Embed Size (px)
Citation preview

The National ArchivesDigital Records Infrastructure Catalogue
First Steps to Creating a Semantic Digital Archive
Rob Walpole
DeveXe LimitedThe National Archives

Disclaimer
This presentation is in no way intended to express views or opinions of The National Archives and is solely the work of Rob Walpole, an employee of DeveXe Limited who are currently contracted to assist in the development of the Digital Records Infrastructure at Kew in London.
Apart from providing a case study of developing a semantic digital archive, this presentation discusses the opportunities permitted by such development. It should not be assumed that these developments will occur and DeveXe Limited take no responsibility for any perceived inaccuracies.

Background

Background – The National Archives
The National Archives (TNA) Over 11 million historical
government and public records
From the Domesday Book to the Agreement on a Referendum on Independence for Scotland
Photo by Chris Hill

Background – The National Archives
The National Archives (TNA) Over 11 million historical
government and public records
From the Domesday Book to the Agreement on a Referendum on Independence for Scotland
But not births, deaths and marriages, these are held by the General Register Office!
Photo by Chris Hill

Background – The National Archives
Most of these documents are currently held on paper - or even parchment...
Photo by Liz West

Background – The National Archives
But soon this will be overtaken by a tsunami of digital files...
Photo by Marco Mazzei

Background – The National Archives
But soon this will be overtaken by a tsunami of digital files...
...including office documents, emails, images, videos and much more.
Photo by Marco Mazzei

Background – Digital Records Infrastructure
There are many challenges around digital preservation including:-
Format recognition Software preservation Compatibility Degradation of media

Background – Digital Records Infrastructure
There are many challenges around digital preservation including:-
Format recognition Software preservation Compatibility Degradation of media
Many of these issues werehighlighted by the BBCDomesday Project (1986)

Background – Digital Records Infrastructure
TNA have been at the forefront of meeting this digital preservation challenge:-PRONOM – file format registryDROID – file format identification toolLegislation.gov.uk – all UK legislation on-lineUK Government Web Archive –http://www.nationalarchives.gov.uk/webarchive/The London Gazette – published by HMSO (part of TNA)

Background – Digital Records Infrastructure
In 2006 TNA deployed the Digital Repository System (DRS) which provided terabyte scale long-term storage.
In 2012 TNA starts to build DRI (Digital Records Infrastructure) on the foundations of DRS to deliver extensible storage to the petabyte scale and beyond.

80,000 Digitised Home Guard Records from World War 2 were ingested into DRI as a proof of concept...
Background – Digital Records Infrastructure

Background – Digital Records Infrastructure
80,000 Digitised Home Guard Records from World War 2 were ingested into DRI as a proof of concept...
...now many more including LOCOG (2012 Olympic
games) Leveson Enquiry

Background – Digital Records Infrastructure
At its core this massive storage is provided by a robot tape library with frequently requested and low resolution copies of data held in a disk cache.
Photo by Cory Doctrow

Background – The DRI Catalogue
The DRI Catalogue is essentially an inventory of the items held in the archive.
It is distinct from the TNA Catalogue which is a comprehensive catalogue system covering both paper and digital documents. Public access to the TNA Catalogue is provided by Discovery.

Background – The DRI Catalogue
Rich XML metadata is stored in the archive itself, alongside the original document and a copy is sent to Discovery. This comes from a variety of sources:
Record providerArchiving processDocument transcriptionArchivists
And there is a very good reason for using XML...

Background – The DRI Catalogue
Rich XML metadata is stored in the archive itself, alongside the original document and a copy is sent to Discovery. This comes from a variety of sources:
Record providerArchiving processDocument transcriptionArchivists
And there is a very good reason for using XML......it's human readable!

Requirements

Requirements – The DRI Catalogue
Apart from being an inventory, the DRI Catalogue is needed to help manage:-
Closure information Record opening Export lists Export status
Requirements - Closure
Closure can be very fine-grained.e.g. Home Guard records have open description (individual's
name, battalion etc.) butService record closed until individual deceasedMedical record closed until record = 100 years old
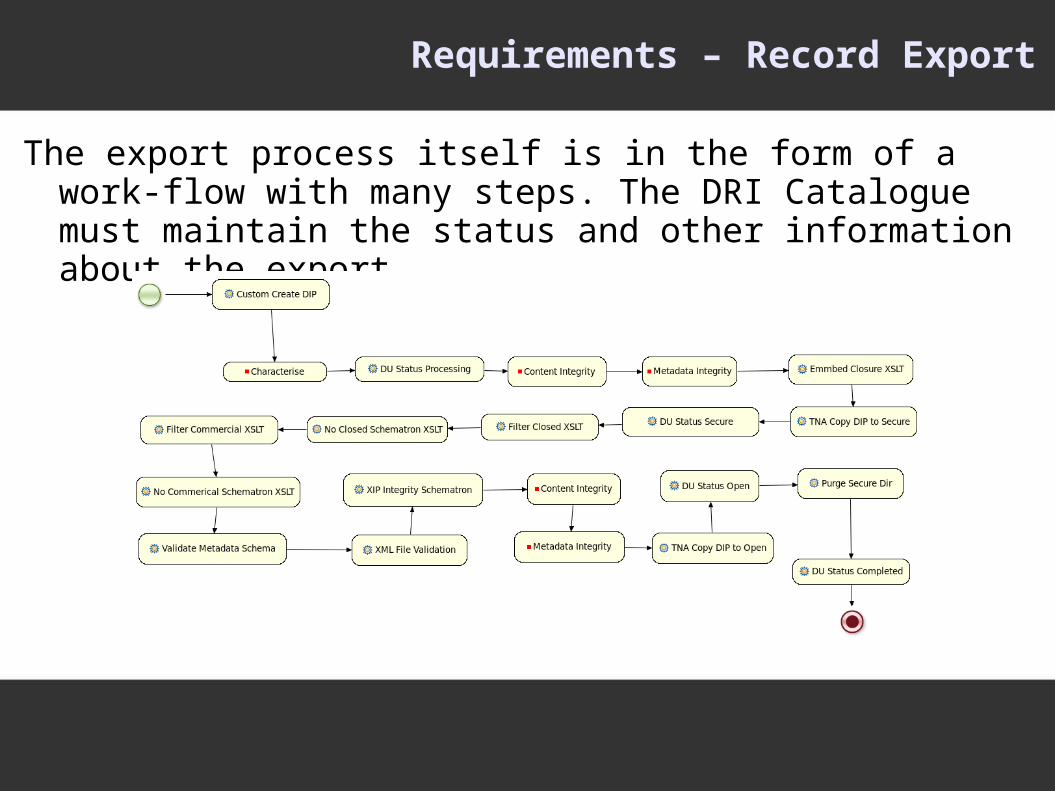
Requirements – Record Export
The export process itself is in the form of a work-flow with many steps. The DRI Catalogue must maintain the status and other information about the export...

