Embed Size (px)
Citation preview

Megha Daga
Sr Manager, Product Marketing & Management, AI, Cadence IP Group
Feb 17, 2019
Tensilica DNA 100 Processor: A High-Performance, Power-Efficient DNN Processor for On-Device Inference

2 © 2019 Cadence Design Systems, Inc. All rights reserved.
AI Experiences are Everywhere
“Alexa, Add a 2pm meeting to my calendar”

3 © 2019 Cadence Design Systems, Inc. All rights reserved.
Majority of AI Inferences Are in the Cloud
“Alexa, when is my
new camera arriving?”
Smart Assistant
Voice search
Travel Assistant
Translation
Navigation Assistant
Store finder
AI in
Cloud

4 © 2019 Cadence Design Systems, Inc. All rights reserved.
On-Device AI – Why?
Low Latency requirements
• Natural dialogue in speech assistants - requires less than 200 ms latency
• Real time decision making in Automotive, Robots, etc. need low latency
Lack of Good Connectivity
• Smart City cameras are hard to connect to existing network
• Inspection drones for wind turbines and power lines operate in rural areas
Privacy
• Smart home video cameras and smart assistants – consumers desire privacy
‒ Baby monitors, home security cameras – can devices generate alerts?
‒ Voice assistants – keyword detection today small vocabulary recognition?

5 © 2019 Cadence Design Systems, Inc. All rights reserved.
On-Device AI Processing Needs Are Increasing
Mobile
• On-device AI experiences like face detection and people recognition at videocapture rates
AR/VR headsets
• On-device AI for object detection, people recognition, gesture recognition,and eye tracking
Surveillance cameras
• On-device AI for family or stranger recognition and anomaly detection
Automotive
• On-device AI to recognize pedestrians, cars, signs, lanes, driver alertness, etc. for ADAS and AV
Drones and robots
• On-device AI to recognize subjects, objects, obstacles, emotions, etc.

6 © 2019 Cadence Design Systems, Inc. All rights reserved.
Target Markets for On-Device AI Inferencing
IoT
< 0.5TMAC
AR/VR
1 - 4TMACs
Mobile
0.5 - 2TMACs
Autonomous Vehicles
10s - 100s TMACs
Smart Surveillance
2 - 10TMACs

7 © 2019 Cadence Design Systems, Inc. All rights reserved.
Tensilica DNA 100 Processor IP for AI
Tensilica®
Application-
Specific DSPs
Tensilica AI
DSPs
Vision C5
DSP
DNA 100
Processor
Tensilica Standalone AI Processor IP
AI
Perf
orm
an
ce
0.5 to 100s of TMACs
8 © 2019 Cadence Design Systems, Inc. All rights reserved.
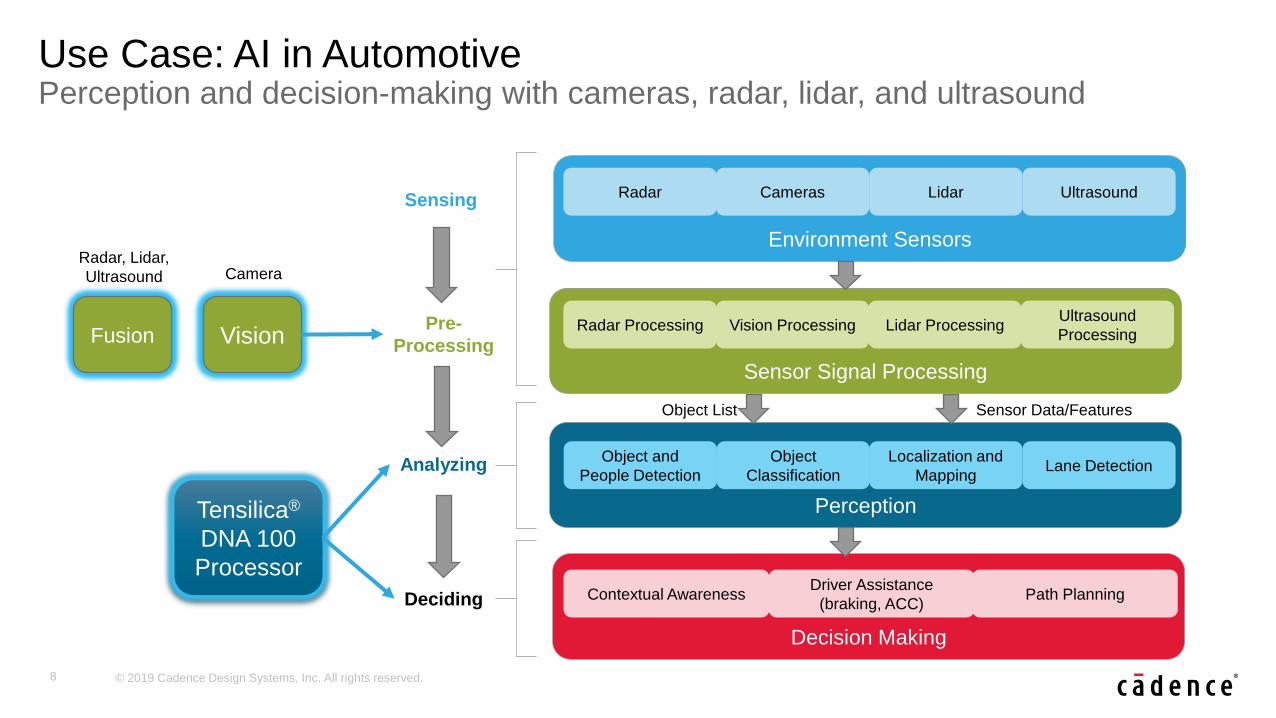
Use Case: AI in AutomotivePerception and decision-making with cameras, radar, lidar, and ultrasound
Environment Sensors
CamerasRadar Lidar Ultrasound
Perception
Object
Classification
Object and
People Detection
Localization and
MappingLane Detection
Decision Making
Driver Assistance
(braking, ACC)Contextual Awareness Path Planning
Sensor Signal Processing
Vision ProcessingRadar Processing Lidar ProcessingUltrasound
Processing
Sensing
Analyzing
Deciding
Pre-
Processing
Object List Sensor Data/Features
Vision
Tensilica®
DNA 100
Processor
Fusion
Radar, Lidar,
Ultrasound Camera

