Embed Size (px)
Citation preview

Time-Predictability onMulti-/Many-Core Platforms
Wolfgang Puffitsch
Department of Applied Mathematics and Computer ScienceTechnical University of Denmark
CESEC Summer School, ToulouseJune 30, 2015
partially based on slides by Jens Sparsø
Wolfgang Puffitsch, DTU 1/50

Overview
p1 Multi-/Many-Core Platforms
p2 Networks-on-Chip
p3 Predictability on General-Purpose Platforms
p4 Time-Predictable Computer Architectures
p5 Conclusion
Wolfgang Puffitsch, DTU 2/50

Overview
p1 Multi-/Many-Core Platforms
p2 Networks-on-Chip
p3 Predictability on General-Purpose Platforms
p4 Time-Predictable Computer Architectures
p5 Conclusion
Wolfgang Puffitsch, DTU 3/50

Multi-/Many-Core Platforms
I Everyone wants higher performanceI More functionalityI Fewer computing nodes (costs, weight, . . . )
I Moore’s law gives us more transistors
I Many transistors needed for smallsingle-core performance increase
I More cores promise better trade-offI Higher raw performanceI Higher performance per Watt
Wolfgang Puffitsch, DTU 4/50

Converging ArchitecturesI General-purpose computing
I Chip Multi-Processors (CMPs)I Speed is convenience (best effort)I Identical processors (homogeneous)
I Embedded systemsI Multi-Processor System-on-Chip (MPSoC)I Application-specific systemsI Often heterogeneous (accelerators, DSPs, . . . )I Real-time requirements (soft/hard)
I Converging architecturesI “Cores” communicating via a packet-switched
Network-on-Chip (NoC)
Wolfgang Puffitsch, DTU 5/50

How Many are “Many” Cores?
I No hard line between a “multi”-core and a“many”-core
I 8? 16? 32?
I Burns’ classification (scheduling)
I OneI A few (homogeneous)I Lots (and heterogeneous)I Too many
I Common characteristic of many-coreplatforms: NoC
Wolfgang Puffitsch, DTU 6/50

How Many are “Many” Cores?
I No hard line between a “multi”-core and a“many”-core
I 8? 16? 32?
I Burns’ classification (scheduling)
I OneI A few (homogeneous)I Lots (and heterogeneous)I Too many
I Common characteristic of many-coreplatforms: NoC
Wolfgang Puffitsch, DTU 6/50

How Many are “Many” Cores?
I No hard line between a “multi”-core and a“many”-core
I 8? 16? 32?
I Burns’ classification (scheduling)I One
I A few (homogeneous)I Lots (and heterogeneous)I Too many
I Common characteristic of many-coreplatforms: NoC
Wolfgang Puffitsch, DTU 6/50

How Many are “Many” Cores?
I No hard line between a “multi”-core and a“many”-core
I 8? 16? 32?
I Burns’ classification (scheduling)I OneI A few (homogeneous)
I Lots (and heterogeneous)I Too many
I Common characteristic of many-coreplatforms: NoC
Wolfgang Puffitsch, DTU 6/50

How Many are “Many” Cores?
I No hard line between a “multi”-core and a“many”-core
I 8? 16? 32?
I Burns’ classification (scheduling)I OneI A few (homogeneous)I Lots (and heterogeneous)
I Too many
I Common characteristic of many-coreplatforms: NoC
Wolfgang Puffitsch, DTU 6/50

How Many are “Many” Cores?
I No hard line between a “multi”-core and a“many”-core
I 8? 16? 32?
I Burns’ classification (scheduling)I OneI A few (homogeneous)I Lots (and heterogeneous)I Too many
I Common characteristic of many-coreplatforms: NoC
Wolfgang Puffitsch, DTU 6/50

