Embed Size (px)
Citation preview

The Grammatical Annotation of Speech Corpora:
Techniques and Perspectives
Eckhard BickUniversity of Southern Denmark

Outline
Introduction: Annotation of speech data
Part 1: Brazilian speech corpora (C-ORAL, NURC)
Constraint Grammar & Parser architecture
Parser adaptations for speech data:● text flow, tokenization, orthography, lexicon
● syntactic segmentation
Evaluation
Part 2: Parser adaptations for speech-like data: Chat and E-mail
Orality markers: Pronouns, emoticons, syntax
Conclusions & Outlook

Introduction
Corpora of both spoken language and non-standard, speech-like text are becoming more available, growing in scope and size
To fully exploit such corpora linguistically, grammatical annotation is needed in addition to phonetic-prosodic annotation
Automatic annotation is desirable in the face of large data quantities, to a certain extent also for the sake of consistency
Problems
● Spoken language has many non-standard features, both in grammar and lexicon
● Speech data are notationally ”colourful” and use different strategies for retaining non-text information in transcription
Research questions:
● Can a standard written-language parser be adapted for speech?
● To what extent do orality features carry over into non-standard text (chat, e-mail, twitter)

Brazilian Speech Corpora
NURC (Castilho et al. 1993)● 120,000 words, São Paulo
C-ORAL (Raso & Mello 2010, 2012)● 300,000 words, Minas
Modified orthography in transcriptions, to capture pronunciation variation, silent endings etc.
Meta annotation: ● pauses, non-word sounds
● speaker identity, turn taking and turn overlap, retractions
● time
Systematic manual prosodic annotation (C-ORAL)

Annotation methods
C-ORAL sister projects, using statistical taggers, no syntax● Italian: PiTagger (Moneglia et al. 2004) with lexicon (107.000
standard lemmas and 2000 non-standard forms) and training corpus (50.000 words ~ 25% of C-ORAL size)
● European Portuguese: Brill tagger (Brill 1993) with written Portuguese training corpus (250.000 words)
Arabic treebank, i.e. syntax (Maamouri et al. 2010)● manual selection of analyzer suggestion, followed by automatic
parsing
● not directly comparable: broadcast news, not spontaneous speech
Our approach: Constraint Grammar annotation● context-driven rules rather than statistics

Why Constraint Grammar
robust annotation methodology (Karlsson et al. 1994)● focus on disambiguation - no breakdowns due to generative rules
● token-based annotation, one tag per feature --> easy to filter
● modular methodology --> allows the combination of grammars targeting different linguistic levels
existing parser for Portuguese: PALAVRAS (Bick 2000)● has been succesfully used on a large variety of genres
(Linguateca project, CorpusEye)
● has proven adaptability in the face of non-standard data also in other areas, e.g. historical texts (Bick & Módolo 2005)
● keeps annotation levels seperate, while allowing them to interact– e.g. prosodic versus syntactic information

CG formalism
rule-base approach● robust & accurate (F-pos 99%, F-syn 95% on news text)
● tokens with tag-encoded information
● contextual rules remove, select, add or substitute information
REMOVE VFIN IF (*-1C PRP BARRIER NON-PRE-N)
((0 N) OR (*1C N BARRIER NON-PRE-N))
● modular architecture with rule batches orderd according to heuristicity
CG3 innovations● feature unification (both tag lists and sets)
● integration of statistical information
● use of regular expressions and environment variables
● allows generative rules

CG in comparable projects
Other projects with CG annotation of speech corpora● Estonian speech corpus (Müürisep & Uibo 2006)
● Nordic Dialect Corpus (Bondi et al. 2009), hybrid method– (a) written-language CG used on Oslo dialaect
– (b) manual correction
– (c) train Decision Tree Tagger (Schmid 1994) for other dialects
● Spanish section of European C-ORAL– CG-inspired rules for PoS disambiguation of morphological output
from the GRAMPAL system (Moreno 2003)
● Early experiments with PALAVRAS (Bick 1998)– NURC corpus (”Norma Lingüística Urbana Culta”, Castilho 1993)

