Embed Size (px)
Citation preview

TDT4173 Machine LearningDecision Trees, Hypothesis Testing, and Learning Theory
Norwegian University of Science and Technology
Helge LangsethIT-VEST 310
1 TDT4173 Machine Learning

Outline
1 Wrap-up from last time2 Decision trees
BasicsEntropy and ID3BiasOverfitting
3 Evaluating hypothesisSample error, true errorEstimatorsConfidence intervals for observed hypothesis errorComparing hypothesisComparing learners
4 Computational Learning TheoryBackgroundBounding the errorPAC learning
2 TDT4173 Machine Learning

First Assignment
First assignment is out
Should be delivered by September 6th at 20:00.
Question time:Wednesdays 1215 – 1400 in Lars Bungums office (IT-VestRoom 359).
Remember:If you for some reason do not pass the assignment it will take3.33 points from the top of your evaluation (out of the max.100 points).
3 TDT4173 Machine Learning

Wrap-up from last time
Summary-points from last lesson
1 Hypothesis space:
Concept learning as search through HGeneral-to-specific ordering over H
2 Version spaces:
Version space candidate elimination algorithm
S and G boundaries characterize learner’s uncertainty
3 Inductive bias:
Inductive leaps possible only if learner is biased
Inductive learners can be modelled by equivalent deductive
systems
4 TDT4173 Machine Learning

Decision trees Basics
Training Examples for EnjoySport
Day Outlook Temperature Humidity Wind EnjoySport
D1 Sunny Hot High Weak NoD2 Sunny Hot High Strong NoD3 Overcast Hot High Weak YesD4 Rain Mild High Weak YesD5 Rain Cool Normal Weak YesD6 Rain Cool Normal Strong NoD7 Overcast Cool Normal Strong YesD8 Sunny Mild High Weak NoD9 Sunny Cool Normal Weak YesD10 Rain Mild Normal Weak YesD11 Sunny Mild Normal Strong YesD12 Overcast Mild High Strong YesD13 Overcast Hot Normal Weak YesD14 Rain Mild High Strong No
5 TDT4173 Machine Learning

Decision trees Basics
Decision Tree for EnjoySport
Outlook
Overcast
Humidity
NormalHigh
No Yes
Wind
Strong Weak
No Yes
Yes
RainSunny
6 TDT4173 Machine Learning

Decision trees Basics
Decision Trees
Decision tree representation:
Each internal node tests an attribute
Each branch corresponds to attribute value
Each leaf node assigns a classification
7 TDT4173 Machine Learning

Decision trees Basics
When to Consider Decision Trees
Instances describable by attribute–value pairs
Target function is discrete valued
Disjunctive hypothesis may be required
Possibly noisy training data
Examples:
Equipment or medical diagnosis
Credit risk analysis
Classifying email as spam or ham
8 TDT4173 Machine Learning

Decision trees Basics
Top-Down Induction of Decision Trees
Main loop:
1 A← the best decision attribute for next node
2 Assign A as decision attribute for node
3 For each value of A, create new descendant of node
4 Sort training examples to leaf nodes
5 If training examples perfectly classified, Then STOP, elseiterate over new leaf nodes
9 TDT4173 Machine Learning

Decision trees Basics
Hypothesis Space Search
...
+ + +
A1
+ – + –
A2
A3+
...
+ – + –
A2
A4–
+ – + –
A2
+ – +
... ...
–
10 TDT4173 Machine Learning

