Embed Size (px)
Citation preview
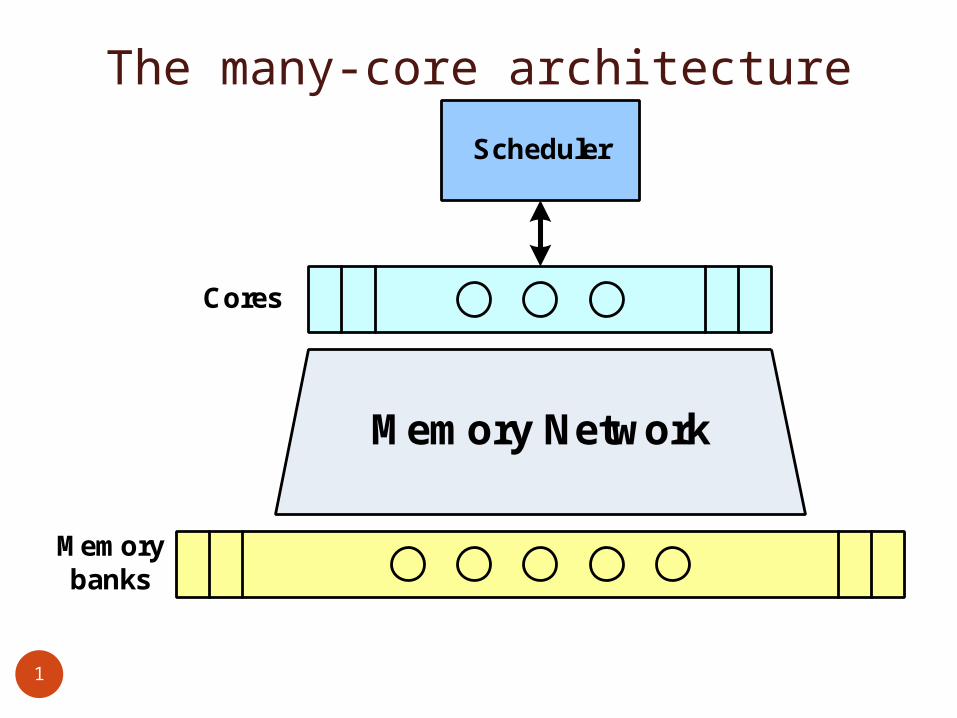
The many-core architecture
1
Scheduler
Cores
Memory Network
Memory banks