The point of departure: PALAVRAS
Modular Constraint Grammar (CG) parser with a hierarchically structured sets of contextual rules
● morphosyntactic tagging, dependency trees
● 6000 rules, full lexical support, semantics
O <artd> DET M S @>N #1>3 Theúltimo <numord> ADJ M S @>N #2>3 lastdiagnóstico <semc> N M S @SUBJ> #3>9 diagnosticelaborado <pass> V PCP2 M S @ICLN< #4>3 producedpor PRP @<PASS #5>4 bya <artd> DET F S @>N #6>7 theComissão=Nacional <org> PROP F S @P< #7>5 CNnão <neg> ADV @ADVL> #8>9 notdeixa <vt> V PR 3S @FMV #9>0 leavesdúvidas <semc> N F P @<ACC #10>9 doubts$. #11->0
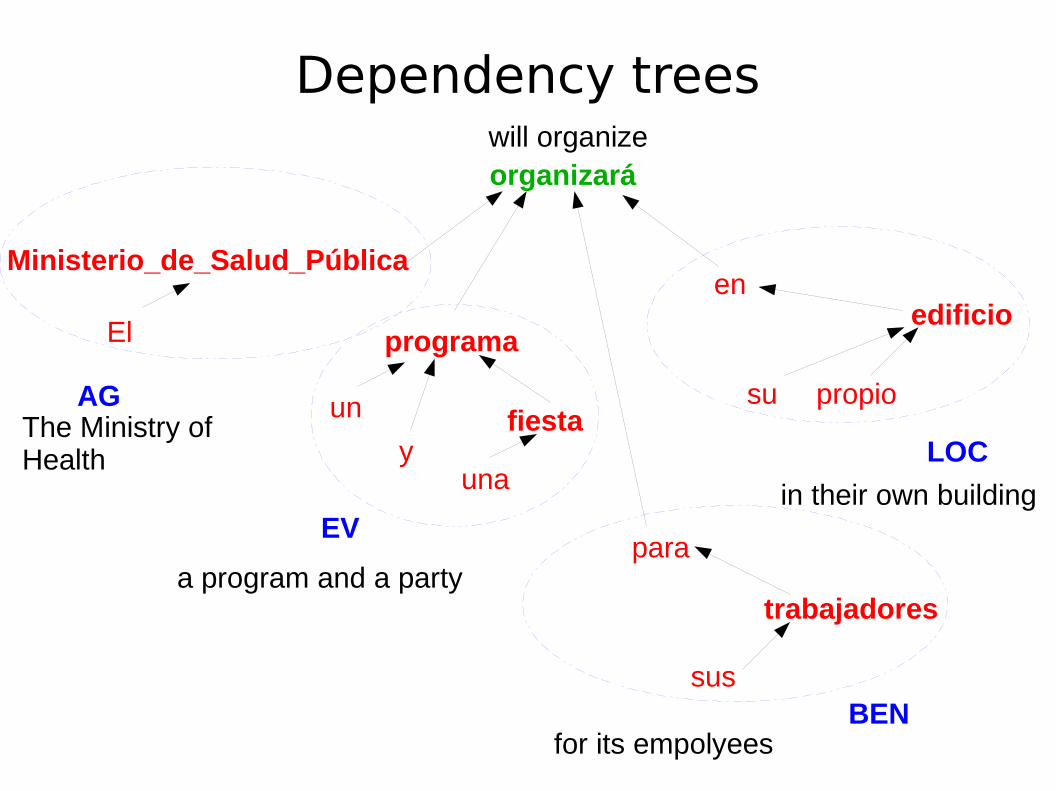
Dependency trees
organizará
Ministerio_de_Salud_Pública
El programa
para
trabajadores
sus
LOC
EV
BEN
fiesta
enedificio
su propioun
unay
AGThe Ministry of Health
a program and a party
for its empolyees
in their own building
will organize
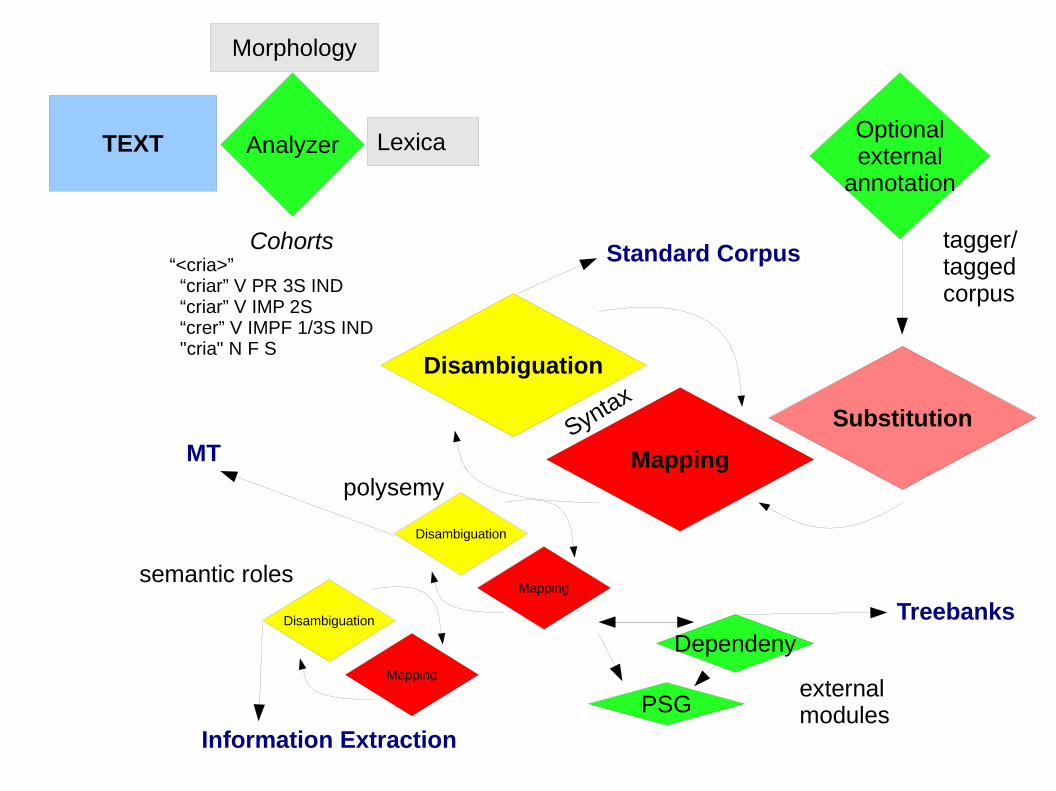
TEXT
Cohorts“<cria>” “criar” V PR 3S IND “criar” V IMP 2S “crer” V IMPF 1/3S IND "cria" N F S
Disambiguation
Mapping
Analyzer
Morphology
Lexica
Substitution
Optionalexternal
annotation
Disambiguation
Mapping
Disambiguation
Mapping
Dependeny
PSGexternalmodules
Syntax
polysemy
semantic roles
tagger/taggedcorpus
Information Extraction
MT
Treebanks
Standard Corpus

Text flow normalisation

Text flow: problems
● nesting and overlapping markers (the latter also problematic in xml)
● focus marker é_que (2% of turns) transcribed as que -> need for disambiguation
● syntax needs (separate) prepositions built-in ordinary contractions: do, nele, pelo ...
corpus-specific: pa (pra), pro, pum, naquea ...
difficult ambiguity: pra (para vs. para_a)
● post-tokenization (coral-inter) with support from normalization lexicon for the most difficult contractions, e.g. né = não é

Lexical and orthographical normalization
● Parser's treatment of unknown wordforms: Affix-based derivations Variants: br vs. pt, accents, orthographical reforms
● Special needs for C-ORAL speech corpus "phonetically" transcribed word forms (aquelas -> aqueas) grammatical variants (-amos -> -amo)
● Solutions two-level annotation and specialized standardisation modules
– meninim OALT menininho [menino] N M S coral.inter: second preprocessor with systematic and item-based
changes and MWE-tokenization– a'=qui (olha aqui), cabou (acabou)
postlex_pt: postprocessor with morphological analyzer using separate lexicon (2000 entries) and overriding PALAVRAS' heuristics

