Embed Size (px)
Citation preview

Synchronization without Contention
John M. Mellor-Crummey and Michael L. Scott+
ECE 259 / CPS 221 Advanced Computer Architecture II
Presenter : Tae Jun Ham2012. 2. 16

Problem Busy-waiting synchronization incurs high memory/network
contention- Creation of hot spot = degradation of performance- Causes cache-line invalidation (for every write on lock) Possible Approach : Add special-purpose hardware for
synchronization - Add synchronization variable to the switching nodes on
interconnection- Implement lock queuing mechanisms on cache controller Suggestion in this paper : Use scalable synchronization
algorithm (MCS) instead of special-purpose hardware

Test and Set- Require : Test and Set (Atomic operation)
- Problem :
1. Large Contention – Cache / Memory
2. Lack of Fairness - Random Order
Review of Synchronization Algorithms
LOCKwhile (test&set(x) == 1); UNLOCKx = 0;

Test and Set with Backoff- Almost similar to Test and Set but has delay
- Time :
1. Linear : Time = Time + Some Time
2. Exponential : Time = Time * Some constant- Performance : Reduced contention but still not fair
Review of Synchronization Algorithms
LOCKwhile (test&set(x) == 1) {
delay(time);} UNLOCKx = 0;

Ticket Lock- Requires : fetch and increment (Atomic Operation)
- Advantage : Fair (FIFO)- Disadvantage : Contention (Memory/Network)
Review of Synchronization Algorithms
LOCKmyticket = fetch & increment (&(L->next_ticket));while(myticket!=L->now_serving) {
delay(time * (myticket-L->now_serving));}UNLOCKL->now_serving = L->now_serving+1;

Anderson Lock (Array based queue lock)- Requires : fetch and increment (Atomic Operation)
- Advantage : Fair (FIFO), No cache contention- Disadvantage : Requires coherent cache / Space
Review of Synchronization Algorithms
LOCKmyplace= fetch & increment (&(L->next_location));while(L->location[myplace] == must_wait) ;L->location[myplace]=must_wait;}UNLOCKL->location[myplace+1]=has_lock;