The System One clock Scheduler (ideal)
distributes tasks to the Cores according to a task map Cores
256 simple RISC Cores, no cachesPerform tasks given by the SchedulerReport back to Scheduler when done
Memory BanksInterleaved addresses among the cores
Processor-to-Memory NetworkPropagates read/write commands from Cores to MemoryBufferlessCollision on >1 Read/Write requests to same bank at same
time No collision for 2 Reads from the same address Return NACK to cores (one succeeds, others fail) Core retries after NACK
Access timeFixed (same to all addresses) in base systemVariable in this research
2
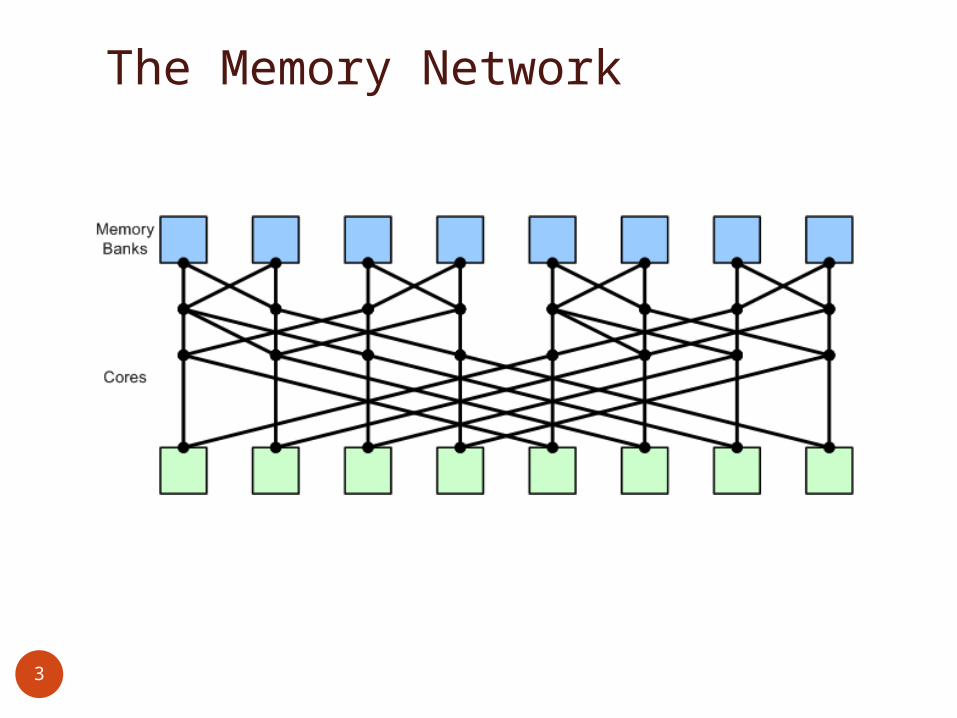
The Memory Network
3
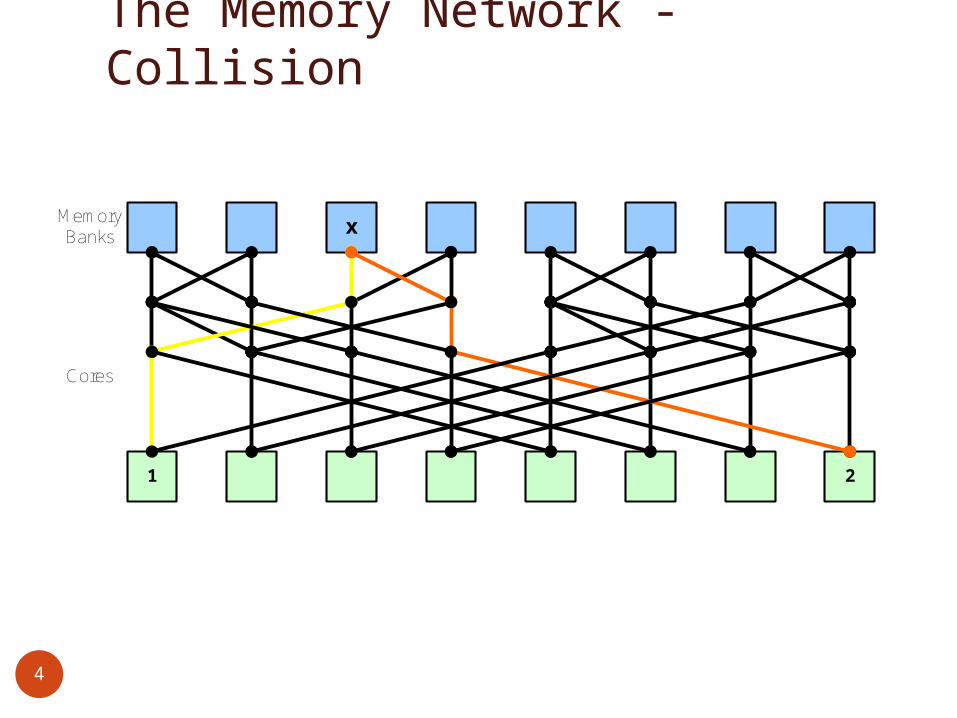
The Memory Network - Collision
4
x
Cores
Memory Banks
1 2