How Many are “Many” Cores?
I No hard line between a “multi”-core and a“many”-core
I 8? 16? 32?
I Burns’ classification (scheduling)I OneI A few (homogeneous)I Lots (and heterogeneous)I Too many
I Common characteristic of many-coreplatforms: NoC
Wolfgang Puffitsch, DTU 6/50

Example: Intel Xeon PhiMany-core x86 architecture, 2012
Wolfgang Puffitsch, DTU 8/50

Example MPSoC I
Clermidy, F. and Bernard, C. and Lemaire, R. and Martin, J. andMiro-Panades, I. and Thonnart, Y. and Vivet, P. and Wehn, N.A 477mW NoC-based digital baseband for MIMO 4G SDRProc. IEEE International Solid-State Circuits Conferencepp. 278–279, 2012
Wolfgang Puffitsch, DTU 10/50

Example MPSoC II
M. Balsby, Oticon A/SKeynote at NOCS ’12
Wolfgang Puffitsch, DTU 11/50

Overview
p1 Multi-/Many-Core Platforms
p2 Networks-on-Chip
p3 Predictability on General-Purpose Platforms
p4 Time-Predictable Computer Architectures
p5 Conclusion
Wolfgang Puffitsch, DTU 12/50
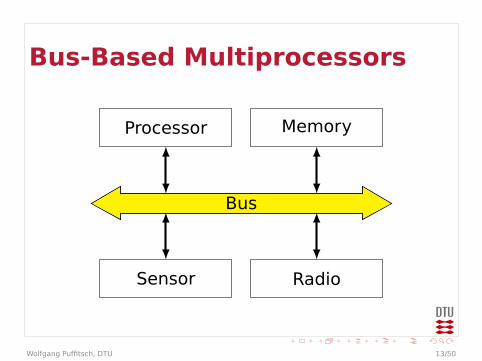
Bus-Based Multiprocessors
Processor Memory
Sensor Radio
Bus
Wolfgang Puffitsch, DTU 13/50

Scaling to Large Systems?
Processor Memory
Sensor Radio
Bus
Wolfgang Puffitsch, DTU 14/50

Scaling to Large Systems?
Processor Memory
Sensor Radio
More Memory
Bus
Wolfgang Puffitsch, DTU 14/50

Scaling to Large Systems?
Processor Memory
Sensor Radio
More Memory
USB Port
Bus
Wolfgang Puffitsch, DTU 14/50

Scaling to Large Systems?
Processor Memory
Sensor Radio
More Memory
USB Port
Graphics Proc
Bus
Wolfgang Puffitsch, DTU 14/50

Scaling to Large Systems?
Processor Memory
Sensor Radio
More Memory
USB Port
Graphics Proc
DSP
Bus
Wolfgang Puffitsch, DTU 14/50

Scaling to Large Systems?
Processor Memory
Sensor Radio
More Memory
USB Port
Graphics Proc
DSP
2nd Processor
Bus
Wolfgang Puffitsch, DTU 14/50

Scaling to Large Systems?
Processor Memory
Sensor Radio
More Memory
USB Port
Graphics Proc
DSP
2nd Processor
. . .
Bus
Wolfgang Puffitsch, DTU 14/50

Scaling to Large Systems?
Processor Memory
Sensor Radio
More Memory
USB Port
Graphics Proc
DSP
2nd Processor
. . .. . .
. . .
Bus
Wolfgang Puffitsch, DTU 14/50

Scaling to Large Systems?
Processor Memory
Sensor Radio
More Memory
USB Port
Graphics Proc
DSP
2nd Processor
. . .. . .
. . .
. . .
. . .
Bus
Wolfgang Puffitsch, DTU 14/50

Scaling to Large Systems?
Processor Memory
Sensor Radio
More Memory
USB Port
Graphics Proc
DSP
2nd Processor
. . .. . .
. . .
. . .
. . .
. . .
. . .
Bus
Wolfgang Puffitsch, DTU 14/50

