Embed Size (px)
Citation preview

219
CHAPTER7
SYNTACTIC PARSERFOR KANNADA LANGUAGE
This chapter deals with the development of Penn Treebank based statistical syntactic
parsers for Kannada language. Syntactic parsing is the task of recognizing a sentence and
assigning a syntactic structure to it. A syntactic parser is an essential tool used for various
NLP applications and natural language understanding. The well known grammar
formalism called Penn Treebank structure was used to create the corpus for developed
statistical syntactic parser. The parsing system was trained using Treebank based corpus
consists of 1,000 distinct Kannada sentences that was carefully created. The developed
corpus has been already annotated with correct segmentation and POS information. The
developed system uses an SVM based POS tagger generator as explained in chapter 5, for
assigning proper tags to each and every word in the training and test sentences.
Penn Treebank corpora have proved their value both in linguistics and language
technology all over the world. At present a lot of research has been done in the field of
Treebank based probabilistic parsing successfully. The main advantage of Treebank based
probabilistic parsing is its ability to handle the extreme ambiguity produced by context-
free natural language grammars. Information obtained from the Penn Treebank corpora
has challenged the intuitive language study for various NLP purposes [168]. South
Dravidian language like Kannada is morphologically rich in which a single word may
carry different sorts of information. The different morphs composing a word may stand
for, or indicate a relation to other elements in the syntactic parse tree. Therefore, it is a
challenging task to the developers in terms of the status of the orthographic words in the
syntactic parse trees.
The proposed syntactic parser was implemented using supervised machine learning
and PCFG approaches. Training, testing and evaluation were done by SVM algorithms.
Experiment shows that the performance of the developed system is significantly well and
has very competitive accuracy.

220
7.1 RELATED WORK
A series of statistical based parsers for English were developed by various researchers
namely: Charniak-1997, Collins-2003, Bod et al. - 2003 and Charniak and Johnson- 2005
[169,170]. All these parsers were trained and tested on the standard benchmark corpora
called WSJ. A probability model for a lexicalized PCFG was developed by Charniak
in1997. In the same time Collins also describes three generative parsing models, where
each model is a refinement of the previous one, and achieving improved performance. In
1999 Charniak introduced a much better parser called maximum-entropy parsing
approach. This parsing model is based on a probabilistic generative model and uses a
maximum-entropy inspired technique for conditioning and smoothing purposes. In the
same period Collins also present a statistical parser for Czech using the Prague
Dependency Treebank. The first statistical parsing model based on a Chinese Treebank
was developed in 2000 by Bikel and Chiang. A probabilistic Treebank based parser for
German was developed by Dubey and Keller in 2003 using a syntactically annotated
corpus called „Negra‟. The latest addition to the list of available Treebank is the „French
Le Monde‟corpus and it was made available for research purposes in May 2004. Ayesha
Binte Mosaddeque & Nafid Haque wrote CFG for 12 Bangla sentences that have taken
from a newspaper [76]. They used a recursive descent parser for parsing the CFG.
7.2 THEORETICAL BACKGROUND
7.2.1 Parsing
Syntactic analysis is the process of analyzing a text or sentence that is made up of a
sequence of words called tokens, and to determine its grammatical structure with respect
to given grammatical rules.Parsing is an important process in NLP, which is used to
understand the syntax and semantics of a natural language sentences confined to the
grammar. Parsing is actually related to the automatic analysis of texts according to a
grammar. Technically, it is used to refer to the practice of assigning syntactic structure to a
text.On the other way, a parser is a computational system which processes input sentence
according to the productions of the grammar, and builds one or more constituent structures
called parse trees which conform to the grammar.

221
Before a syntactic parser can parse a sentence, it must be supplied with information
about each word in the sentence.In another way, a parser accepts a sequence of words and
an abstract description of possible structural relations that may hold between words or
sequences of words in some language as input and produces zero or more structural
descriptions of the input as output,as permitted by the structural rule set. There will be
zero descriptions, if either the input sequence cannot be analyzed by the grammar, i.e. is
ungrammatical, or if the parser is incomplete, i.e. fails to find all of the structure the
grammar permits. There will be more than one description if the input is ambiguous with
respect to the grammar, i.e. if the grammar permits more than one analysis of the input.
In English, countable nouns have only two inflected forms,singular and plural, and
regular verbs have only four inflected forms: the base form, the -s form, the -ed form, and
the –ing form. But the case is not same for a language like Kannada, which may have
hundreds of inflected forms for each noun or verb. Here an exhaustive lexical listing is
simply not feasible. For such languages, one must build a word parser that will use the
morphological system of the language to compute the part of speech and inflectional
categories of any word.
7.2.1.1 Top-Down Parser
Top-down parsing can be viewed as an attempt to find left-most derivations of an
input-stream by searching for parse trees using a top-down expansion of the given formal
grammar rules. Tokens are consumed from left to right. Inclusive choice is used to
accommodate ambiguity by expanding all alternative right-hand-sides of grammar rules. It
starts from the start symbol S, and goes down to reach the input. This is an advantage of
this method. The top-down strategy never wastes time for exploring trees that cannot
result in an S (root), since it begins by generating just those trees. This means it also never
explores sub trees that cannot find a place in some S-rooted tree. But this also has its
disadvantages. While it does not waste time with trees that do not lead to an S, it does
spend considerable effort on S trees that are not consistent with the input. This weakness
in top-down parsers arises from the fact that they generate trees before ever examining the
input. Recursive descent parser and LL parsers are examples of this parser.