Decision trees Entropy and ID3
Entropy
Ent
ropy
(S)
1.0
0.5
0.0 0.5 1.0p+
S is a sample of training examples
p⊕ is the proportion of positive examples in S
p⊖ is the proportion of negative examples in S
Entropy measures the impurity of S
Entropy(S) ≡ −p⊕ log2 p⊕ − p⊖ log2 p⊖
11 TDT4173 Machine Learning
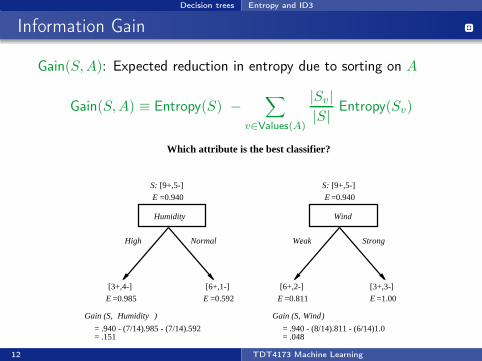
Decision trees Entropy and ID3
Information Gain
Gain(S,A): Expected reduction in entropy due to sorting on A
Gain(S,A) ≡ Entropy(S) −∑
v∈Values(A)
|Sv|
|S|Entropy(Sv)
Which attribute is the best classifier?
High Normal
Humidity
[3+,4-] [6+,1-]
Wind
Weak Strong
[6+,2-] [3+,3-]
= .940 - (7/14).985 - (7/14).592 = .151
= .940 - (8/14).811 - (6/14)1.0 = .048
Gain (S, Humidity ) Gain (S, )Wind
=0.940E =0.940E
=0.811E=0.592E=0.985E =1.00E
[9+,5-]S:[9+,5-]S:
12 TDT4173 Machine Learning

Decision trees Entropy and ID3
Hypothesis Space Search by ID3
Hypothesis space is complete, so target function surely inthere. . .
Outputs a single hypothesis
No back tracking: Local minima. . .
Statistically-based search choices, so robust to noisy data. . .
13 TDT4173 Machine Learning

Decision trees Bias
Inductive Bias in ID3
Note: Hypothesis space is complete, so H is the power set ofinstances X.
Does this imply that ID3 is an unbiased learner (lacking bothinductive bias as well as preference bias)?
14 TDT4173 Machine Learning

Decision trees Bias
Inductive Bias in ID3
Note: Hypothesis space is complete, so H is the power set ofinstances X.
Does this imply that ID3 is an unbiased learner (lacking bothinductive bias as well as preference bias)?
Not really. . .
Preference for short trees, and for those with high informationgain attributes near the root
Bias is a preference for some hypotheses, rather than arestriction of hypothesis space H
Occam’s razor: prefer the shortest hypothesis that fits the data
14 TDT4173 Machine Learning

Decision trees Bias
Why Occam’s Razor?
Why prefer short hypotheses?
Argument in favor:
Fewer short hyps. than long hyps.
a short hyp that fits data unlikely to be coincidence
a long hyp that fits data might be coincidence
Argument opposed:
What’s so special about small sets based on size ofhypothesis??
There are many ways to define small sets of hypothesis, e.g.,all trees with a prime number of nodes that use attributesbeginning with “Z”
15 TDT4173 Machine Learning
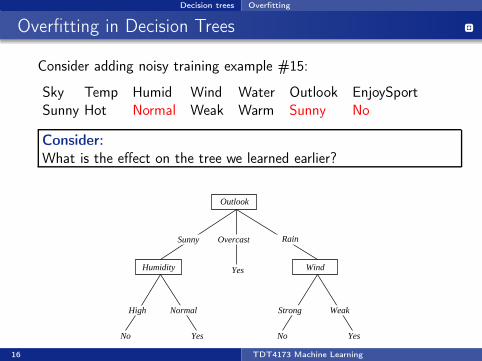
Decision trees Overfitting
Overfitting in Decision Trees
Consider adding noisy training example #15:
Sky Temp Humid Wind Water Outlook EnjoySportSunny Hot Normal Weak Warm Sunny No
Consider:What is the effect on the tree we learned earlier?
Outlook
Overcast
Humidity
NormalHigh
No Yes
Wind
Strong Weak
No Yes
Yes
RainSunny
16 TDT4173 Machine Learning

