Embed Size (px)
Citation preview

The Social Web or how flickr changed my life
Kristina LermanUSC Information Sciences
Institutehttp://www.isi.edu/~lerman

2
Web 1.0

3
Web 2.0

4
Elements of Social Web
Users contribute content • Images (Flickr, Zoomr), news stories (Digg, Reddit), bookmarks
(Delicious, Bibsonomy), videos (YouTube, Vimeo), …
Users add metadata to content• Tags: annotate content with freely chosen keywords• Discussion: leave comments• Evaluation: active through voting or passive through views
& favorites
Users create social networks• Add other users as friends/contacts• Sites provide an easy interface to track friends’ activities
Transparency• Publicly navigable content and metadata

5
Flickr
tags
submitter
discussion
image stats

6
User profile

7
User’s tags
Tags are keyword-based metadata added to content • Help users
organize their own data
• Facilitate searching and browsing for information
• Freely chosen by user
8
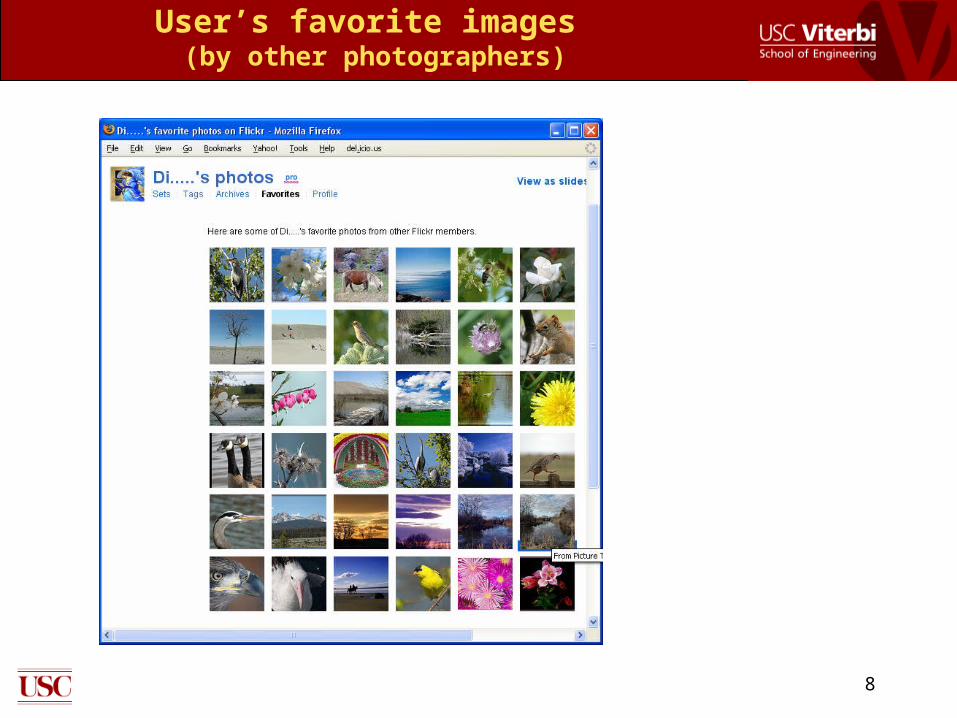
User’s favorite images (by other photographers)

9
So what?
By exposing human activity, Social Web allows users to exploit the intelligence and opinions of others to solve problems• New way of interacting with information
− Social Information Processing
• Exploit collective effects− Word of mouth to amplify good information
• Amenable to analysis− Design optimal social information processing systems
Challenge for AI: harness the power of collective intelligence to solve information processing problems

10
Outline for the rest of the talk
User-contributed metadata can be used to solve following information processing problems
DiscoveryCollectively added tags used for information discovery
PersonalizationUser-added metadata, in the form of tags and social networks,
used to personalize search results
Recommendation Social networks for information filtering
Dynamics of collaborationMathematical study of collaborative rating system

Discoverypersonalizationrecommendationdynamics of collaboration
with: Anon Plangrasopchok

12
Information discovery
Goal: Automatically find resources that provide some functionality• weather conditions, flight tracking, geocoding, …
Simpler goal: Find resources that provide the same functionality as the seed, e.g., http://flytecomm.com• Improve robustness of information integration applications• Increase coverage of the applications
Approach: Leverage user-contributed tags to discover new resources similar to the seed