The Memory Banks - Interleaved
64 banks 4B example
5

Research Question: Non equi-distant memoryThe base system [Bayer Ginosar 91] uses
equi-distant memoryClock cycle time good for
Processor cycleAccess to farthest memory bank
Slow clock (Freq 1)Access to memory takes 2 cycles (one cycle
to memory & one back)But the Cores can work faster…
Higher clock frequencyfaster processors, higher performanceSome memory access is shorter
6
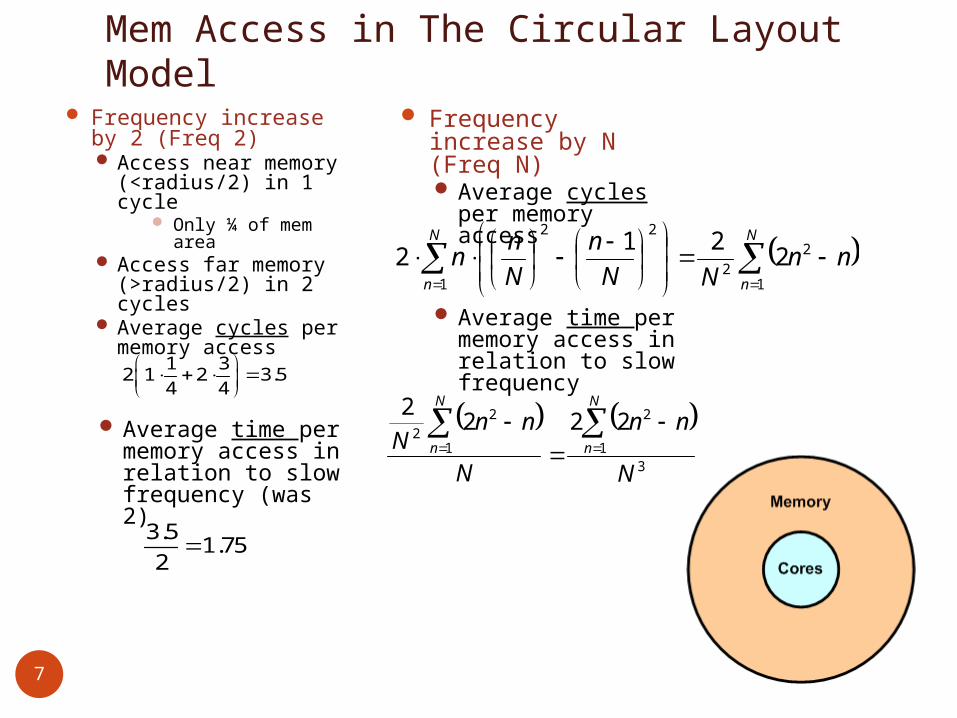
Mem Access in The Circular Layout Model
Frequency increase by 2 (Freq 2) Access near
memory (<radius/2) in 1 cycle