Requirements – The Problem
Initially the DRI Catalogue was held in an RDBMS. However the fine-grained nature of closure meant very slow queries when attempting to export large numbers of records – sometimes taking hours to complete!
Another approach was needed...!

Requirements – Initial Analysis
Three different proposals were made for modelling the catalogue and therefore a trial was conducted to establish the best approach. Three models trialled were:-
Relational – optimising the existing SQL queries against a modified table structureGraph – running SPARQL queries against a RDF storeHierarchical – running XQuery against a XML database
Requirements – Analysis Results
Relational – reduced query time from hours to minutes 😌

Requirements – Analysis Results
Relational – reduced query time from hours to minutes 😌
Graph – reduced query time to seconds 😎

Requirements – Analysis Results
Relational – reduced query time from hours to minutes 😌
Graph – reduced query time to seconds 😎
Hierarchical – approach abandoned 😞

Requirements – Analysis Results
The hierarchical approach was abandoned because:-The graph approach provided a good solutionThe graph approach offered a path towards Linked Data Cost overheads and deadlines obliged us to move on.

Requirements – Analysis Results
The hierarchical approach was abandoned because:-The graph approach provided a good solutionThe graph approach offered a path towards Linked Data Cost overheads and deadlines obliged us to move on.
A hierarchical approach may have offered comparable performance and opportunity, we simply don't know...

Requirements – Analysis Conclusion
The issues of closure and export had led to fundamental questions about the nature of the catalogue.
We don't know exactly what information will need to go into DRI but we know it will be information about people, organisations, their relationships and activities. These things are complex and varied – just like the world around us!
A graph approach not only resolved the issues with closure and export but provides a powerful and flexible tool for discovering information within the archive.

Design

Design - Technology
Technologies used during the trial included:-D2RQApache Jena framework (including TDB and Fuseki)Turtle (RDF)SPARQL 1.1 (Query and Update)
The Jena framework was chosen because:-Excellent Java APIOpen Source

Design - Technology
UK Government Service Design Manual states...
“...it remains the policy of the government that, where there is no significant overall cost difference between open and non-open source products that fulfil minimum and essential capabilities, open source will be selected on the basis of its inherent flexibility.”
“Use open standards and common Government platforms (e.g. Identity Assurance) where available”
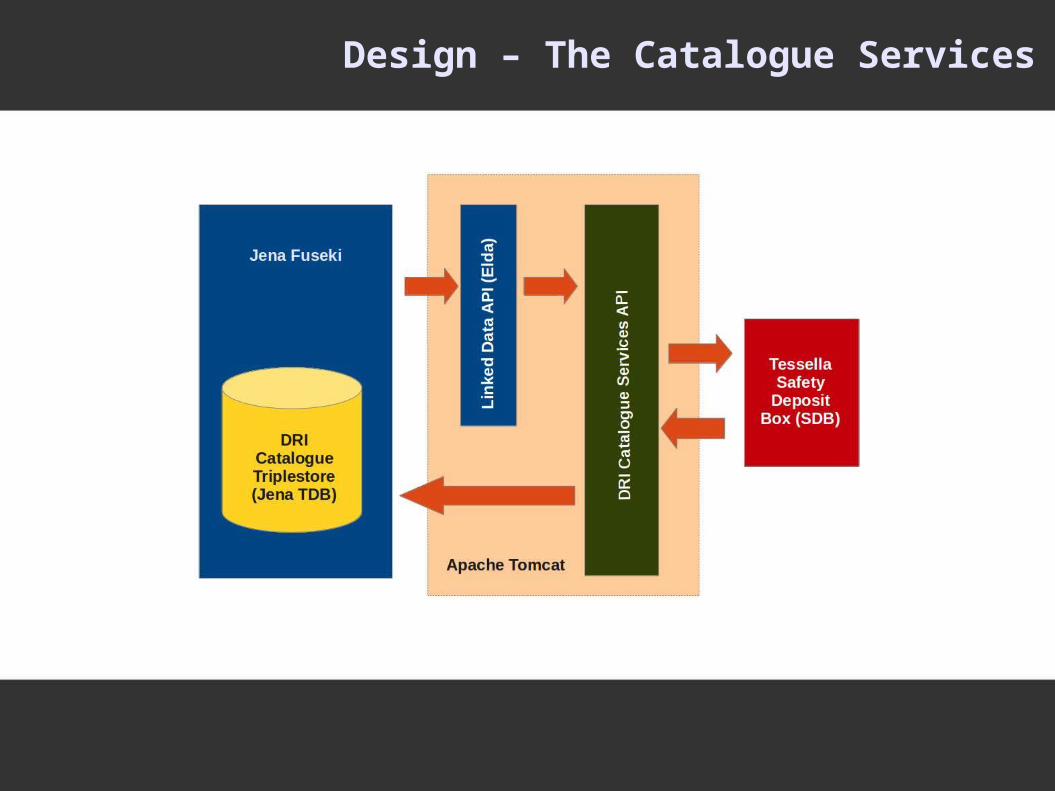
Design – The Catalogue Services