Scaling to Large Systems?
Processor Memory
Sensor Radio
More Memory
USB Port
Graphics Proc
DSP
2nd Processor
. . .. . .
. . .
. . .
. . .
. . .
. . .
Bus
Hmmm. . .
Wolfgang Puffitsch, DTU 14/50

From Bus to NoC
IP DSP CPU
Mem I/O IP
Bus
Wolfgang Puffitsch, DTU 15/50
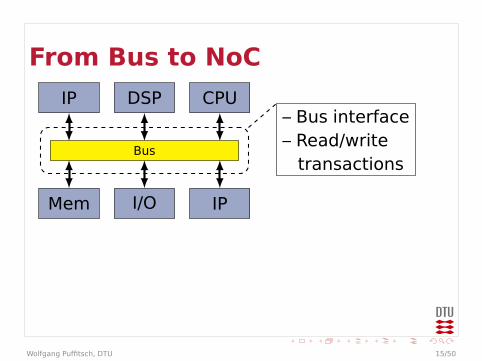
From Bus to NoC
IP DSP CPU
Mem I/O IP
Bus
– Bus interface– Read/write
transactions
Wolfgang Puffitsch, DTU 15/50

From Bus to NoC
IP DSP CPU
Mem I/O IP
Bus
– Bus interface– Read/write
transactions
Wolfgang Puffitsch, DTU 15/50

From Bus to NoC
IP DSP CPU
Mem I/O IP
– Bus interface– Read/write
transactions
Wolfgang Puffitsch, DTU 15/50

From Bus to NoC
IP DSP CPU
Mem I/O IP
– Bus interface– Read/write
transactionsNA
NA
NA
NA
NA
NA
R
R
R
R
R
R
IP IP block
NA network adapter
R router
link
Wolfgang Puffitsch, DTU 15/50

From Bus to NoC
IP DSP CPU
Mem I/O IP
– Packet-switchednetworkNA
NA
NA
NA
NA
NA
R
R
R
R
R
R
IP IP block
NA network adapter
R router
link
Wolfgang Puffitsch, DTU 15/50
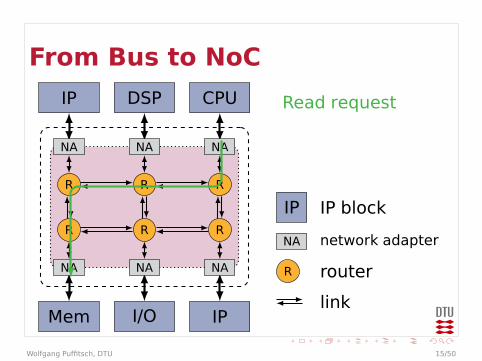
From Bus to NoC
IP DSP CPU
Mem I/O IP
NA
NA
NA
NA
NA
NA
R
R
R
R
R
R
IP IP block
NA network adapter
R router
link
Read request
Wolfgang Puffitsch, DTU 15/50

From Bus to NoC
IP DSP CPU
Mem I/O IP
NA
NA
NA
NA
NA
NA
R
R
R
R
R
R
IP IP block
NA network adapter
R router
link
Read response
Wolfgang Puffitsch, DTU 15/50

Advantages of NoCs
I Scalability
I Wires / technology
I Design methodology: “Lego bricks”
Wolfgang Puffitsch, DTU 16/50

Advantages of NoCs
I Scalability
I Wires / technology
I Design methodology: “Lego bricks”
TileCPU
$ M
NAR
Wolfgang Puffitsch, DTU 16/50

NoC Topology: Mesh
Wolfgang Puffitsch, DTU 17/50

NoC Topology: Bitorus
Wolfgang Puffitsch, DTU 18/50

NoC Topology: Bitorus
Wolfgang Puffitsch, DTU 19/50

NoC Topology: Tree
Wolfgang Puffitsch, DTU 20/50

Overview
p1 Multi-/Many-Core Platforms
p2 Networks-on-Chip
p3 Predictability on General-Purpose Platforms
p4 Time-Predictable Computer Architectures
p5 Conclusion
Wolfgang Puffitsch, DTU 21/50