MCS Lock – Based on Linked List Acquire
1. Fetch & Store Last processor node (Get predecessor & set tail)
2. Set arriving processor node to locked
3. Set last processor node’s next node to arriving processor node
4. Spin till Locked=false
MCS Lock
1 2 3 4
tail
1 2 3 4
tail
Locked : False(Run)
Locked : False(Run)
Locked :True(Spin)
Locked :True(Spin)
Locked :True(Spin)
Locked :True(Spin)
Locked :True(Spin)
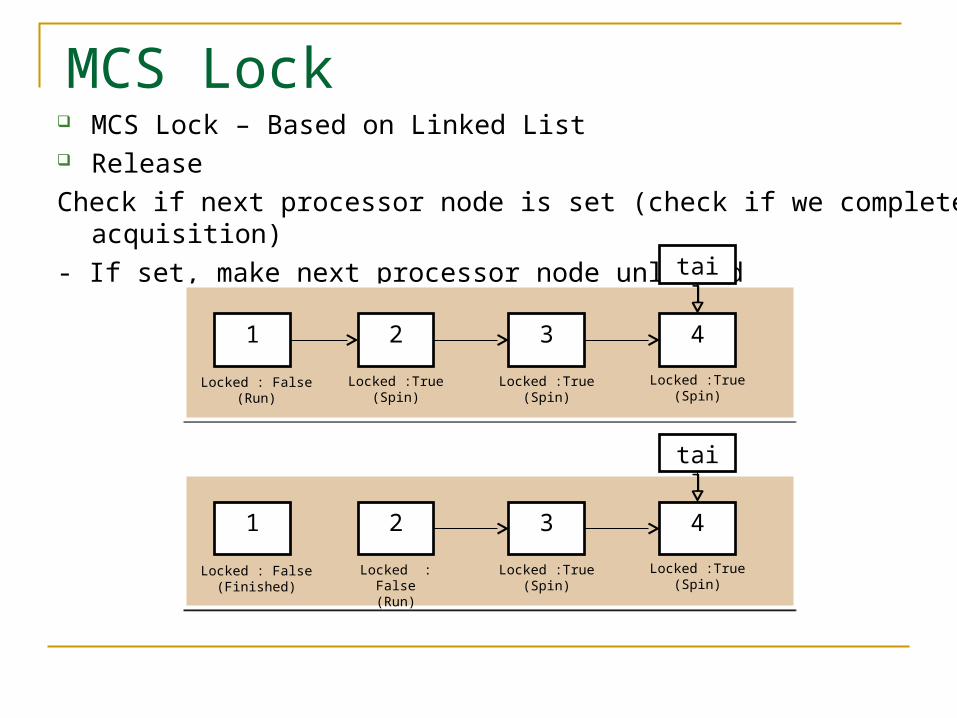
MCS Lock – Based on Linked List Release
Check if next processor node is set (check if we completed acquisition)
- If set, make next processor node unlocked
MCS Lock
1 2 3 4
tail
Locked : False(Run)
Locked :True(Spin)
Locked :True(Spin)
Locked :True(Spin)
1 2 3 4
tail
Locked : False(Finished)
Locked : False(Run)
Locked :True(Spin)
Locked :True(Spin)
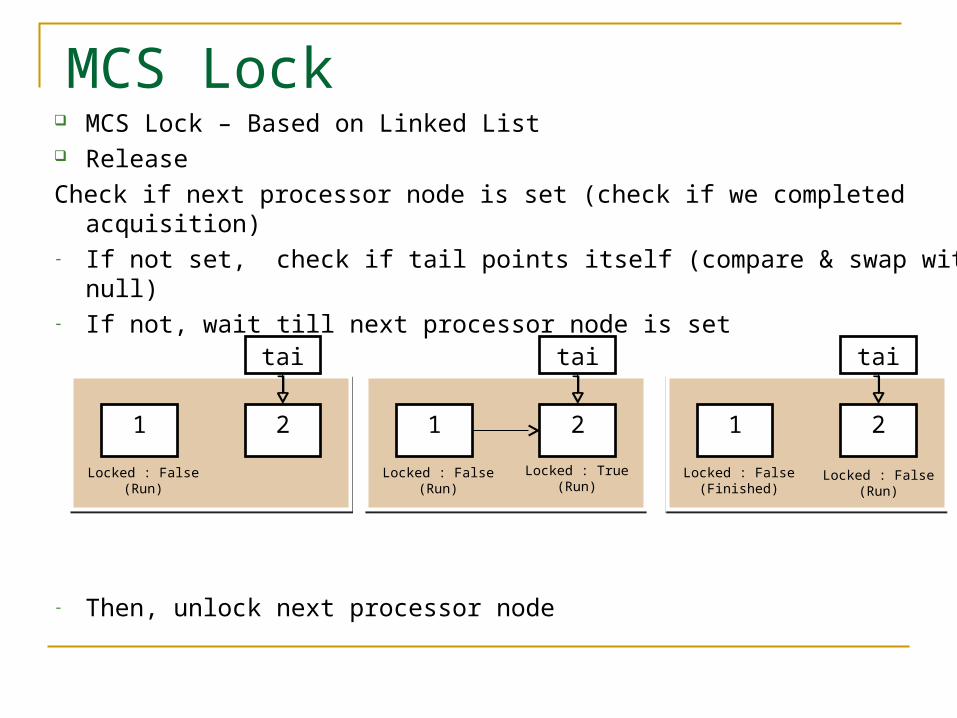
MCS Lock – Based on Linked List Release
Check if next processor node is set (check if we completed acquisition)- If not set, check if tail points itself (compare & swap with null)- If not, wait till next processor node is set
- Then, unlock next processor node
MCS Lock
1 2
tail
Locked : False(Run)
1 2
tail
Locked : False(Run)
1 2
tail
Locked : False(Finished)
Locked : False(Run)
Locked : True(Run)

MCS Lock – Based on Linked List
MCS Lock – Concurrent Read Version
MCS Lock – Concurrent Read Version