Design – DRI Vocabulary
W3C recommend re-using vocabularies wherever possible and DRI already does this extensively in the XML metadata.
But we needed to be able to talk about things very specific to DRI such as Closure and Export .
So we extended the RDF Schema (RDFS) with a few of our own classes and properties such as:-
<http://nationalarchives.gov.uk/terms/dri#Export>– rdf:type rdfs:Class .
<http://nationalarchives.gov.uk/terms/dri#exportMember>– rdf:type rdfs:Property
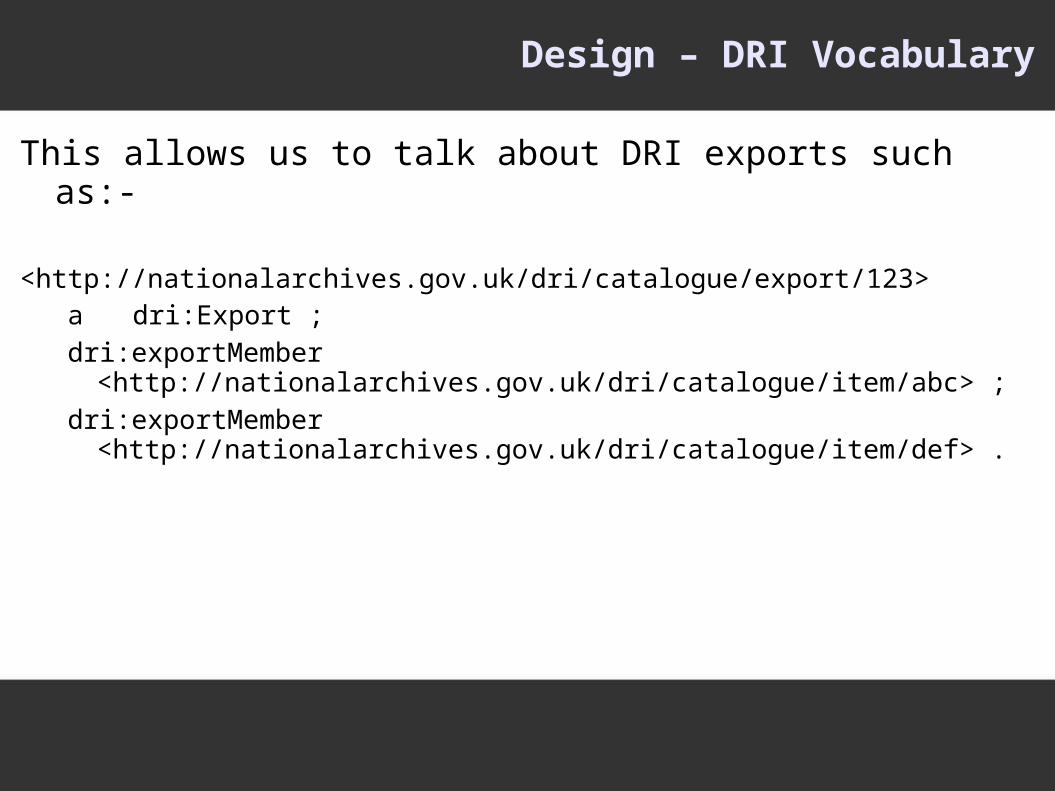
Design – DRI Vocabulary
This allows us to talk about DRI exports such as:-
<http://nationalarchives.gov.uk/dri/catalogue/export/123>a dri:Export ;dri:exportMember <http://nationalarchives.gov.uk/dri/catalogue/item/abc> ;
dri:exportMember <http://nationalarchives.gov.uk/dri/catalogue/item/def> .

Design – The Catalogue Services
The Apache Jena Framework provides a straightforward approach to reading, writing, updating and deleting data using W3C standards...

Design – The Catalogue Services
The Apache Jena Framework provides a straightforward approach to reading, writing, updating and deleting data using W3C standards...
Reading – SPARQL 1.1 Query Language Writing – creating and persisting new RDF triples (e.g. Turtle)
SPARQL 1.1 Graph Store Protocol Updating and Deleting – SPARQL 1.1 Update Language

Design – The Catalogue Services
However......having to learn SPARQL can be a hurdle to widespread
acceptance of this technology!
The answer......Elda (Linked Data API implementation) provides RESTful
access to pre-configured SPARQL queries:-
spec:collectionList a apivc:ListEndpoint ; apivc:uriTemplate "/collection"; apivc:selector [
apivc:where " ?item a dri:Collection . " ;]; .
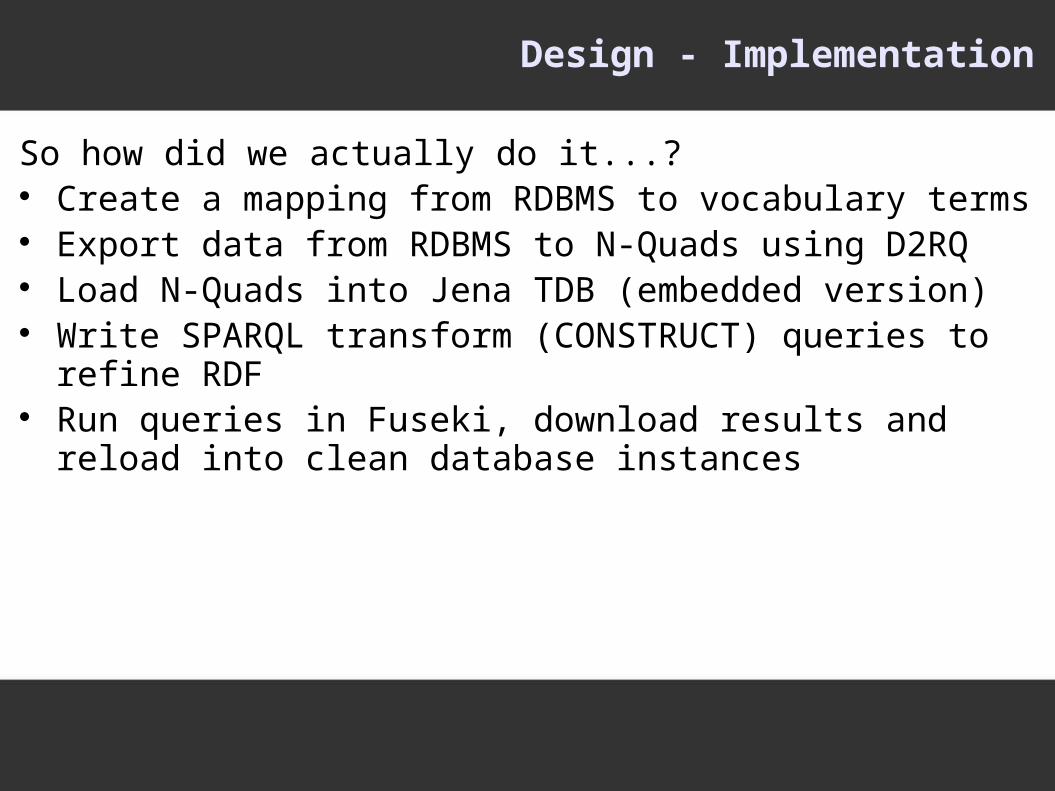
Design - Implementation
So how did we actually do it...? Create a mapping from RDBMS to vocabulary terms Export data from RDBMS to N-Quads using D2RQ Load N-Quads into Jena TDB (embedded version) Write SPARQL transform (CONSTRUCT) queries to refine RDF Run queries in Fuseki, download results and reload into clean
database instances