Arbitration in GP NoC
I Only one packet can use a link at a timeI Similar to bus
I Router decides which packet to transmitI Round-robin, priorities, . . .
I Packets buffered in routers
I Flow control/back pressure to avoid bufferoverflows
Wolfgang Puffitsch, DTU 22/50

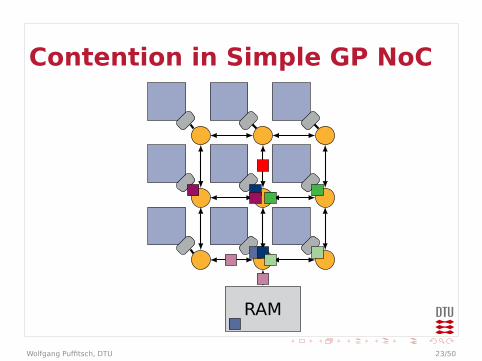
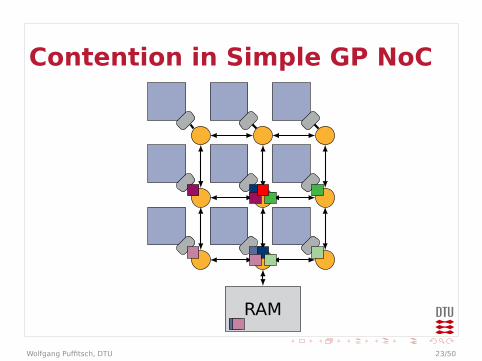
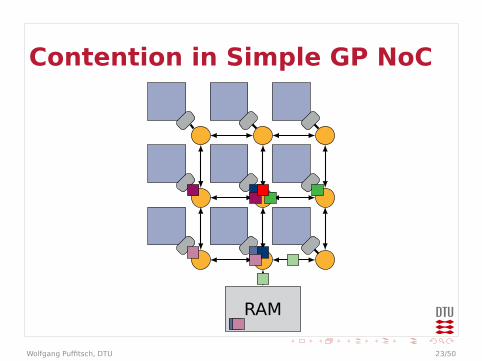
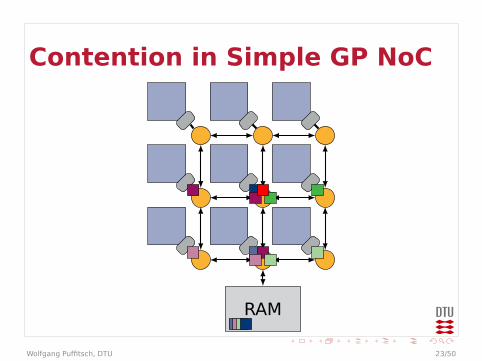
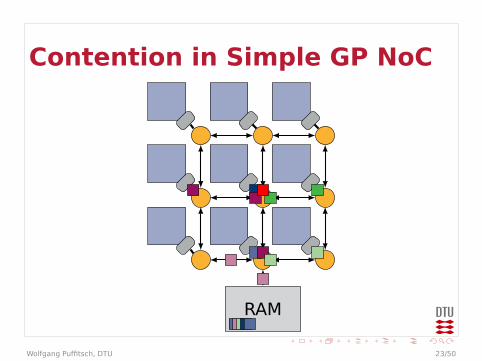
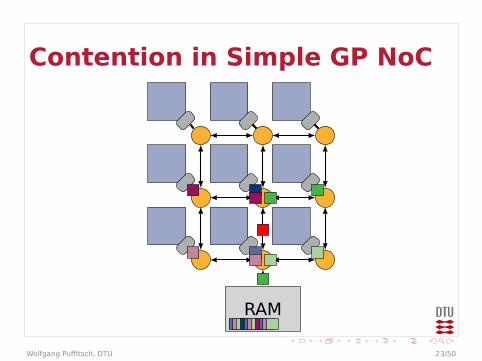
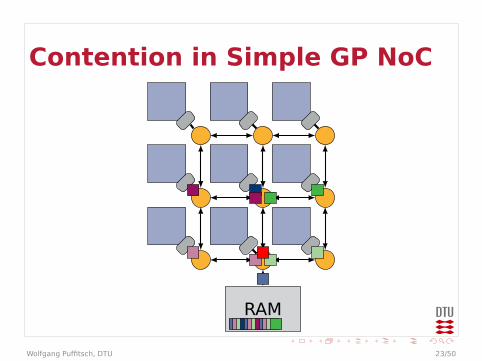
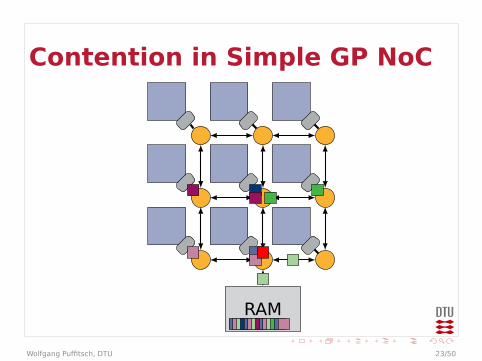
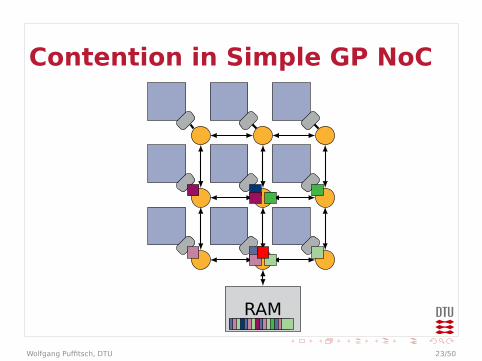
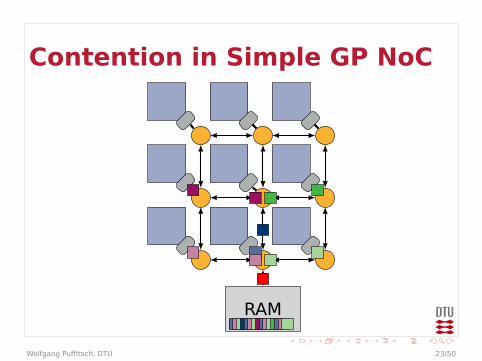
Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50
Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50
Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50
Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50
Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50
Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50
Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50
Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50
Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50
Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50
Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention in Simple GP NoC
RAM
Wolfgang Puffitsch, DTU 23/50