(a1) emedebê MDB (phonetic abbreviations)(b3) inda ainda ( (word-initial changes)(b4) roz arroz(d2) fazido feito (overregularization)
● Multi-word strings: effect also tokenization, but help disambiguate their parts, e.g.n' = não (not em) in: n'=era, n'=ocê
● Non-systematic new words and names:(a1) fazeção <activity> N F S(a2) zenes N M P # termo de jogo(a3) caça-talentos N M S(a5) superbem-arrumada ADJ F S(b) mil-oitocentos-e=vovó=gostosa NUM M/F P(c1) remote N M S # estrangeirismo(c2) completed ADJ M/F S/P # estrangeirismo(c5) anche ADV # estrangeirismo(d1) tu=tu X # onomatopéia(e2) TIM <org> PROP F S # company(e3) Timoftol <cm-rem> PROP M S
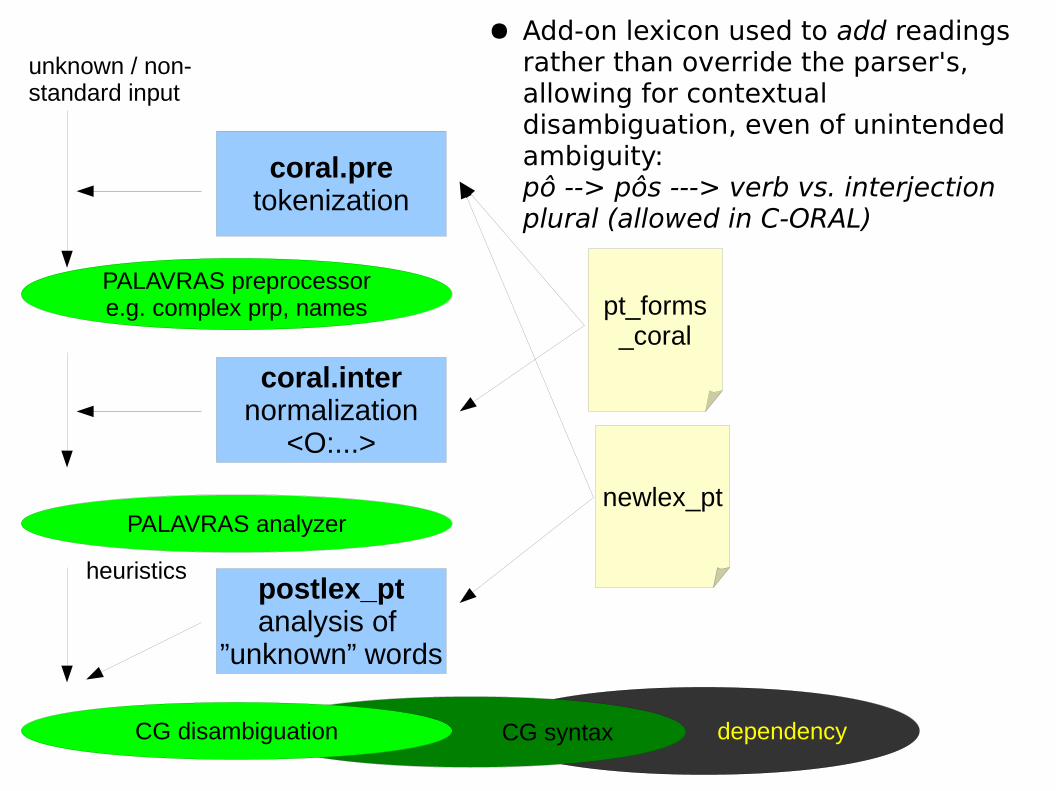
dependencyCG syntax
● Add-on lexicon used to add readings rather than override the parser's, allowing for contextual disambiguation, even of unintended ambiguity:pô --> pôs ---> verb vs. interjection plural (allowed in C-ORAL)
coral.pretokenization
coral.internormalization
<O:...>
PALAVRAS preprocessore.g. complex prp, names
newlex_pt
pt_forms_coral
PALAVRAS analyzer
postlex_ptanalysis of
”unknown” words
CG disambiguation
unknown / non-standard input
heuristics

Syntax
● Problem: syntactic noise: ah, eeh, uh Solution: two-level annotation
● Problem:Syntactic annotation needs long-distance contexts, so how can existing rules be made to work on a speech corpus > 80% unbounded/global CG rules in syntax but the corpus lacks sentence segmentation and punctuation
to delimit these rules Solution: Exploit prosodic information by not moving it to a
meta-level, but rather change it into punctuation● // (major prosodic break) --> semicolon● / (soft prosodic break) --> <break> <pause>

prosodic ”break markers”: rule-based disambiguation
● <break> --> comma
● <pause> --> meta-level (a) between a noun or a nominative pronoun or a conjunction
to the left, and a finite verb to the right, a prosodic /-marker is treated as <pause> (subject - verb case)
(b) prosodic /-markers between a noun and another np are treated as <break> (appositions)
(c) / between a prenominal and its head is treated as <pause> (np cohesion), e.g. 388 cases of article + <pause>
... <break> tipo <retract:José> Zé=Mourinho <break> falando assim <break> não <break>
o [o] <artd> DET M S @>N<pause><campeonato> [campeonato] <occ> N M S @SUBJ>d' OALT de [de] PRP @N<ocês OALT vocês [você] PERS M/F 3P NOM/PIV @P<é [ser] <vK> V PR 3S IND VFIN @FMV
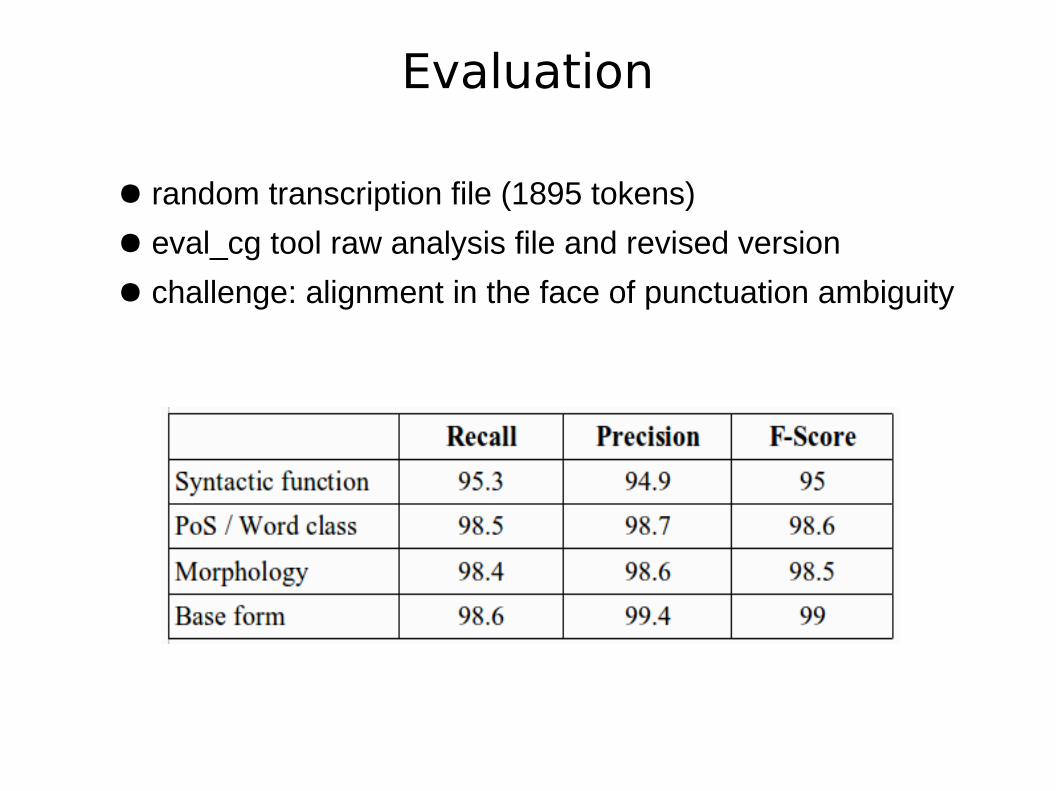
Evaluation
● random transcription file (1895 tokens)
● eval_cg tool raw analysis file and revised version
● challenge: alignment in the face of punctuation ambiguity
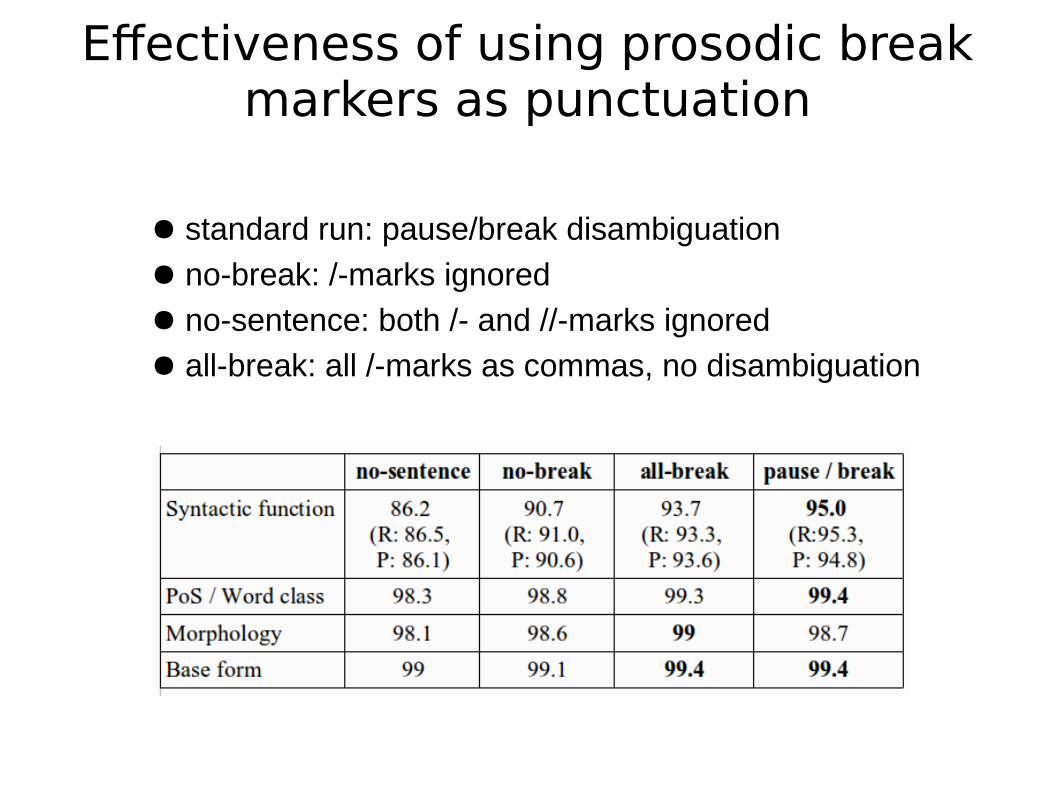
Effectiveness of using prosodic break markers as punctuation
● standard run: pause/break disambiguation● no-break: /-marks ignored● no-sentence: both /- and //-marks ignored● all-break: all /-marks as commas, no disambiguation