Design - Implementation

Design – Catalogue Services API
RESTful JAX-RS web application providing a very simple API
<result xmlns=”http://nationalarchives.gov.uk/dri/catalogue”><uuid>e9f3c8e9-e883-4fcf-a9a3-5caf0c808c5d</uuid>
</result>
Why XML? Why not JSON? Web services consumed by Java applications.JSON is used in some circumstances, i.e. for a JavaScript
tree editor.
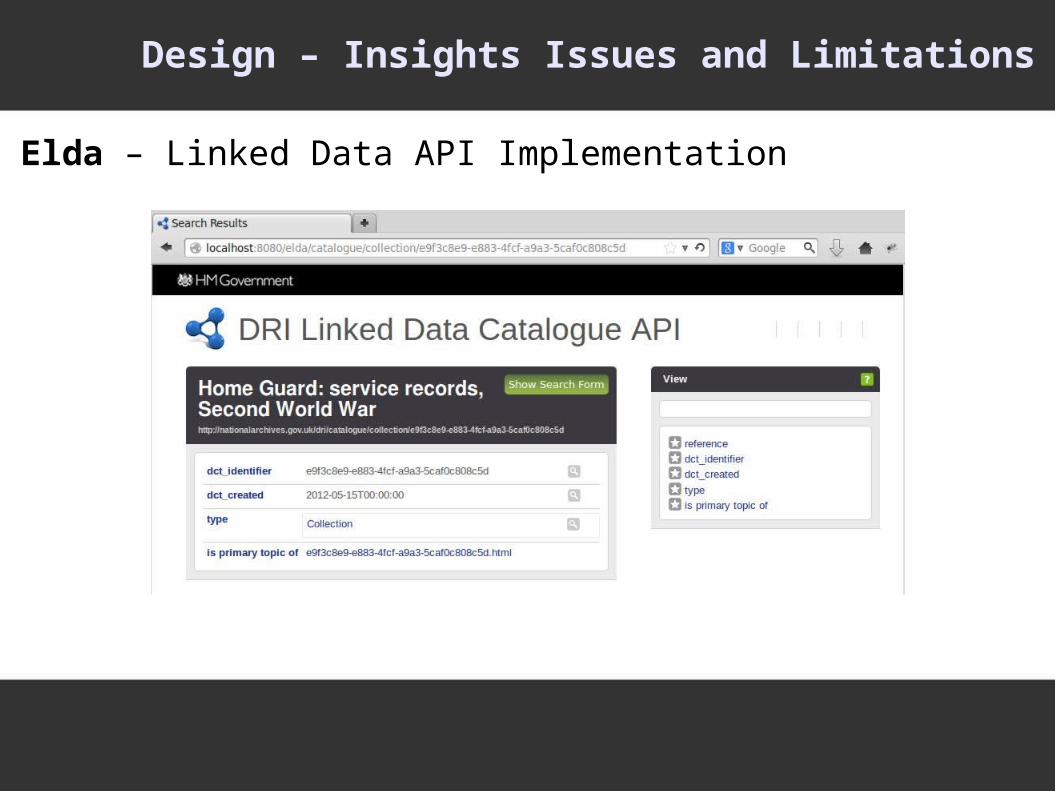
Design – Insights Issues and Limitations
Elda – Linked Data API Implementation
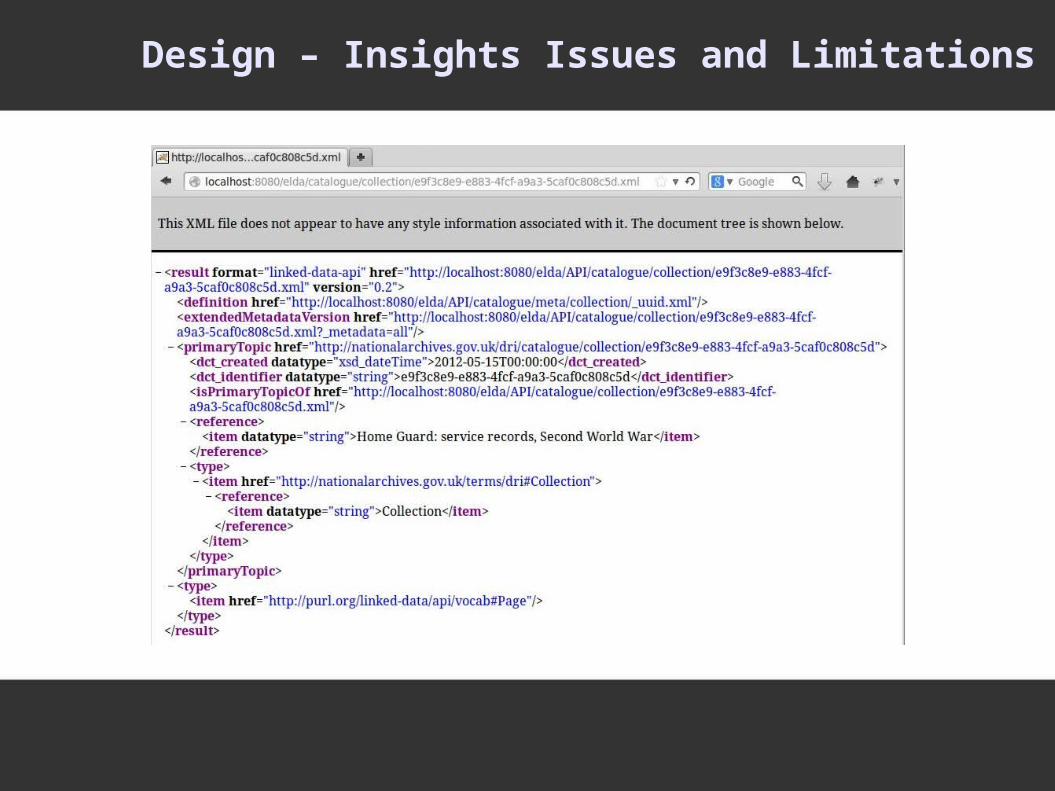
Design – Insights Issues and Limitations