13
Anatomy of Delicious
resource
popular tags
user
tags
user notes

14
Probabilistic approach
Find a compressed description of the source• Extract “latent topics” in a collection of sources, using
Probabilistic Generative Model
Compute pair-wise similarity between the seed and a source using compressed description
Users Tags
Sources
Probabilistic Model
Compute Source Similarity
Compressed description
Similar sources(sorted)

15
Alternative models
U
I
Nt
D
Z
R
TNt
D
Z
R
T
U
Nb
Z
R
T
ITM pLSA MWA
[Plangrasopchok & Lerman, in IIWeb’07]
[Hoffman, in UAI’99] [Wu+, in WWW’06]

16
Datasets
Seed resources: flytecomm, geocoder, wunderground• For each seed, retrieve the 20 popular tags • For each tag, retrieve other resources annotated with same tag• For each resource, retrieve all resource-user-tag triples
flytecomm geocoder wunderground
Resources
3,562 5,572 7,176
Tags 14,297 16,887 77,056
Users 34,594 46,764 45,852

17
Experimental results
# of sources with similar functionality to the seed found• pLSA – ignores users• MWA – naïve Bayes• ITM – our model (user
interests and source topics)• Google – ‘find similar pages’
Sources retrieved by seed Flytecomm
0
5
10
15
20
25
0 10 20 30 40 50 60 70 80 90 100
# All Retrieved Sources
# P
ositi
ve R
etrie
ved
Sou
rces
pLSA
MWA
ITM
Sources retrieved by seed Geocoder
0
5
10
15
20
25
0 10 20 30 40 50 60 70 80 90 100
# All Retrieved Sources
# P
ositi
ve R
etrie
ved
Sou
rces
pLSA
MWA
ITM
Sources retrieved by seed Wunderground
0
15
30
45
60
75
0 10 20 30 40 50 60 70 80 90 100
# All Retrieved Sources
# Po
sitiv
e R
etrie
ved
Sour
ces
pLSA
MWA
ITM
Plangrasopchok & Lerman, “Exploiting Social Annotation for Resource Discovery” in AAAI IIWeb workshop, 2007

18
Summary and future work
Exploit tagging activities of different users to find data sources similar to the seed
Future work• Extend the probabilistic model to learn topic hierarchies
(aka folksonomies)− Travel
• Flights» Booking» Status
• Hotels» Booking» Reviews
• Car rentals• Destinations

discovery
Personalizationrecommendationdynamics of collaboration
with: Anon Plangrasopchok & Michael Wong

20
Image search on Flickr
Tag search finds all images tagged with a given keyword… It is prone to ambiguity
Beetle• Insect• Car model
Tiger• Panthera tigris• House cat• Shark (tiger shark)• Mac OS X• Flower (tiger lily)
Newborn• Baby• Kitten• Puppy • Etc…

21
Plain tag search
Query Sense Relevant
Precision
newborn baby 412 0.82
tiger Panthera tigris 337 0.67
beetle insect 232 0.46
Relevance results for top 500 images retrieved by tag search Relevance results for top 500 images retrieved by tag search (manually labeled using the first sense of each keyword)

22
Personalizing search results
Users express their tastes and preferences through the metadata they create• Contacts they add to their social networks• Tags they add to their own images• Images they mark as their favorite• Groups they join
Use this metadata to improve image search results!• Personalizing by tags• Personalizing by contacts
− Restrict results of image search to those images that were submitted by user u ‘s friends (Level 1 contacts)Level 1 contacts)

23
# L1+L2 Pr Re
49,539 0.85 0.85
10,970 0.90 0.77
13,153 0.89 0.79
8,439 0.91 0.75
13,142 0.78 0.76
14,425 0.76 0.79
7,270 0.79 0.67
7,073 0.79 0.71
53,480 0.49 0.93
41,568 0.49 0.90
62,610 0.49 0.94
14,324 0.52 0.70
Personalizing by contacts results
User #L 1
rel.
Not rel.
Pr Re
newborn
user1 719 232
0 1.00
0.56
user2 154 169
0 1.00
0.41
user3 174 147
0 1.00
0.36
user4 128 132
0 1.00
0.32
tiger
user5 63 11 1 0.92
0.03
user6 103 78 3 0.96
0.23
user7 62 65 1 0.98
0.19
user8 56 30 0 0.97
0.09
beetle
user9 445 18 1 0.95
0.08
user10
364 25 8 0.81
0.15
user11
783 78 25 0.75
0.34
user12
102 7 1 0.88
0.03
L1+L2: 9%-16% average improvement in precision