222
7.2.1.2 Bottom-up Parser
A parser can start with the input and attempt to rewrite it to the start symbol.
Intuitively, the parser attempts to locate the most basic elements, then the elements
containing these, and so on. LR parsers are examples of bottom-up parsers. Another term
used for this type of parser is Shift-Reduce parsing. The advantage of this method is, it
never suggests trees that are not at least locally grounded in the input. The major
disadvantage of this method is that, trees that have no hope of leading to an S, or fitting in
with any of their neighbors, are generated with wild abandon. LR parser and Operator
Precedence parsers are examples of this type of parsers.
Another important distinction is whether the parser generates a leftmost derivation or
a rightmost derivation. LL parsers will generate a leftmost derivation and LR parsers will
generate a rightmost derivation (although usually in reverse).
7.2.2 Syntactic Tree Structure
The different parts-of-speech tags and phrases associated with a sentence can be easily
illustrated with the help of a syntactic structure. Fig. 7.1 below shows the output syntactic
tree structure produced by a syntactic parser for the Kannada input sentence
„ರಭಚೆಂಡನನುಎಸೆದನನ‟ (Rama threw the ball).
Fig. 7.1: Syntactic tree structure
223
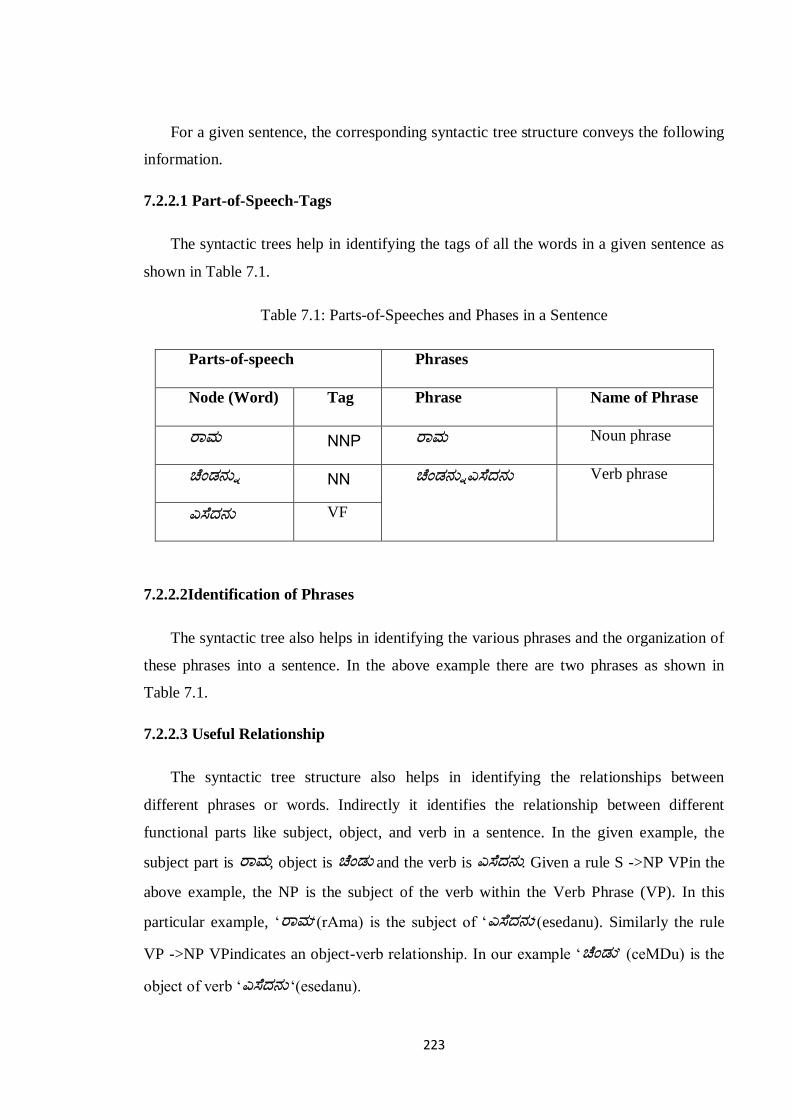
For a given sentence, the corresponding syntactic tree structure conveys the following
information.
7.2.2.1 Part-of-Speech-Tags
The syntactic trees help in identifying the tags of all the words in a given sentence as
shown in Table 7.1.
Table 7.1: Parts-of-Speeches and Phases in a Sentence
Parts-of-speech Phrases
Node (Word) Tag Phrase Name of Phrase
ರಭ NNP ರಭ Noun phrase
ಚೆಂಡನನು NN ಚೆಂಡನನುಎಸೆದನನ Verb phrase
ಎಸೆದನನ VF
7.2.2.2Identification of Phrases
The syntactic tree also helps in identifying the various phrases and the organization of
these phrases into a sentence. In the above example there are two phrases as shown in
Table 7.1.
7.2.2.3 Useful Relationship
The syntactic tree structure also helps in identifying the relationships between
different phrases or words. Indirectly it identifies the relationship between different
functional parts like subject, object, and verb in a sentence. In the given example, the
subject part is ರಭ, object is ಚೆಂಡನ and the verb is ಎಸೆದನನ. Given a rule S ->NP VPin the
above example, the NP is the subject of the verb within the Verb Phrase (VP). In this
particular example, „ರಭ„(rAma) is the subject of „ಎಸೆದನನ„(esedanu). Similarly the rule
VP ->NP VPindicates an object-verb relationship. In our example „ಚೆಂಡನ‟ (ceMDu) is the
object of verb „ಎಸೆದನನ „(esedanu).
224
7.2.3 Context Free Grammars
CFG, sometimes called a phrase structure grammar plays a central role in the
description of natural languages. In general a CFG [172]) is a set of recursive rewriting
rules called productions that are used to generate patterns of strings and it consists of the
following components:
A finite set of terminalsymbols (∑).
A finite set of non-terminalsymbols (NT).
A finite set of productions (P).
A start symbol (S).
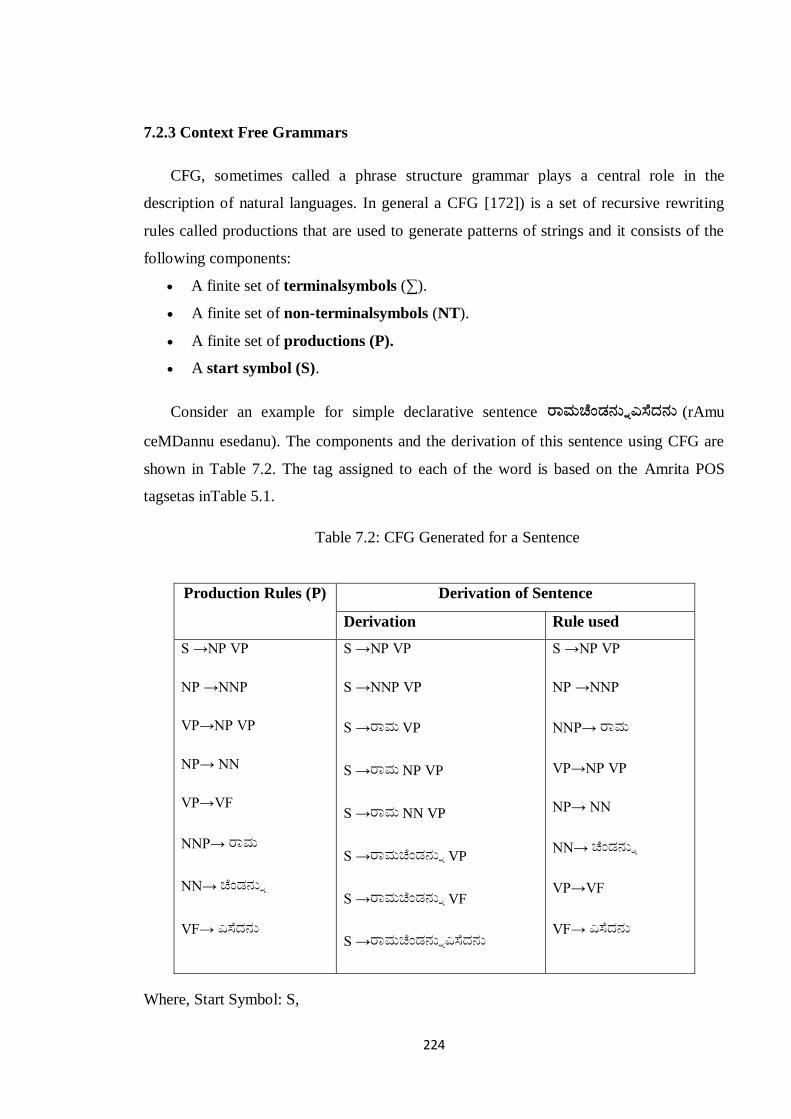
Consider an example for simple declarative sentence ರಭಚೆಂಡನನುಎಸೆದನನ (rAmu
ceMDannu esedanu). The components and the derivation of this sentence using CFG are
shown in Table 7.2. The tag assigned to each of the word is based on the Amrita POS
tagsetas inTable 5.1.
Table 7.2: CFG Generated for a Sentence
Production Rules (P) Derivation of Sentence
Derivation Rule used
S →NP VP
NP →NNP
VP→NP VP
NP→ NN
VP→VF
NNP→ ರಭ
NN→ ಚೆಂಡನನು
VF→ ಎಸೆದನನ
S →NP VP
S →NNP VP
S →ರಭ VP
S →ರಭ NP VP
S →ರಭ NN VP
S →ರಭಚೆಂಡನನು VP
S →ರಭಚೆಂಡನನು VF
S →ರಭಚೆಂಡನನುಎಸೆದನನ
S →NP VP
NP →NNP
NNP→ ರಭ
VP→NP VP
NP→ NN
NN→ ಚೆಂಡನನು
VP→VF
VF→ ಎಸೆದನನ
Where, Start Symbol: S,

