Embed Size (px)
Citation preview

Uczenie ze wzmocnieniem
Maria Ganzha
Wydział Matematyki i Nauk Informatycznych
2018-2019

Metoda Monte-Carlo
Cel wykładu – przedstawić metody Monte-Carlo predykcji funkcji wartości iznalezienia polityki optymalnej. Metoda Monte-Carlo (MC):
nie wymaga pełnej wiedzy o środowiskudo predykcji używamy “doświadczeń” (experience) – przykładowejsekwencji stanów, akcji i nagród w rzeczywistej lub symulowanejinterakcji ze środowiskiemI interakcja z symulowanym środowiskiem potrzebuje modelu środowiska,
który wystarczy, że wygeneruje próbkowane przejścia bez pełnegorozkładu podobieństwa wszystkich możliwych przejść
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 2 / 24

Metoda Monte-Carlo (1)
Metodę MC zdefiniujemy tylko dla zadań “epizodycznych” (episodictask)I gra składa się z koniecznej ilości krokówI zwrot (nagroda do zdoycia):
Gt = Rt+1 + · · ·+ RT ,
gdzie stan T – specjalny stan (stan terminalny). Zadania, składającesię z takich epizodów będziemy nazywać zadaniami epizodycznymi(episodic tasks). Zbiór stanów ze stanem terminalnym będziemyoznaczać X+
Funkcja wartości i polityka są oceniane po zakończeniu epizodu
Idea MC – uśrednienie całkowitej wygranejPodobnie do DP używamy podejścia GPI (General Policy Iteration),ale uczymy się funkcji wartości na podstawie przykładowych nagród wprocesie MDP
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 3 / 24

Metoda Monte-Carlo (1)
Metodę MC zdefiniujemy tylko dla zadań “epizodycznych” (episodictask)I gra składa się z koniecznej ilości krokówI zwrot (nagroda do zdoycia):
Gt = Rt+1 + · · ·+ RT ,
gdzie stan T – specjalny stan (stan terminalny). Zadania, składającesię z takich epizodów będziemy nazywać zadaniami epizodycznymi(episodic tasks). Zbiór stanów ze stanem terminalnym będziemyoznaczać X+
Funkcja wartości i polityka są oceniane po zakończeniu epizoduIdea MC – uśrednienie całkowitej wygranej
Podobnie do DP używamy podejścia GPI (General Policy Iteration),ale uczymy się funkcji wartości na podstawie przykładowych nagród wprocesie MDP
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 3 / 24

Metoda Monte-Carlo (1)
Metodę MC zdefiniujemy tylko dla zadań “epizodycznych” (episodictask)I gra składa się z koniecznej ilości krokówI zwrot (nagroda do zdoycia):
Gt = Rt+1 + · · ·+ RT ,
gdzie stan T – specjalny stan (stan terminalny). Zadania, składającesię z takich epizodów będziemy nazywać zadaniami epizodycznymi(episodic tasks). Zbiór stanów ze stanem terminalnym będziemyoznaczać X+
Funkcja wartości i polityka są oceniane po zakończeniu epizoduIdea MC – uśrednienie całkowitej wygranejPodobnie do DP używamy podejścia GPI (General Policy Iteration),ale uczymy się funkcji wartości na podstawie przykładowych nagród wprocesie MDP
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 3 / 24

Metoda Monte-Carlo (2)
Zadanie – ocenić funkcję wartości V π(x) dla danej polityki(rem.expected return): wartość stanu x przy stosowaniu polityki π(rozpatrujemy zbiór epizodów zgodnych z π i odwiedzających stan x).I każde “włączenie” stanu x do epizodu będziemy nazywać wizytą
“Metoda MC pierwszej wizyty” oceny V π(x) jako średnią dochodów(return) od “pierwszej wizyty” stanu xI “Metoda MC wszystkich wizyt” – średnia dochodów od wszystkich
wizyt stanu x
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 4 / 24

initialization π ← policy to be evaluated;V (x)← arbitrary state-value function;Returns(x)← empty list (∀x ∈ X );Repeat foreverGenerate an episode using π;for x appearing in the episode do
G ← the return that follows the first occurence of x ;Append G to Returns(x);V (x)← average(Returns(x))
endAlgorithm 1: First-visit MC prediction, for estimating V ≈ V π
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 5 / 24