Decision trees Overfitting
Overfitting
Consider error of hypothesis h over
Training data: errort(h)
Entire distribution D of data: errorD(h)
Hypothesis h ∈ H overfits training data if there is an alternativehypothesis h′ ∈ H such that
errort(h) < errort(h′)
anderrorD(h) > errorD(h
′)
17 TDT4173 Machine Learning
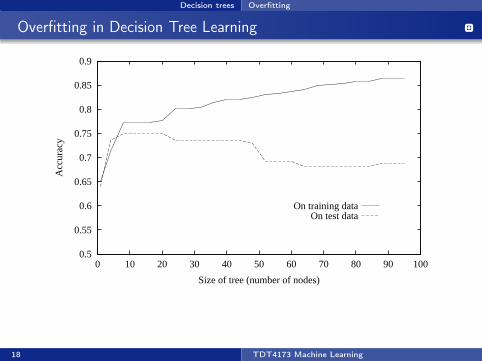
Decision trees Overfitting
Overfitting in Decision Tree Learning
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0 10 20 30 40 50 60 70 80 90 100
Acc
urac
y
Size of tree (number of nodes)
On training dataOn test data
18 TDT4173 Machine Learning

Decision trees Overfitting
Avoiding Overfitting
How can we avoid overfitting?
stop growing when data split not statistically significant
grow full tree, then post-prune
How to select “best” tree:
Measure performance over training data
Measure performance over separate validation data set
MDL: Minimize size(tree) + size(misclassifications(tree))
19 TDT4173 Machine Learning

Decision trees Overfitting
Reduced-Error Pruning
Split data into training and validation set
Do until further pruning is harmful:
1 Evaluate impact on validation set of pruning each possiblenode (plus those below it)
2 Greedily remove the one that most improves validation setaccuracy
Produces smallest version of most accurate subtree
20 TDT4173 Machine Learning
Decision trees Overfitting
Nice applet on the web
If you want to learn (more) about decision trees, try this applet:
http://www.cs.ualberta.ca/~aixplore/learning/DecisionTrees/
21 TDT4173 Machine Learning

Evaluating hypothesis Sample error, true error
Two Definitions of Error
The true error of hypothesis h with respect to target function fand distribution D is the probability that h will misclassify aninstance drawn at random according to D.
errorD(h) ≡ Prx∈D
[f(x) 6= h(x)]
The sample error of h with respect to target function f and datasample S is the proportion of examples h misclassifies
errorS(h) ≡1
n
∑
x∈S
δ(f(x) 6= h(x))
Where δ(f(x) 6= h(x)) is 1 if f(x) 6= h(x), and 0 otherwise.
How well does errorS(h) estimate errorD(h)?
22 TDT4173 Machine Learning

Evaluating hypothesis Sample error, true error
Problems Estimating Error
1 Bias: If S is training set, errorS(h) is optimistically biased
bias ≡ E[errorS(h)]− errorD(h)
For unbiased estimate, h and S must be chosen independently.
→ Assume S is a separate validation set (for now).
2 Variance: Even with unbiased S, errorS(h) may still vary fromerrorD(h)
23 TDT4173 Machine Learning

Evaluating hypothesis Sample error, true error
Example
Hypothesis h misclassifies 12 of the 40 examples in S
errorS(h) =12
40= .30
What is errorD(h)?
24 TDT4173 Machine Learning

Evaluating hypothesis Sample error, true error
Example
Hypothesis h misclassifies 12 of the 40 examples in S
errorS(h) =12
40= .30
What is errorD(h)?
And if true error is errorD(h) = 0.30, what can we say about thenumber of misclassifies from 40 examples?
24 TDT4173 Machine Learning
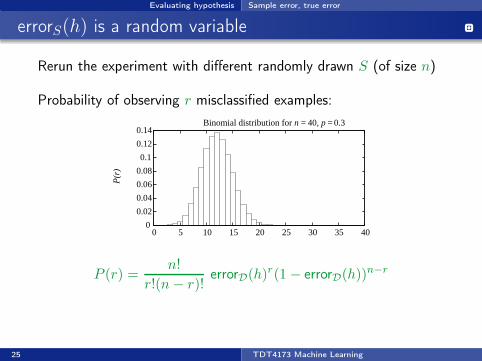
Evaluating hypothesis Sample error, true error
errorS(h) is a random variable
Rerun the experiment with different randomly drawn S (of size n)
Probability of observing r misclassified examples:
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0 5 10 15 20 25 30 35 40
P(r
)Binomial distribution for n = 40, p = 0.3
P (r) =n!
r!(n− r)!errorD(h)
r(1− errorD(h))n−r
25 TDT4173 Machine Learning