24
Personalizing by tags
Users often add descriptive metadata to images• Tags • Titles• Image descriptions• Add image to groups
Personalizing by tags• Find (hidden) topics of interest to the user• Find images in the search results related to these topics

25
Probabilistic topic model
Tagging as a stochastic process• User u posts an image i• Based on u’s interests, topics z are chosen• Tag t is selected based on z
Probabilistic topic model
Use EM to estimate p(t|z) and p(z|u) from data• To find topics in each search set of 4500 images
U
Z
TNt
I)(
)|()|()(),(tn
kki
kikiii
i
ztpuzpupTup

26
p(t|z)
Topic 1 Topic 2 Topic 5 Topic 8 Topic 10tiger tiger tiger tiger tigerzoo specanimal cat apple lion
animal animalkingdomelite kitty mac dognature abigfave cute osx shark
animals flower kitten macintosh nycwild butterfly cats screenshot cattijger macro orange macosx man
wildlife yellow eyes desktop peopleilovenature swallowtail pet imac arizona
cub lily tabby stevejobs rocksiberiantiger green stripes dashboard beach
blijdorp canon whiskers macbook sandlondon insect white powerbook sleeping
australia nature art os treeportfolio pink feline 104 forest
““tiger” image set: 4500 images trained on 10 topicstiger” image set: 4500 images trained on 10 topics
27
Personalizing by tags: Results
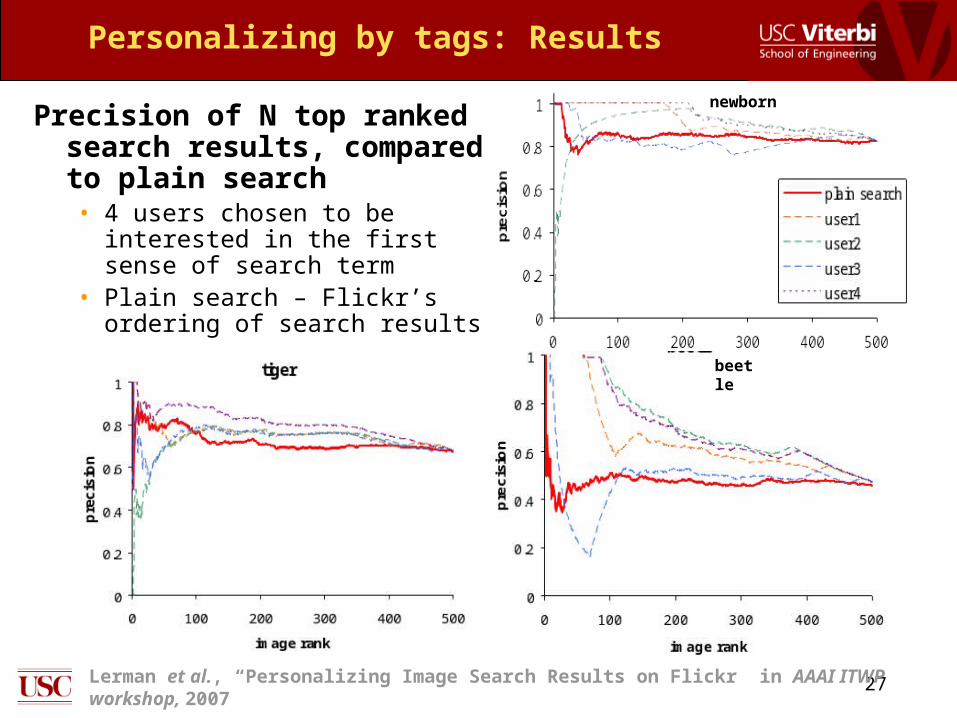
Precision of N top ranked search results, compared to plain search • 4 users chosen to be interested
in the first sense of search term• Plain search – Flickr’s ordering
of search results
Lerman et al., “Personalizing Image Search Results on Flickr” in AAAI ITWP workshop, 2007
newborn
beetle