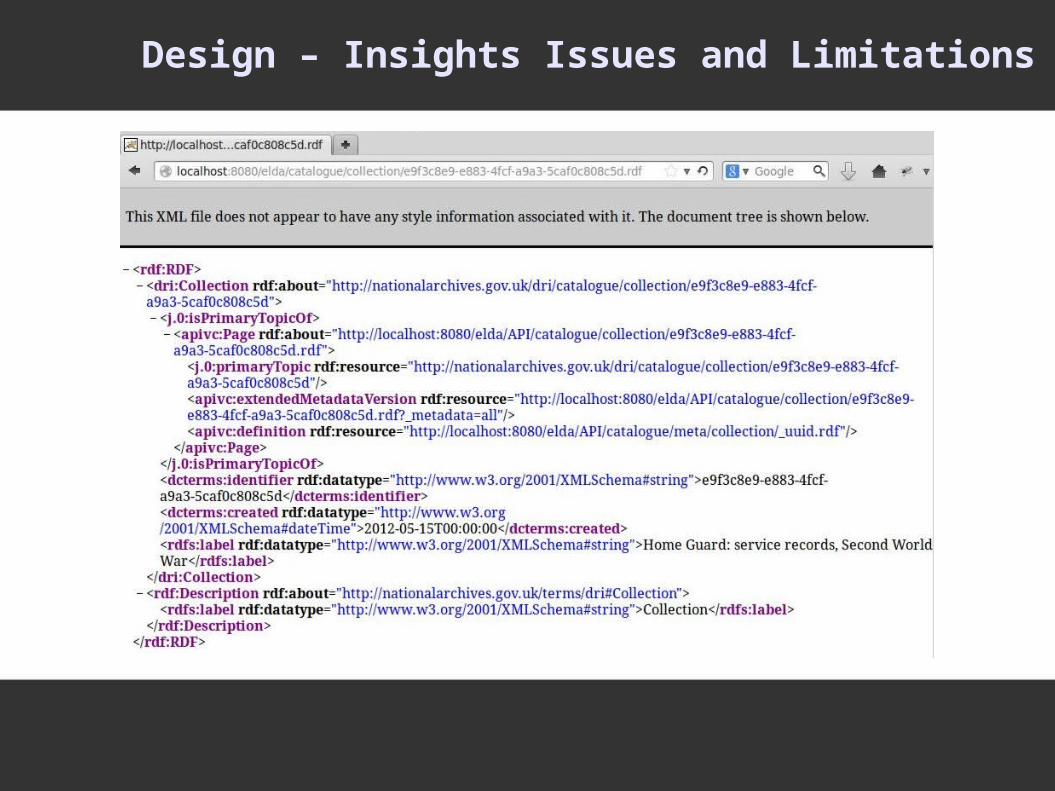
Design – Insights Issues and Limitations
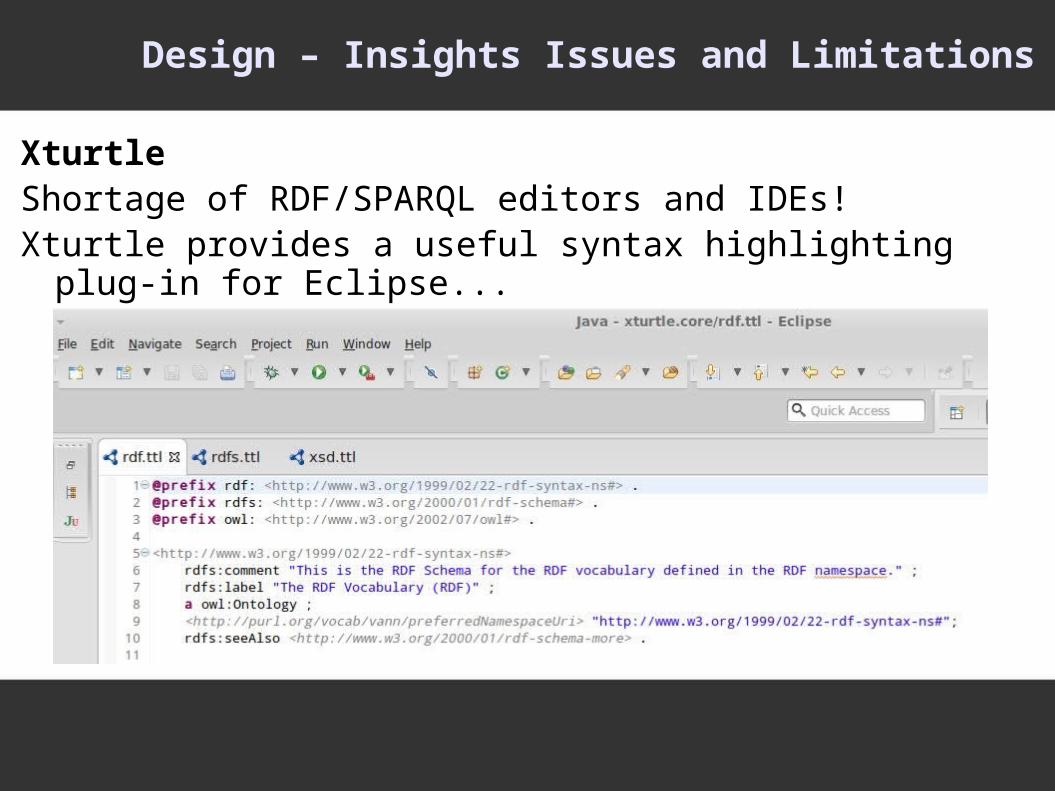
Design – Insights Issues and Limitations
XturtleShortage of RDF/SPARQL editors and IDEs!Xturtle provides a useful syntax highlighting plug-in for Eclipse...
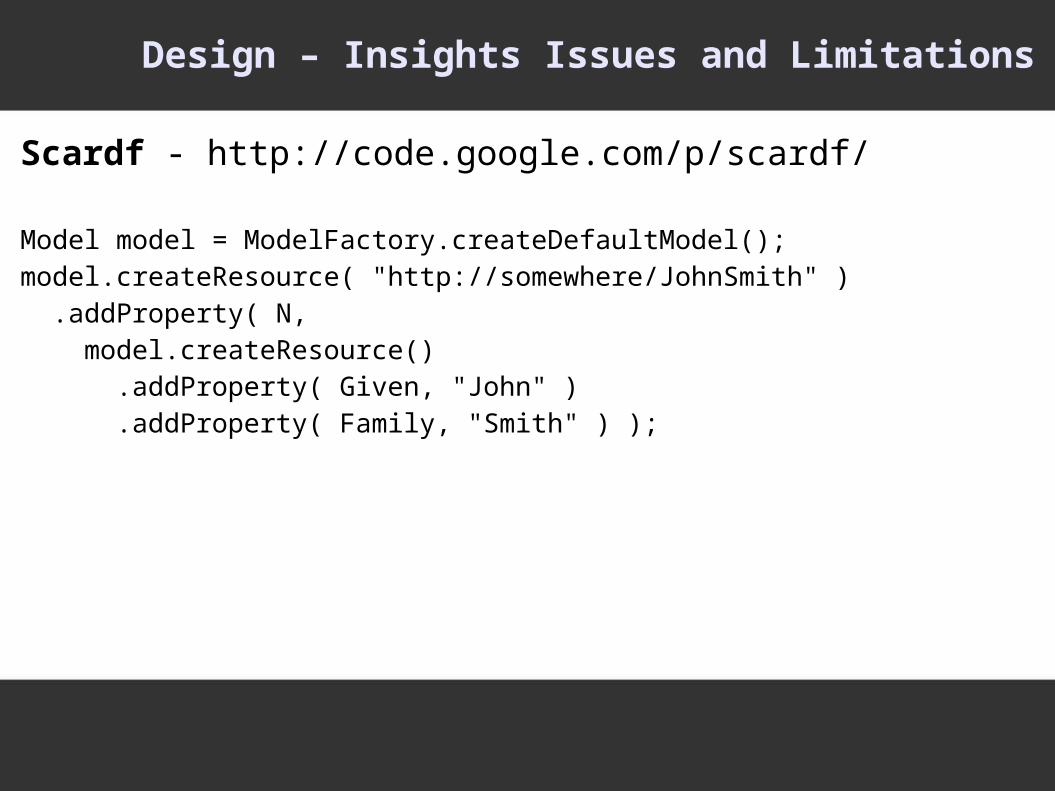
Design – Insights Issues and Limitations
Scardf - http://code.google.com/p/scardf/
Model model = ModelFactory.createDefaultModel();model.createResource( "http://somewhere/JohnSmith" ) .addProperty( N, model.createResource() .addProperty( Given, "John" ) .addProperty( Family, "Smith" ) );