9 © 2019 Cadence Design Systems, Inc. All rights reserved.
AXI Interconnect
Tensilica DNA 100 Processor Block DiagramSparse compute engine with high MAC utilization
I/O DMA
Compression/
Decompression
Tensor
Fetch
Coefficient
RAM
Activation
RAM
QuantizationPooling/Vector
Processing Unit
Tightly Coupled
Tensilica® DSP
Data
RAM 0
Data
RAM 1TIEQ
TIEPort
Interrupt
128b/256b
Master (1 to 4)128b Slave
128b Master128b
IDMA Master128b Slave
Output
RAM
Scalable Sparse
Compute
Engine

10 © 2019 Cadence Design Systems, Inc. All rights reserved.
AXI Interconnect
Tensilica DNA 100 Processor Block DiagramSparse compute engine with high MAC utilization
I/O DMA
Compression/
Decompression
Tensor
Fetch
Coefficient
RAM
Activation
RAM
QuantizationPooling/Vector
Processing Unit
Tightly Coupled
Tensilica® DSP
Data
RAM 0
Data
RAM 1TIEQ
TIEPort
Interrupt
128b/256b
Master (1 to 4)128b Slave
128b Master128b
IDMA Master128b Slave
Output
RAM
✓ Bandwidth reduction
• Weight compression
• Activation compression
✓ Compute reduction
• Non-zero MAC operations only
✓ Efficient convolution and fully connected
• High MAC occupancy rate
✓ Non-convolution layers
• Pooling
• Sigmoid, tanh…
• Elementwise add, sub…
✓ Programmable
• Future proof
✓ Extensible
• Custom layers
Scalable Sparse
Compute
Engine
Tensilica DNA 100 supports key requirements for on-device AI processing