Blackjack (1)
skończona gra (MDP), epizodyczna (czyli każda gra to epizod)nagrody +1, −1, i 0 są dawane za “wygranie”, “przegranie” i “ktobliżej do 21” lub losowanie, kto wygrałnie używamy dyskontowego mnożnika (γ = 1)stan – zależy od kart gracza i od odkrytej karty rozdającegoI karty są liczone od 2 do 10, figury – po 10, as – 11 lub 1
zakładamy, że stos kart jest niekończący sięas nazywany używalnym, jeżeli gracz może go policzyć nieprzekraczając granicy 21powyższe oznacza, że gracz podejmuje decyzje na podstawieI aktualnej sumy (od 12 do 21),I jaka jest karta otwarta u rozdającego (as-10),I czy ma używalnego asa.
200 możliwych stanów
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 6 / 24

Blackjack (1)
skończona gra (MDP), epizodyczna (czyli każda gra to epizod)nagrody +1, −1, i 0 są dawane za “wygranie”, “przegranie” i “ktobliżej do 21” lub losowanie, kto wygrałnie używamy dyskontowego mnożnika (γ = 1)stan – zależy od kart gracza i od odkrytej karty rozdającegoI karty są liczone od 2 do 10, figury – po 10, as – 11 lub 1
zakładamy, że stos kart jest niekończący sięas nazywany używalnym, jeżeli gracz może go policzyć nieprzekraczając granicy 21powyższe oznacza, że gracz podejmuje decyzje na podstawieI aktualnej sumy (od 12 do 21),I jaka jest karta otwarta u rozdającego (as-10),I czy ma używalnego asa.
200 możliwych stanówMaria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 6 / 24

Blackjack (2)
Polityka: stop jeżeli gracz ma 20 lub 21, w innym przypadku bierzekolejną kartę
Rysunek: Aprosymacja funkcji wartości stanu przy polityce 20/21
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 7 / 24

Ocena MC wartości akcji
Jeżeli model niedostępny → funkcja wartości akcji bardziej przydatnaCel – obliczyć Q∗
Problem – może pominąć wiele par stan-akcjaSposób – exploring starts
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 8 / 24

Generelized Policy IterationMetoda Monte-Carlo w zagadnieniach kontroli
Rozpatrzmy wersje Monte-Carlo klasycznej iteracji polityki. Zacznijmyz “dowolnej polityki” π
π0E−→ Qπ0
I−→ π1E−→ Qπ1
I−→ . . .I−→ π∗
E−→ Q∗
sprawdzamy wiele(!) epizodówjako metodę do polepszenia polityki – zachłanna
π(x) = arg maxa
Q(x , a)
Qπk (x , πk+1(x)) =Qπk (x , arg maxa
Qπk (x , a)) =
= maxa
Qπk (x , a) maxa
Qπk (x , πk(x)) Vπk (x)
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 9 / 24

Iteracja polityki MC
zakłądamy, że mamy nieskończoną ilość epizodów i tak zwany“odkrywczy” start ⇒ zrezygnować z tych założeń???
initialization ∀x ∈ X , a ∈ A; Q(x , a)← arbitrary;π ← arbitrary;V (x)← arbitrary state-value function;Returns(x , a)← empty list ;Repeat forever Choose S0 ∈ X , A0 ∈ A(S′);Generate an episode starting from S0,A0 using π;for x , a appearing in the episode do
Append G to Returns(x,a);Q(x , a)← average(Returns(x,a));For each x in episode: π(x)← arg maxa Q(s, a)
endAlgorithm 2: MonteCarlo ES for estimation π ≈ π∗
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 10 / 24