28
Summary & future work
Improve results of image search for an individual user as long as the user has expressed interest in the topic of search
Future work• Lots of other metadata to exploit
− Favorites, groups, image titles and descriptions
• Discover relevant synonyms to expand search• Topics that are new to the user?
− Exploit collective knowledge to find communities of interest− Identify authorities within those communities

discoverypersonalization
Recommendationdynamics of collaboration
with: Dipsy Kapoor

30
Social News Aggregation on Digg
Users submit stories Users vote on (digg)
stories• Select stories promoted to
the front page based on received votes
• Collaborative front page emerges from the opinions of many users, not few editors
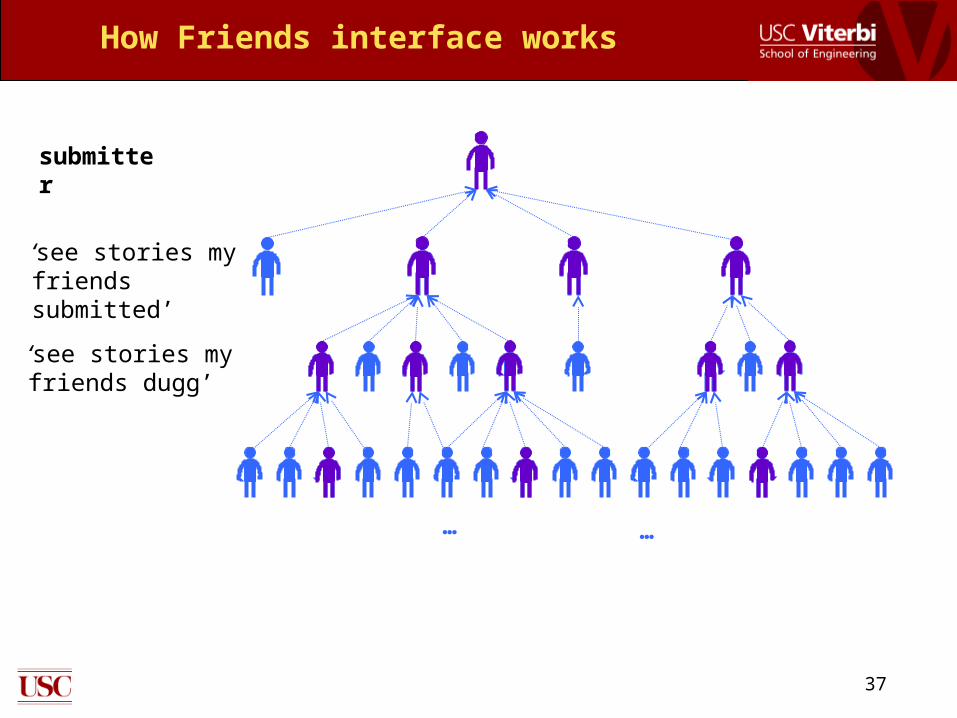
Users create social social networksnetworks by adding others as friends• Friends Interface makes it
easy to track friends’ activities− Stories friends submitted− Stories friends dugg (voted
on)

31
Top users
Digg ranks users Based on how many of their stories were promoted to front
page− User with most stories is ranked #1, …
Top 1000 users dataCollected by scraping Digg … now available through the API• Usage statistics
− User rank− How many stories user submitted, dugg, commented on
• Social networks− Friends: outgoing links
A B := B is a friend of A
− Reverse friends: incoming linksA B := A is a reverse friend of B

32
Digg datasets
To see how votes change in time• Tracked 2858 stories submitted over a period > day in May
2006• Only 98 stories were promoted to the front page
To see how users vote on stories• For ~200 front page stories
− Names of users who voted on (dugg) the story

33
Dynamics of votes
0
500
1000
1500
2000
2500
0 1000 2000 3000 4000 5000
time (min)
nu
mb
er
of
vo
tes
(d
igg
s)
Top users’ stories

34
`Interestingness’ distribution
0
500
1000
1500
2000
2500
1 10 100 1000
user rank
ma
xim
um
vo
tes
Top users are not submitting the most “interesting” stories
50 stories from 14 usersave. max votes=600
48 stories from 45 usersave. max votes=1050

35
Social filtering as recommendation
Social filtering explains why top users are so successful
Users express their preferences by creating social networks
Use these networks – through the Friends Interface – to find new stories to read• Claim 1: Users digg stories their friends submit• Claim 2: Users digg stories their friends digg