225
Terminal Symbols (∑): {ರಭ, ಚೆಂಡನನು, ಎಸೆದನನ},
Non-terminal Symbols (NT): {S, NP, VP, NNP, NN, VF}
7.2.4 Probabilistic Context Free Grammars
The problem of CFG is that it misses the probabilistic model which is needed in order
to disambiguate between parses. A PCFG is a probabilistic version of a CFG where each
production has a probability [174]. Probabilities of all productions rewriting a given non-
terminal must add to 1, defining a distribution for each non-terminal. The simplest way to
gather statistical information about a CFG is to count the number of times each production
rule is used in a corpus containing parsed sentences. This count is used in order to estimate
the probability of each rule being used. In our case, we estimate the rule‟s probabilities
using the relative frequency of the rule in the training set. For a generic rule “A → B C”,
this means that every time we find the symbol A, it can be substituted with the symbol B
and C. Its conditional probability is defined as in equation 7.1:
𝑃 𝐴 → 𝐵𝐶 | 𝐴 =𝑓𝑟𝑒𝑞 𝐴→𝐵𝐶
𝑓𝑟𝑒𝑞 𝐴 (7.1)
Once we have the probability of the production rules in a PCFG, the probability of a
parse tree for a particular sentence can easily be calculated by multiplying the probabilities
of the rules that has built its sub-trees. The advantage of PCFG based syntactic parser
model is that, for any two or more different sentences that have same POS tag sequence,
but have different syntactic tree structure, then the sentence structure that has more
probability would be considered or correctly parsed.
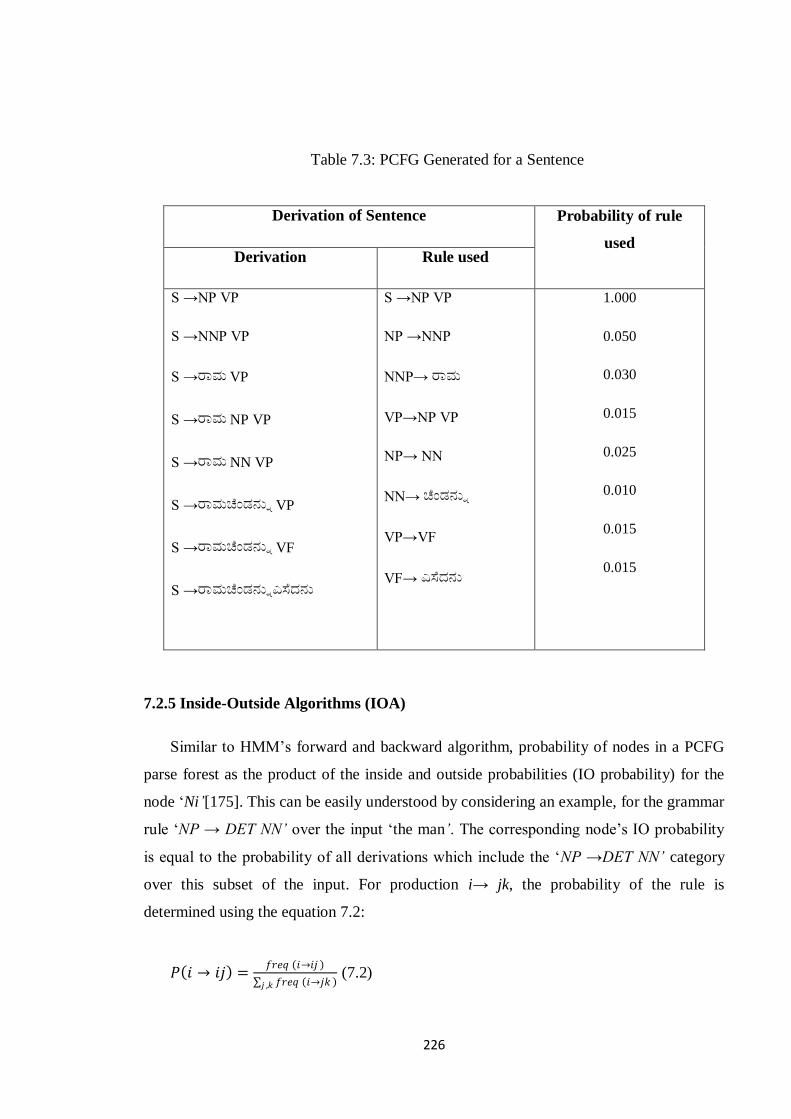
Table 7.3 shows the total probability derivation of our previous sentence
ರಭಚೆಂಡನನುಎಸೆದನನ (rAmu ceMDannu esedanu) ‟Rama threw the ball‟. Total probability
for derivation of sentence is calculated by multiplying the probabilities used to derive the
sentence.
Total probability = 1.0 * 0.05 * 0.030 * 0.015 * 0.025 * 0.010 * 0.015 * 0.015
226
Table 7.3: PCFG Generated for a Sentence
Derivation of Sentence Probability of rule
used Derivation Rule used
S →NP VP
S →NNP VP
S →ರಭ VP
S →ರಭ NP VP
S →ರಭ NN VP
S →ರಭಚೆಂಡನನು VP
S →ರಭಚೆಂಡನನು VF
S →ರಭಚೆಂಡನನುಎಸೆದನನ
S →NP VP
NP →NNP
NNP→ ರಭ
VP→NP VP
NP→ NN
NN→ ಚೆಂಡನನು
VP→VF
VF→ ಎಸೆದನನ
1.000
0.050
0.030
0.015
0.025
0.010
0.015
0.015
7.2.5 Inside-Outside Algorithms (IOA)
Similar to HMM‟s forward and backward algorithm, probability of nodes in a PCFG
parse forest as the product of the inside and outside probabilities (IO probability) for the
node „Ni’[175]. This can be easily understood by considering an example, for the grammar
rule „NP → DET NN’ over the input „the man’. The corresponding node‟s IO probability
is equal to the probability of all derivations which include the „NP →DET NN’ category
over this subset of the input. For production i→ jk, the probability of the rule is
determined using the equation 7.2:
𝑃 𝑖 → 𝑖𝑗 =𝑓𝑟𝑒𝑞 𝑖→𝑖𝑗
𝑓𝑟𝑒𝑞 𝑖→𝑗𝑘 𝑗 ,𝑘 (7.2)

