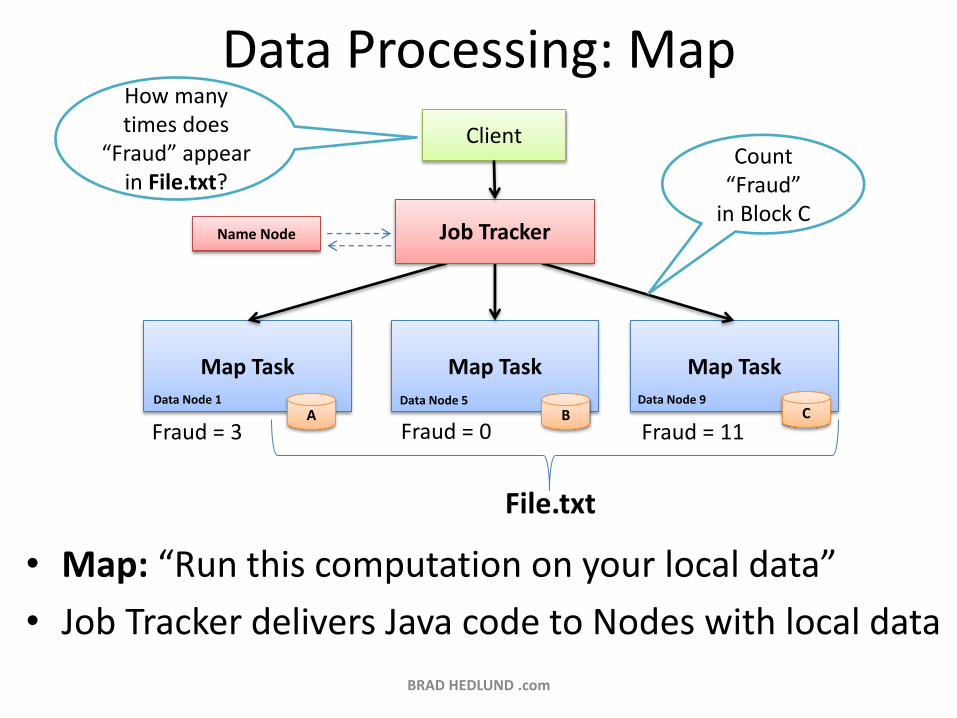
Data Processing: Map
• Map: “Run this computation on your local data”
• Job Tracker delivers Java code to Nodes with local data
Map Task Map Task Map Task
A B C
Client
How many times does
“Fraud” appear in File.txt?
Count “Fraud”
in Block C
File.txt
Fraud = 3 Fraud = 0 Fraud = 11
Job Tracker Name Node
Data Node 1 Data Node 5 Data Node 9
BRAD HEDLUND .com

switch switch switch
What if data isn’t local?
• Job Tracker tries to select Node in same rack as data • Name Node rack awareness
“I need block A” Map Task Map Task
B C
Client
How many times does
“Fraud” appear in File.txt?
Count “Fraud”
in Block C
Fraud = 0 Fraud = 11
Job Tracker Name Node
Data Node 1
Data Node 5 Data Node 9
“no Map tasks left”
A
Data Node 2
Rack 1 Rack 5 Rack 9
BRAD HEDLUND .com

Data Processing: Reduce
• Reduce: “Run this computation across Map results”
• Map Tasks deliver output data over the network
• Reduce Task data output written to and read from HDFS
Fraud = 0
Job Tracker
Reduce Task
Sum “Fraud”
Results.txt Fraud = 14
Map Task Map Task Map Task
A B C
Client
HDFS
X Y Z
Data Node 1 Data Node 5 Data Node 9
Data Node 3
BRAD HEDLUND .com

Unbalanced Cluster
New Rack
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
Rack 2
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
Rack 1
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch NEW
switch
New Rack
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch NEW
File.txt
• Hadoop prefers local processing if possible
• New servers underutilized for Map Reduce, HDFS*
• Might see more network bandwidth, slower job times**
**I was assigned a Map Task but don’t have the block. Guess I need to get it.
*I’m bored!
BRAD HEDLUND .com
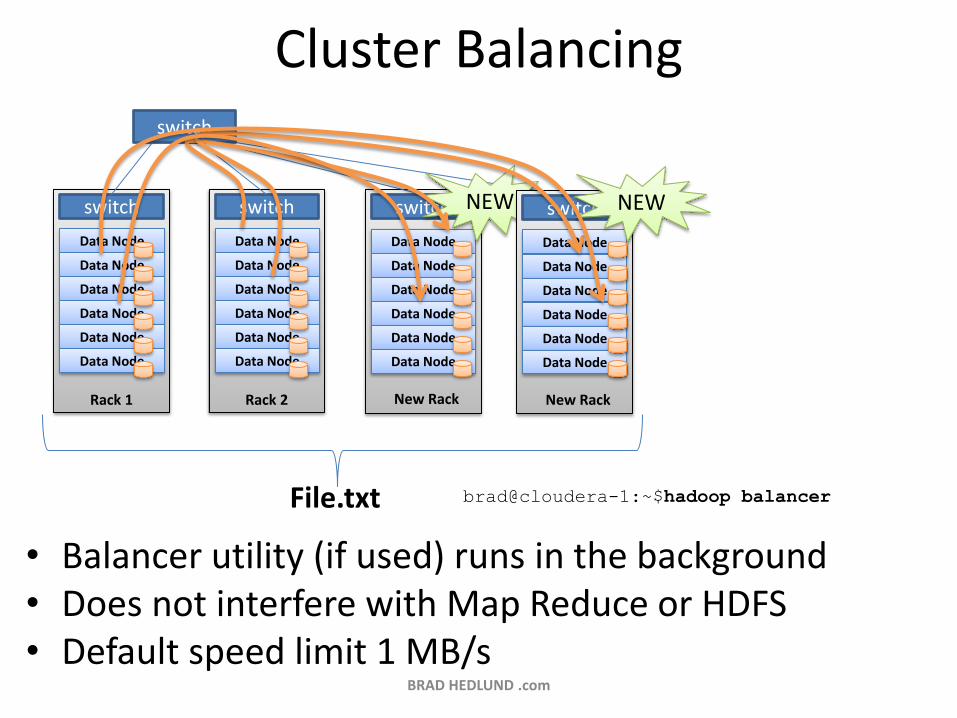
Cluster Balancing
New Rack
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
Rack 2
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch
Rack 1
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch NEW
switch
New Rack
Data Node
Data Node
Data Node
Data Node
Data Node
Data Node
switch NEW
File.txt
• Balancer utility (if used) runs in the background • Does not interfere with Map Reduce or HDFS • Default speed limit 1 MB/s
brad@cloudera-1:~$hadoop balancer
BRAD HEDLUND .com

Thanks!
Narrated at:
http://bradhedlund.com/?p=3108
BRAD HEDLUND .com





























