Embed Size (px)
Citation preview

The Beauty of Local Invariant FeaturesThe Beauty of Local Invariant Features
Svetlana LazebnikSvetlana LazebnikBeckman Institute, University of Illinois at Urbana-ChampaignBeckman Institute, University of Illinois at Urbana-Champaign
IMA Recognition WorkshopIMA Recognition Workshop
University of MinnesotaUniversity of Minnesota
May 22, 2006May 22, 2006
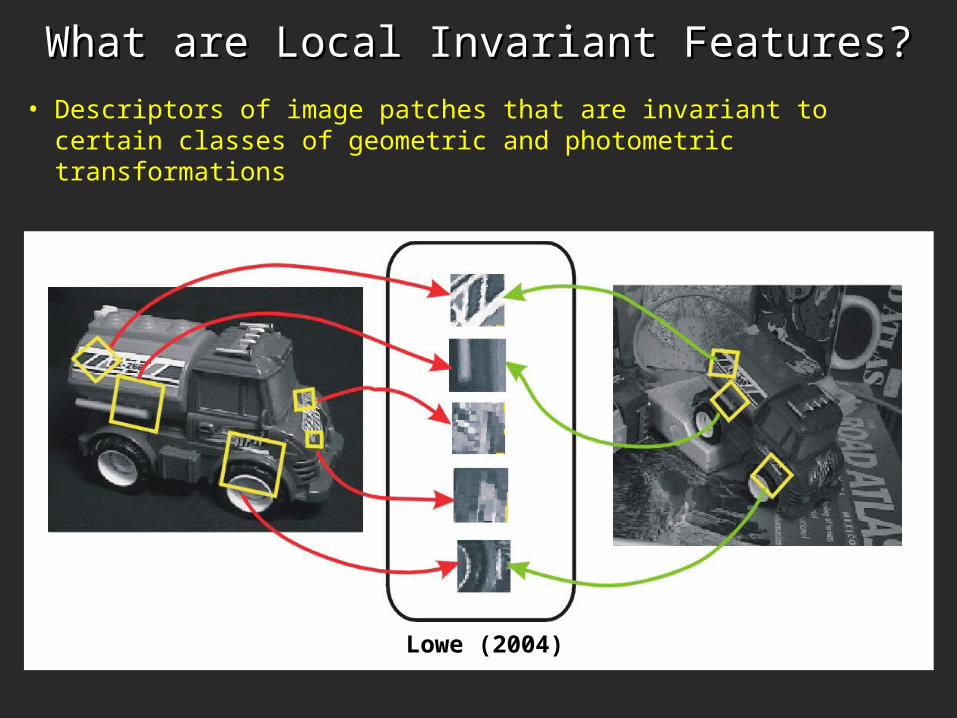
What are Local Invariant Features?What are Local Invariant Features?
• Descriptors of image patches that are invariant to certain classes of geometric and photometric transformations
Lowe (2004)

A Historical PerspectiveA Historical Perspective
ACRONYM: Brooks and Binford (1981)Alignment: Huttenlocher & Ullman (1987)Invariants: Rothwell et al. (1992)
Model-based methods: local shape, no appearance information
Appearance-based methods: global appearance, no local shape
Eigenfaces: Turk & Pentland (1991)Appearance manifolds: Murase & Nayar (1995)Color histograms: Swain & Ballard (1990)
Local invariant features: local shape + appearance pattern
+

Feature Detection and DescriptionFeature Detection and Description
covariant detection
1. Detect regions
invariant description
3. Compute appearancedescriptors
SIFT: Lowe (2004)
2. Normalize regions

AdvantagesAdvantages
• Locality– Robustness to clutter and occlusion
• Repeatability– The same feature occurs in multiple images of the same scene or class
• Distinctiveness– Salient appearance pattern that provides strong matching constraints
• Invariance– Allow matching despite scale changes, rotations, viewpoint changes
• Sparseness– Relatively few features per image, compact and efficient representation
• Flexibility– Many existing types of detectors, descriptors

Scale-Covariant DetectorsScale-Covariant Detectors• Laplacian, Hessian, Difference-of-Gaussian (blobs)
Lindeberg (1998), Lowe (1999, 2004)
• Harris-Laplace (corners) Mikolajczyk & Schmid (2001)

Scale-Covariant DetectorsScale-Covariant Detectors
• Salient (high entropy) regions Kadir & Brady (2001)
• Circular edge-based regions Jurie & Schmid (2003)

• Laplacian, Hessian-Affine (blobs) Gårding & Lindeberg (1996), Mikolajczyk et al. (2004)
• Harris-Affine (corners) Mikolajczyk & Schmid (2002)
Affine-Covariant DetectorsAffine-Covariant Detectors

