Embed Size (px)
Citation preview

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Syntaktisk analys
Yvonne Adesam
2014

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Outline
Syntaktisk analys
Parsning
Ambiguitet
Utvärdering

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Min bakgrund
I Disputerade 2012I Avhandling om att skapa högkvalitativa parallella
trädbankerI Flerspråkiga parallella trädbanken Smultron
I Forskare på SpråkbankenI Historiska resurser (MAÞiR 2014-2016)I Högkvalitativ korpusannotering (Koala 2014-2016)

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Korpuslingvistik
Varför korpusar för språkforskning?
I Faktiska språkliga beläggI Storskaliga empiriska språkstudier
TrädbankerA treebank is “a linguistically annotated corpus that includessome grammatical analysis beyond the part-of-speech level”(Nivre et al., 2005; Nivre, 2008).
I Annotering hjälper oss vaska fram guldkornenI utökar (bok, boken, böcker, böckerna, Bok, BOKEN etc.)I begränsar (Caesar=subjekt + besegra)

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Vad är ett träd?
Varje mening mappas till en graf som representerar desshierarkiska syntaktiska struktur.
?DL
varVBFIN
välAB
ändaAB
EnDT
människaNN
någontingPN
merAB
änPR
enDT
maskinNN
THEDT
GARDENNNP
OFIN
EDENNNP
HD
HD
AVP
MO
HD
AVP
MO
NK HD
NP
SB
MO HD
CM NK HD
NP
CC
AVP
PD
S
NP
PPLOC
NP

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Konstituenter och dependenser
I KonstituenterI fraserI strukturella kategorierI möjligen funktionella kategorierI orden byggklossar i större enheter
I DependenserI relationer mellan huvudenI funktionella kategorierI syntaktiska funktionerI möjligen strukturella kategorier (ordklasser)I ords relation till varandra

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Konstituenter och dependenser
Richard Johansson and Pierre Nugues
idea of the new conversion method is to make use
of the extended structure of the recent versions of
the Penn Treebank to derive a more “semantically
useful” representation. The first section of the arti-
cle presents previous approaches to converting con-
stituent trees into dependency trees. We then de-
scribe the modifications we brought to the previous
methods. The last section describes a small experi-
ment in which we study the impact of the new format
on the performance of two statistical dependency
parsers. Finally, we examine how the new represen-
tation affects semantic role classification.
2 Previous Constituent-to-Dependency
Conversion Methods
The current conversion procedures are based on the
idea of assigning each constituent in the parse tree a
unique head selected amongst the constituent’s chil-
dren (Magerman, 1994). For example, the toy gram-
mar below would select the noun as the head of an
NP, the verb as the head of a VP, and VP as the head
of an S consisting of a noun phrase and and a verb
phrase:
NP --> DT NN*VP --> VBD* NP
S --> NP VP*
By following the child-parent links from the token
level up to the root of the tree, we can label every
constituent with a head token. The heads can then
be used to create dependency trees: to determine the
parent of a token in the dependency tree, we locate
the highest constituent that it is the head of and select
the head of its parent constituent.
Magerman (1994) produced a head percolation
table, a set of priority lists, to find heads of con-
stituents. Collins (1999) modified Magerman’s rules
and used them in his parser, which is constituent-
based but uses dependency structures as an inter-
mediate representation. Yamada and Matsumoto
(2003) modified the table further and their proce-
dure has become the most popular one to date.
PENN2MALT (Nivre, 2006) is a reimplementation
of Yamada and Matsumoto’s method, and also de-
fines a set of heuristics to infer arc labels in the
dependency tree. Figure 1 shows the constituent
tree of the sentence Why, they wonder, should it be-
long to the EC? from the Penn Treebank and Fig-
ure 2, the corresponding dependency tree produced
by PENN2MALT.
SBARQ
VP
SBAR
ADVP
S
NP
SQ
PRN
VP
SBJ
NP
SBJ
PP
CLR
NP
SBARQ
WHADVP
PRP
*T*
*T*
Why wonderthey 0 EC ?should, belongit to the*T* *T*,
Figure 1: A constituent tree from the Penn Treebank.
Why wonderthey, , should it belong to the EC
SUB
P
P
VMOD
?
SUB
P
VMOD VMOD
VMOD
PMOD
NMOD
ROOT
Figure 2: Dependency tree by PENN2MALT.
3 The New Conversion Procedure
As can be seen from the figures, the dependency tree
that is created by PENN2MALT discards deep infor-
mation such as the fact that the word Why refers to
the purpose of the verb belong. It thus misses the di-
rect relation between this question and a possible an-
swer It should belong to the EC because. . . This re-
lation is nevertheless present in the Penn Treebank II
and is encoded in the form of a PRP link (purpose or
reason) from the verb phrase to an empty node that
is linked via a secondary edge to Why (Figure 1). In
the new method, we link wh-words and topicalized
phrases to their semantic heads, which we believe
makes more sense in a dependency grammar.
In addition to the modification of dependency
links, the new method uses a much richer set of de-
pendency arc labels than PENN2MALT. The Penn
annotation guidelines define a fairly large set of edge
labels (referring to grammatical functions or proper-
ties of phrases), and most of these are retained in
the new format. PENN2MALT only used SBJ, sub-
ject, and PRD, predicative complement. In addition,
the number of inferred labels (i.e. the labels on the
edges that carry no label in the Penn Treebank) has
been extended.
Figure 3 shows the dependency tree that is pro-
duced by the new procedure. The benefit of retain-
ing the deeper information should be obvious for ap-
106
Figurer från Johansson and Nugues (2007).