Start_Read :- If predecessor is nill or active reader, reader_count++ (atomic) ; proceed;- Else, spin till (another Start_Read or End_Write) unblocks this => Then, this unblocks its successor reader (if any)
End_Read : - If successor is writer, set next_writer=successor- reader_count-- (atomic)- If last reader(reader_count==0), check next_writer and unblocks it
Start_Write : - If predecessor is nill and there’s no active reader(reader_count=0), proceed- Else, spin till (last End_Read ) unblocks this
End_Write : - If successor is reader, reader_count++ (atomic) and unblocks it
MCS Lock – Concurrent Read Version

Centralized counter barrier
Keeps checking(test & set) centralized counter Advantage : Simplicity Disadvantage : Hot spot, Contention
Review of Barriers

Combining Tree Barrier
Advantage : Simplicity, Less contention, Parallelized fetch&increment Disadvantage : Still spins on non-local location
Review of Barriers
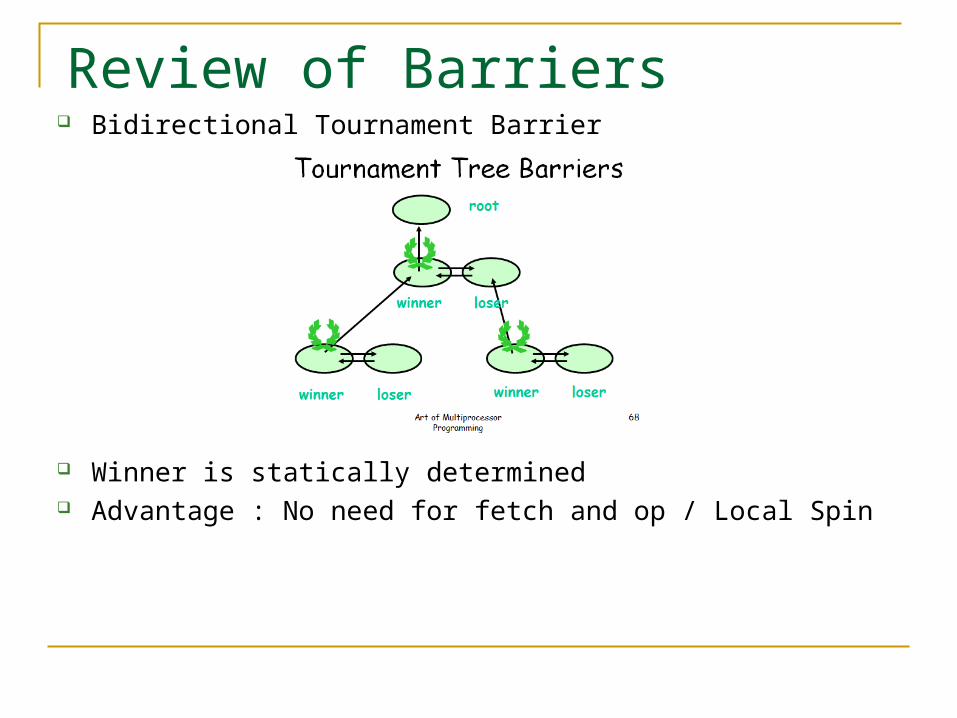
Bidirectional Tournament Barrier
Winner is statically determined Advantage : No need for fetch and op / Local Spin
Review of Barriers

Dissemination Barrier
Can be understood as a variation of tournament (Statically determined) Suitable for MPI system
Review of Barriers