Affine-Covariant DetectorsAffine-Covariant Detectors
• Edge- and intensity-based regions Tuytelaars & Van Gool (2004)
• Maximally stable extremal regions (MSER) Matas et al. (2002)

Types of DescriptorsTypes of Descriptors
• Differential invariants Koenderink & Van Doorn (1987), Florack et al. (1991) • Filter banks: complex, Gabor, steerable, …• Multidimensional histograms
PCA-SIFT: Ke & Sukthankar (2004)GLOH: Mikolajczyk & Schmid (2004)
Johnson & Hebert (1999)Lazebnik, Schmid & Ponce (2003)
Lowe (1999, 2004)Belongie, Malik & Puzicha (2002)

Applications (1)Applications (1)• Wide-baseline matching and recognition of specific objects
Tuytelaars & Van Gool (2004)
Rothganger, Lazebnik, Schmid & Ponce (2005)
Ferrari, Tuytelaars & Van Gool (2005)
Lowe (2004)

Applications (2)Applications (2)• Category-level recognition based on geometric
correspondence
Berg, Berg & Malik (2005)
Lazebnik, Schmid & Ponce (2004)
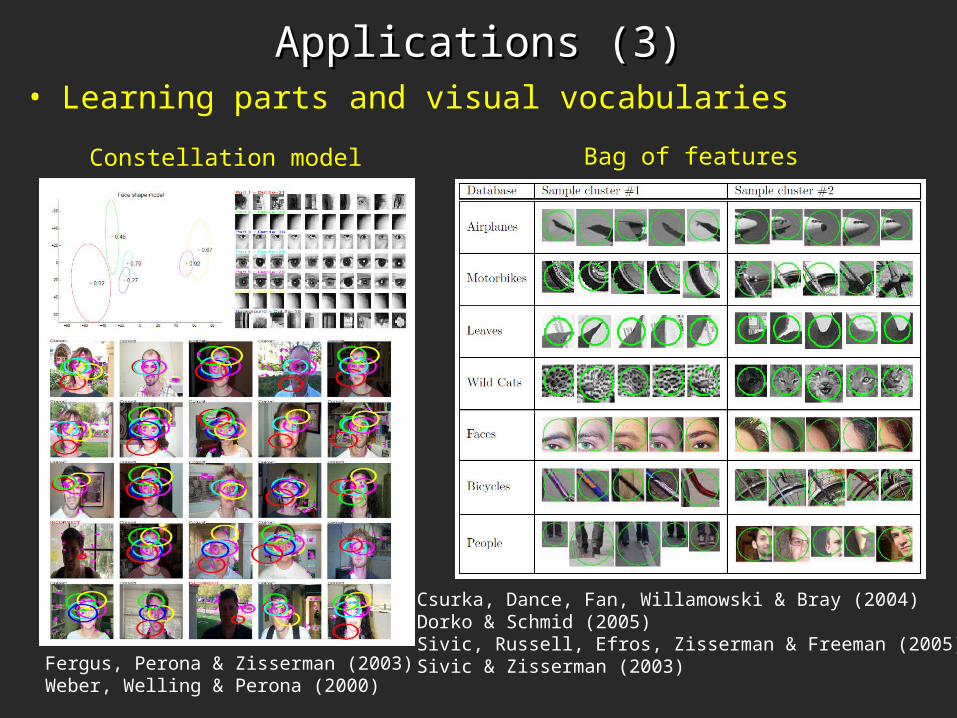
Applications (3)Applications (3)• Learning parts and visual vocabularies
Constellation model
Csurka, Dance, Fan, Willamowski & Bray (2004)Dorko & Schmid (2005)Sivic, Russell, Efros, Zisserman & Freeman (2005)Sivic & Zisserman (2003)
Bag of features
Fergus, Perona & Zisserman (2003)Weber, Welling & Perona (2000)

Applications (4)Applications (4)• Building global image models invariant to a wide range of
deformations
Lazebnik, Schmid & Ponce (2005)

Comparative EvaluationsComparative Evaluations• Flat scenes Mikolajczyk & Schmid (2004), Mikolajczyk et al. (2004)
– MSER and Hessian regions have the highest repeatability– Harris and Hessian regions provide the most correspondences– SIFT (GLOH, PCA-SIFT) descriptors have the highest performance
• 3D objects Moreels & Perona (2006)
– Features on 3D objects are much more unstable than on planar objects– All detectors and descriptors perform poorly for viewpoint changes > 30°– Hessian with SIFT or shape context perform best