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
The history of treebanks
I Penn Treebank (English; Phase 1: 1989-1992)I Forerunners:
I Talbanken (Swedish; Lund 1970s)I Ellegård (English; Gothenburg 1978)I Tosca (English; Nijmegen 1980s)I LOB (Lancaster-Oslo-Bergen) Treebank (Engl.; late 1980s)I SynTag (Swedish; Gothenburg 1986-1989)
I FollowersI NEGRA / TIGER Treebanks (German; 1997-2000s)I Prague Dependency Treebank (Czech; 2000s)I Svensk trädbank (Swedish; 2007)I Bulgarian, Danish, Dutch, French, Chinese, Japanese,
Arab, Hebrew, Turkish . . .

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Penn treebank
Penn Treebank Example from 1991
( bd0011sx .)( (S (NP *)
(VP Show(NP me)(NP (NP all)
the nonstop flights(PP (PP from
(NP Dallas))(PP to
(NP Denver)))(ADJP early
(PP in(NP the morning))))) .) )

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
The Swedish Treebank
I Developed in Uppsala and VäxjöI Harmonizing two resources:
I Talbanken: Swedish written and transcribed spokenlanguage from the 1970s, manually annotated withsyntactic information according to a traditionalScandinavian analysis tradition (cf. Diderichsen’s fieldanalysis)
I SUC (Stockholm Umeå Corpus), a morphosyntacticallyannotated (part-of-speech and lemma), balanced corpus ofpublished Swedish written language from the 1990s
I Talbanken annotated with SUC morphosyntactic in asemi-automatic process
I Both Talbanken and SUC automatically syntacticallyannotated with phrase structure version of Talbanken’soriginal syntax analysis

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
The Swedish Treebank

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Varför automatisk syntaktisk analys?
I Manuell annotering tidskrävandeI Vi vill ha stora mängder annoterad text
I träningsmaterial för NLP-systemI möjliggör mer detaljerade sökningarI grammatikforskning

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CFG
Context-free grammar
I Formell grammatikI Regler
I S → sI G = (N, T , R, S)
1. N: mängden icke-terminaler2. T : mängden terminaler3. R: relation från N till (N ∪ T )∗ (regler, produktioner)4. S: startsymbol, del av mängden N

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CFG
Jag ser det glada barnet.
Jag ser att det glada barnet sjunger.
I pn → ’jag’I vb → ’ser’I dt → ’det’I adj → ’glada’I nn → ’barnet’
I S → NP VPI NP → pn | (dt) (adj)* nnI VP → vb (NP)*

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CFG
Jag ser det glada barnet.
Jag ser att det glada barnet sjunger.
I pn → ’jag’I vb → ’ser’I dt → ’det’I adj → ’glada’I nn → ’barnet’
I S → NP VPI NP → pn | (dt) (adj)* nnI VP → vb (NP)*

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CFG
Jag ser det glada barnet.
Jag ser att det glada barnet sjunger.
I pn → ’jag’I vb → ’ser’I dt → ’det’I adj → ’glada’I nn → ’barnet’
I S → NP VPI NP → pn | (dt) (adj)* nnI VP → vb (NP)*