Design – Insights Issues and Limitations
Scardf - http://code.google.com/p/scardf/
Model model = ModelFactory.createDefaultModel();model.createResource( "http://somewhere/JohnSmith" ) .addProperty( N, model.createResource() .addProperty( Given, "John" ) .addProperty( Family, "Smith" ) );
Graph( UriRef( "http://somewhere/JohnSmith" ) -N-> Branch( Given -> "John", Family -> "Smith" ) )

Design – Insights Issues and Limitations
Scale and Performance
Will the DRI Catalogue cope with the tsunami?

Design – Insights Issues and Limitations
Scale and Performance
Will the DRI Catalogue cope with the tsunami?We think it will...1) This solution was chosen because of it's performance2) We are confident we can scale horizontally. In fact a catalogue
for each collection makes some sense. You could then create a catalogue of catalogues to search everything!
3) If the existing framework fails to scale satisfactorily the fact that we are using open standards means moving to another framework should be straightforward.

The Future

The Future
The story so far:- Remodelling of the DRI Catalogue Solution for Closure and Export

The Future
The story so far:- Remodelling of the DRI Catalogue Solution for Closure and Export
So what next?

The Future
The story so far:- Remodelling of the DRI Catalogue Solution for Closure and Export
So what next?
More metadata into the Catalogue Starting with the rich XML that we already have
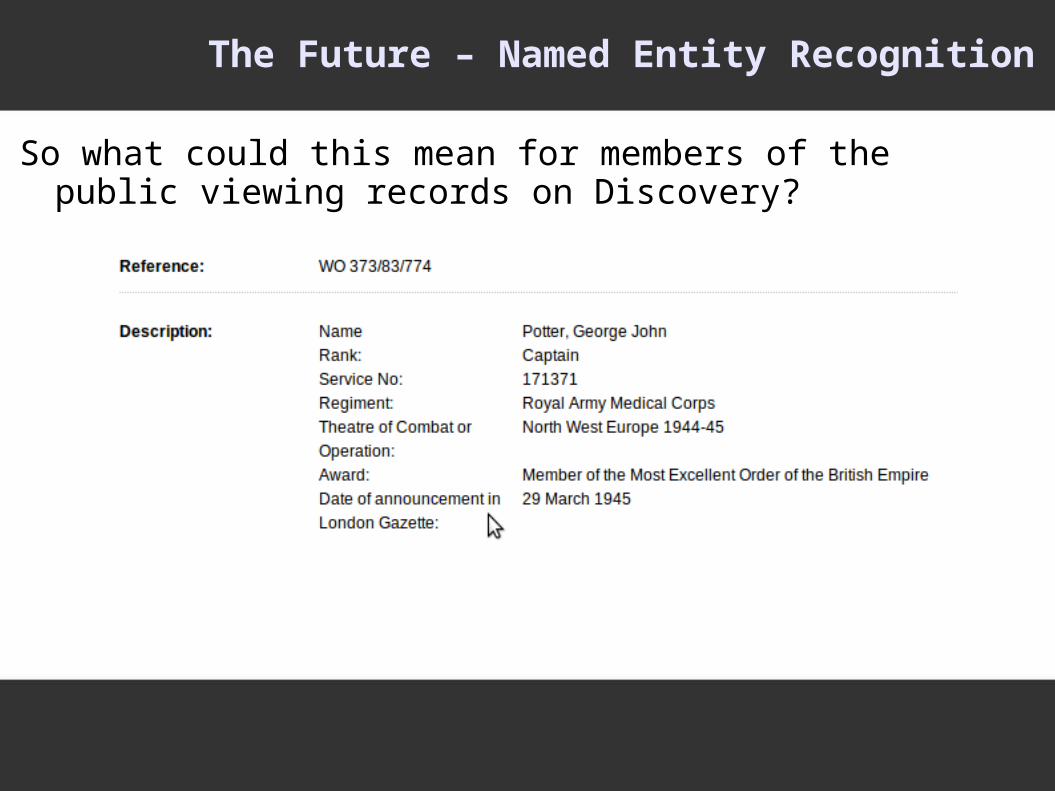
The Future – Named Entity Recognition