Evaluating hypothesis Estimators
Estimators
Experiment:
1 choose sample S of size n according to distribution D
2 measure errorS(h)
We know:
errorS(h) is a random variable (i.e., result of an experiment)
errorS(h) is an unbiased estimator for errorD(h)
But:Given observed errorS(h) what can we conclude about errorD(h)?
→ Theory from statistics will give us the answer . . .
26 TDT4173 Machine Learning

Evaluating hypothesis Confidence intervals for observed hypothesis error
Central Limit Theorem
Consider a set of independent, identically distributed randomvariables Y1 . . . Yn, all governed by an arbitrary probabilitydistribution with mean µ and finite variance σ2. Define the samplemean,
Y ≡1
n
n∑
i=1
Yi
Central Limit Theorem
As n→∞, the distribution governing Y approaches a Normaldistribution, with mean µ and variance σ2
n.
27 TDT4173 Machine Learning

Evaluating hypothesis Confidence intervals for observed hypothesis error
Confidence Intervals
If S contains n examples that are drawn independently of h andeach other, and n ≥ 30 then
With approximately 95% probability, errorD(h) lies in interval
errorS(h)± 1.96
√
errorS(h)(1 − errorS(h))
n
28 TDT4173 Machine Learning

Evaluating hypothesis Confidence intervals for observed hypothesis error
Confidence Intervals
If S contains n examples that are drawn independently of h andeach other, and n ≥ 30 then
With approximately N% probability, errorD(h) lies in interval
errorS(h)± zN
√
errorS(h)(1 − errorS(h))
n
where
N%: 50% 68% 80% 90% 95% 98% 99%zN : 0.67 1.00 1.28 1.64 1.96 2.33 2.58
28 TDT4173 Machine Learning

Evaluating hypothesis Confidence intervals for observed hypothesis error
Calculating Confidence Intervals
1 Pick parameter p to estimate:
errorD(h)
2 Choose an estimator:
errorS(h)
3 Determine probability distribution that governs estimator:
errorS(h) governed by Binomial distribution, approximated by
Normal when n ≥ 30
4 Find interval (L,U) such that N% of probability mass falls inthe interval:
Use table of zN values
29 TDT4173 Machine Learning

Evaluating hypothesis Comparing hypothesis
Difference Between Hypotheses
Test h1 on sample S1, test h2 on S2
1 Pick parameter to estimate: d ≡ errorD(h1)− errorD(h2)
2 Choose an estimator: d ≡ errorS1(h1)− errorS2
(h2)
3 Determine probability distribution that governs estimator
σd≈
√
errorS1(h1)(1− errorS1
(h1))
n1+
errorS2(h2)(1− errorS2
(h2))
n2
4 Find interval (L,U) such that N% of probability mass falls inthe interval
d± zN · σd
30 TDT4173 Machine Learning

Evaluating hypothesis Comparing learners
Comparing learning algorithms LA and LB
Moving from comparing hypothesis to comparing learners we nowlike to estimate the expected difference in true error betweenhypotheses output by learners LA and LB , when trained usingrandomly selected training sets S drawn according to distributionD:
ES⊂D[errorD(LA(S))− errorD(LB(S))]
L(S) is the hypothesis output by learner L using training set S
Given limited data D0, what is a good estimator?
Partition D0 into training set S0 and test set T0, and measure
errorT0(LA(S0))− errorT0
(LB(S0))
Other ideas?
31 TDT4173 Machine Learning

Evaluating hypothesis Comparing learners
Comparing learning algorithms LA and LB
Moving from comparing hypothesis to comparing learners we nowlike to estimate the expected difference in true error betweenhypotheses output by learners LA and LB , when trained usingrandomly selected training sets S drawn according to distributionD:
ES⊂D[errorD(LA(S))− errorD(LB(S))]
L(S) is the hypothesis output by learner L using training set S
Given limited data D0, what is a good estimator?
Partition D0 into training set S0 and test set T0, and measure
errorT0(LA(S0))− errorT0
(LB(S0))
Partition data, repeat this for each part, and average!
31 TDT4173 Machine Learning