Only ¼ of mem area
Access far memory (>radius/2) in 2 cycles
Average cycles per memory access1 32 1 2 3.5
4 4
Average time per memory access in relation to slow frequency (was 2)
3.51.75
2
Frequency increase by N (Freq N) Average cycles per
memory access
N
n
N
n
nnNN
n
N
nn
1
22
1
22
221
2
Average time per memory access in relation to slow frequency
3
1
2
1
22
2222
N
nn
N
nnN
N
n
N
n
7
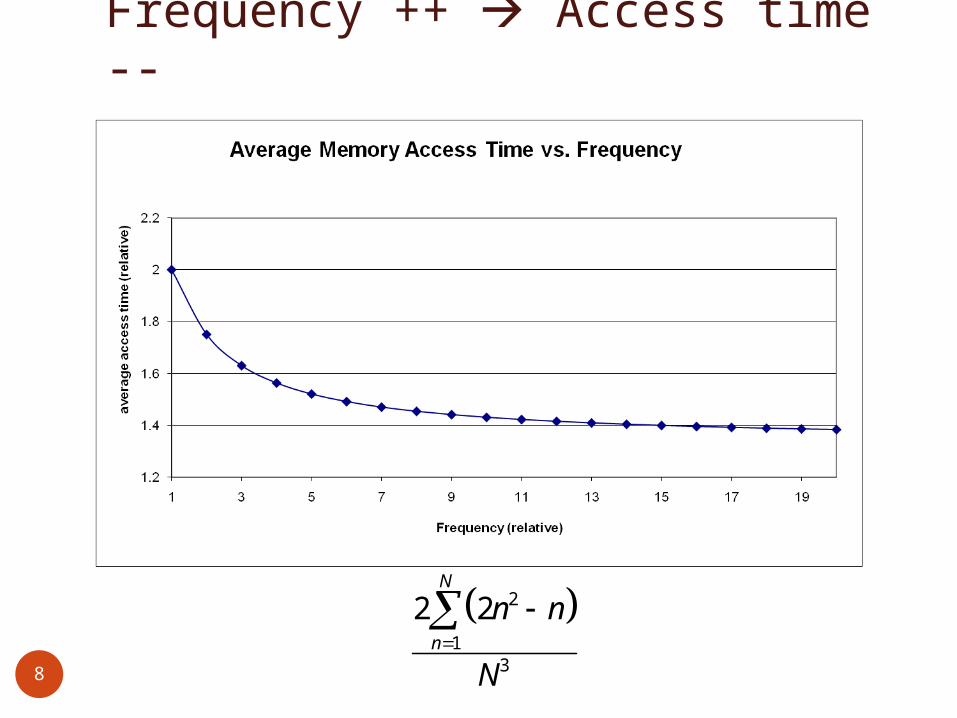
Frequency ++ Access time --
2
13
2 2N
n
n n
N
8
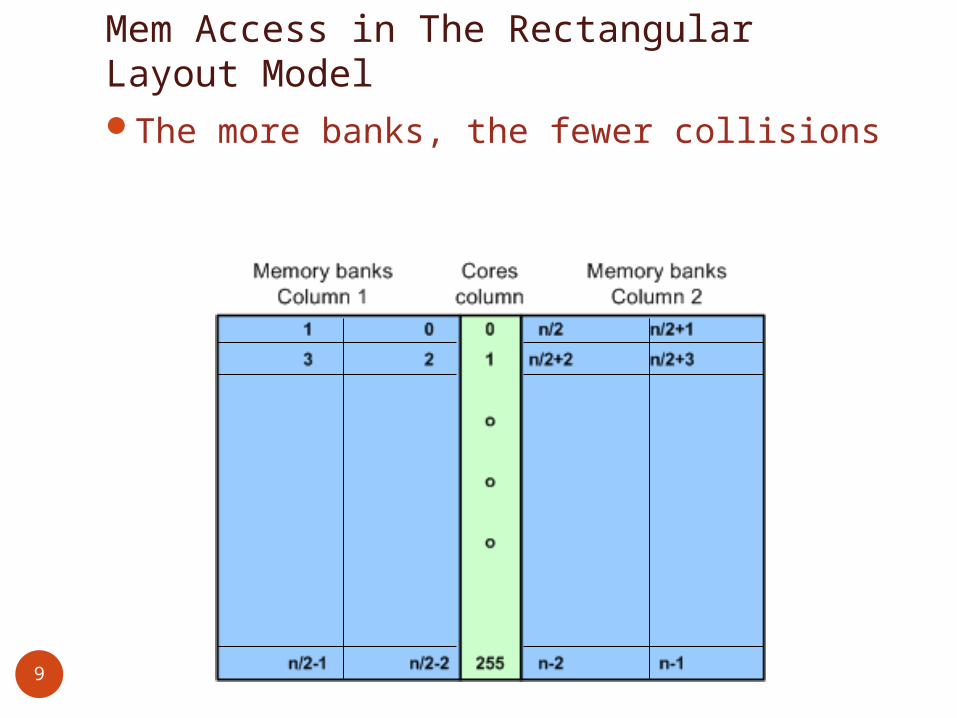
Mem Access in The Rectangular Layout ModelThe more banks, the fewer collisions
