Embed Size (px)
Citation preview

Synchronization Transformationsfor
Parallel Computing
Pedro Dinizand
Martin Rinard
Department of Computer ScienceUniversity of California, Santa Barbara
http://www.cs.ucsb.edu/~{pedro,martin}

Motivation
Parallel Computing Becomes Dominant Form of Computation
Parallel Machines Require Parallel Software
Parallel Constructs Require New Analysis and Optimization Techniques
Our GoalEliminate Synchronization Overhead

Talk Outline
• Motivation
• Model of Computation
• Synchronization Optimization Algorithm
• Applications Experience
• Dynamic Feedback
• Related Work
• Conclusions

Model of Computation
• Parallel Programs• Serial Phases• Parallel Phases
• Single Address Space
• Atomic Operations on Shared Data• Mutual Exclusion Locks• Acquire Constructs• Release Constructs
Acq
S1MutualExclusionRegion
Rel

Reducing Synchronization Overhead
Acq
S1
S2
Rel
S3

Rel
Acq

Synchronization Optimization
Idea:Replace Computations that Repeatedly Acquire and Release the Same Lock with a Computation that Acquires and Releases the Lock Only Once
Result:Reduction in the Number of
Executed Acquire and Release Constructs
Mechanism:Lock Movement Transformations and
Lock Cancellation Transformations

Lock Cancellation

Acquire Lock Movement

Release Lock Movement

Synchronization Optimization Algorithm
Overview:
• Find Two Mutual Exclusion Regions With the Same Lock
• Expand Mutual Exclusion Regions Using Lock Movement Transformations Until They are Adjacent
• Coalesce Using Lock Cancellation Transformation to Form a Single Larger Mutual Exclusion Region

Interprocedural Control Flow Graph

Acquire Movement Paths

Release Movement Paths

Migration Paths and Meeting Edge

Intersection of Paths

Compensation Nodes

Final Result

Synchronization Optimization Trade-Off
• Advantage: • Reduces Number of Executed Acquires and Releases• Reduces Acquire and Release Overhead
• Disadvantage: May Introduce False Exclusion• Multiple Processors Attempt to Acquire Same Lock• Processor Holding the Lock is Executing Code that
was Originally in No Mutual Exclusion Region

False Exclusion Policy
Goal: Limit Potential Severity of False Exclusion
Mechanism: Constrain the Application of Basic
Transformations
• Original: Never Apply Transformations• Bounded: Apply Transformations only on
Cycle-Free Subgraphs of ICFG
• Aggressive: Always apply Transformations

Experimental Results
• Automatic Parallelizing Compiler Based on Commutativity Analysis [PLDI’96]
• Set of Complete Scientific Applications (C++ subset)• Barnes-Hut N-Body Solver (1500 lines of Code)• Liquid Water Simulation Code (1850 lines of Code)• Seismic Modeling String Code (2050 lines of Code)
• Different False Exclusion Policies
• Performance of Generated Parallel Code on Stanford DASH Shared-Memory Multiprocessor

Lock Overhead
0
20
40
60
Perc
enta
ge L
ock
Ove
rhea
d
Barnes-Hut (16K Particles)
Original
Bounded
Aggressive
Percentage of Time that the Single Processor Execution Spends Acquiring and Releasing Mutual Exculsion Locks
0
20
40
60
Perc
enta
ge L
ock
Ove
rhea
d
Water (512 Molecules)
Original
BoundedAggressive
0
20
40
60
Perc
enta
ge L
ock
Ove
rhea
d
String (Big Well Model)
OriginalAggressive

Contention OverheadC
onte
ntio
n Pe
rcen
tage
Percentage of Time that Processors Spend Waiting to Acquire Locks Held by Other Processors
100
0
25
50
75
0 4 8 12 16Processors
Barnes-Hut (16K Bodies)
0
25
50
75
100
0 4 8 12 16Processors
Water (512 Molecules)
0
25
50
75
100
0 4 8 12 16Processors
String (Big Well Model)
OriginalBoundedAggressive

0
2
4
6
8
10
12
14
16
Spe
edup
0 2 4 6 8 10 12 14 16Number of Processors
Ideal
Aggressive
Bounded
Original
Barnes-Hut (16384 bodies)
Performance Results : Barnes-Hut

Performance Results: Water
Ideal
Aggressive
Bounded
Original
0
2
4
6
8
10
12
14
16
0 2 4 6 8 10 12 14 16
Spe
edup
Number of Processors
Water (512 Molecules)

Performance Results: String
String (Big Well Model)
Spe
edup
Number of Processors
0
2
4
6
8
10
12
14
16
0 2 4 6 8 10 12 14 16
Ideal
Original
Aggressive

Choosing Best Policy
• Best False Exclusion Policy May Depend On• Topology of Data Structures• Dynamic Schedule Of Computation
• Information Required to Choose Best Policy Unavailable at Compile Time
• Complications• Different Phases May Have Different Best Policy• In Same Phase, Best Policy May Change Over Time