11 © 2019 Cadence Design Systems, Inc. All rights reserved.
AXI Interconnect
Neural Network Mapping onto Tensilica DNA 100 ProcessorAn example
I/O DMA
Compression/
Decompression
Tensor
Fetch
Coefficient
RAM
Activation
RAM
QuantizationPooling/Vector
Processing Unit
Tightly Coupled
Tensilica® DSP
Data
RAM 0
Data
RAM 1TIEQ
TIEPort
Interrupt
128b/256b
Master (1 to 4)128b Slave
128b Master128b
IDMA Master128b Slave
Output
RAM
Scalable Sparse
Compute
Engine
12 © 2019 Cadence Design Systems, Inc. All rights reserved.
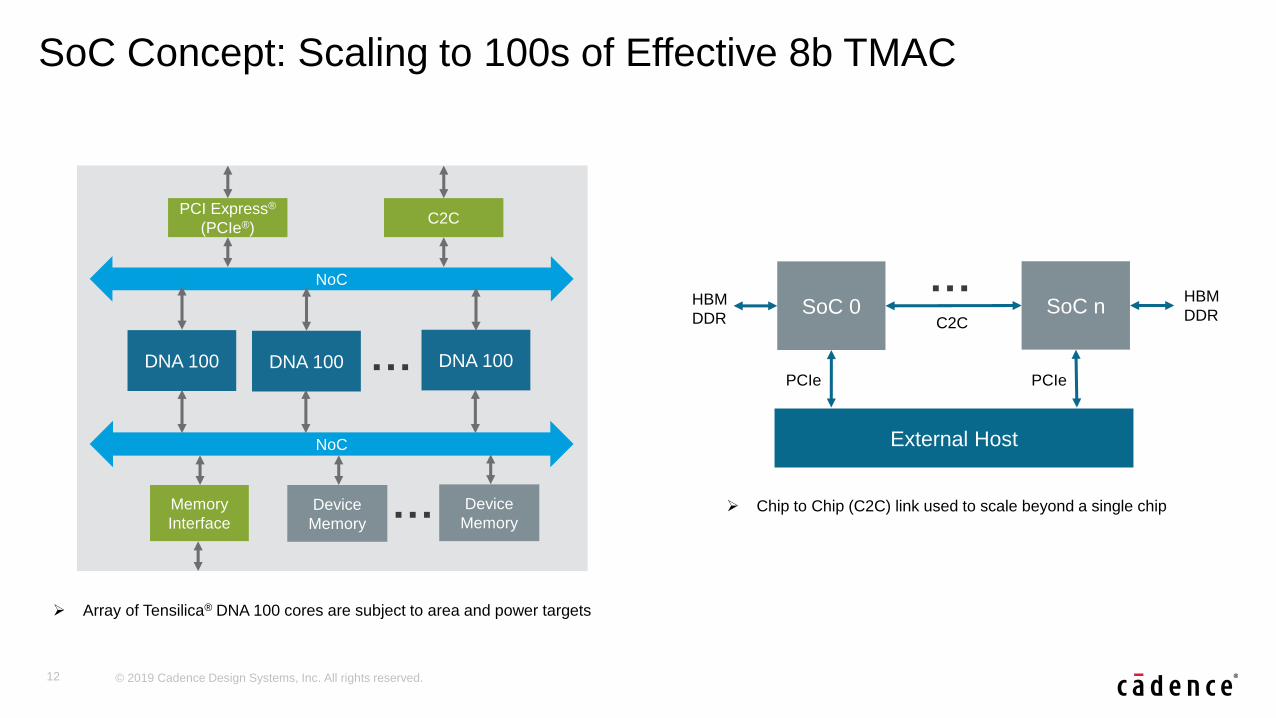
SoC Concept: Scaling to 100s of Effective 8b TMAC
➢ Array of Tensilica® DNA 100 cores are subject to area and power targets
…
External Host
PCIe PCIe
C2C
HBM
DDR
HBM
DDR
➢ Chip to Chip (C2C) link used to scale beyond a single chip
NoC
Device
Memory
…
NoC
Memory
Interface
PCI Express®
(PCIe®)C2C
DNA 100 DNA 100DNA 100
SoC 0 SoC n
Device
Memory…

13 © 2019 Cadence Design Systems, Inc. All rights reserved.
Effective MAC on Tensilica® DNA 100 Processor Enabled by sparse compute engine
Physical
Array Size
Effective TMAC or Performance @ 1GHz
No Network Pruning1 With Network Pruning2
256MAC
2X0.5TMAC
3X0.75TMAC
1K MAC 2TMAC 3TMAC
4K MAC 8TMAC 12TMAC
1 For 15% sparse weights and 50% sparse activation
2 For 35% sparse weights and 60% sparse activation
Network pruning and re-training provides higher sparsity