9
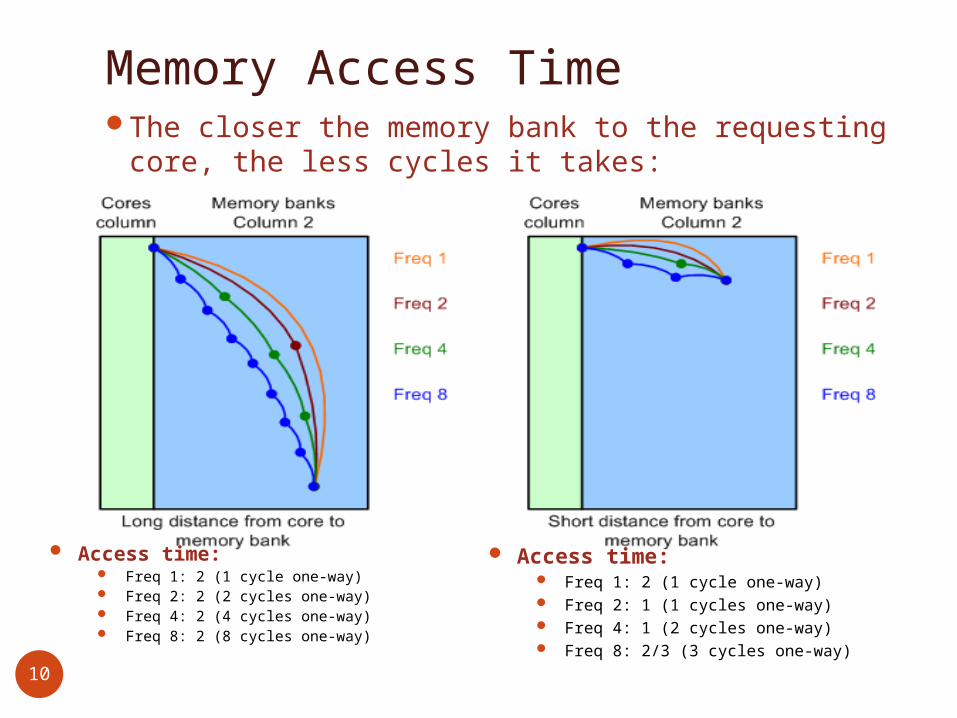
Memory Access TimeThe closer the memory bank to the
requesting core, the less cycles it takes:
Access time: Freq 1: 2 (1 cycle one-way) Freq 2: 2 (2 cycles one-way) Freq 4: 2 (4 cycles one-way) Freq 8: 2 (8 cycles one-way)
Access time: Freq 1: 2 (1 cycle one-way) Freq 2: 1 (1 cycles one-way) Freq 4: 1 (2 cycles one-way) Freq 8: 2/3 (3 cycles one-way)
10
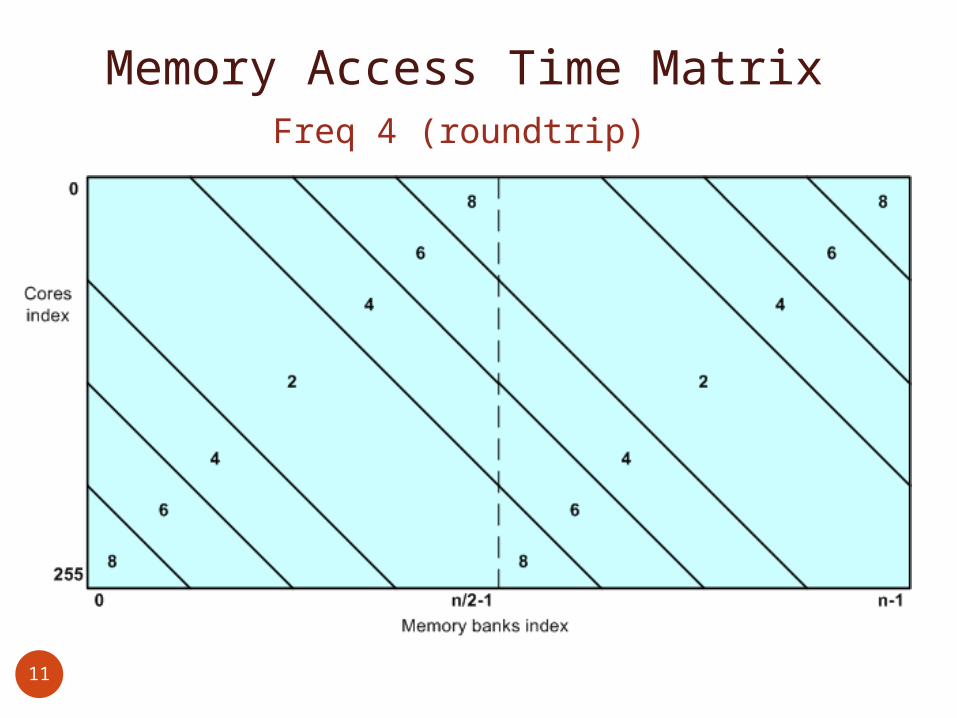
Memory Access Time MatrixFreq 4 (roundtrip)
11
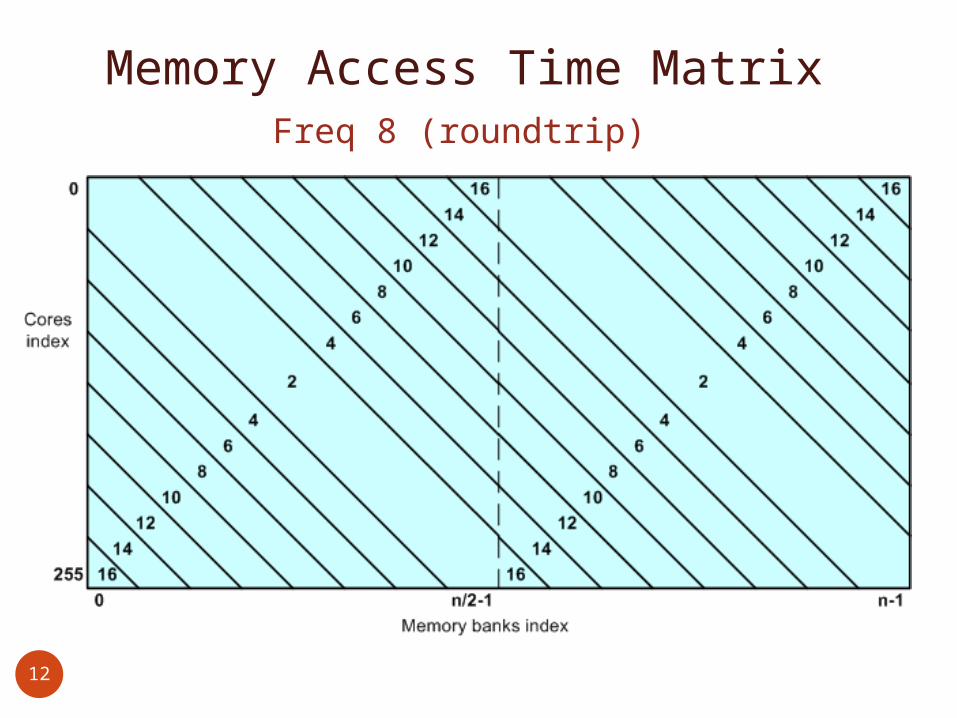
Memory Access Time MatrixFreq 8 (roundtrip)
12