227
Consider a CFG grammar G as a tuple {NT, Σ, P, R}, where NTand Σ elements
represent the set of non-terminal and terminal symbols of the grammar respectively. The
element P represents the set of production rules, while R represents the non-terminal
category that is considered the top grammar category. For given input sequence of
terminals of the grammar {a1,... aT}, we denote e(s, t, Ni) and f(s, t, Ni) are the inside and
outside probabilities respectively for a node „Ni’, that spans input items as to at
inclusively. Fig. 7.2 illustrates the corresponding nodes in the parse forest used when
calculating the inside and outside probabilities for Ni. Nonleaf nodes in the figure
represent NT categories, and „Nr’is the root node whose category r is in the set R. Leaf
nodes represent S categories of the grammar, that is, the input sequence {a1, ... aT}.
Fig. 7.2:The inside (e) and outside (f) regions for node Ni
7.2.5.1 Inside Probability
The inside probability e(s, t, Ni) represents the probability of sub-analyses that are
rooted with mother category „i'for this sentence over the word span s to t. Each production
is of the form i → jkwhere each set of daughter nodes „Nj‟ and „Nk‟ span from as to „ar‟
and „ar‟+1 to „at‟, respectively.Fig. 7.3 illustrates this structure for node „Ni’.Inside
probability of each node corresponds to the product of all CFG rules that are applied to
create the sub-analysis as shown in equation 7.3.
𝑒 𝑠, 𝑡, 𝑁𝑖 = 𝑃 𝑖 → 𝑗𝑘 𝑒 𝑠, 𝑟, 𝑁𝑗 𝑒𝑡−1𝑟=𝑠 𝑟 + 1, 𝑡,𝑁𝑘 𝑗 ,𝑘 (7.3)

228
Fig. 7.3: Inside probabilities for node Ni
7.2.5.2Outside Probability
On the other hand, the outside probability f(s, t, Ni), for a node „Ni‟ is calculated using
all the nodes for which the node is a daughter (sub-analysis). This calculation includes the
inside probability of the other daughter nodes of which „Ni’is a member. This means,
category „i'could appear in two different settings: j→ik or j→ki, as shown in Fig. 7.4.
Fig. 7.4: Outside probabilities for node Ni
The outside probability of „Ni’is calculatedusing the outside probability of the mother
node (Nj) multiplied by the product of inside probabilities of the daughters other than
„Ni’i.e. „Nk’. In each instance when „Ni’is a daughter of a node, the outside probability f (s,
t, Ni) for a given sentence is calculated using the equation 4.

229
𝑓 𝑠, 𝑡, 𝑁𝑖 = 𝑓 𝑠, 𝑟, 𝑁𝑗 𝑃 𝑗 → 𝑖𝑘 𝑒 𝑡 + 1, 𝑟, 𝑁𝑘
𝑇
𝑟=𝑡+1
𝑗 ,𝑘
+ 𝑓 𝑟, 𝑡,𝑁𝑗 𝑃 𝑗 → 𝑘𝑖 𝑒 𝑟, 𝑠 − 1,𝑁𝑘
𝑠−1
𝑟=1
𝑗 ,𝑘
(7.4)
7.2.6 Support Vector Machine as a Classifier
SVM is a useful technique for data classification. A typical use of SVM involves two
steps: first, training a data set to obtain a model and second, using the model to predict
information of a testing data set [11,176]. For Each instance in the training set contains
one “target value" (i.e. the class labels) and several “attributes" (i.e. the features or
observed variables). The goal of SVM is to produce a model (based on the training data)
which predicts the target values of the test data given only the test data attributes. The
SVMs rely on maximum-margin hyper plane classifier which is used to predict the next
action at the parsing time.
7.3 PROPOSED SYNTACTIC PARSER
7.3.1 Contribution
The most important work in thedeveloped systemwasthe creation of training data set.
The training data set plays a key role in determining the efficiency of the syntactic parser.
The more accurate the training data, the more accurate is the syntactic parser. Around
1000 diverse sentences have been taken from various Kannada grammar books and tagged
using the SVM based POS tagger. All the sentences were then manually converted into
Penn Treebank format.
7.3.2Bracketing Guidelines for Kannada Penn Treebank Corpus
Penn Treebank corpora have proved their value both in linguistics and language
technology all over the world. Information obtained from the Penn Treebank corpora has
challenged the intuitive language study for various NLP purposes [171, 173]. The main
effort for developing a Penn Treebank based corpus is to represent the text in the form of a
„Treebank‟, where tree structures represent syntactic structures of phrases and sentences.