using prosodic breaks for syntax:results
● prosodic break markers do help the parser
● more so for syntax than PoS/morphology (wider contextual scope with corresponding segmentation needs)
● pause/break disambiguation more relevant for syntax than PoS

Searchability: Access to C-ORAL and NURC

graphical search interface

concordances
PRP + @SUB + V INF(Preposition + subject + infinitive)
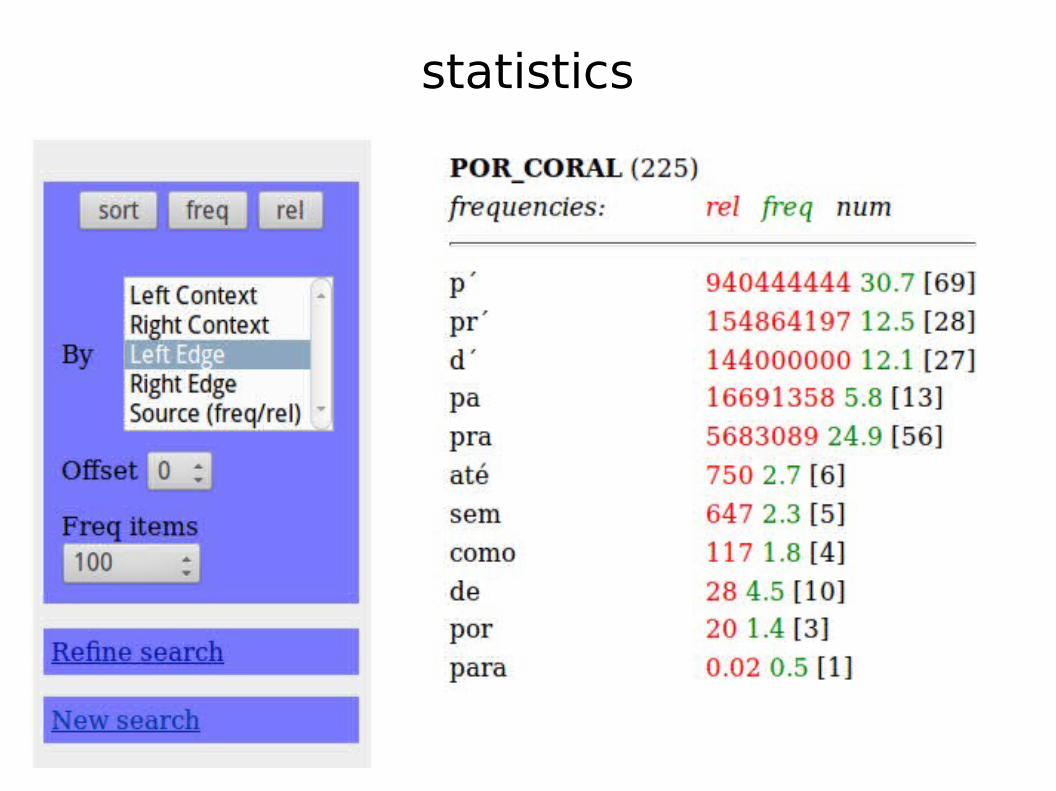
statistics
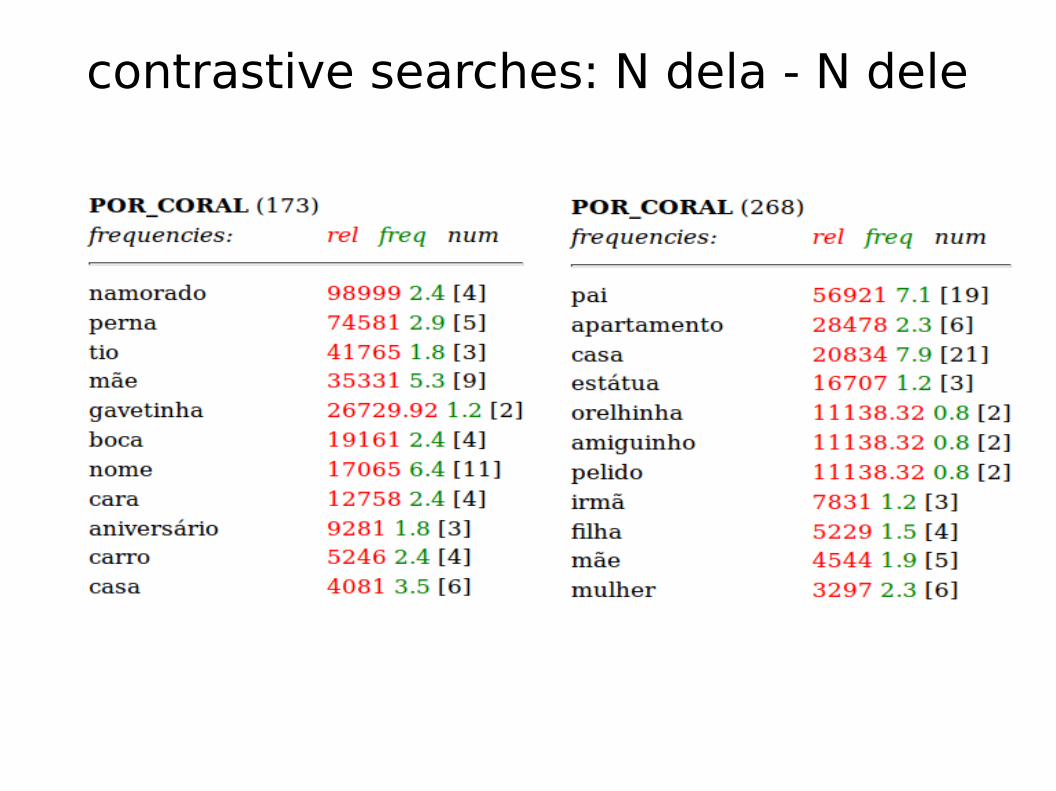
contrastive searches: N dela - N dele