Tested ParametersCores:
Fixed 256Frequency
1, 2, 4, 8Results are compared to Freq 1
Memory Banks:128, 256, 512The more banks, the fewer collisions ??
13
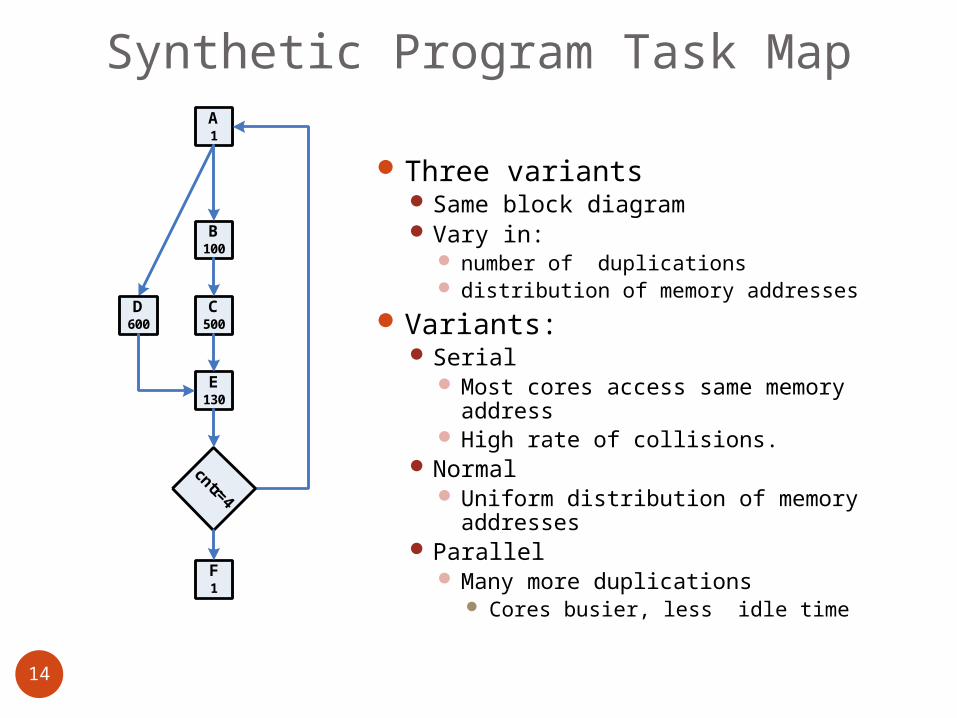
Synthetic Program Task Map
Three variantsSame block diagramVary in:
number of duplications distribution of memory addresses
Variants:Serial
Most cores access same memory address
High rate of collisions.Normal
Uniform distribution of memory addresses
Parallel Many more duplications
Cores busier, less idle time
14
A1
B100
C500
D600
E130
F1
cntr=4