230
This is followed by an application of a parsing model to the resulting Treebank. Therefore
with the availability of Treebank of annotated sentences it is easy to develop natural
language syntactic parser and other NLP application tools. The main effort is to create
well balanced Treebank based corpus with almost all possible inflections. The developed
corpus mainly consists of simple sentences as well as some of the compound
sentences.Some of which are illustrated as follows:
7.3.2.1 Simple Declarative Sentence
Consider a simple declarative sentence ರಭಚೆಂಡನನುಎಸೆದನನ (rAma ceMDannu esedanu
„Rama threw the ball’). The Fig. 7.5 shows an example for the „Penn tree syntax‟ and the
Fig. 7.6show the corresponding parse tree for this sentence.
(S (NP (NNP ರಭ ) (VP (NN ಚೆಂಡನನು) (VF ಎಸೆದನನ ))) (. .))
Fig. 7.5:Penn Treebank format of a Declarative sentence
Fig. 7.6:Parse tree for the Fig. 7.5
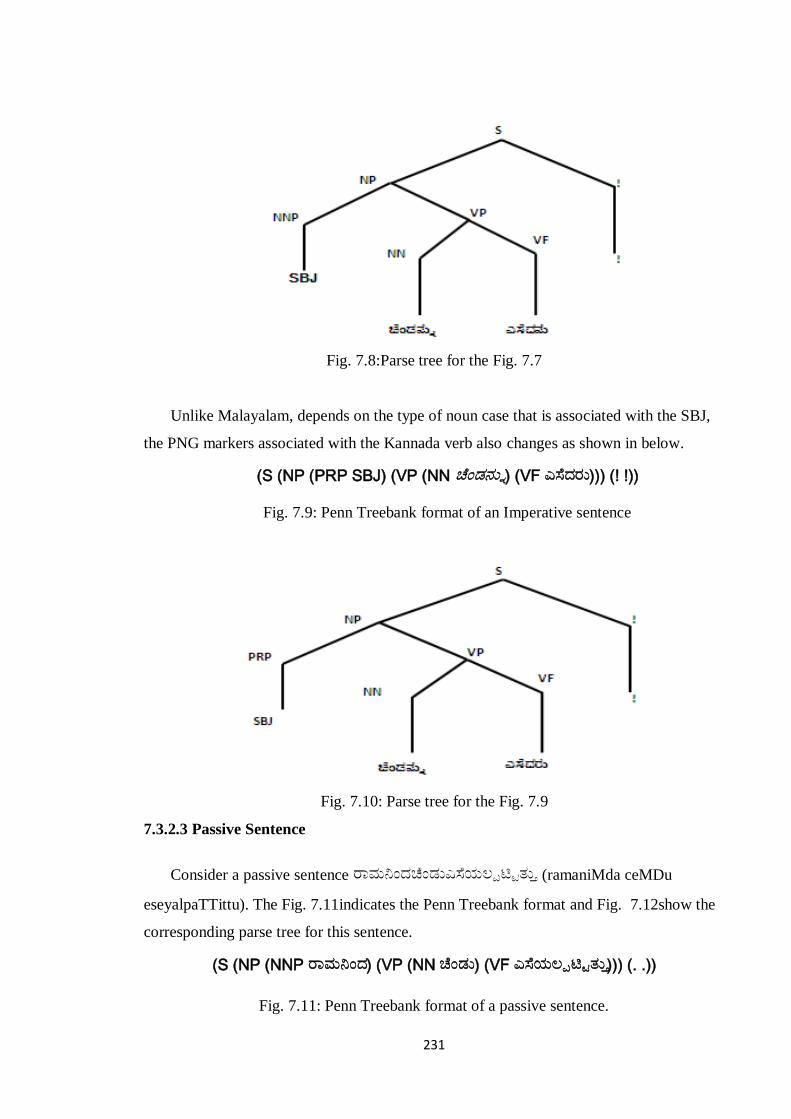
7.3.2.2Imperative Sentences
Imperatives are formed from the root of the verb and usually given a null subject-SBJ,
as shown in Fig. 7.7 and7.8.
(S (NP (NNP SBJ) (VP (NN ಚೆಂಡನನು) (VF ಎಸೆದನನ ))) (! !))
Fig. 7.7:Penn Treebank format of an Imperative sentence
231
Fig. 7.8:Parse tree for the Fig. 7.7
Unlike Malayalam, depends on the type of noun case that is associated with the SBJ,
the PNG markers associated with the Kannada verb also changes as shown in below.
(S (NP (PRP SBJ) (VP (NN ಚೆಂಡನನು) (VF ಎಸೆದಯನ))) (! !))
Fig. 7.9: Penn Treebank format of an Imperative sentence
Fig. 7.10: Parse tree for the Fig. 7.9
7.3.2.3 Passive Sentence
Consider a passive sentence ರಭನೆಂದಚೆಂಡನಎಸೆಮಲ್ಪಟ್ಟುತನತ (ramaniMda ceMDu
eseyalpaTTittu). The Fig. 7.11indicates the Penn Treebank format and Fig. 7.12show the
corresponding parse tree for this sentence.
(S (NP (NNP ರಭನೆಂದ) (VP (NN ಚೆಂಡನ) (VF ಎಸೆಮಲ್ಪಟ್ಟುತನತ))) (. .))
Fig. 7.11: Penn Treebank format of a passive sentence.
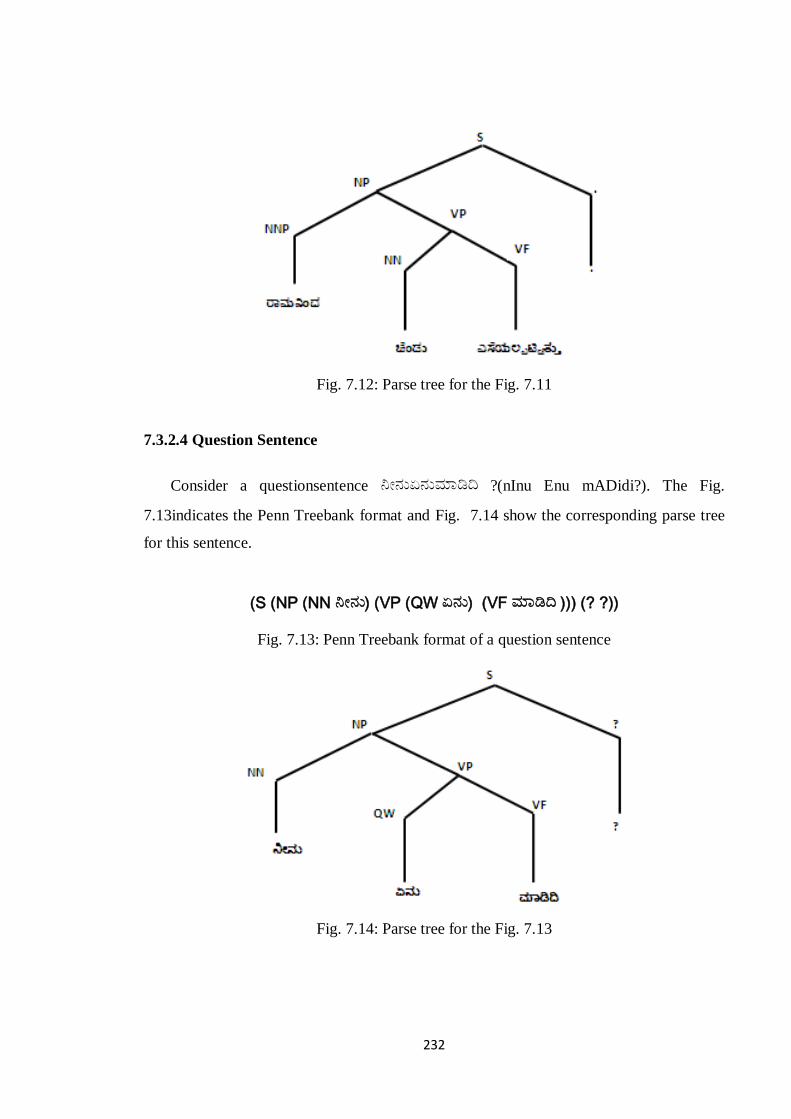
232
Fig. 7.12: Parse tree for the Fig. 7.11
7.3.2.4 Question Sentence
Consider a questionsentence ನೋನನಏನನಮಡಿದ ?(nInu Enu mADidi?). The Fig.
7.13indicates the Penn Treebank format and Fig. 7.14 show the corresponding parse tree
for this sentence.
(S (NP (NN ನೋನನ) (VP (QW ಏನನ) (VF ಮಡಿದ ))) (? ?))
Fig. 7.13: Penn Treebank format of a question sentence
Fig. 7.14: Parse tree for the Fig. 7.13