So what could this mean for members of the public viewing records on Discovery?
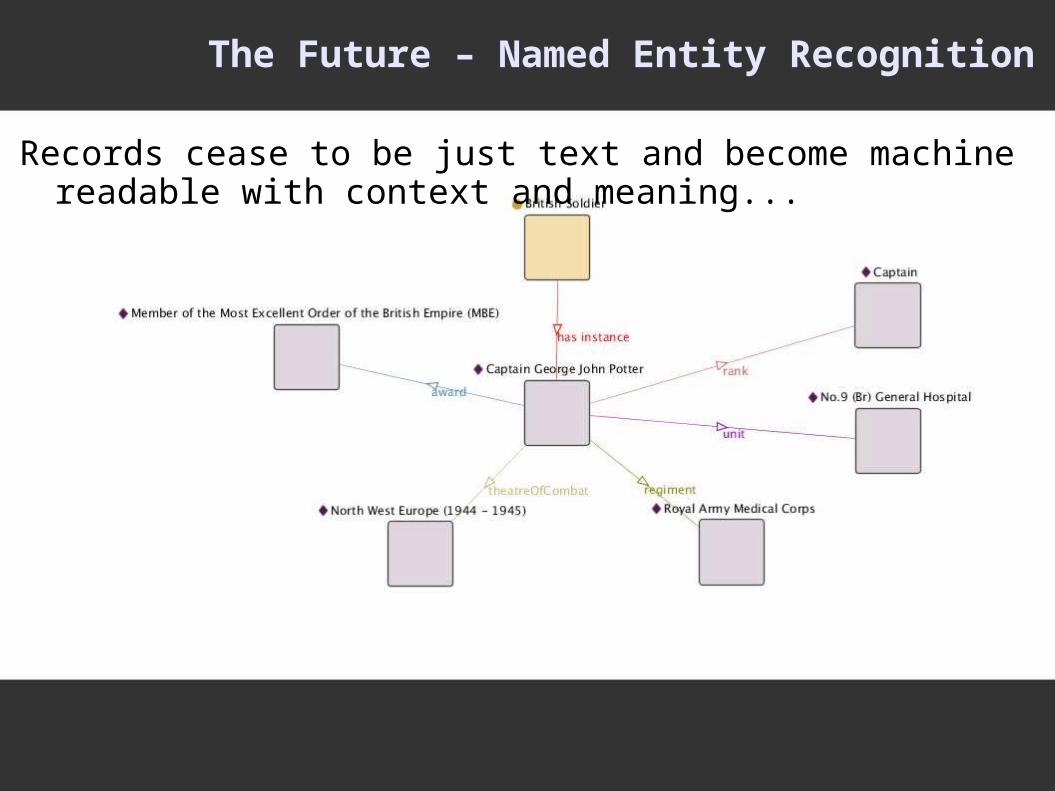
The Future – Named Entity Recognition
Records cease to be just text and become machine readable with context and meaning...

The Future – Ontology-driven NLP
Natural Language Processing (NLP) tools can be used in conjunction with RDF to extract meaning...
“From 1 Aug 44 to 20 Oct 44 Bayeux, Rouen and Antwerp. During the period from 1 Aug to date this officer has carried the principal strain of establishing and re-establishing the hospital in three situations. His unrelenting energy, skill and patience have been the mainstay of the unit. His work as a quartermaster is the most outstanding I have met in my service. (A.R.ORAM) Colonel Comdg. No.9 (Br) General Hospital”

The Future – Ontology-driven NLP
Natural Language Processing (NLP) tools can be used in conjunction with RDF to extract meaning...
“From 1 Aug 44 to 20 Oct 44 Bayeux, Rouen and Antwerp. During the period from 1 Aug to date this officer has carried the principal strain of establishing and re-establishing the hospital in three situations. His unrelenting energy, skill and patience have been the mainstay of the unit. His work as a quartermaster is the most outstanding I have met in my service. (A.R.ORAM) Colonel Comdg. No.9 (Br) General Hospital”
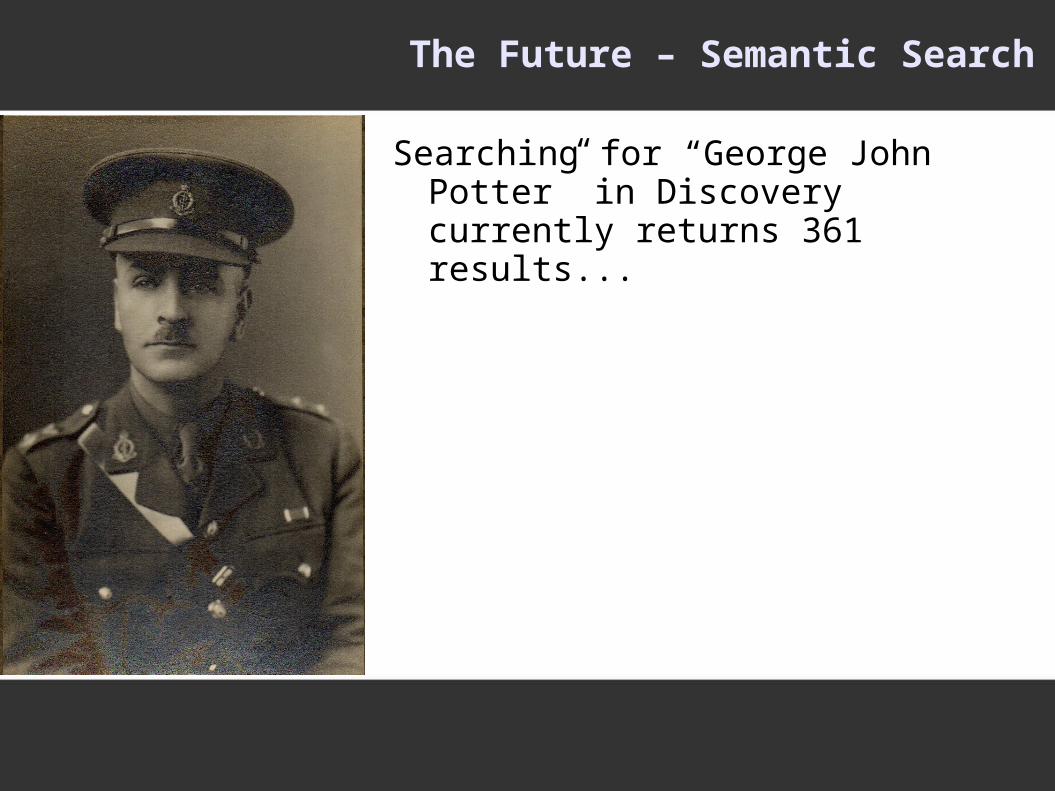
The Future – Semantic Search
Searching for “George John Potter” in Discovery currently returns 361 results...