36
Social network on Digg
1
10
100
1,000
10,000
100,000
1 10 100 1,000
number friends+1
nu
mb
er
rev
ers
e f
rie
nd
s+
1
Top 1000 Digg usersTop 1000 Digg users
37
How Friends interface works
submitter
‘see stories myfriends submitted’
… …
‘see stories myfriends dugg’
38
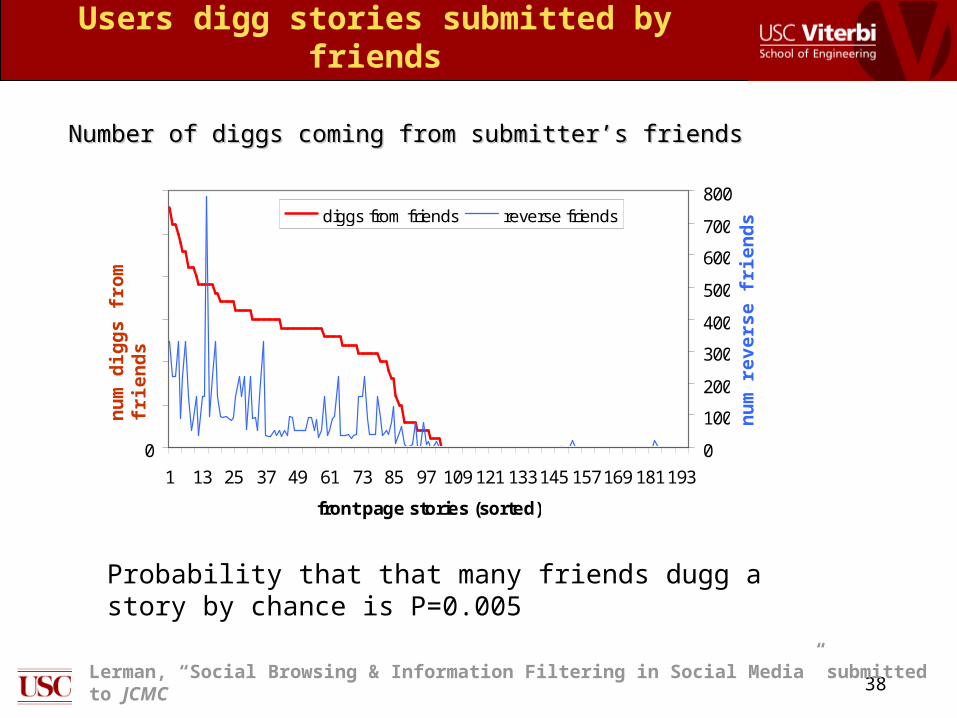
Users digg stories submitted by friends
0
5
10
15
20
25
30
1 13 25 37 49 61 73 85 97 109 121 133145 157169 181193
front page stories (sorted)
nu
m d
igg
s fr
om
fri
end
s
0
100
200
300
400
500
600
700
800
nu
m r
ever
se f
rien
ds
diggs from friends reverse friends
Number of diggs coming from submitter’s friendsNumber of diggs coming from submitter’s friends
Probability that that many friends dugg a story by chance is P=0.005
nu
m r
ever
se f
rien
ds
nu
m d
igg
s fr
om
fri
end
s
Lerman, “Social Browsing & Information Filtering in Social Media” submitted to JCMC

40
`Tyranny of the minority’
Top users submit lion’s share of front page stories Explained by social filtering
• Top users have bigger, more active social networks Conspiracy: alternative explanation of top user success
• Top users accused of colluding to automatically promote each other’s stories
• Resulting uproar led Digg to change its story promotion algorithm …
− To discount votes coming from friends− Led to greater front page diversity, but also unintended
consequences

42
Design of collaborative rating systems
Designing a collaborative rating system, which exploits the emergent behavior of many independent evaluators, is difficult• Small changes can have big consequences• Few tools to predict system behavior
− Execution− Simulation
Can we explore the effects of promotion algorithms before before they are implemented?

discoverypersonalizationrecommendation
Dynamics of collaboration
with: Dipsy Kapoor

44
Analysis as a design tool
Mathematical analysis can help understandunderstand and predictpredict the emergent behavior of collaborative information systems• Study the choice of the promotion algorithm before it is
implemented• Effect of design choices on system behavior
− story timeliness, interestingness, user participation, incentives to join social networks, etc.