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CFG
Jag ser det glada barnet.
Jag ser att det glada barnet sjunger.
I pn → ’jag’I vb → ’ser’I dt → ’det’I adj → ’glada’I nn → ’barnet’
I S → NP VPI NP → pn | (dt) (adj)* nnI VP → vb (NP)*

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Parsning
I Parsning: söka igenom alla möjliga träd för en givenmening
I För att söka igenom alla möjliga träd måste vi skapa dem

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Parsers
I Parser: program som tar sträng som input ochåterskapar strukturen i form av träd
I Alla parsers läser input från vänster till högerI Olika sätt att skapa trädstrukturen
I bottom-up: börja med löven(kan ge träd utan toppnod S)
I top-down: börja med toppnoden(kan ge träd som inte motsvarar input)

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dynamic Programming
I Divide and conquerLös ett problem genom att dela upp det i delproblem, lösvarje delproblem och kombinera lösningarna.
I Memo-iseringLös varje delproblem en gång, mellanlagra lösningen,återanvänd som dellösning i större problem.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
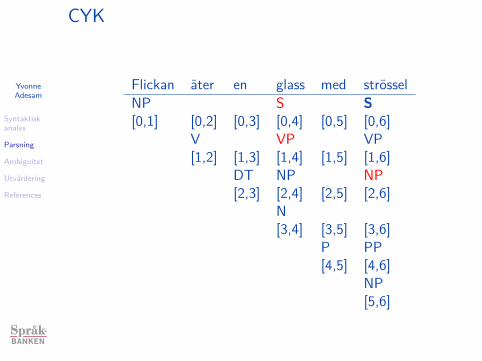
CYK
Cocke-Younger-Kasami
I Bottom-up för kontextfri grammatikI Regler maximalt binära:
(Chomsky normal form!)I A→ a eller A→ BC
I Finns i många variationer...I Skapa triangelformad parsningstabell
I Varje cell [i,j] innehåller alla icke-terminaler för position i-jI Börja med strängar av längd 1, sedan längd 2 osv.I Hitta alla alternativ upp till toppnoden

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CYK
Exempelgrammatik
I S → NP VPI VP → V NPI VP → VP PPI NP → DT NI NP → NP PPI PP → P NPI V → ’äter’I NP → ’flickan’I NP → ’strössel’I N → ’glass’I P → ’med’I DT → ’en’
Flickan äter en glass med strössel.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CYK
Flickan äter en glass med strössel
NP S S
[0,1] [0,2] [0,3] [0,4] [0,5] [0,6]
V VP VP
[1,2] [1,3] [1,4] [1,5] [1,6]
DT NP NP
[2,3] [2,4] [2,5] [2,6]
N
[3,4] [3,5] [3,6]
P PP
[4,5] [4,6]
NP
[5,6]

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CYK
Flickan äter en glass med strösselNP
S S
[0,1] [0,2] [0,3] [0,4] [0,5] [0,6]V
VP VP
[1,2] [1,3] [1,4] [1,5] [1,6]DT
NP NP
[2,3] [2,4] [2,5] [2,6]N[3,4] [3,5] [3,6]
P
PP
[4,5] [4,6]NP[5,6]

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CYK
Flickan äter en glass med strösselNP
S S
[0,1] [0,2] [0,3] [0,4] [0,5] [0,6]V
VP VP
[1,2] [1,3] [1,4] [1,5] [1,6]DT NP
NP
[2,3] [2,4] [2,5] [2,6]N[3,4] [3,5] [3,6]
P PP[4,5] [4,6]
NP[5,6]

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CYK
Flickan äter en glass med strösselNP S
S
[0,1] [0,2] [0,3] [0,4] [0,5] [0,6]V VP
VP
[1,2] [1,3] [1,4] [1,5] [1,6]DT NP NP[2,3] [2,4] [2,5] [2,6]
N[3,4] [3,5] [3,6]
P PP[4,5] [4,6]
NP[5,6]

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CYK
Flickan äter en glass med strösselNP S
S
[0,1] [0,2] [0,3] [0,4] [0,5] [0,6]V VP VP[1,2] [1,3] [1,4] [1,5] [1,6]
DT NP NP[2,3] [2,4] [2,5] [2,6]
N[3,4] [3,5] [3,6]
P PP[4,5] [4,6]
NP[5,6]
YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
CYK
Flickan äter en glass med strösselNP S S[0,1] [0,2] [0,3] [0,4] [0,5] [0,6]
V VP VP[1,2] [1,3] [1,4] [1,5] [1,6]
DT NP NP[2,3] [2,4] [2,5] [2,6]
N[3,4] [3,5] [3,6]
P PP[4,5] [4,6]
NP[5,6]