233
Questions may consists of a null subject-SBJ. Fig. 7.15 and 7.16 below shows an
example for the question with null subject.Depending on the type of noun case associated
with the SBJ, the PNG markers associated with the Kannada verb also changes
(S (NP (NNP SBJ) (VP (QW ಏನನ) (VF ಮಡಿದ ))) (? ?))
Fig. 7.15: Penn Treebank format of a question sentence
Fig. 7.16: Parse tree for the Fig. 7.15
7.3.2.5Compound Sentences
The relationship of conjoining in Kannada may be any one of: (i) additive indicated by
„ಭತನತ‟(mattu) or „ಊ‟(U) (ii) alternative indicated by „ಅಥವ‟ (adhava) or
„ಇಲ್ಿಲ್ಲಲ್ಿಳ‟(illalillave) and (iii) adversative indicated by „ಆದರ‟(Adare). Coordination
may be take place either at phrase or clause level. Fig 7.17 and 7.19 illustratestwo
examples of Treebank formatforcompound sentences coordinated at phrase level. Fig 7.18
and 7.20 shows their corresponding parse tree structures.
(S (NP (NN ಹನಡನಗಿಮಯನ) (NP (CNJ ಭತನತ) (NN ಹನಡನಗಯನ)))
(VP (NNಚೆಂಡನನು)(VP (ADV ಎಸೆದನ) (VF ಹಿಡಿಮನತ್ತತದ್ಯನ))) (. .))
Fig. 7.17: Penn Treebank format of a compound sentence coordinated at phrase level
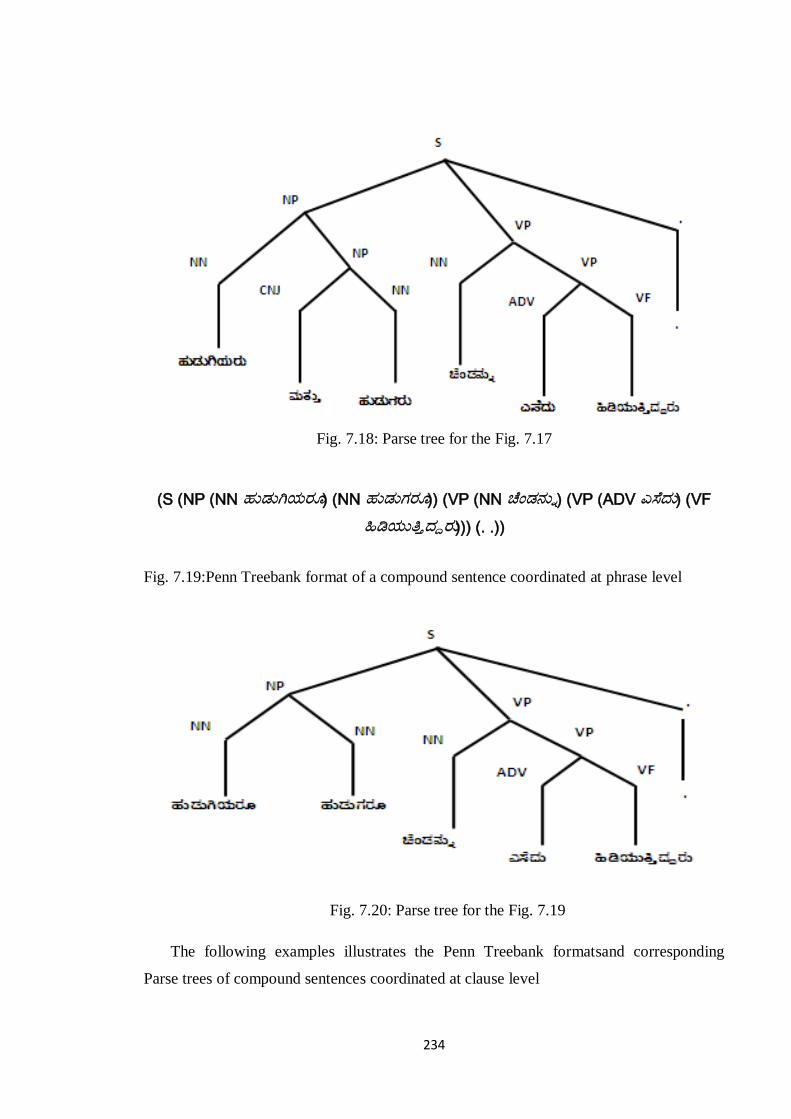
234
Fig. 7.18: Parse tree for the Fig. 7.17
(S (NP (NN ಹನಡನಗಿಮಯ ) (NN ಹನಡನಗಯ )) (VP (NN ಚೆಂಡನನು) (VP (ADV ಎಸೆದನ) (VF
ಹಿಡಿಮನತ್ತತದ್ಯನ))) (. .))
Fig. 7.19:Penn Treebank format of a compound sentence coordinated at phrase level
Fig. 7.20: Parse tree for the Fig. 7.19
The following examples illustrates the Penn Treebank formatsand corresponding
Parse trees of compound sentences coordinated at clause level
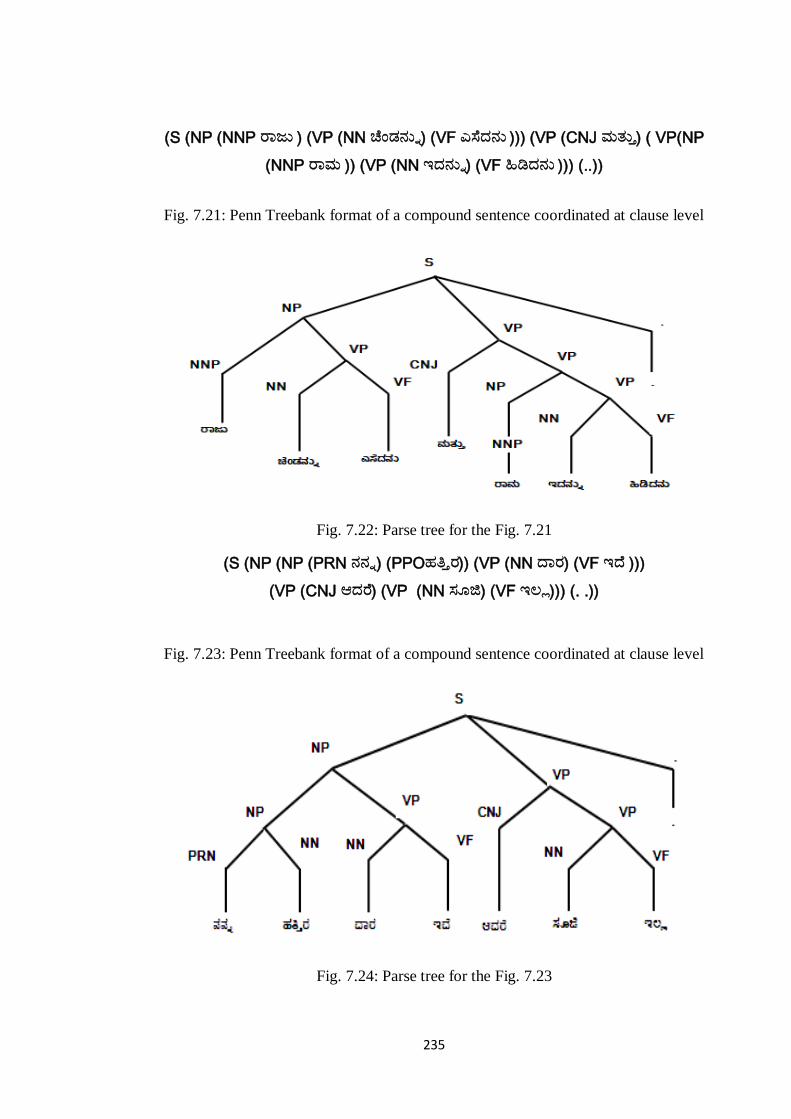
235
(S (NP (NNP ರಜನ ) (VP (NN ಚೆಂಡನನು) (VF ಎಸೆದನನ ))) (VP (CNJ ಭತನತ) ( VP(NP
(NNP ರಭ )) (VP (NN ಇದನನು) (VF ಹಿಡಿದನನ ))) (..))
Fig. 7.21: Penn Treebank format of a compound sentence coordinated at clause level
Fig. 7.22: Parse tree for the Fig. 7.21
(S (NP (NP (PRN ನನು) (PPOಹತ್ತತಯ)) (VP (NN ದಯ) (VF ಇದೆ )))
(VP (CNJ ಆದರ) (VP (NN ಸ ಜಿ) (VF ಇಲ್ )ಿ)) (. .))
Fig. 7.23: Penn Treebank format of a compound sentence coordinated at clause level
Fig. 7.24: Parse tree for the Fig. 7.23
236
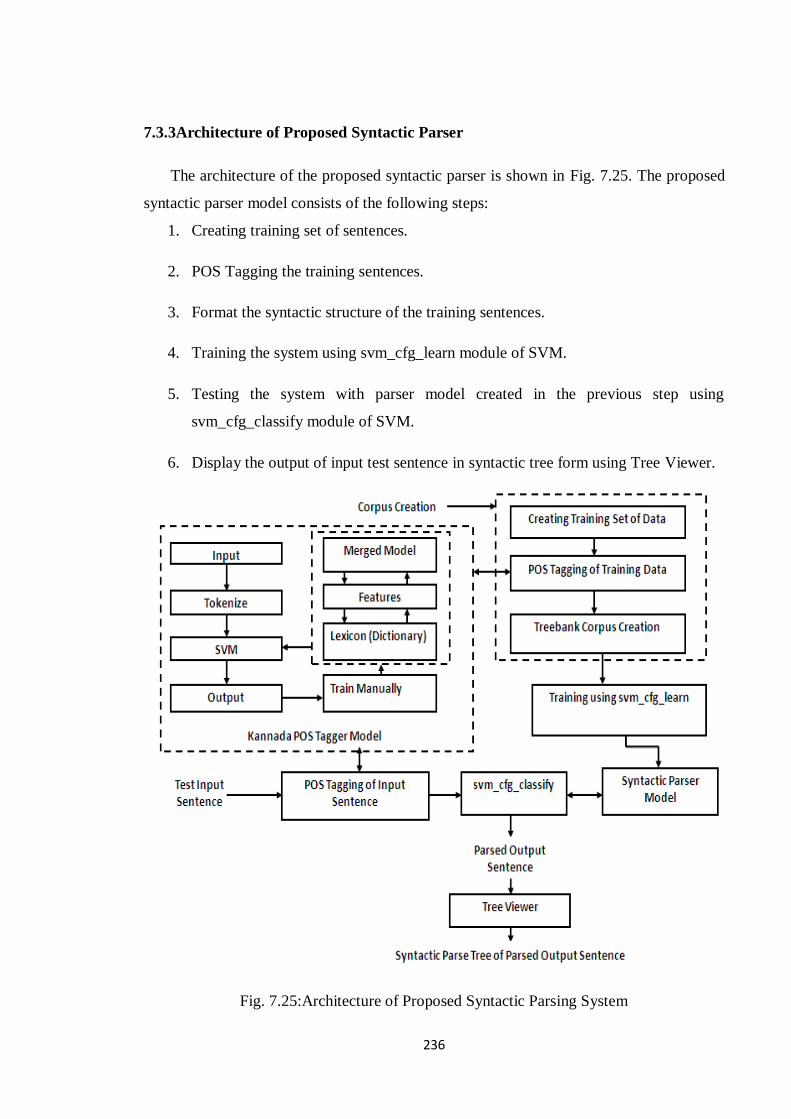
7.3.3Architecture of Proposed Syntactic Parser
The architecture of the proposed syntactic parser is shown in Fig. 7.25. The proposed
syntactic parser model consists of the following steps:
1. Creating training set of sentences.
2. POS Tagging the training sentences.
3. Format the syntactic structure of the training sentences.
4. Training the system using svm_cfg_learn module of SVM.
5. Testing the system with parser model created in the previous step using
svm_cfg_classify module of SVM.
6. Display the output of input test sentence in syntactic tree form using Tree Viewer.
Fig. 7.25:Architecture of Proposed Syntactic Parsing System