Iteracja polityki MC
zakłądamy, że mamy nieskończoną ilość epizodów i tak zwany“odkrywczy” start ⇒ zrezygnować z tych założeń???initialization ∀x ∈ X , a ∈ A; Q(x , a)← arbitrary;π ← arbitrary;V (x)← arbitrary state-value function;Returns(x , a)← empty list ;Repeat forever Choose S0 ∈ X , A0 ∈ A(S′);Generate an episode starting from S0,A0 using π;for x , a appearing in the episode do
Append G to Returns(x,a);Q(x , a)← average(Returns(x,a));For each x in episode: π(x)← arg maxa Q(s, a)
endAlgorithm 3: MonteCarlo ES for estimation π ≈ π∗
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 10 / 24

MC bez “odkrywczego” startu
Jak uniknąć ES (“odkrywczy start”)?on-policy vs off-policyI on-policy – miękka polityka: π(x |a) > 0 for ∀x ∈ X i a ∈ A, która
powoli “schodzi się” do deterministycznejI greedy → non-greedy (ε-greedy)
Z definicji:I non-greedy akcja ma prawdopodobieństwo “zajścia” ε
|A(x)|I “zachłanna” akcja ma prawdopodobieństwo zdarzenia się 1− ε+ ε
|A(x)|
Ogólna idea on-policy MC control – oszacowanie funkcji Q(x,a). Dotego analogicznie jak w przypadku MC ES, używamy first-visit MCdla aktualnej/bieżącej polityki.
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 11 / 24

MC bez “odkrywczego” startu
Jak uniknąć ES (“odkrywczy start”)?on-policy vs off-policyI on-policy – miękka polityka: π(x |a) > 0 for ∀x ∈ X i a ∈ A, która
powoli “schodzi się” do deterministycznejI greedy → non-greedy (ε-greedy)
Z definicji:I non-greedy akcja ma prawdopodobieństwo “zajścia” ε
|A(x)|I “zachłanna” akcja ma prawdopodobieństwo zdarzenia się 1− ε+ ε
|A(x)|
Ogólna idea on-policy MC control – oszacowanie funkcji Q(x,a). Dotego analogicznie jak w przypadku MC ES, używamy first-visit MCdla aktualnej/bieżącej polityki.
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 11 / 24

MC bez “odkrywczego” startu
Jak uniknąć ES (“odkrywczy start”)?on-policy vs off-policyI on-policy – miękka polityka: π(x |a) > 0 for ∀x ∈ X i a ∈ A, która
powoli “schodzi się” do deterministycznejI greedy → non-greedy (ε-greedy)
Z definicji:I non-greedy akcja ma prawdopodobieństwo “zajścia” ε
|A(x)|I “zachłanna” akcja ma prawdopodobieństwo zdarzenia się 1− ε+ ε
|A(x)|
Ogólna idea on-policy MC control – oszacowanie funkcji Q(x,a). Dotego analogicznie jak w przypadku MC ES, używamy first-visit MCdla aktualnej/bieżącej polityki.
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 11 / 24

initialization ∀x ∈ X , a ∈ A;Q(x , a)← arbitrary ;Returns(x , a)← empty list;π(a|x)← arbitrary ε-soft policy; ;Repeat forever: (a) Generate an episode using π;(b) for every x , a appearing in the episode do
G ← return that follows the first occurence s, & a;Append G to Returns(x,a) Q(x , a)← average(Returns(x,a))
end cfor each x in episode do
A∗ ← arg maxa Q(s, a);for ∀a ∈ A(x): do
π(a|x)←
1− ε+ ε|A(x)| if a = A∗
ε|A(x)| if a 6= A∗
endend
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 12 / 24

On-policy first-visit MC control (dla ε-soft polityki) c.d.
można udowodnić, że ε-zachłanna polityka π′ w stosunku do Qπ jestlepsza lub taka sama jak ε-soft polityka π (π′ π)można udowodnić, że π = π′ tylko wtedy, gdy π i π′ są optymalne dlaε-soft polityk.
Podsumowanie: Iteracja polityki działa dla ε-soft polityki → ten wniosekjest niezależny od tego jak definiowana jest funkcja Qπ (zakładamy tylko,że jest obliczana dokładnie)
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 13 / 24