14 © 2019 Cadence Design Systems, Inc. All rights reserved.
Tensilica DNA 100 Processor Performance – Up to 4.7X CompetitionEnabled by sparse compute and high MAC utilization
DNA 100
4TMAC
Competition
4TMAC
Competition
4TMAC
4.7X
2550fps
Competition
4TMAC
Competition
4TMAC
Competition
4TMAC
538fps 538fps 538fps 538fps 398fps
• Tensilica® DNA 100 processor performance on ResNet50 @ 1GHz is 2550 frames per second (fps)
• Tensilica DNA 100 processor and competition are both 4KMAC physical array configuration
• Tensilica DNA 100 processor numbers are with network pruning
‒ Assuming 35% sparse weights and 60% sparse activation
15 © 2019 Cadence Design Systems, Inc. All rights reserved.
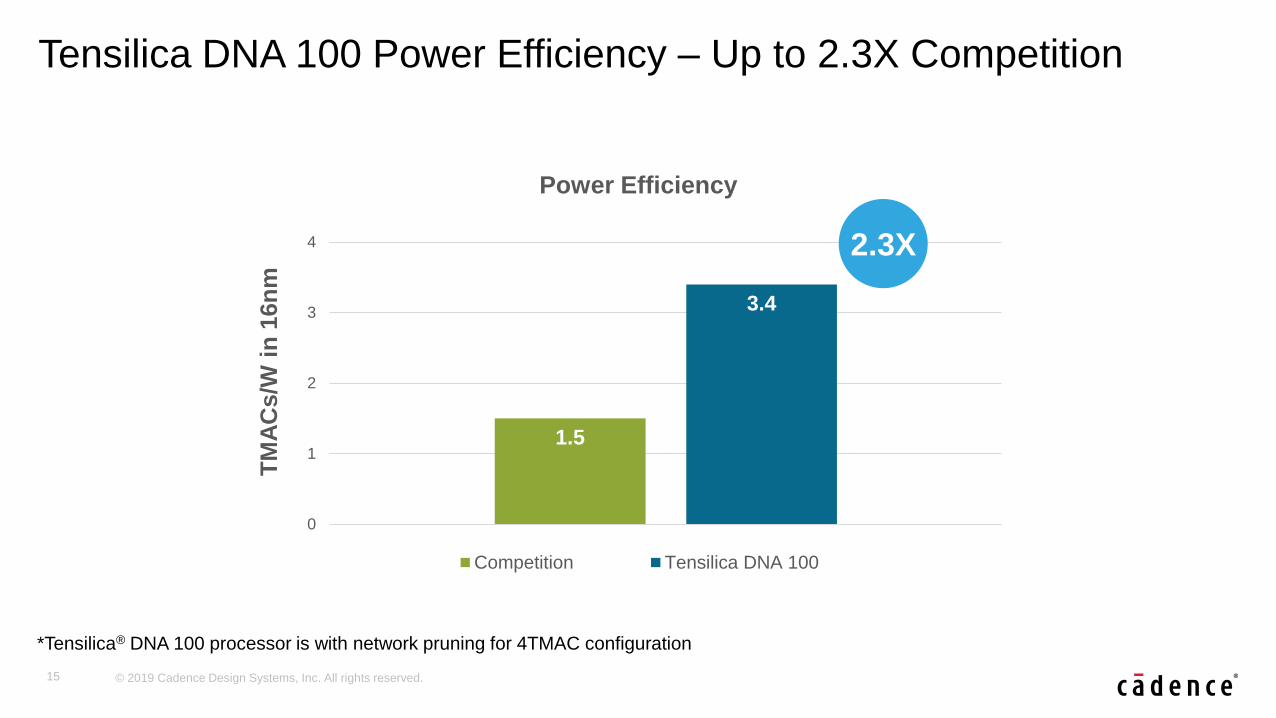
Tensilica DNA 100 Power Efficiency – Up to 2.3X Competition
1.5
3.4
0
1
2
3
4
TM
AC
s/W
in
16n
m
Power Efficiency
Competition Tensilica DNA 100
2.3X
*Tensilica® DNA 100 processor is with network pruning for 4TMAC configuration

16 © 2019 Cadence Design Systems, Inc. All rights reserved.
Android Neural Network App
AI Software Platform
Tensilica DNA 100 Code
Network Optimizer
Neural Network Descriptor
Tensilica® Neural Network Compiler
Network Analyzer/Quantizer to 8b and 16b
Target-Specific Library Selection
DMA and Tile Manager
Android Neural Network Runtime
Android Neural Network API
Android Neural Network HAL
Tensilica IP Neural Network Driver
Tensilica DNA 100 Code
Lite
Cadence® Tool
Cadence SW Runtime
User Code
Tensilica Processor
Android NN API Code