237
In any statistical system, the corpus creation is a major task which consumes
considerable time. The parser model is created with the data set containing simple
sentences and some complex sentences. The training data covers almost all the patterns
available for the simple sentences. The first three steps in the developed system were used
to create the Treebank based corpus. A brief description of each of these steps is as
follows:
7.3.3.1 Creating training set of sentences
The developed Kannada Treebank corpora consist of 1,000 random diverse Kannada
sentences. These sentences were carefully constructed by taking care of various factors for
generating good corpora.
7.3.3.2 POS Tagging the training sentences
The next step was to assign parts-of speech tags to each and every word in the
sentences using the POS tagger model. Parts-of speech tagging is an important stage in our
Treebank based syntactic parsing approach. The developed system uses a statistical based
POS tagger developed using SVMTool, for assigning proper tags to each and every word
in the training and testing sentences. More detailed information on the POS tagset and
guidelines concerning its uses are found in [177].
7.3.3.3 Format the syntactic structure of the training sentences
The major work in the corpus creation stage is to find out the syntactic structure of
each and every sentence.The developed statistical corpus was based on well known Penn
Treebank corpora, so that the syntactic format of each and every training sentence were
manually created by resolving various ambiguities and dependencies. The sentences in the
training corpus were divided into various phrases and phrases are further divided into one
or more words.
7.3.3.4 Training the system using svm_cfg_learn
SVMcfg is a flexible and extensible tool for learning models in a wide range of
domains. SVMcfg is an implementation of the SVM algorithm for learning a weighted
context free grammar. The weight of an instantiated rule can depend on the complete
terminal sequence, the span of the rule, and the spans of the children trees. Another

238
important property of the SVMcfg is that, it‟s easy to add attributes that reflect the
properties of the particular domain at hand.
The SVMcfg mainly consists of two modules called learning module namely
svm_cfg_learn and classification module namely svm_cfg_classify. These modules are
used respectively for learning and classification for a set of data.SVMcfg uses the learning
module called svm_cfg_learn for learning the training corpus. The usage of this module is
much like the svm_light module and the syntax is as follows:
svm_cfg_learn -c 1.0 train.data model
Which train SVM on training set train.data and output the learned grammar to the two
model files called model.svm and model.grammar by setting the regularization parameterC
to 1.0. In the developed systems, 171 different rules were extracted from a training data of
1000 sentences as shown in table 7.4. Since the svm_cfg_leran module utilized the
probabilistic context free grammar formalism, the module also finds out the probabilities
of each and every rule as explained in section 8.
Table 7.4: Generated Rules from the Training Corpus
NP --> VNAJ NN
VP --> ADV CVB
VP_VP --> VP VP
'ROOT' --> S
NP --> PRP VP
NP --> PRP VINT
VP --> PRP VP
NP --> PRP NNQ_NN
VP --> NP
NP --> NNQ
NP --> NN
NP --> COMPINT NN
NP --> NN NNP
NP --> NNP VINT
VP --> NNP VP
NP --> NNP NNQ_NN
NP --> NN NNP_NN
VP --> VP NNP
VP --> VNAV VBG
VP --> VF
VP --> VF NNP
VP --> ADV VINT
ADJ_NNP --> ADJ NNP