Contention
I Example could be even worseI Arbitration in every router
I Effectively multiple levels of arbitrationsI May behave worse than a bus
I Bandwidth at end-points limitedI Packets may queue up in front of end-point
I Traffic to different end-points may affecteach other
I On-chip communication may be affected bycontention on external memory
Wolfgang Puffitsch, DTU 24/50

Understanding the Platform
I Example assumed simplified model
I No formal models availableI Implementation details not disclosed
I HW vendors may acknowledge flaws andprovide work-arounds, but full disclosuredifficult/impossible
I Stress-testing to evaluate platformI N cores generate noiseI Accessing local or external memoriesI Measure round-trip times (reads from on-chip
memory)
Wolfgang Puffitsch, DTU 25/50
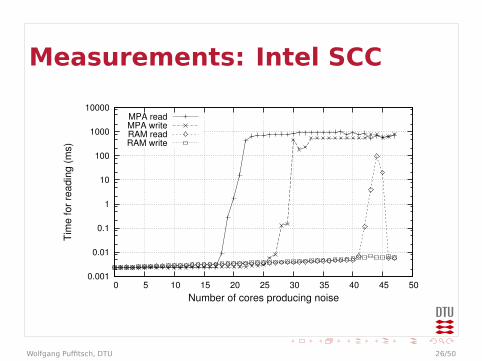
Measurements: Intel SCC
0.001
0.01
0.1
1
10
100
1000
10000
0 5 10 15 20 25 30 35 40 45 50
Tim
e f
or
rea
din
g (
ms)
Number of cores producing noise
MPA readMPA writeRAM readRAM write
Wolfgang Puffitsch, DTU 26/50