Actual test programsThree programs
JPEGLinear SolverMandelbrot fractals
Executed by sw simulator on a single core, generated traces
Traces processed by many-core architecture simulator

Results
16
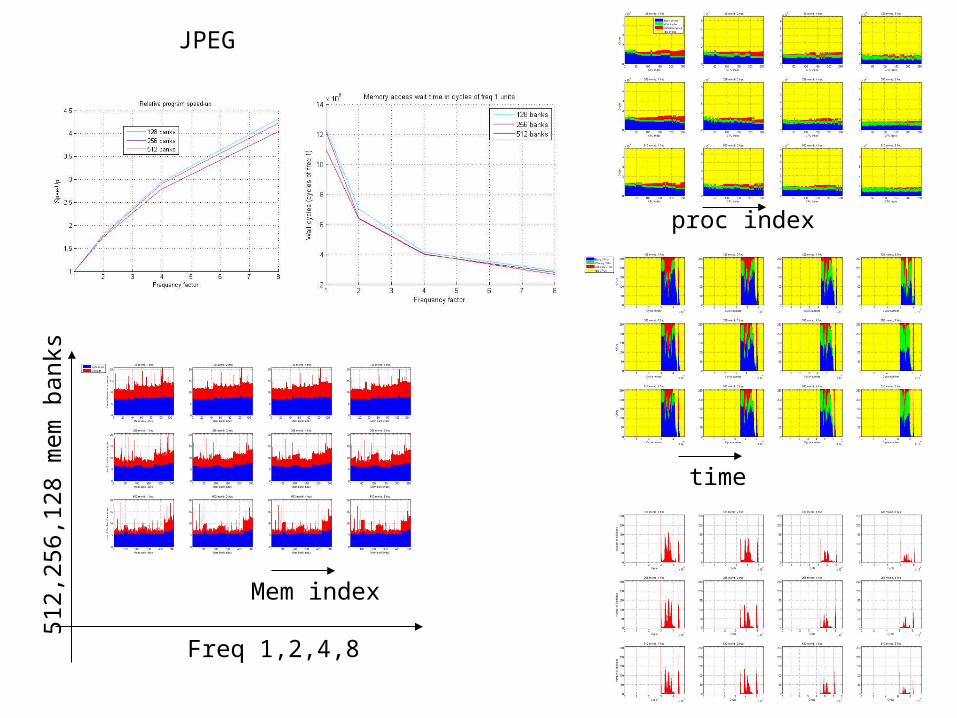
JPEG
Mem index
Freq 1,2,4,8
512,
256,
128
mem
ban
ks
proc index
time
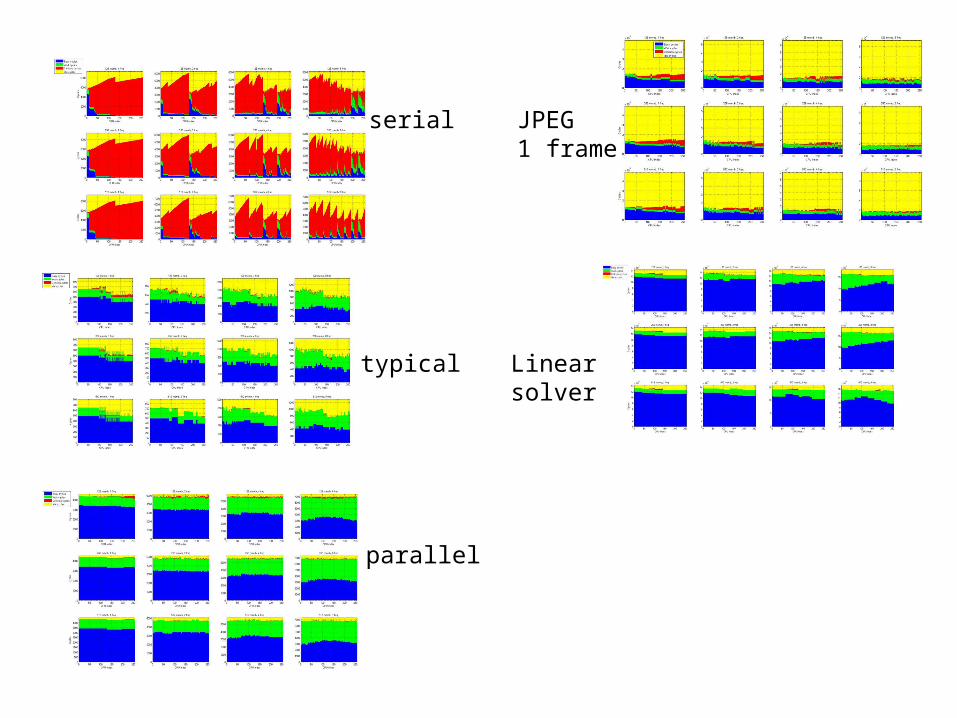
serial
parallel
typical
JPEG1 frame
Linearsolver