• Object classes Mikolajczyk, Liebe & Schiele (2005)
– Hessian regions with GLOH perform best– Salient regions work well for object classes
• Texture and object classes Zhang, Marszalek, Lazebnik & Schmid (2005)
– Laplacian regions with SIFT perform best– Combining multiple detectors and descriptors improves performance– Scale+rotation invariance is sufficient for most datasets
Comparative EvaluationsComparative Evaluations

Sparse vs. Dense Features: Sparse vs. Dense Features: UIUC texture datasetUIUC texture dataset
Lazebnik, Schmid & Ponce (2005)
25 classes, 40 samples each

Sparse vs. Dense Features: Sparse vs. Dense Features: UIUC texture datasetUIUC texture dataset
• A system with intrinsically invariant features can learn from fewer training examples
Invariant local features
Non-invariant dense patches
Baseline(global features)
SVM
Zhang, Marszalek, Lazebnik & Schmid (2005)
SVM
NN
NN
Multi-class classification accuracy vs. training set size
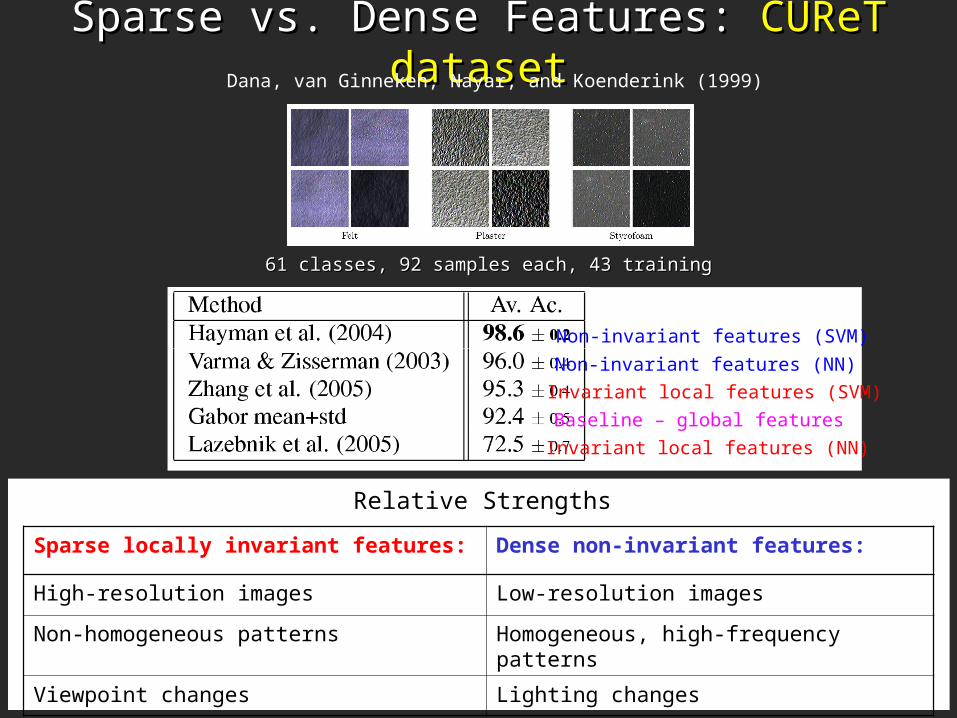
Sparse vs. Dense Features: Sparse vs. Dense Features: CUReT datasetCUReT dataset
Sparse locally invariant features: Dense non-invariant features:
High-resolution images Low-resolution images
Non-homogeneous patterns Homogeneous, high-frequency patterns
Viewpoint changes Lighting changes
Relative Strengths
61 classes, 92 samples each, 43 training61 classes, 92 samples each, 43 training
Dana, van Ginneken, Nayar, and Koenderink (1999)
Invariant local features (SVM)
Non-invariant features (SVM)
Baseline – global features
Invariant local features (NN)
Non-invariant features (NN)

Anticipating CriticismAnticipating Criticism• Existing local features are not ideal for category-level
recognition and scene understanding– Designed for wide-baseline matching and specific object recognition
– Describe texture and albedo pattern, not shape
– Do not explain the whole image
• A little invariance goes a long way– It is best to use features with the lowest level of invariance required
by a given task– Scale+rotation is sufficient for most datasets
Zhang, Marszalek, Lazebnik & Schmid (2005)
• Denser sets of local features are more effective – Hessian detector produces the most regions and performs best in several
evaluations– Regular grid of fixed-size patches is best for scene category recognition
Fei-Fei & Perona (2005)

Future WorkFuture Work
• Systematic evaluation of sparse vs. dense features• Combining sparse and dense representations,
e.g., keypoints and segments Russell, Efros, Sivic, Freeman & Zisserman (2006)
• Learning detectors and descriptors automatically• Developing shape-based features





