Measurements: TILEmpower-Gx36
0.1
1
10
100
1000
10000
100000
0 5 10 15 20 25 30 35
Tim
e f
or
rea
din
g (
us)
Number of cores producing noise
MPA readMPA writeRAM readRAM write
Wolfgang Puffitsch, DTU 27/50

Controlling Contention
I Limiting contention is key to achievepredictable behavior
⇒ Must understand application behaviorI Which tasks are communicating?I How is memory accessed?
I Avoid accesses to external memoryI Timing difficult to predictI On-chip memory less susceptible to
contention
Wolfgang Puffitsch, DTU 28/50

Scheduling
I Task migration causes network trafficI Overhead may be very highI May cause contentionI May interfer with predictability
I Many cores availableI Use more cores instead of loading one coreI In extreme cases one task per core
⇒ Partitioned scheduling a good option
Wolfgang Puffitsch, DTU 29/50

Time Synchronization
I Surprisingly difficult to establish globalnotion of time on COTS platforms
I Core-local clocks driven by same oscillator
I . . . but may have arbitrary offsets⇒ Initial time synchronization needed for
global notion of timeI Synchronization via NoCI Perfect synchronization impossible
Wolfgang Puffitsch, DTU 30/50

Heuristic Mapping [PNP13]
I Application written in multi-ratesynchronous language Prelude
I Periods, deadlines, dependencies,communication patterns
I Communication via on-chip memoryI Heuristic to map application to Intel SCC
I Bounded contentionI Schedulability
I Partitioned scheduling using global ticksI Leave gaps to accomodate clock imprecision
and communication latencies
Wolfgang Puffitsch, DTU 31/50

Mapping Intuition8 cores access same end-point
Wolfgang Puffitsch, DTU 32/50

Mapping Intuition6 cores access same end-point
Wolfgang Puffitsch, DTU 32/50

Mapping Intuition3 cores access same end-point
Wolfgang Puffitsch, DTU 32/50

Constraint Solving [PNP15]
I Evaluation of Intel SCC, TI TMS320C6678,Tilera TILEmpower-Gx36
I Execution model that fits these platformsI Partitioned off-line schedulingI Data and code in local memoriesI Communication via message-passingI Pre-computed communication delays
I Constraint solving for mappingI Bounded contentionI Off-line scheduleI Scales to hundreds of tasks
Wolfgang Puffitsch, DTU 33/50

Time-Triggered Execution
I Split tasks into communication andexecution phases
I Schedule communication to avoid/reduceconflicts on shared resources
I Eliminate/limit contention
I Strict model advocated by Kopetz
I Requires tight timing synchronization
I Analysis of extended (relaxed) model:[SPC+11]
Wolfgang Puffitsch, DTU 34/50

Memguard [YYP+13]
I Split available memory bandwidthbetween tasks
I Every task assigned a memory budgetI Use bandwidth that can be guaranteed
I Task stalled when exceeding the budget
I Replenish budget periodically
I No more requests than bandwidthavailable ⇒ limit contention
I Best-effort use of remaining bandwidth
Wolfgang Puffitsch, DTU 35/50

Optimistic Execution [KRF+14]
I Mixed-criticality systemI Critical tasks and non-critical tasks
I Determine WCET in isolation and undercontention
I Monitor progress of critical tasksI Stall non-critical tasks when in danger of
missing deadlineI Switch to mode with limited contention
Wolfgang Puffitsch, DTU 36/50