17 © 2019 Cadence Design Systems, Inc. All rights reserved.
Cadence Tensilica® Supports Facebook’s Glow
Integrating Facebook’s Glow, an open-source machine learning compiler based on
LLVM, to enable a modular, robust, and easily extensible approach
https://code.fb.com/ml-applications/glow-a-community-driven-approach-to-ai-infrastructure/
18 © 2019 Cadence Design Systems, Inc. All rights reserved.
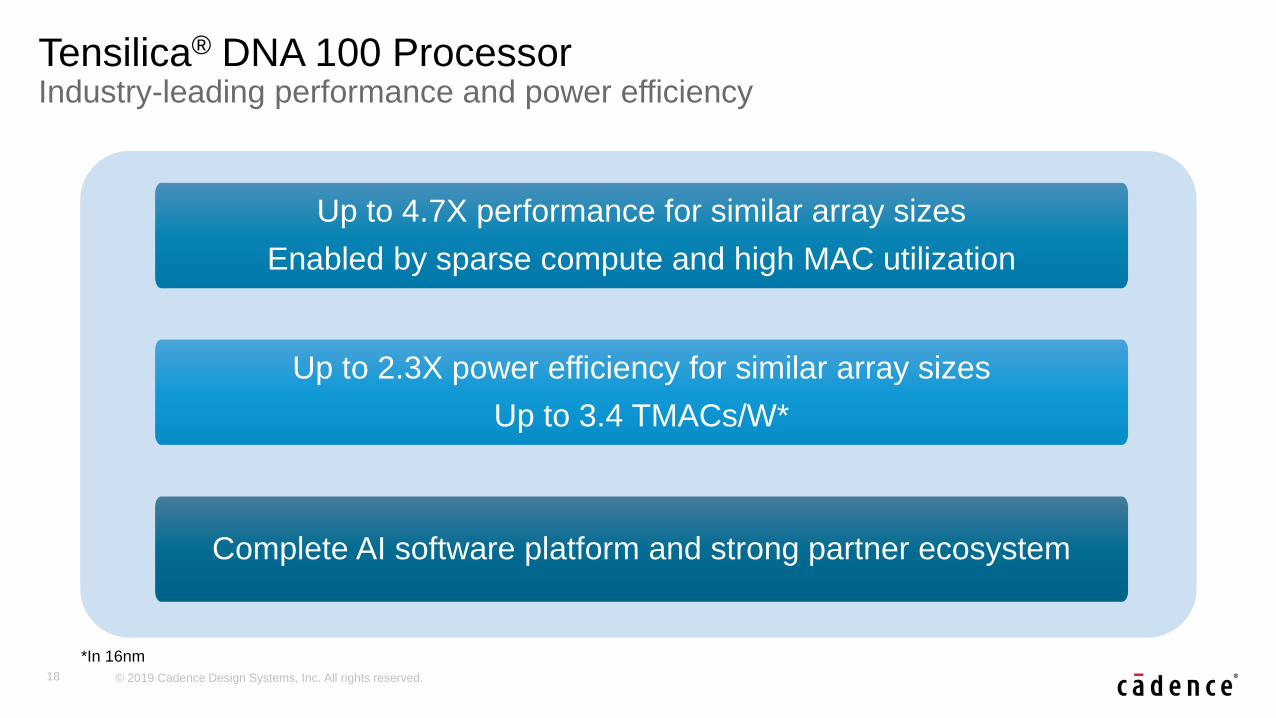
Tensilica® DNA 100 ProcessorIndustry-leading performance and power efficiency
Up to 2.3X power efficiency for similar array sizes
Up to 3.4 TMACs/W*
Up to 4.7X performance for similar array sizes
Enabled by sparse compute and high MAC utilization
Complete AI software platform and strong partner ecosystem
*In 16nm

© 2019 Cadence Design Systems, Inc. All rights reserved worldwide. Cadence, the Cadence logo, and the other Cadence marks found at www.cadence.com/go/trademarks are trademarks or registered trademarks of Cadence Design
Systems, Inc. Accellera and SystemC are trademarks of Accellera Systems Initiative Inc. All Arm products are registered trademarks or trademarks of Arm Limited (or its subsidiaries) in the US and/or elsewhere. All MIPI
specifications are registered trademarks or service marks owned by MIPI Alliance. All PCI-SIG specifications are registered trademarks or trademarks of PCI-SIG. All other trademarks are the property of their respective owners.





