Predykcja metodą off-policyZ wykorzystaniem “wartościowości próbek”
dylemat: proces uczenia się vs eksploracja (wszystkich) akcjipolityka docelowa (target policy) – którą będziemy badaćpolityka behawioralna – wykorzystywana do generacji zachowań
uczenie się metodą off-policy – uczymy się na danych “z poza”polityki docelowej
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 14 / 24

Predykcja metodą off-policyZ wykorzystaniem “wartościowości próbek”
dylemat: proces uczenia się vs eksploracja (wszystkich) akcjipolityka docelowa (target policy) – którą będziemy badaćpolityka behawioralna – wykorzystywana do generacji zachowańuczenie się metodą off-policy – uczymy się na danych “z poza”polityki docelowej
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 14 / 24

Predykcja metodą off-policy c.d.Zalożenia
zakładamy, że polityki π i b – znane i nie zmieniają się. Zamierzamyocenić Vπ i Qπ (π – polityka docelowa), ale znamy tylko epizodyzgodne z inną polityką – b, b 6= π
∀a ∈ A: jeżeli π(a|x) > 0, to b(a|x) > 0 – założenie “pokrycia”I założenie pokrycia oznacza, że b musi być stochastyczne w tych
stanach, gdzie b 6= π (π może być deterministyczne)
“wartościowość próbki” – (popularna) technika szacowania wartościoczekiwanej dla jednego rozkładu na podstawie próbkowania w innymrozkładzie
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 15 / 24

Predykcja metodą off-policy c.d.Zalożenia
zakładamy, że polityki π i b – znane i nie zmieniają się. Zamierzamyocenić Vπ i Qπ (π – polityka docelowa), ale znamy tylko epizodyzgodne z inną polityką – b, b 6= π
∀a ∈ A: jeżeli π(a|x) > 0, to b(a|x) > 0 – założenie “pokrycia”I założenie pokrycia oznacza, że b musi być stochastyczne w tych
stanach, gdzie b 6= π (π może być deterministyczne)“wartościowość próbki” – (popularna) technika szacowania wartościoczekiwanej dla jednego rozkładu na podstawie próbkowania w innymrozkładzie
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 15 / 24

Współczynnik wartościowości próbek: niech Xt – stan “startowy”.Prawdopodobieństwo następstwa At , Xt+1, At+1,. . . ,XT :
Pr{At ,Xt+1, . . . ,XT |Xt ,At:T−1 ∼ π} ==π(At |Xt)p(Xt+1|Xt ,At)π(At+1|Xt+1) . . . p(XT |Xt−1,AT−1) =
=T−1∏k=t
π(Ak |Xk)p(Xk+a|Xk ,Ak)
Oznacza to, że względne prawdopodobieństwo trajektorii przy docelowej ibehawioralnej politykach (czyi współczynnik wartościowości próbek)
ρt:T−1 =∏T−1
k=t π(Ak |Xk)p)(Xk+1|Xk ,Ak)∏T−1k=t b(Ak |Xk)p)(Xk+1|Xk ,Ak)
=T−1∏k=t
π(Ak |Xk)b(Ak |Xk)
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 16 / 24

Zakładamy, że:Liczenie stanów: jeżeli poprzedni epizod skończył się w stanie 100, tonastępny epizod zaczyna się 101,...T (x) – zbiór wszystkich “kroków”, które doprowadzą do stanu x (wprzypadku zastosowania podejścia first-visit – T (x) zawiera tylkokroki czasowe do stanu x w epizodzie)T (t) – pierwszy stan terminalny (koniec epizodu);Gt – dochód od momentu t do T (t); {Gt}t∈T (x) – dochody związanyze stanem x a {ρt:T (t)−1}t∈T (x) odpowiednie współczynnikiwartościowości próbek
Normalna metoda wartościowości próbek : szacujemy Vπ(x) jako:
V (s) =∑
t∈T (x) ρt:T (t)−1Gt
|T (x)| (1)
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 17 / 24