comparative search across corpora
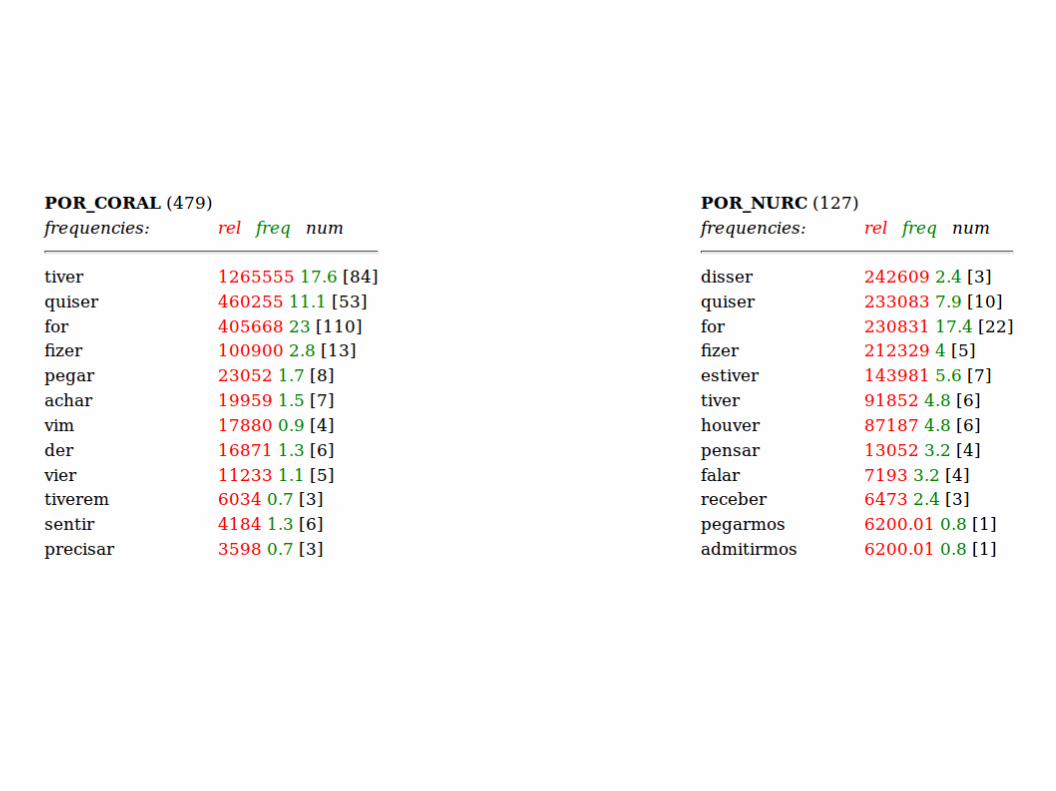

cqp speak: [pos="ADJ" & func="N<"]

Exchange and export formatsC-ORAL dependency annotation in xml format

Annotation alternatives:
VISL Constituent treesfor CORDIAL-SIN:
exports to xml, PENN, TIGER, MALT, CQP ...
(Vila Praia de Âncora, 1999)
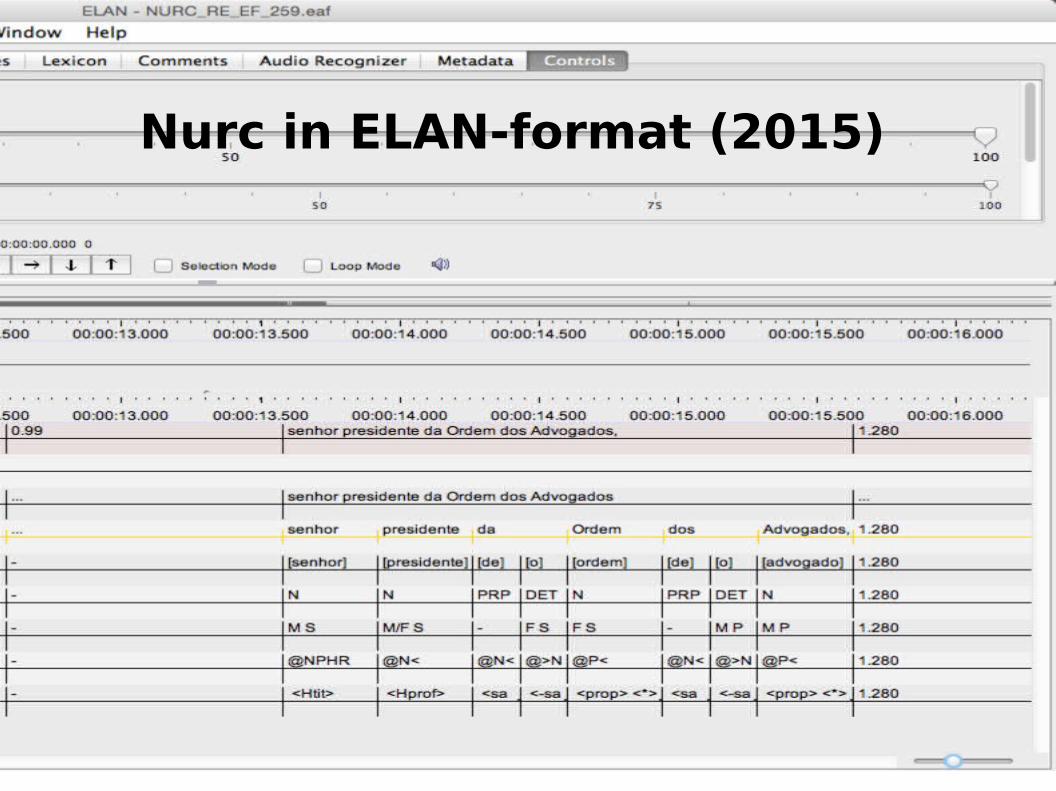
Nurc in ELAN-format (2015)