MCS Barrier (Arrival)
Similar to Combined Tree Barrier Local Spin / O(P) Space / 2(P-2) communication / O(log p) critical path
MCS Barriers
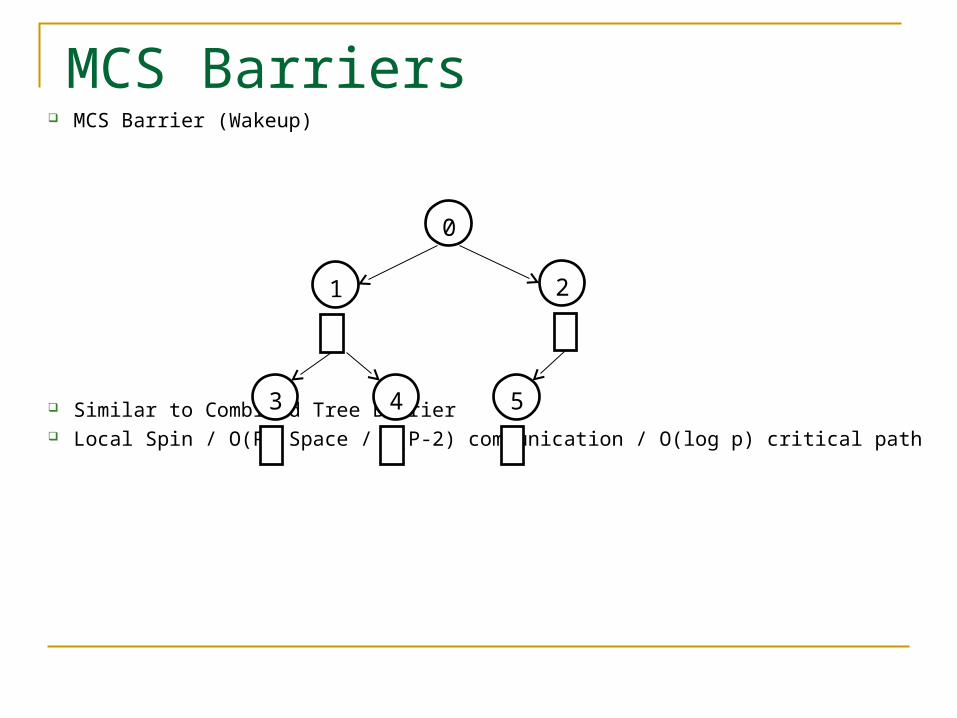
MCS Barrier (Wakeup)
Similar to Combined Tree Barrier Local Spin / O(P) Space / 2(P-2) communication / O(log p) critical path
MCS Barriers
0
1 2
3 4 5

Butterfly Machine result
Three scaled badly; Four scaled well. MCS was best
Backoff was effective
Spin Lock Evaluation

Butterfly Machine result
Measured consecutive lock acquisitions on separate processors instead of acquire/release pair from start to finish
Spin Lock Evaluation

Symmetry Machine Result
MCS and Anderson scales well
Ticket lock cannot be implemented in Symmetry due to lack of fetch and increment operation
Symmetry Result seems to be more reliable
Spin Lock Evaluation

Network Latency
MCS has greatly reduced increases in network latency
Local Spin reduces contention
Spin Lock Evaluation

Butterfly Machine Dissemination was best Bidirectional and MCS Tree was
okay Remote memory access
degrades performance a lot
Barrier Evaluation

Symmetry Machine Counter method was best Dissemination was worst Bus-based architecture:
Cheap broadcast MCS arrival tree outperforms
counter for more than 16 processors
Barrier Evaluation

Local Memory Evaluation

Local Memory Evaluation
Having a local memory is extremely important
It both affects performance and network contention
Dancehall system is not reallyscalable

Summary This paper proposed a scalable spin-lock synchronization algorithm
without network contention
This paper proposed a scalable barrier algorithm
This paper proved that network contention due to busy-wait
synchronization is not really a problem
This paper proved an idea that hardware for QOSB lock
would not be cost-effective when compared with MCS lock
This paper suggests the use of distributed memory or coherent
caches rather than dance-hall memory without coherent caches

Discussion What would be the primary disadvantage of MCS lock?
In what case MCS lock would have worse performance than other
locks?
How do you think about special-purpose hardware based locks?
Is space usage of lock important?
Can we benefit from dancehall style memory architecture?
(disaggregated memory ?)
Is there a way to implement energy-efficient spin-lock?
















![cartaz - aritmar.gal · aRi[t]mar galiza e portugal premio ao mellor tema musical galego premio ao mellor tema musical portugués Premio ao mellor poema portugués premio ao mellor](https://img.dokumen.tips/doc/110x75/5f6b198371734345df77d704/cartaz-aritmar-galiza-e-portugal-premio-ao-mellor-tema-musical-galego-premio.jpg)