45
Dynamics of collaborative rating
Story is characterized by Interestingness r
• probability a story will received a vote when seen by a user
Visibility • Visibility on the upcoming stories page
− Decreases with time as new stories are submitted
• Visibility on the front page− Decreases with time as new stories are promoted
• Visibility through the friends interface − Stories friends submitted− Stories friends dugg (voted on)

46
Mathematical model
Mathematical model describes how the number of votes m(t) changes in time
Solve equation• Solutions parametrized by S, r• Other parameters estimated from data
tvvvrtm iuf )()(

47
Dynamics of votes
data model
Lerman, “Social Information Processing in Social News Aggregation” Internet Computing (in press) 2007
48
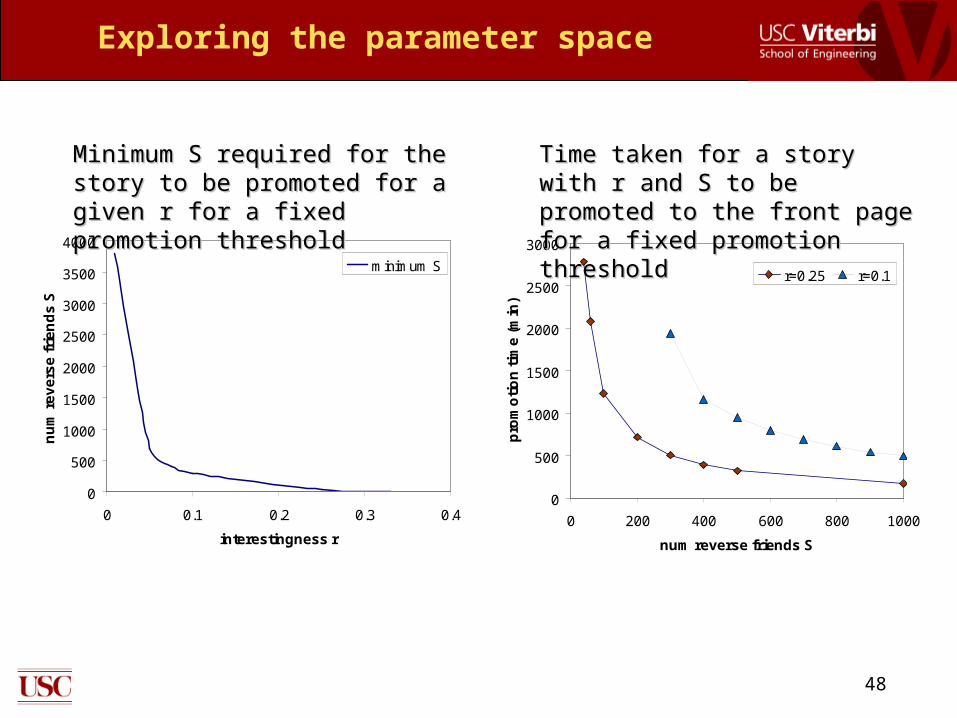
Exploring the parameter space
0
500
1000
1500
2000
2500
3000
0 200 400 600 800 1000
num reverse friends S
pro
mo
tio
n t
ime
(m
in)
r=0.25 r=0.1
0
500
1000
1500
2000
2500
3000
3500
4000
0 0.1 0.2 0.3 0.4
interestingness r
nu
m r
ev
ers
e f
rie
nd
s S
minimum S
Minimum S required for the story to Minimum S required for the story to be promoted for a given r for a fixed be promoted for a given r for a fixed promotion thresholdpromotion threshold
Time taken for a story with r and S Time taken for a story with r and S to be promoted to the front page for to be promoted to the front page for a fixed promotion thresholda fixed promotion threshold

49
Dynamics of user influence
Digg ranked users according to how many front page stories they had
Model of the dynamics of user influence• Number of stories promoted
to the front page F• User’s social network growth S
user1 user2 user3user4 user5 user6

50
Model of rank dynamics
Number of stories promoted to the front page F • Number of stories M submitted over t=week• User’s promotion success rate S(t)
User’s social network S grows as• Others discover him through new front page stories ~F
• Others discover him through the Top Users list ~g(F)
Solve equations• Estimate b, c, g(F) from data
tMtcStF )()(
tFgtFbtS )()()(