Alternatywa – metoda ważonej wartościowości próbek – średnia ważona :
V (s) =
∑
t∈T (x) ρt:T (t)−1Gt∑t∈T (x) ρt:T (t)−1
, jeżeli∑
t∈T (x) ρt:T (t)−1 6= 0
0, w przeciwnym przypadku(2)
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 18 / 24

Przykłady jako podsumowaniePrzykład 1: Blackjack funkcja wartości (szacowanie metodą off-policy)
Oceniamy stan, w którym rozdający ma “otwartą” dwójkę, gracz makartę, których suma punktów jest 13 i gracz ma “używalnego” asa(czyli lub ma dwójkę i asa lub trzy asy).Generacja danych:I polityka behawioralna – wybór kolejna karta lub odkryć karty z
prawdopodobieństwem 0.5I polityka docelowa – odkryć karty tylko jeżeli mamy na rękach 20 lub
21; wartość stanu – 0.27726 (oddzielne obliczenia)
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 19 / 24

Blackjack – odchylenie oszacowań, wykres
Rysunek: R.Sutton, A.Barto “Reinformcement learning: an Introduction”
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 20 / 24

Przykład 2: Nieskończona wariacja
Zagadnienie: jeden stan nieterminalny x, 2 akcji – lewo/prawoAkcja “prawo” – przejście do stanu terminalnego (R=0)Akcja “lewo” – z prawdopodobieństwem 0.9 wraca do stanu x (R=0),lub z prawdopodobieństwem 0.1 przechodzi do stanu terminalnego(R=1)Polityka docelowa – zawsze “left” (czyli lub z nagrodą 0 powracamydo x lub z nagrodą 1 do stanu terminalnego). Oznacza to, że wartośćstanu x Vπ(x) = 1Polityka behawioralna – left i right wybiera się z równymprawdopodobieństwem
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 21 / 24
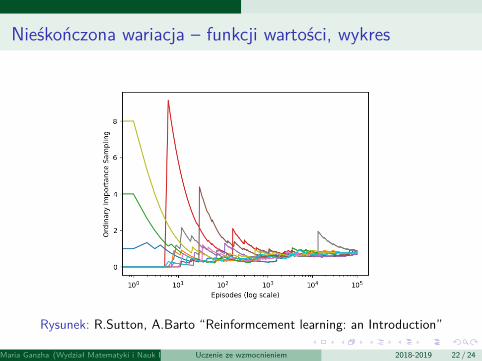
Nieśkończona wariacja – funkcji wartości, wykres
Rysunek: R.Sutton, A.Barto “Reinformcement learning: an Introduction”
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 22 / 24

Implementacja przyrostowa
MC metoda predykcji – uśrednienie “dochodu” (returns)
Vn =∑n−1
k=1 WkGk∑n−1k=1 Wk
,
przy n 2Nowe zasady obliczania Vn+1:
Vn+1 = VnWnCn
[Gn − Vn] ,
przy n 1 i
Cn+1 = Cn + Wn+1,
C0 = 0, V1 – dowolne
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 23 / 24

input π arbitrary target policy;initialization ∀x ∈ X , a ∈ A;Q(x , a)← arbitrary ;C(x , a)← 0;Repeat forever: b ← any policy with coverage of π;Generate an episode using b: X0, A0, R1, . . . ,XT−1,AT−1, Rt , XT ;G ← 0;W ← 1;for each t = T − 1,T − 2, . . . , 0 do
G ← γG + Rt+1;C(Xt ,At)← C(Xt ,At) + W ;Q(Xt ,At)← Q(Xt ,At) + W
C(Xt ,At) [G − Q(Xt ,At)];W ←W π(Xt ,At)
b(Xt ,At) ;if W = 0 then EXIT for loop;
end
Maria Ganzha (Wydział Matematyki i Nauk Informatycznych)Uczenie ze wzmocnieniem 2018-2019 24 / 24





