The Future – Semantic Search
Searching for “George John Potter” in Discovery currently returns 361 hits...
...that's 360 irrelevant ones as there is only one record for a person with that name.

The Future – Semantic Search
Searching for “George John Potter” in Discovery currently returns 361 hits...
...that's 360 irrelevant ones as there is only one record for a person with that name.
A semantic search would allow you to search for a “person”, a “soldier” or an “officer” with that name.
This is known as query string extension.

The Future – Semantic Search
Semantic search also allows you to search for terms closely associated with your matches – known as cross referencing.
In this case we would receive information about Colonel A.R.Oram as he also had an entry in Discovery...

The Future – Semantic Search
Because related concepts are held in a graph it is possible to do exploratory search into a particular area of interest.
In this case we might discover that Colonel Oram was himself awarded a medal his work with No.9 British General Hospital...
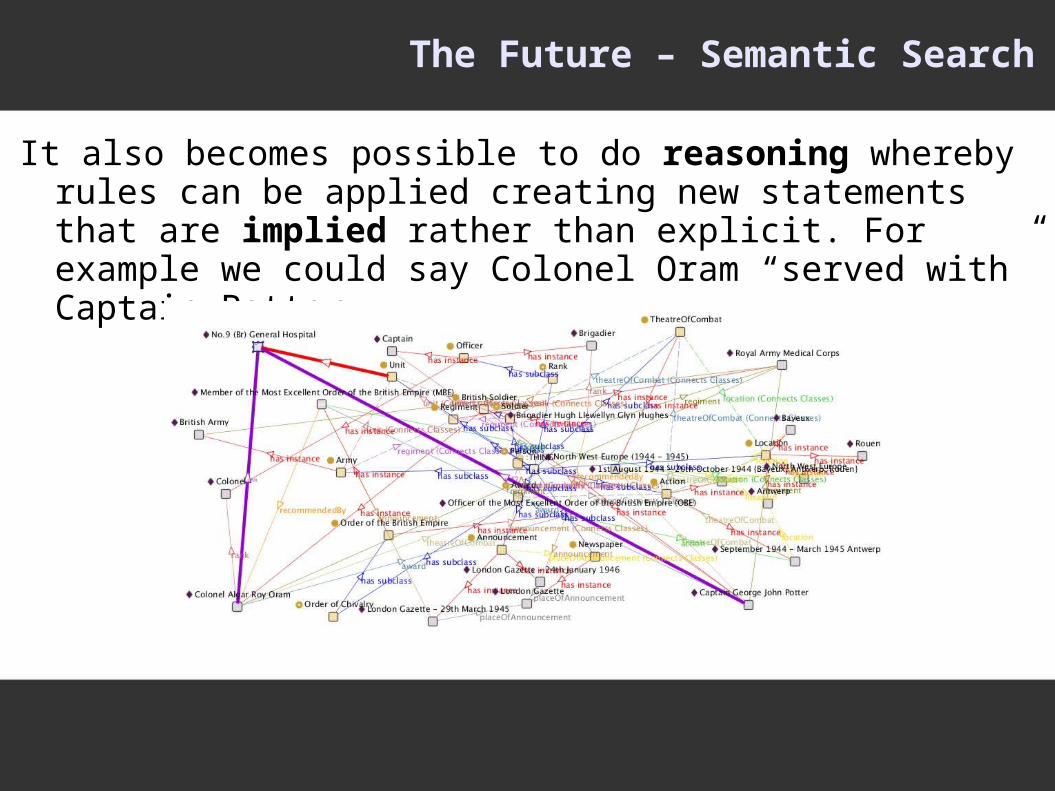
The Future – Semantic Search
It also becomes possible to do reasoning whereby rules can be applied creating new statements that are implied rather than explicit. For example we could say Colonel Oram “served with” Captain Potter...

The Future – Linked Data
While TNA is a huge national (and international) source of information it is not an authority on all things.
Linked Data, the brainchild of WWW inventor Sir Tim Berners-Lee provides a way of un-siloing and linking datasets using RDF-based machine-readable formats standardised by the W3C.

The Future – Linked Data
While TNA is a huge national (and international) source of information it is not an authority on all things.
Linked Data, the brainchild of WWW inventor Sir Tim Berners-Lee provides a way of un-siloing and linking datasets using RDF-based machine readable formats standardised by the W3C.
TNA data could be Linked Data sources such as DBPedia Ordnance Survey British Library Smithsonian

The Future – Crowd-sourced linking
Even the best machine reading will miss key facts and links.
Digitised documents rely on transcriptions for metadata as OCR still has a long way to go.
Crowd-sourced linking would allow users to link established vocabulary terms to specific documents.
Discovery already allows tagging but users tend to create very personal terminology which doesn't necessarily help others...

The Future – Open World Assumption
Using a semantic approach allows for an Open World Assumption. That is to say that it is...
“implicitly assumed that a knowledge base may always be incomplete”
[Hitzler, Krötzsch, Rudolph – Foundations of Semantic Web Technologies]
This means that TNA can always add new information to the DRI Catalogue as it is discovered – without needing to redesign the storage architecture. Exactly what you want for an archive!

Thank you





