51
dirtyfratboy model
0
200
400
600
800
1000
1200
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
dirtyfratboy data
0
200
400
600
800
1000
1200
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
digitalgopher model
0
300
600
900
1200
1500
1800
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
digitalgopher data
0
300
600
900
1200
1500
1800
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
Solutions 1
user2 data
user6 data
user2 model
user6 model
Lerman, “Dynamics of Collaborative Rating of Information” in KDD/SNA workshop, 2007

52
aaaz model
0
200
400
600
800
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
aaaz data
0
200
400
600
800
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
3monkeys model
0
100
200
300
400
500
600
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
3monkeys data
0
100
200
300
400
500
600
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
Solutions 2
user1 data
user5 data
user1 model
user5 model
Lerman, “Dynamics of Collaborative Rating of Information” in KDD/SNA workshop, 2007

53
MrCalifornia model
0
20
40
60
80
100
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
MrCalifornia data
0
20
40
60
80
100
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
felchdonkey model
0
20
40
60
80
100
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
felchdonkey data
0
20
40
60
80
100
0 5 10 15 20 25 30 35
week
nu
mb
er
F
S
Solutions 3
user3 data
user4 data
user3 model
user4 model
Lerman, “Dynamics of Collaborative Rating of Information” in KDD/SNA workshop, 2007

54
Previous works
Technologies that exploit independent activities of many users for information discovery and recommendation
Collaborative filtering [e.g., Grouplens project 1997-present]
• Users express opinions by rating many products• System finds users with similar opinions and recommends
products liked by those users• Product recommendation used by Amazon & Netflix
− Users reluctant to rate products
Social navigation [Dieberger et al, 2000]
• Exposes activity of others to help guide users to quality information sources
− “N users found X helpful”− best seller lists, “what’s popular” pages, etc.

55
Conclusions
In their every day use of Social Web sites, users create large quantity of data, which express their knowledge and opinions• Content
− Articles, media content, opinion pieces, etc.
• Metadata− Tags, ratings, discussion, social networks
• Links between users, content, and metadata
Social Web enables new problem solving approaches• Social Information Processing
− Use knowledge, opinions, work of others for own information needs
• Collective problem solving− Efficient, robust solutions beyond the scope of individual
capabilities

56
Upcoming events
Social Information Processing Symposium • When: March 2008• Where: AAAI Spring Symposium series @ Stanford• Organizers: K. Lerman, B. Huberman (HP Labs), D. Gutelius
(SRI), S. Merugu (Yahoo)• http://www.isi.edu/~lerman/sss07/

57
The future of the Social Web 2
Instead of connecting datadata, the Web connects peoplepeople
New applications• Collaboration tools
− Collective intelligence: Collective intelligence: A large group of connected individuals acts more intelligently than individuals on their own
• The personalization of everything− The more the system learns about me, the better it should filter
• Discovery, not search− What papers do I need to read to know about the research on
social networks?
• Identifying emerging communities − Community-based vocabulary− Authoritative sources within the community

58
The future of the Social Web
New challenge for AI: Instead of ever cleverer algorithmsalgorithms, harness the Collective IntelligenceCollective Intelligence
Semantic Web vision [Berners-Lee & Hendler in Scientific American, 2001]
• Web content annotated with machine-readable metadata (a formal classification system) to aid automatic information integration
• Still unrealized in 2007− Too complicated: specialized training to be used effectively− Costly and time-consuming to produce− Variety of specialized ontologies: ontology alignment problem
Folksonomy• “user generated taxonomy used to categorize and retrieve
web content using open-ended labels called tags.” [source: Wikipedia]
− Bottom-up: decentralized, emergent, scalable− Dynamic: adapts to changing needs and priorities− Noisy: need tools to extract meaning from data




![KRISTINA LERMAN, arXiv:1808.03281v1 [cs.SI] 9 …Who Falls for Online Political Manipulation? The case of the Russian Interference Campaign in the 2016 US Presidential Election ADAM](https://img.dokumen.tips/doc/110x75/5e8ba1f27723dd0d0d7d3455/kristina-lerman-arxiv180803281v1-cssi-9-who-falls-for-online-political-manipulation.jpg)
