NURC: time-alignedxml & ELAN
cf. Oliveira & da Silva 2015Projeto NURC DigitalIX LABLITA, Belo Horizonte

Part 2: Speech-like Corpora
Spoken language data are difficult to obtain in large quantities (very time & labour consuming)
Hypothesis: Certain written data may approximate some of the linguistic features of spoken language● Candidates: chat, e-mail, broadcasts, speech and discussion
transcripts, film subtitle files
Topics● Suitable/available corpora
● Tokenization and annotation methodology
● linguistic insights and cross-corpus comparison

The corpora
Enron E-mail Dataset: corporate e-mail (CALO Project)
Chat Corpus 2002-2004 (Project JJ)● (a) Harry Potter, (b) Goth Chat, (c) X Underground, (d)
Amarantus: War in New York
Europarl - English section (Philipp Koehn)● transcribed parliamentary debates
BNC (British National Corpus)● split in (a) written and (b) spoken sections
http://www.cs.cmu.edu/~enron/
Annotation: Constraint Grammer - EngGram (CG3)(demo: http://visl.sdu.dk/en/)

CG adaptations for speech-like data
even a robust parser will suffer a performance decrease when ported from written to data with oral language traits
CG does not need hand-corrected training corpora (which would be hard to find cross-domain, or with unified tagset)
CG guarantees complete cross-domain compatibility, while at the same time allowing specific and repeated domain adaptations● Imperatives --> context rules & lexical statistics
● Questions --> context rules
● oral genre-specific items: interjections, emoticons (smileys)--> lexicon additions (e.g. grg, oy)--> heuristics for "productive" interjections (e.g. oh ooh oooh, uh uh-uh)
● 1. and 2. pronoun frequency, "I"-disambiguation

Imperative vs. infinitive and present tense
written language parsers have an anti-imperative bias
use context to disambiguate imperatives more precicely SELECT (IMP) IF (-1 KOMMA) (*-2 VFIN BARRIER CLB LINK *-1 ("if") BARRIER CLB OR VV LINK *-1 >>> BARRIER NON-ADV/KC)
use lexical likelihood statistics from mixed corpora● "<add>"
– "add" <fr:12> V IMP – "add" <fr:68> V PR -3S – "add" <fr:20> V INF
● "<achieve>" – "achieve" <fr:0> V IMP– "achieve" <fr:4> V PR -3S– "achieve" <fr:96> V INF

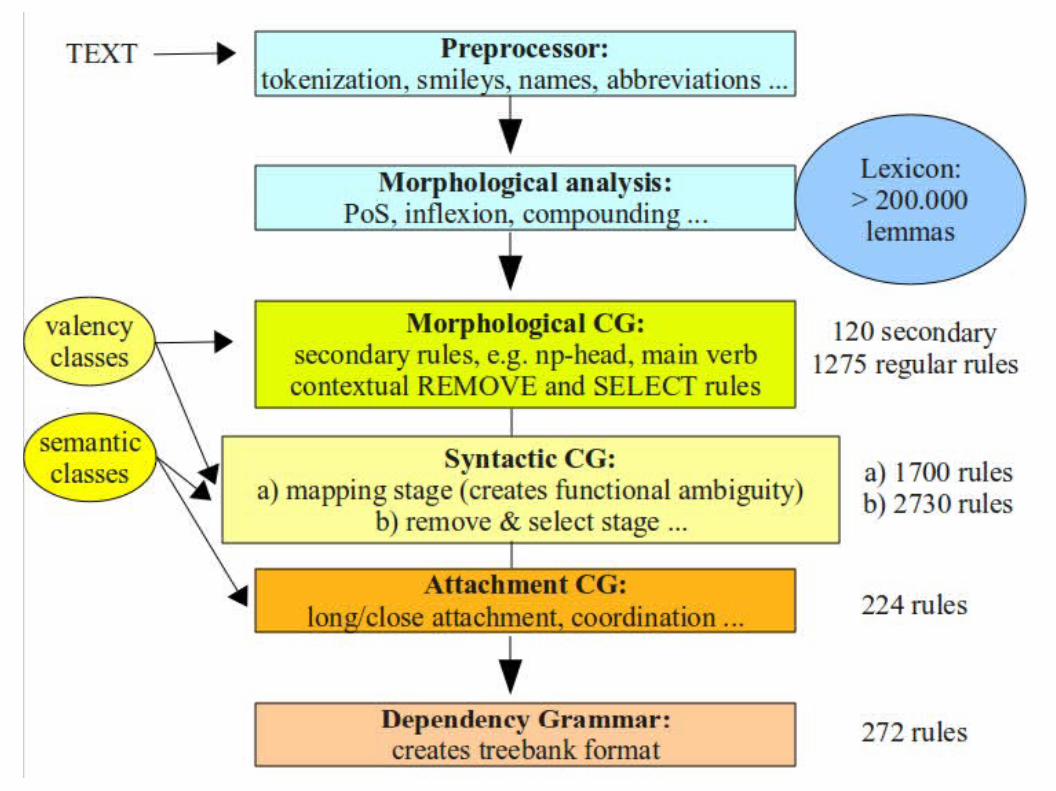
Parsing architecture
multiple modularity● emoticon etc. preprocessing + morphological analysis + CG
● multi-stage CG with rule sets at progressive levels with different annotation tasks
● within each level: rule batches with increasing heuristicity, i.e. safe rules first: 1-2 ... 1-2-3 ... 1-2-3-4 ... 1-2-3-4-5 etc.
lexicon support at all levels, both pos and syntax● valency: <vt>, <+on>, <+INF>, <vtk+ADJ>
● semantic prototypes for nouns <Hprof>, <tool> and some adjectives <jnat> (nationhood), <jgeo> (geographical)
highest level in this project is a kind of live dependency treebank, with all words linked to other words