Overview
p1 Multi-/Many-Core Platforms
p2 Networks-on-Chip
p3 Predictability on General-Purpose Platforms
p4 Time-Predictable Computer Architectures
p5 Conclusion
Wolfgang Puffitsch, DTU 37/50

Time-Predictable ArchitecturesI In hard real-time systems, the worst case
is what countsI General-purpose architectures designed
for average caseI Speed is a convenienceI Caches, branch predictionI Poor worst-case behavior
I Time-predictable architecturesI Optimize worst-case behaviorI Guaranteed performanceI May sacrifice average-case performanceI Enable worst-case execution time analysis
Wolfgang Puffitsch, DTU 38/50
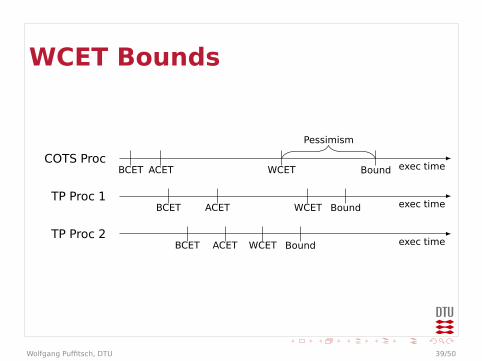
WCET Bounds
COTS Proc
TP Proc 1
TP Proc 2
exec time
exec time
exec time
BCET ACET WCET Bound
Pessimism
BCET ACET WCET Bound
BCET ACET WCET Bound
Wolfgang Puffitsch, DTU 39/50

Kalray MPPA
I www.kalray.eu
I MPPA-256: 16 clusters with 16 cores eachI Designed to be timing composable
I No weird timing effects, can combinesub-analyses
I Trade off between predictability andaverage-case performance
I Limit data rates of network interfacesI Network calculus to compute latency/rate
Wolfgang Puffitsch, DTU 40/50

Network Calculus
I Initially developed for off-chip networks
I Arriving traffic described by arrival curve
I Outgoing traffic described bydeparture/service curve
I Math. . .
I Backlog in routers (buffer sizes)
I Delay in routers
Wolfgang Puffitsch, DTU 41/50
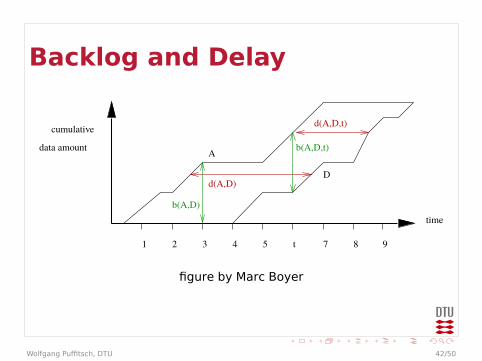
Backlog and Delay
1 32 4 5 7 8 9
cumulative
time
data amount
b(A,D)
d(A,D)
A
d(A,D,t)
b(A,D,t)
D
t
figure by Marc Boyer
Wolfgang Puffitsch, DTU 42/50

T-CREST Platform [SAA+15]
I Many-core platform withtime-predictability as design goal
I Time-predictable processor coresI Separate NoCs for memory and on-chip
communicationI Memory: many-to-one ⇒ treeI On-chip: many-to-many ⇒ bitorus, mesh, . . .I Time-division multiplexing
I Predictable memory controllerI Open source: http://patmos.compute.dtu.dk
Wolfgang Puffitsch, DTU 43/50

T-CREST Overview
T-CREST Chip
Patmos
DecM$ +
SPM
S/D$
NI
Patmos
DecM$ +
SPM
S/D$
NI
R
Patmos
DecM$ +
SPM
S/D$
NI
R
MemoryTree
MemoryController
SDRAMMemory
R
Wolfgang Puffitsch, DTU 44/50