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Earley
CYK har nackdelar:
I begränsad grammatikI följer inte lingvistisk teoriI använder inte top-down-information
Earley-algoritmen
I har inte ovanstående nackdelarI men är komplicerad (framför allt med sannolikheter)

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Earley
Parsning i ett steg vänster till höger
I Börja med startsymbolen SI Skapa alla möjliga expansioner för den vänstraste
icke-terminalen (predictor)I Om nästa led i regeln är en terminal, matcha mot input
(scanner)I När regeln inte längre kan expanderas, fortsätt med nästa
subträd (completer)I Delprocessade regler markeras med punkt
A → a • b

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
EarleyExample run
0 I 1 prefer 2 a 3 morning 4 flight 5
S [0, 0]
Predict the rule S → • NP VP
The Earley algorithm
Montag, 3. Dezember 12
Exempel från Marco Kuhlmann, Uppsala.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
EarleyExample run
VPNP
S [0, 0]
[0, 0]
0 I 1 prefer 2 a 3 morning 4 flight 5
Predict the rule NP → • Pro
The Earley algorithm
S → • NP VP
Montag, 3. Dezember 12
Exempel från Marco Kuhlmann, Uppsala.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
EarleyExample run
Pro
VPNP
S [0, 0]
[0, 0]
[0, 0]
0 I 1 prefer 2 a 3 morning 4 flight 5
Predict the rule Pro → • I
The Earley algorithm
NP → • Pro
S → • NP VP
Montag, 3. Dezember 12
Exempel från Marco Kuhlmann, Uppsala.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
EarleyExample run
I
Pro
VPNP
S [0, 0]
[0, 0]
[0, 0]
[0, 0]
0 I 1 prefer 2 a 3 morning 4 flight 5
Scan this word
The Earley algorithm
Pro → • I
NP → • Pro
S → • NP VP
Montag, 3. Dezember 12
Exempel från Marco Kuhlmann, Uppsala.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
EarleyExample run
0 I 1 prefer 2 a 3 morning 4 flight 5
The Earley algorithm
Pro → • I
NP → • Pro
I
Pro
VPNP
S [0, 0]
[0, 0]
[0, 0]
[0, 1]
Update the dot
S → • NP VP
Montag, 3. Dezember 12
Exempel från Marco Kuhlmann, Uppsala.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
EarleyExample run
0 I 1 prefer 2 a 3 morning 4 flight 5
The Earley algorithm
Pro → I •
NP → • Pro
The predicted rule is complete.
I
Pro
VPNP
S [0, 0]
[0, 0]
[0, 1]
[0, 1]
S → • NP VP
Montag, 3. Dezember 12
Exempel från Marco Kuhlmann, Uppsala.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
EarleyExample run
0 I 1 prefer 2 a 3 morning 4 flight 5
I
Pro
VPNP
S [0, 1]
[0, 1]
[0, 1]
[0, 1]
The Earley algorithm
S → NP • VP
Montag, 3. Dezember 12
Exempel från Marco Kuhlmann, Uppsala.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
EarleyExample run
0 I 1 prefer 2 a 3 morning 4 flight 5
I
Pro
VPNP
S [0, 1]
[0, 1]
[0, 1]
[0, 1]
[1, 1]
The Earley algorithm
S → NP • VP
Montag, 3. Dezember 12
Exempel från Marco Kuhlmann, Uppsala.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
EarleyExample run
0 I 1 prefer 2 a 3 morning 4 flight 5
prefer
a
morning
flightNoun
Nom Noun
NomDet
NPVerb
I
Pro
VPNP
S [0, 5]
[0, 1]
[0, 1]
[0, 1]
[1, 5]
[1, 2]
[1, 2]
[2, 3]
[2, 3]
[3, 4]
[3, 4]
[3, 4]
[4, 5]
[4, 5]
[3, 5]
[2, 5]
Update the dot
The Earley algorithm
S → NP • VP
Montag, 3. Dezember 12
Exempel från Marco Kuhlmann, Uppsala.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
EarleyExample run
prefer
a
morning
flightNoun
Nom Noun
NomDet
NPVerb
I
Pro
VPNP
S [0, 5]
[0, 1]
[0, 1]
[0, 1]
[1, 5]
[1, 2]
[1, 2]
[2, 3]
[2, 3]
[3, 4]
[3, 4]
[3, 4]
[4, 5]
[4, 5]
[3, 5]
[2, 5]
The Earley algorithm
0 I 1 prefer 2 a 3 morning 4 flight 5
Montag, 3. Dezember 12
Exempel från Marco Kuhlmann, Uppsala.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
PCFG
Probabilistic context-free grammar
I Varje regel får en sannolikhetI Sannolikheten för regler med samma vänstersida summeras
till 1I Sannolikheten för ett träd är produkten av sannolikheterna
för de regler som använtsI Varje del i trädet pekar till de delar som det byggdes av,
för att minnas hur det mest sannolika trädet såg ut