Solution: Dynamic Feedback
• Generated Code Consists of• Sampling Phases: Measure Performance of Different
Policies• Production Phases : Use Best Policy From Sampling
Phase
• Periodically Resample to Discover Changes in Best Policy
• Guaranteed Performance Bounds

Dynamic Feedback
AggressiveOriginalBounded
Time
Ove
rhea
d
Sampling Phase Production Phase Sampling Phase
AggressiveCodeVersion
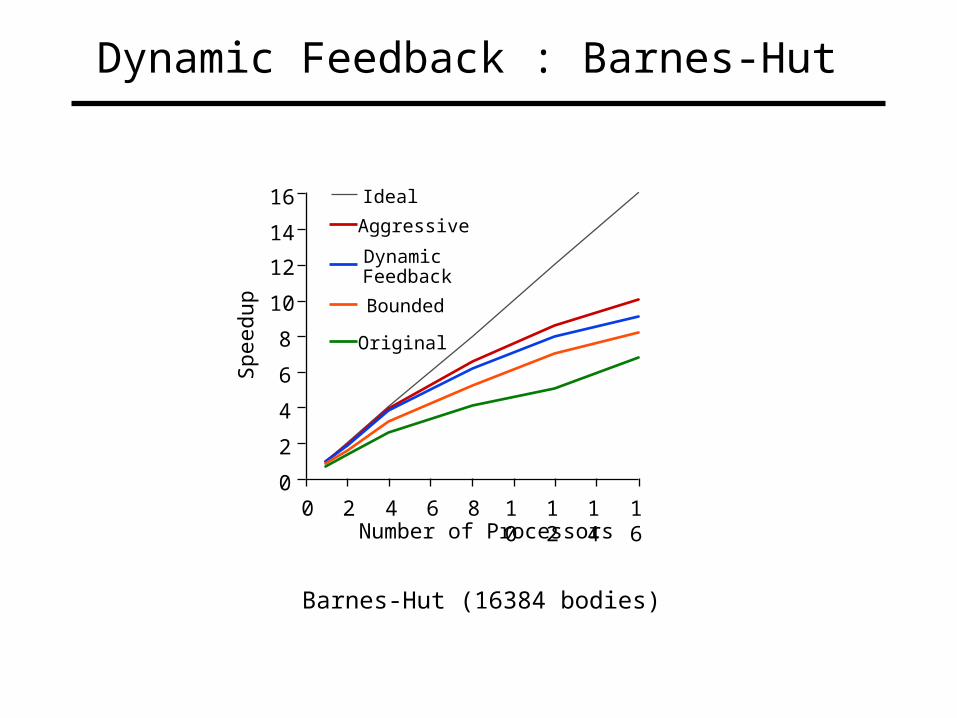
Dynamic Feedback : Barnes-Hut
0
2
4
6
8
10
12
14
16
Spe
edup
0 2 4 6 8 10
12
14
16Number of Processors
Ideal
Aggressive
Dynamic Feedback
Bounded
Original
Barnes-Hut (16384 bodies)

Dynamic Feedback : Water
0
2
4
6
8
10
12
14
16
0 2 4 6 8 10 12 14 16
Spe
edup
Number of Processors
Ideal
Bounded
Original
Aggressive
Dynamic Feedback
Water (512 Molecules)

Dynamic Feedback : String
String (BigWell Model)
0
2
4
6
8
10
12
14
16
0 2 4 6 8 10 12 14 16
Spe
edup
Number of Processors
Ideal
Original
Aggressive
Dynamic Feedback

Related Work
• Parallel Loop Optimizations (e.g. [Tseng:PPoPP95])
• Array-based Scientific Computations• Barriers vs. Cheaper Mechanisms
• Concurrent Object-Oriented Programs (e.g. [PZC:POPL95])
• Merge Access Regions for Invocations of Exclusive Methods
• Concurrent Constraint Programming• Bring Together Ask and Tell Constructs
• Efficient Synchronization Algorithms• Efficient Implementations of Synchronization
Primitives

Conclusions
• Synchronization Optimizations• Basic Synchronization Transformations for Locks• Synchronization Optimization Algorithm
• Integrated into Prototype Parallelizing Compiler• Object-Based Programs with Dynamic Data Structures• Commutativity Analysis
• Experimental Results• Optimizations Have a Significant Performance Impact• With Optimizations, Applications Perform Well
• Dynamic Feedback
![Efficient Object-Based Software Transactions · Ananian/Rinard: Efficient Object-Based Software Transactions, SCOOL '05 [3] Why object-based transactions? Synchronization abstraction](https://img.dokumen.tips/doc/110x75/5e77d0f8466d33505011f7b6/efficient-object-based-software-transactions-ananianrinard-efficient-object-based.jpg)




