Evaluating hypothesis Comparing learners
Comparing learning algorithms LA and LB (2)
1 Partition data D0 into k disjoint test sets T1, T2, . . . , Tk ofequal size, where this size is at least 30.
2 For i from 1 to k, do
use Ti for the test set, and the remaining data for training set Si
Si ← {D0 − Ti}hA ← LA(Si)hB ← LB(Si)δi ← errorTi
(hA)− errorTi(hB)
3 Return the value δ ≡ 1k
∑ki=1 δi
N% confidence interval estimate for d:
δ ± tN,k−1
√
√
√
√
1
k(k − 1)
k∑
i=1
(δi − δ)2
Note! δi and δ are approximately Normally distributed.
32 TDT4173 Machine Learning

Computational Learning Theory Background
Computational Learning Theory
Top-level question:What general laws constrain inductive learning?
We seek theory to relate:
Probability of successful learning
Number of training examples
Complexity of hypothesis space
Accuracy to which target concept is approximated
The manner in which training examples are presented
33 TDT4173 Machine Learning

Computational Learning Theory Background
Prototypical Concept Learning Task
Given:
Instances x ∈ X : Possible days, each described by theattributes Sky, AirTemp, Humidity, Wind, Water, Forecast
Target function c: EnjoySport : X → {0, 1}
Hypotheses H: Conjunctions of literals. E.g.
〈?,Cold,High, ?, ?, ?〉.
Training examples D: Positive and negative noise freeexamples of the target function
〈x1, c(x1)〉, . . . , 〈xm, c(xm)〉
Determine:
A hypothesis h in H such that h(x) = c(x) for all x ∈D.
A hypothesis h in H such that h(x) = c(x) for all x ∈ X .
34 TDT4173 Machine Learning

Computational Learning Theory Background
Sample Complexity
How many training examples are sufficient to learn the targetconcept?
1 If learner proposes instances, as queries to teacher
Learner proposes instance x, teacher provides c(x)
2 If teacher (who knows c) provides training examples
Teacher provides sequence of examples of form 〈x, c(x)〉
3 If some random process (e.g., nature) proposes instances
Instance x generated randomly, teacher provides c(x)
35 TDT4173 Machine Learning

Computational Learning Theory Background
Sample Complexity: Case 1
Learner proposes instance x, teacher provides c(x)(assume c is in learner’s hypothesis space H)
Optimal query strategy: pretend to play 20 questions
Pick instance x such that half of hypotheses in VersionSpace
classify x positive, half classify x negative
When this is possible, need ⌈log2 |H|⌉ queries to learn c
When not possible, we need more queries
36 TDT4173 Machine Learning

Computational Learning Theory Background
Sample Complexity: Case 2
Teacher (who knows c) provides training examples(assume c is in learner’s hypothesis space H)
Optimal teaching strategy: Depends on H used by learner
Consider the case H = conjunctions of up to n boolean literals andtheir negations
e.g., (AirTemp = Warm) ∧ (Wind = Strong), whereAirTemp,Wind, . . . each have 2 possible values.
If there are n possible boolean attributes in H, it will sufficewith n+ 1 examples. Why?
37 TDT4173 Machine Learning

Computational Learning Theory Background
Sample Complexity: Case 3
Given:
Set of instances X
Set of hypotheses H
Set of possible target concepts C
Training instances generated by a fixed, unknown probabilitydistribution D over X
38 TDT4173 Machine Learning

Computational Learning Theory Background
Sample Complexity: Case 3
Given:
Set of instances X
Set of hypotheses H
Set of possible target concepts C
Training instances generated by a fixed, unknown probabilitydistribution D over X
Learner observes a sequence D of training examples of form〈x, c(x)〉, for some target concept c ∈ C:
instances x are drawn from distribution D
teacher provides target value c(x) for each
Learner must output a hypothesis h estimating c:
h is evaluated by its performance on subsequent instancesdrawn according to D
Note: randomly drawn instances, noise-free classifications38 TDT4173 Machine Learning