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
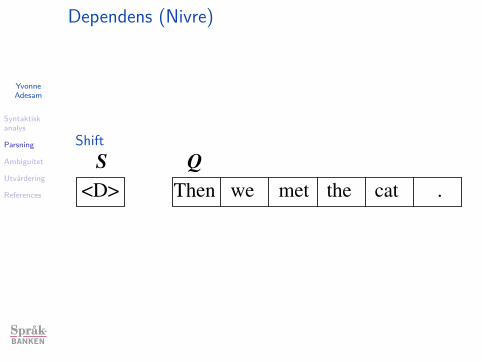
Dependens (Nivre)
I Inkrementell: från vänster till höger i ett svepI Bottom-upI Shift-reduce
I Kö (’först in först ut’)I Stack (’sist in först ut’)I Shift: flytta ett ord från kö till stackI Reduce: Flytta ett ord från stacken

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependens (Nivre)
Exempel från Richard Johansson.
<D> we met .Then
S Q
the cat
YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependens (Nivre)
Shift
we met .Then
Q
<D>
S
the cat

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependens (Nivre)
Shift
we met .<D>
Q
Then
S
the cat

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependens (Nivre)
Shift
met .<D> Then the cat
Q
we
S

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
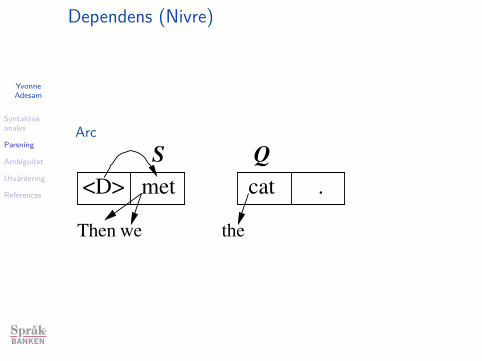
Dependens (Nivre)
Arc
<D> Then
S
.the catmet
Q
we

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependens (Nivre)
ArcS
.the catmet
Q
weThen
<D>

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependens (Nivre)
Arc
met
weThen
.the cat
QS
<D>

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependens (Nivre)
Shift
met
weThen
<D> .catthe
QS
YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependens (Nivre)
Arc
.cat
Q
the
<D> met
weThen
S

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependens (Nivre)
Arc
cat
the
<D> met
weThen
.
QS

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependens (Nivre)
Reduce
the
cat
<D> met
weThen
S
.
Q

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependens (Nivre)
Arc
the
cat
<D> met
weThen
.
S Q
Done!

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Ambiguitet
Språket är flertydigt
I Lexical ambiguityI Structural ambiguity
I Attachment ambiguityI Coordination ambiguityI NP bracketing ambiguity

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Attachment ambiguity
Jag såg mannen med kikaren.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Coordination ambiguity
Där dansade stora pojkar och flickor.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Treebank Quality
I Well-formedness
Each token and each non-terminal node is part of asentence-spanning tree, and has a label.
I Consistency
The same sequence (oftokens/part-of-speechs/constituents) is annotated thesame way given the same context.
I Soundness
Conform to sound linguistic principles.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Treebank Quality
I Well-formednessEach token and each non-terminal node is part of asentence-spanning tree, and has a label.
I ConsistencyThe same sequence (oftokens/part-of-speechs/constituents) is annotated thesame way given the same context.
I SoundnessConform to sound linguistic principles.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Utvärdering av parsning
I FrasstrukturI ParsevalI Leaf-ancestor
I DependensstrukturI Attachment och accuracy