Time-Division Multiplexing
I Static network scheduleI Time at which packet may use link
predeterminedI Slots always reserved, may be unusedI Guaranteed bandwidth, but does not adapt
dynamically
I No buffering, no flow controlI Significantly cheaper routers
I Only wait for slot, free flow in NoC
Wolfgang Puffitsch, DTU 45/50

Argo NoC
I Message passing instead of sharedaddress space
I DMA transfers instead of bus interfaceI Communication is explicit
I Communication via SPMsI Reads and writes to local SPMI Only writes to remote SPM (“push”) via DMA
I Integration of DMA controller and TDMschedule
I Small, efficient hardware
I Is explicit communication the future?
Wolfgang Puffitsch, DTU 46/50

Argo NoC
I Message passing instead of sharedaddress space
I DMA transfers instead of bus interfaceI Communication is explicit
I Communication via SPMsI Reads and writes to local SPMI Only writes to remote SPM (“push”) via DMA
I Integration of DMA controller and TDMschedule
I Small, efficient hardware
I Is explicit communication the future?
Wolfgang Puffitsch, DTU 46/50

Overview
p1 Multi-/Many-Core Platforms
p2 Networks-on-Chip
p3 Predictability on General-Purpose Platforms
p4 Time-Predictable Computer Architectures
p5 Conclusion
Wolfgang Puffitsch, DTU 47/50

Conclusions
I Many cores are the way to go
I NoCs provide scalability
I Contention may severely affect timingI Limiting contention is key to achieve
predictabilityI Mapping, time-triggered, budgets
I Time-predictable architecturesI Kalray MPPA, T-CREST platform
Wolfgang Puffitsch, DTU 48/50

References I
Angeliki Kritikakou, Christine Rochange, Madeleine Faugère, Claire Pagetti, Matthieu Roy, Sylvain Girbal,
and Daniel Gracia Pérez.Distributed run-time WCET controller for concurrent critical tasks in mixed-critical systems.In Proceedings of the 22nd International Conference on Real-Time Networks and Systems, page 139.ACM, 2014.
Wolfgang Puffitsch, Eric Noulard, and Claire Pagetti.
Mapping a multi-rate synchronous language to a many-core processor.In Proceedings of the 19th Real-Time and Embedded Technology and Applications Symposium, RTAS ’13,pages 293–302. IEEE, 2013.
Wolfgang Puffitsch, Eric Noulard, and Claire Pagetti.
Off-line mapping of multi-rate dependent task sets to many-core platforms.Real-Time Systems, 2015.accepted for publication.
Martin Schoeberl, Sahar Abbaspour, Benny Akesson, Neil Audsley, Raffaele Capasso, Jamie Garside, Kees
Goossens, Sven Goossens, Scott Hansen, Reinhold Heckmann, Stefan Hepp, Benedikt Huber, AlexanderJordan, Evangelia Kasapaki, Jens Knoop, Yonghui Li, Daniel Prokesch, Wolfgang Puffitsch, Peter Puschner,André Rocha, Cláudio Silva, Jens Sparsø, and Alessandro Tocchi.T-CREST: Time-predictable multi-core architecture for embedded systems.Journal of Systems Architecture, 0(0):–, 2015.published online, to appear in print.
Wolfgang Puffitsch, DTU 49/50

References II
Andreas Schranzhofer, Rodolfo Pellizzoni, Jian-Jia Chen, Lothar Thiele, and Marco Caccamo.
Timing analysis for resource access interference on adaptive resource arbiters.In Proceedings of the 17th Real-Time and Embedded Technology and Applications Symposium, RTAS ’11,pages 213–222. IEEE, 2011.
Heechul Yun, Gang Yao, Rodolfo Pellizzoni, Marco Caccamo, and Lui Sha.
Memguard: Memory bandwidth reservation system for efficient performance isolation in multi-coreplatforms.In Proceedings of the 19th Real-Time and Embedded Technology and Applications Symposium, RTAS ’13,pages 55–64. IEEE, 2013.
Wolfgang Puffitsch, DTU 50/50