239
NP --> PRP
NP --> PRP NNP
NN --> PRP
NP --> NNP
NP --> NNP NNP
NP --> NNP CNJ
NP --> NN NN_ADJ
VP --> NNP CVB_VF
NN_ADJ --> NN ADJ
NNP_NNP --> NNP NNP
VP --> VNAV CVB
VP --> ADV CVB_VF
VP --> VAX
VP --> VBG
NP --> PRP ADJ_NN
NP --> DET ADJ_NN
VP --> NP VP_VP
NP --> QW
NP --> NNPC
NP --> NNP ADJ_NN
NP --> CRD ADJ_NN
NP --> CVB NNP
VP --> CVB
VP --> NP VF
S --> NP VP_.
NP --> ORD
ADV_NN_VAX --> ADV NN_VAX
VP --> NNQ VF
NP --> NN VF
VP --> NN VF
VP --> NN NN_VF
NP_VP_. --> NP VP_.
VP --> ADJ NN_VF
NNP_NNP_NNP --> NNP NNP_NNP
NN_VF --> NN VF
INT_ADJ_NN --> INT ADJ_NN
NP --> PRP VF
VP --> PRP VF
ADJ_NN_VF --> ADJ NN_VF
VP --> DET VF
VP --> DET NN_VF
PRP_VF --> PRP VF
NP --> NNP VF
VP --> NNP VF
VP --> CRD VF
VP --> COM VF
VP --> COM NN_VF
VP --> ADV VF

240
NNP_VF --> NNP VF
VP --> ADV NN_VF
VP --> VAX VF
ADV_VF --> ADV VF
VP --> VBG VF
NP --> PRP ORD
S -->NP .
VP --> VINT VF
NP --> NNC NNC
S --> NP NP_VP_.
NP --> NNP COM
NP --> NNP ORD
NP --> NNP NNP_NNP_NNP
NP --> NNP COM_NN
S -->VP .
NP_. -->NP .
VP --> INT VF
VP --> INT ADV_NN_VAX
NNP_NNP_NNP_NNP --> NNP NNP_NNP_NNP
VP_. -->VP .
VP --> CVB VF
VP --> CVB NN_VF
NP --> NP NP
NP --> DET NN_NN
CVB_VF --> CVB VF
VP --> ORD VF
CVB_NN_VF --> CVB NN_VF
NP --> NN NP
NP --> CRD NN_PPO
VP --> RDW NN_VF
NP --> ADJ NP
VP --> VF ADV
NP --> PRP NP
NP --> NNP NP
NP --> NN PPO
NP --> NNP NNP_NNP_NNP_NNP
VP --> NN ADV_VF
NP --> CRD NP
VP --> VP PRP
VP --> CRD ADJ_NN_VF
NN_PPO --> NN PPO
NP --> PRP PRP
NP --> NNP PRP
VP --> NN VAX
NN_VAX --> NN VAX
VP --> ADV PRP_VAX
VP --> PRP VAX
PRP_VAX --> PRP VAX

241
VP --> NNP VAX
NP --> CRD INT_ADJ_NN
VP --> COM PRP_VF
VP --> ADV VAX
VP --> ADV PRP_VF
NP --> CVB PRP
NP --> NNQ NN
NP --> NN NN
VP --> NN VBG
NP --> NN NN_CVB
NNQ_NN --> NNQ NN
NP --> CRD ADJ_NNP
NP --> ADJ NN
NN_NN --> NN NN
VP --> ADJ NN
VP --> ADV CVB_NN_VF
ADJ_NN --> ADJ NN
NP --> PRP NN
NP --> PRP VBG
NP --> DET NN
NP --> DET VBG
NP --> NP NP_VP
S --> NP NP_.
VP --> NP NP_VP
NP --> NNP NN
NP --> NNP VBG
NP --> NN CVB
VP --> NN CVB
PRP_NN --> PRP NN
NP --> CRD NN
S --> VP NP_.
NNP_NN --> NNP NN
VP --> COM NNP_VF
NN_EMP --> NN EMP
NN_CVB --> NN CVB
NP --> ADV NN_CVB
VP --> ADV NNP_VF
NP --> VBG NN
NP --> PRP CVB
VP --> VBG NN
COM_NN --> COM NN
NP --> NP VP
VP --> NP VP
NP --> NN VP
NP --> NNP CVB
VP --> NN VP
NP_VP --> NP VP
VP --> NN VINT

242
NP --> NN PRP_NN
NP --> INT NN
VP --> VP VP
NP --> ADJ NN_EMP
7.3.3.5 Testing the system using svm_cfg_classify
The trained model created in the previous step can be used to predict the syntactic tree
structure of new test sentences. The test file containing the test sentences is given to the
POS tagger model for assigning syntactic tags to each and every word in the sentence. The
result of the POS tagger is given to the svm_cfg_classify. Svm_ cfg_classify analyzes the
syntactic structure of test sentences by referring the model files that were created by
svm_cfg_learn. Svm_cfg_classify module makes predictions about the syntactic structure
of test sentences based on probabilistic context free grammar formalism and inside-outside
algorithms. The syntax of svm_cfg_classify is as follows:
svm_cfg_classify test.data model predictions
For all test examples in test.data, the predicted parse trees are written to a file called
predictions.
7.3.3.6 Display the output using Tree Viewer
NLP or Linguistic researchers who work in syntax often want to visualize parse trees or
create linguistic trees for analyzing the structure of a language. The syntactic parse tree of
the test sentence is created and displayed by using „Syntax Tree Viewer‟ software
developed using Java language.
7.4 SYSTEM PERFORMANCE AND RESULT
Even though the proposed syntactic parser system was developed with a small sized
corpus consists only 1000 distinct sentences, the result obtained was well promising and
encouraging. The performance of the system was evaluated using svm_cfg_classify
module and the incorrect outputs were noticed.On contrast to the rule based approach, the
systems performance was considerably increased by adding the input sentences to the
training corpus whose corresponding outputs were incorrect during testing and evaluation.

243
Performances of the systems were evaluated with a set of 100 distinct sentences that were
not present in the corpus. Even though this is just a prototype system with very small sized
corpus, the result obtained was promising and encouraging. Fig. 7.26 shows the output
screen shot for a test sentence „ರ್ನನಒೆಂದನತರಫರಮನತತಇದೆ್ೋನೆ‟ (nAnu oMdu patra
bareyutta iddEne-I am writing a letter).
Fig. 7.26: Output Screenshot
7.5 SUMMARY
This work is used to create a prototype version of a statistical based syntactic parser
for Kannada language implemented using SVM. The training corpus consists of Penn
Treebank form of the Kannada sentences. The corpus creation is the main objective of the
work which consumes considerable time. The SVM based POS tagger is used to tag each
and every word in the training. The performance of the developed syntactic parser model

244
can be improved by incorporating more syntactical information by increasing more and
more sentence types and well-formed large corpus. In future we can also use these
syntactic parsers for tree to tree translation. This will be very useful for bilingual MT from
English to South Dravidian languages. To the best of my knowledge this is the first
attempt of computationally constructing statistical based syntactic parser models for
Kannada language.
7.6 PUBLICATION
Antony P J, Nandini. J. Warrier and Soman K P: “Penn Treebank-Based Syntactic
Parsers for South Dravidian Languages using a Machine Learning Approach”,
International journal on Computer Application (IJCA), No. 08, 2010, ISBN: 978-93-
80746-92-0, Published by: Foundation of Computer Science,Abstracted and indexed in
DOAJ, Google Scholar, Informatics, ProQuest CSA Technology Research Database.
Impact factor: 0.87.





