Decomposed ContributionsThree factors affect speedup
Processors executing faster (freq=1,2,4,8)Network latency shorter
Far blocks take same long timeNearer blocks reachable at shorter latencies
Memories allow faster access (freq=1,2,4,8)Need to separate 3 contributions
By modified simulationsBy re-computing (manipulating) the results

Contribution of processorsSimulation
Processors at freq=1,2,4,8Network single cycle (equi-distant), freq=1Memories at freq=1
ComputingUse data of Freq=1 for everythingDividing processor busy times by 1,2,4,8

Contribution of networkSimulation
Processors at freq=1,2,4,8Network multi-cycleMemories at freq=1
Does not make sense: cancels network effect
ComputingCompare single and multi-cycle runs

Contribution of memoriesSimulation
Processors at freq=1,2,4,8Network single cycle, slow (freq=1)Memories at freq=1,2,4,8
By multi-port memories (1,2,4,8 ports per cycle)

Contributions
Differential Speed Up (Mendelbrot)
0%10%20%30%40%50%60%70%80%90%
100%
Freq1,
Bank1
28
Freq1,
Bank2
56
Freq1,
Bank5
12
Freq2,
Bank1
28
Freq2,
Bank2
56
Freq2,
Bank5
12
Freq4,
Bank1
28
Freq4,
Bank2
56
Freq4,
Bank5
12
Freq8,
Bank1
28
Freq8,
Bank2
56
Freq8,
Bank5
12
CPU saved % Bank saved % Net saved %
128banks
256banks
512banks
Freq 1Freq 2
Freq 4Freq 8
0.8530.9390.9850.7960.9230.975
0.8130.9140.958
0.181
0.8380.914
0
0.5
1
Network Efficiency (Mendelbrot)
Differential Speed Up (JPEG)
0%10%20%30%40%50%60%70%80%90%
100%
Freq1,
Bank1
28
Freq1,
Bank2
56
Freq1,
Bank5
12
Freq2,
Bank1
28
Freq2,
Bank2
56
Freq2,
Bank5
12
Freq4,
Bank1
28
Freq4,
Bank2
56
Freq4,
Bank5
12
Freq8,
Bank1
28
Freq8,
Bank2
56
Freq8,
Bank5
12
CPU saved % Bank saved % Net saved %
128banks
256banks
512banks
Freq 1Freq 2
Freq 4Freq 8
0.7630.8250.8260.6640.6890.716
0.5270.5810.5770.3940.4000.444
0
0.5
1
Network Efficiency (JPEG)
NE=wait time / (wait + collision)

Conclusions
24

Cores temporal activity Higher frequency cores executing versions of same
task finish at different timesThanks to path latency diversityThis is finer granularity of core activity
Lower frequency cores executing versions of same task finish closer togetherMany cores become free at onceCoarser granularity activitySeen both in CPU activity and Temporal activity graphsWorse (burst) load on scheduler
More banks fewer accesses per bankFewer collisions
25

CollisionsCollisions decreases with
Higher frequencyMore banksAffects both Speed-Up & Wait Time
Higher frequency, more banks higher diversity of path latencyFewer collisions
Higher frequency collisions incur lower wait time penalty
26

Speed-Up Frequency is the dominant Factor, mostly due to faster
Cores, smaller number of collisions and mean shorter memory access cycles.
Within the same frequency, larger bank# is better due to lower collision rate. This can be seen in Normal and Parallel cases. In Serial case we don’t see such a dependency due to many accesses to a single memory address, which physically located differently on systems with different bank #.
In a highly collided program, Speed-Up is larger for fast frequencies than for parallel program, because of Cores/Banks path latency diversity (low frequencies have larger wait time penalty).
27

Relative Wait Time Relative Wait Time Decreases with frequency because
of path latency diversity. Bank# has hardly no impact for the Serial program,
because of the high collision number. In Normal & Parallel programs, the difference between
bank# is significant in low frequencies because of the higher collision number. In higher frequencies the bank# factor becomes less significant because of path latency diversity hence less collisions.
28





