Cross-corpus parser evaluation
pilot evaluation with small data sets
"soft" gold standard, created from parser output rather than from scratch, no multi-annotator cross-evaluation

Problems with oral-specific traits (especially chat corpus)
Contractions: ● dont, gotta
"phonetic" writing: ● Ravvvvvvvvveeee
unknown or drawn-out interjections read as nouns:● tralalalala
unknown non-noun abbreviations● sup (adjective), rp (infinitive), lol (interjection)
Subject-less sentences● dances about wild and naked ('dances' misread as noun)

Cross-corpus comparison oforality markers
because CG annotation is token based at all levels, even higher-level syntactic information can be used
BNC-written included as a kind of reference corpus for the orally-influenced text types
expected differences along a "linguistic complexity" axis: ● chat < e-mail < Europarl < BNC-oral < BNC-written
high-complexity markers:● verb chain length, sentence length, subordination / subclauses,
would/should-distancing, passive/active ratio for participles
low-complexity markers:● interjections, pronouns
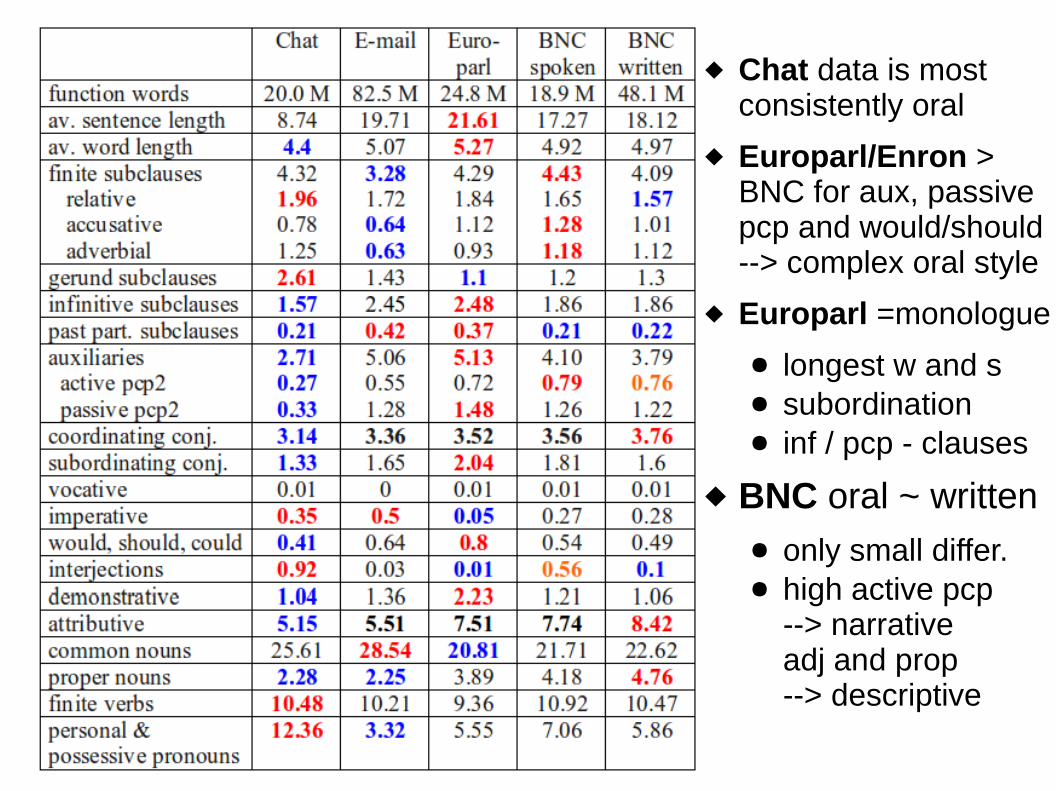
Chat data is most consistently oral
Europarl/Enron > BNC for aux, passive pcp and would/should--> complex oral style
Europarl =monologue
● longest w and s● subordination● inf / pcp - clauses
BNC oral ~ written● only small differ.● high active pcp
--> narrativeadj and prop--> descriptive

Pronouns
2nd person orality cline
monologue:1st > 2nd
lowest relative 3rd--> most personalized
mostpronouns-> deictic
BNC beats email /Europarl on pronouns:coherent narrativity outweighs orality

Emoticons
high incidence, especially in the Chat corpus
Western-tilted rather than Japanese-horizontal or number-letter-integrating
Preprocessed as tokens rather than punctuation
Functionally treated as free or bound adverbials
Happy smileys are most common● unnosed :) more than nosed :-)
● chat > e-mail
● if few smileys are used, the proportion of the common ones will rise
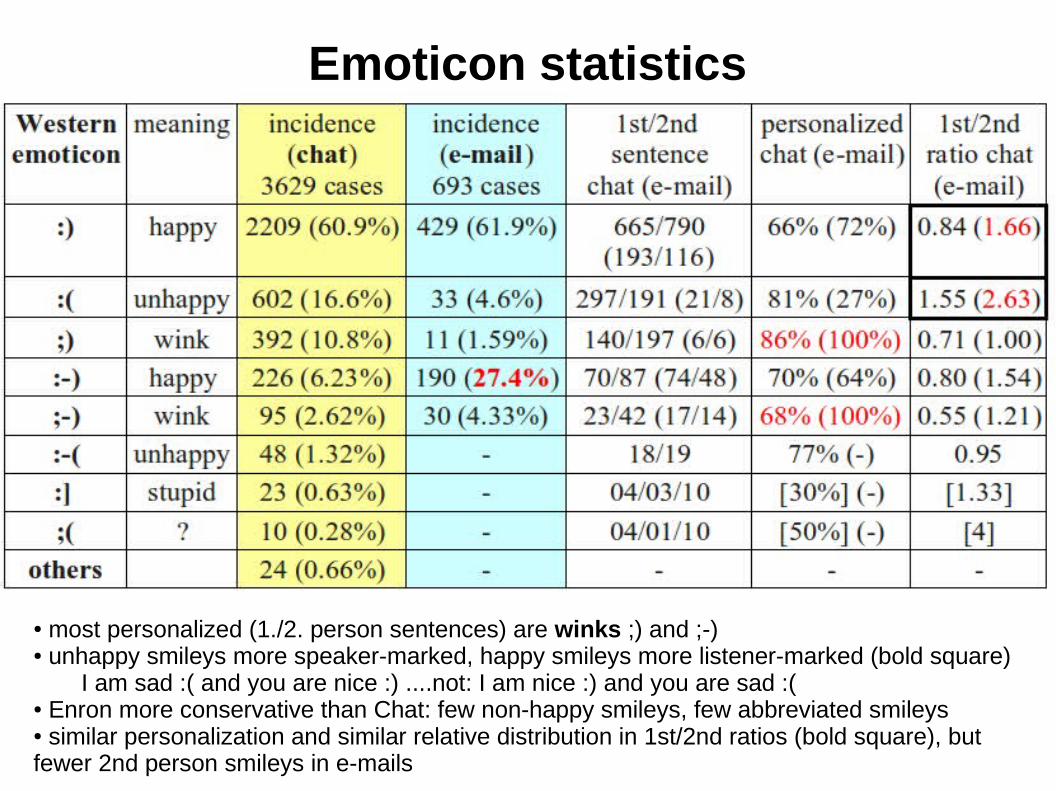
Emoticon statistics
● most personalized (1./2. person sentences) are winks ;) and ;-)● unhappy smileys more speaker-marked, happy smileys more listener-marked (bold square)
I am sad :( and you are nice :) ....not: I am nice :) and you are sad :(● Enron more conservative than Chat: few non-happy smileys, few abbreviated smileys● similar personalization and similar relative distribution in 1st/2nd ratios (bold square), but fewer 2nd person smileys in e-mails