Computational Learning Theory Bounding the error
Two Notions of Error
Remember the definition of the True error of hypothesis h withrespect to c:
How often h(x) 6= c(x) over future random instances
Now, also focus on Training error of hypothesis h with respect totarget concept c
How often h(x) 6= c(x) over training instances
Focus for the rest of the lesson
Earlier today we considered the sample error on a validation setbecause we wanted to avoid bias.
From now on we try to bound the true error of h given that thetraining error of h on the training set is zero (i.e.,h ∈ VersionSpaceH,D)
39 TDT4173 Machine Learning

Computational Learning Theory Bounding the error
Exhausting the Version Space
VersionSpaceH,D
error = .1, r = .2
error = .3, r = .1
error = .3, r = .4
error = .2, r = .3
error = .2, r = 0
error = .1, r = 0
Hypothesis Space H
(r: training error, error: true error)
Definition (ǫ-exhausted)
The version space VersionSpaceH,D is said to be ǫ-exhausted withrespect to c and D, if every hypothesis h in VersionSpaceH,D haserror less than ǫ with respect to c and D.
(∀h ∈ VersionSpaceH,D) errorD(h) < ǫ
40 TDT4173 Machine Learning

Computational Learning Theory Bounding the error
How many examples will ǫ-exhaust the VS?
Theorem (Haussler, 1988)
If the hypothesis space H is finite, and D is a sequence of m ≥ 1independent random examples of some target concept c, then forany 0 ≤ ǫ ≤ 1, the probability that the version space with respectto H and D is not ǫ-exhausted (with respect to c) is less than
|H|e−ǫm
→ This bounds the probability that any consistent learner willoutput a hypothesis h with error(h) ≥ ǫ:
If we want this probability to be below δ, |H|e−ǫm ≤ δ, then
m ≥1
ǫ(ln |H|+ ln(1/δ))
41 TDT4173 Machine Learning

Computational Learning Theory Bounding the error
Example: Learning Conjunctions of Boolean Literals
How many examples are sufficient to assure with probability at least(1− δ) that every h in VersionSpaceH,D satisfies errorD(h) ≤ ǫ?
Use the theorem:
m ≥1
ǫ(ln |H|+ ln(1/δ))
Suppose H contains conjunctions of constraints on up to n booleanattributes (i.e., n boolean literals).
Then |H| = 3n, and
m ≥1
ǫ(ln 3n + ln(1/δ)) =
1
ǫ(n ln 3 + ln(1/δ))
42 TDT4173 Machine Learning

Computational Learning Theory Bounding the error
How About EnjoySport?
m ≥1
ǫ(ln |H|+ ln(1/δ))
If H is as given in EnjoySport then |H| = 973, and
m ≥1
ǫ(ln 973 + ln(1/δ))
If want to assure that with probability 95%, VersionSpacecontains only hypotheses with errorD(h) ≤ .1, then it is sufficientto have m examples, where
m ≥1
.1(ln 973 + ln(1/.05))
= 10(6.88 + 3.00)
= 98.843 TDT4173 Machine Learning

Computational Learning Theory PAC learning
PAC Learning
Consider a class C of possible target concepts defined over a set ofinstances X of length n, and a learner L using hypothesis space H.
Definition (PAC-learnable)
C is PAC (Probably Approximately Correct)-learnable by L using Hif for all
c ∈ C,
distributions D over X ,
ǫ such that 0 < ǫ < 1/2, and
δ such that 0 < δ < 1/2,
the learner L will – with probability at least (1− δ) – output ahypothesis h ∈ H such that errorD(h) ≤ ǫ, in time that ispolynomial in 1/ǫ, 1/δ, n and size(c).
44 TDT4173 Machine Learning

Computational Learning Theory PAC learning
Example: PAC Learning of Conjunction of Boolean Literals
Is there a learner L which makes the “Conjunction of BooleanLiterals” - problem PAC learnable?
Number of examples required by consistent learner:
m =1
ǫ(n ln 3 + ln(1/δ))
Find-S is consistent, and the number of operations requiredper training example for Find-S is O(n).
Learning is linear in 1/ǫ, logarithmic in 1/δ, linear in n andconstant in size(c).
So. . . Yes, it is PAC learnable, e.g. using Find-S!
45 TDT4173 Machine Learning



