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Parseval
I Beräknar precision och recall för konstituenterI Precision: found correct items
found itemsI Recall: found correct items
correct itemsI Labelled parseval
I korrekt konstituent: dominerar samma terminaler medsamma etiketter (POS och fras)

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Leaf-ancestor
I Jämför ’lineage’, icke-terminalerna från varje ord tillträdets rot
I Använder markörer för ytterkanten på fraserI Jämför med guldstandard via Levenshtein/edit distanceI Fungerar inte för frasträd med korsande kanterThe Multilingual Forest
R R
P P P
w1 w2 w3 w1 w2 w3
w1 P ( R w1 P ( Rw2 P ) R w2 P Rw3 P R ) w3 P R )
Figure 7.3: Example gold standard and automatically parsed trees and their Leaf-Ancestor lineages.
correct if a constituent in the gold standard dominates the same sequence ofterminals (has the same bracketing) with the same labels (PoS and syntacticlabels). In general, the Parseval-scripts are used for English Penn Treebankannotation types. Language specific items like auxiliaries, not, pre-infinitivalto, and possessive endings, as well as word-external punctuation, are removedfrom the fully-parsed sentence. Additionally, empty brackets and unary nodesare removed, and then the result is compared to “a similarly reduced versionof the Penn Treebank parse of the same sentence” (Black et al., 1991). Whilethe metric has been criticised, see e.g., Carroll et al. (1998), Rehbein and vanGenabith (2007), it is still widely used. We use a script provided by JohanHall, for Parseval evaluation on TIGER trees with crossing branches.
The Leaf-ancestor metric (Sampson, 2000, Sampson and Babarczy, 2003)assigns a score to every word in a test sentence by comparing the lineage (thesequence of non-terminals from a word up to the root node) of the word inthe parser output tree to the lineage of the same word in the gold tree, using aLevenshtein or edit-distance. To distinguish between the lineages of differentphrase structures, Sampson and Babarczy (2003) add markers to the left-mostand right-most child of a branching node in the lineage. These left-most ‘(’and right-most ‘)’ markers are inserted once for each terminal, at the top-mostnode that the child is the left-most or right-most child of. This is only done fornodes that have multiple children, i.e., not for unary nodes. Figure 7.3 showstwo example trees and their lineages, for a three word sentence. The differencebetween the two trees is where the markers are inserted.
The Leaf-Ancestor metric was not developed for trees containing crossingbranches. In Figure 7.4, we see two trees, which the Leaf-Ancestor evaluation
126

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Dependensevaluering
I LAS: labelled attachment score,% ord med rätt huvud och relation
I UAS: unlabelled attachment score,% ord med rätt huvud
I LAcc: labelled accuracy score,% ord med rätt relation
Kan också användas för frasstruktur, men kräver konvertering.

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Why manual work?
Accuracy of most annotation tools depend on
I set of labelsI training dataI language
Part-of-speech tagging: accuracy normally above 95-96%.Example: HunPoS 97% accuracy when trained on SUC(Megyesi, 2009) An error in every second sentence!
Parsing: accuracy varies considerably across languages Example:CoNLL shared task 2007: LAS 84-90: Catalan, Chinese,English, Italian LAS 76-80: Arabic, Basque, Czech, Greek,Hungarian, Turkish

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Summary
I Trädbanker är korpusar med grammatisk analysI Stora textmängder kräver automatiska metoderI Parsning kan göras top-down eller bottom-upI Några algoritmer: CYK, Earley, NivreI Utvärdering behövs

YvonneAdesam
Syntaktiskanalys
Parsning
Ambiguitet
Utvärdering
References
Referenser I
Megyesi, B. (2009). The open source tagger HunPoS for Swedish. In Jokinen, K.and Bick, E., editors, Proceedings of the Nordic Conference on ComputationalLinguistics (Nodalida), volume 4 of NEALT Proceedings Series, pages239–241, Odense, Denmark.
Nivre, J. (2008). Treebanks (Article 13). In Lüdeling, A. and Kytö, M., editors,Corpus Linguistics. An International Handbook. Mouton de Gruyter.
Nivre, J., de Smedt, K., and Volk, M. (2005). Treebanking in Northern Europe: Awhite paper. In Holmboe, H., editor, Nordisk Sprogteknologi. Årbog forNordisk Sprogteknologisk Forskningsprogram 2000-2004. MuseumTusculanums Forlag, Copenhagen.





