Conclusions
Constraint Grammar is a robust method to handle the annotation of both speech data and speech-like text across varying domains● Standard parser tools will work on such data, with certain modifications
– Orthographical normalization
– Lexicon extensions
– Segmentation: Syntactic use of prosodic markers
● Under optimal conditions, almost-normal F-scores (98% PoS, 95% syntax) can be achieved for both transcribed speech and written data of modes orality, but not for chat, which is hardest to annotate
Certain types of oral language features can be examined and quantified in certain types of text corpora rather than traditional transcribed speech corpora, provided that problems such as emoticons, interjections and imperatives are treated reliably
Distribution of orality markers is neither uniform nor consistently bundled across corpus types● Chat data is most consistenly "oral"
● E-mail is most personalized, but more "written" than chat - reminiscent, in fact, of traditional letters
● Europarl as formal spoken monologue has some features that are more "written" than ordinary text
● Some literary sources of spoken language (BNC plays/radio?) are not as "oral" as one would expect

Outlook
● Annotation scheme does preserve the original prosodic-transcriptional information (speech flow, retractions, overlaps etc.) encoded as metatagging alongside morphosyntactic tags, but how to make this accessible to GUI searches searchable now on with grammar: prosodic breaks not searchable now: speech flow, retractions, overlaps
● Wish lish: higher level annotation: Dependency (done) semantic classes and roles anaphoric relations ....

Outlook
Higher-level analysis (semantic roles, anaphora)
Error analysis targeting inter-corpus differences
Genre-specific rule modules and CG use of genre-indicating meta-tags
Very "oral" text (chat corpus, twitter):● use of 2 orthographic levels as in transcribed speech or
historical texts
Corpus searchability● How to include speech flow, retractions, overlaps

Parsers: http://beta.visl.sdu.dkCorpora: http://corp.hum.sdu.dk

References 1
Bick, Eckhard. 2000. The Parsing System Palavras - Automatic Grammatical Analysis of Portuguese in a Constraint Grammar Framework, Aarhus: Aarhus University Press
Bick, Eckhard. 1998. Tagging Speech Data - Constraint Grammar Analysis of Spoken Portuguese, in: Proceedings of the 17th Scandinavian Conference of Linguistics (Odense 1998)
Bick, Eckhard & Marcelo Módolo. 2005. Letters and Editorials: A grammatically annotated corpus of 19th century Brazilian Portuguese. In: Claus Pusch & Johannes Kabatek & Wolfgang Raible (eds.) Romance Corpus Linguistics II: Corpora and Historical Linguistics (Proceedings of the 2nd Freiburg Workshop on Romance Corpus stics, Sept. 2003). pp. 271-280. Tübingen: Gunther Narr Verlag.
Brill, Eric. 1992. A simple rule-based part of speech tagger. In: Proceedings of the workshop on Speech and Natural Language. HLT '91, Morristown, NJ, USA: Association for Computational Linguistics, pp.112–116
Castilho, Ataliba de (ed.), 1993. Gramática do Português Falado, vol.3, Campinas: Editora da Unicamp.
Johannessen, Janne Bondi, Joel Priestley, Kristin Hagen, Tor Anders Åfarli, and Øystein Alexander Vangsnes. 2009. The Nordic Dialect Corpus - an Advanced Research Tool. In Jokinen, Kristiina and Eckhard Bick (eds.): Proceedings of the 17th Nordic Conference of Computational Linguistics NODALIDA 2009. NEALT Proceedings Series Volume 4
Karlsson, Fred & Voutilainen, Atro & Heikkilä, Juka & Anttila, Arto. 1995. Constraint Grammar, A Language-Independent System for Parsing Unrestricted Text. Berlin: Mouton de Gruyter.

References 2
Maamouri, Mohamed et al. 2010. From Speech to Trees: Applying Treebank Annotation to Arabic Broadcast News. In: Proceedings of LREC 2010, Valletta, Malta, May 2010.
Moreno, A. & J.M. Guirão. 2003. "Tagging a spontaneous speech corpus of Spanish". In: Proceedings of the International Conference on Recent Advances in Natural Language Processing.). Borovets, Bulgaria, 2003. p. 292-296.
Müürisep, Kaili and Uibo, Heli (2006). "Shallow Parsing of Spoken Estonian Using Constraint Grammar". In: P.J.Henriksen & P.R.Skadhauge, Proceedings of NODALIDA-2005 special session on treebanking. Copenhagen Studies in Language #33/2006
Moneglia, M., A. Panunzi, E. Picchi, 2004, Using PiTagger for Lemmatization and PoS Tagging of a Spontaneous Speech Corpus : C-Oral-Rom Italian. In M.T. Lino et al. (eds.), Proceedings of the 4th LREC Conference, vol. 2, ELRA, Paris, pp. 563-566.
Raso, Tommaso & Heliana Mello. 2010. The C-ORAL BRASIL corpus. In: Massimo Moneglia & Alessandro Panunzi (eds): Bootstrapping Infromation from Corpora in a Cross-Linguistic Perspective. Universitá degli studi di Firenze, Biblioteca Digitale.
Schmid, Helmut. 1994. Probabilistic Part-of-Speech Tagging Using Decision Trees. Proceedings of the International Conference on New Methods in Language Processing 1994. pp. 44-49.





























